SPSS实验报告册
- 格式:doc
- 大小:2.16 MB
- 文档页数:29

spss分析实验报告SPSS分析实验报告引言在社会科学研究领域,SPSS(Statistical Package for the Social Sciences)作为一种数据分析工具,被广泛应用于统计分析和数据挖掘。
本实验报告旨在通过SPSS软件对某项研究进行数据分析,探索其背后的数据模式和相关关系。
一、研究背景与目的本次研究旨在探究大学生的学习成绩与睡眠时间之间的关系。
学习成绩和睡眠时间是大学生日常生活中两个重要的方面,通过分析两者之间的关联,可以为学生提供科学的学习指导,提高学习效果。
二、研究设计与数据收集本研究采用问卷调查的方式,通过随机抽样的方法选取了500名大学生作为研究对象。
问卷内容包括学生的学习成绩和每日平均睡眠时间。
收集到的数据以Excel表格的形式整理并导入SPSS软件进行分析。
三、数据预处理在进行数据分析之前,需要对数据进行预处理。
首先,检查数据是否存在缺失值或异常值。
通过SPSS软件的数据清洗功能,将缺失值进行填补或删除,确保数据的完整性和准确性。
其次,对数据进行标准化处理,以消除不同变量之间的量纲差异。
四、描述性统计分析描述性统计分析是对数据的基本特征进行总结和描述。
通过SPSS软件的统计功能,可以计算出学生的学习成绩和睡眠时间的平均值、标准差、最大值、最小值等统计指标。
同时,可以绘制直方图、箱线图等图表来展示数据的分布情况。
五、相关性分析相关性分析是研究不同变量之间相关关系的一种方法。
本研究中,我们使用Pearson相关系数来衡量学习成绩和睡眠时间之间的线性相关性。
通过SPSS软件的相关性分析功能,可以得到相关系数的数值和显著性水平。
如果相关系数接近于1或-1,并且显著性水平小于0.05,则说明学习成绩和睡眠时间之间存在显著的相关关系。
六、回归分析回归分析是研究自变量对因变量影响程度的一种方法。
在本研究中,我们使用线性回归模型来探究睡眠时间对学习成绩的影响。
通过SPSS软件的回归分析功能,可以得到回归方程的系数、显著性水平和模型的拟合优度。

SPSS统计分析软件实验报告石河子大学经济与管理学院经济与贸易系国际经济与贸易专业2009级1班雍荣2009165106实验一SPSS基本操作一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容及步骤(一)数据的输入和保存1. SPSS界面当打开SPSS后,展现在我们面前的界面如下:请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
该界面和EXCEL极为相似,很多操作也与EXCEL类似,同学们可以自己试试。
2.定义变量选择菜单Data==>Define Variable。
系统弹出定义变量对话框如下:对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
假如有两组数据如下:GROUP 1: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 GROUP 2: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87先来建立分组变量GROUP。
请将变量名改为GROUP,然后单击OK按钮。
现在SPSS的数据管理窗口如下所示:第一列的名称已经改为了“group”,这就是我们所定义的新变量“group”。
现在我们来建立变量X。
单击第一行第二列的单元格,然后选择菜单Data==>Define Variable,同样,将变量名改为X,然后确认。

【精品】spss实验报告
本报告主要研究了SPSS实验的结果。
通过对原始数据的收集、预处理、描述性统计信息和统计图分析,讨论了实验结果。
首先,本文进行了实验数据的收集,共收集了100个实验样本。
收集的数据包括以下几个变量:性别(男士/女士),年龄,收入和教育水平。
收集的数据将交给SPSS模型进行处理。
其次,进行了数据的预处理,包括数据的清洗、缺失值的处理和异常值的处理等。
根据数据的性质,进行了适当的数据转换。
第三,计算了一些描述性统计信息,如数据中变量的平均数、标准差、最小值和最大值等。
然后,使用绘图功能绘制出直方图,用于描述数据中变量的分布情况。
箱线图用于刻画变量的离散程度,并可以汇总和识别变量的一些特征。
最后,进行多元统计分析,如相关性分析、回归分析等,以深入研究不同变量之间的关系。
总之,通过对SPSS实验的有效处理,可以得出数据属性、分布特征、变量关系等有效结果,有助于对实践事件做出正确判断,并且在改进实验步骤时也可以添加核心变量,从而得到更准确的结果。
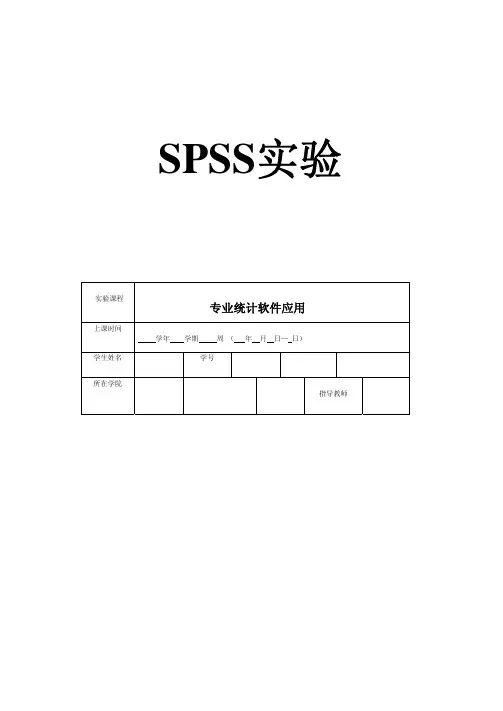
