安德森《商务与经济统计》(第10版)(上册)课后习题详解(离散型概率分布)
- 格式:pdf
- 大小:1.88 MB
- 文档页数:51
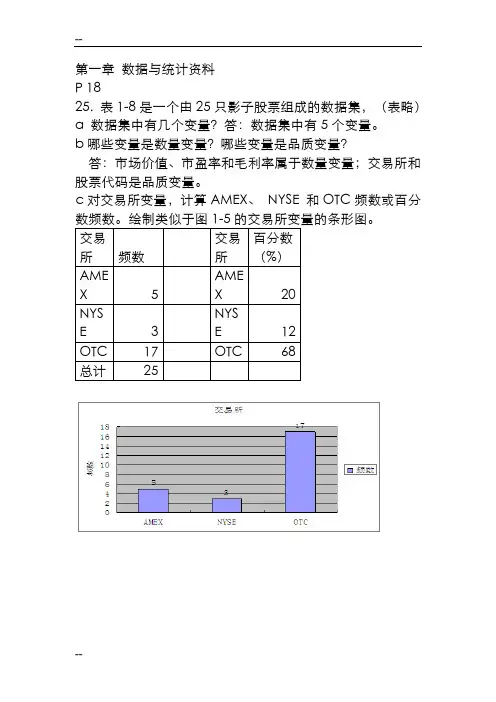
第一章数据与统计资料P 1825. 表1-8是一个由25只影子股票组成的数据集,(表略)a 数据集中有几个变量?答:数据集中有5个变量。
b哪些变量是数量变量?哪些变量是品质变量?答:市场价值、市盈率和毛利率属于数量变量;交易所和股票代码是品质变量。
c对交易所变量,计算AMEX、NYSE 和OTC频数或百分数频数。
绘制类似于图1-5的交易所变量的条形图。
e 平均市盈率是多少?答:利用EXCEL的求平均值功能得出平均市盈率是20.2第二章表格法和图形法P 235按字母顺序,美国最常见的6个姓氏为:布朗、戴维斯、约翰逊、琼斯、史密斯和威廉姆斯。
假设根据一个由50个人组成的样本,得到如下的姓氏数据(图略)a相对频数分布和百分数频数分布。
mstotal 50 b构建条形图c 构建饼形图d根据这些数据,最常见的3个姓氏是哪些?答:最常见的3个姓氏分别是史密斯、约翰逊和威廉姆斯。
P5051 表2-17 给出了50家《财富》500强公司的所有者权益、市场价值和利润数据。
(图略)a.构建所有者权益和利润变量的交叉分组表。
对利润数据以0-200,200-400,…,1000-1200分组,对所有者权益数据以0-1200,1200-2400,…,4800-6000分组。
b. 计算(a)中交叉分组表的行百分数。
P 5153. 参考表2-17中的数据集a. 绘出显示利润和所有者权益变量之间关系的散点图。
b. 评价这两个变量之间的关系。
答:二者呈正相关的关系,即所有者权益增加,利润也增加。
但因为所有点并不在一条直线上,所以这种关系不是完全的。
案例2-1 Pelican 商店1. 主要变量的百分数频数分布2. 条形图或饼形图,以显示因促销活动而使顾客购买的百分数。
3. 顾客类型(常规性或奖励性)与销售额的交叉分组表,并评价其相似性与差异性。
动取得了显著成效。
使用折扣赠券购买的奖励性顾客占全体顾客总数的70%,分布于各个销售额区域,尤其在销售额100内的范围里做出了突出贡献,尽管未使用折扣赠券的常规性顾客也主要集中在该销售额区域,但比重明显低于奖励性顾客,且在200以上的销售额区域则无常规性顾客,奖励性顾客的消费金额也扩大到300。


《商务统计学》题集一、选择题(每题2分,共10分)1.下列哪项不属于商务统计学的应用范围?A. 市场调查B. 质量控制C. 财务分析D. 天气预测2.在统计学中,总体是指什么?A. 研究的全部对象B. 研究中的一部分对象C. 某个具体的样本D. 某一特定数据3.下列哪种抽样方法是随机抽样?A. 方便抽样B. 系统抽样C. 配额抽样D. 判断抽样4.如果一组数据的均值是20,中位数是22,那么这组数据的分布可能是?A. 正偏态B. 负偏态C. 对称分布D. 无法确定5.在回归分析中,解释变量和被解释变量分别是什么?A. 因变量和自变量B. 自变量和因变量C. 都是自变量D. 都是因变量二、填空题(每空1分,共10分)1.在统计学中,用来衡量数据分布集中趋势的指标有______、______和______。
2.若一组数据的四分位数Q1=10,Q2=20,Q3=30,则该组数据的中位数为______。
3.在假设检验中,如果P值小于显著性水平α,则我们______原假设。
4.统计表中,频数和频率分别表示数据的______和______。
5.在回归分析中,回归系数的经济意义是解释变量每增加一个单位,被解释变量平均增加______单位。
三、判断题(每题1分,共10分)1.统计学的目的是收集、整理、分析和解释数据,从而帮助人们做出决策。
( )2.在正态分布中,均值、中位数和众数三者相等。
( )3.标准差是衡量数据波动大小的一个重要指标,标准差越大,说明数据的波动越大。
( )4.在假设检验中,如果P值大于显著性水平α,则我们有足够的证据拒绝原假设。
( )5.相关系数r的取值范围是[-1, 1],r=1表示完全正相关,r=-1表示完全负相关。
( )6.如果一组数据的偏度系数大于0,则说明这组数据是正偏态分布。
( )7.在抽样调查中,样本容量越大,抽样误差就越小。
( )8.统计推断是通过样本数据来推断总体的特征。
( )9.移动平均法是一种常用的时间序列预测方法。



商务与经济统计课后答案【篇一:商务经济统计学复习题】.简答题1.简要谈谈你对统计与统计学的初步认识。
2.谈谈你对统计的三种含义的理解,并举出现实经济生活中你所了解到的运用统计学的一个例子3.试就统计数据的四种类型给出统计整理与显示的方法(统计图要求划出示意图)。
4.概述数据的离散程度的常用的测度方法(异众比率标准差离散系数)。
5.什么是个体指数? 什么是总指数?它们的作用分别是什么?6.试简要说明总量指标、平均指标和相对指标的在统计学中的作用。
