Oracle10g正则表达式及常用函数汇总
- 格式:doc
- 大小:44.50 KB
- 文档页数:5

oracle regexp语法Oracle正则表达式语法一、引言正则表达式是一种强大的文本匹配工具,用于在文本中查找、匹配和替换符合特定模式的字符串。
Oracle数据库提供了一套强大的正则表达式函数和操作符,可以方便地在数据库中进行模式匹配操作。
本文将介绍Oracle正则表达式的语法及常用函数,帮助读者更好地理解和应用正则表达式。
二、正则表达式基础1. 字符匹配正则表达式中的基本元字符可以用于匹配特定的字符,例如:- \d:匹配任意一个数字字符;- \w:匹配任意一个字母、数字或下划线字符;- \s:匹配任意一个空白字符。
2. 重复匹配正则表达式中的重复匹配符号用于匹配重复出现的字符,例如:- *:匹配前一个字符的零个或多个重复;- +:匹配前一个字符的一个或多个重复;- ?:匹配前一个字符的零个或一个重复。
3. 边界匹配正则表达式中的边界匹配符号用于匹配字符串的边界,例如:- ^:匹配字符串的开始位置;- $:匹配字符串的结束位置;- \b:匹配一个单词边界。
4. 分组匹配正则表达式中的分组机制用于将多个字符组合在一起进行匹配,例如:- (pattern):将pattern作为一个分组进行匹配;- (pattern1|pattern2):匹配pattern1或pattern2。
三、Oracle正则表达式函数1. REGEXP_LIKEREGEXP_LIKE函数用于判断一个字符串是否匹配某个正则表达式,语法如下:```sqlREGEXP_LIKE(source_string, pattern)```其中,source_string为待匹配的字符串,pattern为正则表达式。
2. REGEXP_REPLACEREGEXP_REPLACE函数用于将一个字符串中符合某个正则表达式的部分替换为指定的字符串,语法如下:```sqlREGEXP_REPLACE(source_string, pattern, replace_string)```其中,source_string为待替换的字符串,pattern为正则表达式,replace_string为要替换的字符串。

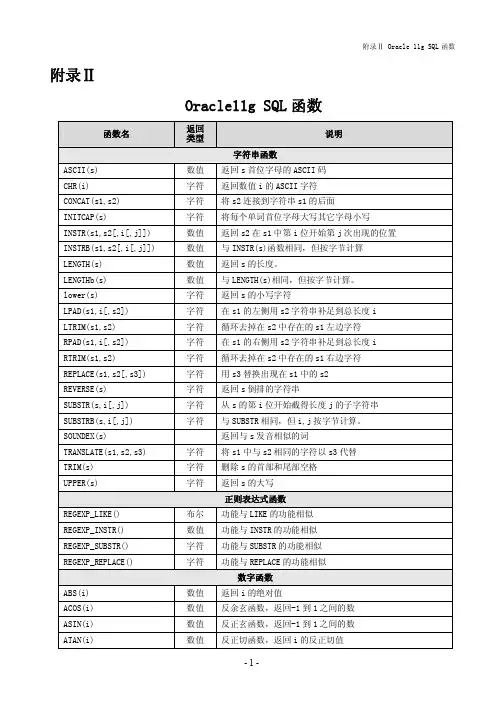
附录ⅡOracle11g SQL函数函数名 返回类型说明字符串函数ASCII(s) 数值 返回s首位字母的ASCII码CHR(i) 字符 返回数值i的ASCII字符CONCAT(s1,s2) 字符 将s2连接到字符串s1的后面INITCAP(s) 字符 将每个单词首位字母大写其它字母小写 INSTR(s1,s2[,i[,j]]) 数值 返回s2在s1中第i位开始第j次出现的位置 INSTRB(s1,s2[,i[,j]]) 数值 与INSTR(s)函数相同,但按字节计算 LENGTH(s) 数值 返回s的长度。
LENGTHb(s) 数值 与LENGTH(s)相同,但按字节计算。
lower(s) 字符 返回s的小写字符LPAD(s1,i[,s2]) 字符 在s1的左侧用s2字符串补足到总长度i LTRIM(s1,s2) 字符 循环去掉在s2中存在的s1左边字符RPAD(s1,i[,s2]) 字符 在s1的右侧用s2字符串补足到总长度i RTRIM(s1,s2) 字符 循环去掉在s2中存在的s1右边字符 REPLACE(s1,s2[,s3]) 字符 用s3替换出现在s1中的s2REVERSE(s) 字符 返回s倒排的字符串SUBSTR(s,i[,j]) 字符 从s的第i位开始截得长度j的子字符串 SUBSTRB(s,i[,j]) 字符 与SUBSTR相同,但i,j按字节计算。
SOUNDEX(s) 返回与s发音相似的词TRANSLATE(s1,s2,s3) 字符 将s1中与s2相同的字符以s3代替TRIM(s) 字符 删除s的首部和尾部空格UPPER(s) 字符 返回s的大写正则表达式函数REGEXP_LIKE() 布尔 功能与LIKE的功能相似REGEXP_INSTR() 数值 功能与INSTR的功能相似REGEXP_SUBSTR() 字符 功能与SUBSTR的功能相似REGEXP_REPLACE() 字符 功能与REPLACE的功能相似数字函数ABS(i) 数值 返回i的绝对值ACOS(i) 数值 反余玄函数,返回-1到1之间的数ASIN(i) 数值 反正玄函数,返回-1到1之间的数ATAN(i) 数值 反正切函数,返回i的反正切值CEIL(i) 数值 返回大于或等于n的最小整数COS(i) 数值 返回n的余玄值COSH(i) 数值 返回n的双曲余玄值EXP(i) 数值 返回e的i次幂,e=2.71828183FLOOR(i) 数值 返回小于等于i的最大整数LN(i) 数值 返回i的自然对数,i>0LOG(i,j) 数值 返回以i为底j的对数MOD(i) 数值 返回i除以j的余数POWER(i,j) 数值 返回i的j次方ROUND(i,j) 数值 返回i四舍五入值,j是小数点位数SIGN(i) 数值 i>0返回1,i=0返回0,i<0返回-1SIN(i) 数值 返回i的正玄值SINH(i) 数值 返回i的双曲正玄值SQRT(i) 数值 返回i的平方根TAN(i) 数值 返回i的正切值TANH(i) 数值 返回i的双曲正切值TRUNC(I,j) 数值 返回i的结尾值,j可正、零、负数转换函数CONVERT(s,ds,ss) 字符 将s,由ss字符集转换为ds字符集HEXTORAW(s) 字符 将16进制的s转换为RAW数据类型。