SPSS实验实验课程专业统计软件应用上课时间学年学期周(年月日—日)学生姓名学号所在学院指导教师第五章第一题通过样本分析,结果如下图One-Sample StatisticsN Mean Std. Deviation Std. Error Mean 成绩27 77.9312.111 2.331One-Sample TestTest Value = 70t df Sig. (2-tailed)Mean Difference 95% Confidence Interval of theDifferenceLower Upper成绩 3.400 26.0027.926 3.13 12.72从图看出,sig=0.002,小于0.05,因此本班平均成绩与全国平均成绩70分有显著性差异。
第五章第二题通过独立样本分析,结果如下图Group Statistics成绩N Mean Std. Deviation Std. Error Mean成绩1=男10 84.0011.528 3.6450=女10 62.9018.454 5.836Independent Samples TestLevene's Test forEquality of Variances t-test for Equality of MeansF Sig. t dfSig.(2-tailed)MeanDifferenceStd. ErrorDifference95% Confidence Interval of theDifferenceLower Upper成绩Equalvariancesassumed1.607.221 3.06718.007 21.100 6.881 6.64435.556Independent Samples TestLevene's Test forEquality of Variances t-test for Equality of MeansF Sig. t dfSig.(2-tailed)MeanDifferenceStd. ErrorDifference95% Confidence Interval of theDifferenceLower Upper成绩Equalvariancesassumed1.607.221 3.06718.007 21.100 6.881 6.64435.556Equalvariancesnotassumed3.06715.096.008 21.100 6.881 6.44235.758在显著性水平为0.05的情况下,t统计量的概率p为0.007,故拒绝零假设,既两样本的均值不相等,既男女生成绩有显著性差异。

《SPSS统计软件应用》实验报告册20 13 ——20 14 学年第一学期班级:学号:姓名:实验教师:实验学时:实验组号:目录实验一SPSS的数据管理 (1)实验二描述性统计分析 (13)实验三均值检验 (21)实验四相关分析 (27)实验五方差分析 (34)实验六绘制统计图 (40)实验七因子分析 (44)实验八聚类分析 (48)实验九判别分析 (58)实验十回归分析 (67)实验十一非参数检验 (75)实验一 SPSS的数据管理一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容及步骤:1、定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
表1 大学教师基本情况调查表实验步骤:(1)打开定义变量的界面启动SPSS,进入主界面,单击图6-2所示的屏幕左下角的“Variable View”选项卡,打开定义变量的表格。
(2)输入变量名,符合变量的命名规则在“Name”列的第一个单元格输入第一个变量名,如“xm”。
(3)确定变量类型,单击“Type”列的第一个单元格,如图6-3所示,SPSS的默认变量类型为数值型。
单击数值型变量后的“”,弹出如图6-4所示的对话框,用户可以从该对话框中选择其他的变量类型。
(4)设置字段值(5)依次按要求输入完毕即可。
结果如下:2 、高校提前录取名单的确定某高校今年对部分考生采取单独出题、提前录取的招生模式。
现有20名来自国内不同省市的考生报考该校,7个录取名额。
见数据文件compute.sav. 该校制定了如下录取原则:(1)文化课成绩由数学、语文、英语和综合四门成绩组成。
文化课成绩制定最低录取分数线:400分。
(2)个人档案中若有“不良记录”,不予录取。
(3)对西部考生和少数民族考生,给予加分优惠。

SPSS期末综合实验报告姓名:学号:成绩:(附:本实验报告基于SPSS 20.0)一、用“SUMMARIZE CASES”作一个分组比较【1】点击【分析】——【报告】——【个案汇总】菜单项,弹出“摘要个案”对话框,设置如下:【2】点击【确定】,输出结果,整理后得三线表,如下:个案汇总N性别城市学历男北京188 上海221 广州228 Total 637女北京190 上海166 广州154 Total 510从上表可以看出,上海市和广州市的男性比例要高于女性,而在北京市方面,男女之间则差别不大,但同时也要考虑到抽样调查数据中男性和女性的绝对数的大小不同。
