hadoop + zookeeper +hive + hbase安装学习-12页文档资料
- 格式:doc
- 大小:71.50 KB
- 文档页数:12

Hadoop+Zookeeper+HBase安装指南RUC DB-IIR 卞昊穹/bhq2010bianhaoqiong@2012.07.28-Version1集群情况:4个节点,IP分别为:node0: 192.168.181.136(NameNode/JobTracker/SecondaryNameNode/HMaster)node1: 192.168.181.132(DataNode/TaskTracker/HRegionServer/QuorumPeerMain)node2: 192.168.181.133(DataNode/TaskTracker/HRegionServer/QuorumPeerMain)node3: 192.168.181.134(DataNode/TaskTracker/HRegionServer/QuorumPeerMain)软件版本:CentOS Linux 6.2 x86_64(2.6.32)OpenJDK-1.6.0_24Hadoop-1.0.2Zookeeper-3.4.3HBase-0.94.0目录1. hosts和hostname设置 (2)2. SSH设置 (2)3. Hadoop配置安装 (3)4. Zookeeper配置安装 (5)5. HBase配置安装 (6)1. hosts和hostname设置安装分布式的Hadoop和HBase集群需要在每一个节点上都设置网络中的hosts和本机的hostname。
首先将/etc/hosts文件中127.0.0.1这一行的中间一段改为本机的主机名,并在文件末尾添加hosts配置,每行为一个ip地址和对应的主机名,以空格分隔。
以node0为例,修改后的hosts 文件如下:再将/etc/sysconfig/network文件中HOSTNAME=一行中“=”之后内容改为主机名,如:2. SSH设置之后,在node0生成ssh公钥,添加到node1/2/3的~/.ssh/authorized_keys文件中以实现node0无密码登录node1/2/3,参考:/bhq2010/article/details/6845985此处node0是ssh客户端,node1/2/3是ssh服务器端。



工作总结主题:debian下安装配置HBase,Hive,Chukwa,Pig,Zookeeper;windows下结合eclipse进行MapReduce开发。
一、安装HBase✧#apt-cache search jdk命令找到当前可用jdk版本,选择open-6-jdk openjdk-6-jre;✧#apt-get install open-6-jdk openjdk-6-jre进行安装。
✧#cd /opt转到opt目录下,通过命令✧#wget /apache-mirror/hbase/hbase-0.90.6/hbase-0.90.6.tar.gz下载HBase到/opt目录下✧#tar –zxvf hbase-0.90.6.tar.gz在当前目录下将hbase-0.90.6.tar.gz解压✧#vi /opt/hbase-0.90.6/conf/hbase-env.sh 编辑hbase-env.sh来配置JAVA_HOME✧找到有JAVA_HOME的那一行去掉前面的#号改为你的Java安装路径JAVA_HOME=/usr/lib/jvm/jdk1.6.0-24✧配置好后,通过#bin/hbase 可以获取HBase的选项列表✧#bin/start-hbase.sh 启动HBase✧#bin/hbase shell启动HBase的外壳环境(shell)。
✧安装成功。
二、安装Hive✧#cd /opt转到opt目录下,通过命令✧#wget /apache-mirror/hive/hive-0.9.0/hive-0.9.0.tar.gz下载Hive✧#tar –zxvf hive-0.9.0.tar.gz进行解压。
✧配置HIVE_HOME,直接输入以下命令,或者编辑hive-env.sh配置#export HIVE_HOME=/opt/hive-0.9.0# export PATH=$PATH:$HIVE_HOME/bin✧除此之外还要保证HADOOP_HOME的配置#export HADOOP_HOME=/opt/hadoop-1.0.3.✧直接输入bin/hive即可启动✧安装成功三、安装Pig✧#cd /opt转到opt目录下,通过命令✧#wget /pig/pig-0.10.0/pig-0.10.0.tar.gz下载Pig✧#tar –zxvf pig-0.10.0.tar.gz在当前目录下解压✧直接在命令行输入以下命令配置好PIG_HOME#export PIG_HOME=/opt/pig-0.10.0#export PATH=$PATH:$PIG_HOME/bin✧还需要设置JAVA_HOME环境变量,以指明Java安装路径✧#pig –help可获得使用帮助✧#bin/pig –x local这样就能启动Grunt。

2023年大数据专业毕设选题推荐选题注意事项:(1)数据是否能够获取(2)工作量是否满足毕设要求(3)代码是否通俗易懂,能否在短期内掌握(4)选题是否具有现实意义(5)个人电脑硬件是否支持运行大数据项目大数据毕设项目主要流程:(1)大数据环境搭建:虚拟机搭建(分布式、伪分布式)、Hadoop、Hbase、Zookeeper、Hive、Hbase、Kafka、Flume等组件的安装(2)数据获取与清洗:爬虫、公开渠道获取等(3)数据分析:选择合适的大数据分析技术(4)数据挖掘:聚类、预测、推荐等(5)可视化展示:大屏、导航栏跳转等一、Hive数据仓库相关选题Hive数据仓库项目的核心仓库分层:ODS(源数据层)、DWD(数据明细层)、DWS(数据汇总层)、ADS(数据应用层)(1)基于hive的民宿价格分析系统选题意义:在消费升级背景下,消费转型、消费提升成为新的研究热点.当前,中国旅游市场在加速复兴中,新型优质的中高端旅游产品推动旅游市场的迅速恢复.近两年民宿标准化文件相继出台,民宿行业对民宿评级工作的有序开展,使得民宿业进入了转型升级通道,也为民宿的理论研究创造出有利的条件。