Oracle 10g - 常用SQL函数Oracle常用函数数字函数ABS()语法说明示例 ABS(x) 返回x的绝对值。
ACOS()语法说明示例 ACOS(x) 返回x的反余弦值。
x应该是从-1到1之间的数,并且输出值从0到Pi,以弧度为单位。
ASIN()语法说明示例 ASIN(x) 返回x的反正弦值。
x应该是从-1到1之间的数,并且输出值从-Pi/2到Pi/2,以弧度为单位。
ATAN(x)语法说明示例 ATAN(x) 返回x的反正切值。
输出值是从-Pi/2到Pi/2,以弧度为单位。
ATAN2(x, y)语法说明 ATAN2(x, y) 返回x和y的反正切值。
输出值是从-Pi到Pi,取决于x和y的符号,以弧度为单位。
ATAN2(x, y)和ATAN(x/y)是完全相同的。
示例 CEIL()语法 CEIL(x) 说明示例返回大于或等于x的最小整数值。
COS()语法说明示例 COS(x) 返回x的余弦值。
x是以弧度表达的角度。
COSH()语法说明示例 COSH(x) 返回x的双曲余弦值。
x是以弧度表达的角度。
EXP语法说明示例 EXP(x) 返回e的x次幂。
e = 2.71828183… FLOOR()语法说明示例 FLOOR(x) 返回小于或等于x的最大整数值。
LN()语法说明示例 LN(x) 返回x的自然对数值。
x必须大于0。
LOG()语法说明示例 LOG(x, y) 返回以x为底的y的对数。
x必须是不为0和1的正数,y可以是任意正数。
MOD()语法说明示例 MOD(x, y) 返回x除以y的余数。
如果y是0,则返回x。
MEDIAN语法说明 MEDIAN(column) MEDIAN函数用于返回一个数据集合的中间值。
中间值的定义是,集合中大于它的元素数目与小于它的元素数目相同)MEDIAN 是通过对集合进行排序,然后选择中间元素的。
示例比如部门20中所有员工的工资集合为:SAL ---------- 800 1100 2975 3000 3000 6000 8000 它们的中间值为: select median(sal) from emp where deptno =20; MEDIAN(SAL) -------------------------------------- 3000POWER()语法说明 POWER(x, y) 返回x的y次幂。

Oracle正则表达式基于Perl语言的正则表达式语法,其基本语法和使用方法如下:1. 字符匹配:* .:匹配除了换行外的任意一个字符。
* \d:匹配任何数字,相当于[0-9]。
* \D:匹配任何非数字字符,相当于[^0-9]。
* \w:匹配任何字母数字字符或下划线,相当于[a-zA-Z0-9_]。
* \W:表示匹配任何非字母数字字符或下划线,相当于[^a-zA-Z0-9_]。
2. 限定符:* *:匹配前一个字符出现0次或多次。
* +:匹配前一个字符出现1次或多次。
* ?:匹配前一个字符出现0次或1次。
* {n}:匹配前一个字符出现n次。
* {n,}:匹配前一个字符出现n次或更多。
* {n,m}:匹配前一个字符出现n~m次。
3. 边界匹配:* ^:匹配开始位置。
* $:匹配结束位置。
* \b:匹配单词边界,即单词的开头或结尾位置。
* \B:匹配非单词边界,即不是单词的开头或结尾位置。
4. 分组和引用:* ( ):分组,标记一个子表达式的开始和结束位置。
* \num:引用第num个子表达式,num从1开始。
5. 字符集合:[]表示一组字符中的任意一个。
6. 转义符:\表示转义一个字符。
7. 其他高级语法支持:贪婪匹配、非贪婪匹配、零宽断言(zero-width assertion)、后向引用(backreference)、捕获组等。
另外,Oracle 10g支持正则表达式的四个新函数分别是REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR和REGEXP_REPLACE,它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
请注意,具体使用方法可能因不同的数据库版本或应用场景而有所不同。
建议查阅Oracle官方文档或相关教程以获取更详细和准确的信息。

oracle正则表达式用法-回复Oracle正则表达式用于在Oracle数据库中对字符串进行模式匹配和替换。
它提供了一种强大的方式来处理字符串数据,特别是在数据查询和数据转换方面。
在本文中,我们将一步一步地回答关于Oracle正则表达式的常见问题,以帮助读者更好地理解和使用它。
第一部分:正则表达式的基本概念和语法在使用Oracle正则表达式之前,我们需要了解一些基本概念和语法。
1.1 正则表达式是什么?正则表达式是一种用于匹配和搜索文本模式的工具。
它通过使用元字符和特殊字符来定义模式。
1.2 元字符是什么?元字符是正则表达式中具有特殊含义的字符。
常见的元字符包括^、、.、*、+、?、\、[]、{} 等。
