结构设计常用数据表
- 格式:pdf
- 大小:1.28 MB
- 文档页数:1

标题:如何制作高效的Excel每日数据汇总表模板在日常工作中,我们经常需要对各种数据进行汇总和分析,而Excel 表格是一个非常常用的工具。
但是,每天手动创建数据汇总表格非常耗时,为了提高工作效率,我们可以制作一个高效的Excel每日数据汇总表模板。
下面将介绍如何制作这样的模板。
一、设计表格结构1. 确定需要汇总的数据在设计每日数据汇总表模板时,首先需要确定需要汇总的数据内容,例如销售额、成本、利润等。
根据实际工作需要,确定需要包括哪些字段。
2. 设置表头在Excel中,表头是非常重要的部分,可以使数据更加清晰明了。
在设计表头时,应该考虑到后续数据的筛选和排序功能,同时也要保证表头的简洁明了。
3. 设计数据输入区域在每日数据汇总表模板中,需要设置数据输入区域,用于输入每日的具体数据。
在设计数据输入区域时,可以根据实际情况设置公式,以减少手工计算的工作量。
二、设置数据汇总公式1. 使用SUM函数进行数据汇总在每日数据汇总表模板中,通常需要对各项数据进行汇总,例如计算每日销售额的总和、成本的总和、利润的总和等。
可以使用Excel的SUM函数快速实现这些计算。
2. 使用VLOOKUP函数进行数据查询在数据汇总表模板中,可能需要根据某些条件进行数据查询,例如根据产品名称查询对应的销售额,这时可以使用Excel的VLOOKUP函数实现快速的数据查询。
3. 设置数据自动更新为了保证每日数据汇总表模板的准确性,可以设置数据自动更新的功能。
可以使用Excel的数据透视表功能,实现数据的动态更新和分析。
三、美化表格格式1. 使用颜色和边框为了使每日数据汇总表模板更加美观,可以使用颜色和边框进行装饰。
也可以根据不同数据的大小,设置不同的颜色和格式,以便更直观地反映数据情况。
2. 设置条件格式在Excel中,可以使用条件格式功能,根据数据的大小、范围等条件,自动设置单元格的格式。
这样可以帮助用户更快速地发现数据中的规律和异常。

目录1 选题背景 (1)2 方案与论证 (1)2。
1 链表的概念和作用 (1)2。
3 算法的设计思想 (2)2。
4 相关图例 (3)2.4.1 单链表的结点结构 (3)2.4。
2 算法流程图 (3)3 实验结果 (4)3.1 链表的建立 (4)3.2 单链表的插入 (4)3.3 单链表的输出 (5)3.4 查找元素 (5)3。
5 单链表的删除 (5)3。
6 显示链表中的元素个数(计数) (5)4 结果分析 (6)4。
1 单链表的结构 (6)4。
2 单链表的操作特点 (6)4。
2。
1 顺链操作技术 (6)4.2。
2 指针保留技术 (6)4。
3 链表处理中的相关技术 (6)5 设计体会及今后的改进意见 (6)参考文献 (8)附录代码: (8)1 选题背景陈火旺院士把计算机60多年的发展成就概括为五个“一”:开辟一个新时代-—--信息时代,形成一个新产业-—-—信息产业,产生一个新科学—---计算机科学与技术,开创一种新的科研方法-—--计算方法,开辟一种新文化---—计算机文化,这一概括深刻影响了计算机对社会发展所产生的广泛而深远的影响。
数据结构和算法是计算机求解问题过程的两大基石。
著名的计算机科学家P.Wegner指出,“在工业革命中其核心作用的是能量,而在计算机革命中其核心作用的是信息”.计算机科学就是“一种关于信息结构转换的科学”.信息结构(数据结构)是计算机科学研究的基本课题,数据结构又是算法研究的基础。
2 方案与论证2。
1 链表的概念和作用链表是一种链式存储结构,链表属于线性表,采用链式存储结构,也是常用的动态存储方法。
链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) + 指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
以“结点的序列”表示线性表称作线性链表(单链表)单链表是链式存取的结构,为找第 i 个数据元素,必须先找到第 i-1 个数据元素。

Caxa 数据库表结构的设计是数据库开发中非常重要的一部分,它直接影响着数据库的性能、数据存储和查询效率。
在SQLServer 数据库中,设计合理的表结构可以提高数据的管理和操作效率,减少存储空间的浪费,并且有利于系统的维护和升级。
下面我们将对 Caxa 数据库表结构的设计原则、常用数据类型、索引选取和数据表优化等方面进行详细的介绍。