利用Hadoop、Hive、MapReduce等技术为用户解决在民宿选择问题,通过对用户所提供房屋的容纳人数、便利设施、洗手间数量、床的数量、卧室数量等相关信息,来进行可视化展示,更加详细的面向用户,更加清晰的展示当前房屋情况,为用户提供最合理的价格方案,该系统的设计目标是为用户提供可靠的可视化数据分析服务。
创新点:(1)对Hive数据仓库进行分层建设(2)聚焦热点领域,较强的现实意义(3)可视化大屏展示技术路线:1、数据爬取:基于python爬取去哪网相关民宿信息,并进行数据清洗2、数据分析:基于Hive数据仓库进行数据存储和分析,分析维度包括:民宿价格均值、民宿评分排名、各区域民宿数量、民宿简介词云、民宿均价等3、数据迁移:Sqoop4、数据可视化:springBoot+echarts+MySQL可视化(2)基于hive的厨具用品数据分析可视化选题意义:目前智能手机随处可见,各种年龄段的人群都可以在网络上随心所欲的购买商品。
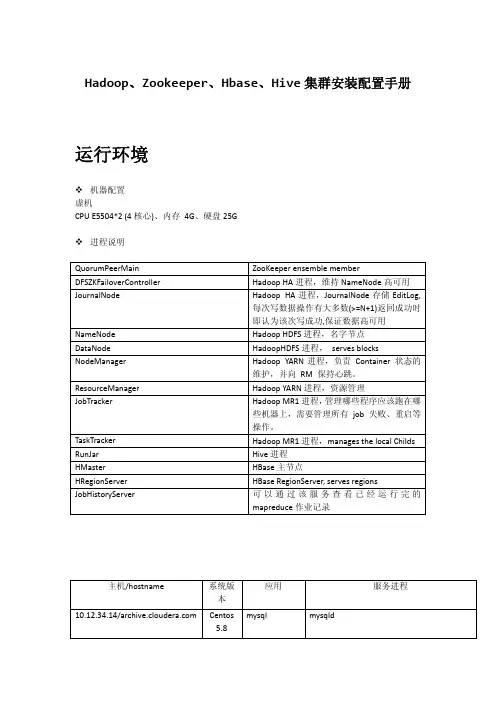
Hadoop、Zookeeper、Hbase、Hive集群安装配置手册运行环境机器配置虚机CPU E5504*2 (4核心)、内存 4G、硬盘25G进程说明QuorumPeerMain ZooKeeper ensemble member DFSZKFailoverController Hadoop HA进程,维持NameNode高可用 JournalNode Hadoop HA进程,JournalNode存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,保证数据高可用 NameNode Hadoop HDFS进程,名字节点DataNode HadoopHDFS进程, serves blocks NodeManager Hadoop YARN进程,负责 Container 状态的维护,并向 RM 保持心跳。
ResourceManager Hadoop YARN进程,资源管理 JobTracker Hadoop MR1进程,管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
TaskTracker Hadoop MR1进程,manages the local Childs RunJar Hive进程HMaster HBase主节点HRegionServer HBase RegionServer, serves regions JobHistoryServer 可以通过该服务查看已经运行完的mapreduce作业记录应用 服务进程 主机/hostname 系统版本mysql mysqld10.12.34.14/ Centos5.810.12.34.15/h15 Centos5.8 HadoopZookeeperHbaseHiveQuorumPeerMainDFSZKFailoverControllerNameNodeNodeManagerRunJarHMasterJournalNodeJobHistoryServerResourceManagerDataNodeHRegionServer10.12.34.16/h16 Centos5.8 HadoopZookeeperHbaseHiveDFSZKFailoverControllerQuorumPeerMainHMasterJournalNodeNameNodeResourceManagerDataNodeHRegionServerNodeManager10.12.34.17/h17 Centos5.8 HadoopZookeeperHbaseHiveNodeManagerDataNodeQuorumPeerMainJournalNodeHRegionServer环境准备1.关闭防火墙15、16、17主机:# service iptables stop2.配置主机名a) 15、16、17主机:# vi /etc/hosts添加如下内容:10.12.34.15 h1510.12.34.16 h1610.12.34.17 h17b) 立即生效15主机:# /bin/hostname h1516主机:# /bin/hostname h1617主机:# /bin/hostname h173. 创建用户15、16、17主机:# useraddhduser密码为hduser# chown -R hduser:hduser /usr/local/4.配置SSH无密码登录a)修改SSH配置文件15、16、17主机:# vi /etc/ssh/sshd_config打开以下注释内容:#RSAAuthentication yes#PubkeyAuthentication yes#AuthorizedKeysFile .ssh/authorized_keysb)重启SSHD服务15、16、17主机:# service sshd restartc)切换用户15、16、17主机:# su hduserd)生成证书公私钥15、16、17主机:$ ssh‐keygen ‐t rsae)拷贝公钥到文件(先把各主机上生成的SSHD公钥拷贝到15上的authorized_keys文件,再把包含所有主机的SSHD公钥文件authorized_keys拷贝到其它主机上)15主机:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys16主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'17主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'15主机:# cat ~/.ssh/authorized_keys | ssh hduser@h16 'cat >> ~/.ssh/authorized_keys'# cat ~/.ssh/authorized_keys | ssh hduser@h17 'cat >> ~/.ssh/authorized_keys'5.Mysqla) Host10.12.34.14:3306b) username、passwordhduser@hduserZookeeper使用hduser用户# su hduser安装(在15主机上)1.