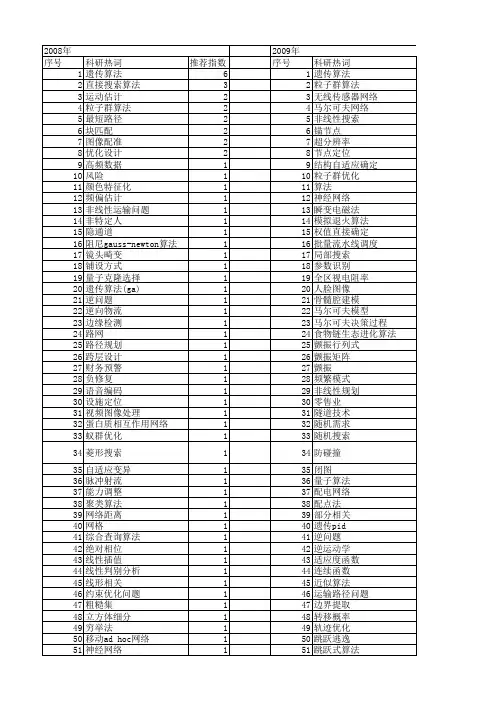
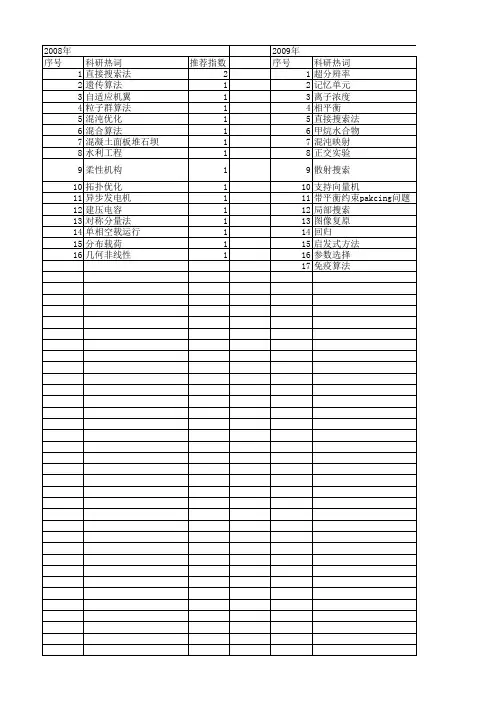
直接搜索算法
- 格式:pdf
- 大小:481.75 KB
- 文档页数:60

搜索算法⼊门详解什么是搜索算法搜索算法是利⽤计算机的⾼性能来有⽬的的穷举⼀个问题解空间的部分或所有的可能情况,从⽽求出问题的解的⼀种⽅法。
现阶段⼀般有枚举算法、深度优先搜索、⼴度优先搜索、A*算法、回溯算法、蒙特卡洛树搜索、散列函数等算法。
在⼤规模实验环境中,通常通过在搜索前,根据条件降低搜索规模;根据问题的约束条件进⾏剪枝;利⽤搜索过程中的中间解,避免重复计算这⼏种⽅法进⾏优化。
搜索⽅式⾸先给⼤家扫个盲在搜索中,不仅仅只有常见的递归式搜索,也存在着⼀部分正向迭代式搜索,但是在真正的使⽤中递归式搜索占到了绝⼤多数,基本上所有的递归式搜索⽤是递归都可以实现只不过代价⽐较⼤⽐如我们想要求出数字 1 - 3之间所有数字的全排列这个问题很简单,简单到不想⽤⼿写。
还是写⼀下吧对于这个问题我们只⽤三重循环就可以完全搞定它int n = 3;for(int i = 1;i <= n ;i ++){for(int j = 1;j <= n ;j ++){for(int k = 1;k <= n; k++){if(i != j && i != k && j != k){printf("%d %d %d\n",i ,j ,k);}}}}这个时候有同学就会问了,既然⽤递推就可以实现我们的搜索那么我们为什么还要费劲的去写递归呢?原因是之前举的哪⼀个例⼦规模很⼩,如果此时我们讲n 换成10 我们需要枚举 1 - 10的全排列那么你⽤递推的话代码⼤致式这样的int n = 3;for(int i = 1;i <= n ;i ++){for(int j = 1;j <= n ;j ++){for(int k = 1;k <= n; k++){for(int o = 1; 0 <= n ;o++){for(int p = 1;p <= n ; p++){for(){for().......不写了我吐了}}}}}}⾸先不说你有没有⼼情实现,光是变量的字母引⽤就够你喝⼀壶了这⾥n = 10 还没超过26,那如果超过了26,你岂不是要把汉字搬来了....这⾥就暴露出⼀个问题。

A*算法
A* [1](A-Star)算法是一种静态路网中求解最短路径最有效的直接搜索方法,也是许多其他问题的常用启发式算法。
注意——是最有效的直接搜索算法,之后涌现了很多预处理算法(如ALT,CH,HL等等),在线查询效率是A*算法的数千甚至上万倍。
公式表示为:f(n)=g(n)+h(n),
其中,f(n) 是从初始状态经由状态n到目标状态的代价估计,
g(n) 是在状态空间中从初始状态到状态n的实际代价,
h(n) 是从状态n到目标状态的最佳路径的估计代价。
(对于路径搜索问题,状态就是图中的节点,代价就是距离)
h(n)的选取
保证找到最短路径(最优解的)条件,关键在于估价函数f(n)的选取(或者说h(n)的选取)。
我们以d(n)表达状态n到目标状态的距离,那么h(n)的选取大致有如下三种情况:
1. 如果h(n)< d(n)到目标状态的实际距离,这种情况下,搜索的点数多,搜索
范围大,效率低。
但能得到最优解。
2. 如果h(n)=d(n),即距离估计h(n)等于最短距离,那么搜索将严格沿着最短路
径进行,此时的搜索效率是最高的。
3. 如果h(n)>d(n),搜索的点数少,搜索范围小,效率高,但不能保证得到最