1.3 什么是字符类别?字符类别是用于匹配字符的一组字符。
它们可以简化正则表达式的编写,并提供更具表达力的匹配方式。
在Oracle正则表达式中,可以使用一些预定义的字符类别,如\d(匹配数字)、\w(匹配字母数字字符)、\s(匹配空白字符)等。
1.4 什么是限定符?限定符是指定模式的数量的特殊字符。
它可以控制匹配的次数,如*(零次或多次)、+(一次或多次)、?(零次或一次)、{n}(恰好n次)、{n,}(至少n次)和{n,m}(至少n次且不超过m次)。
1.5 总结一下正则表达式的基本语法正则表达式的基本语法包括元字符、字符类别和限定符。
它结合使用这些元素来定义匹配和搜索模式。
第二部分:如何在Oracle中使用正则表达式函数现在我们将探讨如何在Oracle数据库中使用正则表达式函数。
2.1 Oracle中的正则表达式函数Oracle提供了一些内置函数,用于处理正则表达式操作。
常见的函数包括REGEXP_LIKE、REGEXP_REPLACE、REGEXP_INSTR、REGEXP_SUBSTR。
这些函数可以用来执行模式匹配、替换和提取操作。
2.2 REGEXP_LIKE函数REGEXP_LIKE函数用于检查一个字符串是否与指定的模式匹配。

orcl中用正则表达式在Oracle中,你可以使用正则表达式来执行各种字符串操作,例如搜索、替换、提取等。
Oracle的正则表达式功能主要通过`REGEXP_SUBSTR`、`REGEXP_INSTR`、`REGEXP_REPLACE`等函数提供。
以下是一些在Oracle中使用正则表达式的示例:1. 使用`REGEXP_SUBSTR`提取字符串假设你想从某个字符串中提取所有的数字:```sqlSELECT REGEXP_SUBSTR('abc123def456', '[0-9]+') FROM dual;```这会返回`123`和`456`。
2. 使用`REGEXP_INSTR`查找字符串查找某个字符串在另一个字符串中的位置:```sqlSELECT REGEXP_INSTR('abc123def456', '[0-9]+') FROM dual;```这会返回数字`4`,表示第一个数字(123)开始于位置4。
3. 使用`REGEXP_REPLACE`替换字符串替换所有匹配正则表达式的子串:```sqlSELECT REGEXP_REPLACE('abc123def456', '[0-9]+', 'XX') FROM dual;```这会返回`abcXXdefXX`。
4. 使用复杂的正则表达式例如,如果你想从字符串中提取所有由字母组成的子串:```sqlSELECT REGEXP_SUBSTR('abc123def456', '[a-zA-Z]+') FROM dual;```这会返回`abc`和`def`。
5. 分组和捕获使用括号进行分组和捕获:```sqlSELECT REGEXP_SUBSTR('abc123def456', '([a-z]+)([0-9]+)', 1, 1, NULL, 1) FROM dual;```这将返回`abc`,因为它是第一个匹配的子串。


By flyORACLE终于在10G中提供了对正则表达式的支持,以前那些需要通过LIKE来进行的复杂的匹配就可以通过使用正则表达式更简单的实现。
ORACLE中的支持正则表达式的函数主要有下面四个:1,REGEXP_LIKE :与LIKE的功能相似2,REGEXP_INSTR :与INSTR的功能相似3,REGEXP_SUBSTR :与SUBSTR的功能相似4,REGEXP_REPLACE :与REPLACE的功能相似在新的函数中使用正则表达式来代替通配符‘%’和‘_’。
正则表达式由标准的元字符(metacharacters)所构成:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。
如果设置了RegExp 对象的Multiline 属性,则$ 也匹配'n' 或'r'。
'.' 匹配除换行符n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。
例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
num 匹配num,其中num 是一个正整数。
对所获取的匹配的引用。
字符簇:[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。

Oracle正则表达式的用法正则表达式具有强大、便捷、高效的文本处理功能。
能够添加、删除、分析、叠加、插入和修整各种类型的文本和数据。
Oracle从10g开始支持正则表达式一、Oracle预定义的 POSIX 字符类字符类说明[:alpha:]字母字符[:lower:]小写字母字符[:upper:]大写字母字符[:digit:]数字[:alnum:]字母数字字符[:spac e:]空白字符(禁止打印),如回车符、换行符、竖直制表符和换页符[:punct:]标点字符[:cntrl:]控制字符(禁止打印)[:print:]可打印字符[:alnum:]字母和数字混合的字符二、正则表达式运算符和函数1、REGEXP_SUBSTRREGEXP_SUBSTR为指定字符串的一部分与正则表达式建立匹配。