下载/apache/zookeeper/2.解压缩$ tar ‐zxvf /zookeeper‐3.4.6.tar.gz ‐C /usr/local/配置(在15主机上)1.将zoo_sample.cfg重命名为zoo.cfg$ mv /usr/local/zookeeper‐3.4.6/conf/zoo_sample.cfg /usr/local/zookeeper‐3.4.6/conf/zoo.cfg2.编辑配置文件$ vi /usr/local/zookeeper‐3.4.6/conf/zoo.cfga)修改数据目录dataDir=/tmp/zookeeper修改为dataDir=/usr/local/zookeeper‐3.4.6/datab)配置server添加如下内容:server.1=h15:2888:3888server.2=h16:2888:3888server.3=h17:2888:3888server.X=A:B:C说明:X:表示这是第几号serverA:该server hostname/所在IP地址B:该server和集群中的leader交换消息时所使用的端口C:配置选举leader时所使用的端口3.创建数据目录$ mkdir /usr/local/zookeeper‐3.4.6/data4.创建、编辑文件$ vi /usr/local/zookeeper‐3.4.6/data/myid添加内容(与zoo.cfg中server号码对应):1在16、17主机上安装、配置1.拷贝目录$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.16:/usr/local/$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.17:/usr/local/2.修改myida)16主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1 修改为2b)17主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1修改为3启动$ cd /usr/local/zookeeper‐3.4.6/$./bin/zkServer.sh start查看状态:$./bin/zkServer.sh statusHadoop使用hduser用户# su hduser安装(在15主机上)一、安装Hadoop1.下载/apache/hadoop/common/2.解压缩$ tar ‐zxvf /hadoop‐2.4.0.tar.gz ‐C /usr/local/二、 编译本地库,主机必须可以访问internet。
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册前言: (3)一. Hadoop安装(伪分布式) (4)1. 操作系统 (4)2. 安装JDK (4)1> 下载并解压JDK (4)2> 配置环境变量 (4)3> 检测JDK环境 (5)3. 安装SSH (5)1> 检验ssh是否已经安装 (5)2> 安装ssh (5)3> 配置ssh免密码登录 (5)4. 安装Hadoop (6)1> 下载并解压 (6)2> 配置环境变量 (6)3> 配置Hadoop (6)4> 启动并验证 (8)前言:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。
为什么是Hadoop2.2.0,而不是Hadoop2.4.0本文写作时,Hadoop的最新版本已经是2.4.0,但是最新版本的Hbase0.98.1仅支持到Hadoop2.2.0,且Hadoop2.2.0已经相对稳定,所以我们依然采用2.2.0版本。
一. Hadoop安装(伪分布式)1. 操作系统Hadoop一定要运行在Linux系统环境下,网上有windows下模拟linux环境部署的教程,放弃这个吧,莫名其妙的问题多如牛毛。
2. 安装JDK1> 下载并解压JDK我的目录为:/home/apple/jdk1.82> 配置环境变量打开/etc/profile,添加以下内容:export JAVA_HOME=/home/apple/jdk1.8export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar执行source /etc/profile ,使更改后的profile生效。

