离线手写体笔迹鉴别方法研究
- 格式:pdf
- 大小:243.31 KB
- 文档页数:4

《蒙古文脱机手写识别研究》篇一一、引言随着信息技术的快速发展,手写识别技术逐渐成为人工智能领域的研究热点。
蒙古文脱机手写识别作为该领域的重要分支,具有广阔的应用前景。
本文旨在探讨蒙古文脱机手写识别的研究现状、方法及挑战,以期为相关研究提供参考。
二、蒙古文脱机手写识别的研究背景与意义蒙古文作为一种独特的文字系统,具有丰富的文化内涵和历史价值。
然而,随着科技的发展,蒙古文的书写方式逐渐向数字化转变。
脱机手写识别技术能够实现对蒙古文手写文字的自动识别,对于推动蒙古文化传承、提高书写效率、促进信息化建设具有重要意义。
三、蒙古文脱机手写识别的研究现状目前,蒙古文脱机手写识别技术已取得一定成果。
研究方法主要包括特征提取、模型训练和识别算法等。
其中,特征提取是关键步骤,需要从手写文字中提取出能够反映文字特征的向量;模型训练则需要利用大量标注数据训练出能够准确识别文字的模型;识别算法则需要根据具体应用场景选择合适的算法。
此外,研究者们还在不断探索新的方法和技术,如深度学习、神经网络等,以提高蒙古文脱机手写识别的准确率和效率。
四、蒙古文脱机手写识别的技术研究在特征提取方面,研究者们采用多种方法提取手写文字的特征,如笔画特征、结构特征、形态特征等。
这些特征能够有效地反映手写文字的形态和结构,为后续的识别提供重要依据。
在模型训练方面,研究者们利用大量标注数据训练出能够准确识别蒙古文手写文字的模型。
这些模型通常采用机器学习算法或深度学习算法,能够自动学习和提取手写文字的特征,提高识别的准确率。
在识别算法方面,研究者们根据具体应用场景选择合适的算法。
例如,在离线手写识别中,研究者们采用基于模板匹配的算法或基于神经网络的算法;在线手写识别则更加注重对手写过程的动态分析和建模。
五、挑战与展望尽管蒙古文脱机手写识别技术取得了一定成果,但仍面临诸多挑战。
首先,手写文字的多样性使得特征提取和模型训练的难度较大;其次,标注数据的获取和处理也是一项复杂而繁琐的工作;此外,现有算法在处理复杂场景和多种字体时仍存在一定局限性。


《蒙古文脱机手写识别研究》篇一一、引言随着信息技术的快速发展,手写识别技术已成为一项重要的研究领域。
特别是在少数民族语言环境中,如蒙古文等,脱机手写识别技术的发展具有更重要的意义。
此技术能够帮助我们更快速、更准确地获取和处理蒙古文手写信息,从而提高文字处理的效率和准确性。
本文将对蒙古文脱机手写识别的相关研究进行详细的阐述和分析。
二、蒙古文脱机手写识别的背景和意义蒙古文作为一种独特的文字系统,其书写风格和结构具有鲜明的民族特色。
然而,由于手写文字的多样性和复杂性,蒙古文手写识别的准确性和效率一直是研究的难点。
脱机手写识别技术可以在不依赖于任何书写工具或设备的条件下,通过对手写文字的分析和识别,实现对文字的输入和转化。
这对于提高蒙古文信息处理的速度和准确性具有重要意义。
三、蒙古文脱机手写识别的技术方法(一)特征提取特征提取是蒙古文脱机手写识别的关键步骤之一。
通过对手写文字的形状、结构、笔画等特征进行提取,可以有效地提高识别的准确性和效率。
目前,常用的特征提取方法包括基于像素的方法、基于轮廓的方法、基于笔画的方法等。
(二)分类器设计分类器是蒙古文脱机手写识别的核心部分。
通过对提取的特征进行分类和判断,可以实现对手写文字的识别。
目前,常用的分类器包括神经网络、支持向量机、决策树等。
其中,神经网络在蒙古文脱机手写识别中具有较好的应用效果。
(三)识别算法优化为了提高蒙古文脱机手写识别的准确性和效率,需要不断对识别算法进行优化。
这包括对特征提取方法的改进、对分类器参数的调整、对算法运行速度的优化等。
同时,还需要考虑算法在实际应用中的可扩展性和可移植性。
四、蒙古文脱机手写识别的研究现状和挑战目前,蒙古文脱机手写识别技术已经取得了一定的研究成果。
然而,由于手写文字的多样性和复杂性,以及蒙古文独特的书写风格和结构,该技术的研发仍然面临诸多挑战。
这包括如何提高识别的准确性和效率、如何处理手写文字的噪声和变形、如何实现算法的实时性和可靠性等。

基于机器学习的离线手写字符识别技术研究近年来,随着机器学习的兴起,各种基于机器学习的技术也逐渐涌现。
离线手写字符识别技术就是其中一种重要的应用场景。
离线手写字符识别技术能够识别手写文本中的字符,将其转换为计算机可读取的形式,从而实现文字识别、字体转换等功能。
在现代社会中,离线手写字符识别技术被广泛应用于银行、邮政、快递、物流、防伪等领域。
一、离线手写字符识别技术的现状目前,离线手写字符识别技术的应用场景已经非常广泛,但是其效果却有待提高。
手写字符涉及到人类,所以没有固定形状和大小,这也给字符识别带来了困难。
而且,手写字符出现频率不高,导致数据样本比较少,这也会影响到识别的准确率。
二、基于机器学习的离线手写字符识别技术原理机器学习是指计算机通过大量的数据进行学习和训练,从而得到事物之间的相关规律和规律之间的关系。
这种方法十分适合于离线手写字符识别技术的应用场景。
机器学习的过程可以分为数据预处理、特征提取、模型训练和模型评估四个部分。
数据预处理:将离线手写字符转换成数字矩阵,便于计算机处理。
数字矩阵中的每一个元素代表字符的一个像素,值为0或1。
