常用统计量与计算方法
- 格式:pdf
- 大小:7.47 MB
- 文档页数:52

检验统计量的定义和计算统计学是一门研究数据收集、分析和解释的学科。
在统计学中,检验统计量是一种用于评估样本数据与假设之间差异的工具。
本文将探讨检验统计量的定义和计算方法,并介绍一些常见的检验统计量。
一、检验统计量的定义检验统计量是一种数值指标,用于衡量样本数据与假设之间的差异。
它是根据样本数据计算得出的,可以用来判断样本数据是否支持或反驳某个假设。
在假设检验中,通常会提出一个原假设(null hypothesis)和一个备择假设(alternative hypothesis)。
原假设是我们想要验证的假设,而备择假设则是与原假设相对立的假设。
检验统计量可以帮助我们评估样本数据是否支持原假设或备择假设。
二、检验统计量的计算方法计算检验统计量的方法因具体情况而异。
下面将介绍几种常见的检验统计量及其计算方法。
1. t检验统计量t检验统计量是一种常用于小样本情况下的检验统计量。
它可以用于比较两个样本均值是否存在显著差异。
计算t检验统计量的公式如下:t = (x1 - x2) / (s * sqrt(1/n1 + 1/n2))其中,x1和x2分别是两个样本的均值,s是两个样本的标准差,n1和n2分别是两个样本的样本容量。
2. 卡方检验统计量卡方检验统计量是一种用于比较观察值与期望值之间差异的检验统计量。
它常用于分析分类数据的关联性或拟合度。
计算卡方检验统计量的公式如下:χ^2 = Σ((O - E)^2 / E)其中,O是观察值,E是期望值。
Σ表示对所有观察值进行求和。
3. F检验统计量F检验统计量是一种用于比较两个或多个样本方差是否存在显著差异的检验统计量。
计算F检验统计量的公式如下:F = (s1^2 / s2^2)其中,s1^2和s2^2分别是两个样本的方差。
三、检验统计量的应用检验统计量在统计学中有广泛的应用。
它可以帮助我们验证假设、做出决策和推断。
举例来说,假设我们想要比较两种不同的治疗方法在疾病治疗效果上是否有显著差异。

初中数学知识归纳统计量的计算与应用统计量是统计学中用于度量和描述数据集合特征的数值指标。
在初中数学中,我们经常会遇到统计量的计算与应用。
本文将对常见的统计量进行归纳,并介绍它们在实际问题中的应用。
一、平均数平均数是一组数据的总和除以数据的个数。
计算平均数时,首先将所有数据求和,然后除以数据的个数。
平均数常用于表示一组数据的“典型”或“平衡”值。
例如,某班级6位学生的考试分数分别为85、90、78、92、88、95。
我们可以先将这些分数相加,得到85+90+78+92+88+95=528,然后再将总分528除以学生人数6,得到平均分88。
平均数在生活中有很多应用。
比如,我们可以通过计算某商品的平均价格来了解其市场价格水平;又比如,平均年龄可以用来衡量一个国家或地区的人口结构。
二、中位数中位数是按照从小到大的顺序排列后,处于中间位置的那个数。
当数据个数为奇数时,中位数为排序后的中间值;当数据个数为偶数时,中位数为排序后中间两个数的平均值。
对于数据集合{3,7,2,9,1},将其排序得到{1,2,3,7,9},可以看出中间位置的数是3,因此中位数为3。
中位数在应用中经常用于衡量数据的“中心位置”,尤其对于有异常值的数据集合更具有稳定性。
比如,某公司员工的年龄数据{23,25,27,29,100},若使用平均数来衡量,那么受到100这个异常值的影响会使平均年龄看起来很大;而计算中位数时,这个异常值并不能对结果产生显著影响。
三、众数众数是一组数据中出现频次最高的数值。
一个数据集合可能会有一个或多个众数,也可能没有众数。
比如,某班级8位学生的考试分数分别为85、90、78、92、88、95、90、90。
在这个数据集合中,90出现的频次最高,因此众数为90。
众数在统计学中常用于描述数据的“集中趋势”。
例如,通过分析一项产品销售数据中的众数,可以帮助企业了解市场需求,进而调整产品供应。
四、极差极差是一组数据的最大值减去最小值得到的差值。