语法如下:REGEXP_SUBSTR(source_string,pattern,start_position,occurrence,match_parameter)说明其中source_string是必须的。
可以是带引号的字符串或者变量。
Pattern是用单引号引用的与正则表达式。
Start_position指定了在字符串中的准确位置,默认值为1。
Occurrence是一个选项,指定在源字符串匹配过程中相对其他字符串,哪个字符串应该匹配。
最后,match_parameter也是一个选项,指定在匹配时是否区分大水写。
实例(1)、返回从ename的第二个位置开始查找,并且是以“L”开头到结尾的字串SQL> select regexp_substr(ename,'L.*','2') substr from emp;(2)、SELECT REGEXP_SUBSTR(mc,'[a-z]+') FROM test;SELECT REGEXP_SUBSTR(mc,'[0-9]+') FROM test;SELECT REGEXP_SUBSTR('aababcde','^a.*b') FROM DUAL;(3)、SQL 代码复制DECLARE V_RESULT VARCHAR2(255); BEGIN--返回‘light’SELECT REGEXP_SUBSTR('But, soft! What light through yonder window breaks?','l[[:alpha:]]{4}') INTO V_RESULT FROM DUAL;DBMS_OUTPUT.PUT_LINE(V_RESULT); END;2、REGEXP_INSTRREGEXP_INSTR返回与正则表达式匹配的字符和字符串的位置。
Oracle正则表达式函数介绍2011-3-1Oracle中的支持正则表达式的函数主要有下面四个:1,REGEXP_LIKE :与LIKE的功能相似2,REGEXP_INSTR :与INSTR的功能相似3,REGEXP_SUBSTR :与SUBSTR的功能相似4,REGEXP_REPLACE :与REPLACE的功能相似它们在用法上与Oracle SQL 函数LIKE、INSTR、SUBSTR 和REPLACE 用法相同,但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
POSIX 正则表达式由标准的元字符(metacharacters)所构成:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。
如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。
'.' 匹配除换行符之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。
例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
\num 匹配 num,其中 num 是一个正整数。
对所获取的匹配的引用。
字符簇:[[:alpha:]] 任何字母。
Oracle正则表达式Oracle正则表达式正则表达式具有强⼤、便捷、⾼效的⽂本处理功能。
能够添加、删除、分析、叠加、插⼊和修整各种类型的⽂本和数据。
Oracle从10g开始⽀持正则表达式。
下⾯通过⼀些例⼦来说明使⽤正则表达式来处理⼀些⼯作中常见的问题。
1.REGEXP_SUBSTRREGEXP_SUBSTR 函数使⽤正则表达式来指定返回串的起点和终点,返回与source_string 字符集中的VARCHAR2 或CLOB 数据相同的字符串。
语法:--1.REGEXP_SUBSTR与SUBSTR函数相同,返回截取的⼦字符串REGEXP_SUBSTR(srcstr, pattern [, position [, occurrence [, match_option]]])注:srcstr 源字符串pattern 正则表达式样式position 开始匹配字符位置occurrence 匹配出现次数match_option 匹配选项(区分⼤⼩写)1.1 从字符串中截取⼦字符串SELECT regexp_substr('1PSN/231_3253/ABc', '[[:alnum:]]+') FROM dual;Output: 1PSN[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符。
