编译原理词法2(NFA、DFA的确定化和化简)
- 格式:ppt
- 大小:551.50 KB
- 文档页数:28

实用文档2016.11.02不确定有穷状态自动机的确定化目录一、实验名称 (2)二、实验目的 (2)三、实验原理 (2)1、NFA定义 (2)2、DFA的定义 (2)3、closure函数 (2)4、move函数 (3)四、实验思路 (3)1、输入 (3)2、closure算法 (3)3、move算法 (3)4、构造子集 (4)5、输出 (4)五、实验小结 (4)1、输入存储问题 (4)2、closure算法问题 (4)3、输出问题 (5)六、附件 (5)1、源代码 (5)2、运行结果截图 (7)一、实验名称不确定有穷状态自动机的确定化二、实验目的输入:非确定有穷状态自动机NFA输出:确定化的有穷状态自动机DFA三、实验原理1、NFA定义一个不确定的有穷自动机M是一个五元组,M=(K,E,f,S,Z)其中a.K是一个有穷集,它的每个元素称为一个状态;b.E是一个有穷字母表,它的每个元素称为一个输入符号;c.f是一个从K×E*到K的子集的映像,即:K*E*->2k,其中2k表示K的幂集;d.S包含于K,是一个非空初态集;e.Z包含于K,是一个终态集。
2、DFA的定义一个确定的有穷自动机M是一个五元组,M=(K,E,f,S,Z)其中a.K是一个有穷集,它的每个元素称为一个状态;b.E是一个有穷字母表,它的每个元素称为一个输入符号;c.f是转换函数,是K×E->K上的映像,即,如f(ki,a)=kj(ki∈K,kj∈K)就意味着,当前状态为ki,输入字符为a时,将转换到下一状态kj,我们把kj称作ki的一个后继状态;d.S∈K,是唯一的一个初态;e.Z包含于K,是一个终态集,终态也称可接受状态或结束状态。
3、closure函数状态集合I的ε—闭包,表示为ε—closure(I),定义为一状态集,是状态集I中的任何状态S经任意条ε弧而能到达的状态的集合。
4、move函数状态集合I的a弧转换,表示为move(I,a),定义为状态集合J,其中J是所有那些从I中的某一状态经过一条a弧而到达的状态的全体。


编译原理词法NFADFA的确定化和化简编译原理中的词法分析主要包括以下步骤:词法分析器将输入的源程序文本转化为一个个单词(token),即词法单元。
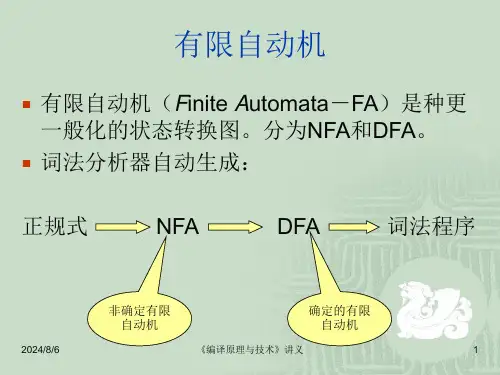
在词法分析过程中,使用的主要工具是有限自动机(NFA)和确定的有限自动机(DFA)。
NFA(DFA)的确定化是指将一个非确定的有限自动机转化为一个确定的有限自动机。
非确定有限自动机具有多个可能的转换路径,而确定有限自动机每个状态只能有一个转换路径。
确定化的目的是简化自动机的状态图,减少转换的复杂性,便于理解和实现。
确定化的过程一般包括以下步骤:1)初始化:将NFA的起始状态作为DFA的起始状态,并为其创建一个新的DFA状态。
2)闭包运算:对于DFA中的每个状态,根据NFA的ε-转换,计算其ε-闭包(即能够通过ε-转换到达的状态集合)。
3)转换运算:对于DFA中的每个状态和每个输入符号,根据NFA的转换函数,计算DFA中该输入下的状态转移集合。
4)如果新生成的DFA状态集合不在已有的DFA状态集合中,则将其加入到DFA状态集合中,并进行闭包和转换运算;如果已存在,则继续下一个输入符号的转换运算。
5)重复步骤4,直到不再生成新的DFA状态集合。
化简是指对于一个确定的有限自动机(DFA),将其中无用的状态进行合并,得到一个更加简洁的自动机。
化简的目的是减少状态数目,提高运行效率和存储效率。
化简的过程一般包括以下步骤:1)初始化:将DFA状态分为两个集合,一个是终止状态集合,一个是非终止状态集合。
2)将所有的等价状态划分到同一个等价类中。
3)不断迭代以下步骤,直到不能再划分等价类为止:a)对于每对不同的状态p和q,若存在一个输入符号a,通过转移函数计算得到的状态分别位于不同的等价类中,则将该状态划分到不同的等价类中。
b)对于每个等价类中的状态集合,将其进一步划分为更小的等价类。
最终,得到的化简DFA状态图比原始DFA状态图要小,且功能等价。
![[编译原理代码][NFA转DFA并最小化DFA并使用DFA进行词法分析]](https://uimg.taocdn.com/4706449103d276a20029bd64783e0912a2167c14.webp)
[编译原理代码][NFA转DFA并最⼩化DFA并使⽤DFA进⾏词法分析]#include <iostream>#include <vector>#include <cstring>#include "stack"#include "algorithm"using namespace std;int NFAStatusNum,AlphabetNum,StatusEdgeNum,AcceptStatusNum;char alphabet[1000];int accept[1000];int StartStatus;int isDFAok=1;int isDFA[1000][1000];/** NFA状态图的邻接表*/vector<vector<int>> Dstates;int Dstatesvisit[1000];int Dtran[1000][1000];vector<int> Dtranstart;vector<int> Dtranend;int