优解。
[2]。

搜索引擎算法分析与应用随着互联网技术的不断发展,搜索引擎已经成为人们获取信息的主要途径之一。
然而,搜索引擎背后的算法其实也是极其复杂的。
在本文中,我们将对搜索引擎算法进行一些简单的分析,并说明它们在实际应用中是如何帮助人们获取精准的信息。
一、基本原理搜索引擎的基本原理是将互联网上的信息通过各种手段收录到一个巨大的数据库中,然后通过搜索关键词来匹配这些信息,并按照一定的规则进行排序。
那么如何确定哪些信息是与搜索关键词最相关的呢?这就需要涉及到搜索引擎算法了。
搜索引擎的算法可以分为两个部分:爬虫算法和检索算法。
其中,爬虫算法用于收录互联网上的信息,而检索算法则用于根据用户的搜索关键词来返回最相关的信息。
二、爬虫算法爬虫算法是搜索引擎中极其重要的一部分,它决定了搜索引擎能够收录哪些网站以及如何收录。
爬虫算法主要分为以下几个部分:1.网址识别首先,爬虫需要确定待抓取的网站。
这涉及到网址的识别问题。
一般来说,爬虫会从一些知名的入口网站开始,然后通过网页中的链接不断地抓取其他网站。
2.内容解析在确定了待抓取的网站之后,爬虫需要对这些网站进行内容解析。
一般来说,爬虫会通过正则表达式等方法来识别页面中的文本、图片、视频等内容,并将这些内容存储到数据库中。
3.网站排重当爬虫不断地抓取网站时,可能会遇到重复网站的情况。
因此,搜索引擎需要对网站进行排重,以保证数据库中只有一份相同的网站内容。
三、检索算法检索算法是搜索引擎中决定搜索结果排序的核心算法。
以下是一些常见的检索算法:1.关键词匹配在完成用户搜索关键词之后,搜索引擎需要将这些关键词与数据库中的网站内容进行匹配。
匹配的原则是:如果一个网站中包含了用户输入的所有关键词,那么这个网站会排在搜索结果的前面。
2.网站权重除了关键词匹配之外,搜索引擎还需要对不同网站的权重进行评估。
一般来说,权重较高的网站会获得更好的排名。
而网站权重的评估主要依靠“PageRank”算法。




实现简单并高效的搜索算法搜索算法是计算机科学中一个重要的主题,可以解决各种搜索问题。
搜索算法的目标是在给定的一组数据中找到所需的特定数据。
在本文中,我们将讨论几种简单且高效的搜索算法,包括线性搜索、二分搜索和哈希搜索。
1.线性搜索(Linear Search)线性搜索是最简单的搜索算法之一,也是最直观的一种。
它从给定的一组数据中按顺序逐个查找所需的数据,直到找到或搜索完所有的数据。
假设有一个包含n个元素的数据集合,要查找的元素为x。
线性搜索的实现如下:```function linearSearch(arr, x):for i in range(len(arr)):if arr[i] == x:return i #返回元素的索引return -1 #如果没有找到,返回-1```线性搜索的时间复杂度是O(n),其中n是数据集合的大小。
这是因为在最坏情况下,需要遍历整个数据集合来找到所需的元素。
2.二分搜索(Binary Search)二分搜索是一种更高效的搜索算法,但前提是数据必须是有序的。
它通过将数据集合分成两部分,并根据目标值与中间元素的大小比较,确定在哪一部分继续搜索。
假设有一个有序数组arr,要查找的元素为x。
二分搜索的实现如下:```function binarySearch(arr, x):low = 0high = len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == x:return mid #返回元素的索引elif arr[mid] < x:low = mid + 1else:high = mid - 1return -1 #如果没有找到,返回-1```二分搜索的时间复杂度是O(log n),其中n是数据集合的大小。