7.只能用统计条形图和饼图来展示的是哪种类型的数据?画出这两种图形的示意图。
8.自己用一个实例画出统计条形图和饼图的示意图,它们通常可以用来展示哪种类型的数据? 9.某高校毕业生就业指导中心想对2007届本校大学本科毕业生的毕业去向做一网上调查,请你为此设计一份半开放式(即:既含有封闭式问题又含有开放式问题)调查问卷。
(要求涉及学生的性别、专业、意向中的毕业去向:如出国、考研、自主创业、自主择业,以及意向中的就业领域、工薪待遇、单位性质、工作地区等等信息)。
二.填空题1.将下列指标按要求分类(只填写标号即可)(1)我国高等院校2006届本科毕业生就业率;(2)某贺岁片在国内上演第一周的票房收入;(3) 2006年第3季度一汽大众销售的某品牌小汽车台数占其全部小汽车销售量的比率;,(5)进藏铁路开通后第一周,每天乘火车前往西藏的旅客的累计人数;(6)第3季度某商场的月平均销售额。
哪些是时点时标;哪些是时期指标;哪些是平均指标;哪些是相对指标。
2.统计调查方式除了重点调查,典型调查之外,另三种主要方式是 3.加权调和平均公式为4.异众比率公式是其含义是5.一组数据中非众数组所占的比率叫做,它可测度分类数据的趋势;离散系数测度的是总体的平均离散程度,它的计算公式是v?=。
6.将下列指标分类:(1)2005年我国人均占有粮食产量(2)我国第五次人口普查总人口数(3)股价指数(4)销售量指数(5)单位产品成本(6)某商店全年销售额(7)某企业在岗职工人数和下岗职工人数的比例 (8)我国高等院校“十五”期间年平均招生人数哪些是时期指标哪些是时点指标;哪些是一般平均数, 哪些是序时平均数;哪些是相对指标 7.个体指数是反映项目或变量变动的相对数;反映多种项目或变量变动的相对数是。


《商务统计》试题4参考答案及评分标准一、判断题(每题1分,共10分)三、填空题(每题3四、计算题(每题15分,共45分)1.(1)令μ1、μ2分别表示塔吉特、沃尔玛两家零售商的顾客总体,则原假设为H 0:μ1−μ2=0(2分),备择假设为 H a :μ1−μ2≠0(1分)。
(2)应该应用标准正态分布的z 统计量(1分)。
因为两家零售商顾客满意度服从正态分布,且两家零售商顾客满意度的方差σ12、σ22已知。
则x̅1−x̅2服从均值为μ1−μ2,标准差为σx̅1−x̅2=√σ1/n 12+σ2/2212√σ1/n 1+σ2/2(2分)。
检验统计量z =12√σ1/n 1+σ2/2=√122/25+122/30=2.46(2分)。
(3)显著性水平是α=0.05,则拒绝域的临界值z 0.025=1.96, 拒绝原假设的决策准则为:z ≥1.96或者z ≤−1.96时,拒绝原假设H 0(2分)。
2.46>1.96,因此拒绝原假设。
塔吉特、沃尔玛两家零售商的顾客满意度存在显著差异(1分)。
(4)两家零售商顾客满意度的差μ1−μ2的的置信区间为(x̅1−x̅2)±z α2√σ12n 1+σ22n 2(2分)。
在1−α=95%的置信水平下,置信区间(x̅1−x̅2)±z α2√σ12n 1+σ22n 2=(79−71)±1.96√12225+12230=8±6.37(2分)。
2.(1)总的平均值x̿=133+139+136+1444=138(2分)。
(2)组间平方和:SSTR =∑n j (x̅j −x̿)2k j=1=330(2分)。
组间均方:MSTR =SSTR k−1=3303=110(1分)。
(3)误差平方和:SSE =∑(n j −1)s j 2k j=1=764(2分)。
均方误差:MSE =SSEnT−k=76416=47.75(1分)。
(4)(每空0.5分,共5分)。

概率论与数理统计第二章课后习题及参考答案1.离散型随机变量X 的分布函数为⎪⎪⎩⎪⎪⎨⎧≥<≤<≤--<=≤=.4,1,42,7.0,21,2.0,1,0)()(x x x x x X P x F 求X 的分布律.解:)0()()(000--==x F x F x X P ,∴2.002.0)01()1()1(=-=----=-=F F X P ,5.02.07.0)02()2()2(=-=--==F F X P ,3.07.01)04()4()4(=-=--==F F X P ,∴X 的分布律为2.设k a k X P 32()(==, ,2,1=k ,问a 取何值时才能成为随机变量X 的分布律.解:由规范性,a a a n n k k 2321]32(1[32lim)32(11=--=⋅=+∞→∞+=∑,∴21=a ,此时,k k X P 32(21)(⋅==, ,2,1=k .3.设离散型随机变量X 的分布律为求:(1)X 的分布函数;(2)21(>X P ;(3))31(≤≤-X P .