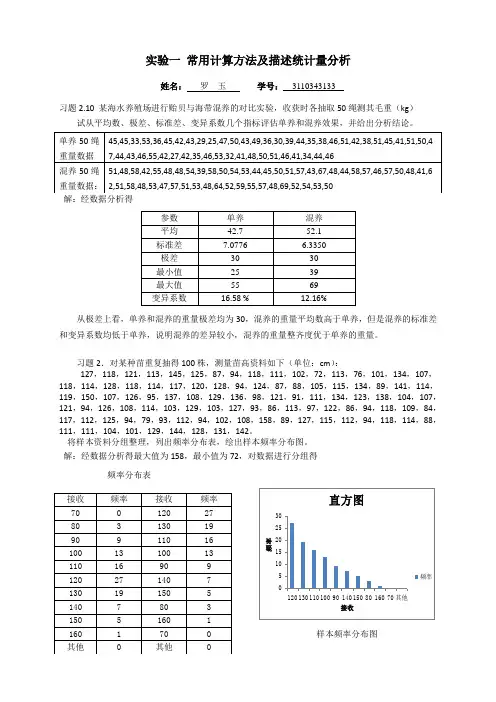
实验一 常用计算方法及描述统计量分析姓名: 罗 玉 学号: 3110343133习题2.10 某海水养殖场进行贻贝与海带混养的对比实验,收获时各抽取50绳测其毛重(kg )试从平均数、极差、标准差、变异系数几个指标评估单养和混养效果,并给出分析结论。
解:经数据分析得从极差上看,单养和混养的重量极差均为30,混养的重量平均数高于单养,但是混养的标准差和变异系数均低于单养,说明混养的差异较小,混养的重量整齐度优于单养的重量。
习题2.对某种苗重复抽得100株,测量苗高资料如下(单位:cm ):127,118,121,113,145,125,87,94,118,111,102,72,113,76,101,134,107,118,114,128,118,114,117,120,128,94,124,87,88,105,115,134,89,141,114,119,150,107,126,95,137,108,129,136,98,121,91,111,134,123,138,104,107,121,94,126,108,114,103,129,103,127,93,86,113,97,122,86,94,118,109,84,117,112,125,94,79,93,112,94,102,108,158,89,127,115,112,94,118,114,88,111,111,104,101,129,144,128,131,142。
将样本资料分组整理,列出频率分布表,绘出样本频率分布图。
解:经数据分析得最大值为158,最小值为72,对数据进行分组得频率分布表样本频率分布图实验二 假设检验4.7 检查三化螟各世代每卵块的卵数,检查第一代 128 个卵块,其平均数为 47.3 粒,标准差为 25.4 粒;检查第二代 69 个卵块,其平均数为 74.9 粒,标准差为 46.8 粒。
试检验两代每卵块的卵数有无显著差异。

统计量公式统计量是一种用于描述和总结数据集的数值指标或函数。
它们可以对数据进行量化和比较,从而得到有关数据分布和关系的信息。
以下是一些常见的统计量和它们的公式:1.平均数(Mean):平均数是一组数据的总和除以数据的个数。
公式为:μ = (x₁ + x₂ + ... + xₙ) / n,其中x₁,x₂,...,xₙ为数据集中的观测值,n为观测值的个数。
拓展:除了算术平均数,还有几种不同的平均数,如加权平均数、几何平均数和调和平均数。
2.中位数(Median):中位数是将一组数据按升序或降序排列后,位于中间位置的观测值。
若数据个数n为奇数,则中位数为第(n+1)/2个观测值;若n为偶数,则中位数为第n/2和n/2+1个观测值的平均值。
拓展:除了中位数,还有四分位数、百分位数等分位数,从而可以描述数据的分布和位置。
3.方差(Variance):方差衡量了数据集的离散程度,它表示每个观测值与平均值之间的差异的平方的平均值。
公式为:σ² = Σ (xᵢ- μ)² / n,其中xᵢ为观测值,μ为平均数,n为观测值的个数。
拓展:方差的开平方称为标准差,它将方差的测量单位换成了与原始观测值相同的单位,更易于解释和比较。
4.相关系数(Correlation coefficient):相关系数衡量了两个变量之间的线性关系的强度和方向。
常用的是皮尔逊相关系数,其公式为:r = Σ (xᵢ - μₓ)(yᵢ - μᵧ) / (nσₓσᵧ),其中xᵢ和yᵢ为两个变量的观测值,μₓ和μᵧ为两个变量的平均值,σₓ和σᵧ为两个变量的标准差。
拓展:除了皮尔逊相关系数,还有斯皮尔曼等级相关系数和判定系数等其他类型的相关系数。
这些统计量广泛用于统计学和数据分析中,可以帮助我们理解和解释数据的特征和关系。
同时,也有其他更多的统计量公式和概念,根据不同的数据类型和问题,可以选择适当的统计量来进行分析。

统计题型及解题方法引言统计学是一门研究数据收集、处理、分析和解释的学科。
在日常生活和学术研究中,我们经常会遇到统计题型,例如调查数据分析、假设检验和回归分析等。