特征提取:选取特定的像素位置,并将其数值组合成特征向量,然后将多个特征向量合并,形成一个特征矩阵。
模型训练:选定合适的机器学习算法,对特征矩阵进行训练。
常用的机器学习算法包括支持向量机、随机森林、神经网络等。
模型评估:使用测试集对模型进行评估,得到模型的准确率、召回率、F1分数等指标。
通过以上过程,机器学习就可以生成一个可以识别离线手写字符的模型。
三、目前的离线手写字符识别技术存在的问题虽然基于机器学习的离线手写字符识别技术已经在一定程度上解决了问题,但是仍然存在许多问题。
首先,基于机器学习的离线手写字符识别技术需要大量的数据集来训练模型。
但是,在实际应用中,手写字符数据集往往较小,难以满足训练数据的需求,从而影响模型的精度和可靠性。
其次,由于手写字符不具有固定的形状和大小,而且人类写字的习惯也不同,所以同一字符出现的形状和大小也不同。

《蒙古文脱机手写识别研究》篇一一、引言在信息技术高速发展的今天,计算机手写识别技术逐渐成为了研究的热点之一。
对于具有独特书写体系的蒙古文而言,脱机手写识别技术的发展尤为关键。
蒙古文因其独特性和复杂性,其识别率直接影响到文字信息化的效率和准确性。
本文旨在深入探讨蒙古文脱机手写识别技术的研究现状及前景,以期为相关研究提供理论依据和技术支持。
二、蒙古文脱机手写识别的现状蒙古文脱机手写识别技术的研究始于上世纪末,经过多年的发展,已经取得了一定的成果。
然而,由于蒙古文书写风格的多样性和复杂性,以及书写工具、纸张等外部因素的影响,使得蒙古文脱机手写识别的准确率仍有待提高。
目前,蒙古文脱机手写识别技术主要面临以下几个问题:1. 识别准确率有待提高。
受书写风格、字形变化等因素的影响,蒙古文手写识别的准确率仍然较低。
2. 算法复杂度高。
为了满足识别准确性的要求,现有算法通常较为复杂,导致处理速度较慢,难以满足实时应用的需求。
3. 缺乏标准化数据集。
蒙古文手写识别的研究需要大量的训练数据,而目前缺乏标准化、公开可用的数据集,制约了研究的进展。
三、蒙古文脱机手写识别的技术研究针对上述问题,本文提出以下几种可能的解决方案和技术研究方向:1. 深度学习技术的应用。
深度学习在图像识别领域取得了显著的成果,可以尝试将深度学习技术应用于蒙古文脱机手写识别中,提高识别准确率。
2. 特征提取技术的改进。
针对蒙古文书写风格的多样性,可以通过改进特征提取技术,提取更具有代表性的特征,提高识别的准确性。
3. 构建标准化数据集。
为了促进蒙古文脱机手写识别技术的发展,需要构建标准化、公开可用的数据集,为研究提供充足的数据支持。
4. 优化算法设计。
针对算法复杂度高的问题,可以通过优化算法设计,降低算法复杂度,提高处理速度,满足实时应用的需求。
四、研究前景随着信息技术的不断发展,蒙古文脱机手写识别技术具有广阔的应用前景。
未来可以尝试将该技术应用于以下领域:1. 文字输入领域。

脱机手写体汉字识别方法的研究的开题报告题目:脱机手写体汉字识别方法的研究一、研究背景及意义手写体汉字是中文书写的重要形式之一,但由于每个人的书写习惯、风格不同,手写体汉字的识别一直是计算机视觉领域的难点之一。
这个问题一直对文字识别、自然语言处理等相关领域的研究产生了重要影响。
目前,随着深度学习技术的发展,手写体汉字的识别也变得更加准确和实用。
然而,传统的在线手写字识别中,需要使用笔尖及其在纸面上留下的轨迹,以便更好地确定书写者所书写的汉字。
这种方法虽然准确度很高,但是可能不太适用于一些场景,比如智能手机、平板电脑等移动设备,因为这些设备没有任何手写笔在运动时留下的轨迹信息。
因此,脱机手写体汉字识别,作为一种新型的处理方式,目前正受到越来越多的关注。
本研究旨在探索脱机手写体汉字识别的新方法,以提升其准确性和实用性,为汉字信息处理领域的发展做出积极的贡献。
二、研究内容和方法本研究将主要聚焦以下三个方面:1. 脱机手写体汉字数据集的建立。
由于缺少足够的脱机手写体汉字数据集,本研究将首先建立一个大规模的脱机手写体汉字数据集。
我们将利用现有的在线手写体汉字数据集,并利用一系列的前后处理方法,转化为具有脱机手写体的特征的数据集。
我们将针对该数据集,开展进一步的识别实验,以评估我们的算法性能。
2. 脱机手写体汉字特征提取方法研究。
本研究将基于深度学习技术对脱机手写体汉字中的特征进行提取。
具体来说,我们将采用卷积神经网络(CNN)和循环神经网络(RNN)等算法,来设计和优化脱机手写体汉字的特征提取模型。
3. 脱机手写体汉字识别算法研究。
我们将利用深度学习的技术,开发具有高准确率,高稳定性,和高实用性的脱机手写体汉字识别算法。
我们将首先对所建立数据集进行批量测试,以评估我们算法的实际应用性能,并与现有手写体识别方法进行对比。
三、预期成果本研究预期的主要成果包括以下内容:1. 脱机手写体汉字数据集的建立,该数据集包含样本的数量和种类均达到了先进水平。
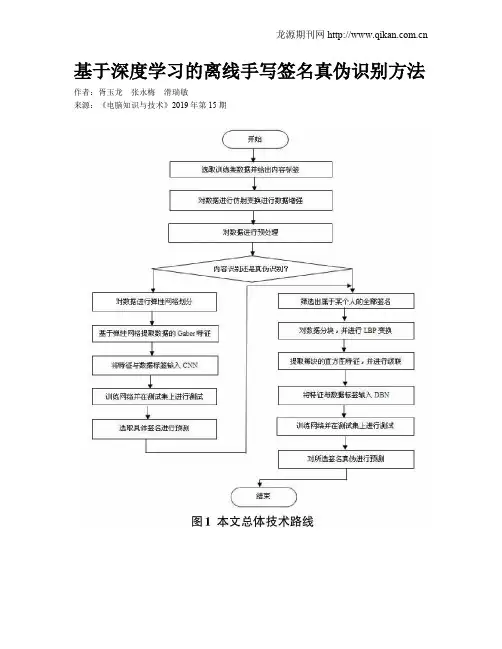
基于深度学习的离线手写签名真伪识别方法作者:胥玉龙张永梅滑瑞敏来源:《电脑知识与技术》2019年第15期摘要:针对手写签名样本数据量少、需要较高准确率的特点,设计了一种基于弹性网格的Gabor特征提取结合卷积神经网络的离线手写签名内容识别方法,利用仿射变换扩展数据集,基于弹性网格提取Gabor特征,训练带有BN层和Dropout层的卷积神经网络进行签名内容分类。
