【决策管理】决策树分析及SPSS实现
- 格式:ppt
- 大小:4.07 MB
- 文档页数:62


决策分析复习题(请和本学期的大纲对照,答案供参考)第一章一、选择题(单项选)1.1966年,R. A. Howard在第四届国际运筹学会议上发表( C )一文,首次提出“决策分析”这一名词,用它来反映决策理论的应用。
A.《对策理论与经济行为》B.《管理决策新科学》C.《决策分析:应用决策理论》D.《贝叶斯决策理论》2.决策分析的阶段包含两种基本方式:( A )A. 定性分析和定量分析B. 常规分析和非常规分析C. 单级决策和多级决策D. 静态分析和动态分析3.在管理决策中,许多管理人员认为只要选取满意的方案即可,而无须刻意追求最优的方案。
对于这种观点,你认为以下哪种解释最有说服力?( D )A.现实中不存在所谓的最优方案,所以选中的都只是满意方案B.现实管理决策中常常由于时间太紧而来不及寻找最优方案C.由于管理者对什么是最优决策无法达成共识,只有退而求其次D.刻意追求最优方案,常常会由于代价太高而最终得不偿失4.关于决策,正确的说法是(A )A.决策是管理的基础B.管理是决策的基础C.决策是调查的基础D.计划是决策的基础5.根据决策时期,可以将决策分为:(D )A.战略决策与战术决策 B. 定性决策与定量决策C. 常规决策与非常规决策D. 静态决策与动态决策6.我国五年发展计划属于(B)。
A.非程序性决策 B.战略决策 C.战术决策 D.确定型决策7.管理者的基本行为是(A)A.决策 B.计划 C.组织 D.控制8.管理的首要职能是(D)。
A.组织 B. 控制 C.监督 D. 决策9. 管理者工作的实质是(C)。
A.计划 B. 组织 C. 决策D.控制10. 决策分析的基本特点是(C )。
A.系统性 B. 优选性 C. 未来性 D.动态性二、判断题1.管理者工作的实质就是决策,管理者也常称为“决策者”。
(√)2.1944年,Von Neumann和Morgenstern从决策角度来研究统计分析方法,建立了贝叶斯(统计)决策理论。



SPSS分类分析:决策树⼀、决策树(分析-分类-决策树)“决策树”过程创建基于树的分类模型。
它将个案分为若⼲组,或根据⾃变量(预测变量)的值预测因变量(⽬标变量)的值。
此过程为探索性和证实性分类分析提供验证⼯具。
1、分段。
确定可能成为特定组成员的⼈员。
2、层次。
将个案指定为⼏个类别之⼀,如⾼风险组、中等风险组和低风险组。
3、预测。
创建规则并使⽤它们预测将来的事件,如某⼈将拖⽋贷款或者车辆或住宅潜在转售价值的可能性。
4、数据降维和变量筛选。
从⼤的变量集中选择有⽤的预测变量⼦集,以⽤于构建正式的参数模型。
5、交互确定。
确定仅与特定⼦组有关的关系,并在正式的参数模型中指定这些关系。
6、类别合并和连续变量离散化。
以最⼩的损失信息对组预测类别和连续变量进⾏重新码。
7、⽰例。
⼀家银⾏希望根据贷款申请⼈是否表现出合理的信⽤风险来对申请⼈进⾏分类。
根据各种因素(包括过去客户的已知信⽤等级),您可以构建模型以预测客户将来是否可能拖⽋贷款。
⼆、增长⽅法(分析-分类-决策树)1、CHAID.卡⽅⾃动交互检测。
在每⼀步,CHAID选择与因变量有最强交互作⽤的⾃变量(预测变量)。
如果每个预测变量的类别与因变量并⾮显著不同,则合并这些类别。
2、穷举CHAID.CHAID的⼀种修改版本,其检查每个预测变量所有可能的拆分。
3、CRT.分类和回归树。
CRT将数据拆分为若⼲尽可能与因变量同质的段。
所有个案中因变量值都相同的终端节点是同质的“纯”节点。
4、QUEST.快速、⽆偏、有效的统计树。
⼀种快速⽅法,它可避免其他⽅法对具有许多类别的预测变量的偏倚。
只有在因变量是名义变量时才能指定QUEST。
三、验证(分析-分类-决策树-验证)1、交叉验证:交叉验证将样本分割为许多⼦样本(或样本群)。
然后,⽣成树模型,并依次排除每个⼦样本中的数据。
第⼀个树基于第⼀个样本群的个案之外的所有个案,第⼆个树基于第⼆个样本群的个案之外的所有个案,依此类推。

给大家拜个晚年!这年也过完了,又要开始工作了!本想春节期间写写博客,但不忍心看到那么多的祝福被顶下去,过节就过个痛快的节日,不写了!直接上开心网,结果开了个“老友面馆”都经营到18级了!还是蛮开心的,但是我决定了从今天开始就不再玩了!今天我们来说说分类决策树的应用和操作!主要包括CH AID&CRT,是非常好用和有价值的多变量分析技术,∙CHAID——Chi-square d Automa tic Intera ction Detect or卡方自交互侦测决策树∙CRT——Classi ficat ion Regres sionTree分类回归树;CHAID和CART是最有名的分类树方法,主要用于预测和分类。
