手把手教你批量下载抖音视频
- 格式:doc
- 大小:617.50 KB
- 文档页数:3

怎么批量采集下载抖音短视频?
抖音上优秀的短视频数不胜数,很多做视频搬运的朋友经常会到这个平台下载作品,那怎么下载会比较方便呢,小编今日教大家几个方法。
方法一,按作者主页批量下载全部的作品
打开固乔视频助手,点击自媒体视频下载。
可以看到,固乔会弹出一个新页面,找到“作者作品下载”单击打开一个小窗口如下图。
然后,拿出手机去复制链接。
在抖音APP上面找到你要下载的个人主页,找到复制链接,点击。
然后,打开微信,利用微信同步信息,将链接同步到电脑端的微信上面。
回到电脑上,在微信电脑端找到这个链接,选中复制,切换到固乔窗口后,粘贴到小窗口上面,然后点击获取。
获取的过程中,窗口下方会显示获取到多少数量的视频,等到获取完毕,会自动关闭这个小窗口,并把获取到的视频链接粘贴好。
最后,点击立即下载,等到下载完成,点击打开文件夹就可以查看下载好的视频了。
方法二,采集视频链接批量下载
复制视频链接粘贴到工具,然后点击“立即下载”
点击打开文件夹,即可看到下载好了的视频
方法三,搜索热门视频下载
点击随机获取热门视频,选择抖音视频。
获取到链接后,点击立即下载
以上是抖音视频批量下载的三种方法。

短视频搬运技巧短视频搬运技巧适用于各大短视频平台(快手,抖音,火山小视频,美拍)微视不考虑,因为微视需要认证,不认证的账号,不给推荐,只有200-500 播放。
短视频平台推荐的原理:一个账号如果正常,每个视频平台都给你200 左右的播放量。
在根据播放完成度,点赞,评论,转发数量,推荐下一个级别,几千,几万,几十万,甚至几百万的播放,所以我们要做的的就是:注册的号一定要是模拟正常用户使用,搬运的视频质量一定得好,十个差的视频,抵不过一个质量好视频的播放量。
只有当我们的视频质量足够好,才能上大热门。
今天我们主要讲讲抖音的搬运玩法,适用于其他几个平台下面我们一步一步的讲解注册→养号→选材→处理→上传→留微信号1,注册手机号,QQ 号,微信号,微博号都可以注册。
最好的注册方式,手机号+QQ 号,手机号+微信号,手机号+微博号。
没有手机号的,可以拿自己的亲戚朋友手机号注册,家里有老人不用这些,我们就可以拿他们的手机号绑定,实在没有手机号的,用阿里小号(应用商店都有下载)批量操作的,可以去网上买QQ 号,微博跳转登录。
注册登录时,尽量用流量,别用WiFi。
2,养号这是最最最重要的步骤,一个号能不能被推荐这是最关键的一步,号没养好,平台不给推荐,你搬运的视频质量再好,都不会有播放量的。
所以这步是非常重要注册好后的抖音,我们先把资料改成一个正常的用户,名字,头像,年龄,学校,签名都改成一个正常的用户,千万不要有任何的违规操作,要留微信号也是后期的事,前期只要改成一个正常的用户就可以了。
如果用微信,QQ,微博登录的,一定记得去绑定个手机号,手机号怎么解决,自己去注册里看,都写的很清楚了。
资料什么都改成一个正常用户了,接下来,就模拟一个正常的用户使用了,怎么操作呢,花个5-10 分钟看看抖音里面的视频,点点赞,点点关注,看看同城附近人,还有评论,转发,看到喜欢的视频,点进别人的主页,看看他其他的视频,说白了就是尽可能的模仿一个正常的用户使用。

2022最新短视频批量搬运方法
随着短视频平台的不断涌现,越来越多的人开始关注短视频的营销价值,而批量搬运短视频成为了很多人的选择。
但是,如何才能有效地进行短视频批量搬运呢?本文将介绍2022年最新短视频批量搬运方法。
首先,选择合适的短视频平台。
目前,国内短视频平台主要有抖音、快手、小红书等。
这些平台都有着大量的用户和优质的内容,但是每个平台的用户群体和内容特点都不同,需要根据自己的需求选择合适的平台。
其次,选择适合自己的搬运方式。
短视频批量搬运有多种方式,常见的有下载、转发和剪辑。
下载是将短视频下载到本地,然后再上传到其他平台,但是需要注意版权问题;转发是直接在原平台上进行转发,但是对于一些平台来说,转发量过大会被认为是刷量行为;剪辑是将多个短视频进行剪辑拼接成一个长视频,但是需要注意剪辑的质量和版权问题。
再次,注意短视频内容的选择。
短视频的内容是吸引用户的关键,需要选择符合自己品牌或产品特点的内容。
同时,需要注意短视频的质量和原创性,避免侵权行为。
最后,进行短视频批量搬运的同时,也需要注意营销策略的实施。
可以通过定向投放等方式提高视频曝光率,吸引更多的用户关注。
同时,可以通过互动、评论等方式与用户进行互动,增加用户粘性和转化率。
总之,短视频批量搬运是一种有效的营销手段,但是需要注意选择合适的平台、搬运方式和内容,并结合营销策略进行实施,才能取得更好的效果。

怎么用Python爬取抖音小视频?资深程序员都这样爬取的(附源码)简介抖音,是一款可以拍短视频的音乐创意短视频社交软件,该软件于2016年9月上线,是一个专注年轻人的15秒音乐短视频社区。
用户可以通过这款软件选择歌曲,拍摄15秒的音乐短视频,形成自己的作品。
此APP已在Android各大应用商店和APP Store均有上线。