一、Caxa 数据库表结构设计原则1. 合理性和规范性:表的设计必须符合数据库标准化设计的原则,保证每一个数据字段都具有清晰明确的含义,表与表之间的关联关系要清晰明了。
2. 紧凑性和完整性:避免过度冗余和不必要的数据重复,确保数据的完整性和准确性。
3. 拓展性和易维护性:数据库表结构在设计之初要具备一定的拓展性,能够满足未来业务的发展需要,并且易于维护和扩展。
4. 效率和性能:数据库表结构设计要考虑到数据库的查询效率、数据的存储性能和系统的稳定性,尽量减少数据的冗余和重复存储,提高数据的访问效率。
二、Caxa 数据库常用数据类型1. int:整数类型,用于存储整数数据。
2. varchar:可变长度字符串类型,用于存储可变长度的字符数据。
3. datetime:日期时间类型,用于存储日期和时间数据。
4. float:浮点数类型,用于存储浮点数数据。
5. decimal:精确数值类型,用于存储精确的数值数据。
三、Caxa 数据库索引选取1. 主键索引:每个表只能有一个主键索引,用于唯一标识每一行数据,通常选择表的主键字段作为主键索引。
2. 唯一索引:用于保证某一列的数值唯一,可以加快数据的唯一性约束和加速查询。
3. 聚集索引:按照每一行的物理顺序在磁盘上存放,适用于频繁范围查找或排序的列。
4. 非聚集索引:按照逻辑顺序在索引中存放,适用于频繁单值查询的列。
四、Caxa 数据表优化1. 数据分解:将大的数据表拆分成多个小的数据表,提高数据的查询效率和维护性。
2. 数据压缩:对于大量的历史数据可以进行数据压缩,减少数据占用的存储空间。

架构设计之数据架构数据架构是指在软件系统中,对数据进行组织、存储、管理和访问的结构和规范。
一个良好的数据架构设计能够提高系统的性能、可靠性和可扩展性。
在本文中,将介绍数据架构的基本概念、设计原则和常用技术,以及一个示例数据架构设计的详细说明。
一、数据架构的基本概念1. 数据模型:数据模型是对现实世界中的实体和关系进行抽象和描述的方法。
常用的数据模型有层次模型、网络模型、关系模型和对象模型等。
2. 数据库管理系统(DBMS):DBMS是负责管理和操作数据库的软件系统。
它提供了数据存储、数据访问、数据安全和数据一致性等功能。
3. 数据库:数据库是指存储在物理介质上的数据集合。
它按照一定的数据模型进行组织和管理,可以被DBMS管理和访问。
4. 数据库实例:数据库实例是指在内存中加载数据库,并提供对数据库的访问和操作的运行时环境。
5. 数据库表:数据库表是数据在数据库中的组织形式,由行和列组成。
每一行表示一个记录,每一列表示一个属性。
6. 数据库索引:数据库索引是一种提高数据检索速度的数据结构。
它通过建立索引键和数据之间的映射关系,加快数据的查找和访问速度。
二、数据架构的设计原则1. 数据一致性:数据架构应该保证数据的一致性,即数据在不同的地方和时间访问时,保持一致的值和状态。
2. 数据完整性:数据架构应该保证数据的完整性,即数据的约束条件和业务规则得到满足,不会浮现错误或者不一致的数据。
3. 数据安全性:数据架构应该保证数据的安全性,即数据只能被授权的用户访问和修改,防止未经授权的访问和恶意操作。
4. 数据可扩展性:数据架构应该具备良好的可扩展性,能够适应系统的增长和变化,保持系统的性能和可靠性。
5. 数据性能:数据架构应该优化数据的访问和操作性能,提高系统的响应速度和吞吐量。
三、常用的数据架构技术1. 分布式架构:分布式架构将数据分布在多个节点上,通过网络进行通信和协作,提高系统的可扩展性和性能。
常用的分布式架构有主从架构、集群架构和分布式数据库等。


数据库设计中常见表结构分析⼀、树型关系的数据表不少程序员在进⾏数据库设计的时候都遇到过树型关系的数据,例如常见的类别表,即⼀个⼤类,下⾯有若⼲个⼦类,某些⼦类⼜有⼦类这样的情况。
当类别不确定,⽤户希望可以在任意类别下添加新的⼦类,或者删除某个类别和其下的所有⼦类,⽽且预计以后其数量会逐步增长,此时我们就会考虑⽤⼀个数据表来保存这些数据。
设计结构:名称类型约束条件说明type_id int⽆重复类别标识,主键type_name char(50)不允许为空类型名称,不允许重复type_father int不允许为空该类别的⽗类别标识,如果是顶节点的话设定为某个唯⼀值type_layer char(6)限定3层,初始值为000000类别的先序遍历,主要为减少检索数据库的次数这样设计的好处就是遍历⽅便,只需要⼀个检索即可,通过设置type_layer即可设定遍历顺序,000000为3层,若要求多则可增加,每⼀层允许最多99个⼦类。
010101表⽰为第三层。