isDtranstart[1000];int isDtranend[1000];class Edge{public:int to,w,next;} ;Edge edge[10000];int edgetot=0;int Graph[1000];void link(int u,int v,int w){edge[++edgetot].to=v;edge[edgetot].w=w;edge[edgetot].next=Graph[u];Graph[u]=edgetot;}void input(){int u,v,w;memset(Dtran,-1,sizeof(Dtran));scanf("%d %d %d %d\n",&NFAStatusNum,&AlphabetNum,&StatusEdgeNum,&AcceptStatusNum);for(int i=1;i<=AlphabetNum;i++){ //读⼊字母表scanf("%c",&alphabet[i]);}for(int i=1;i<=AcceptStatusNum;i++){scanf("%d",&accept[i]);}//开始状态序号scanf("%d",&StartStatus);for(int i=0;i<StatusEdgeNum;i++){scanf("%d%d%d\n",&u,&v,&w);link(u,v,w);if(isDFA[u][v]==0){isDFA[u][v]=1;}else{isDFAok=0;}if(w==0){isDFAok=0;}}//读⼊测试字符串}void e_clouser(vector<int> &T,vector<int> &ans){int visit[1000];memset(visit,0,sizeof(visit));stack<int> Stack;//T all push in Stack and copy to ansfor (int i=0;i < T.size();++i){Stack.push(T[i]);ans.push_back(T[i]);visit[T[i]]=1;while(Stack.empty()!=1){int t = Stack.top(); Stack.pop();for(int p=Graph[t];p!=0;p=edge[p].next){if(edge[p].w==0){if(visit[edge[p].to]==0){visit[edge[p].to]=1;Stack.push(edge[p].to);ans.push_back(edge[p].to);}}}}sort(ans.begin(),ans.end());}void move(vector<int> &T,int a,vector<int> &ans){ int visit[1000];memset(visit,0,sizeof(visit));for(int i=0;i<T.size();i++) {int t=T[i];for (int p = Graph[t]; p != 0; p = edge[p].next) { if (edge[p].w == a) {if (visit[edge[p].to] == 0) {visit[edge[p].to] = 1;ans.push_back(edge[p].to);}}}}}bool notin(vector<int> &a,int &U){for(int i=0;i<Dstates.size();i++){int ok=1;if(Dstates[i].size()==a.size()){for(int j=0;j<a.size();j++){if(Dstates[i][j]!=a[j]){ok=0;break;}}if(ok==1) {U=i;return false;}}}U=Dstates.size();return true;}void nfatodfa(){vector<int> s,t;s.push_back(StartStatus);e_clouser(s,t);Dstates.push_back(t);stack<int> Stack;Stack.push(Dstates.size()-1);while(Stack.empty()!=1){int T=Stack.top();Stack.pop();int U;for(int i=1;i<=AlphabetNum;i++){vector<int> ans,ans2;move(Dstates[T],i,ans2);e_clouser(ans2,ans);if(notin(ans,U)){Dstates.push_back(ans);Stack.push(Dstates.size()-1);}Dtran[T][i]=U;}}}void getDtranStartEnd(){for(int i=0;i<Dstates.size();i++){int ok=1;for(int j=0;j<Dstates[i].size();j++){if(Dstates[i][j]==StartStatus){Dtranstart.push_back(i);isDtranstart[i]=1;}for(int