今天咱们就用Python爬取抖音视频准备:环境:Python3.6 WindowsIDE:你开行就好,喜欢用哪个就用哪个模块:1 from splinter.driver.webdriver.chrome import Options, Chrome2 from splinter.browser import Browser3 from contextlib import closing4 import requests, json, time, re, os, sys, time5 from bs4 import BeautifulSoup获得视频播放地址•查询的用户ID•视频名字列表•视频链接列表•用户昵称1 def get_video_urls(self, user_id):23 video_names = []4 video_urls = []5 unique_id = ''6 while unique_id != user_id:7 search_url ='/aweme/v1/discover/search/?cursor=0&keyword=%s&count=1 0&type=1&retry_type=no_retry&iid=17900846586&device_id= 34692364855&ac=wifi&channel=xiaomi&aid=1128&app_name =aweme&version_code=162&version_name=1.6.2&device_platf orm=android&ssmix=a&device_type=MI5&device_brand=Xiaomi&os_api=24&os_version=7.0&uuid=86 1945034132187&openudid=dc451556fc0eeadb&manifest_versi on_code=162&resolution=1080*1920&dpi=480&update_versio n_code=1622' % user_id8 req = requests.get(url = search_url, verify = False)9 html = json.loads(req.text)10 aweme_count = html['user_list'][0]['user_info']['aweme_count']11 uid = html['user_list'][0]['user_info']['uid']12 nickname = html['user_list'][0]['user_info']['nickname']13 unique_id = html['user_list'][0]['user_info']['unique_id']14 user_url = 'https:///aweme/v1/aweme/post/?user_id=%s &max_cursor=0&count=%s' % (uid, aweme_count)15 req = requests.get(url = user_url, verify = False)16 html = json.loads(req.text)17 i = 118 for each in html['aweme_list']:19 share_desc = each['share_info']['share_desc']20 if '抖音-原创音乐短视频社区' == share_desc:21 video_names.append(str(i) '.mp4')22 i = 123 else:24 video_names.append(share_desc '.mp4')25 video_urls.append(each['share_info']['share_url'])2627 return video_names, video_urls, nickname获得带水印的视频播放地址•video_url:带水印的视频播放地址•download_url: 带水印的视频下载地址1 def get_download_url(self, video_url):23 req = requests.get(url = video_url, verify = False)4 bf = BeautifulSoup(req.text, 'lxml')5 script = bf.find_all('script')[-1]6 video_url_js = re.findall('var data = \[(. )\];', str(script))[0]7 video_html = json.loads(video_url_js)8 download_url = video_html['video']['play_addr']['url_list'][0]9 return download_url视频下载•video_url: 带水印的视频地址•video_name: 视频名•watermark_flag: 是否下载不带水印的视频1 def video_downloader(self, video_url, video_name, watermark_flag=True):2 '''3 视频下载4 Parameters:5 video_url: 带水印的视频地址6 video_name: 视频名7 watermark_flag: 是否下载不带水印的视频8 Returns:9 无10 '''11 size = 012 if watermark_flag == True:13 video_url = self.remove_watermark(video_url)14 else:15 video_url = self.get_download_url(video_url)16 with closing(requests.get(video_url, stream=True, verify = False)) as response:17 chunk_size = 102418 content_size = int(response.headers['content-length'])19 if response.status_code == 