Oracle中比对2张表之间数据是否一致的几种方法
- 格式:pdf
- 大小:914.37 KB
- 文档页数:25

竭诚为您提供优质文档/双击可除2个excel表格如何比对数据篇一:如何比较两个电子表格数据的异同1、如何比较两个电子表格数据的异同?1、新建一个excel文件,将两个人的两张表格分别复制到sheet1和sheet2;2、切换到sheet3中,选中a1单元格,输入公式:=if(sheet1!a1=sheet2!a1,"ok","结果不同");3、采用拖拉复制的办法将这个公式单元格的内容复制到与原表格相同大小的位置;4、结果已经呈现在你的面前--凡是单元格内有“结果不同”字样的,表明相应位置的两张表格内容是不一样的;凡是有“ok”字样的单元格,说明两张表格的内容是相同的。
2、钢筋符号打印到word中程序→附件→系统工具→字符映射表→sjqy篇二:两个excel表格核对的6种方法两个excel表格核对的6种方法,用了三个小时才整理完成!20xx-12-17兰色幻想-赵志东excel精英培训excelpx-teteexcel应用分享与问题解答,提供excel技巧、函数和Vba相关学习资料的自助查询。
每天一篇原创excel教程,伴你excel学习每一天!excel表格之间的核对,是每个excel用户都要面对的工作难题,今天兰色带大家一起盘点一下表格核对的方法,一共6种,以后再也不用加班勾数据了。
(兰色用了三个小时整理出了这篇教程,估计你再也找不到这么全的两表核对教程,一定要转发或收藏起来备用哦)一、使用合并计算核对excel中有一个大家不常用的功能:合并计算。
利用它我们可以快速对比出两个表的差异。
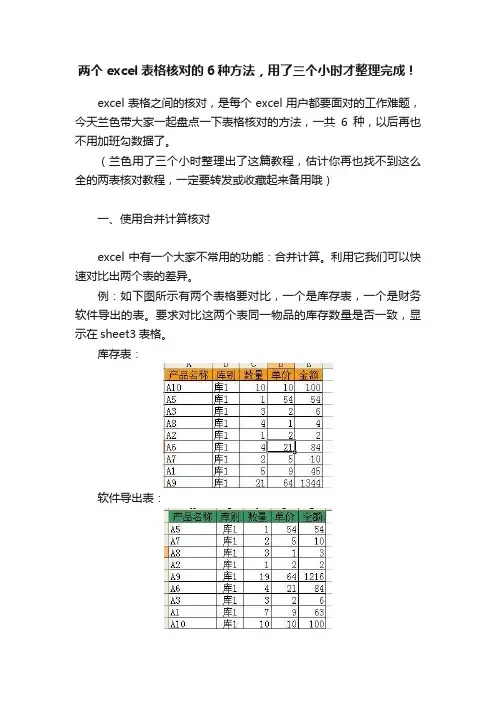
例:如下图所示有两个表格要对比,一个是库存表,一个是财务软件导出的表。
要求对比这两个表同一物品的库存数量是否一致,显示在sheet3表格。
库存表:软件导出表:操作方法:步骤1:选取sheet3表格的a1单元格,excel20xx版里,执行数据菜单(excel20xx版数据选项卡)-合并计算。

excel两个单元格内容是否一致在Excel中,我们经常需要比较两个单元格中的内容是否一致。
这种比较可以帮助我们找出数据中的差异,进行有效的数据分析和处理。
接下来,我将介绍几种方法来判断两个单元格内容是否一致。
第一种方法是使用IF函数。
IF函数可以根据指定的条件返回不同的数值。
我们可以利用IF函数来比较两个单元格的内容是否一致。
例如,我们可以使用以下公式来比较A1和B1两个单元格的内容是否一致,=IF(A1=B1,"内容一致","内容不一致")。
这样,如果A1和B1的内容相同,公式返回“内容一致”,否则返回“内容不一致”。
第二种方法是使用EXACT函数。
EXACT函数可以比较两个文本字符串是否完全相同。
我们可以将两个单元格的内容作为参数传递给EXACT函数,然后判断它们是否一致。
例如,我们可以使用以下公式来比较A1和B1两个单元格的内容是否一致,=EXACT(A1,B1)。
如果A1和B1的内容完全相同,公式返回TRUE,否则返回FALSE。
第三种方法是使用条件格式化。
我们可以利用条件格式化功能来直观地显示两个单元格的内容是否一致。
首先选中需要比较的单元格范围,然后依次点击“开始”选项卡中的“条件格式化”、“新建规则”、“使用公式确定要格式化的单元格”,在“格式值为”框中输入公式=A1=B1(假设需要比较的单元格分别为A1和B1),然后设置好格式化的样式,点击确定即可。
这样,如果A1和B1的内容一致,对应的单元格将按照我们设置的格式显示。
除了以上提到的方法,我们还可以使用VBA(Visual Basicfor Applications)来编写自定义的比较脚本。
通过编写VBA脚本,我们可以实现更复杂的比较逻辑,满足更多的需求。
例如,我们可以编写一个VBA脚本来批量比较多个单元格的内容,然后将比较结果汇总到一个新的工作表中,以便进一步分析和处理。
总的来说,Excel提供了多种方法来比较两个单元格的内容是否一致。

oracle 两表全字段比较方法在Oracle数据库中,可以使用SQL语句来比较两个表的全字段。
以下是一种可能的方法:1. 创建临时表:首先,你可以创建两个临时表,用于存储要比较的两个表的数据。
例如,你可以使用以下语句创建临时表:```sqlCREATE TABLE temp_table1 AS SELECT FROM table1;CREATE TABLE temp_table2 AS SELECT FROM table2;```这将从表1和表2中复制数据到临时表temp_table1和temp_table2中。
