SQLServer2000数据库中如何重建索引
- 格式:pdf
- 大小:46.24 KB
- 文档页数:1

一、基础1、说明:创建数据库CREATE DATABASE database-name2、说明:删除数据库drop database dbname3、说明:备份sql server--- 创建备份数据的 deviceUSE masterEXEC sp_addumpdevice 'disk', 'testBack', 'c:/mssql7backup/MyNwind_1.dat'--- 开始备份BACKUP DATABASE pubs TO testBack4、说明:创建新表create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)A:create table tab_new like tab_old (使用旧表创建新表)B:create table tab_new as select col1,col2… from tab_old definition only5、说明:删除新表drop table tabname6、说明:增加一个列Alter table tabname add column col type注:列增加后将不能删除。
DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
7、说明:添加主键:Alter table tabname add primary key(col)说明:删除主键: Alter table tabname drop primary key(col)8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname注:索引是不可更改的,想更改必须删除重新建。
9、说明:创建视图:create view viewname as select statement删除视图:drop view viewname10、说明:几个简单的基本的sql语句选择:select * from table1 where 范围插入:insert into table1(field1,field2) values(value1,value2)删除:delete from table1 where 范围更新:update table1 set field1=value1 where 范围查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料!排序:select * from table1 order by field1,field2 [desc]总数:select count as totalcount from table1求和:select sum(field1) as sumvalue from table1平均:select avg(field1) as avgvalue from table1最大:select max(field1) as maxvalue from table1最小:select min(field1) as minvalue from table111、说明:几个高级查询运算词A:UNION 运算符UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。
SQLServer创建索引(index)索引的简介:索引分为聚集索引和⾮聚集索引,数据库中的索引类似于⼀本书的⽬录,在⼀本书中通过⽬录可以快速找到你想要的信息,⽽不需要读完全书。
索引主要⽬的是提⾼了SQL Server系统的性能,加快数据的查询速度与减少系统的响应时间。
但是索引对于提⾼查询性能也不是万能的,也不是建⽴越多的索引就越好。
索引建少了,⽤ WHERE ⼦句找数据效率低,不利于查找数据。
索引建多了,不利于新增、修改和删除等操作,因为做这些操作时,SQL SERVER 除了要更新数据表本⾝,还要连带⽴即更新所有的相关索引,⽽且过多的索引也会浪费硬盘空间。
索引的分类:索引就类似于中⽂字典前⾯的⽬录,按照拼⾳或部⾸都可以很快的定位到所要查找的字。