提出了一种LBP特征提取算法结合深度置信网络的离线手写签名真伪识别方法,分块提取LBP直方图特征,进行特征合并,训练由三层受限玻尔兹曼机堆叠而成的深度置信网络进行签名真伪识别。
实验结果表明,该方法可以有效提高离线手写签名分类和真伪识别的准确率,并减少了过拟合现象的发生。
关键词:弹性网格;Gabor特征;卷积神经网络;深度置信网络;离线手写签名中图分类号:TP391 ; ; ; ;文献标识码:A文章编号:1009-3044(2019)15-0228-05Abstract: Considering less sample data quantity and higher accuracy in handwritten signature,design an off-line handwritten signature content identification method combined with Gabor feature extraction based on spring mesh and Convolutional Neural Networks (CNN). The data sets are extended by affine transformation, Gabor features are extracted based on spring mesh, and CNNwith the BN layer and the Dropout layer is trained for signature content classification. An LBP featureextraction algorithm in combination with Deep Belief Networks (DBN) offline identification for signature authenticity method is proposed. LBP histogram features are extracted on the block and merged, and the DBN formed by the three-layer Restricted Boltzmann Machines is trained for signature authenticity. The experiment results show the methods can effectively improve the accuracy of off-line handwritten signature classification and authenticity, and reduce the occurrence of overfitting phenomenon.Key words: spring mesh; Gabor features; Convolutional Neural Networks; Deep Belief Networks; off-line handwritten signature1 引言身份鉴别手段,文字书写具有通用性、独特性、易获取等优点,因而在用户中易于推广普及。

脱机手写体汉字识别技术研究[摘要]脱机手写体汉字识别是汉字高速、自动输入计算机的重要手段,是智能计算机接口的一个重要组成部分,在文献检索、办公自动化、邮政系统、银行票据处理、表格录入及盲人阅读机等方面有着广阔的应用前景。
脱机手写体汉字识别因其自身的复杂性,使得系统的实现具有很大的困难,目前还没有十分成熟的产品,是一门待发展的技术,因此它成为了国内外研究的热点。
[关键词]脱机手写体汉字识别特征提取分类器脱机手写体汉字识别是从扫描仪或数字式照相机等图像输入设备获取已经写好的文件或单据后,再对全文进行手写汉字或符号的识别,并将结果输入到计算机中存档。
一、研究现状及技术困难(一)研究历史及现状。
对汉字识别研究最早的是美国IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,用模板匹配法识别1000个印刷体汉字,从此在世界范围内拉开了汉字识别研究的序幕。
手写体汉字识别的研究最早始于20世纪70年代中期的日本,我国则在80年代初期开始进行手写体汉字识别的研究。
目前进行手写体汉字识别研究的国家和地区主要集中在中国、日本、中国台湾、美国和加拿大,实际应用水平最高的首推日本。
尽管一些实验系统已经达到了较高的识别率,然而这些系统性能的好坏在很大程度上依赖于手写汉字样本质量,绝大多数对书写的规范性都有较严格的要求。
因此,可以说脱机手写体汉字识别目前仍然处于实验阶段,要研制出通用性高、性能稳定的实用系统,则是任重而道远。
(二)面临的技术困难。
脱机手写体汉字识别技术中存在的困难是多方面的。
就识别对象本身而言,客观上的技术困难主要有:1.汉字类别多。
国标一级汉字3755个。
二级汉字6763个。
2.汉字字形结构复杂。
平均每个汉字的笔划数约为11,不可避免会带来一些障碍,如连笔、笔划不清、畸变等。
3.汉字集合中相似字较多,手写时变形的存在,产生较印刷体更多的相似字。