k=1;k<=AcceptStatusNum;k++){if(Dstates[i][j]==accept[k]){ok=0;Dtranend.push_back(i);isDtranend[i]=1;}}}}}}vector<vector<int>> newDstates;int newDstatesvisit[1000];int newDtran[1000][1000];int set[1000];vector<int> newDtranstart;vector<int> newDtranend;int isnewDtranstart[1000];int isnewDtranend[1000];void simple(){int visit[1000];memset(visit,0,sizeof(visit));vector<int> a,b;//接受结点加⼊afor(int i=0;i<Dtranend.size();i++){a.push_back(Dtranend[i]);visit[Dtranend[i]]=1;set[Dtranend[i]]=0;}//剩余结点加⼊bfor(int i=0;i<Dstates.size();i++){if(visit[i]==0){b.push_back(i);set[i]=1;}}newDstates.push_back(a);newDstates.push_back(b);while(1){int ok=0;for(int i=0;i<newDstates.size();i++){for (int k = 1; k <= AlphabetNum; k++) {for(int j=1;j<newDstates[i].size();j++) {int pp= Dtran[newDstates[i][0]][k];int u = newDstates[i][j], v = Dtran[u][k];if (set[v] != set[pp] ) {//将u剥离newDstates[i].erase(newDstates[i].begin() + j); vector<int> temp;temp.push_back(u);set[u] = newDstates.size();newDstates.push_back(temp);ok = 1;break;}if (ok == 1) break;}if(ok==1) break;}if(ok==1) break;}if(ok==0) break;}//isnewDtranstart,isnewDtranend,newDtranfor(int i=0;i<Dstates.size();i++) {for (int j = 1; j <= AlphabetNum; j++) {newDtran[set[i]][j]=set[Dtran[i][j]];}if(isDtranend[i]==1)isnewDtranend[set[i]]=1;if(isDtranstart[i]==1)isnewDtranstart[set[i]]=1;}//isnewDtranstart,isnewDtranend}bool dfa(char *S){int status=0;for(int i=0;i<newDstates.size();i++){if(isnewDtranstart[i]==1){status=i;}}for(int i=0;i<strlen(S);i++) {//这⾥我偷懒了,懒得弄个map存映射,直接对这个例⼦进⾏操作,就是 S[i]-'a'+1; int p=S[i]-'a'+1;status=newDtran[status][p];}if(isnewDtranend[status]==1) return true;else return false;}int main() {freopen("E:\\NFATODFA\\a.in","r",stdin);input();if(isDFAok==0){printf("This is NFA\n");nfatodfa();}else{printf("This is DNA\n");}//打印DFAprintf("\nPrint DFA's Dtran:\n");printf(" DFAstatu a b");getDtranStartEnd();for(int i=0;i<Dstates.size();i++){printf("\n");if(isDtranstart[i]==1)printf("start ");else if(isDtranend[i]==1)printf("end ");else printf(" ");printf("%5c ",i+'A');for(int j=1;j<=AlphabetNum;j++)printf("%5c ",Dtran[i][j]+'A');}printf("\nPrint simple DFA's Dtran:\n");simple();printf(" DFAstatu a b");for(int i=0;i<newDstates.size();i++){printf("\n");if(isnewDtranstart[i]==1)printf("start ");else if(isnewDtranend[i]==1)printf("end ");else printf(" ");printf("%5c ",i+'A');for(int j=1;j<=AlphabetNum;j++)printf("%5c ",newDtran[i][j]+'A');}printf("\n");char S[1000];while(scanf("%s\n",S)!=EOF){if(dfa(S)){printf("%s belongs to the DFA\n",S);}elseprintf("%s don't belong to the DFA\n",S);}return 0;}。