二、对某一个变量“选择个案(select)”进行频数分析【1】点击【分析】——【描述统计】——【频率】菜单项,弹出“频率”对话框,设置如下:【2】点击【确定】,输出结果,整理后得三线表,如下:城市频数百分比(%)北京上海广州Total 378 33.0 387 33.7 382 33.3 1147 100.0从上表可以看出,在抽样调查的数据当中,样本中北京市的被调查者有378人,占总数的33.0%,样本中上海市的被调查者有387人,占总数的33.7%,样本中广州市的被调查者有382人,占总数的33.3%,因此,在误差允许的范围内,可以认为抽样是相对均匀的。
三、对某一个变量进行重新分组(recode)【1】点击【转换】——【重新编码为不同变量】,弹出“重新编码为不同变量”对话框,设置如下:【2】点击【更改】后,如上图,点击【旧值和新值】,弹出如下对话框,依次设置如下:【3】点击【继续】——【确定】可得如下效果,变量视图:四、对某两个定类变量进行卡方检验【1】点击【分析】——【描述统计】——【交叉表】菜单项,弹出“交叉表”对话框,如图所示:【2】在“行”列表框中选入“家庭收入2级Ts9”;在“列”列表框中选入“是否拥有家用轿车O1”,如图所示:【3】单击【单元格】,弹出“单元显示”对话框,选中“行百分比”复选框;如图:【4】单击【继续】,再单击【统计量】,弹出“统计量”对话框,选中“卡方”复选框,如图:【5】单击【继续】——【确定】,得到输出结果,整理后得三线表,如下:Ⅰ交叉表:家庭收入2级 * 是否拥有家用轿车Crosstabulation是否拥有家用轿车有没有家庭收入2级Below 48,000Count% within 家庭收入2级32 3039.6% 90.4%Over 48,000Count 225 429% within 家庭收入2级34.4% 65.6% TotalCount 257 732% within 家庭收入2级26.0% 74.0%Ⅰ由交叉表可知低收入家庭中只有9.6%拥有轿车,而中高收入家庭中有34.4%拥有轿车,样本数据差异明显,但该差异是否具有统计学意义尚需检验,卡方检验结果如下表。

《SPSS统计软件应用》报告册20 15 - 20 16 学年第 1 学期班级:学号:姓名:实验教师:学时: 2周目录1.实验一 SPSS的数据管理2.实验二描述性统计分析3.实验三均值检验4.实验四相关分析5.实验五方差分析6.实验六统计图7.实验七因子分析8.实验八聚类分析9.实验九回归分析10.实验十判别分析11.实验十一非参数检验实验一SPSS的数据管理一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容及步骤:1、定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
表1 大学教师基本情况调查表实验步骤:(1)首先ssps统计分析软件,(2)然后新建一个文件,点击左下角“变量视图”,(3)然后依据所给表格创建字段,如“姓名”、“性别”等。
在输入每个名称字段时,(4)对其类型和宽度等限制条件按要求分别限制指即可。
实验结果及分析:实验结果如下图最终建成了所要的表格。
2 、高校提前录取名单的确定某高校今年对部分考生采取单独出题、提前录取的招生模式。
现有20名来自国内不同省市的考生报考该校,7个录取名额。
见数据文件compute.sav. 该校制定了如下录取原则:(1)文化课成绩由数学、语文、英语和综合四门成绩组成。
文化课成绩制定最低录取分数线:400分。
(2)个人档案中若有“不良记录”,不予录取。
(3)对西部考生和少数民族考生,给予加分优惠。
少数民族考生加20分,西部考生加10分。
(4)对参加过省以上竞赛并取得三等奖以上名次的考生,每项加10分。
(5)文化课成绩和加分总和构成综合分,录取综合排名为前7名的学生。
练习:利用spss软件,综合利用所学,给出成绩排名的操作步骤。
实验步骤:(1)计算文化课总成绩: 打开数据文件compute.sav.变量计算:点击“转换”——“计算变量”,定义变量总分,目标变量中的值设为“总分”,数字表达式设置“语文+数学+英语+综合”,单击“确定”按钮。

《SPSS统计软件应用》报告册20 - 20 学年第学期班级:学号:姓名:实验教师:学时:目录:实验一、SPSS数据文件的建立和管理 (3)实验二、数据预处理 (5)实验三、基本统计分析 (8)实验四、参数检验 (11)实验五、方差分析 (15)实验六、非参数检验 (21)实验七、相关分析 (25)实验八、回归分析 (30)实验九、聚类分析 (36)实验十、因子分析 (43)实验一、SPSS数据文件的建立和管理一、实验目的了解SPSS的基本操作环境,理解SPSS进行数据分析的基本步骤,掌握SPSS数据录入与编辑的方法,掌握SPSS的数据管理的相关功能。
