SPSS之统计表和统计图
- 格式:ppt
- 大小:3.51 MB
- 文档页数:45


实验三SPSS统计分析与统计图表的绘制一、实验目的要求学生能够进行基本的统计分析;能够对频数分析、描述分析和探索分析的结果进行解读;完成基本的统计图表的绘制;并能够对统计图表进行编辑美化与结果分析;能够理解多元统计分析的操作(聚类分析和因子分析)。
二、实验内容与步骤2.1 基本的统计分析打开“分析/描述统计”菜单,可以看到以下几种常用的基本描述统计分析方法:1.Frequencies过程(频数分析)频数分析可以考察不同的数据出现的频数与频率,并且可以计算一系列的统计指标,包括百分位值、均值、中位数、众数、合计、偏度、峰度、标准差、方差、全距、最大值、最小值、均值的标准误等。
2.Descriptives过程(描述分析)调用此过程可对变量进行描述性统计分析,计算并列出一系列相应的统计指标,包括:均值、合计、标准差、方差、全距、最大值、最小值、均值的标准误、峰度、偏度等。
3.Explore过程(探索分析)调用此过程可对变量进行更为深入详尽的描述性统计分析,故称之为探索性统计。
它在一般描述性统计指标的基础上,增加有关数据其他特征的文字与图形描述,显得更加细致与全面,有助于用户思考对数据进行进一步分析的方案。
Descriptives:输出均数、中位数、众数、5%修正均数、标准误、方差、标准差、最小值、最大值、全距、四分位全距、峰度系数、峰度系数的标准误、偏度系数、偏度系数的标准误;Confidence Interval for Mean:平均值的%估计;M-estimators:作中心趋势的粗略最大似然确定,输出四个不同权重的最大似然确定数;Outliers:输出五个最大值与五个最小值;Percentiles:输出第5%、10%、25%、50%、75%、90%、95%位数。
4.Crosstabs过程(列联表分析)调用此过程可进行计数资料和某些等级资料的列联表分析,在分析中,可对二维至n维列联表(RC表)资料进行统计描述和χ2 检验,并计算相应的百分数指标。

使用SPSSSPSS中文版统计软件的统计分析操作方法SPSS(Statistical Package for the Social Sciences)是一种用于统计分析的软件工具,它可以帮助研究人员对数据进行处理、分析和解释。
下面将介绍SPSS中文版统计软件的常见统计分析操作方法。
一、数据导入和预处理1. 启动SPSS软件后,在主界面选择"文件"->"打开"->"数据",然后选择要导入的数据文件,如Excel或CSV格式文件。
2.在数据导入对话框中,选择正确的数据类型和分隔符,并指定变量名和数据属性。
3.完成数据导入后,可以对数据进行预处理操作,如数据清洗、变量选择、数据转换等。
二、描述统计分析1.在数据导入后,在主界面选择"统计"->"描述性统计"->"频数",然后选择要进行频数分析的变量。
2.设置所需的统计量和显示选项,如均值、标准差、最小值、最大值等,并生成描述统计表。
三、数据可视化1.在主界面选择"图表"->"柱形图",然后选择要进行柱形图分析的变量。
2.设置柱形图的样式、颜色和标题等,并生成柱形图。
3.可以根据需要选择其他类型的统计图表,如折线图、散点图、饼图等,以进行数据可视化展示。
四、假设检验1.在主界面选择"分析"->"描述统计"->"交叉表",然后选择要进行交叉表分析的变量。
2.设置所需的交叉表分析选项,如分组变量、交叉分类表等,并生成交叉表。
3.可以根据需要进行卡方检验、t检验、方差分析等假设检验方法来比较两个或多个变量之间的差异。
五、回归分析1.在主界面选择"回归"->"线性",然后选择要进行回归分析的因变量和自变量。