4.手写体汉字的变形因人而异,差别很大,具体表现在以下方面:①基本笔划变化,横不平,竖不直,直笔变弯,折笔的拐角变成圆弧等;②笔划模糊,不规范,该连的不连,不该连的却相连;③笔划与笔划之间、部件与部件之间的位置发生变化;④笔划的倾斜角、笔划的长短、部件的大小发生变化:⑤笔划的粗细变化,主要由于不同人使用不同的书写笔。

《蒙古文脱机手写识别研究》篇一一、引言随着信息化时代的到来,文字识别技术得到了广泛的应用。
其中,手写文字识别技术作为一种重要的输入方式,具有很高的实用价值。
在众多文字体系中,蒙古文手写识别技术的研究具有重要的意义。
本文旨在探讨蒙古文脱机手写识别技术的研究现状、研究方法及存在的问题,并提出相应的解决方案。
二、蒙古文脱机手写识别的研究现状蒙古文脱机手写识别技术是指在没有计算机辅助设备的情况下,通过计算机对蒙古文手写文字进行自动识别的技术。
近年来,随着人工智能技术的不断发展,蒙古文脱机手写识别技术取得了显著的进展。
目前,蒙古文脱机手写识别技术主要采用基于特征提取和分类器的方法。
通过对手写文字的形状、结构、纹理等特征进行提取,并利用机器学习算法进行分类和识别。
同时,随着深度学习技术的发展,基于神经网络的蒙古文脱机手写识别技术也得到了广泛的应用。
然而,蒙古文脱机手写识别技术仍存在一些问题。
首先,由于蒙古文字形复杂、书写风格多样,导致识别准确率较低。
其次,现有算法对于复杂的手写文字和噪声干扰等复杂情况的处理能力还有待提高。
此外,缺乏大规模的蒙古文手写数据集也是制约蒙古文脱机手写识别技术发展的重要因素之一。
三、研究方法针对上述问题,本文提出了一种基于深度学习的蒙古文脱机手写识别方法。
该方法主要包括以下几个步骤:1. 数据预处理:对收集到的蒙古文手写数据进行预处理,包括去噪、归一化、分割等操作,以便于后续的特征提取和分类识别。
2. 特征提取:利用深度学习算法对预处理后的数据进行特征提取。
通过构建卷积神经网络等模型,提取出手写文字的形状、结构、纹理等特征。
3. 分类识别:将提取出的特征输入到分类器中进行分类和识别。
采用支持向量机等算法对手写文字进行分类和识别。
4. 模型优化:通过不断调整模型参数和结构,优化模型的性能,提高识别准确率。
四、实验结果与分析本文采用大规模的蒙古文手写数据集进行实验,并与传统算法进行对比分析。

《蒙古文脱机手写识别研究》篇一一、引言随着信息技术的飞速发展,手写识别技术已成为人工智能领域的重要研究方向。
蒙古文作为世界上独特的文字之一,其手写识别技术在近年来受到了广泛的关注。
本文旨在研究蒙古文脱机手写识别技术的发展现状,以及相关的技术和算法。
二、蒙古文脱机手写识别技术的现状蒙古文手写识别技术的发展历经了数十年的研究,取得了显著的成绩。
脱机手写识别技术相较于联机手写识别技术,具有更高的灵活性和便利性。
在蒙古文手写识别的研究中,主要面临的问题包括文字的形态多样性、文字的连笔现象等。
目前,蒙古文脱机手写识别的研究已经取得了较大的进展。
在特征提取方面,研究人员通过使用多种特征描述方法,如笔划特征、结构特征、统计特征等,有效地提高了识别的准确率。
在分类器设计方面,采用了多种机器学习算法和深度学习算法,如支持向量机、神经网络、卷积神经网络等,为蒙古文手写识别提供了强大的技术支持。
三、关键技术与算法1. 特征提取技术特征提取是蒙古文脱机手写识别的关键技术之一。
研究人员通过提取笔划特征、结构特征、统计特征等多种特征描述方法,对蒙古文字符进行描述和表达。
其中,笔划特征主要关注笔画的形态和顺序;结构特征则关注字符的空间布局和结构关系;统计特征则通过分析字符的统计规律来提取特征。
2. 分类器设计分类器是蒙古文脱机手写识别的核心部分。
研究人员采用了多种机器学习算法和深度学习算法来设计分类器。
其中,支持向量机是一种常用的分类器设计方法,它通过将数据映射到高维空间来实现分类;神经网络和卷积神经网络则是深度学习算法的代表,它们可以通过训练大量的数据来自动提取特征和设计分类器。
4. 实验与结果分析为了验证蒙古文脱机手写识别技术的效果,我们进行了大量的实验。
首先,我们采用了公开的蒙古文手写数据集进行实验,并比较了不同算法的识别效果。
实验结果表明,基于深度学习的算法在蒙古文脱机手写识别中具有较高的准确率和稳定性。
其次,我们还对不同特征提取方法和分类器设计进行了比较和分析,得出了各种方法的优缺点和适用场景。

《蒙古文脱机手写识别研究》篇一一、引言随着信息技术的快速发展,手写识别技术已成为一项重要的研究领域。
蒙古文脱机手写识别作为其中的一个分支,具有其独特的挑战性和应用价值。
本文旨在探讨蒙古文脱机手写识别的研究现状、方法及挑战,以期为相关研究提供参考。
二、蒙古文脱机手写识别的研究背景及意义蒙古文作为世界上较为独特的文字之一,其书写风格独特,字形复杂。
脱机手写识别技术能够在无网络环境下实现文字的输入与识别,对于提高蒙古族地区的信息化水平、促进民族文化的传承与发展具有重要意义。
同时,蒙古文脱机手写识别技术的研究也有助于推动人工智能、模式识别等领域的发展。
三、蒙古文脱机手写识别的研究现状目前,蒙古文脱机手写识别技术已取得了一定的研究成果。
然而,由于蒙古文字形的复杂性和多样性,以及书写风格的差异,使得识别率仍有待提高。