目录1. 前言 (2)2. 准备工作 (2)2.1. 下载Hadoop (2)2.2. 下载hadoop-common (3)2.3. 下载Hbase (3)2.4. 下载JDK (4)3. 环境配置 (4)3.1. 将下载好的3个压缩包分别解压缩 (4)3.2. 覆盖文件 (6)3.3. 安装JDK (7)3.3.1. 配置JAVA环境变量 (8)3.3.2. 测试JDK安装是否成功 (11)4. 配置Hadoop (11)4.1. hadoop-env.cmd (12)4.2. core-site.xml (13)4.3. hdfs-site.xml (14)4.4. 创建mapred-site.xml (15)4.5. yarn-site.xml (18)5. 启动Hadoop (20)5.1. 以管理员身份运行CMD命令提示符 (20)5.2. 切换到hadoop目录 (21)5.3. 运行hadoop-env.cmd脚本 (21)5.4. 格式化HDFS文件系统 (21)5.5. 启动HDFS (22)5.6. 遇到异常 (23)5.6.1. 解决方案 (23)5.7. 停止Hadoop (25)6. 配置Hbase (26)6.1. 编辑hbase-site.xml (26)6.2. 编辑hbase-env.cmd (27)7. 启动Hbase (28)8. Hbase Shell (31)8.1. 用shell连接HBase (31)8.2. 使用shell (31)8.2.1. 创建表 (31)8.2.2. Scan表 (32)8.2.3. Get一行 (33)8.2.4. 删除表 (33)8.2.5. 关闭shell (34)8.2.6. 停止Hbase (34)9. Java API Hbase (35)1.前言工作需要,现在开始做大数据开发了,通过下面的配置步骤,你可以在win10系统中,部署出一套hadoop+hbase,便于单机测试调试开发。

安装和配置HBase需要按照以下步骤进行:
1. 解压安装包:将HBase安装包解压到指定的目录中。
2. 重命名路径:将解压后的路径重命名为HBase的根目录。
3. 添加环境变量:将HBase的根目录添加到系统的环境变量中,以便在命令行中访问HBase。
4. 配置hbase-env.sh文件:打开HBase根目录下的conf文件夹,找到hbase-env.sh文件,修改其中的配置项,例如HBASE_HEAPSIZE 等。
5. 配置hbase-site.xml文件:打开HBase根目录下的conf文件夹,找到hbase-site.xml文件,修改其中的配置项,例如HBASE_HOME、HBASE_ZOOKEEPER_QUORUM等。
6. 配置regionservers文件:打开HBase根目录下的conf文件夹,找到regionservers文件,添加需要运行的regionserver节点的主机名。
7. 创建hbase.tmp.dir目录:在HBase根目录下创建一个临时目录,用于存储HBase运行时产生的临时文件。
8. 将文件分发到slave节点:将HBase的安装包和配置文件分发到其他slave节点上,以便这些节点可以运行HBase。
9. 修改hbase目录权限:在所有节点上修改HBase目录的权限,确保只有指定的用户可以访问和修改HBase的目录和文件。
完成以上步骤后,您已经成功安装和配置了HBase。
您可以使用HBase 提供的命令行工具或API进行基本操作,例如创建表、插入数据、查询数据等。

大数据技术实验报告大数据技术实验一Hadoop大数据平台安装实验1实验目的在大数据时代,存在很多开源的分布式数据采集、计算、存储技术,本实验将在熟练掌握几种常见Linux命令的基础上搭建Hadoop(HDFS、MapReduce、HBase、Hive)、Spark、Scala、Storm、Kafka、JDK、MySQL、ZooKeeper等的大数据采集、处理分析技术环境。
2实验环境个人笔记本电脑Win10、Oracle VM VirtualBox 5.2.44、CentOS-7-x86_64-Minimal-1511.iso3实验步骤首先安装虚拟机管理程序,然后创建三台虚拟服务器,最后在虚拟服务器上搭建以Hadoop 集群为核心的大数据平台。
3.1快速热身,熟悉并操作下列Linux命令·创建一个初始文件夹,以自己的姓名(英文)命名;进入该文件夹,在这个文件夹下创建一个文件,命名为Hadoop.txt。
·查看这个文件夹下的文件列表。
·在Hadoop.txt中写入“Hello Hadoop!”,并保存·在该文件夹中创建子文件夹”Sub”,随后将Hadoop.txt文件移动到子文件夹中。
·递归的删除整个初始文件夹。
3.2安装虚拟机并做一些准备工作3.2.1安装虚拟机下载系统镜像,CentOS-7-x86_64-Minimal-1511.iso。
虚拟机软件使用Oracle VM VirtualBox 5.2.44。
3.2.2准备工作关闭防火墙和Selinux,其次要安装perl 、libaio、ntpdate 和screen。
然后检查网卡是否开机自启,之后修改hosts,检查网络是否正常如图:然后要创建hadoop用户,之后多次用,并且生成ssh 密钥并分发。
最后安装NTP 服务。
3.3安装MYSQL 3.3.1安装3.3.2测试3.4安装ZooKeeper。

hadoop和hbase伪分布式安装实验总结Hadoop和HBase伪分布式安装实验总结一、实验目标本次实验的目标是掌握Hadoop和HBase的伪分布式安装与配置,了解其在大数据处理中的应用。
通过实验,我们将深入了解Hadoop和HBase的基本概念、架构和工作原理,并亲自动手进行系统安装和配置。
二、实验步骤与过程1. 准备环境:确保实验环境满足Hadoop和HBase的最低硬件和软件要求,包括足够的内存、磁盘空间和网络带宽。
2. 安装Java:由于Hadoop和HBase都依赖于Java,因此需要先安装Java开发工具包(JDK)。
3. 下载Hadoop和HBase:从Apache官网下载Hadoop和HBase的稳定版本。
4. 配置Hadoop:编辑Hadoop的配置文件,包括、等,设置NameNode、SecondaryNameNode、DataNode的地址。
5. 格式化HDFS:使用Hadoop的命令行工具初始化HDFS文件系统。
6. 启动Hadoop:启动NameNode、SecondaryNameNode和DataNode,使HDFS进入运行状态。