200:20 sys.stdout.write(' [文件大小]:%0.2f MB\n' % (content_size / chunk_size / 1024))2122 with open(video_name, 'wb') as file:23 for data in response.iter_content(chunk_size = chunk_size):24 file.write(data)25 size = len(data)26 file.flush()2728 sys.stdout.write(' [下载进度]:%.2f%%' % float(size / content_size * 100) '\r')29 sys.stdout.flush()获得无水印的视频播放地址1 def remove_watermark(self, video_url):2 '''3 获得无水印的视频播放地址4 Parameters:5 video_url: 带水印的视频地址6 Returns:7 无水印的视频下载地址8 '''9 self.driver.visit('/') 10 self.driver.find_by_tag('input').fill(video_url) 11 self.driver.find_by_xpath('//button[@class='btn btn-default']').click() 12 html = self.driver.find_by_xpath('//div[@class='thumbnail']/div/p')[0].ht ml 13 bf = BeautifulSoup(html, 'lxml') 14 return bf.find('a').get('href')下载视频1 def run(self):2 '''3 运行函数4 Parameters:5 None6 Returns:7 None8 '''9 self.hello()10 user_id = input('请输入ID(例如40103580):')11 video_names, video_urls, nickname = self.get_video_urls(user_id)12 if nickname not in os.listdir():13 os.mkdir(nickname)14 print('视频下载中:共有%d个作品!\n' % len(video_urls))15 for num in range(len(video_urls)):16 print(' 解析第%d个视频链接 [%s] 中,请稍后!\n' % (num 1, video_urls[num]))17 if '\\' in video_names[num]:18 video_name = video_names[num].replace('\\', '')19 elif '/' in video_names[num]:20 video_name = video_names[num].replace('/', '')21 else:22 video_name = video_names[num]23 self.video_downloader(video_urls[num], os.path.join(nickname, video_name))24 print('\n')2526 print('下载完成!')全部代码1 # -*- coding:utf-8 -*-23 Python学习交流群:1252409634 Python学习交流群:1252409635 Python学习交流群:12524096367 from splinter.driver.webdriver.chrome import Options, Chrome8 from splinter.browser import Browser9 from contextlib import closing 10 import requests, json, time, re, os, sys, time 11 from bs4 import BeautifulSoup 12 13 class DouYin(object): 14 def __init__(self, width = 500, height = 300): 15 ''' 16 抖音App视频下载17 ''' 18 # 无头浏览器19 chrome_options = Options() 20 chrome_options.add_argument('user-agent='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'') 21 self.driver = Browser(driver_name='chrome',executable_path='D:/chromedriver', options=chrome_options, headless=True) 22 23 def get_video_urls(self, user_id): 24 ''' 25 获得视频播放地址26 Parameters: 27 user_id:查询的用户ID 28 Returns: 29 video_names: 视频名字列表 30 video_urls: 视频链接列表 31 nickname: 用户昵称 32 ''' 33 video_names = [] 34 video_urls = [] 35 unique_id = '' 36 while unique_id != user_id: 37 