实验一:利用子集法构造DFA一.实验目的掌握将非确定有限自动机确定化的方法和过程。
二.实验要求、内容及步骤实验要求:1.输入一个NFA,输出一个接受同一正规集的DFA;2.采用C++语言,实现该算法;3.编制测试程序;4.调试程序。
实验步骤:1.输入一个NFA关系图;2.通过一个转换算法将NFA转换为DFA;3.显示DFA关系图。
三.实验设备计算机、Windows 操作系统、Visual C++ 程序集成环境。
四.实验原理1.NFA-DFA转换原理:从NFA的矩阵表示中可以看出,表项通常是一状态的集合,而在DFA的矩阵表示中,表项是一个状态,NFA到相应的DFA的构造的基本思路是:DFA的每一个状态对应NFA的一组状态。
DFA使用它的状态去记录在NFA读入一个输入符号后可能到达的所有状态。
输入:一个NFA N输出:一个接受同样语言的DFA D方法:为D构造转换表Dtran,DFA的每个状态是NFA的状态集。
D的状态集合用Dstates表示。
D的开始状态为ε-closure(s0),s0是N的开始状态。
使用下列算法构造D的状态集合Dstates和转换表Dtran。
如果D的某个状态是至少包含一个N的接受状态的NFA状态集,那么它是D的一个接受状态。
2.子集构造法:初始时, ε-closure(S0) 是Dstates中唯一的状态且未被标记;while Dstates中存在一个未标记的状态T do begin标记T;for 每个输入符号a do beginU := ε-closure ( move (T, a) );if U 没在Dstates中then将U作为一个未被标记的状态添加到 Dstates.Dtran [ T, a ] := Uendend3.ε-closure的计算:将T中所有状态压入栈stack;将ε-closure (T) 初始化为T;while stack不空 do begin将栈顶元素t弹出栈;for 每个这样的状态u:从t到u有一条标记为ε的边do if u不在ε-closure ( T )中 do begin将u 添加到ε-closure ( T );将u压入栈stack中 endend五.程序设计1.总体设计2.子程序设计识别模块读入字符识别模块识别标识符识别分界符、运算符识别常数输出六.程序中的结构说明1.结构体Symbolrecord 结构体结构体成员名 成员属性Symbol[10] 用于存储关键字编码名 id用于存储关键字对应的编码读取字符字母识别标识符数字识别数字/识别注释打印并结束FTFTFTentrytype结构体结构体成员名成员属性idname[10] 用于存储识别后标识符名address 用于存储标识符的地址type 用于存储标识符的类型digittype结构体结构体成员名成员属性num 用于存储识别后的数字address 用于存储标识符数字的地址tokentype结构体结构体成员名成员属性id 用于存储被识别的类型名entry 用于存储标识符的地址idname[10] 用于存储被识别的标识符名2.符号编码表符号编码表符号名代码符号名代码Begin 0 } 14End 1 ( 15If 2 ) 16 Then 3 < 17 Else 4 <= 18for 5 = 19do 6 != 20while 7 > 21+ 8 >= 22- 9 := 23* 10 ‘’24/ 11 Id 25; 12 Const 26{ 133.重要函数介绍tokentype recogid(char ch)//识别标识符算法tokentype recogdig(char ch) ///识别数字函数tokentype recogdel(char ch) //识别算符和界符函数tokentype handlecom(char ch) //handlecom函数,识别注释函数void sort(char ch) //sort函数,读取文件内容,并根据读入内容调用不同的识别函数void scanner()//scanner函数,打开文件七.函数代码#include <stdio.h>#include <string.h>#include <ctype.h>#include <stdlib.h>;-----------------------定义单词编码表的数据结构-------------------- struct symbolrecord{ char symbol[10];int id;} ;;-------------------------定义符号表的数据结构---------------------- struct entrytype{ char idname[10];int address;int type;};;-------------------------定义常数表的数据结构---------------------- struct digittype{ int