7. 安装HBase:解压下载的HBase压缩包到指定目录。
8. 配置HBase:编辑HBase的配置文件,包括、等,设置ZooKeeper的地址、HBase master和regionserver的地址。
9. 启动HBase:启动ZooKeeper和HBase master,然后启动regionserver。
10. 验证安装:通过Web浏览器访问HBase的管理界面,以及使用HBase shell命令进行基本操作,验证安装是否成功。
三、实验结果与分析通过本次实验,我们成功地在实验环境中安装了Hadoop和HBase,并验证了其基本功能。
在安装过程中,我们遇到了一些问题,如环境变量配置错误、端口冲突等,但通过查阅文档和在线求助,最终都得到了解决。
Hadoop是Apache下的一个项目,由HDFS、MapReduce、Hbase、Hive和ZooKeeper等成员组成,其中HDFS和MapReduce是两个最重要的成员。
HDFS是Google GFS的开源版本,一个高度容错的分布式文件系统,它能够提供高吞吐量的数据访问,适合存储海量的大文件,其原理如下图所示:采用Master/Slave结构。
NameNode维护集群内的元数据,对外提供创建、打开、删除和重命名文件或目录的功能。
DataNode存储数据,并提负责处理数据的读写请求。
DataNode 定期向NameNode上报心跳,NameNode通过响应心跳来控制DataNode。
InfoWord将MapReduce评为2009年十大新兴技术的冠军。
MapReduce是大规模数据计算的利器,Map和Reduce是它的主要思想,来源于函数式编程语言,它的原理如下图所示:Map负责将数据打散,Reduce负责对数据进行集聚,用户只需要实现Map和Reduce 两个接口,即可完成TB级数据的计算,常见的应用包括:日志分析和数据挖掘等数据分析应用。
另外,还可用于科学数据计算,入圆周率PI的计算等。
Hadoop MapReduce的实现也采用了Master/Slave结构。
Master叫做JobTracker,而Slave 叫做TaskTracker。
用户提交的计算叫做Job,每一个Job会被划分成若干个Tasks。
JobTracker负责Job和Tasks的调度,而TaskTracker负责执行Tasks。
在Linux下搭建Hadoop集群,要先熟悉Linux的基本概念和操作,如cd、ls、tar、cat、ssh、sudo、scp等操作。
养成搜索意识很重要,遇到问题借用Google、百度等,或者论坛,推荐Hadoop技术论坛。
Ubuntu和redhat等版本的Linux在操作命令上有不同点,但安装Hadoop的流程一样。
Hbase的安装与基本操作简介:1安装 HBase本节介绍HBase的安装⽅法,包括下载安装⽂件、配置环境变量、添加⽤户权限等。
1.1 下载安装⽂件HBase是Hadoop⽣态系统中的⼀个组件,但是,Hadoop安装以后,本⾝并不包含HBase,因此,需要单独安装HBase。
hbase-1.1.5-bin.tar.gz假设已经下载了HBase安装⽂件hbase-1.1.5-bin.tar.gz,被放到了Linux系统的“/home/hadoop/下载/”⽬录下。
进⼊下载⽬录,需要对⽂件进⾏解压。
按照Linux系统使⽤的默认规范,⽤户安装的软件⼀般都是存放在“/usr/local/”⽬录下。
$ cd ~/下载$ sudo tar -zxf ~/下载/hbase-1.1.5-bin.tar.gz -C /usr/local将解压的⽂件名hbase-1.1.5改为hbase,以⽅便使⽤,命令如下:$ sudo mv /usr/local/hbase-1.1.5 /usr/local/hbase1.2 配置环境变量将HBase安装⽬录下的bin⽬录(即/usr/local/hbase/bin)添加到系统的PATH环境变量中,这样,每次启动HBase时就不需要到“/usr/local/hbase”⽬录下执⾏启动命令,⽅便HBase的使⽤。
请使⽤vim编辑器打开“~/.bashrc”⽂件,命令如下:$ vim ~/.bashrc⽂件以后,添加添加PATH路径时只需要加上":路径"即可,下⾯这条命令是添加了三条路径,配置的是hadoop和hbasd的打开.bashrc⽂件以后,启动路径export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin:/usr/local/hbase/bin添加后,执⾏如下命令使设置⽣效:$ source ~/.bashrc1.3 添加⽤户权限需要为当前登录Linux系统的hadoop⽤户(我的⽤户是msq)添加访问HBase⽬录的权限,将HBase安装⽬录下的所有⽂件的所有者改为msq,命令如下:$ cd /usr/local$ sudo chown -R msq ./hbase1.4 查看HBase版本信息可以通过如下命令查看HBase版本信息,以确认HBase已经安装成功:$ /usr/local/hbase/bin/hbase version2 HBase的配置HBase有三种运⾏模式,即单机模式、伪分布式模式和分布式模式:单机模式:采⽤本地⽂件系统存储数据;伪分布式模式:采⽤伪分布式模式的HDFS存储数据;分布式模式:采⽤分布式模式的HDFS存储数据。
贵州XXX学院《HBase入门与实践》课程标准(2023年版)《HBase入门与实践》课程标准一、课程基本信息二、课程定位与任务(一)课程定位《HBase入门与实践》是一门分布式数据库,是大数据技术核心课程之一,为学生搭建起通向“大数据知识空间”的桥梁和纽带,以“构建知识体系、阐明基本原理、引导初级实践、了解相关应用”为原则,为学生在大数据领域“深耕细作”奠定基础、指明方向。