检索过程:SELECT * FROM Type_table_2 ORDER BY type_layer列出记录集如下:type_id type_name type_father type_layer1 总类别 0 0000002 类别1 1 0100003 类别1.1 2 0101004 类别1.2 2 0102005 类别2 1 0200006 类别2.1 5 0201007 类别3 1 0300008 类别3.1 7 0301009 类别3.2 7 03020010 类别1.1.1 3 010101…… ⼆、商品信息表的设计(如何使数据表的属性可扩展)假设你是⼀家百货公司电脑部的开发⼈员,某天⽼板要求你为公司开发⼀套⽹上电⼦商务平台,该百货公司有数千种商品出售,不过⽬前仅打算先在⽹上销售数⼗种⽅便运输的商品,当然,以后可能会陆续在该电⼦商务平台上增加新的商品出售。

业务系统数据表设计方法随着信息技术的发展,业务系统在企业中的应用越来越广泛。
而业务系统的核心组成部分之一就是数据表。
良好的数据表设计可以提高系统的性能、可维护性和扩展性。
本文将介绍一些常用的业务系统数据表设计方法。
一、确定数据表的目标和范围在设计数据表之前,首先需要明确数据表的目标和范围。
例如,确定数据表所要存储的数据类型、数据量和访问方式等。
这些信息将有助于确定数据表的结构和索引设计。
二、选择适当的数据类型在设计数据表时,选择适当的数据类型是非常重要的。
不同的数据类型有不同的存储要求和性能特征。
常用的数据类型包括整数、浮点数、日期时间、字符和二进制等。
根据实际需求选择最合适的数据类型,可以提高系统的性能和存储效率。
三、规范命名和命名约定良好的命名规范可以提高数据表的可读性和可维护性。
在命名数据表和字段时,应遵循一定的命名约定,例如使用有意义的名称、使用小写字母和下划线分隔单词等。
此外,还应避免使用保留字和特殊字符,以免引起命名冲突和语法错误。
四、设计数据表的结构数据表的结构是指数据表中字段的定义和关系。
在设计数据表结构时,应遵循一些基本原则,例如将数据表拆分成合理的独立实体、避免数据冗余和数据丢失、保证数据表的一致性和完整性等。
此外,还应合理设计字段的属性,包括字段长度、是否允许为空、默认值和唯一约束等。
五、建立适当的索引索引是提高数据表查询性能的重要手段。
在设计数据表时,应根据查询需求建立适当的索引。
常用的索引包括主键索引、唯一索引和普通索引等。
合理的索引设计可以加快查询速度,减少系统资源的消耗。
六、考虑数据表的扩展性和可维护性随着业务的发展,数据量和需求可能会不断增加。
因此,在设计数据表时应考虑数据表的扩展性和可维护性。
例如,可以通过分区、分表和分库等方式来提高系统的扩展性。
此外,还应合理设置字段的默认值和约束条件,以保证数据的完整性和一致性。
七、进行数据表的优化和调整数据表设计完成后,还需要进行优化和调整。

常见电商项⽬的数据库表设计(MySQL版)转⾃:https:///developer/article/1164332简介:⽬的:电商常⽤功能模块的数据库设计常见问题的数据库解决⽅案环境:MySQL5.7图形客户端,SQLyogLinux模块:⽤户:注册、登陆商品:浏览、管理订单:⽣成、管理仓配:库存、管理电商实例数据库结构设计电商项⽬⽤户模块⽤户表涉及的实体改进1:第三范式:将依赖传递的列分离出来。
⽐如:登录名<-⽤户级别<-级别积分上限,级别积分下限改进2:尽量做到冷热数据的分离,减⼩表的宽度⽤户登录表(customer_login)CREATE TABLE customer_login(customer_id INT UNSIGNED AUTO_INCREMENT NOT NULL COMMENT '⽤户ID',login_name VARCHAR(20) NOT NULL COMMENT '⽤户登录名',password CHAR(32) NOT NULL COMMENT 'md5加密的密码',user_stats TINYINT NOT NULL DEFAULT 1 COMMENT '⽤户状态',modified_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间', PRIMARY KEY pk_customerid(customer_id)) ENGINE = innodb COMMENT '⽤户登录表'⽤户信息表(customer_inf)CREATE TABLE customer_inf(customer_inf_id INT