在市场研究中经常用于市场细分和客户促销研究,属于监督类分析技术。
其中,树根节点是独立变量-因变量,例如:使用水平、购买倾向、用户或非用户、客户类型、套餐类别、细分类别等。
子节点基于独立变量和其他分类变量(父节点),按照卡方显著性不断划分或组合为树状结构。
预测变量一般也是非数量型的分类变量。
CHAID最常用,但独立变量只能是分类变量,也就是离散性的,CRT可以处理数量型变量,有时候二者结合使用。
CHAID和CRT都可以处理非数量型和定序性变量。
分类树方法产生真实的细分类别,这种类是基于一个独立变量得到的一种规则和细分市场。
也就是说,每一个树叶都是一个细分市场。
下面我们通过一个案例来操作SPS S软件的分类决策树模块假设我们有一个移动业务数据,包含有客户的性别、年龄、语音费用、数据费用、客户等级、支付方式和促销套餐变量。
我们现在期望能够得到针对不同的促销套餐来分析“客户画像”,这样有利于针对性的促销!也就是不同套餐客户特征描述!因变量是促销套餐,其它是预测变量或自变量!我们看到,首先要求我们定义变量的测量等级并定义好变量变标和值标!因为,CHAID和CRT具有智能特性,也就是自交互检验和自回归能力,所以对变量测量尺度要求严格!为什么说变量测量等级重要呢?例如,我们有个变量叫学历(1-初中、2-高中、3-大专、4-本科、5-硕士以上),如果我们设定为定序变量,则决策树可以自动组合分类,但无论如何都是顺序组合,也就是说可能(1-初中、2-高中、3-大专)为一类,(4-本科、5-硕士以上)为一类,但绝对不会把1和5合并一类;如果我们定义为名义变量,则可以任意学历组合为某类了!基本原理:基于目标变量(独立变量)自我分层的树状结构,根结点是因变量,预测变量根据卡方显著性程度不断自动生成父节点和子节点,卡方显著性越高,越先成为预测根结点的变量,程序自动归并预测变量的不同类,使之成为卡方显著性。




决策树分析及SPSS实现决策树是一种常用的机器学习算法,可用于解决分类和回归问题。
它通过构建一棵由决策节点和叶子节点组成的树型结构来对数据进行分类或预测。
本文将介绍决策树分析的基本原理,并演示如何使用SPSS软件进行决策树的实现。
决策树的基本原理是根据数据的特征属性,选择最佳的切分点将数据分割成不同的子集。
切分点的选择通常基于最大化信息增益、基尼指数或其他指标。
在每个切分点上,根据特征属性的不同取值,决策树生成分支节点,直至叶子节点。
叶子节点代表最终的分类结果或预测值。
SPSS是一款功能强大的统计分析软件,提供了丰富的分析工具,包括决策树的实现。
以下是在SPSS中实现决策树的步骤:1.数据准备:将需要进行决策树分析的数据导入SPSS。
确保数据的质量和完整性。
2. 创建决策树模型:在SPSS的菜单栏选择“Analyze”->“CART”->“Classification Tree”(或其他类似选项,具体菜单栏位置可能会有所不同)。
在弹出的对话框中,选择需要进行决策树分析的变量。
3.设置决策树参数:在对话框中,可以设置决策树的参数,如最大深度、节点分裂的最小样本数等。
这些参数的设置将影响决策树的生成和准确性。
4.运行决策树分析:点击“OK”按钮后,SPSS将开始进行决策树分析。
该过程可能需要一段时间,具体时间取决于数据集的大小和复杂性。
5.解释和评估决策树结果:分析完成后,SPSS将生成一棵决策树模型,显示每个节点的切分规则、样本数量和分类结果。
可以通过查看节点间的连接关系和节点属性,对生成的决策树进行解释和评估。
6.预测与验证:使用生成的决策树模型对新的数据进行分类或预测。
可以使用SPSS的预测工具,将新的数据输入到决策树模型中,得到相应的分类结果或预测值。
在实际应用中,决策树分析可用于市场分析、客户群体划分、产品推荐等领域。
通过了解决策树的基本原理,并掌握SPSS的使用方法,可以更好地进行决策树分析,并将其应用于实际问题中。
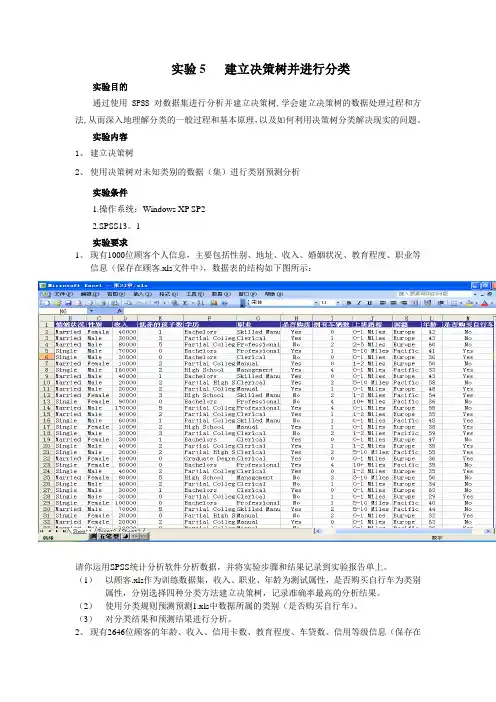