课程将系统讲授大数据的基本概念、HBase数据模型、数据操纵语言数据可视化以及大数据在互联网、生物医学和物流等各个领域的应用。
在Hbase Shell的使用、模式设计等重要章节,安排了HBase入门级的实践操作,让学生更好地学习和掌握大数据关键技术。
(二)课程任务以“构建知识体系、阐明基本原理、引导初级实践、了解相关应用”为原则,为学生在大数据领域“深耕细作”奠定基础、指明方向。
课程将系统讲授大数据的基本概念、HBase数据模型、数据操纵语言数据可视化以及大数据在互联网、生物医学和物流等各个领域的应用。
在Hbase Shel1的使用、模式设计等重要章节,安排了HBase入门级的实践操作,让学生更好地学习和掌握大数据关键技术。
三、课程设计思路面向实践,以理论知识与具体应用相结合的方式介绍HBase,理论切合实际,由浅入深,深入解析分布式数据库原理,加强对HBse概念及技术的理解与巩固。
面向企业,切实培养企业方需要的操作型人才,课程设计围绕大数据技术要求合理设计HBase所需相关知识,为深入学习大数据做下铺垫。
四、课程目标本课程重点是学习 HBase 的设计与应用。
重点学习分布式数据库HBase 的访问接口、数据模型、实现原理、运行机制。
(一)知识目标(1)HBase 分布式数据库背景-NoSQL 与传统 ROBMS(2)HBase 安装(3)HBase 单机部署(4)HBase 的配置与启动(5)分布式部署(6)启动集群与集群增删节点(7)HBase 数据模型(8)逻辑模型与物理模型(9)HBase Shell 的使用(10)数据操纵语言(11)模式设计(12)HBase 性能调优(二)素质目标(13)培养学生诚实守信的性格(14)培养学生独立思考、解决问题的能力(15)培养按时、守时的工作观念(16)培养学生的团队协作能力(17)培养学生能遵纪守法并尊重知识产权,不使用计算机伤害和危害他人利益(18)培养学生自主学习的能力(三)能力目标(19)能够掌握 HBase 的基本概念。
Hadoop2.7.3+Hbase-1.2.6完全分布式安装部署Hadoop安装部署基本步骤:1、安装jdk,配置环境变量。
jdk可以去⽹上⾃⾏下载,环境变量如下:编辑 vim /etc/profile ⽂件,添加如下内容:export JAVA_HOME=/opt/java_environment/jdk1.7.0_80(填写⾃⼰的jdk安装路径)export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH=$PATH:$JAVA_HOME/bin输⼊命令,source /etc/profile 使配置⽣效分别输⼊命令,java 、 javac 、 java -version,查看jdk环境变量是否配置成功2、linux环境下,⾄少需要3台机⼦,⼀台作为master,2台(以上)作为slave。
这⾥我以3台机器为例,linux⽤的是CentOS 6.5 x64为机器。
master 192.168.172.71slave1 192.168.172.72slave2 192.168.172.733、配置所有机器的hostname和hosts。
(1)更改hostname,可以编辑 vim /etc/sysconfig/network 更改master的HOSTNAME,这⾥改为HOSTNAME=master 其它slave为HOSTNAME=slave1、HOSTNAME=slave2 ,重启后⽣效。
或者直接输: hostname 名字,更改成功,这种⽅式⽆需重启即可⽣效, 但是重启系统后更改的名字会失效,仍是原来的名字 (2)更改host,可以编辑 vim /etc/hosts,增加如下内容: 192.168.172.71 master 192.168.172.72 slave1 192.168.172.73 slave2 hosts可以和hostname不⼀致,这⾥为了好记就写⼀致了。
Hive基础(习题卷1)第1部分:单项选择题,共88题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]HBase交互模式中,查看当前服务状态的命令是( )A)serviceB)servicesC)statusD)statu答案:C解析:2.[单选题]HBase是一种“NoSQL”数据库,支持大型( )数据存储A)集中式B)集合式C)分布式D)分散式答案:C解析:3.[单选题]HBase中的所有数据文件都存储在Hadoop HDFS上,主要有HFile格式与( )格式A)HTXTB)HLogC)HLog FileD)HFile Log答案:C解析:4.[单选题]OLAP是什么意思( )A)联机分析处理B)单机分析处理C)联网分析处理D)事务分析处理答案:A解析:5.[单选题]命令行界面,也就是( ),是和Hive交互的最常用的方式A)CMDB)CLIC)CMID)CLD答案:B解析:6.[单选题]在Hive中,如果只需要结构集的部分数据,可以通过( )子句来限定返回的行数答案:A解析:7.[单选题]内部表和外部表之间可以互相转换,所使用的关键字是( )。
A)CreateB)AlterC)TruncateD)Drop答案:B解析:8.[单选题]Hive交互Shell指执行$HIVE_HOME/bin/hive之后,交互式命令行的提示符是( )A)help>B)hive>C)user>D)cmd>答案:B解析:9.[单选题]在HBase中,Scan类的( )方法限定返回数据的列簇A)family()B)addFamily()C)Column()D)addColumn()答案:B解析:10.[单选题]在Hive的查询语句中,表示A和B按位取或的是( )A)A|BB)A&BC)A-BD)A~B答案:A解析:11.[单选题]Hive将表中的数据保存到文本,并使用命令插入到employee表中的命令正确是( )A)load local inpath '/opt/data/test.txt' overwrite into table employee;B)load data inpath '/opt/data/test.txt' overwrite into table employee;C)load data local inpath '/opt/data/test.txt' into table employee;D)load data local inpath '/opt/data/test.txt' overwrite into table employee;答案:D解析:12.[单选题]关于Hive嵌入模式说法错误的是( )。