唯⼀索引(UNIQUE):每⼀⾏的索引值都是唯⼀的(创建了唯⼀约束,系统将⾃动创建唯⼀索引)主键索引:当创建表时指定的主键列,会⾃动创建主键索引,并且拥有唯⼀的特性。
聚集索引(CLUSTERED):聚集索引就相当于使⽤字典的拼⾳查找,因为聚集索引存储记录是物理上连续存在的,即拼⾳ a 过了后⾯肯定是 b ⼀样。
⾮聚集索引(NONCLUSTERED):⾮聚集索引就相当于使⽤字典的部⾸查找,⾮聚集索引是逻辑上的连续,物理存储并不连续。
PS:聚集索引⼀个表只能有⼀个,⽽⾮聚集索引⼀个表可以存在多个。
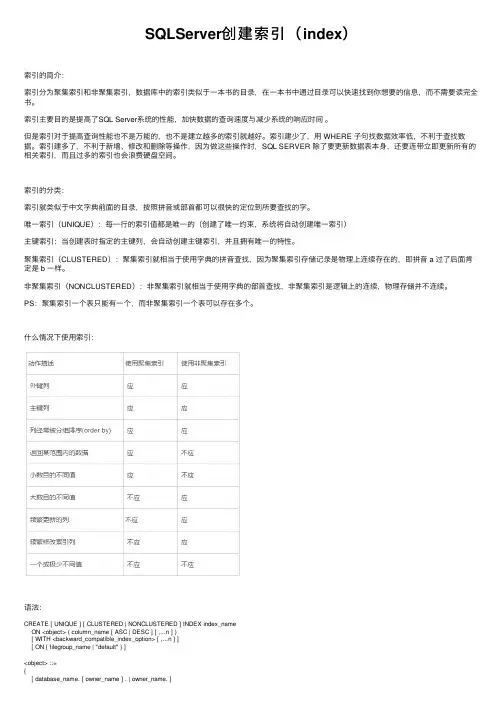
什么情况下使⽤索引:语法:CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_nameON <object> ( column_name [ ASC | DESC ] [ ,...n ] )[ WITH <backward_compatible_index_option> [ ,...n ] ][ ON { filegroup_name | "default" } ]<object> ::={[ database_name. [ owner_name ] . | owner_name. ]table_or_view_name}<backward_compatible_index_option> ::={PAD_INDEX| FILLFACTOR = fillfactor| SORT_IN_TEMPDB| IGNORE_DUP_KEY| STATISTICS_NORECOMPUTE| DROP_EXISTING}参数:UNIQUE:为表或视图创建唯⼀索引。

索引的重建⼀、何时需要重建索引1. 表上频繁发⽣update,delete操作;2. 表上发⽣了alter table ..move操作(move操作导致了rowid变化)。
⼆、判断某索引是否应被重建1、索引重建是否有必要,⼀般看索引是否倾斜的严重,是否浪费了空间,那应该如何才可以判断索引是否倾斜的严重,是否浪费了空间,对索引进⾏结构分析:SQL> analyze index index_name validate structure;2、在相同的session中查询index_stats表SQL> select height,DEL_LF_ROWS/LF_ROWS from index_stats;当查询的height>=4(索引的深度,即从根到叶节点的⾼度)或DEL_LF_ROWS/LF_ROWS>0.2的情况下,就应该考虑重建该索引。
三、如何执⾏重建索引的操作1、drop原索引,然后再创建索引SQL> drop index index_name;SQL> create index index_name on table_name (index_column);上述⽅法相当耗时间,不建议使⽤。
2 、直接重建索引SQL> alter index indexname rebuild;SQL> alter index indexname rebuild online;此⽅法较快,建议使⽤。
rebuild是快速重建索引的⼀种有效的办法,因为它是⼀种使⽤现有索引项来重建新索引的⽅法。
如果重建索引时有其他⽤户在对这个表操作,尽量使⽤带online参数来最⼤限度的减少索引重建时将会出现的任何加锁问题。
由于新旧索引在建⽴时同时存在,因此,使⽤这种重建⽅法需要有额外的磁盘空间可供临时使⽤,当索引建完后把⽼索引删除,如果没有成功,也不会影响原来的索引。
利⽤这种办法可以⽤来将⼀个索引移到新的表空间。

Sql2000r 提供了很多数据库修复的命令,当数据库质疑或是有的无法完成读取时可以尝试这些修复命令。
1. DBCC CHECKDB重启服务器后,在没有进行任何操作的情况下,在SQL查询分析器中执行以下SQL进行数据库的修复,修复数据库存在的一致性错误与分配错误。