这是因为每次搜索都将数据集合减半,直到找到所需的元素或确定不存在。
3.哈希搜索(Hash Search)哈希搜索是一种基于哈希表的搜索算法。

1.差分进化算法背景差分进化(Differential Evolution,DE)是启发式优化算法的一种,它是基于群体差异的启发式随机搜索算法,该算法是Raincr Stom和Kenneth Price为求解切比雪夫多项式而提出的。
差分进化算法具有原理简单、受控参数少、鲁棒性强等特点。
近年来,DE在约束优化计算、聚类优化计算、非线性优化控制、神经网络优化、滤波器设计、阵列天线方向图综合及其它方面得到了广泛的应用。
差分算法的研究一直相当活跃,基于优胜劣汰自然选择的思想和简单的差分操作使差分算法在一定程度上具有自组织、自适应、自学习等特征。
它的全局寻优能力和易于实施使其在诸多应用中取得成功。
2.差分进化算法简介差分进化算法采用实数编码方式,其算法原理同遗传算法相似刚,主要包括变异、交叉和选择三个基本进化步骤。
DE算法中的选择策略通常为锦标赛选择,而交叉操作方式与遗传算法也大体相同,但在变异操作方面使用了差分策略,即:利用种群中个体间的差分向量对个体进行扰动,实现个体的变异。
与进化策略(Es)采用Gauss或Cauchy分布作为扰动向量的概率密度函数不同,DE使用的差分策略可根据种群内个体的分布自动调节差分向量(扰动向量)的大小,自适应好;DE 的变异方式,有效地利用了群体分布特性,提高了算法的搜索能力,避免了遗传算法中变异方式的不足。
3.差分进化算法适用情况差分进化算法是一种随机的并行直接搜索算法,最初的设想是用于解决切比雪夫多项式问题,后来发现差分进化算法也是解决复杂优化问题的有效技术。
它可以对非线性不可微连续空间的函数进行最小化。
目前,差分进化算法的应用和研究主要集中于连续、单目标、无约束的确定性优化问题,但是,差分进化算法在多目标、有约束、离散和噪声等复杂环境下的优化也得到了一些进展。
4.基本DE算法差分进化算法把种群中两个成员之间的加权差向量加到第三个成员上以产生新的参数向量,这一操作称为“变异”。

搜索引擎算法分析随着互联网的快速发展,搜索引擎作为网民获取信息的主要方式,其优良的检索效果备受人们的欢迎。
然而,搜索引擎背后的技术并不简单,其中最核心的部分就是搜索引擎算法。
那么,搜索引擎算法是什么?它又是如何实现优质搜索结果的呢?一、搜索引擎算法概述搜索引擎算法,是指一系列用于生成搜索结果的数学计算或规则。
如果将搜索引擎比作一个宏伟的图书馆,那么搜索引擎算法就是其中的索书号和分类标准。
通过算法的引导,搜索引擎可以根据用户的输入内容,在其巨大的索引数据库中迅速找到相关的网页,从而为用户提供高质量、个性化的搜索结果。
二、搜索引擎算法的优化随着搜索引擎用户数量不断增多,对搜索结果的要求也越来越高。
因此,搜索引擎公司在不断升级修改自己的搜索引擎算法,以提升搜索结果的品质,满足用户的需求。
就像谷歌公司的创始人拉里·佩奇曾说:“我们不会因为用户数超过了100亿而停滞不前。
”那么,为了提升搜索结果的品质,企业在优化算法时需要关注以下几点:1. 移动优化如今,移动互联网的发展极为迅速,搜索引擎公司必须及时优化算法以适应这一变化。
一方面,搜索引擎的结果页面需要适配移动端设备,提供更加方便、快捷的搜索体验;另一方面,为了提高页面的加载速度,企业需要针对移动设备进行技术优化,以获得更好的用户评价。