本文将全面、详细、完整和深入地探讨统计题型及解题方法。
一、描述统计描述统计是研究数据的集中趋势、离散程度和分布形态的方法。
常用的描述统计量有均值、中位数、众数、方差、标准差和四分位数等。
1. 均值均值是计算一组数据的平均值的统计量。
计算方法是将所有观测值相加,再除以观测值的个数。
例如,已知一组数据为[1, 2, 3, 4, 5],则均值为 (1+2+3+4+5)/5 = 3。
2. 中位数中位数是将一组数据按大小排序后,处于中间位置的观测值。
当数据个数为奇数时,中位数为排序后的中间值;当数据个数为偶数时,中位数为排序后中间两个值的平均值。
例如,已知一组数据为[1, 2, 3, 4, 5],则中位数为 3。
3. 众数众数是一组数据中出现次数最多的观测值。
可能存在多个众数,或者没有众数。
例如,已知一组数据为[1, 2, 2, 3, 4, 4, 4, 5],则众数为 4。
4. 方差和标准差方差和标准差是用来衡量数据的离散程度的统计量。
方差是观测值与均值之间差异的平均值的平方,标准差是方差的正平方根。
例如,已知一组数据为[1, 2, 3, 4, 5],计算其方差和标准差的步骤如下: - 计算均值:(1+2+3+4+5)/5 = 3 - 计算方差:[(1-3)^2 + (2-3)^2 + (3-3)^2 + (4-3)^2 + (5-3)^2]/5 = 2 - 计算标准差:sqrt(2) ≈ 1.4145. 四分位数四分位数是将一组数据分为四等份的统计量,用于描述数据的分布情况。
第一个四分位数是将数据从小到大排序后处于25%位置的观测值,第二个四分位数是位于50%位置的观测值(即中位数),第三个四分位数是位于75%位置的观测值。
例如,已知一组数据为[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],则第一个四分位数为 3,第二个四分位数为 6,第三个四分位数为 9。
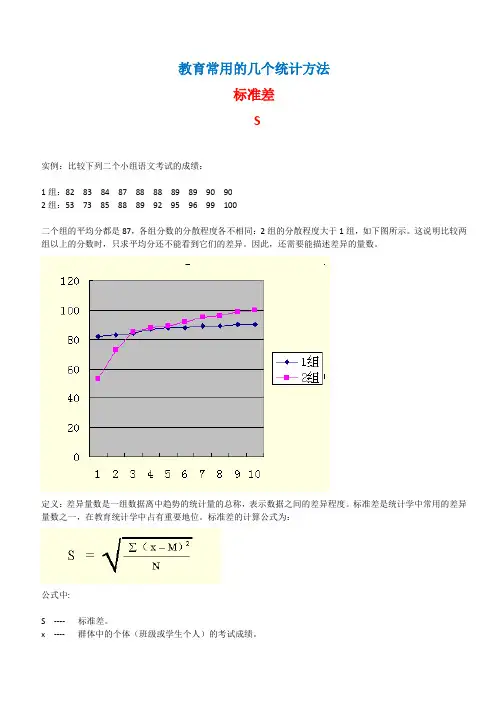
教育常用的几个统计方法标准差S实例:比较下列二个小组语文考试的成绩:1组:82 83 84 87 88 88 89 89 90 902组:53 73 85 88 89 92 95 96 99 100二个组的平均分都是87,各组分数的分散程度各不相同:2组的分散程度大于1组,如下图所示。
这说明比较两组以上的分数时,只求平均分还不能看到它们的差异。
因此,还需要能描述差异的量数。
定义:差异量数是一组数据离中趋势的统计量的总称,表示数据之间的差异程度。
标准差是统计学中常用的差异量数之一,在教育统计学中占有重要地位。
标准差的计算公式为:公式中:S ---- 标准差。
x ---- 群体中的个体(班级或学生个人)的考试成绩。
M ---- 科平均分。
N ---- 群体中的个体(班级或学生个人)数。
由上述公式可以算出:1组的标准差= 2.79 , 2组的标准差= 13.58。
计算结果说明:在平均分相同的情况下班,标准差大,表明分数分散,好差悬殊;标准差小,表明分数比较集中,差距较小。
差异系数C V当数据的单位不同时,不能直接用标准差进行比较,比如学生的身高和体重,前者是长度单位,后者是重量单位。
另外,在单位相同时,如果平均数相差太大,直接用标准差比较也是不合理的。
针对这些情况,统计学中采用了一个相对的量数-----差异系数,用它来衡量不同组数据的离散程度。
定义:差异系数----CV,是标准差与平均数商的百分比:CV = S / M x 100%公式中:S ---- 标准差。
M ---- 科平均分。
实例:初一1班学生体重的平均数M = 46 公斤,标准差S = 6 公斤;身高的平均数M = 1.45米,标准差S=0.5米。
请比较体重与身高的差异程度。
体重CV = 6 / 46 x 100% = 13.04 %身高CV = 0.5 / 1.45 x 100% = 34.48 %身高CV > 体重CV。
学生的身高较体重的差异大。