use masterdeclare @databasename varchar(255)set @databasename='需要修复的数据库实体的名称'exec sp_dboption @databasename, N'single', N'true' --将目标数据库置为单用户状态dbcc checkdb(@databasename,REPAIR_ALLOW_DATA_LOSS)dbcc checkdb(@databasename,REPAIR_REBUILD)exec sp_dboption @databasename, N'single', N'false'--将目标数据库置为多用户状态然后执行DBCC CHECKDB('需要修复的数据库实体的名称') 检查数据库是否仍旧存在错误。
注意:修复后可能会造成部分数据的丢失。
2. DBCC CHECKTABLE如果DBCC CHECKDB 检查仍旧存在错误,可以使用DBCC CHECKTABLE来修复。
use 需要修复的数据库实体的名称declare @dbname varchar(255)set @dbname='需要修复的数据库实体的名称'exec sp_dboption @dbname,'single user','true'dbcc checktable('需要修复的数据表的名称',REPAIR_ALLOW_DATA_LOSS)dbcc checktable('需要修复的数据表的名称',REPAIR_REBUILD)------把’ 需要修复的数据表的名称’更改为执行DBCC CHECKDB时报错的数据表的名称exec sp_dboption @dbname,'single user','false'3. 其他的一些常用的修复命令DBCC DBREINDEX 重建指定数据库中表的一个或多个索引用法:DBCC DBREINDEX (表名,’’) 修复此表所有的索引。
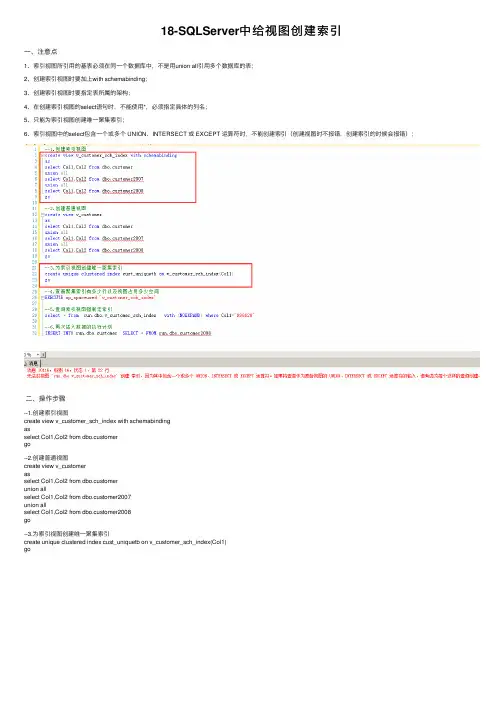
18-SQLServer中给视图创建索引⼀、注意点1、索引视图所引⽤的基表必须在同⼀个数据库中,不是⽤union all引⽤多个数据库的表;2、创建索引视图时要加上with schemabinding;3、创建索引视图时要指定表所属的架构;4、在创建索引视图的select语句时,不能使⽤*,必须指定具体的列名;5、只能为索引视图创建唯⼀聚集索引;6、索引视图中的select包含⼀个或多个 UNION、INTERSECT 或 EXCEPT 运算符时,不能创建索引(创建视图时不报错,创建索引的时候会报错);⼆、操作步骤--1.创建索引视图create view v_customer_sch_index with schemabindingasselect Col1,Col2 from dbo.customergo--2.创建普通视图create view v_customerasselect Col1,Col2 from dbo.customerunion allselect Col1,Col2 from dbo.customer2007union allselect Col1,Col2 from dbo.customer2008go--3.为索引视图创建唯⼀聚集索引create unique clustered index cust_uniquetb on v_customer_sch_index(Col1)go--4.查看聚集索引有多少⾏以及视图占⽤多少空间EXECUTE sp_spaceused 'v_customer_sch_index'--5.查询索引视图强制⾛索引(with (NOEXPAND) )select * from run.dbo.v_customer_sch_index with (NOEXPAND) where Col1='998628'--6.再次插⼊数据的执⾏计划INSERT INTO run.dbo.customer SELECT * FROM run.dbo.customer2008***************************************************如下是个⼈开发系统,欢迎⼤家体验,纯属个⼈爱好,想⼀块玩的,私信。