2. 内容优化无论搜索引擎用户来自哪个国家,内容优化始终是重点,包括网站内容的质量、原创程度、相关性。
如果企业能够保持产出高品质的内容,并及时更新,那么搜索引擎就会更容易将这些网站与用户的搜索需求联系起来,从而提供更准确的搜索结果。
3. 本地化为了提供更个性化、本地化的搜索结果,搜索引擎公司不断加强对用户地理位置信息的获取和处理,并通过IP地址、GPS定位等技术将它们与提供服务的商家、场所联系起来。
同时,企业也可以通过为用户提供特定服务,例如地图、导航、美食推荐等来提高搜索体验。
三、搜索引擎算法的设计思想搜索引擎算法的设计理念可以概括为“排序+遍历+匹配+反馈!”具体来说,可以由以下几个方面来展开说明:1. 排序搜索引擎根据关键词的匹配程度,对一系列网页进行排序,当用户输入的关键词与网页的内容、标题、描述等元素高度匹配时,那么这些网页就会排在搜索结果的靠前位置。
低压排汽缸气动优化设计摘要:结合三阶贝齐尔曲线参数化方法、静压恢复系数评价方法、拉丁立方试验设计、三阶响应面近似模型及Hooke-Jeeves直接搜索算法的组合优化策略,基于iSight优化软件平台,建立了排汽缸外导流环优化设计系统。
以静压恢复系数最大为目标完成了单独排汽缸优化设计,采用数值求解三维Reynolds-Averaged Navier-Stokes (RANS)方程的方法验证了耦合低压末级和排汽缸结构的排汽缸优化设计系统的有效性。
结果表明,基于优化设计系统进行的优化设计,使得排汽缸静压恢复系数相对于初始排汽缸提高了61.1%,排汽缸蜗壳内的静压损失明显减小,从而验证了排汽缸优化设计的有效性和耦合低压末级对排汽缸气动性能分析的必要性。
关键词:排汽缸;静压恢复;优化设计;数值模拟中图分类号:TK474.7文献标志码:A文章编号:0253-987X(2015)03-0019-06冷凝式汽轮机排汽缸的主要功能是将低压末级出口的蒸汽动能转化为压力能,在凝汽器真空度给定的条件下,可降低末级出口截面处的静压,增加末级的出力,提高汽轮机机组的热效率。
大功率汽轮机低压缸末级出口平均绝对马赫数为0.5~0.8,其排汽动能约占机组总焓降的1.5%,如果能有效地回收、利用这部分能量,可以使机组的热效率提高约1%。
因此,高性能排汽缸设计是提高汽轮机能量转换效率的重要技术手段。
图1给出了典型的大功率汽轮机低压缸三维结构图。
静压恢复主要在排汽缸的扩压器导流环中完成,还有一部分在排汽缸的蜗壳中完成。
蒸汽在该结构的排汽缸内流动是先轴向再径向流向凝汽器。
科研人员采用实验测量和数值模拟等方法研究了排汽缸内的三维流动形态和损失产生机理。
随着优化设计方法和计算机技术的进步,提高排汽缸静压恢复系数的优化设计得到了发展。
陈川等采用正交试验设计、二次多项式响应面近似评价方法和二次规划的组合优化策略对排汽缸进行了优化设计,以提高排汽缸的静压恢复能力。
搜索引擎算法定义获得网站网页资料,建立数据库并提供查询的系统,我们都可以把它叫做搜索引擎。
搜索引擎的数据库是依靠一个叫“网络机器人(crawlers)”或叫“网络蜘蛛(Spider)”的软件,通过网络上的各种链接自动获取大量网页信息内容,并按一定的规则分析整理形成的。
Google、百度都是比较典型的搜索引擎系统。
为了更好的服务网络搜索,搜索引擎的分析整理规则---既搜索引擎算法是变化的。