search_url ='/aweme/v1/discover/search/?cursor=0&keyword=%s&count=1 0&type=1&retry_type=no_retry&iid=17900846586&device_id= 34692364855&ac=wifi&channel=xiaomi&aid=1128&app_name =aweme&version_code=162&version_name=1.6.2&device_platf orm=android&ssmix=a&device_type=MI5&device_brand=Xiaomi&os_api=24&os_version=7.0&uuid=86 1945034132187&openudid=dc451556fc0eeadb&manifest_versi on_code=162&resolution=1080*1920&dpi=480&update_versio n_code=1622' % user_id 38 req = requests.get(url = search_url, verify = False) 39 html = json.loads(req.text) 40 aweme_count = html['user_list'][0]['user_info']['aweme_count'] 41 uid = html['user_list'][0]['user_info']['uid'] 42 nickname = html['user_list'][0]['user_info']['nickname'] 43 unique_id = html['user_list'][0]['user_info']['unique_id'] 44 user_url = 'https:///aweme/v1/aweme/post/?user_id=%s &max_cursor=0&count=%s' % (uid, aweme_count) 45 req = requests.get(url = user_url, verify = False) 46 html = json.loads(req.text) 47 i = 1 48 for each in html['aweme_list']: 49 share_desc = each['share_info']['share_desc'] 50 if '抖音-原创音乐短视频社区' == share_desc: 51 video_names.append(str(i) '.mp4') 52 i = 1 53 else: 54 video_names.append(share_desc '.mp4') 55 video_urls.append(each['share_info']['share_url']) 56 57 return video_names, video_urls, nickname 58 59 def get_download_url(self, video_url): 60 ''' 61 获得带水印的视频播放地址62 Parameters: 63 video_url:带水印的视频播放地址64 Returns: 65 download_url: 带水印的视频下载地址66 ''' 67 req = requests.get(url = video_url, verify = False) 68 bf = BeautifulSoup(req.text, 'lxml') 69 script = bf.find_all('script')[-1] 70 video_url_js = re.findall('var data = \[(. )\];', str(script))[0] 71 video_html = json.loads(video_url_js) 72 download_url = video_html['video']['play_addr']['url_list'][0] 73 return download_url 74 75 def video_downloader(self, video_url, video_name, watermark_flag=True): 76 ''' 77 视频下载78 Parameters: 79 video_url: 带水印的视频地址 80 video_name: 视频名 81 watermark_flag: 是否下载不带水印的视频 82 Returns: 83 无84 ''' 85 size = 0 86 if watermark_flag == True: 87 video_url = self.remove_watermark(video_url) 88 else: 89 video_url = self.get_download_url(video_url) 90 with closing(requests.get(video_url, stream=True, verify = False)) as response: 91 chunk_size = 1024 92 content_size = int(response.headers['content-length']) 93 if response.status_code == 200: 94 sys.stdout.write(' [文件大小]:%0.2f MB\n' % (content_size / chunk_size / 1024)) 95 96 with open(video_name, 