2. 使用NOT EXISTS子查询:接下来,你可以使用NOT EXISTS子查询来比较两个临时表的全字段。
以下是一个示例查询:```sqlSELECT column1, column2, column3, ...FROM temp_table1 aWHERE NOT EXISTS (SELECT 1FROM temp_table2 bWHERE = AND = AND = AND ...);```在上述查询中,你需要将column1、column2、column3等替换为你要比较的实际列名。
该查询将返回在temp_table1中存在但在temp_table2中不存在的行。
3. 处理NULL值:在比较字段时,需要注意处理NULL值的情况。
在Oracle中,NULL不等于NULL,因此需要使用IS NULL或IS NOT NULL 条件来正确比较NULL值。
例如,如果你想比较两个列是否都为NULL或都不为NULL,可以使用以下条件:```sqlIS NULL AND IS NULL OR IS NOT NULL AND IS NOT NULL```请根据你的具体需求进行相应的调整。
请注意,上述方法是一种比较简单的方法,适用于比较两个结构相同且数据量较小的表。
对于更复杂的情况,可能需要使用更高级的SQL技术或工具来执行全字段比较。

核对2列数据是否一致的方法
核对2列数据是否一致,可以通过以下方法进行:
使用“=”法。
选中目标单元格区域,直接输入等号进行比较。
使用快捷键(Ctrl+\)法。
选中目标单元格区域,快捷键Ctrl+\,填充颜色。
使用Exact函数法。
这个函数用于比较指定的字符串是否一致。
使用定位(Ctrl+G或F5)法。
选定目标单元格区域,快捷键Ctrl+G或F5打开【定位】对话框,单击左下角的【定位条件】,选择【定位条件】对话框中的【行内容差异单元格】并【确定】,最后填充颜色即可。
使用If函数法。
在目标单元格中输入公式:=IF(B3=C3,"相同","不相同")。
使用条件格式法。
选定目标单元格区域,单击【开始】选项卡【样式】组中的【条件格式】-【突出显示单元格规则】-【重复值】,打开【重复值】对话框,在第一个下拉列表中选择【唯一】,选择填充色,并【确定】。
使用vlookup函数法。
在Excel中用vlookup函数来对比两列数据是否一致。
请根据具体情况选择合适的方法,如果有更复杂的需求,可以请教Excel使用经验丰富的同事或朋友。

筛选两个表中相同的数据
摘要:
在数据分析和处理过程中,经常会遇到需要筛选两个表中相同数据的需求。
本文将介绍如何使用常见的数据处理工具和技术来实现这一目标,包括使用SQL语句,Excel的VLOOKUP函数和Python 中的pandas库。
引言:
在实际的数据分析和处理中,我们经常需要比较和处理两个或多个数据表中的数据。
有时我们需要找出两个表中相同的数据,以便进行进一步的分析或处理。
这个需求在数据清洗、合并以及数据质量检查等方面都非常常见。
这篇文章将重点介绍如何使用不同的工具和技术来筛选两个表中相同的数据。
一、使用SQL语句筛选相同的数据
SQL是一种广泛应用于关系型数据库的查询语言,它提供了一种强大的方式来处理和操作表中的数据。
具体步骤如下:
1. 创建两个表,并确保它们存储在相同的数据库中。
2. 编写一条SELECT语句,使用JOIN操作符连接两个表,并使用WHERE子句筛选出相同的数据。
3. 执行这条SQL语句,并将结果保存到一个新的表中。
举个例子,假设我们有两个表,一个是\。

oracle小时差值计算
在Oracle数据库中,我们可以使用不同的方法来计算小时差值。
以下是一些常见的方法:
1. 使用DATEDIFF函数:可以使用DATEDIFF函数来计算两个日
期之间的小时差值。
例如,可以使用以下查询来计算两个日期之间
的小时差值:
sql.
SELECT (date2 date1) 24 AS hour_diff.
FROM your_table;
这将返回两个日期之间的小时差值。
2. 使用EXTRACT函数:可以使用EXTRACT函数来提取日期中的
小时部分,并进行计算。
例如,可以使用以下查询来计算两个日期
之间的小时差值:
sql.
SELECT EXTRACT(HOUR FROM (date2 date1)) AS hour_diff.
FROM your_table;
这将返回两个日期之间的小时差值。
3. 使用TIMESTAMPDIFF函数:可以使用TIMESTAMPDIFF函数来计算两个日期之间的小时差值。
例如,可以使用以下查询来计算两个日期之间的小时差值:
sql.
SELECT TIMESTAMPDIFF(HOUR, date1, date2) AS hour_diff.