二、实验内容大学生基本情况调查问卷1、性别 A.男 B.女2、您现在是大学几年级?A.大一 B.大二 C.大三 D.大四3、您所在学院?4、您的出生日期?5、在大学里,您是否学习过双语课程? A.是 B.否6、您参加了学校哪些社团?(多选)A.文艺社团B.体育社团C.读书社団D.公益社团E.创业社团7、您本学期选修课的门数?A.0 B.1 C.2 D.3 E.4门以上8、您的月平均消费?A.300元以下B.300-400C.400-500D.500-600E.600以上9、您对自己在大学里的表现满意程度如何?A.非常满意B.比较满意C.满意D.不太满意E.不满意10、您认为最受欢迎的老师应该具有哪些特点?要求:根据问卷建立SPSS数据文件,文件名为:大学生基本情况调查问卷.sav。
至少录入2条数据。
三、实验关键步骤1、定义变量图1.1变量视图窗口2、录入数据图1.2 录入数据窗口3、保存数据保存路径及文件名如下:图1.3保存数据四、结果分析(手写)实验二、数据预处理一、实验目的掌握利用SPSS的“数据”菜单和“转换”菜单提供的相关功能实现数据的预处理,为后续的数据分析做准备。
二、实验内容某年级确定学生奖学金等级,制定了如下规则:1、学生如果有违纪,不能获得奖学金。

spss实验报告SPSS实验报告引言:本实验旨在探究男性和女性在处理视觉任务时的差异。
研究表明,男性和女性在处理不同类型的视觉信息时有着不同的注意倾向和反应时间。
本实验将运用SPSS软件对实验数据进行分析,进一步研究这种差异的存在及其具体表现。
方法:参与者:本实验共招募了60名大学本科生(30名男性和30名女性),无近视、色盲、疲劳等视觉障碍的健康受试者。
实验材料与设计:实验使用了一台电脑,显示器大小为17英寸,分辨率为1280×1024像素。
实验设计为重复测量设计,所有参与者将接受两个视觉任务:定向判断和颜色识别。
定向判断任务:参与者要在屏幕上显示的五个不同方向的箭头中,判断指向右边的箭头的个数。
该任务共有50个试次,每个试次的箭头数量和方向均不相同。
颜色识别任务:参与者需要判断屏幕上显示的5个不同颜色的圆圈中,颜色不同的圆圈的个数。
该任务共有50个试次,每个试次的颜色和位置均不相同。
数据收集:在每个试次开始时,实验者测量参与者所花费的时间,并将其记录在数据表中。
每个参与者完成两个任务,任务的顺序是随机分配的。
数据分析:首先,我们利用SPSS软件计算了整体样本的平均反应时间(RT)和标准偏差(SD)。
结果显示,整体样本的平均RT 为300.56毫秒,SD为25.34毫秒。
然后,我们将样本按照性别分组,并分别计算男性和女性的平均RT和SD。
结果显示,男性的平均RT为289.45毫秒,SD 为23.67毫秒;女性的平均RT为311.67毫秒,SD为27.98毫秒。
接下来,我们进行了配对样本t检验,比较了男性和女性在两个任务中的平均RT。
结果显示,男性在定向判断任务中的平均RT (279.89毫秒)显著低于女性(297.83毫秒)(t(29)= -2.45, p<0.05)。
然而,男性和女性在颜色识别任务中的平均RT(298.01毫秒和304.51毫秒,分别)之间的差异并不显著(t(29)= -1.32, p>0.05)。

统计分析软件课程期末案例分析作业性别及职称对工资的影响因素分析--- 基于有序选择模型的实证分析员兵帅学院商学院、专业:会计学、学号:20133150144、邮箱: yunbingshuai@一、研究背景亚当斯密《国富论》中说:“一国国民每年的劳动,本来就是供给他们每年消费的一切生活必需品和便利的源泉。
”一个劳动者的工资,要用来养家糊口,因此对于它的研究至关重要。
职工工资的增长逐渐成为一个热点话题,在百度中输入“职工工资”,你会得到非常多相关报道,工资协商制、工资拖欠、工资保障机制也成为学术界人士争相研究的焦点。
而也是随着职工工资的增长,其他的一些问题,诸如个税征收、社会保障机制改革等接踵而来。
因此,研究好职工工资的影响因素,对于预测工资走向,安排生产生活,体制改革等有积极意义。
影响工资的因素有很多,在此我们主要选性别和职称这两个因素来研究,从该研究中发现更深层次的原因,这就是本问研究的主要目的二、研究方法、数据来源和变量选择本文选取了不同员工的性别、职称、工资等数据,以分析性别、职称对职工员工工资的影响,三、实验描述及实验过程(一)实验描述一、针对数据职工数据•绘制统计图1•生成年龄和基本工资的统计图2•生成职称和基本工资的统计图3•生成文化程度和基本工资的统计图二、针对数据职工数据•求出描述性统计量(如均值,方差,标准差等)三、进行一元回归分析四、进行多元回归分析㈡实验过程(一)利用SPSS绘制统计图1、打开“职工数据.sav”,调用Graphs菜单的Bar功能,绘制直条图。
直条图用直条的长短来表示非连续性资料的数量大小。
弹出Bar Chart定义选项。
2、在定义选项框的下方有一数据类型栏,大多数情形下,统计图都是以组为单位的形式来体现数据的。
在定义选项框的上方有3种直条图可选:Simple为单一直条图、Clustered为复式直条图、Stacked为堆积式直条图,本实验选单一直条图。