UNSIGNED AUTO_INCREMENT NOT NULL COMMENT '⾃增主键ID',customer_id INT UNSIGNED NOT NULL COMMENT 'customer_login表的⾃增ID',customer_name VARCHAR(20) NOT NULL COMMENT '⽤户真实姓名',identity_card_type TINYINT NOT NULL DEFAULT 1 COMMENT '证件类型:1 ⾝份证,2 军官证,3 护照',identity_card_no VARCHAR(20) COMMENT '证件号码',mobile_phone INT UNSIGNED COMMENT '⼿机号',customer_email VARCHAR(50) COMMENT '邮箱',gender CHAR(1) COMMENT '性别',user_point INT NOT NULL DEFAULT 0 COMMENT '⽤户积分',register_time TIMESTAMP NOT NULL COMMENT '注册时间',birthday DATETIME COMMENT '会员⽣⽇',customer_level TINYINT NOT NULL DEFAULT 1 COMMENT '会员级别:1 普通会员,2 青铜,3⽩银,4黄⾦,5钻⽯',user_money DECIMAL(8,2) NOT NULL DEFAULT 0.00 COMMENT '⽤户余额',modified_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间', PRIMARY KEY pk_customerinfid(customer_inf_id)) ENGINE = innodb COMMENT '⽤户信息表';⽤户级别表(customerlevelinf)CREATE TABLE customer_level_inf(customer_level TINYINT NOT NULL AUTO_INCREMENT COMMENT '会员级别ID',level_name VARCHAR(10) NOT NULL COMMENT '会员级别名称',min_point INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '该级别最低积分',max_point INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '该级别最⾼积分',modified_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间', PRIMARY KEY pk_levelid(customer_level)) ENGINE = innodb COMMENT '⽤户级别信息表';⽤户地址表(customer_addr)CREATE TABLE customer_addr(customer_addr_id INT UNSIGNED AUTO_INCREMENT NOT NULL COMMENT '⾃增主键ID',customer_id INT UNSIGNED NOT NULL COMMENT 'customer_login表的⾃增ID',zip SMALLINT NOT NULL COMMENT '邮编',province SMALLINT NOT NULL COMMENT '地区表中省份的ID',city SMALLINT NOT NULL COMMENT '地区表中城市的ID',district SMALLINT NOT NULL COMMENT '地区表中的区ID',address VARCHAR(200) NOT NULL COMMENT '具体的地址门牌号',is_default TINYINT NOT NULL COMMENT '是否默认',modified_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间', PRIMARY KEY pk_customeraddid(customer_addr_id)) ENGINE = innodb COMMENT '⽤户地址表';⽤户积分⽇志表(customerpointlog)CREATE TABLE customer_point_log(point_id