现有的研究主要集中在手写数据的采集、预处理、特征提取、分类器设计等方面。
其中,特征提取和分类器设计是提高识别率的关键。
四、蒙古文脱机手写识别的研究方法针对蒙古文脱机手写识别的特点,本文提出以下研究方法:1. 数据采集:通过收集大量的蒙古文手写样本,建立手写数据库。
在数据采集过程中,应充分考虑不同年龄、性别、地域等因素的影响,以保证数据的多样性和代表性。
2. 数据预处理:对采集的手写数据进行预处理,包括去噪、归一化、二值化等操作,以提高识别的准确性。
3. 特征提取:针对蒙古文字形的特点,采用合适的方法提取手写数据的特征。
如基于笔画、结构、形状等特征的提取方法。
4. 分类器设计:根据提取的特征,设计合适的分类器进行识别。
如基于神经网络、支持向量机、决策树等分类算法的应用。
5. 模型优化:通过对比实验,对模型进行优化,提高识别率。
同时,对模型进行泛化能力的评估,以适应不同书写风格和字形变化的情况。
五、面临的挑战与展望尽管蒙古文脱机手写识别技术取得了一定的研究成果,但仍面临诸多挑战。
首先,蒙古文字形的复杂性和多样性使得特征提取和分类器设计具有较大的难度。
脱机手写体汉字识别中细化、特征提取和相似字识别算法研究中文信息处理汉字象形文字汉字的输入编码方案(拼音,五笔等)人机交互OCR系统有:TH—OCR、BI—OCR、SY—OCR汉字识别能否通过市场这一严峻的考验,主要取决于两个重要因素:识别方案是否具有较好的抗干扰能力,是否能适应实际应用环境中各种干扰噪声的影响,并保持较高的识别正确率,满足实际应用的要求识别系统是否可以根据用户和市场的需求,不断及时地改进系统的性能指标和使用环境,从而在激烈的市场竞争中取得一席之地。
目前,印刷体汉字的识别率已经达到了99%以上,联机手写体汉字的识别率已经达到了99%,但是脱机手写体汉字的识别率较低,还不能满足社会的迫切需求目前的脱机手写体汉字识别系统存在的主要问题有:识别结果受图像质量影响较大预处理和后处理在系统中的作用还需要不断加强对于自由书写汉字的识别仍然不能令人满意提取的特征区分能力较弱,难以适应不同字型的变换典型的脱机手写体汉字识别系统由前段数字化输入装置、预处理系统、识别系统和后处理系统四大部分组成进行脱机手写体汉字识别时,首先用输入装置将写在介质上的原始文本通过光电扫描仪等输入设备转换成二维图像信号(可以是灰度图像或二值图像):然后进行行、字切分,将整页版面的原始图像先按书写行分割开后从每行中切分出单个汉字图像,送入单字识别部分进行处理。
单字识别依次包括预处理、特征提取、匹配识别。
其中,预处理通常有大小归一化、二值化、平滑、细化等:特征提取是从预处理后的图像中按一定的方式获取代表汉字特征的一组向量;最后,将汉字特征向量与模板特征向量按一定的原则进行匹配判决,以此确定待识汉字的类别。
单字识别完成后对识别结果进行后处理,即对单字识别的结果利用语言知识等上下文先验信息进行确认或纠错。
(1)手写体汉字风格众多,随意性较大,几乎无规律可循。
特别市对于脱机手写汉字,不同的书写风格导致的汉字的变形差别很大,即使是同一个人使用不同的书写笔或纸张等写出来的笔画也可能不一样。
离线手写签名识别技术研究在当今社会,签名识别技术已经成为日常生活和工作中不可或缺的一部分。
而在诸多应用场景中,离线手写签名识别技术的价值尤为凸显。
本文将详细介绍离线手写签名识别技术的原理、实现方法、优化策略以及实际应用效果,旨在强调该技术的研究意义和价值。
离线手写签名识别技术是通过对输入的签名图像进行特征提取和匹配,从而识别出签名者的身份。
其实现方法主要分为以下几个步骤:预处理:首先对输入的签名图像进行预处理,包括去噪、二值化、分割等操作,以提高图像质量。
特征提取:通过对预处理后的图像进行特征提取,获取签名的关键信息,如笔画方向、长度、宽度等。
模板匹配:将提取的特征与事先存储的模板进行匹配,找出最相似的模板,进而确定签名者的身份。
离线手写签名识别技术所面临的挑战和难点主要包括以下几个方面:签名的复杂性和多样性:由于每个人的书写习惯和方式不同,使得签名具有很大的变化性和复杂性,这给识别技术带来了很大的难度。
签名的变形和失真:在实际应用场景中,签名可能会因为各种原因而产生变形或失真,如情绪紧张、疲劳等,这会导致识别率下降。
伪造和篡改:不法分子可能会伪造或篡改他人的签名,这给签名识别技术提出了更高的安全要求。
为了解决上述问题,研究者们不断尝试改进算法和模型,以提高识别准确率和速度。
其中,深度学习技术的兴起为离线手写签名识别带来了新的突破。
通过对大量的签名数据进行训练,深度学习模型能够自动学习签名的特征表示,从而实现更高的识别准确率。
为了进一步提高离线手写签名识别的准确率和速度,研究者们提出了一系列优化和改进策略,主要包括以下几个方面:特征提取方法的优化:通过对特征提取过程进行优化,提高特征的质量和表示能力,从而更好地描述签名的特点。
深度学习模型的选择:针对离线手写签名识别的特点,选择合适的深度学习模型进行训练,以便更好地适应签名的多样性和变形情况。
数据增强技术:利用数据增强技术对训练数据进行扩增,提高模型的鲁棒性和泛化能力,从而减少对特定签名数据的依赖。
《蒙古文脱机手写识别研究》篇一一、引言随着人工智能技术的发展,脱机手写识别技术在多语言场景下越来越受到研究者的关注。