'wb') as file: 97 for data in response.iter_content(chunk_size = chunk_size): 98 file.write(data) 99 size = len(data) 100 file.flush() 101 102 sys.stdout.write(' [下载进度]:%.2f%%' % float(size / content_size * 100) '\r') 103 sys.stdout.flush() 104 105 106 def remove_watermark(self, video_url): 107 ''' 108 获得无水印的视频播放地址 109 Parameters: 110 video_url: 带水印的视频地址 111 Returns: 112 无水印的视频下载地址113 ''' 114 self.driver.visit('/') 115 self.driver.find_by_tag('input').fill(video_url) 116 self.driver.find_by_xpath('//button[@class='btn btn-default']').click() 117 html = self.driver.find_by_xpath('//div[@class='thumbnail']/div/p')[0].ht ml 118 bf = BeautifulSoup(html, 'lxml') 119 return bf.find('a').get('href') 120 121 def run(self): 122 ''' 123 运行函数124 Parameters: 125 None 126 Returns: 127 None 128 ''' 129 self.hello() 130 user_id = input('请输入ID(例如40103580):') 131 video_names, video_urls, nickname = self.get_video_urls(user_id) 132 if nickname not in os.listdir(): 133 os.mkdir(nickname) 134 print('视频下载中:共有%d个作品!\n' % len(video_urls)) 135 for num in range(len(video_urls)): 136 print(' 解析第%d个视频链接[%s] 中,请稍后!\n' % (num 1, video_urls[num])) 137 if '\\' in video_names[num]: 138 video_name =video_names[num].replace('\\', '') 139 elif '/' in video_names[num]: 140 video_name = video_names[num].replace('/', '') 141 else: 142 video_name = video_names[num] 143 self.video_downloader(video_urls[num], os.path.join(nickname, video_name)) 144 print('\n') 145 146 print('下载完成!') 147 148 def hello(self): 149 ''' 150 打印欢迎界面151 Parameters: 152 None 153 Returns: 154 None 155 ''' 156 print('*' * 100) 157 print('\t\t\t\t抖音App视频下载小助手') 158 print('\t\t作者:Python学习交流群:125240963') 159 print('*' * 100) 160 161 162 if __name__ == '__main__': 163 douyin = DouYin() 164 douyin.run()。

批量下载抖⾳作者的所有视频
今天给⼤家介绍两个⼩⼯具,可以批量下载抖⾳作者的所有视频。
前两天我也尝试过⾃⼰写⼀个⼩⼯具,来做同样的事情。
但是在抖⾳签名算法那卡壳了。
好像现在抖⾳升级了算法,现在不能⽤了。
这两款软件来⾃吾爱破解论坛,在⽂章最后我会放上链接。
1. 获取抖⾳作者链接
进⼊抖⾳作者⾸页,点击右上⾓...————分享————复制链接。
2. 下载视频
粘贴地址后,点击查询。
软件会解析作者所有的作品,并且是不带⽔印的。
然后点击全选,选择下载所有勾选视频,即可开始下载。
另⼀款也是同样的做法,先点击查询,然后点击获取作品。
然后点击视频,全部下载即可。
这个作者没有加⼊打赏功能。
3. 下载的视频在软件同⼀个⽬录下
4. 下载地址。
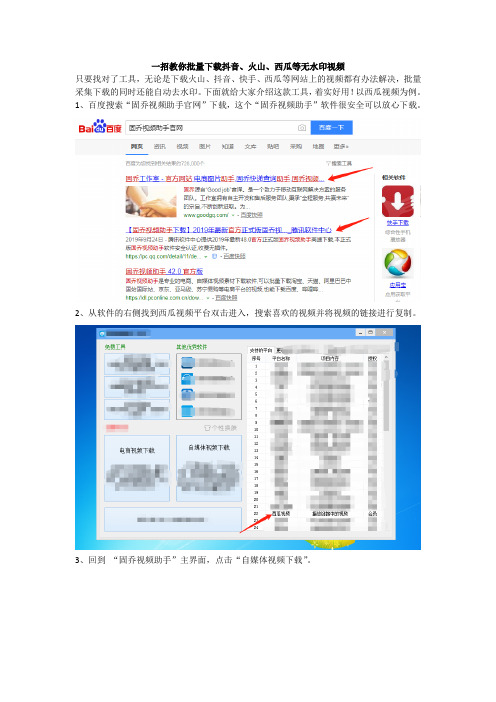
一招教你批量下载抖音、火山、西瓜等无水印视频
只要找对了工具,无论是下载火山、抖音、快手、西瓜等网站上的视频都有办法解决,批量采集下载的同时还能自动去水印。
下面就给大家介绍这款工具,着实好用!以西瓜视频为例。
1、百度搜索“固乔视频助手官网”下载,这个“固乔视频助手”软件很安全可以放心下载。
2、从软件的右侧找到西瓜视频平台双击进入,搜索喜欢的视频并将视频的链接进行复制。
3、回到“固乔视频助手”主界面,点击“自媒体视频下载”。
4、将复制的链接粘贴到窗口的白色框框里面,点击“浏览”按钮可以改变保存路径,然后点击“立即下载”。
5、下载好的视频可以直接通过“打开文件夹”查看。