标题:深入了解SQL Server索引的用法摘要:本文将深入探讨SQL Server索引的用法,包括索引的概念、创建、优化和使用技巧,帮助读者更好地利用索引提高数据库的性能。
一、索引的概念1. 什么是索引在SQL Server中,索引是一种特殊的数据结构,用于快速定位和访问数据库表中的数据。
通过索引,可以加快数据检索的速度,提高查询性能。
2. 索引的作用索引可以帮助数据库引擎快速定位到符合查询条件的数据,减少数据库的扫描和比对操作,从而提高数据检索的效率。
二、创建索引1. 创建索引的语法在SQL Server中,可以通过CREATE INDEX语句来创建索引,语法如下:```CREATE INDEX index_nameON table_name (column1, column2, ...);```2. 索引的类型SQL Server支持多种类型的索引,包括主键索引、唯一索引、聚簇索引和非聚簇索引等。
不同类型的索引适用于不同的场景,需要根据实际情况选择合适的索引类型进行创建。
三、优化索引1. 索引的设计原则在设计索引时,需要考虑到索引的覆盖性、选择性和唯一性等因素,以及索引对于 INSERT、UPDATE 和 DELETE 操作的影响。
合理的索引设计可以有效提高数据库的性能。
2. 索引的优化策略为了提高索引的性能,可以采取一些优化策略,如合并重叠索引、删除不必要的索引、定期重建索引和使用索引查找替代检索等方法。
四、使用技巧1. 如何使用索引在编写SQL查询语句时,可以通过使用EXPL本人N PLAN或者执行计划等工具来帮助分析查询语句的执行计划,以及确定是否使用了合适的索引。
2. 注意事项在使用索引时,需要注意索引的命中率、页面填充因子、索引维护等问题,以及定期对索引进行监控和优化。
五、总结通过本文的介绍,读者应该对SQL Server索引的概念、创建、优化和使用技巧有了一定的了解。
在实际应用中,需要根据具体的业务需求和数据库环境,选择合适的索引策略,以提高数据库的性能和稳定性。

标题:SQL Server中空字段索引的使用及其优化方法目录1. SQL Server中空字段索引的作用2. SQL Server中空字段索引的使用方法3. SQL Server中空字段索引的优化方法一、SQL Server中空字段索引的作用在SQL Server数据库中,索引是一种用于加快数据查询速度的重要技术。
空字段索引是指在数据库表中对某个字段建立的索引,该字段允许为空值。
空字段索引的作用在于提高查询速度、优化数据检索效率,同时对于包含大量空值的字段,可以节约存储空间。
二、SQL Server中空字段索引的使用方法在SQL Server中,可以通过以下步骤对空字段建立索引:1. 分析数据表结构,确定哪些字段允许为空值且需要建立索引。
2. 使用CREATE INDEX语句来创建空字段索引,例如:```sqlCREATE INDEX idx_name ON table_name (column_name);```3. 使用SQL Server Management Studio(SSMS)或其他数据库管理工具来验证空字段索引的创建情况,并进行必要的优化和调整。
三、SQL Server中空字段索引的优化方法在使用空字段索引的过程中,可以通过以下方法来优化其性能:1. 确保索引列的数据类型和长度合理。
索引列的数据类型应尽量选择较小的类型,避免浪费存储空间。
2. 定期对空字段索引进行重新组织或重建。
由于数据的增删改会导致索引碎片化,因此需要定期对索引进行维护,以提高查询性能。
3. 根据业务需求和实际查询情况,合理选择索引类型。
在SQL Server 中,可以使用聚集索引、非聚集索引、覆盖索引等不同类型的索引,根据查询需求来选择最合适的索引类型。
4. 考虑在查询条件中对空字段进行合理的处理。
对于可能涉及到空字段的查询条件,需要针对性地优化查询语句,避免性能损耗。
总结在SQL Server中,空字段索引可以有效提高数据查询的速度和效率,但在使用过程中需要注意合理选择索引列、定期维护索引以及优化查询语句,以达到最佳的性能效果。