num;int address;};;---------------------------Token字的数据结构----------------------- struct tokentype{ int id;int entry;char idname[10];};FILE *fp; //源文件指针struct digittype d[10]; //定义常数表,个数指针struct entrytype a[40];int k=0,t=0;;---------------------------单词编码表初始化------------------------ struct symbolrecord s[26]={ "Begin",0,"End",1,"If",2,"Then",3, "Else",4, "for",5, "do",6,"while",7, "+",8,"-",9,"*",10,"/",11,";",12,"{",13,"}",14,"(",15,")",16,"<",17,"<=",18, "=",19,"!=",20, ">",21,">=",22, ":=",23, " ",24,"const",26 };;---------------------------识别标识符算法-------------------------- tokentype recogid(char ch){ tokentype tokenid;FILE *fs;int flag,fflag;char word[10]={0};int i,j;i=0;while(isalpha(ch)||isdigit(ch)){ word[i]=ch;ch=fgetc(fp);i=i+1;}ungetc(ch,fp);word[i]='\0';for(j=0;j<=8;j++){ flag=strcmp(word, s[j].symbol);if(flag==0) //是关键字{ tokenid.id=j;tokenid.entry=-1;break;} }if(flag!=0){ for(j=0;j<=k;j++){ fflag=strcmp(a[j].idname,word);if(fflag==0) //在符号表中可以找到{ tokenid.id=25;tokenid.entry=a[j].address;break;} }if(fflag!=0){ fs=fopen("symbol.txt","a"); //符号表中不存在的标识符 strcpy(a[k].idname, word);a[k].address=k;a[k].type=25;tokenid.id=25;tokenid.entry=k;for(j=0;j<9;j++)fprintf(fs,"%c",word[j]);fprintf(fs,"%c",'\t');fprintf(fs,"%d",a[k].address);fprintf(fs,"%c",'\t');fprintf(fs,"%d",a[k].type);fprintf(fs,"%c",'\n');fclose(fs);k=k+1;} }strcpy(tokenid.idname, word);//自行添加的return tokenid;};-----------------------------识别数字函数-------------------------- tokentype recogdig(char ch){ int flag;int i=0,j;int num=0;tokentype tokenid;while(isdigit(ch)){ num=(ch-48)+num*10;ch=fgetc(fp);i=i+1;}for(j=0;j<=t;j++)if(d[j].num==num){ flag=1;tokenid.id=26;tokenid.entry=d[j].address;break;}if(flag!=1){ d[t].num=num;d[t].address=t;tokenid.id=26;tokenid.entry=t;t=t+1;}sprintf(tokenid.idname, "%d", num);//int>>charreturn tokenid;};------------------------识别算符和界符函数------------------------- tokentype recogdel(char ch){ tokentype tokenid;switch(ch){ case'{':{ tokenid.id=13;strcpy(tokenid.idname, "{");//自行添加的}break;case'}':{ tokenid.id=14;strcpy(tokenid.idname, "}");}break;case';':{ tokenid.id=12;strcpy(tokenid.idname, ";");}break;case'=':{ tokenid.id=19;strcpy(tokenid.idname, "=");}break;case':':ch=fgetc(fp);if(ch=='=') tokenid.id=23; break;case'!':{ ch=fgetc(fp);if(ch=='=') tokenid.id=20;strcpy(tokenid.idname, "!