INT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '积分⽇志ID',customer_id INT UNSIGNED NOT NULL COMMENT '⽤户ID',source TINYINT UNSIGNED NOT NULL COMMENT '积分来源:0订单,1登陆,2活动',refer_number INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '积分来源相关编号',change_point SMALLINT NOT NULL DEFAULT 0 COMMENT '变更积分数',create_time TIMESTAMP NOT NULL COMMENT '积分⽇志⽣成时间',PRIMARY KEY pk_pointid(point_id)) ENGINE = innodb COMMENT '⽤户积分⽇志表';⽤户余额变动表(customerbalancelog)CREATE TABLE customer_balance_log(balance_id INT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '余额⽇志ID',customer_id INT UNSIGNED NOT NULL COMMENT '⽤户ID',source TINYINT UNSIGNED NOT NULL DEFAULT 1 COMMENT '记录来源:1订单,2退货单',source_sn INT UNSIGNED NOT NULL COMMENT '相关单据ID',create_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录⽣成时间',amount DECIMAL(8,2) NOT NULL DEFAULT 0.00 COMMENT '变动⾦额',PRIMARY KEY pk_balanceid(balance_id)) ENGINE = innodb COMMENT '⽤户余额变动表';⽤户登陆⽇志表(customerloginlog)CREATE TABLE customer_login_log(login_id INT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '登陆⽇志ID',customer_id INT UNSIGNED NOT NULL COMMENT '登陆⽤户ID',login_time TIMESTAMP NOT NULL COMMENT '⽤户登陆时间',login_ip INT UNSIGNED NOT NULL COMMENT '登陆IP',login_type TINYINT NOT NULL COMMENT '登陆类型:0未成功,1成功',PRIMARY KEY pk_loginid(login_id)) ENGINE = innodb COMMENT '⽤户登陆⽇志表';Hash分区表分区表特点:逻辑上为⼀个表,在物理上存储在多个⽂件中CREATE TABLE customer_login_log(login_id INT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '登陆⽇志ID',customer_id INT UNSIGNED NOT NULL COMMENT '登陆⽤户ID',login_time TIMESTAMP NOT NULL COMMENT '⽤户登陆时间',login_ip INT UNSIGNED NOT NULL COMMENT '登陆IP',login_type TINYINT NOT NULL COMMENT '登陆类型:0未成功,1成功',PRIMARY KEY pk_loginid(login_id)) ENGINE = innodb COMMENT '⽤户登陆⽇志表'PARTITION BY HASH(customer_id) PARTITIONS 4;区别就在于加了PARTITION这个命令。