对于非计算机直接输入文字,特别是少数民族语言文字的手写识别领域,脱机手写识别技术的重要性愈发凸显。
本篇论文旨在研究蒙古文脱机手写识别技术的相关研究现状,提出研究意义和挑战,以及展望未来研究方向。
二、蒙古文脱机手写识别的研究现状在国内外,针对蒙古文脱机手写识别的研究已取得一定成果。
其中,包括识别算法的改进、训练数据集的完善、识别精度的提升等方面。
随着深度学习技术的快速发展,越来越多的研究者开始将这一技术应用于蒙古文脱机手写识别中。
同时,该技术也被广泛用于解决文字录入等问题,如语音识别和语音输入系统中蒙古文的辅助识别。
三、研究方法及技术应用针对蒙古文脱机手写识别的问题,我们可以从多个角度进行研究。
首先,通过分析和优化识别算法来提高识别准确率。
具体来说,可以尝试利用神经网络技术对输入的手写蒙古文字符进行分类和预测,并通过不断地训练和调整网络参数来优化模型。
其次,为了增强模型对不同书写风格和书写习惯的适应性,我们需要构建更加完善的数据集,包括不同书写风格、不同笔迹、不同字体的样本等。
此外,我们还可以结合图像处理技术对手写文字进行预处理和后处理,以提高识别的准确性和稳定性。
四、挑战与展望尽管蒙古文脱机手写识别技术在一定程度上已经取得了成功,但仍存在许多挑战和问题需要解决。
首先,不同人的书写风格和习惯存在差异,这使得模型对不同人的书写方式的适应性成为一大难题。
其次,对于某些复杂的蒙古文字符,由于字形相似度较高或存在混淆的情况,导致识别准确率不高。
此外,随着科技的发展和应用的普及,用户对于识别速度和准确性的要求也在不断提高。
因此,未来的研究方向包括进一步提高算法的准确性、速度和稳定性,同时也要关注算法在不同书写风格、书写环境和语言环境下的适用性。
五、结论总体来说,蒙古文脱机手写识别技术在研究与应用中均具有重要意义。
脱机手写体汉字识别中的细化算法研究的开题报告一、选题背景与意义随着智能手机和平板电脑的广泛普及,手写输入法成为一种流行的输入方式,但如何对离线手写体汉字进行准确、快速的识别一直是一个重要的研究课题。
对于手写体汉字的识别,细化算法是一个关键的技术。
通过对手写汉字进行细化,可以得到汉字笔画的详细信息,从而提高汉字的识别精度。
因此,本文基于脱机手写体汉字识别中的细化算法,开展研究工作,旨在提高汉字识别的准确率和稳定性。
二、研究内容与方法1. 研究内容本研究的主要内容包括以下方面:(1) 对汉字进行二值化处理,将图像转化为二值图像,减少干扰。
(2) 提取汉字的轮廓信息,确定汉字的边界。
(3) 进行细化算法,得到汉字笔画的精细信息。
(4) 设计基于深度学习的汉字识别模型,提高识别准确率。
2. 研究方法针对研究内容,本研究将采用以下研究方法:(1) MATLAB编程实现汉字的二值化处理、轮廓提取和细化算法。
(2) 基于TensorFlow框架搭建深度学习模型,进行汉字识别。
(3) 对比分析细化算法前后的汉字识别准确率及稳定性。
三、预期成果与意义1. 预期成果(1) 实现脱机手写体汉字的二值化处理、轮廓提取和细化算法。
(2) 搭建基于深度学习的汉字识别模型,提高识别准确率。
(3) 对比分析细化算法前后的汉字识别准确率及稳定性。
2. 意义(1) 通过对脱机手写体汉字进行细化算法,可以得到更加精细的汉字笔画信息,从而提高汉字识别的准确率和稳定性。
(2) 基于深度学习的汉字识别模型可以有效提高识别准确率,而本文基于脱机手写体汉字识别中的细化算法,进一步提高了汉字的识别精度。
(3) 本研究的成果可以应用到智能手机、平板电脑等设备中,提高手写输入法的识别效果,具有一定的实际应用价值。
四、研究进度安排本研究的进度安排如下:(1) 第一阶段(1-2周):收集相关文献,熟悉细化算法和深度学习技术。
(2) 第二阶段(3-4周):编写汉字的二值化处理、轮廓提取和细化算法程序。
摘要摘要在人们的很多生活场合,都离不开签名。
而签名作为一种身份鉴别的方式,在商务、金融、司法、保险等众多领域中都有着广泛的应用,可以说签名在当今社会生活中扮演着重要的角色。
因此实现计算机自动签名鉴别具有很大的实用价值。
签名鉴别属于一种特殊的模式识别技术,本文重点研究在离线状态下的签名鉴别技术,并在此理论研究的基础上实现一套高效率的离线签名自动识别系统。
离线签名鉴别(脱机手写签名鉴别)的主要困难在于签名特征的提取。
因此本文在大量的学者研究的基础上对签名特征进行总结研究,提出了一套基于签名纹理的特征提取方法。
并采用PCNN神经网络的方法进行签名特征提取,以及结BP 神经网络,支持向量机等多种分类方式进行识别鉴定。
本文的创新型主要归纳如下:1、在签名图像预处理阶段,针对多个签名采样如何进行的自动划分和提取问题,提出了一种基于种子领域的提取算法。
此算法运算效率高,能较好的提取同一个采样中的多个签名.2、在签名特征提取阶段,引入签名纹理分析方式。
对签名纹理特征进行分析和归纳,并且首次将PCNN(脉冲耦合神经网络)作为签名纹理特征的提取方法。
并与其他的纹理算法进行比较分析。
得出一个高效且鉴别率较高的特征提取方法。
在已有采样数据库测试FAR和FRR分别能达到4%和2%3、在前面纹理分析的方法上结合其他学者的研究成果,将纹理分析和其他特征提取方法相结合,得到一个鉴别率很高的离线签名特征提取系统。