解:(1)1-<x 时,0)()(=≤=x X P x F ,11<≤-x 时,2.0)1()()(=-==≤=X P x X P x F ,21<≤x 时,7.0)1()1()()(==+-==≤=X P X P x X P x F ,2≥x 时,1)2()1()1()()(==+=+-==≤=X P X P X P x X P x F ,∴X 的分布函数为⎪⎪⎩⎪⎪⎨⎧≥<≤<≤--<=.2,1,21,7.0,11,2.0,1,0)(x x x x x F .(2)方法1:8.0)2()1()21(==+==>X P X P X P .方法2:8.02.01)21(121(1)21(=-=-=≤-=>F X P X P .(3)方法1:1)2()1()1()31(==+=+-==≤≤-X P X P X P X P .方法2:101)01()3()31(=-=---=≤≤-F F X P .4.一制药厂分别独立地组织两组技术人员试制不同类型的新药.若每组成功的概率都是0.4,而当第一组成功时,每年的销售额可达40000元;当第二组成功时,每年的销售额可达60000元,若失败则分文全无.以X 记这两种新药的年销售额,求X 的分布律.解:设=i A {第i 组取得成功},2,1=i ,由题可知,1A ,2A 相互独立,且4.0)()(21==A P A P .两组技术人员试制不同类型的新药,共有四种可能的情况:21A A ,21A A ,21A A ,21A A ,相对应的X 的值为100000、40000、60000、0,则16.0)()()()100000(2121====A P A P A A P X P ,24.0)()()()40000(2121====A P A P A A P X P ,24.0)()()()60000(2121====A P A P A A P X P ,36.0)()()()0(2121====A P A P A A P X P ,∴X 的分布律为5.对某目标进行独立射击,每次射中的概率为p ,直到射中为止,求:(1)射击次数X 的分布律;(2)脱靶次数Y 的分布律.解:(1)由题设,X 所有可能的取值为1,2,…,k ,…,设=k A {射击时在第k 次命中目标},则k k A A A A k X 121}{-== ,于是1)1()(--==k p p k X P ,所以X 的分布律为1)1()(--==k p p k X P , ,2,1=k .(2)Y 的所有可能取值为0,1,2,…,k ,…,于是Y 的分布律为1)1()(--==k p p k Y P , ,2,1,0=k .6.抛掷一枚不均匀的硬币,正面出现的概率为p ,10<<p ,以X 表示直至两个面都出现时的试验次数,求X 的分布律.解:X 所有可能的取值为2,3,…,设=A {k 次试验中出现1-k 次正面,1次反面},=B {k 次试验中出现1-k 次反面,1次正面},由题知,B A k X ==}{,=AB ∅,则)1()(1p p A P k -=-,p p B P k 1)1()(--=,p p p p B P A P B A P k X P k k 11)1()1()()()()(---+-=+=== ,于是,X 的分布律为p p p p k X P k k 11)1()1()(---+-==, ,3,2=k .7.随机变量X 服从泊松分布,且)2()1(===X P X P ,求)4(=X P 及)1(>X P .X 100000060000400000P0.160.240.240.36解: )2()1(===X P X P ,∴2e e2λλλλ--=,∴2=λ或0=λ(舍去),∴224e 32e !42)4(--===X P .)1()0(1)1(1)1(=-=-=≤-=>X P X P X P X P 222e 31e 2e 1----=--=.8.设随机变量X 的分布函数为⎩⎨⎧<≥+-=-.0,0,0,e )1(1)(x x x x F x 求:(1)X 的概率密度;(2))2(≤X P .解:(1)⎩⎨⎧<≥='=-.0,0,0,e )()(x x x x F x f x ;(2)2e 31)2()2(--==≤F X P .9.设随机变量X 的概率密度为xx Ax f e e )(+=-,求:(1)常数A ;(2))3ln 210(<<X P ;(3)分布函数)(x F .解:(1)⎰⎰+∞∞--+∞∞-+==xAx x f xx d e e d )(1A A x A x x x 2|e arctan d e 21e 2π==+=∞+∞-∞+∞-⎰,∴π2=A .(2)61|e arctan 2d e e 12)3ln 210(3ln 2103ln 210==+=<<⎰-x xx x X P ππ.(3)x xx x xx t t f x F e arctan 2d e e 12d )()(ππ=+==⎰⎰∞--∞-.10.设连续型随机变量X 的分布函数为⎪⎪⎩⎪⎪⎨⎧>≤<-+-≤=.a x a x a a x B A a x x F ,1,,arctan ,,0)(其中0>a ,试求:(1)常数A ,B ;(2)概率密度)(x f .