目录1 选题背景 (2)2 方案与论证 (3)2.1 链表的概念和作用 (3)2.3 算法的设计思想 (4)2.4 相关图例 (5)2.4.1 单链表的结点结构 (5)2.4.2 算法流程图 (5)3 实验结果 (6)3.1 链表的建立 (6)3.2 单链表的插入 (6)3.3 单链表的输出 (7)3.4 查找元素 (7)3.5 单链表的删除 (8)3.6 显示链表中的元素个数(计数) (9)4 结果分析 (10)4.1 单链表的结构 (10)4.2 单链表的操作特点 (10)4.2.1 顺链操作技术 (10)4.2.2 指针保留技术 (10)4.3 链表处理中的相关技术 (10)5 设计体会及今后的改进意见 (11)参考文献 (12)附录代码: (13)1 选题背景陈火旺院士把计算机60多年的发展成就概括为五个“一”:开辟一个新时代----信息时代,形成一个新产业----信息产业,产生一个新科学----计算机科学与技术,开创一种新的科研方法----计算方法,开辟一种新文化----计算机文化,这一概括深刻影响了计算机对社会发展所产生的广泛而深远的影响。
数据结构和算法是计算机求解问题过程的两大基石。
著名的计算机科学家P.Wegner指出,“在工业革命中其核心作用的是能量,而在计算机革命中其核心作用的是信息”。
计算机科学就是“一种关于信息结构转换的科学”。
信息结构(数据结构)是计算机科学研究的基本课题,数据结构又是算法研究的基础。
2 方案与论证2.1 链表的概念和作用链表是一种链式存储结构,链表属于线性表,采用链式存储结构,也是常用的动态存储方法。
链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) + 指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
以“结点的序列”表示线性表称作线性链表(单链表)单链表是链式存取的结构,为找第 i 个数据元素,必须先找到第 i-1 个数据元素。
实验报告三线表在科学研究和实验中,实验报告是对实验过程和结果的详细描述和总结。
而三线表则是实验报告中常用的一种形式,用于清晰地呈现实验数据和相关信息。
本文将围绕实验报告三线表展开讨论,并探讨其作用、结构和如何撰写。
一、什么是实验报告三线表是科学实验报告中常用的一种表格形式,通过横线将标题、表头和表体分隔开,以清晰地呈现实验数据和相关信息。
它可以用于呈现实验数据的统计结果、实验条件的变化、实验组与对照组之间的差异、实验结果的趋势等内容。
二、实验报告三线表的结构1. 标题栏:标题栏通常位于三线表的顶端,用于简洁明了地描述表格内容。
标题一般应具备准确性、简洁性和醒目性,方便读者迅速了解表格的主题。
2. 表头:表头位于标题栏下方,用于标明每一列所代表的数据意义。
表头需要简洁明了,能够清晰表达数据的含义,有助于读者理解表格内容和数据结果。
3. 表体:表体是表格的主体部分,用于展示实验数据和相关信息。
表格的行数和列数应根据实验数据的复杂程度进行设置,并合理安排数据排列的顺序,便于读者对数据进行查找和比较。
三、如何撰写1. 数据准备:在撰写实验报告三线表之前,需先进行实验并获得相关数据。
在实验过程中,应注意准确记录每次实验的数据和实验条件,并进行数据分析和验证,以确保数据的准确性和可靠性。
2. 表格设计:在设计实验报告三线表时,需要考虑表头的分类、数据排列的顺序和表格的分组等因素。
表头的分类应符合逻辑,方便读者理解和分析数据。
数据排列的顺序可以按照时间、大小、组别等进行设置,以呈现最有利于数据分析和对比的形式。
3. 数据填充:在填充实验报告三线表时,应遵循数据的真实性和完整性原则。
不可随意填写或遗漏数据,需通过仔细核对实验记录和数据计算结果,确保数据的准确性。
4. 数据分析:实验报告三线表的价值在于呈现实验数据和分析结果。
在描述实验结果时,应清晰地呈现数据的趋势和差异,并结合实验目的和设定,进行合理的数据解读和分析。
结构设计常用数据表格结构设计常用数据表格1.项目信息表---- 字段名 ---- 类型 ---- 说明 ---- ---- --------- ---- ------- ---- -------------- ---- ---- 项目名称 ---- 字符串 ---- 项目的名称 ---- ---- 项目编号 ---- 字符串 ---- 项目的编号 ---- ---- 项目负责人---- 字符串 ---- 项目负责人姓名 ---- ---- 项目描述 ---- 字符串 ---- 项目的描述信息 ---- ---- 开始日期 ---- 日期 ---- 项目开始的日期 ---- ---- 结束日期 ---- 日期 ---- 项目预计结束日期 ----2.