Python不仅能爬网页还能爬取APP呢!批量爬取抖音视频!最新代码繁华落尽and曲终人散 2018-08-09 15:29:58介绍这次爬的是当下大火的APP--抖音,批量下载一个用户发布的所有视频。
各位也应该知道,抖音只有移动端,官网打开除了给你个APP下载二维码啥也没有,所以相比爬PC网站,还是遇到了更多的问题,也花了更多的时间,不过好在基本实现了,除了一点咱在后面说。
谷歌Chrome浏览器有一个模拟手机访问的功能,我们选在iPhone X模式来访问页面,果然看到发布的视频了:我们接下来看下后台请求,不多,很快就找到我们需要的视频信息了,也能直接打开观看视频,到这感觉已经成功了一大半了:两个地址除了max_cursor其他都一样,其实就是上一条返回的json数据中的max_cursor就是下个链接中的max_cursor,然后has_more等于1的时候表示还未全部加载,这样逻辑就清楚了,我们只要先判断has_more是否等于1,等于1的时候我们将max_cursor的值传入下一个链接继续访问获取视频地址,直到has_more等于0为止。
这样所有视频地址都有了,就开始下载吧!!代码部分from selenium import webdriverfrom bs4 import BeautifulSoupimport jsonimport requestsimport sysimport timeimport osimport uuidfrom contextlib import closingfrom requests.packages.urllib3.exceptions import InsecureRequestWarningrequests.packages.urllib3.disable_warnings(InsecureRequestWarning)class douyin_spider(object):"""docstring for douyin_spider"""def __init__(self,user_id,_signature,dytk):print '*******DouYin_spider******'print 'Author : Awesome_Tang'print 'Date : 2018-07-29'print 'Version: Python2.7'print '**************************'print ''erid = user_idself.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}mobile_emulation = {'deviceName': 'iPhone X'}# chrome浏览器模拟iPhone X进行页面访问options = webdriver.ChromeOptions()options.add_experimental_option("mobileEmulation", mobile_emulation)self.browser = webdriver.Chrome(chrome_options=options)self._signature= _signatureself.dytk= dytkself.url = 'https:///aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=0&aid=1128&_signature=%s&dytk=%s'%(erid,self._signature,self.dytk)def handle_url(self):url_list = [self.url,]self.browser.get(self.url)web_data = self.browser.page_sourcesoup = BeautifulSoup(web_data, 'lxml')web_data = soup.pre.stringweb_data = json.loads(str(web_data))if web_data['status_code'] == 0:while web_data['has_more'] == 1:#最大加载32条视频信息,has_more等于1表示还未全部加载完max_cursor = web_data['max_cursor']#获取时间戳url = 'https:///aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=%s&aid=1128&_signature=%s&dytk=%s'%(erid,max_cursor,self._signature,self.dytk)url_list.append(url)self.browser.get(url)web_data = self.browser.page_sourcesoup = BeautifulSoup(web_data, 'lxml')web_data = soup.pre.stringweb_data = json.loads(str(web_data))max_cursor = web_data['max_cursor']#获取时间戳url = 'https:///aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=%s&aid=1128&_signature=%s&dytk=%s'%(erid,max_cursor,self._signature,self.dytk)url_list.append(url)else:url_list = []return url_listdef get_download_url(self,url_list):download_url = []title_list = []if len(url_list)> 0:for url in url_list:self.browser.get(url)web_data = self.browser.page_sourcesoup = BeautifulSoup(web_data, 'lxml')web_data = soup.pre.stringweb_data = json.loads(str(web_data))if web_data['status_code'] == 0:for i in range(len(web_data['aweme_list'])):download_url.append(web_data['aweme_list'][i]['video']['play_addr']['url_list'][0])title_list.append(web_data['aweme_list'][i]['share_info']['share_desc'].encode('utf-8'))return download_url,title_listdef videodownloader(self,url,title):size = 0path = title+'.mp4'with closing(requests.get(url, headers = self.headers ,stream=True, verify=False)) as response: chunk_size = 1024content_size = int(response.headers['content-length'])if response.status_code == 200:print '%s is downloading...'%titlesys.stdout.write('[File Size]: %0.2f MB ' % (content_size/chunk_size/1024))with open(path, 'wb') as f:for data in response.iter_content(chunk_size=chunk_size):f.write(data)size += len(data)sys.stdout.write('[Progress]: %0.2f%%' % float(size/content_size*100) + ' ')sys.stdout.flush()else:print response.status_codedef run(self):url = 'https:///aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=0&aid=1128&_signature=%s&dytk=%s'%(erid,self._signature,self.dytk)url_list = self.handle_url()download_url,title_list = self.get_download_url(url_list)for i in range(len(download_url)):url = download_url[i]title = title_list[i]self.videodownloader(url,title)if __name__ == '__main__':#创建对象#传入三个参数,user_id,_signature,dytkdouyin_spider =douyin_spider('95870186531','RFE1JhAbHxD7J8TA9HCumURRNT','539f2c59bb57577983b3818b7a7f32ef') douyin_spider.run()print '******DouYin_spider@Awesome_Tang、******'。
全网短视频批量下载神器,批量下载短视频不用愁全网短视频批量下载神器,批量下载短视频不用愁,现在短视频创作可以说是炙手可热,大部分自媒体人都在往短视频这方面去发展,有的人专注于视频剪辑,有的人专注于剧本拍摄,每个人的目标也不一样,但是大方向都是短视频运营。
在互联网发展的今天,仍有很多自媒体人苦于没有素材,尤其是视频运营,没有素材就相当于巧妇难为无米之炊,视频下载一直是一个热门话题,很多人都不知道全网的短视频怎么去批量进行下载,今天我就来给大家介绍一个神器。
相信大家也听说过易撰,易撰是一个可以批量下载视频的神器,它不仅可以下载视频还可以下载文章素材,可以直接搜索关键词选择心仪的视频进行下载,也可以直接选择自媒体平台还有发布时间,进行视频的批量下载,操作也很方便。
怎么去做短视频自媒体?第一步:明确视频的定位在大家开始运作账号之前,一定要想清楚自己的这个账号究竟是做什么的,是朝哪个方面去发展的,确定好了之后就思考视频的受众群体是谁,该怎么取得这些群体的关注。
第二步:确定角色分工一个视频团体,都是有角色分工的,比如摄影,剪辑,文案,运营等等角色,如果你可以胜任这些角色的话,你也可以自己独立操作。
第三步:选择主题主题的选择这一步也是很重要的,一个好的主题决定了你的流量,大家进行主题选择的时候,可以参考一下微博热搜榜,可以给你带来灵感。
第四步:选择拍摄场景拍摄场景的选择很简单,你可以根据你的主题来进行选择,主要还是要光线还有环境这两块。
第五步:进行剪辑这一步就不用我说了,视频自媒体人必须要学会视频剪辑,大家如果对电脑专业剪辑软件不太熟悉,也可以用手机软件进行操作。