SELECT regexp_substr('1PSN/231_3253/ABc', '[[:alnum:]]+', 1, 2) FROM dual;Output: 231与上⾯⼀个例⼦相⽐,多了两个参数1 表⽰从源字符串的第⼀个字符开始查找匹配2 表⽰第2次匹配到的字符串(默认值是“1”,如上例)select regexp_substr('@@/231_3253/ABc','@*[[:alnum:]]+') from dual;Output: 231@* 表⽰匹配0个或者多个@[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符注意:需要区别“+”和“*”的区别select regexp_substr('1@/231_3253/ABc','@+[[:alnum:]]*') from dual;Output: @@+ 表⽰匹配1个或者多个@[[:alnum:]]* 表⽰匹配0个或者多个字母或数字字符select regexp_substr('1@/231_3253/ABc','@+[[:alnum:]]+') from dual;Output: Null@+ 表⽰匹配1个或者多个@[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符select regexp_substr('@1PSN/231_3253/ABc125','[[:digit:]]+$') from dual;Output: 125[[:digit:]]+$ 表⽰匹配1个或者多个数字结尾的字符select regexp_substr('@1PSN/231_3253/ABc','[^[:digit:]]+$') from dual;Output: /ABc[^[:digit:]]+$ 表⽰匹配1个或者多个不是数字结尾的字符select regexp_substr('Tom_Kyte@','[^@]+') from dual;Output: Tom_Kyte[^@]+ 表⽰匹配1个或者多个不是“@”的字符select regexp_substr('1PSN/231_3253/ABc','[[:alnum:]]*',1,2)from dual;Output: Null[[:alnum:]]* 表⽰匹配0个或者多个字母或者数字字符注:因为是匹配0个或者多个,所以这⾥第2次匹配的是“/”(匹配了0次),⽽不是“231”,所以结果是“Null”1.2 匹配重复出现查找连续2个⼩写字母SELECT regexp_substr('Republicc Of Africaa', '([a-z])\1', 1, 1, 'i')FROM dual;Output: cc([a-z]) 表⽰⼩写字母a-z\1 表⽰匹配前⾯的字符的连续次数1 表⽰从源字符串的第⼀个字符开始匹配1 第⼀次出现符合匹配结果的字符i 表⽰区分⼤⼩写查找连续3个6,7,8,9中的数字SELECT CASEWHEN regexp_like('Patch 10888 applied', '([6-9])\1\1') THEN'Match Found'ELSE'No Match Found'1.3 其他⼀些匹配样式查找⽹页地址信息FROM dual其中:([[:alnum:]]+\.?) 表⽰匹配1次或者多次字母或数字字符,紧跟0次或1次逗号符{3,4} 表⽰匹配前⾯的字符最少3次,最多4次/? 表⽰匹配⼀个反斜杠字符0次或者1次提取csv字符串中的第三个值SELECT regexp_substr('1101,Yokohama,Japan,1.5.105', '[^,]+', 1, 3) AS outputFROM dual;Output: Japan其中:[^,]+ 表⽰匹配1个或者多个不是逗号的字符1 表⽰从源字符串的第⼀个字符开始查找匹配3 表⽰第3次匹配到的字符串注:这个通常⽤来实现字符串的列传⾏--字符串的列传⾏SELECT regexp_substr('1101,Yokohama,Japan,1.5.105', '[^,]+', 1, LEVEL) AS output FROM dualCONNECT BY LEVEL <= length('1101,Yokohama,Japan,1.5.105') -length(REPLACE('1101,Yokohama,Japan,1.5.105', ',')) + 1;Output: 1101YokohamaJapan1.5.105这⾥通过LEVEL来循环截取匹配到的字符串。
oracle sql 正则-回复问题:如何在Oracle SQL中使用正则表达式?引言:正则表达式是一种强大的文本匹配工具,可以在字符串中查找、匹配和提取满足特定模式的文本。
在Oracle SQL中,正则表达式可以通过正则表达式函数和操作符来实现。
本文将为您介绍如何在Oracle SQL中使用正则表达式,以及一些常见的正则表达式用例。
正文:一、正则表达式函数Oracle SQL提供了丰富的正则表达式函数,可以在查询中使用。
以下是一些常见的正则表达式函数及其用法:1. REGEXP_LIKE:判断字符串是否满足特定模式。
语法:REGEXP_LIKE(column, pattern, match_parameter)示例:SELECT * FROM employees WHEREREGEXP_LIKE(last_name, 'Pat[rt]on', 'i');查询姓氏为"Patton"或"Patton"的所有员工记录。
2. REGEXP_SUBSTR:从字符串中提取满足特定模式的子字符串。
语法:REGEXP_SUBSTR(column, pattern, position, occurrence,match_parameter)示例:SELECT REGEXP_SUBSTR(email,'(^[A-Za-z0-9]+)[A-Za-z0-9]+\.[A-Za-z]{2,4}') AS domainFROM employees;提取邮箱字段中的域名部分。