构件信息表---- 字段名 ---- 类型 ---- 说明 -------- ---------- ---- ------- ---- ---------------- -------- 构件名称 ---- 字符串 ---- 构件的名称 -------- 构件编号 ---- 字符串 ---- 构件的编号 -------- 构件负责人 ---- 字符串 ---- 构件负责人姓名 -------- 所属项目 ---- 字符串 ---- 构件所属的项目 -------- 构件类型 ---- 字符串 ---- 构件的类型 -------- 材料 ---- 字符串 ---- 构件的材料 -------- 重量 ---- 浮点数 ---- 构件的重量 -------- 尺寸 ---- 字符串 ---- 构件的尺寸 ----3.结构分析表---- 字段名 ---- 类型 ---- 说明 ----------- 构件名称 ---- 字符串 ---- 构件的名称 -------- 所属项目 ---- 字符串 ---- 构件所属的项目 -------- 荷载类型 ---- 字符串 ---- 荷载的类型 -------- 荷载大小 ---- 浮点数 ---- 荷载的大小 -------- 最大应力 ---- 浮点数 ---- 构件的最大应力 -------- 安全系数 ---- 浮点数 ---- 构件的安全系数 -------- 变形量 ---- 浮点数 ---- 构件的变形量 ----4.结构设计细节表---- 字段名 ---- 类型 ---- 说明 ----------- 构件名称 ---- 字符串 ---- 构件的名称 -------- 所属项目 ---- 字符串 ---- 构件所属的项目 -------- 设计参数 ---- 字符串 ---- 结构设计的参数 -------- 设计结果 ---- 字符串 ---- 结构设计的结果 -------- 材料选择 ---- 字符串 ---- 材料的选择 -------- 施工方法 ---- 字符串 ---- 施工方法 ----5.进度表---- 字段名 ---- 类型 ---- 说明 -------- ---------- ---- ------- ---- ---------------- ----------- 所属项目 ---- 字符串 ---- 项目所属的项目 -------- 开始日期 ---- 日期 ---- 任务的开始日期 -------- 结束日期 ---- 日期 ---- 任务的结束日期 -------- 任务描述 ---- 字符串 ---- 任务的描述信息 -------- 负责人 ---- 字符串 ---- 负责人姓名 -------- 完成进度 ---- 字符串 ---- 任务的完成进度 ----6.质量检验表---- 字段名 ---- 类型 ---- 说明 -------- ---------- ---- ------- ---- ---------------- ----------- 所属项目 ---- 字符串 ---- 构件所属的项目 -------- 检验日期 ---- 日期 ---- 检验的日期 -------- 检验结果 ---- 字符串 ---- 检验的结果 -------- 检验人 ---- 字符串 ---- 检验人姓名 ----7.材料清单表---- 字段名 ---- 类型 ---- 说明 -------- ---------- ---- ------- ---- ---------------- -------- 构件名称 ---- 字符串 ---- 构件的名称 -------- 所属项目 ---- 字符串 ---- 构件所属的项目 ----------- 材料数量 ---- 整数 ---- 材料的数量 -------- 材料规格 ---- 字符串 ---- 材料的规格 -------- 供应商 ---- 字符串 ---- 供应商名称 ----附件:1.项目计划书2.构件设计图纸3.结构分析报告4.施工方案法律名词及注释:1.荷载类型:指施加在结构上的力或重量,如静荷载、动荷载等。
芋道trade_order表结构全文共四篇示例,供读者参考第一篇示例:芋道trade_order表结构是一个用于存储订单信息的数据库表结构,在电子商务应用程序中起着至关重要的作用。
在这篇文章中,我们将详细介绍该表的结构和各个字段的含义。
1. 订单表结构trade_order表是芋道系统中用于存储订单信息的关键表之一。
它包含了各种与订单相关的信息,如订单号、订单状态、订单金额、下单时间等。
通过这个表,系统可以实现对订单信息的保存、查询、更新等操作。
2. 字段说明下面是芋道trade_order表的字段说明:- order_id:订单ID,是订单的唯一标识符,通常为一个自增长的整数。