伪分布式安装Hadoop+zookeeper+hive+hbase安装配置1.安装JDK,配置环境JAVA环境变量export JAVA_HOME=/usr/lib/java-1.6.0/jdk1.6.0_37export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/libexport HADOOP_INSTALL=/usr/hadoop/hadoop-1.0.3export PATH=$PATH:$HADOOP_INSTALL/binexport JAVA_HOME=/user/local/jdk1.6.0_27export JRE_HOME=/user/local/jdk1.6.0_27/jreexport ANT_HOME=/user/local/apache-ant-1.8.2export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH2.安装Hadoop-1.0.32.1.下载hadoop文件,地址为:/coases.html,下载完成后解压hadoop-1.0.3.tar.gzsudo tar -xzf hadoop-1.0.3.tar.gz2.2.配置Hadoop环境变量export HADOOP_INSTALL=/user/local/hadoop-1.0.3export PATH=$PATH:$HADOOP_INSTALL/bin激活profile文件:[root@localhost etc]# chmod +x profile[root@localhost etc]# source profile[root@localhost etc]# hadoop version2.3.查看hadoop版本[root@localhost ~]# hadoop versionHadoop 1.0.3Subversionhttps:///repos/asf/hadoop/common/branches/branch-1.0 -r 1335192Compiled by hortonfo on Tue May 8 20:31:25 UTC 2012From source with checksum e6b0c1e23dcf76907c5fecb4b832f3be输入 hadoop version命令后输入下图,则安装hadoop成功2.4.修改配置文件a)解压hadoop-1.0.3/hadoop-core-1.0.3.jarb)去解压后的hadoop-core-1.0.3文件夹下,复制文件core-default.xml,hdfs-default.xml,mapred-default.xml三个文件到hadoop-1.0.3/conf/下,删除hadoop-1.0.3/conf/文件夹下的core-site.xml,hdfs-site.xml,mapred-site.xml,将复制过来的三个文件的文件名中的default修改为sitec)在hadoop-1.0.3文件夹同级创建文件夹hadoop,打开core-site.xml文件,修改属性节点下的name节点为hadoop.tmp.dir对应的value节点,修改为/user/local/${}/hadoop/hadoop-${},这样hadoop生成的文件会放入这个文件夹下.修改name节点为对应的value节点,修改为hdfs://localhost:9000/打开mapred-site.xml文件,修改property节点下name为mapred.job.tracker对应的的value,改为:localhost:90013.安装ssh1.执行命令安装ssh:sudo apt-get install ssh2.基于空口令创建一个新SSH密钥,以启用无密码登陆a)ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa执行结果:b)cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys3.测试ssh localhost测试结果:输入yes再次输入ssh localhost:成功之后,就不需要密钥4.格式化HDFS文件系统输入指令:hadoop namenode –format[root@localhost ~]# hadoop namenode –format13/07/17 14:26:41 INFO Node: STARTUP_MSG:STARTUP_MSG: Starting NameNodeSTARTUP_MSG: host = localhost.localdomain/127.0.0.1STARTUP_MSG: args = [–format]STARTUP_MSG: version = 1.0.3STARTUP_MSG: build =https:///repos/asf/hadoop/common/branches/branch-1.0 -r 1335192; compiled by 'hortonfo' on Tue May 8 20:31:25 UTC 2012Usage: java NameNode [-format] | [-upgrade] | [-rollback] | [-finalize] | [-importCheckpoint]13/07/17 14:26:41 INFO Node: SHUTDOWN_MSG:SHUTDOWN_MSG: Shutting down NameNode at localhost.localdomain/127.0.0.15.