解:(1) 2arcsin (lim )0()(0)(π⋅-=+=+-=-=+-→B A a x B A a F a F a x ,1)(lim )0()(2==+==⋅++→x F a F a F B A a x π,∴21=A ,π1=B .(2)⎪⎩⎪⎨⎧≥<-='=.a x a x x a x F x f ,0,,1)()(22π.11.设随机变量X 的概率密度曲线如图所示,其中0>a .(1)写出密度函数的表达式,求出h ;(2)求分布函数)(x F ;(3)求)2(a X aP ≤<.解:(1)由题设知⎪⎩⎪⎨⎧≤≤-=其他.,0,0,)(a x x ah h x f 2d )(d )(10ahx x a h h x x f a=-==⎰⎰+∞∞-,∴ah 2=,从而⎪⎩⎪⎨⎧≤≤-=其他.,0,0,22)(2a x x a a x f .y hO a x(2)0<x 时,0d 0d )()(===⎰⎰∞-∞-xxt t t f x F ,a x <≤0时,220202d )22(d 0d )()(a x a x t t a a t t t f x F xx-=-+==⎰⎰⎰∞-∞-,a x ≥时,1)(=x F ,∴X 的分布函数为⎪⎪⎩⎪⎪⎨⎧≥<≤-<=.a x a x axa x x x F ,1,0,2,0,0)(22.(3)41411(1)2()()2(=--=-=≤<a F a F a X a P .12.设随机变量X 在]6,2[上服从均匀分布,现对X 进行三次独立观察,试求至少有两次观测值大于3的概率.解:由题意知⎪⎩⎪⎨⎧≤≤=其他.,0,62,41)(x x f ,记3}{>=X A ,则43d 41)3()(63==>=⎰x X P A P ,设Y 为对X 进行三次独立观测事件}3{>X 出现的次数,则Y ~43,3(B ,所求概率为)3()2()2(=+==≥Y P Y P Y P )(()(333223A P C A P A P C +=3227)43(41)43(333223=+⋅=C C .13.设随机变量X 的概率密度为⎩⎨⎧<<=其他.,0,10,3)(2x x x f 以Y 表示对X 的三次独立重复观察中事件}21{≤X 出现的次数,求:(1)}21{≤X 至少出现一次的概率;(2)}21{≤X 恰好出现两次的概率.解:由题意知Y ~),3(p B ,其中81d 321(2102==≤=⎰x x X P p ,(1)}21{≤X 至少出现一次的概率为512169)811(1)1(1)0(1)1(33=--=--==-=≥p Y P Y P .(2)}21{≤X 恰好出现两次的概率为51221811(81()1()2(223223=-=-==C p p C Y P .14.在区间],0[a 上任意投掷一个质点,以X 表示这个质点的坐标.设这个质点落在],0[a 中任意小区间内的概率与这个小区间的长度成正比例.试求X 的分布函数.解:0<x 时,事件}{x X ≤表示X 落在区间],0[a 之外,是不可能事件,此时0)()(=≤=x X P x F ;a x ≤≤0时,事件}{x X ≤发生的概率等于X 落在区间],0[x 内的概率,它与],0[x 的长度x 成正比,即x k x X P x F =≤=)()(,a x =时,1)(=≤x X P ,所以a k 1=,则此时axx F =)(;a x ≥时,事件}{x X ≤是必然事件,有1)(=x F ,综上,⎪⎪⎩⎪⎪⎨⎧≥<≤<=,a x a x a x x x F ,1,0,,0,0)(.15.设X ~),2(2σN ,又3.0)42(=<<X P ,求)0(>X P .解:)24222()42(σσσ-<-<-=<<X P X P 3.0)0(2(=Φ-Φ=σ,∴8.03.0)0()2(=+Φ=Φσ,∴8.0)2()2(1)0(1)0(=Φ=-Φ-=≤-=>σσX P X P .16.设X ~)4,10(N ,求a ,使得9.0)10(=<-a X P .解:)10()10(a X a P a X P <-<-=<-)22102(a X a P <-<-=)2()2(a a -Φ-Φ=9.01)2(2=-Φ=a,∴95.0)2(=Φa,查标准正态分布表知645.12=a,∴290.3=a .17.设X ~)9,60(N ,求分点1x ,2x ,使得X 分别落在),(1x -∞,),(21x x ,),(2∞x 的概率之比为3:4:5.