="); } break;case'<':{ch=fgetc(fp);if(ch=='='){ tokenid.id=18;strcpy(tokenid.idname, "<=");}else{ tokenid.id=17;strcpy(tokenid.idname, "<");ungetc(ch,fp);}}; break;case'>':ch=fgetc(fp);if(ch=='='){tokenid.id=22;strcpy(tokenid.idname, ">=");}else { tokenid.id=21;strcpy(tokenid.idname, ">");ungetc(ch,fp);}; break;case'+':{ tokenid.id=8;strcpy(tokenid.idname, "+");}break;case'*':{ tokenid.id=10;strcpy(tokenid.idname, "*");}break;case'(':{ tokenid.id=15;strcpy(tokenid.idname, "(");}break;case')':{ tokenid.id=16;strcpy(tokenid.idname, ")");}break;}tokenid.entry=-1;return tokenid;};---------------------------handlecom函数--------------------------- tokentype handlecom(char ch){ tokentype tokenid;char ch1;int flag=0;if(ch!='*' ){ tokenid.id=25;tokenid.entry=-1;}else{ while(flag==0){ ch1=ch;ch=fgetc(fp);if((ch1='*')&&(ch='/'))flag=1;}}return tokenid;};---------------------------sort函数---------------------------- void sort(char ch){struct tokentype tokenword;FILE * fq = fopen("tokenfile.txt","a");if(isalpha(ch))tokenword=recogid(ch); //字母else if(isdigit(ch))tokenword=recogdig(ch); //数字else if(ch=='/')tokenword=handlecom(ch);elsetokenword=recogdel(ch);printf("%s\t%d\t%d\n",tokenword.idname,tokenword.id,tokenword.entry) ;fprintf(fq,"%d",tokenword.id);fprintf(fq,"%c",'\t');fprintf(fq,"%d",tokenword.entry);fprintf(fq,"%c",'\n');fclose(fq);};--------------------------scanner函数---------------------------- void scanner(){ char ch;fp=fopen("source.txt","r");ch=getc(fp);while(ch!=EOF){ if(!isspace(ch)){ sort(ch);}ch=fgetc(fp);}fclose(fp);};------------------------------主函数------------------------------ int main(){ int i;printf("输出token字如下:\n");printf("idname\ttype\taddress\n");scanner();printf("************************************\n");printf("输出符号表如下:\n");printf("%s\t%s\t%s\n","idname","address","type");for(i=0;i<=k-1;i++)printf("%s\t%d\t%d\n",a[i].idname,a[i].address,a[i].type);printf("************************************\n"); printf("输出常数表如下:\n");printf("%s\t%s\n","num","address");for(i=0;i<=t-1;i++)printf("%d\t%d\n",d[i].num,d[i].address);printf("\n\n");system("pause");}八.程序测试Source源文件程序截图main(){If a!=35end;do whileend;36}九.实验小结子集构造法的基本思想是构造得到的DFA的每个状态对应于NFA的一个状态集合。
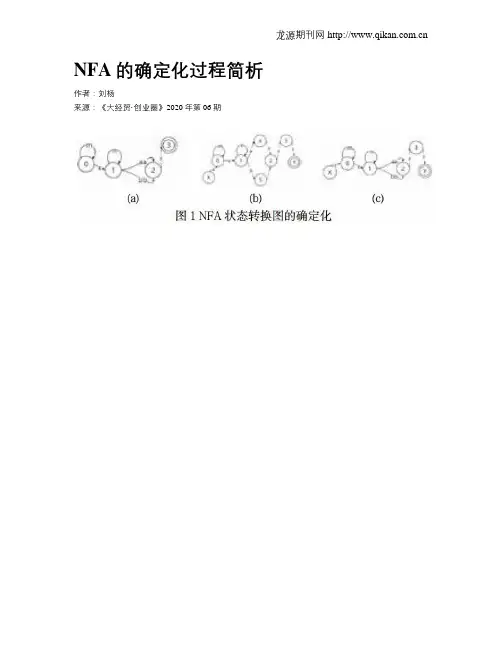
NFA的确定化过程简析作者:刘杨来源:《大经贸·创业圈》2020年第06期【摘要】在编译原理的学习中,从上下文无关文法的初步理解进阶到词法分析过程,是理解整个编译过程的关键一步;其中,确定性有限自动机(DFA)和非确定性有限自动机(NFA)的等价与转换,是这一部分的难点之一。