统计之数据的处理:常用统计量的计算(平均数、加权平均数、中位数、众数、方差)平均数的计算平均数是描述一组数据的常用指标,它反映了这组数据中各数据的平均大小或是集中趋势。
一组数据的平均数只有一个。
称这中位数的计算一般地,n个数据按大小顺序排列,处于最中间位置的一个数据(或最中间的两个数据的平均数)叫做这组数据的中位数。
即:n个数据按大小顺序排列,当数组的个数是奇数时,中间的那个数为这组数据的中位数;当数组的个数是偶数时,居于中间的两个数的平均数才是这组数据的中位数。
注意:(1)一组数据的中位数是唯一的;(2)当数据个数为奇数时,它的中位数一定是这组数据中的某一个数;当数据个数为偶数时,它的中位数不一定是这组数据中的某一个数。
众数的计算一组数据中出现次数最多的那个数据叫做这组数据的众数。
注意:众数着眼于对各数据出现次数的考察,一组数据中,众数可能不止一个。
方差的计算⎤。
⎥⎦(1)已求得甲的平均成绩为8环,求乙的平均成绩;(2)观察图形,直接写出甲,乙这10次射击成绩的方差s甲2,s乙2哪个大;(3)如果其他班级参赛选手的射击成绩都在7环左右,本班应该选参赛更合适;如果其他班级参赛选手的射击成绩都在9环左右,本班应该选参赛更合适.分析:(1)根据平均数的计算公式和折线统计图给出的数据即可得出答案;(2)根据图形波动的大小可直接得出答案;(3)根据射击成绩都在7环左右的多少可得出甲参赛更合适;根据射击成绩都在9环左右的多少可得出乙参赛更合适.解答:解:(1)乙的平均成绩是:(8+9+8+8+7+8+9+8+8+7)÷10=8(环);(2)根据图象可知:甲的波动小于乙的波动,则22乙甲s s ;(3)如果其他班级参赛选手的射击成绩都在7环左右,本班应该选乙参赛更合适;如果其他班级参赛选手的射击成绩都在9环左右,本班应该选甲参赛更合适.故答案为:乙,甲.点评:本题考查方差的意义.方差是用来衡量一组数据波动大小的量,方差越大,表明这组数据偏离平均数越大,即波动越大,数据越不稳定;反之,方差越小,表明这组数据分布比较集中,各数据偏离平均数越小,即波动越小,数据越稳定.。

掌握平均数中位数和众数的计算统计学中有三个常用的统计量,分别是平均数、中位数和众数。
这三个统计量可以帮助我们更好地理解和分析数据。
本文将为您详细介绍如何计算平均数、中位数和众数,并通过例子进行说明。
一、平均数的计算方法平均数是一个数据集的所有数值之和除以数据个数,用于描述数据的集中趋势。
下面是计算平均数的步骤:1. 将数据集中的所有数值相加。
2. 将结果除以数据个数。
3. 得到的结果即为平均数。
例如,我们有一组数据集:2, 4, 6, 8, 10。
我们可以按照以下步骤计算平均数:1. 将所有数值相加:2 + 4 + 6 + 8 + 10 = 30。
2. 将结果除以数据个数:30 / 5 = 6。
3. 得到的结果6即为平均数。
二、中位数的计算方法中位数是一个数据集中的中间数,它将数据集按照大小排列后,中间位置上的数值就是中位数。
下面是计算中位数的步骤:1. 将数据集中的数值按照大小顺序排列。
2. 如果数据个数为奇数,中位数就是中间位置上的数值;如果数据个数为偶数,中位数是中间位置上的两个数值的平均数。
例如,我们有一组数据集:2, 4, 6, 8, 10。
我们可以按照以下步骤计算中位数:1. 将数据集按大小排列:2, 4, 6, 8, 10。
2. 数据个数为奇数,中位数是中间位置上的数值,即6。
三、众数的计算方法众数是指一个数据集中出现次数最多的数值,一个数据集可以有一个或多个众数。
下面是计算众数的步骤:1. 统计数据集中每个数值的出现次数。
2. 找出出现次数最多的数值。
例如,我们有一组数据集:2, 4, 6, 8, 10, 4。
我们可以按照以下步骤计算众数:1. 统计数据集中每个数值的出现次数:2(1次),4(2次),6(1次),8(1次),10(1次)。
2. 出现次数最多的数值是4,因此4是该数据集的众数。
综上所述,平均数、中位数和众数是三个常用的统计量,可以帮助我们更好地了解和分析数据。