解:由题知5:4:3)(:)(:)(2211=><<<x X P x X x P x X P ,又1)()()(2211=>+<<+<x X P x X x P x X P ,∴25.041)(1==<x X P ,33.031)(21==<<x X x P ,125)(2=>x X P ,则5833.0127)(1)(22==>-=≤x X P x X P .25.0)360()360360()(111=-Φ=-<-=<x x X P x X P ,查标准正态分布表知03601<-x ,∴03601>--x ,则75.0)360(1)360(11=-Φ-=--Φx x 查标准正态分布表,有7486.0)67.0(=Φ,7517.0)68.0(=Φ,75.02)68.0()67.0(=Φ+Φ,∴675.0268.067.03601=+=--x ,即975.571=x .5833.0360()360360()(222=-Φ=-≤-=≤x x X P x X P ,查标准正态分布表知5833.0)21.0(=Φ,∴21.03602=-x ,即63.602=x .18.某高校入学考试的数学成绩近似服从正态分布)100,65(N ,如果85分以上为“优秀”,问数学成绩为“优秀”的考生大致占总人数的百分之几?解:设X 为考生的数学成绩,则X ~)100,65(N ,于是)85(1)85(≤-=>X P X P )1065851065(1-≤--=X P 0228.09772.01)2(1=-=Φ-=,即数学成绩为“优秀”的考生大致占总人数的2.28%.19.设随机变量X 的分布律为求2X Y =的分布律.解:Y 所有可能的取值为0,1,4,9,则51)0()0(====X P Y P ,307)1()1()1(==+-===X P X P Y P ,51)2()4(=-===X P Y P ,3011)3()9(====X P Y P ,∴Y 的分布律为20.设随机变量X 在)1,0(上服从均匀分布,求:(1)X Y e =的概率密度;(2)X Y ln 2-=的概率密度.解:由题设可知⎩⎨⎧<<=其他.,0,10,1)(x x f ,(1)当0≤y 时,=≤}{y Y ∅,X 2-1-013P5161511513011X 0149P51307513011∴0)()(=≤=y Y P y F Y ,0)(=y f Y ;e 0<<y 时,)e ()()(y P y Y P y F X Y ≤=≤=)(ln )ln (y F y X P X =≤=,此时,yy f y y y F y F y f X XY X 1)(ln 1)(ln )(ln )()(=='⋅'='=;e ≥y 时,1)()(=≤=y Y P y F Y ,0)(=y f Y ;∴⎪⎩⎪⎨⎧<<=其他.,0,e 0,1)(y y y f Y .(2)当0≤y 时,=≤}{y Y ∅,∴0)()(=≤=y Y P y F Y ,0)(=y f Y ;当0>y 时,)e ()ln 2()()(2y Y X P y X P y Y P y F -≥=≤-=≤=)e (1)e (122y X y F X P ---=<-=,此时,222e 21)e ()e ()()(yy y X Y X F y F y f ---='⋅'-='=;∴⎪⎩⎪⎨⎧≤>=-.0,0,0,e 21)(2y y y f yY .21.设X ~)1,0(N ,求:(1)X Y e =的概率密度;(2)122+=X Y 的概率密度;(3)X Y =的概率密度.解:由题知22e 21)(x X xf -=π,+∞<<∞-x ,(1)0≤y 时,=≤=}e {y Y X ∅,∴0)()(=≤=y Y P y F Y ,0)(=y f Y ;0>y 时,)(ln )ln ()e ()()(y F y X P y P y Y P y F X X Y =≤=≤=≤=,此时,2)(ln 2e 21)(ln 1)(ln )(ln )()(y X XY X y f yy y F y F y f -=='⋅'='=π;综上,⎪⎩⎪⎨⎧≤>=-.0,0,0,e 21)(2)(ln 2y y y f y Y π.(2)1<y 时,=≤+=}12{2y X Y ∅,∴0)()(=≤=y Y P y F Y ;1≥y 时,21()12()()(22-≤=≤+=≤=y X P y X P y Y P y F Y )2121(-≤≤--=y X y P 当1=y 时,0)(=y F Y ,故1≤y 时,0)(=y F Y ,0)(=y f Y ;当1>y 时⎰⎰------==210221212d e22d e21)(22y x y y x Y x x y F ππ,此时,41e)1(21)()(---='=y Y Y y y F y f π,综上,⎪⎩⎪⎨⎧≤>-=--.1,0,1,e )1(21)(41y y y y f y Y π.(3)0<y 时,=≤=}{y X Y ∅,∴0)()()(=≤=≤=y X P y Y P y F Y ,0≥y 时,)()()()(y X y P y X P y Y P y F Y ≤≤-=≤=≤=)()(y F y F X X --=,0=y 时,0)(=y F Y ,∴0≤y 时,有0)(=y F Y ,0)(=y f Y ;0>y 时,22e 22)()()()()(y X X Y Y Y yf y f y F y F y f -=-+=-'+'=π,综上,⎪⎩⎪⎨⎧≤>=-.0,0,0,e 22)(22y y y f yY π.22.