本文将首先介绍DFA和NFA相关的几个基本概念,然后着重介绍确定性有限自动机(DFA)和非确定性有限自动机(NFA)的等价变化过程。
【关键词】编译原理词法分析 DFA NFA 有限自动机一、基本概念(一)正规集和正规式所谓正规集,就是一个集合,是一个字符的集合。
正规指的就是,该集合中的字符,对于我们所研究的程序设计语言来说,是合法的。
正规式则是正规集的另一种表示方式。
或者说,在研究编译原理的过程中,用正规式来表示正规集。
二者的对应关系可以参考如下示例:设有字母表Σ,则Σ上的字符a和b都是正规式,它们分别表示Σ上的正规集{a}和{b}。
词法分析中的等价关系判定的充要条件,就是:被研究的两个对象,其所表示的正規式是否相同。
(二)DFA和NFA首先,FA(finite automaton),有限自动机,本质上就是状态转换图(表示词法分析器逐个识别输入字符并进行状态转换的过程)。
一个有限自动机由一个五元式组成:S:有穷状态集;Σ:有穷输入字母表;f:状态转换函数;S0:初始状态;F:终态有限自动机中的状态转换函数是其精髓所在。
状态转换函数将词法分析器的状态转换过程抽象为一个双输入单输出的函数,而这样的函数很容易使用矩阵来表示,从而使词法分析器的工作过程得以数字化,进而可以使用代码来实现。
DFA(deterministic finite automaton),确定的有限自动机;NFA(Nondeterministic finite automaton),非确定的有限自动机。
二者的区别主要有三点:DFA的初始状态是唯一的,但NFA的初始状态可以不唯一(注意,DFA和NFA的终态结点都可以不唯一);DFA中,每个状态的输入只能是单个字符,且不包括ε(空字符);但是在NFA中,可以是一个字或者单个字符或者ε;DFA中,每个状态接收输入后的转换关系是一定的,但是在这一转换关系NFA中不是确定的。


编译原理实验报告实验名称不确定有限状态自动机的确定化实验时间院系计算机科学与技术学院班级学号姓名1.试验目的输入:非确定有限(穷)状态自动机。
输出:确定化的有限(穷)状态自动机2.实验原理一个确定的有限自动机(DFA)M可以定义为一个五元组,M=(K,∑,F,S,Z),其中:(1)K是一个有穷非空集,集合中的每个元素称为一个状态;(2)∑是一个有穷字母表,∑中的每个元素称为一个输入符号;(3)F是一个从K×∑→K的单值转换函数,即F(R,a)=Q,(R,Q∈K)表示当前状态为R,如果输入字符a,则转到状态Q,状态Q称为状态R的后继状态;(4)S∈K,是惟一的初态;(5)Z⊆K,是一个终态集。
由定义可见,确定有限自动机只有惟一的一个初态,但可以有多个终态,每个状态对字母表中的任一输入符号,最多只有一个后继状态。
对于DFA M,若存在一条从某个初态结点到某一个终态结点的通路,则称这条通路上的所有弧的标记符连接形成的字符串可为DFA M所接受。
若M的初态结点同时又是终态结点,则称ε可为M所接受(或识别),DFA M所能接受的全部字符串(字)组成的集合记作L(M)。
一个不确定有限自动机(NFA)M可以定义为一个五元组,M=(K,∑,F,S,Z),其中:(1)k是一个有穷非空集,集合中的每个元素称为一个状态;(2)∑是一个有穷字母表,∑中的每个元素称为一个输入符号;(3)F是一个从K×∑→K的子集的转换函数;(4)S⊆K,是一个非空的初态集;(5)Z⊆K,是一个终态集。
由定义可见,不确定有限自动机NFA与确定有限自动机DFA的主要区别是:(1)NFA的初始状态S为一个状态集,即允许有多个初始状态;(2)NFA中允许状态在某输出边上有相同的符号,即对同一个输入符号可以有多个后继状态。
即DFA中的F是单值函数,而NFA中的F是多值函数。
因此,可以将确定有限自动机DFA看作是不确定有限自动机NFA的特例。
编译原理课程实践报告设计名称:NFA转化为DFA的转换算法及实现二级学院:数学与计算机科学学院专业:计算机科学与技术班级:计科本091班*名:***学号: ********** 指导老师:***日期: 2012年6月摘要确定有限自动机确定的含义是在某种状态,面临一个特定的符号只有一个转换,进入唯一的一个状态。
不确定的有限自动机则相反,在某种状态下,面临一个特定的符号是存在不止一个转换,即是可以允许进入一个状态集合。
在非确定的有限自动机NFA中,由于某些状态的转移需从若干个可能的后续状态中进行选择,故一个NFA对符号串的识别就必然是一个试探的过程。
这种不确定性给识别过程带来的反复,无疑会影响到FA的工作效率。
而DFA则是确定的,将NFA转化为DFA将大大提高工作效率,因此将NFA转化为DFA是有其一定必要的。
对于任意的一个不确定有限自动机(NFA)都会存在一个等价的确定的有限自动机(DFA),即L(N)=L(M)。
本文主要是介绍如何将NFA转换为与之等价的简化的DFA,通过具体实例,结合图形,详细说明转换的算法原理。