3、点击 Define 钮,弹出 Define Clustered Bar: Summaries for groups of cases 对话框,在左侧的 变量列表中选基本工资点击按钮使之进入 Ba 申-Represan 栏的Othe 頑'summary fun ction4、点击Titles 钮,弹出Titles 对话框,在Title 栏内输入“不同性别的基本工资状况”/ “不同职称的基本工资状况”/ “不同文化程度的基本工资状况”,点击 Continue 钮返回DefineClustered Chart: Summaries for groups of cases 对话框,再点击 OK 钮即完成。
实验报告
实验目的: 通过上机操作, 熟练掌握spss相关知识。
实验内容:
(一)1、首先将表格导入到spss中, 出现如下图结果:
2.选择: 分析——描述统计—频率, 出现如下图的表格,
, /
3、将V1导入到变量中, 然后点击统计量, 出现如下图的表格, 在表格中, 点击, 均值、中位数、四分位数, 标准差。
点击继续, 就完成第一题, 出现下图的结果。
以上就是第一题的结果。
(二)
1.首先将表格导入到spss中, 如下图:
2.从上表中, 可知, 方法A要比B.C的只都要高, 可见平均值要高于B.C, 就应该对这三组进行平均值, 方差的计算进行比较。
选择: 分析——描述统计——描述, 出现如下图的表格:
将方法A.B.C分别导入到变量中, 然后点击选项这个按钮, 出现如下图的表格进行选择:
可以选择标准差, 最大值, 最小值, 均值, 然后点击继续, 则会出现结果, 通过对结果进行对比, 选择方案。
由图可知, 方法A的平均值高于B、C, 而且最小值也都大于B、C的最大值, 可知A的组装优越于B、C, 即使标准差大于B, 稳定性稍微差于B, 但总体上组装的结果要比B好, 所以要选择方案A。
SPSS相关分析实验报告实验目的:通过SPSS软件进行相关分析,探究两个变量之间的相关性。
实验材料与方法:1. 实验对象:100名高中学生。
2. 实验变量:X变量表示学生课外阅读时间(单位:小时),Y变量表示学生考试成绩(百分制)。
3. 实验工具:SPSS软件。
实验步骤:1. 数据收集:调查100名高中学生的课外阅读时间和考试成绩,并记录在调查表中。
2. 数据录入:将调查表中的数据录入SPSS软件的数据编辑器中。
3. 数据分析:a. 相关性分析:打开SPSS软件,选择"分析"菜单下的"相关"子菜单,然后选择"双变量"选项。
b. 设置变量:将X变量(课外阅读时间)和Y变量(考试成绩)设置为分析变量。
c. 选择统计指标:选择所需统计指标,如相关系数、p值等。
d. 进行分析:点击"确定"按钮,SPSS将自动计算相关系数和p值,并生成相应的结果报告。
4. 数据报告:根据SPSS生成的结果报告,编写实验报告。
实验结果与分析:经过对SPSS软件的分析,得出以下结果:1. 相关系数:X变量(课外阅读时间)和Y变量(考试成绩)的相关系数为0.75,说明两个变量之间存在较强的正相关关系。
2. P值:相关系数的p值为0.001,小于显著性水平(α=0.05),说明相关系数具有统计学意义。
3. 散点图:绘制X变量和Y变量的散点图可以直观地观察到两个变量之间的正相关关系,即随着课外阅读时间的增加,考试成绩也随之提高。
结论:通过SPSS软件的相关分析,我们发现学生的课外阅读时间和考试成绩之间存在较强的正相关关系。
这意味着增加课外阅读时间可以提高学生的考试成绩。
对于教育者来说,可以通过鼓励学生增加课外阅读时间来促进其学术成绩的提升。
实验总结与改进:通过本次实验,我们成功地使用SPSS软件进行了相关分析,研究了课外阅读时间与考试成绩之间的关系。
然而,本实验仅限于高中学生,样本量有限,可能存在一定的局限性。
实验报告课程名称:统计分析软件(SPSS)学生实验报告一、实验目的及要求二、实验描述及实验过程(一)、利用SPSS绘制统计图1、打开“职工数据.sav”,调用Graphs 菜单的Bar功能,绘制直条图。
直条图用直条的长短来表示非连续性资料的数量大小。
弹出Bar Chart定义选项。
2、在定义选项框的下方有一数据类型栏,大多数情形下,统计图都是以组为单位的形式来体现数据的。
在定义选项框的上方有3种直条图可选:Simple为单一直条图、Clustered 为复式直条图、Stacked为堆积式直条图,本实验选单一直条图。
3、点击Define钮,弹出Define Clustered Bar: Summaries for groups of cases对话框,在左侧的变量列表中选基本工资点击按钮使之进入Bars Represent栏的Other summary function选项的Variable框,选性别/文化程度/职称点击按钮使之进入Category Axis框。
1.点击analyze中的Descriptive Statistics选择frequencies,弹出一个frequencies对话框,选中基本工资和年龄拖入Variable(s)列2.点击statistics选择相应的统计量(例如:Mean,.median,mode等)3.点击continue ,点击OK。