通过计算平均数,我们可以得到数据集的集中趋势;通过计算中位数,我们可以了解数据集的中间位置上的数值;通过计算众数,我们可以找出数据集中出现次数最多的数值。

统计量公式统计量是统计学中常用的概念,它用来描述和总结数据的特征和分布情况。
统计量可以帮助我们更好地理解数据,并从中提取出有用的信息。
在实际应用中,统计量是进行数据分析和推断的重要工具,它们可以帮助我们做出准确的决策和预测。
常见的统计量包括均值、中位数、众数、标准差、方差、偏度和峰度等。
下面分别介绍这些统计量的计算公式和含义。
1. 均值:均值是一组数据的平均数,用于表示数据的集中趋势。
计算公式为:均值 = 总和 / 观测值的个数。
均值可以帮助我们了解数据的平均水平,并可以用来对比不同数据集之间的差异。
2. 中位数:中位数是一组数据排序后的中间值,它能够较好地反映数据的分布情况,相对于均值更具有鲁棒性。
如果数据个数为奇数,中位数就是排序后的中间值;如果数据个数为偶数,中位数就是排序后中间两个数的平均值。
3. 众数:众数是一组数据中出现频率最高的值,用于描述数据的集中程度。
一个数据集可能存在多个众数,也可能没有众数。
4. 标准差:标准差衡量了数据的波动程度,也就是数据的离散程度。
标准差越大,数据的离散程度就越大;标准差越小,数据的离散程度就越小。
标准差的计算公式为:标准差 = 平方根(方差)。
5. 方差:方差衡量了数据的离散程度,它是各个观测值与均值之差的平方和的平均值。
方差越大,数据的离散程度也越大;方差越小,数据的离散程度也越小。
6. 偏度:偏度用于衡量数据分布的不对称程度。
如果数据分布左偏,即数据的尾部向左拉长,偏度为负数;如果数据分布右偏,即数据的尾部向右拉长,偏度为正数。
7. 峰度:峰度用于衡量数据分布的尖锐程度。
正态分布的峰度为3,如果数据分布的峰度大于3,则分布更为尖锐;如果峰度小于3,则分布较为平缓。
统计量的计算和使用可以帮助我们深入了解数据,从而做出正确的决策。
在不同的领域和问题中,我们可以根据需要选择相应的统计量来分析数据,并且可以结合其他统计方法进行更深入的研究。
同时,统计量的计算结果也需要综合考虑其他因素,如样本的大小和数据的分布特点,以保证统计结果的可靠性和有效性。

统计学中统计量的名词解释统计学作为一门独立的学科,致力于研究数据的收集、分析和解释。
在统计学中,统计量是非常重要的概念,它是通过对样本数据进行计算得到的一种度量指标。
统计量可以帮助我们从样本中获取关于总体特征的信息,从而进行科学的决策和推断。
本文将对统计量进行详细的解释和探讨。
什么是统计量?统计量是根据样本数据计算得出的一个数值,用于描述或估计总体的特征。
常见的统计量包括均值、方差、标准差、中位数和相关系数等。
通过对样本数据的统计量进行分析,我们可以了解样本的集中趋势、离散程度、分布形状以及变量之间的相关性,从而对总体进行推断。
均值:均值是最常用的统计量之一,它表示一组数据的平均水平。
均值的计算方法是将所有的数据相加,然后除以数据的数量。
均值可以帮助我们了解整体数据集的集中趋势,对于连续型数据或者近似正态分布的数据,均值被认为是一个有效的统计量。
方差和标准差:方差和标准差是用来衡量数据的离散程度的统计量。
方差是各个数据与均值之差的平方的平均值,而标准差是方差的平方根。
方差和标准差越大,数据的离散程度就越大,反之亦然。
通过分析方差和标准差,我们可以判断数据的稳定性和可靠性。
中位数:中位数是按照从小到大排列的一组数据中位于最中间的数值,它可以用来表示一组数据的中间位置。
中位数的计算方法是先将数据从小到大排序,然后找出中间位置的数值。
与均值相比,中位数对异常值的影响较小,更能反映数据的中心趋势。
相关系数:相关系数是用来衡量两个变量之间关系的统计量。
它反映了两个变量的线性相关性的强度和方向。
常见的相关系数有皮尔逊相关系数和斯皮尔曼相关系数。
皮尔逊相关系数适用于两个连续型变量之间的相关关系,而斯皮尔曼相关系数适用于两个有序变量之间的相关关系。
通过分析相关系数,我们可以判断两个变量之间的相关性,从而进行预测和推论。