FROM your_table;
这将返回两个日期之间的小时差值。
以上是一些常见的在Oracle数据库中计算小时差值的方法,你
可以根据自己的需求选择合适的方法来进行计算。
希望对你有所帮助。

oracle 时间比较函数Oracle 时间比较函数Oracle数据库是一种关系型数据库管理系统,它支持SQL语言。
在Oracle数据库中,时间比较函数被广泛使用,用于比较和操作日期和时间数据。
这些函数提供了一种简便的方式来处理时间数据,并允许我们在查询中进行各种时间操作。
在Oracle数据库中,有多个时间比较函数可供使用。
下面将介绍其中一些常用的函数。
1. SYSDATE函数SYSDATE函数返回当前日期和时间。
它返回一个日期类型的值,可以用于比较、计算和显示当前日期和时间。
以下是SYSDATE函数的示例用法:SELECT SYSDATE FROM dual;2. TO_DATE函数TO_DATE函数用于将字符串转换为日期类型。
它接受两个参数,第一个参数是要转换的字符串,第二个参数是指定输入字符串的格式。
以下是TO_DATE函数的示例用法:SELECT TO_DATE('2022-01-01', 'YYYY-MM-DD') FROM dual;3. ADD_MONTHS函数ADD_MONTHS函数用于在给定日期上添加指定的月份。
它接受两个参数,第一个参数是要添加的日期,第二个参数是要添加的月份数。
以下是ADD_MONTHS函数的示例用法:SELECT ADD_MONTHS(SYSDATE, 3) FROM dual;4. MONTHS_BETWEEN函数MONTHS_BETWEEN函数用于计算两个日期之间的月份数。
它接受两个参数,第一个参数是较大的日期,第二个参数是较小的日期。
以下是MONTHS_BETWEEN函数的示例用法:SELECT MONTHS_BETWEEN(TO_DATE('2022-01-01', 'YYYY-MM-DD'), SYSDATE) FROM dual;5. NEXT_DAY函数NEXT_DAY函数用于找到给定日期之后的下一个指定的星期几。

oracle比较表结构
Oracle比较表结构是指对于两个或多个Oracle数据库中的表,在数据库结构、对象及其属性等方面进行对比的过程。
通过比较表结构,可以帮助用户发现数据库中存在的表结构差异,便于在数据库之间进行数据同步、备份等操作。
比较表结构需要使用相应的工具,例如Oracle SQL Developer、PL/SQL Developer等。
这些工具提供了很多功能,可以快速、准确地比较数据库中的表结构。
比较表结构主要分为两个方面:表结构的比较和表数据的比较。
表结构的比较主要包括表名、列名、数据类型、长度、精度、约束等方面,而表数据的比较主要是针对表中的数据进行比较,检查表数据是否一致。
在使用Oracle比较表结构工具时,用户需要选择相应的比较方式、比较对象和比较选项等。
比较方式主要包括按表名比较、按列名比较、按数据类型比较等,比较对象主要是指需要比较的表、视图等数据库对象。
而比较选项则包括忽略主键、忽略默认值、忽略空格等,用于指定需要忽略的比较项。
总之,Oracle比较表结构是数据库管理员和开发人员经常使用的工具之一,可以帮助用户快速、准确地发现数据库中存在的表结构差异,有助于保障数据库的稳定性和安全性。
- 1 -。

oracletimestampdiff函数Oracle数据库中的TimestampDiff函数用于计算两个时间或日期之间的差值。
该函数可以用于计算年、月、日、时、分、秒等精确到指定部分值的差异。
在下面的文章中,我们将详细介绍Oracle中的TimestampDiff函数以及其用法。
1.函数语法TimestampDiff函数的语法如下:``````其中,unit代表要计算的时间单位,可以是以下值之一:-YEAR:年-MONTH:月-DAY:日-HOUR:时-MINUTE:分-SECOND:秒2.使用示例下面是一些使用TimestampDiff函数的示例:a.计算两个时间之间的小时差值:```SELECT TIMESTAMPDIFF(HOUR, '2024-01-01 00:00:00', '2024-01-01 12:00:00') AS hour_diff FROM DUAL;```结果将是12,因为两个时间之间相差12小时。
b.计算两个日期之间的天数差值:```SELECT TIMESTAMPDIFF(DAY, TO_DATE('2024-01-01', 'YYYY-MM-DD'), TO_DATE('2024-01-05', 'YYYY-MM-DD')) AS day_diff FROM DUAL;```结果将是4,因为两个日期之间相差4天。
c.计算两个时间之间的分钟差值:```SELECT TIMESTAMPDIFF(MINUTE, '2024-01-01 00:00:00', '2024-01-01 00:10:00') AS minute_diff FROM DUAL;```结果将是10,因为两个时间之间相差10分钟。
3.注意事项- TimestampDiff函数在计算时间差值时,会自动处理闰年的情况。

判断两个表格中几组相同数据的方法要判断两个表格中是否存在相同的数据,可以采用以下方法:1. 使用Excel的“高级筛选”功能:a. 首先,将两个表格的数据放入同一个工作表的不同列中。
b. 选择需要筛选的列,点击“数据”菜单,选择“高级”。
c. 在“高级筛选”对话框中,设置筛选条件,例如“等于”、“不等于”等。
d. 在“输出区域”设置框中,选择一个单元格作为筛选结果的输出位置。
e. 点击“确定”,筛选出相同的数据。
2. 使用Excel的“合并和筛选”功能:a. 将两个表格的数据分别放入两个工作表中。
b. 选择一个空白工作表,点击“数据”菜单,选择“合并和筛选”。
c. 在“合并和筛选”对话框中,选择要合并的表格和输出区域。
d. 在“筛选条件”栏中,设置筛选条件,例如“等于”、“不等于”等。
e. 点击“确定”,合并并筛选出相同的数据。
3. 使用VLOOKUP函数:a. 在一个空白单元格中,输入以下公式:=VLOOKUP(要查找的值, 表格1, 列号, FALSE)b. 将上述公式复制到其他空白单元格,分别用于查找表格1和表格2中的相同数据。
c. 如果找到相同数据,VLOOKUP函数会返回查找的值;如果未找到,会返回“#N/A”。
4. 使用条件格式:a. 选择一个空白工作表,将两个表格的数据分别放入不同列。
b. 在一个单元格中输入公式,例如:=IF(ISERROR(VLOOKUP(A2, 表格1, 1, FALSE)), "相同数据", "不同数据")。
c. 将上述公式复制到其他单元格,以判断表格1和表格2中的数据是否相同。
以上方法可以帮助您判断两个表格中是否存在相同的数据。
根据实际需求和表格大小,您可以选择合适的方法进行操作。
两个excel表格核对的6种方法,用了三个小时才整理完成!excel表格之间的核对,是每个excel用户都要面对的工作难题,今天兰色带大家一起盘点一下表格核对的方法,一共6种,以后再也不用加班勾数据了。
(兰色用了三个小时整理出了这篇教程,估计你再也找不到这么全的两表核对教程,一定要转发或收藏起来备用哦)一、使用合并计算核对excel中有一个大家不常用的功能:合并计算。