实验5 建立决策树并进行分类实验目的通过使用SPSS对数据集进行分析并建立决策树,学会建立决策树的数据处理过程和方法,从而深入地理解分类的一般过程和基本原理,以及如何利用决策树分类解决现实的问题。
实验内容1、建立决策树2、使用决策树对未知类别的数据(集)进行类别预测分析实验条件1.操作系统:Windows XP SP22.SPSS13。
1实验要求1、现有1000位顾客个人信息,主要包括性别、地址、收入、婚姻状况、教育程度、职业等信息(保存在顾客.xls文件中),数据表的结构如下图所示:请你运用SPSS统计分析软件分析数据,并将实验步骤和结果记录到实验报告单上。
(1)以顾客.xls作为训练数据集,收入、职业、年龄为测试属性,是否购买自行车为类别属性,分别选择四种分类方法建立决策树,记录准确率最高的分析结果。
(2)使用分类规则预测预测1.xls中数据所属的类别(是否购买自行车)。
(3)对分类结果和预测结果进行分析。
2、现有2646位顾客的年龄、收入、信用卡数、教育程度、车贷数、信用等级信息(保存在tree_credit.sav中),请你运用SPSS统计分析软件分析数据,并将实验步骤和结果记录到实验报告单上。
(1)分别选择四种分类方法建立决策树,记录准确率最高的分类析果。
(2)使用分类规则预测tree.sav中数据所属的类别(信用等级)。
(3)对分类结果和预测结果进行分析。
实验步骤及指导1、建立决策树第一步:数据准备,将待处理的数据输入或导入SPSS中,本例将顾客.xls导入SPSS 中。
第二步:建立决策树(1)选择统计分析[Statistics]菜单,选聚类分析[Classify]中的树状分析[Classification Tree...]项,弹出树状分析[Classification Tree]对话框,从对话框左侧的变量列表中分别选择类别属性和测试属性进入右侧类别属性[Dependent Variable]和测试属性[Independent Variable]框中。
基于决策树的三支决策中不承诺决策的转化邵晓艳;李言;李丽红【摘要】三支决策是在传统的二支决策中增加了不承诺决策,避免了立即做出承诺型决策所面临的风险.不承诺决策为已知条件和最终决策之间增加了一个缓冲,但是三支决策最终还是要转化为二支决策.提出利用PCA及决策树作为转化依据,利用可以做出承诺型决策的数据对边界域中的数据进行分类,减少了转化过程中的人为因素对结果的影响,最后用实例证明了模型的可行性和正确性.【期刊名称】《河北联合大学学报(自然科学版)》【年(卷),期】2017(039)004【总页数】6页(P111-116)【关键词】三支决策;不承诺决策;转化;决策树;PCA【作者】邵晓艳;李言;李丽红【作者单位】华北理工大学理学院,河北唐山 063210;华北理工大学理学院,河北唐山 063210;华北理工大学理学院,河北唐山 063210【正文语种】中文【中图分类】TP391三支决策现象在人类社会生活中普遍存在,但是三支决策作为一种理论出现,却是近年的事情。
2009年,三支决策[1]的概念被姚一豫提出,自此之后,三支决策受到了国内及国际学者的高度关注,他们对三支决策做了大量的研究,发现三支决策在实际中的重要作用。
现在的研究重点多集中在三支决策整体上,强调的了三支决策在二支决策的基础上,增加不承诺决策[2],实现了对二支决策的改进,更倾向于把不承诺决策看作三支决策的一个重要组成部分,并没有对三支决策中的不承诺决策进行深入研究,但是在实际生活中,不承诺决策等同于拒绝决策,不承诺决策的风险不亚于承诺型决策,同样需要付出代价。
李丽红、李言及刘保相等人在《三支决策中不承诺决策的转化代价与风险控制》[3]一文中研究了不承诺决策所存在的风险,并给出了基于转化代价最小原则的转化模型。
该项研究将利用PCA及决策树的方法实现三支决策中不承诺决策的转化。
首先,针对实际应用中的连续型变量利用PCA进行降维处理,以减少计算量;然后,利用新产生的属性生成决策树,对边界域中的元素在各个节点处进行分类,以生成确定型决策。
Chapter 2 使用决策树的预测建模2.1问题和数据探索 ................................................................................... 错误!未定义书签。
2.2建模问题和数据难点 (10)2.3生成和解释决策树................................................................................ 错误!未定义书签。