1、6、7、SQL Server 2000 数据库优化方案参考查询速度慢的原因很多,常见如下几种:没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)2、I/O 吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足5、网络速度慢查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)8、sp_lock,sp_who, 活动的用户查看,原因是读写竞争资源。
9、返回了不必要的行和列10、查询语句不好,没有优化可以通过如下方法来优化查询1、把数据、日志、索引放到不同的I/O 设备上,增加读取速度,以前可以将Tempdb应放在RAIDO上,SQL2000不在支持。
数据量(尺寸)越大,提高I/O 越重要.2、纵向、横向分割表,减少表的尺寸(sp_spaceuse)3、升级硬件4、根据查询条件,建立索引,优化索引、优化访问方式,限制结果集的数据量。
注意填充因子要适当(最好是使用默认值0)。
索引应该尽量小,使用字节数小的列建索引好(参照索引的创建),不要对有限的几个值的字段建单一索引如性别字段5 、提高网速;6、扩大服务器的内存,Windows 2000 和SQL server 2000 能支持4-8G 的内存。
配置虚拟内存:虚拟内存大小应基于计算机上并发运行的服务进行配置。
运行Microsoft SQL Server? 2000 时,可考虑将虚拟内存大小设置为计算机中安装的物理内存的1.5 倍。
如果另外安装了全文检索功能,并打算运行Microsoft 搜索服务以便执行全文索引和查询,可考虑:将虚拟内存大小配置为至少是计算机中安装的物理内存的3 倍。
将SQL Server max server memory 服务器配置选项配置为物理内存的1.5 倍(虚拟内存大小设置的一半)。
7、增加服务器CPU 个数;但是必须明白并行处理串行处理更需要资源例如内存。

尝试在数据库5 中提取逻辑页() 失败。
该逻辑页属于分配单元xxx而非xxx 博客分类:
•数据库errors
此信息表明数据库或表已经部分损坏可以通过以下步骤尝试修复:
1. DBCC CHECKDB
重启服务器后,在没有进行任何操作的情况下,在SQL查询分析器中执行以下SQL进行数据库的修复,修复数据库存在的一致性错误与分配错误。
Sql代码
Sql代码
然后执行DBCC CHECKDB('需要修复的数据库实体的名称') 检查数据库是否仍旧存在错误。
注意:修复后可能会造成部分数据的丢失。
2. DBCC CHECKTABLE
如果DBCC CHECKDB 检查仍旧存在错误,可以使用DBCC CHECKTABLE来修复。
Sql代码
3. 其他的一些常用的修复命令
DBCC DBREINDEX 重建指定数据库中表的一个或多个索引用法:
Sql代码
Sql代码
4.DBCC CHECKALLOC
检查指定数据库的磁盘空间分配结构的一致性。

SQL Server Bit 索引简介在 SQL Server 中,Bit 索引是一种用于优化查询性能的索引类型。
Bit 索引适用于那些包含布尔值的列,例如布尔类型、逻辑类型等。
通过创建 Bit 索引,可以加快对包含 Bit 列的表进行查询的速度,并减少查询的资源消耗。
在本文中,将介绍 Bit 索引的使用方法、优势和适用场景,并提供一些最佳实践和注意事项,帮助您更好地理解和使用 SQL Server 中的 Bit 索引。
Bit 索引的创建在 SQL Server 中,可以使用以下语法创建 Bit 索引:CREATE INDEX index_name ON table_name (column_name);其中,index_name是索引的名称,table_name是要创建索引的表名,column_name 是要创建索引的列名。
例如,要在名为employees的表的is_active列上创建一个 Bit 索引,可以使用以下语句:CREATE INDEX idx_is_active ON employees (is_active);Bit 索引的优势Bit 索引在以下方面具有一些优势:1.提高查询性能:通过使用 Bit 索引,可以加快对包含 Bit 列的表进行查询的速度。