总结:统计量作为统计学中的重要概念,可以帮助我们从样本数据中获取关于总体的信息。
常见的统计量包括均值、方差、标准差、中位数和相关系数等。

数据的统计量与误差数据统计是现代科学研究和商业决策中不可或缺的一部分。
统计学中,数据的统计量是用来描述和分析数据集的重要指标,而误差则是数据采集和处理过程中不可避免的偏差。
本文将介绍常见的数据统计量及其计算方法,并探讨数据误差的来源和减小方法。
一、数据的统计量数据的统计量是对数据集中数据分布、中心位置和离散程度的度量。
常见的数据统计量包括均值、中位数、众数、方差、标准差、百分位数等。
1. 均值均值是最常用的统计量之一,它描述了数据集的平均水平。
均值的计算方法是将数据集中的所有数据相加,然后除以数据的个数。
均值对异常值比较敏感,因此在分析数据时需要注意异常值的影响。
2. 中位数中位数是将数据集中的数据按照大小顺序排列后,中间位置的数值。
中位数能够较好地反映数据集的中心位置,对异常值的影响相较于均值较小。
3. 众数众数是数据集中出现频率最高的数值。
众数在描述数据集的离散分布时比较有用,特别是在涉及分类变量时。
4. 方差和标准差方差和标准差是用来描述数据的离散程度的统计量。
方差计算的是数据和均值之间的偏差的平方的平均值,而标准差是方差的平方根。
这两个统计量越大,说明数据的离散程度越大。
5. 百分位数百分位数是指在一个数据集中,某个特定百分比的数据落在该数值以下。
例如,第70百分位数表示70%的数据小于或等于该数值。
二、数据误差数据误差是指在数据采集、处理和分析过程中产生的偏差或误差。
误差可能来自多个方面,包括测量错误、采样误差、非响应误差等。
1. 测量误差测量误差是由于测量仪器的精度限制或人为操作不准确等原因导致的误差。
为了减小测量误差,可以提高仪器的精度,加强操作规范,并进行多次重复测量以获取更准确的结果。
2. 采样误差采样误差是由于样本选取不足或选取方式不合理导致的误差。
为了减小采样误差,应该采用随机抽样的方法,并确保样本代表了总体的特征。
3. 非响应误差非响应误差是指由于样本中的一部分个体没有回答或不愿意回答问题而造成的误差。
统计学中的常用统计量统计学是一门关于数据收集、分析和解释的学科,它提供了一系列的统计量来总结和描述数据的特征。
这些统计量可以帮助我们理解数据的分布、趋势和关联性。
在本文中,我们将介绍统计学中的一些常用统计量及其应用。
一、中心位置的统计量1. 均值(Mean):均值是一组数据的平均值。
计算均值的方法是将所有观测值相加,然后除以观测值的总数。
均值对异常值非常敏感,所以在一些情况下,中位数可能更适合作为中心位置的度量。
2. 中位数(Median):中位数是将一组数据按照大小顺序排列后的中间值。
如果数据集中的观测值为奇数个,则中位数就是中间的观测值;如果观测值为偶数个,则中位数是中间两个观测值的平均数。
中位数对异常值不敏感,因此在分析偏态数据时常常使用。
二、离散程度的统计量3. 方差(Variance):方差衡量了数据的离散程度,计算方式为每个数据与均值之差的平方的平均值。
方差的单位是原数据单位的平方,所以为了更好地描述数据的离散程度,常用标准差作为方差的平方根。
4. 标准差(Standard Deviation):标准差是方差的平方根,它衡量了数据相对于均值的平均偏离程度。
标准差越大,数据的离散程度越大。
5. 百分位数(Percentiles):百分位数是将数据按照大小排序后,某个特定百分比处的数值。
例如,第25百分位数是将数据按照从小到大排序后,处于25%位置上的观测值。
三、数据分布形态的统计量6. 偏度(Skewness):偏度衡量了数据分布的对称性。
当数据分布左偏时,偏度为负值;当数据分布右偏时,偏度为正值。
偏度为0表示数据分布对称。
7. 峰度(Kurtosis):峰度衡量了数据分布的尖锐程度。
正态分布的峰度为3,如果峰度大于3,表示分布的尖锐程度高于正态分布;如果峰度小于3,表示分布的尖锐程度低于正态分布。
四、相关性的统计量8. 相关系数(Correlation Coefficient):相关系数衡量了两个变量之间的线性关系强度和方向。