3. REGEXP_INSTR:返回满足特定模式的字符串在另一个字符串中的位置。
语法:REGEXP_INSTR(column, pattern, position, occurrence, return_option, match_parameter)示例:SELECT last_name, REGEXP_INSTR(phone_number,'[0-9]{3}', 1, 1, 0, 'c') AS area_codeFROM employees;查询员工电话号码中的区号部分。
1、正则表达式语法,正则表达式是在10g才添加进来的,其匹配字符、量词字符、匹配选项、相关函数如下:匹配字符内容:匹配字符位置和条件:匹配字符数量:匹配选项:函数:REGEXP_LIKE 是LIKE语句的正则表达式版本语法:REGEXP_LIKE(源字符串, 匹配表达式[,匹配选项])REGEXP_INSTR 返回源字符串中首次匹配正则表达式的起始位置语法:REGEXP_INSTR(srcstr, pattern [, position [, occurrence[,return_option [, match_option]]]])srcstr:源字符串pattern:正则表达式position:搜索开始位置occurrence:返回第几个匹配项return_option:返回选项,0表示开始位置,1表示返回匹配的结束位置match_option:匹配选项REGEXP_SUBSTR 返回源串中匹配正则表达式的子字符串语法:SUBSTR(srcstr, pattern [, position [, occurrence [, match_option]]]) srcstr:源字符串pattern:正则表达式position:搜索的开始位置occurrence:返回第几个匹配的字符串match_option:匹配选项REGEXP_REPLACE 用执行字符串替换源文本中与正则表达式匹配的字符串语法:REGEXP_REPLACE(srcstr, pattern [,replacestr [, position[, occurrence [, match_option]]]])srcstr:源字符串pattern:正则表达式replacestr:新的字符串position:搜索起始位置occurrence:第几个匹配项match_option:匹配选项例题说明:Evaluate the following expression using meta. character for regular expression:'[^Ale|ax.r$]'Which two matches would be returned by this expression? (Choose two.)A. AlexB. AlaxC. AlxerD. AlaxendarE. AlexenderAnswer: DE'[^Ale|ax.r$]'中^表示只匹配不在集合{'A','l','e','|','a','x','.','r','$'}中的字符, 此处的'|'、'.'、'$'只是表示普通的字符,而非匹配符本文由淄博SEO(),淄博网站优化()整理发布,转载请注明出处。
Oracle中的正则表达式Oracle使⽤正则表达式离不开这4个函数:1 、regexp_like2 、regexp_substr3、 regexp_instr4 、regexp_replace2.1、REGEXP_SUBSTRREGEXP_SUBSTR函数使⽤正则表达式来指定返回串的起点和终点。
语法:regexp_substr(source_string,pattern[,position[,occurrence[,match_parameter]]])source_string:源串,可以是常量,也可以是某个值类型为串的列。
position:从源串开始搜索的位置。
默认为1。
occurrence:指定源串中的第⼏次出现。
默认值1.match_parameter:⽂本量,进⼀步订制搜索,取值如下:'i' ⽤于不区分⼤⼩写的匹配。
'c' ⽤于区分⼤⼩写的匹配。
'n' 允许将句点“.”作为通配符来匹配换⾏符。
如果省略改参数,句点将不匹配换⾏符。
'm' 将源串视为多⾏。
即将“^”和“$”分别看做源串中任意位置任意⾏的开始和结束,⽽不是看作整个源串的开始或结束。
如果省略该参数,源串将被看作⼀⾏来处理。
如果取值不属于上述中的某个,将会报错。
如果指定了多个互相⽭盾的值,将使⽤最后⼀个值。
如'ic'会被当做'c'处理。
省略该参数时:默认区分⼤⼩写、句点不匹配换⾏符、源串被看作⼀⾏。
例⼦:1. select regexp_substr('MY INFO: Anxpp,23,and boy','[[:digit:]]',1,2) from users;结果:此处会返回3。
注意这⾥同时⽤到了“[]”和“[:digit:]”。
2.2、REGEXP_INSTRREGEXP_INSTR函数使⽤正则表达式返回搜索模式的起点和终点(整数)。