利用它我们可以快速对比出两个表的差异。
例:如下图所示有两个表格要对比,一个是库存表,一个是财务软件导出的表。
要求对比这两个表同一物品的库存数量是否一致,显示在sheet3表格。
库存表:软件导出表:操作方法:步骤1:选取sheet3表格的A1单元格,excel2003版里,执行数据菜单(excel2010版数据选项卡) - 合并计算。
在打开的窗口里“函数”选“标准偏差”,如下图所示。
步骤2:接上一步别关窗口,选取库存表的A2:C10(第1列要包括对比的产品,最后一列是要对比的数量),再点“添加”按钮就会把该区域添加到所有引用位置里.步骤3:同上一步再把财务软件表的A2:C10区域添加进来。
标签位置:选取“最左列”,如下图所示。
进行以上步骤后,点确定按钮,会发现sheet3中的差异表已生成,C列为0的表示无差异,非0的行即是我们要查找的异差产品。
兰色说:如果你想生成具体的差异数量,可以把其中一个表的数字设置成负数。
(添加一辅助列=c2*-1),在合并计算的函数中选取“求和”,即可。
另外,此类题目也可以用VLOOKUP函数查找另一个表中相同项目对应的值,然后相减核对。
二、使用选择性粘贴核对当两个格式完全一样的表格进行核对时,可以用选择性粘贴方法,如下图所示,表1和表2是格式完全相同的表格,要求核对两个表格中填的数字是否完全一致。
兰色今天就看到一同事在手工一行一行的手工对比两个表格。
兰色马上想到的是在一个新表中设置公式,让两个表的数据相减。
oracletimestampdiff函数在Oracle中,没有内置的`TIMESTAMPDIFF`函数用于计算两个时间戳之间的差异。
但是,可以使用一些其他函数来实现类似的功能。
一种方法是使用`EXTRACT`函数获取两个时间戳之间的差异,并根据需要进行转换。
以下是一个示例:```sqlSELECTFROM(SELECTFROM dual);```在上面的示例中,我们使用`EXTRACT`函数来分别计算两个时间戳之间的天数差异,小时差异,分钟差异和秒差异。
`EXTRACT`函数从时间戳中提取指定的部分,例如年份、月份、天数、小时、分钟或秒数。
通过从第二个时间戳中减去第一个时间戳,我们可以得到它们之间的时间差。
另一种方法是使用`NUMTODSINTERVAL`函数将两个时间戳之间的差异转换为其它时间单位的间隔。
以下是一个示例:```sqlSELECTFROM(SELECTFROM dual);```在上面的示例中,我们使用`NUMTODSINTERVAL`函数将两个时间戳之间的差异转换为天数间隔、小时间隔、分钟间隔和秒间隔。
`NUMTODSINTERVAL`函数接受一个数字参数和一个字符串参数,该字符串参数指定间隔的单位(例如,'DAY'表示天,'HOUR'表示小时,'MINUTE'表示分钟,'SECOND'表示秒)。
这些示例都是使用静态值进行计算的。
在实际应用中,您可以将这些查询与您的表和列结合使用,以计算实际的时间差异。
这是关于在Oracle中计算时间戳差异的两种方法。
根据您的需求和环境,您可以选择使用其中一种方法。
在核对两个表格中的重复数据时,可以使用以下六种方法:
1. **基于关键列的匹配**:选择一个或多个关键列,在两个表格中进行匹配。
如果关
键列的值在两个表格中都存在,则可以确定这是重复数据。
这种方法适用于有明确标
识的关键列。
2. **全表格匹配**:直接比较两个表格的每一行,如果所有列的值都完全相同,则可
以确定这是重复数据。
这种方法适用于表格没有明确的关键列。
3. **模糊匹配**:当关键列的值有一定的差异时,可以使用模糊匹配算法,如编辑距离、相似度计算等方法来判断是否为重复数据。
4. **哈希匹配**:对两个表格中的每一行进行哈希计算,如果哈希值相同,则可以确
定这是重复数据。
哈希匹配适用于大规模数据,可以提高匹配效率。
5. **索引匹配**:在两个表格中创建索引,例如使用哈希表或二叉树等数据结构,然
后根据索引进行匹配。
这种方法可以加快匹配速度,并减少不必要的比较。
6. **数据库匹配**:将两个表格导入到数据库中,并使用数据库的查询语言(如SQL)进行匹配。
数据库具有强大的查询和匹配功能,可以处理大规模数据,并且支持多种
匹配条件。
选择适用于你情况的方法取决于表格的结构、数据量以及匹配的要求。
在实际应用中,可能需要结合多种方法来进行数据的核对和匹配。
希望这些方法对你有所帮助!如果还有其他问题,请随时提问。
oracle 时间比较函数Oracle是一种常用的数据库管理系统,它提供了丰富的函数和操作符来进行数据查询和分析。
其中,时间比较函数是一类非常重要且常用的函数,用于比较和操作日期和时间的数据。
本文将介绍Oracle中常用的时间比较函数,并讨论它们的用法和功能。
在Oracle中,时间比较函数可以帮助我们处理各种与时间相关的任务,例如计算日期之间的差异、比较两个日期的大小、提取日期的部分信息等。
下面将介绍几个常见的时间比较函数。
1. SYSDATE函数:SYSDATE函数用于获取当前的系统日期和时间。
它返回一个日期类型的值,可以直接在SQL语句中使用。
例如,我们可以使用SYSDATE函数来查询当前时间之前的所有订单:```sqlSELECT * FROM orders WHERE order_date < SYSDATE;```2. TO_CHAR函数:TO_CHAR函数用于将日期类型转换为字符类型。
它可以接受两个参数,第一个参数是日期类型的值,第二个参数是日期格式。
通过指定不同的日期格式,我们可以将日期按照不同的方式显示出来。
例如,我们可以使用TO_CHAR函数将日期格式化为"YYYY-MM-DD"的形式:```sqlSELECT TO_CHAR(order_date, 'YYYY-MM-DD') FROM orders;```3. MONTHS_BETWEEN函数:MONTHS_BETWEEN函数用于计算两个日期之间的月份差。
它接受两个日期类型的参数,并返回一个数字类型的值,表示两个日期之间的月份差异。
例如,我们可以使用MONTHS_BETWEEN函数计算两个日期之间相差的月份数:```sqlSELECT MONTHS_BETWEEN(end_date, start_date) FROM projects; ```4. ADD_MONTHS函数:ADD_MONTHS函数用于在给定日期上添加指定的月份数。
Oracle中比对2张表之间数据是否一致的几种方法by Maclean.liuliu.maclean@About Mel Email & Gtalk:liu.maclean@l Blog:l QQ:47079569 QQ Group:23549328l Oracle Certified Database Administrator Master 10g and 11gl Over 6 years experience with Oracle DBA technology l Over 7 years experience with Linux technologyl Member Independent Oracle Users Groupl Member All China Oracle Users Groupl Presents for advanced Oracle topics: RAC, DataGuard, Performance Tuning and Oracle Internal.How To Find Maclean Liu?大约是2个星期前做一个夜班的时候,开发人员需要比对shareplex 数据同步复制软件在 源端和目标端的2张表上的数据是否一致,实际上后来想了下shareplex 本身应当具有这种数据校验功能, 但是还是希望从数据库的角度得出几种可用的同表结构下的数据比对方法。