- user_id:用户ID,标识订单所属的用户。
- order_number:订单号,用于区分不同的订单。
- total_amount:订单总金额,表示该订单的总金额。
- order_status:订单状态,如待支付、已支付、待发货、已发货等。
- create_time:订单创建时间,记录订单的创建时间。
- update_time:订单更新时间,记录订单的最后更新时间。
除了以上字段外,表中还可以包含其他一些与订单相关的信息,如商品ID、商品数量、收货地址、支付方式等。
这些信息可以根据具体业务需求进行扩展。
3. 表的设计原则在设计trade_order表时,需要按照一些基本原则进行设计,以确保表结构的合理性和稳定性。
以下是一些常用的设计原则:- 数据一致性:确保订单表中的数据是一致的,避免出现重复、冗余或不完整的数据。
- 数据完整性:设定适当的约束条件,确保订单表中的数据符合预期格式和要求。
- 数据可扩展性:表结构应具有一定的可扩展性,以便后续根据业务需求进行扩展。
- 性能优化:设计索引、分区等操作,以提高查询性能和数据访问速度。
通过遵循这些设计原则,可以设计出一个高效、稳定的trade_order表结构,满足各种订单信息管理需求。
银行管理系统数据库设计一、引言银行作为金融领域中重要的机构之一,其管理系统的设计对于保障金融交易的安全性和高效性具有至关重要的作用。
本文将详细介绍银行管理系统数据库的设计,包括数据库结构、数据表设计和关键功能模块的数据存储方式等方面。
二、数据库结构设计1. 数据库模型选择在银行管理系统中,常用的数据库模型包括关系型数据库模型和面向对象数据库模型。
考虑到银行业务的复杂性和数据之间的关联性,我们选择关系型数据库模型作为数据库设计的基础。
2. 数据表设计(1) 用户信息表•用户ID(主键)•用户姓名•身份证号•联系方式•地址•注册时间(2) 账户信息表•账户号(主键)•用户ID(外键)•账户类型•账户余额•开户时间•利率(3) 交易记录表•交易ID(主键)•账户号(外键)•交易类型•交易金额•交易时间3. 索引设计为提高数据库的查询效率,可以在用户ID、账户号等频繁被查询的字段上创建索引,加快数据检索速度。
三、关键功能模块数据库存储方式1. 用户注册与登录模块用户注册信息将存储在用户信息表中,登录验证时将对用户名和密码进行匹配验证。
2. 账户管理模块账户信息表存储了用户的账户信息,包括账户类型、余额等,管理员可通过该表进行账户管理操作。
3. 交易记录模块交易记录表用于记录每笔交易的信息,包括交易类型、金额等,对于账户的交易历史进行存储和查询。
四、安全性考虑为保障银行管理系统的安全性,可以采取加密算法对用户信息进行加密存储,确保数据在传输和存储过程中的安全性。
五、总结本文针对银行管理系统数据库设计进行了详细的介绍,包括数据库结构设计、关键功能模块的数据库存储方式及安全性考虑等方面。
通过合理的数据库设计,可提高银行管理系统的运行效率和安全性,保障金融交易信息的完整性和可靠性。
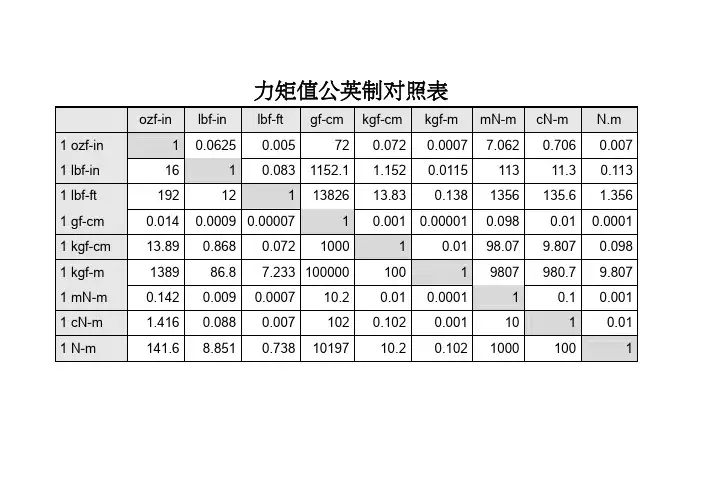
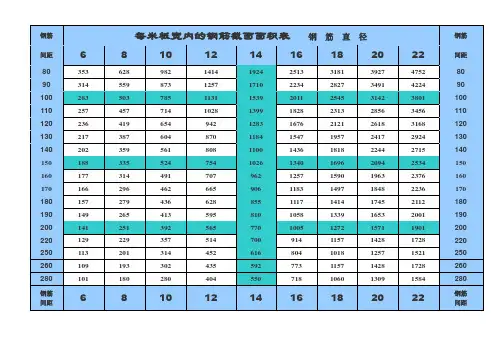
设计常用数据速查表一、集水坑
二、管道井
公式:D=300+200*(M-1) M:布置排数
注:DN25给水管(远传水表)管长最少570mm;DN25给水管(加减压阀)管长最少900mm 2、管井宽度:
注:
1)此做法为水暖共用管道井,单独暖气管井尺寸参见公式二
2)当采暖超过4户用分水器,每排立管最多3根
公式一:L=900+80*N+320*(A-1) N:户数;A:每排立管数
公式二:L=800+70*(2N+1) N:户数
3、天津要求:单排管进深≥550mm;双排管进深≥700mm;管间距≥200mm;管距墙≥150mm;管井设排水地漏。
空压机排气量选择表
五、常用设备尺寸及电量
六、住宅防烟设计
七、地下车库风机房设计(按照防火分区面积4000㎡计算)
1、网上计算方法:
2)设置原则:一个排风机房;一个送风机房
2、自己根据样本总结计算方法:
①风机尺寸:上表根据2000㎡防烟分区计算;风机的尺寸为550~1500mm。
③软接头尺寸:上表按圆形防火伸缩软风管φ1000考虑;直径≤500,L=250;560≤D≤1400,
L=300;D≥1600,L=350。
④止回阀尺寸:所有风管止回阀长度均为300mm
⑤天圆地方尺寸:天圆地方长度可以根据制作的不同而不同,可以用“钢构CAD”进行放
样计算。