第六步:进行分发大家在每个自媒体平台上都要有自己的账号,这样有利于打造你的品牌IP,如果觉得多平台手动发布很麻烦的话,可以用蚁小二进行免费的一键分发,这样会省很多时间。
如何批量下载高品质的方法批量下载高品质的方法近年来,随着互联网技术的飞速发展,我们越来越需要批量下载高品质的文件。
不论是照片、视频还是音乐,我们都渴望能够一次性下载多个文件,同时也要求这些文件具备高品质的特点。
本文将向您介绍几种实用的方法,帮助您轻松实现批量下载高品质文件的目标。
一、使用下载管理器工具一种简单而有效的方法是使用下载管理器工具。
这些工具通常具备较为友好的用户界面,操作方便快捷,适用于批量下载各种类型的高品质文件。
以下是几个常用的下载管理器工具:1. Free Download Manager(FDM):这是一款功能强大且免费的下载管理器工具,支持HTTP、FTP和BT等多种下载协议。
FDM能够根据您的需求自动分割文件,并启动多个下载线程,从而提高下载速度。
同时,它还具备下载调度功能,可以让您设置下载优先级和时间,提供更好的下载管理体验。
2. Internet Download Manager(IDM):IDM是一款经典而受欢迎的下载管理器工具。
它支持加速下载功能,能够自动拦截下载链接,并且可以恢复中断的下载任务。
IDM还集成了浏览器,方便您在浏览网页时直接下载所需文件。
3. JDownloader:JDownloader是一款免费开源的下载管理器工具,特别适合下载批量的文件。
它支持自动识别和处理各种下载链接,可以自动解压RAR等压缩文件,并且能够绕过常见的下载限制。
这些下载管理器工具提供了可靠且高效的下载功能,能够满足您批量下载高品质文件的需求。
二、使用命令行工具除了下载管理器工具,您还可以考虑使用命令行工具来批量下载高品质文件。
这些工具主要面向技术人员和高级用户,需要一定的技术储备。
以下是几个常用的命令行工具:1. wget:wget是一款功能强大的命令行下载工具,支持HTTP、FTP和HTTPS等协议。
通过使用wget的批量下载功能,您可以轻松下载多个文件。
例如,使用`wget -i urls.txt`命令,您可以从一个文本文件中读取下载链接,并将文件保存到指定位置。
在线提取抖音短视频在当今社交媒体的潮流中,短视频已经成为一种新型的传播方式,越来越多的人加入到了短视频制作的行列中。
而其中,抖音作为国内最为流行的短视频应用之一,在年轻人中尤为受欢迎,因为它不仅可以帮助用户快速制作出有趣的短视频,还可以让用户分享自己的生活点滴,这也是它备受欢迎的原因之一。
然而,许多用户在使用抖音时都会遇到一个问题:如何在线提取抖音短视频?这个问题对于那些想要保存自己喜欢的短视频的人来说,是非常重要的。
所以在本文中,我们将为大家介绍如何在线提取抖音短视频。
首先,我们需要了解抖音短视频的基本信息。
抖音短视频是一种短时限的视频形式,其长度一般不超过60秒,并且在抖音上发布的视频都是横屏的。
而在线提取抖音短视频的方法,主要有以下几种:1.使用第三方工具网络上有许多提取抖音短视频的第三方工具,这些工具可以帮助用户快速提取自己喜欢的短视频,并保存到自己的设备中。
这些工具通常都是免费的,而且操作简单,只需要输入对应的视频链接即可。
2.使用抖音自带的保存功能抖音自带了保存短视频的功能,用户可以在观看自己喜欢的短视频时,点击右下角的“分享”按钮,然后选择“保存视频”即可将视频保存到自己的设备中。
3.使用屏幕录制软件如果以上两种方法都无法满足用户的需求,那么可以考虑使用屏幕录制软件。
这些软件可以记录用户在屏幕上的所有操作,包括观看抖音短视频的过程,从而实现在线提取抖音短视频的目的。
总之,以上三种方法都可以帮助用户在线提取抖音短视频。
不过需要提醒的是,为了避免侵犯他人的版权,用户在提取短视频时一定要注意保护好自己和他人的权益。
同时,我们也应该善用网络资源,抵制不良风气,共同营造一个健康、和谐的网络环境。
手把手教你批量下载抖音视频
抖音,是一款可以拍短视频的音乐创意短视频社交软件,该软件于2016年9月上线,是一个专注年轻人的15秒音乐短视频社区。
用户可以通过这款软件选择歌曲,拍摄15秒的音乐短视频,形成自己的作品。
很多商家利用这些短视频编辑成广告媒介来宣传自己的商品。
那么,要怎样下载这些短视频呢?这是很多朋友经常问我的,今天就抽空写个方法给大家参考参考。
因为抖音软件是安装在手机上的,而我们编辑视频时,是在电脑上操作,那么要怎样把抖音软件安装在电脑上,以便复制链接下载视频呢?在这里我们需要用到安卓模拟器,本例中,我们主要以逍遥模拟器来讲解。
一、所需工具:
1、安卓模拟器(安装抖音APP)
2、视频下载高手
二:操作方法:
1、打开逍遥模拟器中的抖音软件,如图:
2、找到需要下载的视频后,点右下角的(分享),然后点里面的
(复制链接),如图:
3、打开视频下载高手软件,并点击“短视频下载”,如图:
4、把链接粘贴到视频下载高手软件中,选择好保存的位置后,点“立即下载”,如图:
(注意:要把网址前面的视频标题删除掉,一行一个网址可以批量下载)
5、下载完成后,当前进度会显示100%,这时点“打开文件夹”,就可以查看已下载好的视频了,如图:
(可以看到,下载下来的视频是没有水印的哦)
好了,下载抖音视频是不是很简单呢?用这个方法不单可以下载抖音视频,还可以下载美拍、火山等短视频,而且还能下载淘宝主图视频、描述视频等,非常方便。
至于视频编辑方法,本文就不作介绍,视频编辑软件可以用:会声会影或premiere等。
本文介绍的软件,可以在百度上搜索并下载。
视频下载高手软件是第一客服软件中心开发的,可以在百度搜索:第一客服。