注意以下几种数据比对方式适用的前提条件:1. 所要比对的表的结构是一致的2. 比对过程中源端和 目标端 表上的数据都是静态的,没有任何DML修改方式1:假设你所要进行数据比对的数据库其中有一个 版本为11g且该表上有相应的主键索引(primary key index)或者唯一非空索引(unique key ¬ null)的话,那么恭喜你! 你可以借助11g 新引入的专门做数据对比的PL/SQL Package dbms_comparison来实现数据校验的目的,如以下演示:Source 源端版本为11gR2 :conn maclean/macleanSQL> select * from v$version;BANNER--------------------------------------------------------------------------------Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit ProductionPL/SQL Release 11.2.0.3.0 - ProductionCORE 11.2.0.3.0 ProductionTNS for Linux: Version 11.2.0.3.0 - ProductionNLSRTL Version 11.2.0.3.0 - ProductionSQL> select * from global_name;GLOBAL_NAME & drop table test1;create table test1 tablespace users as select object_id t1,object_name t2 from dba_objects where object_id is not null;alter table test1 add primary key(t1);exec dbms_stats.gather_table_stats('MACLEAN','TEST1',cascade=>TRUE);create database link maclean connect to maclean identified by maclean using'G10R21';Database link created.以上源端数据库版本为11.2.0.3 , 源表结构为test1(t1 number primary key,t2 varchar2(128),透过dblink链接到版本为10.2.0.1的目标端conn maclean/macleanSQL> select * from v$versionBANNER----------------------------------------------------------------Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - 64biPL/SQL Release 10.2.0.1.0 - ProductionCORE 10.2.0.1.0 ProductionTNS for Linux: Version 10.2.0.1.0 - ProductionNLSRTL Version 10.2.0.1.0 - Productioncreate table test2 tablespace users as select object_id t1,object_name t2from dba_objects where object_id is not null;alter table test2 add primary key(t1);exec dbms_stats.gather_table_stats('MACLEAN','TEST2',cascade=>TRUE);目标端版本为10.2.0.1 , 表结构为test2(t1 number primary key,t2 varchar2(128))。
表格数据比对方法表格数据比对是指将多个表格中的数据进行对比,以找出差异和共同点的过程。
在工作和研究中,表格数据比对是一项非常重要的任务,可以用于数据质量控制、数据集成、数据分析和数据验证等领域。
本文将介绍一些常用的表格数据比对方法。
一、手动比较法手动比较法是最简单也是最基础的比对方法。
它只需要将多个表格放在一起,逐行逐列地进行数据对比和记录。
手动比较法的优点是操作简单,不需要额外的工具和技术。
缺点是速度慢,容易出错,适用于数据量较小的比对任务。
二、公式比对法公式比对法是一种自动化处理表格数据比对的方法。
它利用Excel或其他电子表格软件的函数和公式,将多个表格的数据进行自动比对和标记。
公式比对法的优点是速度快,效率高,可以处理大量的数据。
缺点是需要一定的Excel技术和编程能力,适用于熟练掌握电子表格软件的用户。
三、数据抽取比对法四、数据库比对法数据库比对法是一种将表格数据导入数据库,然后使用SQL查询进行比对的方法。
它适用于大规模的表格数据比对任务,可以高效地进行数据筛选、排序和分析。
数据库比对法的优点是速度快,可以处理大型数据集。
缺点是需要一定的数据库管理和查询技术,适用于对数据处理熟练的用户。
五、专业软件比对法除了上述的方法,还有一些专门的软件可以进行表格数据比对。
这些软件通常具有更复杂的算法和功能,可以自动识别和匹配表格中的数据,进行更精确和深入的比对。
专业软件比对法的优点是准确度高,可以处理各种复杂的数据情况。
缺点是需要购买和学习专门的软件,适用于对比对准确度有较高要求的项目。
综上所述,表格数据比对方法有手动比较法、公式比对法、数据抽取比对法、数据库比对法和专业软件比对法等。
不同的方法适用于不同的比对任务。
在选择方法时,需要考虑数据量、准确度、效率和技能要求等因素,选择最合适的方法进行数据比对。
Excel中如何实现比对不同工作表中相同信息1、Excel中如何实现比对不同工作表中相同信息我有这样一个工作簿,里面的两个工作表中大部分信息是相同的,用什么样的函数能把它们的相同信息找出来。
工作表1:姓名语文数学周二75 78张三75 85李四98 86王五92 98赵六89 97孙七78 67工作表2:姓名语文数学方二92 76孙七75 85李四98 86赵六92 98王五89 97张三78 67也就是将姓名相同的人找出来,成绩也跟着来最佳答案...sheet1..A......B....C姓名语文数学周二75 78张三75 85李四98 86王五92 98赵六89 97孙七78 67sheet2..A......B.....C姓名语文数学方二92 76孙七75 85李四98 86赵六92 98王五89 97张三78 67你可以在sheet1的D2中输入公式如下(第一行必须是指标名称) =IF(COUNTIF(sheet2!A:A,A2)>=1,1,"")向下拉,那么有1 的就是相同的,再用自动筛选选出来有1 的就行了急!如何比对两张Excel表的内容本来是一张Excel表A,因需要分类将其内容分类复制到另外一张Excel表B内,表A,B都分别包含几张分表.由于操作上可能存在失误,最后比对两个表的数据总和时不一致,于是需要对其进行详细比对查出表A、B中不同的内容最佳答案建议将要比较的工作表复制到同一工作簿中进行比较。