4、采用BP神经网络、支持向量机等多种分类器构建了一个稳定的并且较为实用的自动签名鉴别系统。
关键词:离线签名鉴别,纹理分析,PCNNABSCTRACTABSTRACTLiving in a lot of people's occasions,can not be separated from Signature. Signature and identification as a way,in business,finance,justice,and many other areas of insurance have a wide range of applications,it can be said Signature Living in today's society plays an important role. Signature therefore automatically identify your computer implementation of great practical value.Signature identification belong to a special kind of pattern recognition technology,this article focuses on the offline signature verification technology,and at the basis of this theoretical study on the implementation of a highly efficient off-line signature recognition system automatically.Off-line signature verification (off-line handwritten signature verification) the main difficulty lies in extracting features of Signature. So many scholars in this article on the basis of summing up of the signature characteristics of a study and submit a set of signature-based methods of texture feature extraction. And the use of neural network PCNN signature feature extraction methods,as well as the node BP neural networks,support vector machines for classification and other identification.The main innovation of this article are summarized as follows:1,in the signature image pre-processing stage,a number of signature samples for how to proceed with the automatic delineation and extraction of problem,aseed-based algorithm for extracting the field. Efficient operation of this algorithm can extract a better sampling of the same number of signatures.2,in the Signature feature extraction stage,the introduction of Signature texture analysis. Signature characteristics of texture analysis and summarized,and the first time PCNN (Pulse Coupled Neural Network) as a signature method of texture feature extraction. And other comparative analysis of texture algorithms. Identification of efficient and arrive at a higher rate of feature extraction methods. Sample database has been tested in the FAR and FRR to achieve 4%,respectively,and 2%3,in front of the method of texture analysis in combination with other academics on the research results will be texture analysis and other feature