(1)设随机变量X 的概率密度为)(x f ,+∞<<∞-x ,求3X Y =的概率密度.(2)设随机变量X 的概率密度为⎩⎨⎧>=-其他.,00,e )(x x f x 求2X Y =的概率密度.解:(1)0=y 时,0)()(=≤=y Y P y F Y ,0)(=y f Y ;0≠y 时,)()()()()(333y F y X P y X P y Y P y F X Y =≤=≤=≤=,3233331())(()()(-⋅=''='=y y f y y F y F y f XY Y ;∴⎪⎩⎪⎨⎧=≠=-.0,0,0),(31)(332y y y f y y f Y .(2)由于02≥=X Y ,故当0<y 时,}{y Y ≤是不可能事件,有0)()(=≤=y Y P y F Y ;当0≥y 时,有)()(()()()(2y F y F y X y P y X P y Y P y F X X Y --=≤≤-=≤=≤=;因为当0=y 时,0)0()0()(=--=X X Y F F y F ,所以当0≤y 时,0)(=y F Y .将)(y F Y 关于y 求导数,即得Y 的概率密度为⎪⎩⎪⎨⎧≤>-+=.,;,000)](([21)(y y y f y f y y f X X Y ,⎪⎩⎪⎨⎧≤>+=-.0,0,0),e e (21y y yyy .23.设随机变量X 的概率密度为⎪⎩⎪⎨⎧<<=其他.,0,0,2)(2ππx xx f 求X Y sin =的概率密度.解:由于X 在),0(π内取值,所以X Y sin =的可能取值区间为)1,0(,在Y 的可能取值区间之外,0)(=y f Y ;当10<<y 时,使}{y Y ≤的x 取值范围是),arcsin []arcsin ,0(ππy y - ,于是}arcsin {}arcsin 0{}{ππ<≤-≤<=≤X y y X y Y .故)arcsin ()arcsin 0()()(ππ<≤-+≤<=≤=X y P y X P y Y P y F Y ⎰⎰-+=ππyX y X x x f x x f arcsin arcsin 0d )(d )(⎰⎰-+=ππππyy x xx xarcsin 2arcsin 02d 2d 2,上式两边对y 求导,得22222121)arcsin (21arcsin 2)(yyy yyy f Y -=--+-=ππππ;综上,⎪⎩⎪⎨⎧<<-=其他.,0,10,12)(2y y y f Y π.。


3.41 数值型数据的中心趋势包括平均数,中位数和众数,主要体现了一组数据的基本均衡点,能大致反应数据的基本情况。
3.47 经验法则说明大约有68%的数据分布在离均值一个标准差的范围内,大约有95%的数据分布在离均值两个标准差的范围内,大约有99%的数据分布在离均值三个标准差的范围内。
3.52:a.平均43.88889标准误差 4.865816中位数45众数17标准差25.28352方差639.2564峰度-0.90407偏度0.517268区域76最小值16最大值92求和1185观测数27最大(1) 92最小(1) 16置信度10.00183(95.0%)所以平均值是43.88889;中位数是45;上四分数是18;下四分数是63;B.极差是76;内距是45;方差是639.2564;标准差是25.28352;变异系数是57.61%。
ArrayC.该箱线图不对称。
呈右偏分布。
D.平均的程序处理时间大约为44天,据统计,大概50%的处理时间不超过45天,而处理时间在18~63天的情况也占50%,18~69天的情况占67%。
3.53a.平均43.04标准误差 5.92924中位数28.5众数 5标准差41.92606方差1757.794峰度 1.309326偏度 1.487586区域164最小值 1最大值165求和2152观测数50最大(1) 165最小(1) 1置信度11.91525(95.0%)平均值是43.04;中位数是28.5;上四分数是13.75;下四分数是55.75;b.极差是164;内距是27.25;方差是1757.794;标准差是41.9261;变异系数是97.4119% Arrayc.3.54a.平均8.420898标准误差0.0065878中位数8.42众数8.42标准差0.0461146方差0.0021266峰度0.0358142偏度-0.485681区域0.186最小值8.312最大值8.498求和412.624观测数49最大(1) 8.498最小(1) 8.312置信度(95.0%) 0.0132456平均值是8.420898;中位数是8.42;极差是0.186;标准差是0.04611;b..最大值是8.498;最小值8.312;中位数是8.42;上四分数是8.405;下四分数是8.458;因为最小值与中位数的差值0.108大于最大值与中位数的差值0.078,所以这些数据的分布呈轻微的左偏分布d.这些数值均在8.31~8.61之间,所以所有的器材都符合公司的标准。