(三)、用SPSS做回归分析(一元线性回归)1.点击Graphs 选择Scatter/dot2.选择simple scatter 点击Define3.将基本工资这个变量输入Y-Axis ,将年龄输入X-Axise4.点击OK ,结果如图5.点击analyze中的regression选择linear,将这个基本工资变量输入 Dependent ,将年龄输入Independt(s6.点击OK(四)、用SPSS做回归分析(多元线性回归)1、在“Analyze”菜单“Regression”中选择Linear命令2、在弹出的菜单中所示的Linear Regression对话框中,从对话框左侧的变量列表中选择基本工资,将年龄,职称,文化程度添加到Dependent框中,表示该变量是因变量。
spss相关分析实验报告SPSS相关分析实验报告引言:在社会科学研究中,统计分析是不可或缺的一部分。
SPSS(Statistical Package for the Social Sciences)作为一款功能强大的统计分析软件,被广泛应用于社会科学领域的数据处理和分析。
本实验报告将介绍我所进行的一项SPSS相关分析实验,并展示结果和结论。
实验设计:本次实验旨在探究人们的幸福感与社交支持之间的关系。
为了达到这个目的,我采集了一份包含幸福感和社交支持两个变量的问卷调查数据。
幸福感变量使用了一个10分制的评价,社交支持变量使用了一个5分制的评价。
数据处理:首先,我导入了收集到的数据,并进行了数据清洗。
在数据清洗过程中,我删除了缺失值和异常值,以确保数据的准确性和可靠性。
接下来,我使用SPSS软件进行了相关分析。
结果分析:通过SPSS的相关分析功能,我得到了幸福感和社交支持之间的相关系数。
相关系数是衡量两个变量之间相关程度的统计指标,其取值范围为-1到1。
相关系数为正值表示两个变量正相关,为负值表示两个变量负相关,接近0表示无相关关系。
在本次实验中,我得到的幸福感和社交支持之间的相关系数为0.72,且p值小于0.05。
这意味着幸福感和社交支持之间存在着显著正相关关系,且相关程度较高。
换句话说,社交支持的增加会显著提高人们的幸福感。
讨论:这一实验结果与之前的研究相一致,表明社交支持对于个体的幸福感具有积极影响。
社交支持可以提供情感上的支持、实质上的帮助和信息交流,从而增加个体的幸福感。
这一结果对于社会工作者和心理健康专家具有重要的指导意义,可以帮助他们设计和实施幸福感提升的干预措施。
然而,本实验也存在一些限制。
首先,样本容量较小,可能导致结果的偏差和不可靠性。
其次,本实验采用的是自报问卷调查方式,受到被试主观意识和记忆偏差的影响。
未来的研究可以采用更大样本和多种数据收集方式,以提高结果的可信度和普适性。
SPSS相关分析实验报告篇一:spss对数据进行相关性分析实验报告实验一一.实验目的掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。
二.实验原理相关性分析是考察两个变量之间线性关系的一种统计分析方法。
更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。
P值是针对原假设H0:假设两变量无线性相关而言的。
一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。
越小,则相关程度越低。
而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。
三、实验内容掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。
(1)检验人均食品支出与粮价和人均收入之间的相关关系。
a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。
C.在对话窗口中点击ok,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间显著相关。
人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间也显著相关。
(2)研究人均食品支出与人均收入之间的偏相关关系。
读入数据后:A.点击系统弹出一个对话窗口。
B.点击OK,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.000<0.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.8665<0.921,说明它们之间的显著性关系稍有减弱。