当查询条件中包含 Bit 列时,数据库引擎可以直接使用 Bit 索引来提供更快的查询结果。
2.减少资源消耗:使用 Bit 索引可以减少查询的资源消耗。
由于 Bit 列只包含两个可能的值(0 或 1),Bit 索引的大小相对较小,可以减少磁盘空间的使用,并减少内存中索引的加载时间。
3.节省存储空间:Bit 索引占用的存储空间较小。
对于大型表和包含大量Bit 列的表,使用 Bit 索引可以显著减少存储空间的使用。
4.支持快速更新:Bit 索引支持快速的数据插入、更新和删除操作。
当对包含 Bit 索引的表进行数据更改时,数据库引擎可以更快地更新索引,从而提高整体性能。

sqlserver 数据库加索引语句-概述说明以及解释1.引言1.1 概述数据库索引是一种重要的数据库对象,用于提高数据库查询性能并加速数据检索过程。
在SQL Server数据库中,索引可以被理解为一种排好序的数据结构,它能够快速定位和访问存储在数据库表中的数据行。
通过在数据库表中创建索引,可以大大降低查询的时间复杂度,提高数据库的响应速度。
本文将重点介绍SQL Server数据库中的索引是什么,为什么要使用索引以及如何在数据库中添加索引,旨在帮助读者更好地理解数据库索引的作用和使用方法。
1.2 文章结构"文章结构"部分将介绍整篇文章的组织和内容安排。
通过本部分,读者将了解到文章的逻辑结构和各个章节的主要内容。
在本文中,我们将首先介绍数据库索引的概念和作用,然后重点讨论在SQL Server数据库中为什么需要使用索引。
接着,我们将详细讲解如何在SQL Server数据库中添加索引,包括创建、管理和优化索引的具体步骤。
通过这样的结构安排,读者可以清晰地了解到数据库索引在SQL Server中的重要性和应用方法,从而更好地运用索引来提升数据库的性能和效率。
1.3 目的本文的目的是帮助读者了解在SQL Server 数据库中如何使用索引来提高查询性能。
通过深入探讨数据库索引的概念、作用和添加方法,读者可以学习到如何利用索引来优化数据库查询操作,提高数据的检索速度和查询效率。
同时,读者也能够了解到索引在数据库中的重要性,以及如何根据实际需求和场景来选择合适的索引类型并进行优化,从而更好地实现数据管理和处理的目的。
通过本文的学习,读者将能够深入了解索引在数据库中的应用及其优势,为数据库的设计和性能优化提供有力的支持。
2.正文2.1 什么是数据库索引数据库索引是一种数据结构,用于快速查找数据库表中的特定数据。
索引类似于书籍的目录,它可以帮助数据库引擎快速找到表中特定列的数据。
通过创建索引,可以大大减少数据库查询的时间,提高数据库的性能。
sqlserver 维护计划例子SQL Server维护计划是一个用于自动执行一系列维护任务的工具,这些任务包括数据库备份、索引重建、数据库完整性检查等。
以下是一个简单的SQL Server维护计划的例子:1. 备份数据库:任务名称:数据库备份描述:每天凌晨备份数据库操作:使用`BACKUP DATABASE`命令备份数据库频率:每天时间:凌晨1点2. 重建索引:任务名称:索引重建描述:每周重建数据库中的索引操作:使用`ALTER INDEX`命令重建索引频率:每周时间:每周三下午3点3. 检查数据库完整性:任务名称:数据库完整性检查描述:每月检查数据库的完整性操作:运行完整性检查的T-SQL脚本频率:每月时间:每月的第一天上午10点以上是一个简单的维护计划例子,你可以根据自己的需求添加或删除任务。
创建和维护计划的步骤如下:1. 打开SQL Server Management Studio (SSMS)。
2. 在对象资源管理器中,连接到你的SQL Server实例。
3. 在对象资源管理器中,右键点击“维护计划”,选择“新建维护计划”。
4. 在“新建维护计划”窗口中,输入计划名称和描述。
5. 在“步骤”页,点击“新建”按钮,添加一个新的维护任务。
6. 在“新建维护步骤”窗口中,输入任务名称和描述,选择操作类型,并输入或浏览操作内容。
7. 根据需要配置频率和时间。
8. 可以继续添加其他维护任务。