第一次作业题目和答案2.8 试指出下列的变项属于哪个测量层次:(1)性别;(2)籍贯;(3)高校教师职称;(4)民族;(5)温度;(6)宗教信仰;(7)托福成绩;(8)人体体重;(9)产品品级;(10)每月上课天数。
解答提示:定类、定序、定距、定比四种测量层次;答案形式1:(1)定类,(2)定类,(3)定序,(4)定类,(5)定距,(6)定类,(7)定距,(8)定比,(9)定序,(10)定距答案形式2:定类:1,2,4,6定序:3,9定距:5,7,10定比:82.9 试同时以定类、定序和定距三个个量化层次测量下列变项,并写出测量语句。
(1)收入;(2)入学成绩;(3)教育。
(1)收入定类:将收入高低进行分类定序:将收入分为低收入、中等收入、高收入定距:将0—1000分为低收入,1000—2000分为中等收入,2000-3000分为高收入(2)入学成绩定类:将入学成绩高低进行分类定序:将入学成绩按不及格、合格、良好、优秀分类定距:60-70为一个分数段,70-80为一个分数段,80-90为一个分数段,90-100为一个分数段(3)教育定类:将教育程度高低进行分类定序:按小学、初中、高中、大学、研究生进行分类定距:将受教育年限以5年为一个阶段,从低到高排列进行分类2.11 在花卉苗圃进行肥料试验,分A、B、C、D、E五种肥料处理,小区面积为一个苗床,⨯拉丁方设计,田间排列及试验结果如表2-3所示:采用55表2-3 田间排列及试验结果⨯拉丁方的“选择拉丁方”试写出从55A B C D EB A EC DC D A E BD E B A CE C D B A经过变换得到种苗所用的拉丁方的步骤。
【题目答案及说明】从“选择拉丁方”到题目实验组的非标准拉丁方阵的一种变换方法,可能不止这一种:(1)因为通过简单的行列变换无法使一行中的部分元素转移到别的行,或者一列中的部分元素转移到别的列,所以通过观察方阵,实施单单实施行列变化无法得到最终的实验组拉丁方阵。
商务与经济统计精要版答案【篇一:经管类书单推荐】与管理学院 2016.10.17管理类推荐读物孙耀君,《西方管理学名著提要》,江西人民出版社1)管理学邢以群,《管理学》,浙江大学出版社周三多,《管理学》,复旦大学出版社2)管理信息系统kenneth udon/ jane udon ,《管理信息系统—网络化企业的组织与技术》(第六版,影印版),高等教育出版社薛华成,《管理信息系统》(第三版),清华大学出版社小威廉d.佩勒尔特 e.杰罗姆.麦卡锡,《市场营销学基础》:全球管理(英文版.第12版)--国际通用mba教材》,机械工业出版社郭毅等,《市场营销学原理》,电子工业出版社malhotra,n.k.著,《市场营销研究应用导向(第3版)》,电子工业出版社4)战略管理项保华,《战略管理——艺术与实务》,华夏出版社斯蒂文斯(英),《战略性思维》,机械工业出版社arthur a. thompson, jr. and a. j. strickland Ⅲ.crafting implementing strategy. 6th ed. richard d. irwin, inc., 1995中文版《战略管理学:概念与案例(英文版.第十版)-- 国际通用mba教材》,机械工业出版社david besanko, david dranove, mark shanley. the economics of strategy. john wiley sons, inc., 1996alan j. rowe; et al.. strategic management: a methodological approach. 4th ed. addison-wesley publishing company, inc., 19945)组织行为学卢盛忠等,《组织行为学:理论与实践》,浙江教育出版社英文版《human resource management: gaining a competitive advantage》,清华大学出版社约翰.m.伊万切维奇,《人力资源管理(英文版.原书第8版)-- 国际通用mba教材》,机械工业出版社luis r. gomez-mejia,david b.balkin,robert l. cardy,《管理人力资源 managing human resources 》(英文版第三版),北京大学出版社、培生教育出版集团7)财务管理8)管理统计david r.anderson dennis j.sweeney thomasa.william,《商务与经济统计(第七版)-- 经济教材译丛》,机械工业出版社david r.anderson;dennis j.sweeney;thomas a.william,《商务与经济统计(英文版.