统计量的计算与应用统计学作为研究和分析数据的一门学科,涉及到许多计算和应用方法。
在统计学中,统计量是一种用来总结和描述数据的量化指标。
本文将介绍统计量的计算方法以及其在实际应用中的重要性。
一、统计量的计算方法1. 平均值(Mean):平均值是最常见的统计量之一,计算公式为将所有观测值相加,然后除以观测值的数量。
平均值可以反映数据的集中趋势。
2. 中位数(Median):中位数是将数据按大小排序后,处于中间位置的观测值。
如果数据数量为奇数,则中位数就是排序后的中间值;如果数据数量为偶数,则中位数是中间两个观测值的平均值。
中位数适用于有离群值的数据集。
3. 众数(Mode):众数是指数据中出现频率最高的观测值。
一个数据集可能有一个或多个众数,也可能没有众数。
4. 标准差(Standard Deviation):标准差是数据的离散程度的度量,它衡量的是每个数据点与平均值的差距。
标准差越大,数据的离散程度就越大。
5. 方差(Variance):方差是标准差的平方,它描述了每个数据点与平均值之间的平均差异程度。
二、统计量的应用1. 描述性统计分析:统计量广泛应用于描述性统计分析中,可以帮助我们了解数据的集中趋势、离散程度和形状。
例如,通过计算平均值和标准差,我们可以得出一组数据的一般特征。
2. 推断统计分析:统计量在推断统计分析中也有着重要的应用。
通过计算样本均值和样本标准差,可以进行参数估计和假设检验,从而得出关于总体的推断。
3. 质量控制:在生产工艺中,统计量被广泛应用于质量控制。
通过监测平均值、方差和其他统计量,可以评估和改进产品的质量水平。
4. 风险分析:统计量在风险分析和金融领域也有重要应用。
例如,价值-at-风险(Value-at-Risk)是一种常用的风险测量指标,它可以帮助投资者评估投资组合的风险水平。
5. 统计模型建立:在建立统计模型时,统计量可以用于选择适当的模型、估计模型参数和评估模型拟合优度。
统计量公式范文统计量是用来描述样本或总体特征的量,可以帮助我们理解和分析数据。
不同的统计量有不同的公式和计算方法,下面将详细介绍一些常用的统计量及其公式。
1. 均值(Mean):均值是统计样本或总体数据的中心位置的度量,用于表示数值变量的集中趋势。
对于总体来说,均值的公式为:μ=(ΣXi)/N其中,μ为总体平均值,Xi表示总体中的每个变量,Σ表示求和符号,N为总体大小。
对于样本来说,均值的公式为:x̄=(ΣXi)/n其中,x̄为样本平均值,Xi表示样本中的每个变量,Σ表示求和符号,n为样本大小。
2. 中位数(Median):中位数是一组数据中间的值。
当数据被排序后,中位数是位于中间的值,也就是将数据分为较小和较大两部分的分界点。
对于总体来说,中位数的计算公式为:中位数=(N+1)/2对于样本来说,中位数的计算公式为:中位数=(n+1)/23. 众数(Mode):众数是一组数据中出现次数最多的值,可以有一个或多个众数。
4. 方差(Variance):方差是用来衡量数据的离散程度或变异程度。
方差值越大,表示数据越离散;方差值越小,表示数据越集中。
对于总体来说,方差的计算公式为:σ²=Σ(Xi-μ)²/N其中,σ²为总体方差,Σ表示求和符号,Xi表示总体中的每个变量,μ为总体平均值,N为总体大小。
对于样本来说,方差的计算公式为:s²=Σ(Xi-x̄)²/(n-1)其中,s²为样本方差,Σ表示求和符号,Xi表示样本中的每个变量,x̄为样本平均值,n为样本大小。
5. 标准差(Standard Deviation):标准差是方差的平方根,用来度量数据的离散程度或变异程度。
对于总体来说,标准差的计算公式为:σ=√(Σ(Xi-μ)²/N)其中,σ为总体标准差,Σ表示求和符号,Xi表示总体中的每个变量,μ为总体平均值,N为总体大小。
对于样本来说s=√(Σ(Xi-x̄)²/(n-1))其中,s为样本标准差,Σ表示求和符号,Xi表示样本中的每个变量,x̄为样本平均值,n为样本大小。
基本统计量的计算统计学是一门研究收集、整理、分析和解释数据的学科。