《SPSS统计软件应用》实验报告册20 - 20 学年第学期班级:学号:姓名:授课教师:实验教师:实验学时:实验组号:目录实验一SPSS的数据管理 (3)实验二描述性统计分析 (7)实验三均值检验 (10)实验四相关分析 (12)实验五因子分析 (15)实验六聚类分析 (19)实验七回归分析 (23)实验八判别分析 (25)实验一SPSS的数据管理一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容及步骤:1、定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
表1 大学教师基本情况调查表1.定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
实验步骤:(1)、打开定义变量的界面启动SPSS,进入主界面,单击图6-2所示的屏幕左下角的“Variable View”选项卡,打开定义变量的表格。
(2)、输入变量名,符合变量的命名规则在“Name”列的第一个单元格输入第一个变量名,如:“xm”。
(3)、确定变量类型,单击“Type”列的第一个单元格,如图6-3所示,SPSS的默认变量类型为数值型。
单击数值型变量后的“···”,弹出如图6-4所示的对话框,用户可以从该对话框中选择其他的变量类型。
(4)、设置字段值(5)、依次按要求输入完毕即可实验结果:实验分析:本实验,主要是按照要求一步一步来设置条件即可完满完成实验。
2 、高校提前录取名单的确定某高校今年对部分考生采取单独出题、提前录取的招生模式。
现有20名来自国内不同省市的考生报考该校,7个录取名额。
见数据文件compute.sav. 该校制定了如下录取原则:(1)文化课成绩由数学、语文、英语和综合四门成绩组成。
文化课成绩制定最低录取分数线:400分。
(2)个人档案中若有“不良记录”,不予录取。
(3)对西部考生和少数民族考生,给予加分优惠。
少数民族考生加20分,西部考生加10分。
(4)对参加过省以上竞赛并取得三等奖以上名次的考生,每项加10分。
(5)文化课成绩和加分总和构成综合分,录取综合排名为前7名的学生。
练习:利用spss软件,综合利用所学,给出成绩排名的操作步骤。
实验内容:2.高校提前录取名单的确定某高校今年对部分考生采取单独出题、提前录取的招生模式。
现有20名来自国内不同省市的考生报考该校,7个录取名额。
见数据文件compute.sav. 练习:利用spss软件,综合利用所学,给出成绩排名的操作步骤。
实验步骤:(1)计算文化课总成绩: 打开数据文件compute.sav.变量计算transform->compute,在弹出的compute variable对话框中,定义变量zcj, type&label中的label值设为“文化课总成绩”,numberic expression 设置“语文+数学+英语+综合”,单击ok按钮。
(2)筛选出400分以上并且没有不良记录的学生:date-select case ,在弹出的对话框中选择if condition is satisfied 单选按钮并单击if 按钮,在弹出的select case :if 对话框中,设置不良记录=0 & zcj>=400的判断条件,单击continue,选择deleted单选按钮,最后单击ok 。
(3)计算西部考生和少数名族加分项:transform->compute,target variable 选择zcj。
if 条件中设置“名族=2 or 名族=3 or 民族=4”,numberic expression中zcj+20;If 条件中设置“名族=5”numberic expression中设置zcj+10(4)计算最综成绩,并排序:transform->compute,numberic expression ,zcj 奖项*10. 选择“Data→Sort Cases”命令,弹出“Sort Cases”对话框,把“zcj”变量选入“Sort by”中,并在Sort Order中选择“Ascending(降序)”选项,将学生成绩按升序排列,单击“OK”按钮。
实验结果:选取综合成绩升序排列后的前七名即可,如图所示:录取的分别是艾甫尔513分、孙悦婷495分、张囯欣471分、果冻样462分、杨乐451分、高超438分、易仲勃434分。
实验分析:本实验,主要是按照要求一步一步来设置条件,最后边计算有点难,就是算加分。
首先要解决不留空的,不然最后没法求和。
根据结果选出符合要求的即可。
三、实验小结:实验中遇到的问题及解决办法、心得体会等等...本实验,第一小题,主要考察我们创建数据文件的结构,即数据文件的变量和定义变量的属性。
老师上课时给我们演示很到位,在老师的详细讲解下,我熟悉了spss软件界面,以及一些主要组成部分,但是里面的一些具体参数还不太清楚,不过常用主要属性都掌握了,没有太大问题。
第二小问,问题就相当大了,先是选择不小于400分的,经常排除不了,后来在同学的帮助下克服了。
然后在加分部分比较难,最开始先符合一个加一个,但是后来发现不是,经过反复尝试,把需要加分的先列出来,最后汇总,但是没加粉的,我没计算,导致最后求和时,不能加,因为有的是空字符,而不是数字0,后来又经改进,把没有加分的同学,在相对加分位置是-表示,最后才完满完成实验。