完成后,点击“确定”保存维护计划。
9. 如果你想将此计划与作业关联以自动执行,可以在“新建维护计划”窗口中,选择“新建作业”或“使用现有作业”。
10. 最后,点击“确定”保存并关闭窗口。
请注意,这只是一个简单的例子,实际的维护计划可能会更复杂,并包括更多的任务和设置。
在创建和维护计划时,请确保你有足够的权限,并仔细测试计划以确保其按预期工作。
sqlserver创建索引的5种方法一、前言在SQL Server中,索引是提高查询性能的重要手段。
但是,不同的索引创建方式对性能的影响是不同的。
因此,在创建索引时,我们需要根据具体情况选择不同的方式进行操作。
本文将介绍SQL Server中创建索引的5种方法,并详细说明它们的优缺点和适用场景。
二、基础知识在介绍具体方法之前,我们需要了解一些基础知识:1. 索引类型:SQL Server支持聚集索引和非聚集索引两种类型。
2. 索引列:创建索引时需要指定一个或多个列作为索引列。
通常选择经常用于查询条件、排序或分组操作的列作为索引列。
3. 唯一性:唯一性约束可以保证在一个表中每个值只出现一次。
当我们需要根据某个列进行唯一性检查时,可以使用唯一性约束来创建唯一非聚集索引。
4. 覆盖索引:如果查询语句所需的数据都包含在某个非聚集索引中,那么就可以使用该索引来避免扫描整个表而直接返回结果。
这种情况下,该非聚集索引就被称为覆盖索引。
三、方法1:CREATE INDEX语句CREATE INDEX语句是创建索引最基本的方法。
它的语法如下:CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX index_nameON table_name (column1 [ASC | DESC], column2 [ASC | DESC], ...);其中,index_name是索引名称,table_name是表名,column1、column2等是要作为索引列的列名。
优点:1. 可以根据需要创建聚集索引或非聚集索引。
2. 可以在多个列上创建复合索引。
3. 可以指定索引的唯一性。
缺点:1. 需要手动编写SQL语句,不够方便。
2. 如果需要在多个表中创建相同的索引,需要多次编写SQL语句。
适用场景:CREATE INDEX语句适用于需要自定义索引名称、类型和唯一性约束的情况。
如果只需要简单地为一个表中的某个列创建普通非聚集索引,则可以使用方法2或方法3。
sql server 2000文件中,ldf损坏了,但mdf还在,总结一下恢复方法:1)先及时把原来的数据库文件(如test.mdf)备份到其他地方2)停掉服务器3)删除这个test.mdf4) 重新建立一个test同名数据库5)删除这个新建立的test数据库的test.ldf文件,并用开始备份好的test.mdf文件覆盖这个新建立的test.mdf文件6)启动数据库服务器。
此时会看到数据库test的状态为“置疑”。
这时候不能对此数据库进行任何操作。
.设置数据库允许直接操作系统表。
此操作可以在SQL Server Enterprise Manager里面选择数据库服务器,按右键,选择“属性”,在“服务器设置”页面中将“允许对系统目录直接修改”7)设置test为紧急修复模式update sysdatabases set status=-32768 where dbid=DB_ID('test')此时可以在SQL Server Enterprise Manager里面看到该数据库处于“只读\置疑\脱机\紧急模式”可以看到数据库里面的表,但是仅仅有系统表8 下面执行真正的恢复操作,重建数据库日志文件dbcc rebuild_log('test','C:\Program Files\Microsoft SQL Server\MSSQL\Data\test_log.ldf')执行过程中,如果遇到下列提示信息:服务器: 消息5030,级别16,状态1,行 1未能排它地锁定数据库以执行该操作。
DBCC 执行完毕。
如果DBCC 输出了错误信息,请与系统管理员联系。