在统计学中,计算和理解基本统计量是非常重要的,它们能够帮助我们更好地理解数据集的特征和分布,从而做出准确的判断和决策。
一、平均值平均值是数据集中所有观测值的总和除以观测值的数量。
计算平均值的公式如下:平均值 = 总和 / 观测值的数量例如,有一个数据集包括以下观测值:5, 8, 6, 4, 9。
计算这些观测值的平均值,首先将它们相加得到总和:5 + 8 + 6 + 4 + 9 = 32。
然后将总和除以观测值的数量(5个):32 / 5 = 6.4。
所以,这些观测值的平均值是6.4。
二、中位数中位数是将数据集中的观测值按照大小顺序排列后,处于中间位置的值。
如果数据集的观测值数量为奇数,则中位数就是中间位置的观测值;如果数据集的观测值数量为偶数,则中位数是中间两个观测值的平均值。
例如,有一个数据集包括以下观测值:5, 8, 6, 4, 9。
将这些观测值按照大小顺序排列:4, 5, 6, 8, 9。
这个数据集的观测值数量是奇数,中位数就是处于中间位置的观测值,即6。
三、众数众数是数据集中出现次数最多的观测值。
一个数据集可能有一个众数,也可能有多个众数,甚至没有众数。
例如,有一个数据集包括以下观测值:6, 8, 6, 4, 9。
在这个数据集中,观测值6出现了两次,而其他观测值只出现了一次,所以6是这个数据集的众数。
四、范围范围是数据集中最大观测值和最小观测值之间的差值。
计算范围的公式如下:范围 = 最大观测值 - 最小观测值例如,有一个数据集包括以下观测值:5, 8, 6, 4, 9。
这个数据集中的最大观测值是9,最小观测值是4,所以范围是9 - 4 = 5。
五、方差和标准差方差和标准差能够帮助我们了解数据集的离散程度。
方差是观测值与平均值之间差异的平方和的平均值,计算方差的公式如下:方差= ∑(观测值 - 平均值)² / 观测值的数量标准差是方差的平方根,计算标准差的公式如下:标准差= √方差方差和标准差的数值越大,表示数据集中的观测值离平均值越远,数据的离散程度就越大。
统计量的计算与解读统计学是一门研究收集、整理、分析和解释大量数据的学科。
统计量是指在统计分析中使用的数值度量,用于总结和描述数据的特征。
本文将介绍统计量的计算方法和解读,并探讨其在实际应用中的意义。
一、均值均值是统计学中最常用的统计量,用于表示数据的集中趋势。
计算均值的方法是将所有观测值相加,然后除以观测值的个数。
均值的计算公式如下:均值 = (观测值1 + 观测值2 + ... + 观测值n) / n通过计算均值,我们可以得出数据的平均水平,进而对数据进行比较和推断。
例如,在一项市场调研中,我们可以计算出某个产品的平均满意度,从而评估其市场竞争力。
二、中位数中位数是统计学中描述数据的另一个常用统计量,用于表示数据的中间位置。
计算中位数的方法是将数据按照大小进行排序,然后取中间位置的观测值作为中位数。
如果数据个数为奇数,中位数即为排序后的中间值;如果数据个数为偶数,中位数则为排序后中间两个值的平均值。
中位数的计算方法简单直观,能够较好地反映数据的典型特征。
例如,在一组收入数据中,中位数可以用来表示人群的收入水平,较为准确地反映出整体的收入情况。
三、众数众数是指在数据中出现频率最高的数值,反映了数据分布的集中程度。
众数的计算方法是统计各个数值出现的频次,然后找出频次最高的数值作为众数。
众数在处理离散型数据时具有重要意义。
例如,在一组考试成绩中,众数可以帮助我们了解哪个成绩分数出现的次数最多,进而了解哪个分数段的学生占比较高。
四、方差方差是统计学中衡量数据变异程度的统计量,用于反映数据的离散程度。
方差的计算方法是将每个观测值与均值的差值进行平方,然后求平均值。
方差越大,说明数据的波动性越高,反之则说明数据的波动性较低。
例如,在研究某个投资组合的风险时,方差可以用来评估该投资组合的波动性和不确定性。
五、标准差标准差是方差的平方根,用于衡量数据的离散程度。
标准差的计算方法是对方差进行开方。
标准差是一种常用的度量指标,可以帮助我们判断数据的稳定性和可靠性。