例如要比较同一工作簿中SHEET1与SHEET2的不同,先将其格式复制到SHEET3中,在数据区域左上角单元格(假设为B2)输入公式:=IF(SHEET1!B2=SHEET2!B2,SHEET1!B2,"错")将公式向右和向下复制到其他单元格。
比对结果一目了然。
2、如何找出EXCEL一列中相同数据?我有一列数据,因为在录入过程中会出现重复录入,所以在完成之后想快速的找到这一列里有哪些是录入重复的。
Oracle中比对2张表之间数据是否一致的几种方法by Maclean.liuliu.maclean@About Mel Email & Gtalk:liu.maclean@l Blog:l QQ:47079569 QQ Group:23549328l Oracle Certified Database Administrator Master 10g and 11gl Over 6 years experience with Oracle DBA technology l Over 7 years experience with Linux technologyl Member Independent Oracle Users Groupl Member All China Oracle Users Groupl Presents for advanced Oracle topics: RAC, DataGuard, Performance Tuning and Oracle Internal.How To Find Maclean Liu?大约是2个星期前做一个夜班的时候,开发人员需要比对shareplex 数据同步复制软件在 源端和目标端的2张表上的数据是否一致,实际上后来想了下shareplex 本身应当具有这种数据校验功能, 但是还是希望从数据库的角度得出几种可用的同表结构下的数据比对方法。
注意以下几种数据比对方式适用的前提条件:1. 所要比对的表的结构是一致的2. 比对过程中源端和 目标端 表上的数据都是静态的,没有任何DML修改方式1:假设你所要进行数据比对的数据库其中有一个 版本为11g且该表上有相应的主键索引(primary key index)或者唯一非空索引(unique key ¬ null)的话,那么恭喜你! 你可以借助11g 新引入的专门做数据对比的PL/SQL Package dbms_comparison来实现数据校验的目的,如以下演示:Source 源端版本为11gR2 :conn maclean/macleanSQL> select * from v$version;BANNER--------------------------------------------------------------------------------Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit ProductionPL/SQL Release 11.2.0.3.0 - ProductionCORE 11.2.0.3.0 ProductionTNS for Linux: Version 11.2.0.3.0 - ProductionNLSRTL Version 11.2.0.3.0 - ProductionSQL> select * from global_name;GLOBAL_NAME & drop table test1;create table test1 tablespace users as select object_id t1,object_name t2 from dba_objects where object_id is not null;alter table test1 add primary key(t1);exec dbms_stats.gather_table_stats('MACLEAN','TEST1',cascade=>TRUE);create database link maclean connect to maclean identified by maclean using'G10R21';Database link created.以上源端数据库版本为11.2.0.3 , 源表结构为test1(t1 number primary key,t2 varchar2(128),透过dblink链接到版本为10.2.0.1的目标端conn maclean/macleanSQL> select * from v$versionBANNER----------------------------------------------------------------Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - 64biPL/SQL Release 10.2.0.1.0 - ProductionCORE 10.2.0.1.0 ProductionTNS for Linux: Version 10.2.0.1.0 - ProductionNLSRTL Version 10.2.0.1.0 - Productioncreate table test2 tablespace users as select object_id t1,object_name t2from dba_objects where object_id is not null;alter table test2 add primary key(t1);exec dbms_stats.gather_table_stats('MACLEAN','TEST2',cascade=>TRUE);目标端版本为10.2.0.1 , 表结构为test2(t1 number primary key,t2 varchar2(128))。
注意这里2张表上均必须有相同的主键索引或者伪主键索引(pseudoprimary key伪主键要求是唯一键且所有的成员列均是非空NOT NULL)。