oracle的正则表达式oracle的正则表达式(regular expression)简单介绍目前,正则表达式已经在很多软件中得到广泛的应用,包括*nix(Linux, Unix等),HP等操作系统,PHP,C#,Java等开发环境。
Oracle 10g正则表达式提高了SQL灵活性。
有效的解决了数据有效性,重复词的辨认, 无关的空白检测,或者分解多个正则组成的字符串等问题。
Oracle 10g支持正则表达式的四个新函数分别是:REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR、和REGEXP_REPLACE。
它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
特殊字符:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。
如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。
'.' 匹配除换行符 \n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'*' 匹配前面的子表达式零次或多次。
select regexp_replace('dsfsdfsf','a*','A')from dual AdAsAfAsAdAfAsAfA因为其可以匹配a没有出现的地方,所以在每个字符前面和后面都会插A,相当于将两个字符中间的空位也当做一次匹配select regexp_replace('adsfsdfsf','a*','A')from dual AAdAsAfAsAdAfAsAfA因为其可以匹配a没有出现的地方,所以在每个字符前面和后面都会插A,相当于将两个字符中间的空位也当做一次匹配,对于有a出现的地方再换成A正则表达式是最大限度匹配,会匹配所有能够匹配的字符串中长度最长的串Select REGEXP_REPLACE('aa bb cc','.*', 'A') FROM dual;把*后面的空格去掉显示结果为什么是两个A不是一个A因为其首先将匹配没有任何字符的情况加一个A,再对能匹配的最大字符串即aa bb cc换成ASelect REGEXP_REPLACE('aa bb cc','.* ', 'A') FROM dual;结果为Acc,注意表达式在.*后面有个空格'+' 匹配前面的子表达式一次或多次。
'( )' 标记一个子表达式的开始和结束位置。
正则表达式中括号的三种功能:1)限定多选结构的范围;如:ab(c|d|e)fgh,注意上述写法与去掉括号时abc|d|efgh 的区别2)标注量词作用的元素;如:ab(cde)+fgh,注意上述写法与去掉括号时abcde+fhg的区别3)为引用捕获文本;作为这个用法加括号是为了返回或引用匹配结果'[]' 标记一个中括号表达式。
可以用来指定可以取的字符范围,如[a-z],或者排除掉[]中的内容'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
'|' 指明两项之间的一个选择。
例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
\num 匹配 num,其中 num 是一个正整数。
对所获取的匹配的引用。
正则表达式的一个很有用的特点是可以保存子表达式以后使用,被称为Backreferencing. 允许复杂的替换能力如调整一个模式到新的位置或者指示被代替的字符或者单词的位置. 被匹配的子表达式存储在临时缓冲区中,缓冲区从左到右编号, 通过\数字符号访问。
下面的例子列出了把名字 aa bb cc 变成cc, bb, aa.Select REGEXP_REPLACE('aa bb cc','(.*) (.*) (.*)', '\3, \2, \1') FROM dual;REGEXP_REPLACE('ELLENHILDISMITcc, bb, aa'\' 转义符。
字符簇:[[:alpha:]] 任何字母。
任何字符?[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
任何字母?[[:space:]] 任何空白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
各种操作符的运算优先级\ 转义符(), (?, (?=), [] 圆括号和方括号*, +, ?, {n}, {n,}, {n,m} 限定符^, $, \anymetacharacter 位置和顺序| “或”操作--测试数据create table test(mc varchar2(60));insert into test values('112233445566778899');insert into test values('22113344 5566778899');insert into test values('33112244 5566778899');insert into test values('44112233 5566 778899');insert into test values('5511 2233 4466778899');insert into test