某搜索引擎排名的计算公式*leScore = (KW Usage Score * 0.3) + (Domain Strength * 0.25) +(Inbound Link Score * 0.25) + (User Data * 0.1) + (Content QualityScore * 0.1) + (Manual Boosts) – (Automated & Manual Penalties)翻译:*分数=(相关关键词分数X0.3)+(域名权重X0.25)+(外链分数X0.25)+(用户数据X0.1)+(内容质量分数X0.1)+(人工加分)-(自动或人工降分)编辑本段公式中的因子分析从公式中我们可以清楚的知道,影响pagerank分数的因素依次是“相关关键词”、“域名”、“外链”、“用户数据”、“内容质量”以及“人工干预”六个方面。
那么又是哪些因素影响到了这几个方面呢?一、关键词分数1.网页title中关键词的处理2.H标签(h1-h6)中关键词的处理3.文本内容中关键词的密度4.外链中关键词的选择5.域名中的关键词二、域名权重1.域名注册前的历史问题2.域名注册时间的长短3.外链网站的权重4.外链、给出链接的相关度5.是否使用历史、链接形式三、外链分数1.链接域名权重2.是否锚文本3.链接数量/链接权重(PR或其他参数)4.外链网页的主题相关度5.链接的时间四、用户数据1.搜索引擎结果页面(SERPs)的点击率2.用户在网页上呆的时间3.域名或URL搜索量4.访问量及其他*可以监测到的数据(工具条、GA等)五、内容质量分数1.内容的相关度2.内容的原创性3.内容的独特性4.内容的抢先性和长效性六、人工干预1.*投票人员干预2.关键词人工加(扣)分3.机器算法干。
搜索引擎算法详解一、搜索词处理当搜索引擎接收到用户输入的关键词后,需要对关键词做相应处理,才能进入排名过程。
处理包括这么几个方面:1.中文分词与页面索引一样,关键词也需要进行中文分词,将查询字符串转换为以词为基础的关键词组合。
原理和页面分词相同。
2.去停止词跟索引时一样,搜索引擎也需要把关键词中的停止词去掉,为了提高排名相关性及效率。
3.指令处理关键词完成分伺候,搜索引擎的默认处理方式是在关键词之间使用“与”逻辑。
也就是说用户搜索“SEO博客”时,程序分词为“SEO”和“博客”两个词,搜索引擎排序时默认认为,用户寻找的是既包含“SEO”,也包含“博客”的也页面。
那么只包含“SEO”不包含“博客”,或者只包含“博客”不包含“SEO”的页面,会被认为是不符合搜索条件的。
当然,这只是一种简单的说法,其实内部处理还是相当复杂,实际上我们还是会看到只包含一部分关键词的搜索结果,这里与网站权重,还有页面内容等等有密切关联。
4.拼写错误矫正用户如果不小心输入的错误的拼写单词或者英文单词,搜索引擎会提示用户正确的单词。
比如:用户输入“SEO技数”,搜索引擎将提示用户:您要找的是不是“SEO 技术”。
5.整合搜索触发有些关键词会触发整合搜索,比如明星姓名就经常触发图片和视频内容,当前的热门话题又容易触发资讯内容。
什么词能够触发整合搜索,都是在关键词处理阶段进行处理。
二、文件匹配关键词经过处理后,搜索引擎得到的是以词为基础的关键词集合。
文件匹配阶段就是找出含有所有关键词的文件。
在索引部分提到的倒排索引使得文件匹配能够快速完成,假设用户搜索“关键词A 关键词B”,排名程序只要在倒排索引中找到“关键词A”和“关键词B”这两个词,就能找到分别含有这两个词的所有页面。
经过简单计算就能找出既包含“关键词A”,又包含“关键词B”的所有页面。
比如:“关键词A”中有文件1、文件3、文件6,“关键词B”中有文件2、文件4、文件6,那么既包含“关键词A”又包含“关键词B”的页面就是文件6。