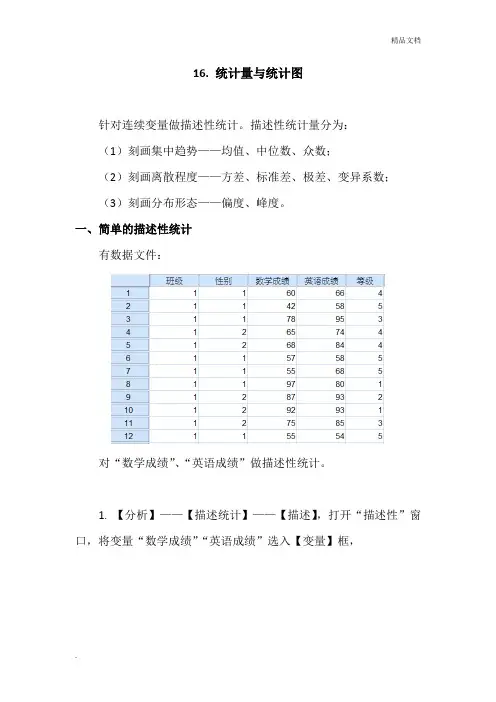
16. 统计量与统计图针对连续变量做描述性统计。
描述性统计量分为:(1)刻画集中趋势——均值、中位数、众数;(2)刻画离散程度——方差、标准差、极差、变异系数;(3)刻画分布形态——偏度、峰度。
一、简单的描述性统计有数据文件:对“数学成绩”、“英语成绩”做描述性统计。
1. 【分析】——【描述统计】——【描述】,打开“描述性”窗口,将变量“数学成绩”“英语成绩”选入【变量】框,2.点【选项】,打开“选项”子窗口,根据需要勾选点【继续】回到原窗口;若需要得到Z标准分数,勾选“将标准化得分另存为变量”;点【确定】得到描述统计量N 全距极小值极大值和均值标准差方差偏度峰度统计量统计量统计量统计量统计量统计量标准误统计量统计量统计量标准误统计量标准误数学成绩50 58 42 100 3789 75.78 1.974 13.960 194.869 -.174 .337 -.651 .662 英语成绩50 62 38 100 3966 79.32 2.280 16.123 259.936 -.725 .337 -.355 .662 有效的 N (列表状态)50注:默认是按变量选入顺序输出上表。
二、探索性描述统计输出统计量和统计图,其主要作用有:(1)检查异常值;(2)检验数据的分布特征(是否服从正态分布);1.【分析】——【描述统计】——【探索】,打开“探索”窗口,将变量“数学成绩”“英语成绩”选入【变量】框注:若在【因子变量】框选入若干分类变量,将按其水平值组合分别统计分析;注意勾选【输出】可选项的“两者都”。
2. 点【统计量】,打开“统计量”子窗口,“M-估计量”——当数据背离正态分布、带长尾、或有极端数据时,M-估计量仍能提供很好的中心趋势估计;“界外值”——可以检验数据是否有极端值存在;3. 点【绘制】,打开“图”子窗口,【箱图】勾选“按因子水平分组”,【描述性】勾选“茎叶图”、“直方图”,勾选“带检验的正态图”(检验数据是否具有正态性)点【继续】回到原窗口,点【确定】得到描述统计量标准误数学成绩均值75.78 1.974 均值的 95% 置信区间下限71.81上限79.755% 修整均值75.92中值75.50方差194.869标准差13.960极小值42极大值100范围58四分位距22偏度-.174 .337 峰度-.651 .662英语成绩均值79.32 2.280 均值的 95% 置信区间下限74.74上限83.905% 修整均值80.30中值85.00方差259.936标准差16.123极小值38极大值100范围62四分位距26偏度-.725 .337 峰度-.355 .662正态性检验Kolmogorov-Smirnov a Shapiro-Wilk统计量df Sig. 统计量df Sig.数学成绩.082 50 .200*.974 50 .340英语成绩.178 50 .000 .913 50 .001*. 这是真实显著水平的下限。



统计表、统计图针对数据“某高校学生衣物支出情况的调查分析”,回答下列问题:1. 分析被访者的月平均生活费、月平均衣物支出的分布情况;(频率)Frequencies2. 男、女同学在买衣服首选因素(涉及两个分类变量性别和买衣服首选因素,Crosstabs只能处理两个变量)、月平均衣物支出((连续变量F/ D /E 性别和月平均衣物支出)连续-直方图)、主要衣服类型方面(Frequency) 有何异同?(频率)1.其他分类变量(列联表)行=性别列=其他1.、Graphs barcharts clustered categoryaxis:月平均衣物defineclustersby:性别3. 四年级的同学中,主要衣物类型有哪些?Data->Select Cases frequencies4. 比较不同年级的同学在月平均生活费、月平均衣物支出方面的差异;Graphs scatter/dot simplescatter xndy5. 月平均生活费、月平均衣物支出之间有何关系?先散点分析相关比例Analyze comparemens one-wayanova dependentlist: 月平均生活费、月平均衣物支出factor:sex6. 请分析所在年级与主要衣物类型的关系?Crossestab7. 分析变量“平均月生活费”和“月平均衣物支出”的集中趋势,离散趋势;Graph –scatter-simple –define X YStd.deviation 标准差Variance 方差Range 极差(全距)S.E.mean均值的标准误Median 中位数Mode 众数Skewness 偏度Kurtosis 峰度频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。
Frequencies过程不仅可以产生详细的频数表,还可以按要求给出百分位点的数值,以及常用的条图、圆图等统计图。
SPSS输出结果统计表与统计图的专业性编辑写在前面:世界前三统计软件,SPSS最容易学习,但SPSS默认输出的统计表与统计图美观度与专业度不够好,离发表水平尚有距离,本期咱们就谈谈SPSS图表的优化!第一部分:统计表的优化(一)SPSS默认统计表是这个样子滴!规范的统计表,简称“三线表”,不能有竖线和斜线。
所以上表不规范!(二)SPSS 没有标准三线表格式,先设置近似三线表菜单操作:编辑菜单—选项,弹出下图:选中—透视表—选择Academic,右边即可展现近似三线表格式。
再次统计分析一次看看,结果如下,怎么样,好看多了吧!但是细看还不对,因为顶线和底线是双线,需要再次调整!(三)进一步优化操作步骤:双击结果输出窗口的统计表,右键-选择Tablelook,弹出下窗口。
按照框中所示,分别把上内框和下内框,调整为单粗线,ok!此处重要:设置完毕,点击保存外观,起个名字“asong”,松哥起的以a开头方便大家能看到,请看左下图红框是否产生一个asong的格式!这就是我们自定义生成的格式啦!(四)调用自定义格式asong操作步骤:再次进行步骤二,选择asong,应用-确定!分析测试一下看看!分析-比较均值-两独立t检验!第二部分:统计图优化(一)先看看SPSS默认统计图的格式吧!步骤:先做一个单式条形图。
主要问题顶部和右侧边框不应该有,同时消除底部背景,我们看看吧!(二)消除顶部与右边边框操作:编辑菜单—选项—点击“图表”按钮.将框架“内部”取消掉!再做一遍图看看,果然外部边框没了!(三)消除底部背景色步骤:双击条形图—弹出下框:选择填充-选择白色-OK!再做一遍看看!背景色没了!(四)条形图的误差线设置(经常有人问)先做一个不同性别,体重比较的条形图。
步骤—图形—条形图-简单,然后如下设置:。