第8版)--21世纪经典原版经济管理教材文库》,机械工业出版9)会计学张启銮等,《会计学――工商管理硕士(mba)系列教材》,大连理工大学出版社cktde p.stickney roman l.weil,《财务会计(英文版第9版) --国际通用mba教材》,机械工业出版社ronald w.hilton,《管理会计(英文版.第三版)-- 国际通用mba教材》,机械工业出版10)西方经济学[美]平狄克等:《微观经济学》,中国人民大学出版社梁小民,《宏观经济学》,中国社会科学出版社梁小民,《西方经济学导论》,北京大学出版社宋承先,《现代西方经济学》(宏观经济学),复旦大学出版社[美] h.克雷格.彼得森等:《管理经济学》,中国人民大学出版社[美]s.charles maurice christopher r.thomas, managerial economics, 机械工业出社,2000年影印版11)运筹学胡运权,《运筹学教程(第二版)》,清华大学出版社蒋绍忠,《运筹学讲义》,浙江大学管理学院12)经济法高程德,《经济法》(第九版),上海人民出版社13)电子商务daniel amor,《电子商务:变革与演进--经济教材译丛》,机械工业出版社14)组织理论[美]达夫特著,李维安译.《组织理论与设计精要》,机械工业出版社[英]bernard burnes.《变革时代的管理》,云南大学出版社15)质量管理刘广第,《质量管理学(第二版)》,清华大学出版社16)生产管理陈荣秋、马士华,生产与运作管理,高等教育出版社,1999潘家轺等,现代生产管理学,北京:清华大学出版社,1994黄卫伟,生产与作业管理,北京:人民大学出版社,199717)项目管理毕星、翟丽,《项目管理》,复旦大学出版社,2000[美]杰克.吉多等著, 《成功的项目管理》,机械工业出版社,1999白思俊主编, 《现代项目管理》(上,中,下),机械工业出版社,20022.认知心理学,robert j.sternberg,中国轻工业出版社3.人格理论,jess feist,gregory j.feist,人民卫生出版社4.社会心理学,elliott aronson等,中国轻工业出版社5.集合起来——群体理论与团队技巧,david w. johnson等,中国轻工业出版社8.招贤纳士自有道,lance a. berger等,清华大学出版社11. 内向者优势,martin olsen laney,华东师范大学出版社13. 超级冷静,铃木丈织,上海人民出版社31. 刘墉的书:我不是教你诈、你不可不知的人性、人生的真相补充书籍:经济类专业推荐读物 1、《摩根财团——美国一代银行王朝和现代金融业的崛起》第二版获得1990年美国国家图书奖推荐理由:摩根家族的发迹史和19-20世纪美国金融市场和银行业发展演变的全景图,前任财政部副部长、现任亚洲开发银行副行长金立群先生的翻译代表了中文相关专业译著的最高水平。
第12章拟合优度检验和独⽴性检验1⽤χ2拟合优度检验对下列假设进⽤检验。
H0:p A=0.40,p B=0.40,p C=0.20H a:总体⽤例不是p A=0.40,p B=0.40,p C=0.20容量为200的样本中有60个个体属于类别A,120个个体属于类别B,20个个体属于类别C。
取=0.01,检验⽤率是否为H0中所述。
a.使⽤p-值法。
b.使⽤临界值法。
解:a.由原假设可得期望频数分别为:e1=200×0.40=80,e2=200×0.40=80,e3=200×0.20=40⽤观察频数为f1=60,f2=120,f3=20。
所以由于⽤由度为k-1=3-1=2,,利⽤⽤由度为2的分布表可知,p-值⽤于0.005,所以拒绝原假设。
b.由于,⽤由度为2,则检验统计量的临界值为,⽤,所以拒绝原假设。
2假设我们有⽤个包含A、B、C和D4个类别的多项总体。
零假设是每个类别的⽤例相同,即H0:p A=p B=p C=p D=0.25容量为300的样本有如下结果。
A:85 B:95 C:50 D:70取=0.05,判断H0是否被拒绝。
p-值是多少?解:由原假设可得期望频数为:e1=e2=e3=e4=300×0.25=75⽤观察频数为f1=85,f2=95,f3=50,f4=70。
所以由于⽤由度为k-1=4-1=3,利⽤Excel可得对应于=15.33的p-值=0.0016< =0.05,所以拒绝原假设,即每个类别的⽤例不是相同的。
3在电视节的前13周中,周六晚8点到9点的有关收视率记录为:ABC 29%,CBS 28%,NBC 25%,其他18%。
在周六晚电视节⽤单修订两周后,分析由300个家庭组成的样本得到如下电视收视率数据:观看ABC有95个家庭,观看CBS有70个家庭,观看NBC有89个家庭,其他有46个家庭。
取=0.05,检验电视收视率是否已经发⽤了变化。