2.1问题和数据探索内容:问题和数据初步数据探索问题和数据a. 预测建模问题一家金融服务公司为其客户提供房屋净值信贷额度。
该公司曾把该项贷款扩展给了数千客户,其中的许多接收者(大约20%)有贷款欺诈行为。
该公司希望使用地理信息、人口信息、和经济状况信息变量建立一个模型预测一个申请人将来会不会欺诈。
b. 输入数据源在对数据进行了分析之后,该公司选择了12个预测变量来建立每一个申请人是否欺诈的模型。
输出变量(或目标)变量(BAD)表示申请人在房屋净值信贷中是否有欺诈活动。
这些变量及其模型角色、测量水平、变量描述列表如下。
表 2.1 SAMPSIO.HMEQ 数据集合的变量Name ModelRole MeasurementLevelDescriptionBAD Target Binary 1=defaulted on loan, 0=paidback loanREASON Input Binary HomeImp=homeimprovement, DebtCon=debtconsolidationJOB Input Nominal Six occupational categoriesLOAN Input Interval Amount of loan requestMORTDUE Input Interval Amount due on existingmortgageV ALUE Input Interval Value of current propertyDEBTINC Input Interval Debt-to-income ratioYOJ Input Interval Years at present jobDEROG Input Interval Number of major derogatoryreportsCLNO Input Interval Number of trade linesDELINQ Input Interval Number of delinquent tradelinesCLAGE Input Interval Age of oldest trade line inmonthsNINQ Input Interval Number of recent creditinquiries需要的结果-信用评分模型该信用评分模型给每一个贷款申请人计算还贷欺诈的概率。
“决策树”——数据挖掘、数据分析决策树是⼀个预测模型;他代表的是对象属性与对象值之间的⼀种映射关系。
树中每个节点表⽰某个对象,⽽每个分叉路径则代表的某个可能的属性值,⽽每个叶结点则对应从根节点到该叶节点所经历的路径所表⽰的对象的值。
决策树仅有单⼀输出,若欲有复数输出,可以建⽴独⽴的决策树以处理不同输出。
决策树的实现⾸先要有⼀些先验(已经知道结果的历史)数据做训练,通过分析训练数据得到每个属性对结果的影响的⼤⼩,这⾥我们通过⼀种叫做信息增益的理论去描述它,期间也涉及到熵的概念。
中决策树是⼀种经常要⽤到的技术,可以⽤于分析数据,同样也可以⽤来作预测(就像上⾯的银⾏官员⽤他来预测贷款风险)。
从数据产⽣决策树的机器学习技术叫做决策树学习, 通俗说就是决策树。
⼀个决策树包含三种类型的节点: 1.决策节点——通常⽤矩形框来表式 2.机会节点——通常⽤圆圈来表式 3.终结点——通常⽤三⾓形来表⽰决策树学习也是资料探勘中⼀个普通的⽅法。
在这⾥,每个决策树都表述了⼀种树型结构,它由它的分⽀来对该类型的对象依靠属性进⾏分类。
每个决策树可以依靠对源的分割进⾏数据测试。
这个过程可以递归式的对树进⾏修剪。
当不能再进⾏分割或⼀个单独的类可以被应⽤于某⼀分⽀时,递归过程就完成了。
另外,随机森林分类器将许多决策树结合起来以提升分类的正确率。
决策树对于常规统计⽅法的优缺点优点: 1) 可以⽣成可以理解的规则; 2) 计算量相对来说不是很⼤; 3) 可以处理连续和种类字段; 4) 决策树可以清晰的显⽰哪些字段⽐较重要。
缺点: 1) 对连续性的字段⽐较难预测; 2) 对有时间顺序的数据,需要很多预处理的⼯作; 3) 当类别太多时,错误可能就会增加的⽐较快; 4) ⼀般的算法分类的时候,只是根据⼀个字段来分类。
决策树的适⽤范围 科学的决策是现代管理者的⼀项重要职责。
我们在企业管理实践中,常遇到的情景是:若⼲个可⾏性⽅案制订出来了,分析⼀下企业内、外部环境,⼤部分条件是⼰知的,但还存在⼀定的不确定因素。