实验二描述性统计分析一、实验目的利用SPSS进行描述性统计分析。
要求掌握频数分析(Frequencies过程)、描述性分析(Descriptives过程)、交叉列联表分析(Crosstabs过程)。
二、实验内容及步骤1、打开数据文件descriptives.sav,是从某校选取的3个班级共16名学生的体检列表,要求以班级为单位列表计算年龄,体重和身高的统计量,包括极差,最小最大值,均值,标准差和方差。
给出操作步骤和分析结果。
1)打开数据文件descriptives.sav,选“数据”菜单的“选择个案”命令项,弹出对话框。
选择“如果条件满足”单选按纽,点击“如果”钮,弹出对话框,输入条件:班级=1单击“继续”按纽。
在“输出”栏选择“过滤掉未选定的个案”项,单击“确定”按钮。
2)在主菜单栏单击“分析”,在出现的下拉菜单里移动鼠标至“描述性统计”项上,在出现的次菜单里单击“描述性”项,打开对话框。
从左则的源变量框里选择年龄、体重、身高三个变量进入“变量”框里。
单击“选项”钮,弹出“选项”对话框,选中均值Std.deviation 标准差最小值方差最大值范围复选框,单击“继续”按钮,单击“确定”按钮。
3)2、3班操作类似,只需将条件改为“班级=2”、“班级=3”即可一班二班。
三班:2、某医生用国产呋喃硝胺治疗十二指肠溃疡,以甲氰咪胍作对照组,问两种方法治疗效果有无差别三、练习题:1、打开数据文件descriptives.sav,是从某校选取的3个班级共16名学生的体检列表,要求以班级为单位列表计算年龄,体重和身高的统计量,包括极差,最小最大值,均值,标准差和方差。
给出操作步骤和分析结果。
分析:1班年龄的最大值,最小值,平均数最小,方差和标准差最大;体重的极差,最大值,最小值,平均数,方差,标准差都最小;身高的极差,最大值,最小值,平均数,方差,标准差都最小。
2班年龄的最大值,最小值,平均数居中,方差和标准差最小;体重的极差,最大值,最小值,平均数,方差,标准差都居中;身高的极差,最大值,最小值,平均数,方差,标准差都居中3班年龄的最大值,最小值,平均数最大,方差和标准差居中;体重的极差,最大值,最小值,平均数,方差,标准差都最大;身高的极差,最大值,最小值,平均数,方差,标准差都最大。
2、某医生用国产呋喃硝胺治疗十二指肠溃疡,以甲氰咪胍作对照组,问两种方法治疗效果有无差别三个变量――行变量、列变量和指示每个格子中频数的变量,然后用Weight Cases对话框指定频数变量,最后调用Crosstabs过程进行X2检验。
假设三个变量分别名为R、C和W,则数据集结构和命令如下):R C W1.001.054.01.002.0044.0 02.001.00 8.002.002.0020.0 0分析:卡方检验统计量的p值=0.013<0.05,拒绝原假设,呋喃硝胺治疗十二指肠溃疡有显著性影响。
四、实验小结:实验中遇到的问题及解决办法、心得体会等等...1、通过本次实验,使我较好地掌握了利用SPSS进行描述性统计分析的方法,学会了频数分布(Frequencies过程)、描述性分析(Descriptives过程)、交叉列联表分析(Crosstabs过程)。
2、频数分布分析主要通过频数分布表、条形图和直方图,以及集中趋势和离散趋势的各种统计量来描述数据的分布特征。
3、Descriptives过程可对变量进行描述性统计分析,计算并列出一系列相应的统计指标,其功能和频数分布过程类似,主要以计算数值型单变量的统计量为主。
实验三均值检验一、实验目的学习利用SPSS进行单样本、两独立样本以及成对样本的均值检验。
二、实验内容及步骤1、一个生产高性能汽车的公司生产直径为322mm的圆盘制动闸。
公司的质量控制部门随机抽取不同机器生产的制动闸进行检验。
共4台机器,每台机器抽取16支产品。
见数据文件ttest1.sav,要求检验每个机器生产的产品均值和322在90%的置信水平下是否有显著差异。
步骤:(1)打开数据文件ttest1.sav,选择菜单“Analyze→Compare Means→One-Sample T Test”。
弹出“One-Sample T Test”对话框。
(2)在对话框左侧的变量列表中选择变量“制动闸直径”进入“Test Variable(s)”框;在“Test Value”编辑框中输入过去的平均生产直径值322 选择Options,置信水平90%,单击contiue-ok2、在体育课上记录14名学生乒乓球得分的数据,男女各7名。
数据如下:男:82.00 80.00 85.00 85.00 78.00 87.00 82.00女:75.00 76.00 80.00 77.00 80.00 77.00 73.00比较在置信度为95%的情况下男女生得分是否有显著差别。
步骤:(1)建立表结构并输入数据(2)选择菜单“Analyze→Compare Means→Independent-samples T Test”项,弹出“Independent- samples T Test”对话框。