启动和终止守护进程启动和终止HDFS和MapReduce守护进程,键入如下指令启动start-all.sh(start-dfs.sh,start-mapred.sh)出错了,JAVA_HOME is not set需要修改文件,打开hadoop-1.0.3/conf/ hadoop-env.sh将红线以内部分注释解开,修改为本机JAVA_HOME再次执行启动命令start-all.sh停止stop-all.sh(stop-dfs.sh,stop-mapred.sh)到此,hadoop就已经安装完成了6.Hadoop文件系统6.1.查看hadoop所有块文件执行命令:hadoop fsck / -files –blocks执行结果:此结果显示,hadoop文件系统中,还没有文件可以显示本机出错,出错原因:datanode没有启动,具体见evernote笔记。
[root@localhost ~]# hadoop fsck / -files –blocks13/07/17 14:44:15 ERROR erGroupInformation: PriviledgedActionException as:root cause:java.ConnectException: Connection refusedException in thread "main" java.ConnectException: Connection refusedat java.PlainSocketImpl.socketConnect(Native Method)at java.PlainSocketImpl.doConnect(PlainSocketImpl.java:351)at java.PlainSocketImpl.connectToAddress(PlainSocketImpl.java:211) at java.PlainSocketImpl.connect(PlainSocketImpl.java:200)at java.SocksSocketImpl.connect(SocksSocketImpl.java:366)at java.Socket.connect(Socket.java:529)at java.Socket.connect(Socket.java:478)at sunworkClient.doConnect(NetworkClient.java:163)at sun.http.HttpClient.openServer(HttpClient.java:388)at sun.http.HttpClient.openServer(HttpClient.java:523)at sun.http.HttpClient.<init>(HttpClient.java:227)at sun.http.HttpClient.New(HttpClient.java:300)at sun.http.HttpClient.New(HttpClient.java:317)atsun.protocol.http.HttpURLConnection.getNewHttpClient(HttpURLConnection.jav a:970)atsun.protocol.http.HttpURLConnection.plainConnect(HttpURLConnection.java:91 1)atsun.protocol.http.HttpURLConnection.connect(HttpURLConnection.java:836)atsun.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java: 1172)at org.apache.hadoop.hdfs.tools.DFSck$1.run(DFSck.java:141)at org.apache.hadoop.hdfs.tools.DFSck$1.run(DFSck.java:110)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:396)aterGroupInformation.doAs(UserGroupInformation. java:1121)at org.apache.hadoop.hdfs.tools.DFSck.run(DFSck.java:110)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:79)at org.apache.hadoop.hdfs.tools.DFSck.main(DFSck.java:182)[root@localhost ~]#6.2.将文件复制到hadoop文件系统中a)在hadoop文件系统中创建文件夹,执行命令:hadoop fs -mkdir docsb)复制本地文件到hadoop文件系统中执行命令:hadoop fs -copyFromLocal docs/test.txt \hdfs://localhost:9000/user/docs/test.txtc)复制hadoop文件系统中的文件回本地,并检查是否一致复制:hadoop fs -copyToLocal docs/test.txt docs/test.txt.bat检查:md5 docs/test.txt docs/text.txt.bat检查结果若显示两个md5加密值相同,则文件内容相同。