实际创建comparison对象,并实施校验:begindbms_comparison.create_comparison(comparison_name => 'MACLEAN_TEST_COM',schema_name => 'MACLEAN',object_name => 'TEST1',dblink_name => 'MACLEAN',remote_schema_name => 'MACLEAN',remote_object_name => 'TEST2',scan_mode => dbms_comparison.CMP_SCAN_MODE_FULL); end;PL/SQL procedure successfully completed.SQL> set linesize 80 pagesize 1400SQL> select * from user_comparison where comparison_name='MACLEAN_TEST_COM'; COMPARISON_NAME COMPA SCHEMA_NAME------------------------------ ----- ------------------------------OBJECT_NAME OBJECT_TYPE REMOTE_SCHEMA_NAME------------------------------ ----------------- ------------------------------REMOTE_OBJECT_NAME REMOTE_OBJECT_TYP------------------------------ -----------------DBLINK_NAME--------------------------------------------------------------------------------SCAN_MODE SCAN_PERCENT--------- ------------CYCLIC_INDEX_VALUE--------------------------------------------------------------------------------NULL_VALUE--------------------------------------------------------------------------------LOCAL_CONVERGE_TAG--------------------------------------------------------------------------------REMOTE_CONVERGE_TAG--------------------------------------------------------------------------------MAX_NUM_BUCKETS MIN_ROWS_IN_BUCKET--------------- ------------------LAST_UPDATE_TIME---------------------------------------------------------------------------MACLEAN_TEST_COM TABLE MACLEANTEST1 TABLE MACLEANTEST2 TABLEMACLEANFULLORA$STREAMS$NV1000 1000020-DEC-11 01.08.44.562092 PM利用dbms_comparison.create_comparison创建comparison后,新建的comparison会出现在user_comparison视图中;以上我们完成了comparison的创建,但实际的校验仍未发生我们利用10046事件监控这个数据对比过程:conn maclean/macleanset timing on;alter system flush shared_pool;alter session set events '10046 trace name context forever,level 8';set serveroutput onDECLAREretval dbms_parison_type;BEGINIF dbms_pare('MACLEAN_TEST_COM', retval, perform_row_dif => TRUE) THENdbms_output.put_line('No Differences');ELSEdbms_output.put_line('Differences Found');END IF;END;/说Differences Found =====> 返回果结为Differences Found,明数据存在差异并不一致PL/SQL procedure successfully completed.Elapsed: 00:00:10.87===========================10046 tkprof result =========================SELECT MIN("T1"), MAX("T1")FROM"MACLEAN"."TEST1"SELECT MIN("T1"), MAX("T1")FROM"MACLEAN"."TEST2"@MACLEANSELECT COUNT(1)FROM"MACLEAN"."TEST1" s WHERE ("T1" >= :scan_min AND "T1" <= :scan_max )SELECT COUNT(1)FROM"MACLEAN"."TEST2"@MACLEAN s WHERE ("T1" >= :scan_min AND "T1" <= :scan_max ) SELECT q.wb1, min(q."T1") min_range1, max(q."T1") max_range1, count(*)num_rows, sum(q.s_hash) sum_range_hashFROM(SELECT /*+ FULL(s) */ width_bucket(s."T1", :scan_min1, :scan_max_inc1,:num_buckets) wb1, s."T1", ora_hash(NVL(to_char(s."T1"), 'ORA$STREAMS$NV'), 4294967295, ora_hash(NVL((s."T2"), 'ORA$STREAMS$NV'), 4294967295, 0))s_hash FROM "MACLEAN"."TEST1" s WHERE (s."T1">=:scan_min1 AND s."T1"<=:scan_max1) ) q GROUP BY q.wb1 ORDER BY q.wb1SELECT /*+ REMOTE_MAPPED */ q.wb1, min(q."T1") min_range1, max(q."T1")max_range1, count(*) num_rows, sum(q.s_hash) sum_range_hashFROM(SELECT /*+ FULL(s) REMOTE_MAPPED */ width_bucket(s."T1", :scan_min1,:scan_max_inc1, :num_buckets) wb1, s."T1", ora_hash(NVL(to_char(s."T1"),'ORA$STREAMS$NV'), 4294967295, ora_hash(NVL((s."T2"), 'ORA$STREAMS$NV'), 4294967295, 0)) s_hash FROM "MACLEAN"."TEST2"@MACLEAN s WHERE (s."T1">=:scan_min1 AND s."T1"<=:scan_max1) ) q