说明您的其他程序正在使用该数据库,如果刚才您在F步骤中使用SQL Server Enterprise Manager打开了test库的系统表,那么退出SQL Server Enterprise Manager就可以了。
SQLServer2000数据库中如何重建索引在数据库中创建索引时,查询所使⽤的索引信息存储在索引页中。
连续索引页由从⼀个页到下⼀个页的指针链接在⼀起。
当对数据的更改影响到索引时,索引中的信息可能会在数据库中分散开来。
重建索引可以重新组织索引数据(对于聚集索引还包括表数据)的存储,清除碎⽚。
这可通过减少获得请求数据所需的页读取数来提⾼磁盘性能。
在 Microsoft® SQL Server™ 2000 中,如果要⽤⼀个步骤重新创建索引,⽽不想删除旧索引并重新创建同⼀索引,则使⽤ CREATE INDEX 语句的 DROP_EXISTING ⼦句可以提⾼效率。
这⼀优点既适⽤于聚集索引也适⽤于⾮聚集索引。
以删除旧索引然后重新创建同⼀索引的⽅式重建聚集索引,是⼀种昂贵的⽅法,因为所有⼆级索引都使⽤聚集键指向数据⾏。
如果只是删除聚集索引然后重新创建,则会使所有⾮聚集索引都被删除和重新创建两次。
⼀旦删除聚集索引并再次重建该索引,就会发⽣这种情形。
通过在⼀个步骤中重新创建索引,可以避免这⼀昂贵的做法。
在⼀个步骤中重新创建索引时,会告诉 SQL Server 要重新组织现有索引,避免了删除和重新创建⾮聚集索引这些不必要的⼯作。
该⽅法的另⼀个重要优点是可以使⽤现有索引中的数据排序次序,从⽽避免了对数据重新排序。
这对于聚集索引和⾮聚集索引都⼗分有⽤,可以显著减少重建索引的成本。
另外,通过使⽤ DBCC DBREINDEX 语句,SQL Server 还允许对⼀个表重建(在⼀个步骤中)⼀个或多个索引,⽽不必单独重建每个索引。
DBCC DBREINDEX 也可⽤于重建执⾏ PRIMARY KEY 或 UNIQUE 约束的索引,⽽不必删除并创建这些约束(因为对于为执⾏ PRIMARY KEY 或 UNIQUE 约束⽽创建的索引,必须先删除该约束,然后才能删除该索引)。
例如,可能需要在 PRIMARY KEY 约束上重建⼀个索引,以便为该索引重建给定的填充因⼦。
大多数SQL Server表需要索引来提高数据的访问速度,如果没有索引,SQL Server 要全表进行扫描读取表中的每一个记录才能找到所要的数据。
索引可以分为簇索引和非簇索引:簇索引通过重排表中的数据来提高数据的访问速度;而非簇索引则通过维护表中的数据指针来提高数据的访问速度。
1. 索引的体系结构SQL Server 2005在硬盘中用8KB页面在数据库文件内存放数据。
缺省情况下这些页面及其包含的数据是无组织的。
为了使混乱变为有序,就要生成索引。
生成索引后,就有了索引页和数据页之分:数据页用来保存用户写入的数据信息;索引页存放用于检索列的数据值清单(关键字)和索引表中该值所在纪录的地址指针。
索引分为簇索引和非簇索引,簇索引实质上是将表中的数据排序,就好像是字典的索引目录。
非簇索引不对数据排序,它只保存了数据的地址。
向一个带簇索引的表中插入数据,当数据页达到100%时,由于页面没有空间插入新的的纪录,这时就会发生分页,SQL Server 将大约一半的数据从满页中移到空页中,从而生成两个1/2满页。
这样就有大量的空的数据空间。
簇索引是双向链表,在每一页的头部保存了前一页、后一页以及分页后数据移出的地址。
由于新页可能在数据库文件中的任何地方,因此页面的链接不一定指向磁盘的下一个物理页。
链接可能指向了另一个区域,这就形成了分块,从而减慢了系统的速度。
对于带簇索引和非簇索引的表来说,非簇索引的关键字是指向簇索引的,而不是指向数据页的本身。
为了克服数据分块带来的负面影响,需要重构表的索引,这是非常费时的,因此只能在需要时进行。
可以通过DBCC SHOWCONTIG来确定是否需要重构表的索引。
2. DBCC SHOWCONTIG用法下面举例来说明DBCC SHOWCONTIG和DBCC REDBINDEX的使用方法。
以应用程序中的Employee数据表作为例子,在 SQL Server的Query analyzer输入命令:输出结果:通过分析这些结果可以知道该表的索引是否需要重构。