values('661122334455778899');insert into test values('771122334455668899');insert into test values('881122334455667799');insert into test values('991122334455667788');insert into test values('aabbccddee');insert into test values('bbaaaccddee');insert into test values('ccabbddee');insert into test values('ddaabbccee');insert into test values('eeaabbccdd');insert into test values('ab123');insert into test values('123xy');insert into test values('007ab');insert into test values('abcxy');insert into test values('The final test is is is how to find duplicate words.'); commit;一、REGEXP_LIKEselect * from test where regexp_like(mc,'^a{1,3}');{}的意思是连续几个的匹配上面的sql的意思是开头有1个到3个连续aselect * from test where regexp_like(mc,'a{1,3}');有连续3个aselect * from test where regexp_like(mc,'^a.*e$');以a开头以e结尾的字符之所以有.是因为如果写成^a*e$就变成以a开头中间都是a以e结尾的字符拉 *的意思是匹配它前面的字符^ab*e$可否查出以a开头以e结尾的字符呢?答案是否定的因为*虽然是可以匹配前面的b0次或者多次但是它也仅仅是匹配以a开头中间可以有b并且都是b,或者中间没有字符,以e结尾的字符.'^[[:alpha:]]+$'的意思是以字母从开头到结尾都包含字母的字符select * from test where regexp_like(mc,'^[[:lower:]]|[[:digit:]]');小写字母或者数字开头的字符select * from test where regexp_like(mc,'^[[:lower:]]');小写字母开头的字符select mc FROM test Where REGEXP_LIKE(mc,'[^[:digit:]]');"^"就是一个有多种意义的字符元,主要看语意环境如果"^"是字符列中的第一个字符,就表示对这个字符串取反,因此, [^[:digit:]]就是表示查找非数字的模式即字符中不都是数字Select mc FROM test Where REGEXP_LIKE(mc,'^[^[:digit:]]');以非数字开头的字符二、REGEXP_INSTRSelect REGEXP_INSTR(mc,'[[:digit:]]$') from test;Select REGEXP_INSTR(mc,'[[:digit:]]+$') from test;Select REGEXP_INSTR('The price is $400.','\$[[:digit:]]+') FROM DUAL;Select REGEXP_INSTR('onetwothree','[^[[:lower:]]]') FROM DUAL;Select REGEXP_INSTR(',,,,,','[^,]*') FROM DUAL;Select REGEXP_INSTR(',,,,,','[^,]') FROM DUAL;三、REGEXP_SUBSTRSELECT REGEXP_SUBSTR(mc,'[a-z]+') FROM test;SELECT REGEXP_SUBSTR(mc,'[0-9]+') FROM test;SELECT REGEXP_SUBSTR('aababcde','^a.*b') FROM DUAL;四、REGEXP_REPLACESelect REGEXP_REPLACE('Joe Smith','( ){2,}', ',') AS RX_REPLACE FROM dual; Select REGEXP_REPLACE('aa bb cc','(.*) (.*) (.*)', '\3, \2, \1') FROM dual;其中\1,\2,\3表示第几个正则表达式如SELECT regexp_substr('Repuuublicc Of Africaa', '([a-z])\1', 1, 1, 'i') from dual请问,这句是取连续两个小写字母,如果想取连续三个小写字母怎么写啊SELECT regexp_substr('Repuuublicc Of Africaa', '([a-z])\1\1', 1, 1, 'i') from dual注:Regexp_substr的参数5个参数第一个是输入的字符串第二个是正则表达式第三个是标识从第几个字符开始正则表达式匹配。