关键词:有限自动机;确定有限自动机(DFA),不确定有限自动机(NFA)AbstractFinite automata is determinate and indeterminate two class. Determine the meaning is in a certain state, faces a particular symbol only one conversion, enter only one state. Not deterministic finite automata is the opposite, in a certain state, faces a particular symbol is the presence of more than one conversion, that is to be allowed to enter a state set.Non deterministic finite state automata NFA, because of some state are transferred from a number of possible follow-up state are chosen, so a NFA symbol string recognition must be a trial process. This uncertainty to the recognition process brought about by repeated, will undoubtedly affect the efficiency of the FA. While the DFA is determined, converting NFA to DFA will greatly improve the working efficiency, thus converting NFA to DFA is its necessary.For any a nondeterministic finite automaton ( NFA ) can be an equivalent deterministic finite automaton ( DFA ), L ( N ) =L ( M ). This paper mainly introduces how to convert NFA to equivalent simplified DFA, through concrete examples, combined with graphics, a detailed description of the algorithm principle of conversion.Keywords::finite automata; deterministic finite automaton ( DFA ), nondeterministic finite automaton ( NFA目录1.前言: (1)1.1背景 (1)1.2实践目的 (1)1.2课程实践的意义 (1)2.NFA和DFA的概念 (2)2.1 不确定有限自动机NFA (2)2.2确定有限自动机DFA (3)3.从NDF到DFA的等价变化步骤 (5)3.1转换思路 (5)3.2.消除空转移 (5)3.3子集构造法 (7)4程序实现 (9)4.1程序框架图 (9)4.2 数据流程图 (9)4.3实现代码 (10)4.4运行环境 (10)4.5程序实现结果 (10)5.用户手册 (12)6.课程总结: (12)7.参考文献 (12)8. 附录 (13)1.前言:1.1背景有限自动机作为一种识别装置,它能准确地识别正规集,即识别正规文法所定义的语言和正规式所表示的集合,引入有穷自动机这个理论,正是为词法分析程序的自动构造寻找特殊的方法和工具。
编译原理实验报告实验三安徽大学计算机科学与技术学院1,实验名称不确定有穷自动机的确定化。
2,实验目的不确定有穷自动机的确定化。
3,实验原理1.NFA:一个不确定的有穷自动机M是一个五元组,M=(K,E,f,S,Z)其中a. K是一个有穷集,它的每个元素称为一个状态;b. E是一个有穷字母表,它的每个元素称为一个输入符号;c. f是一个从K×E*到K的子集的映像,即:K*E*->2k,其中2k表示K的幂集;d. S包含于K,是一个非空初态集;e. Z包含于K,是一个终态集。
2.DFA:一个确定的有穷自动机M是一个五元组,M=(K,E,f,S,Z)其中a. K是一个有穷集,它的每个元素称为一个状态;b. E是一个有穷字母表,它的每个元素称为一个输入符号;c. f是转换函数,是K×E->K上的映像,即,如f(ki,a)=kj(ki∈K,kj∈K)就意味着,当前状态为ki,输入字符为a时,将转换到下一状态kj,我们把kj称作ki的一个后继状态;d. S∈K,是唯一的一个初态;e. Z包含于K,是一个终态集,终态也称可接受状态或结束状态。
3,正规式正规式是一种表示正规集的工具,正规式是描述程序语言单词的表达式,对于字母表∑其上的正规式及其表示的正规集可以递归定义如下。
①ε是一个正规式,它表示集合L(ε)={ε}。
②若a是∑上的字符,则a是一个正规式,它所表示的正规集L(a)={a}。
③若正规式r和s分别表示正规集L(r)、L(s),则(a)r|s是正规式,表示集合L(r)∪L(s);(b)r·s是正规式,表示集合L(r)L(s);(c)r*是正规式,表示集合(L(r))*;(d)(r)是正规式,表示集合L(r)。
仅由有限次地使用上述三个步骤定义的表达式才是∑上的正规式。
运算符“|”、“·”、“*”分别称为“或”、“连接”和“闭包”。
在正规式的书写中,连接运算符“·”可省略。