extraction methods combined with a high rate of identification of off-line signature feature extraction system.4,using BP neural networks,support vector machine classifier,etc. Construction of a stable and more practical system of automatic signature verification.Key words: Off-line Signature Verification,Texture analysis,PCNN目录第一章引言 (1)1.1课题背景 (1)1.1.1 生物识别技术概况 (1)1.1.2签名鉴定的分类及特点 (2)1.1.3 传统的中文签名鉴定 (4)1.2离线签名鉴别的国内外发展现状 (4)1.3离线签名鉴别的难点 (7)1.4本文的工作及组织结构: (7)第二章相关理论与方法 (9)2.1 采集及预处理阶段 (9)2.1.1降噪 (10)2.1.1.1 中值滤波方法 (10)2.1.1.2 新兴的噪声抑制方法 (11)2.1.2二值化图像 (11)2.1.2.1基于最大熵的直方图阀值分割算法[11] (12)2.1.2.2基于最大类间方差法(OTSU) (12)2.1.3图像灰度化处理了 (13)2.1.4图像细化 (13)2.1.5 签名提取(注:该内容已经发表在《四川经济管理学院学报》2009年第二期P53) (17)2.2 签名特征提取阶段 (22)2.2.1基于灰度共生矩阵的签名图像特征提取 (24)2.2.2基于不变量的签名图像特征提取 (27)2.3 签名识别阶段 (31)第三章基于脉冲耦合神经网络的离线签名鉴定 (33)3.1 PCNN模型 (33)3.1.1基本模型 (33)3.1.2 PCNN模型主要特征 (35)3.1.3 PCNN用于特征提取的理论分析 (35)3.2 PCNN熵时间序列特征提取 (37)3.3 实验结果 (38)第四章基于微粒群PSO神经网络的离线签名鉴定 (40)4.1微粒群算法(PSO ) (40)4.1.1 PSO算法理论概述 (40)4.1.2 PSO算法流程 (42)4.1.3 PSO算法与人工神经网络 (42)4.2 PSO 神经网络模型(PSO-NN模型) (42)4.3实验结果 (45)4.4本章小结 (49)第五章离线签名自动鉴定系统 (51)电子科技大学硕士学位论文5.1系统概述 (51)5.2系统功能 (52)5.3 系统分析 (52)5.3.1 Use Case diagram (53)5.3.2 Activity Diagram: (53)5.3.3 Sequence Diagram (54)5.3.4 Class diagram (55)5.4 系统模块设计 (56)5.4.1 图像采集模块 (56)5.4.2 图像预处理模块 (56)5.4.3 签名识别模块 (57)5.5系统评价 (58)第六章结论与展望 (59)致谢 (60)参考文献 (61)附录:离线签名自动鉴定系统设计 (64)主要类代码: (64)class ImgFilter //改类实现图像处理的大部分操作。
离线手写签名鉴别技术研究的开题报告一、研究背景和意义在现代社会中,签名被广泛运用于各个领域中,比如合同签署、银行业务申请和授权、电子商务支付等,它是一种认证和协议确认的手段。
然而,签名的防伪性、真实性和合法性一度备受质疑,特别是手写签名。
因为手写签名容易模仿、伪造,这对真实确认签名的有效性和公正性产生了不利影响。
离线手写签名鉴别技术,是一种通过对离线手写签名进行数字化处理的方法,来确保签名的真实性和合法性,从而避免伪造和欺诈可能。
该技术已经广泛应用于银行、保险、公证等领域,成为手写签名认证的技术之一。
因此,本文拟对离线手写签名鉴别技术进行研究,以期提高手写签名的确认效率和准确度。
二、研究内容与目的本研究将围绕“离线手写签名鉴别技术”这一主题,探讨其在实际应用中存在的问题和瓶颈,同时提出并开发相关算法和方法。
具体包括:1. 研究离线手写签名的特点和构成要素,深入探讨不同人、不同时间、不同工具和不同状态下的离线手写签名类型和特征。
2. 研究离线手写签名鉴别技术的现有研究成果和存在的问题,重点探讨其缺陷和局限性,如对签名的准确性、鲁棒性、复杂度和时间处理速度等的要求。
3. 开发一套基于机器学习和深度学习技术的离线手写签名鉴别系统。
该系统会针对离线手写签名的特征进行分类和判定,包括签名的大小、方向、形状、笔画和压力等多项因素,来进行鉴别对比和确认该签名的真实性和合法性。
4. 对比分析开发的鉴别系统与其他现有的离线手写签名鉴别技术,分析其效率和准确度,从而推进该技术的应用和发展。
三、研究方法1. 文献调研法系统收集与离线手写签名认证技术、模式识别、机器学习和深度学习等领域相关的论文和书籍,以了解目前离线手写签名鉴别技术的现状和存在的问题,为本研究提供理论和方法支持。
2. 数据采集与处理法采集现有的离线手写签名数据,并通过标准的数据预处理方法进行数字化处理,包括图像修复、图形剪裁、特征提取和数据归一化等步骤。