GROUP BY q.wb1 ORDER BY q.wb1SELECT /*+ FULL(P) +*/ * FROM "MACLEAN"."TEST2" PSELECT /*+ FULL ("A1") */WIDTH_BUCKET("A1"."T1", :SCAN_MIN1, :SCAN_MAX_INC1, :NUM_BUCKETS),MIN("A1"."T1"),MAX("A1"."T1"),COUNT(*),SUM(ORA_HASH(NVL(TO_CHAR("A1"."T1"), 'ORA$STREAMS$NV'),4294967295,ORA_HASH(NVL("A1"."T2", 'ORA$STREAMS$NV'), 4294967295, 0)))FROM "MACLEAN"."TEST2" "A1"WHERE "A1"."T1" >= :SCAN_MIN1AND "A1"."T1" <= :SCAN_MAX1GROUP BY WIDTH_BUCKET("A1"."T1", :SCAN_MIN1, :SCAN_MAX_INC1, :NUM_BUCKETS) ORDER BY WIDTH_BUCKET("A1"."T1", :SCAN_MIN1, :SCAN_MAX_INC1, :NUM_BUCKETS)SELECT ROWID, "T1", "T2"FROM "MACLEAN"."TEST2" "R"WHERE "T1" >= :1AND "T1" <= :2--------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |--------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 126 | 3528 | 4 (0)| 00:00:01 ||* 1 | FILTER | | | | | || 2 | TABLE ACCESS BY INDEX ROWID| TEST2 | 126 | 3528 | 4 (0)| 00:00:01 ||* 3 | INDEX RANGE SCAN | SYS_C006255 | 227 | | 2 (0)| 00:00:01 |--------------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter(TO_NUMBER(:1)<=TO_NUMBER(:2))3 - access("T1">=TO_NUMBER(:1) AND "T1"<=TO_NUMBER(:2))SELECT ll.l_rowid, rr.r_rowid, NVL(ll."T1", rr."T1") idx_valFROM(SELECT l.rowid l_rowid, l."T1", ora_hash(NVL(to_char(l."T1"),'ORA$STREAMS$NV'), 4294967295, ora_hash(NVL((l."T2"), 'ORA$STREAMS$NV'), 4294967295, 0)) l_hash FROM "MACLEAN"."TEST1" l WHERE l."T1">=:scan_min1AND l."T1"<=:scan_max1 ) ll FULL OUTER JOIN (SELECT /*+ NO_MERGEREMOTE_MAPPED */ r.rowid r_rowid, r."T1", ora_hash(NVL(to_char(r."T1"),'ORA$STREAMS$NV'), 4294967295, ora_hash(NVL((r."T2"), 'ORA$STREAMS$NV'), 4294967295, 0)) r_hash FROM "MACLEAN"."TEST2"@MACLEAN r WHERE r."T1">=:scan_min1 AND r."T1"<=:scan_max1 ) rr ON ll."T1"=rr."T1" WHERE ll.l_hashIS NULL OR rr.r_hash IS NULL OR ll.l_hash <> rr.r_hash----------------------------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Inst |IN-OUT|----------------------------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 190 | 754K| 9 (12)| 00:00:01 | | ||* 1 | VIEW | VW_FOJ_0 | 190 | 754K| 9 (12)| 00:00:01 | | ||* 2 | HASH JOIN FULL OUTER | | 190 | 754K| 9 (12)| 00:00:01 | | || 3 | VIEW | | 190 | 7220 | 4 (0)| 00:00:01 | | ||* 4 | FILTER | | || | | | || 5 | TABLE ACCESS BY INDEX ROWID| TEST1 | 190 | 5510 | 4 (0)| 00:00:01 | | ||* 6 | INDEX RANGE SCAN | SYS_C0013098 | 341 | | 2 (0)| 00:00:01 | | || 7 | VIEW | | 126 | 495K| 4 (0)| 00:00:01 | | || 8 | REMOTE | TEST2 | 126 | 3528 | 4 (0)| 00:00:01 | MACLE~ | R->S |----------------------------------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter("LL"."L_HASH" IS NULL OR "RR"."R_HASH" IS NULL OR"LL"."L_HASH"<>"RR"."R_HASH")2 - access("LL"."T1"="RR"."T1")4 - filter(TO_NUMBER(:SCAN_MIN1)<=TO_NUMBER(:SCAN_MAX1))6 - access("L"."T1">=TO_NUMBER(:SCAN_MIN1) AND"L"."T1"<=TO_NUMBER(:SCAN_MAX1))Remote SQL Information (identified by operation id):----------------------------------------------------8 - SELECT ROWID,"T1","T2" FROM "MACLEAN"."TEST2" "R" WHERE "T1">=:1 AND"T1"<=:2 (accessing'MACLEAN' )可以看到以上过程中虽然没有避免对TEST1、TEST2表的全表扫描(FULL TABLE SCAN), 但是好在实际参与HASH JOIN FULL OUTER 的仅是访问索引后获得的少量数据,所以效率还是挺高的。