正则表达式笔记
- 格式:docx
- 大小:25.52 KB
- 文档页数:4

笔记整理——Linux下C语⾔正则表达式Linux下C语⾔正则表达式使⽤详解 - Google Chrome (2013/5/2 16:40:37)Linux下C语⾔正则表达式使⽤详解2012年6⽉6⽇627 views标准的C和C++都不⽀持正则表达式,但有⼀些函数库可以辅助C/C++程序员完成这⼀功能,其中最著名的当数Philip Hazel的Perl-Compatible Regular Expression库,许多Linux发⾏版本都带有这个函数库。
C语⾔处理正则表达式常⽤的函数有regcomp()、regexec()、regfree()和regerror(),⼀般分为三个步骤,如下所⽰:C语⾔中使⽤正则表达式⼀般分为三步:1. 编译正则表达式 regcomp()2. 匹配正则表达式 regexec()3. 释放正则表达式 regfree()下边是对三个函数的详细解释1. int regcomp (regex_t *compiled, const char *pattern, int cflags)这个函数把指定的正则表达式pattern编译成⼀种特定的数据格式compiled,这样可以使匹配更有效。
函数regexec 会使⽤这个数据在⽬标⽂本串中进⾏模式匹配。
执⾏成功返回0。
参数说明:①regex_t 是⼀个结构体数据类型,⽤来存放编译后的正则表达式,它的成员re_nsub ⽤来存储正则表达式中的⼦正则表达式的个数,⼦正则表达式就是⽤圆括号包起来的部分表达式。
②pattern 是指向我们写好的正则表达式的指针。
③cflags 有如下4个值或者是它们或运算(|)后的值:REG_EXTENDED 以功能更加强⼤的扩展正则表达式的⽅式进⾏匹配。
REG_ICASE 匹配字母时忽略⼤⼩写。
REG_NOSUB 不⽤存储匹配后的结果。
REG_NEWLINE 识别换⾏符,这样'$'就可以从⾏尾开始匹配,'^'就可以从⾏的开头开始匹配。

PowerShell笔记-13.正则表达式本系列是⼀个重新学习PowerShell的笔记,内容引⽤⾃定义模式如果你需要更加精确的模式识别需要使⽤正则表达式,正则表达式提供了更加丰富的通配符。
正因为如此,它可以更加详细的描述模式,正则表达式也因此稍显复杂。
使⽤下⾯的表格中列出的正则表达式元素,你可以⾮常精准的描述模式。
这些正则表达式元素可以归为三⼤类。
字符:字符可以代表⼀个单独的字符,或者⼀个字符集合构成的字符串。
限定符:允许你在模式中决定字符或者字符串出现的频率。
定位符:允许你决定模式是否是⼀个独⽴的单词,或者出现的位置必须在句⼦的开头还是结尾。
正则表达式代表的模式⼀般由四种不同类型的字符构成。
⽂字字符:像”abc”确切地匹配”abc“字符串转义字符:⼀些特殊的字符例如反斜杠,中括号,⼩括号在正则表达式中居于特殊的意义,所以如果要专门识别这些特殊字符需要转义字符反斜杠。
就像”[abc]”可以识别”[abc]”。
预定义字符:这类字符类似占位符可以识别某⼀类字符。
例如”\d”可以识别0-9的数字。
⾃定义通配符:包含在中括号中的通配符。
例如”[a-d]”识别a,b,c,d之间的任意字符,如果要排除这些字符,可以使⽤”[^a-d]”。
字符元素描述.匹配除了换⾏符意外的任意字符[^abc]匹配除了包含在中括号的任意字符[^a-z]匹配除了包含在中括号指定区间字符的任意字符[abc]匹配括号中指定的任意⼀个字符[a-z]匹配括号中指定的任意区间中的任意⼀个字符\a响铃字符(ASCII 7)\c or \C匹配ASCII 中的控制字符,例如Ctrl+C\d匹配数字字符,等同于[0-9]\D匹配数字以外的字符\e Esc (ASCII 9)\f换页符(ASCII 15)\n换⾏符\r回车符\s⽩空格(空格,制表符,新⾏)\S匹配⽩空格(空格,制表符,新⾏)意外的字符\t制表符\uFFFF匹配Unicode字符的⼗六进制代码FFFF。

JavaScript正则表达式迷你书之贪婪模式-学习笔记贪婪模式:在使⽤修饰匹配次数的特殊符号时,有⼏种表⽰⽅法可以使同⼀个表达式能够匹配不同的次数,⽐如:"{m,n}", "{m,}", "?", "*", "+",具体匹配的次数随被匹配的字符串⽽定。
这种重复匹配不定次数的表达式在匹配过程中,总是尽可能多的匹配⾮贪婪模式:在修饰匹配次数的特殊符号后再加上⼀个 "?" 号,则可以使匹配次数不定的表达式尽可能少的匹配,使可匹配可不匹配的表达式,尽可能的 "不匹配"。
这种匹配原则叫作 "⾮贪婪" 模式,也叫作 "勉强" 模式。
如果少匹配就会导致整个表达式匹配失败的时候,与贪婪模式类似,⾮贪婪模式会最⼩限度的再匹配⼀些,以使整个表达式匹配成功。
var regex = /\d{2,5}/g;var string = "123 1234 12345 123456";console.log( string.match(regex) );// => ["123", "1234", "12345", "12345"]其中正则 /d{2,5}/,表⽰数字连续出现 2 到 5 次。
会匹配 2 位、3 位、4 位、5 位连续数字。
但是其是贪婪的,它会尽可能多的匹配。
你能给我 6 个,我就要 5 个。
你能给我 3 个,我就要 3 个。
反正只要在能⼒范围内,越多越好。
横向模糊匹配横向模糊指的是,⼀个正则可匹配的字符串的长度不是固定的,可以是多种情况的。
其实现的⽅式是使⽤量词。
譬如 {m,n},表⽰连续出现最少 m 次,最多 n 次。
⽐如正则 /ab{2,5}c/ 表⽰匹配这样⼀个字符串:第⼀个字符是 "a",接下来是 2 到 5 个字符 "b",最后是字符 "c"。

(个人收集学习笔记)4字符串处理与正则表达式第四章字符串处理与正则表达式一、字符串处理介绍1、如果字符串处理函数和正则表达式都可以实现字符串操作,建议使用字符串处理函数,因为效率高。
2、因为PHP 是弱类型语言,所以其他类型的数据一般都可以直接应用于字符串操作函数里,而自动转换成字符串类型进行处理。
3、还可以将字符串视为数组,或当作字符集合来看待。
$str[0]$str{0}二、常用的字符串输出函数1、echo()函数:使用它的效率要比其他字符串输出函数高。
2、print()函数:功能和echo()一样,但它有返回值,成功返回1,不成功返回0。
3、die()函数:exit()函数的别名。
1)参数如果是字符串,则该函数会在退出前输出它。
2)如果参数是一个整数,这个值会被用做退出状态。
值在0-254之间,退出状态255由PHP 保留,不会使用。
状态0用于成功终止程序。
4、printf():用于输出格式化字符串。
1)例子:printf(“%s age is $d”,$str,$num);2)%d :带符号十进制数%u :无符号十进制数%f :浮点数%s :字符串%b :二进制数%c :依照ASCII 值的字符%%:返回百分比符号%o :八进制数%x :十六进制数(小写字母)%X :十六进制数(大写字母)3)如果%符号多于arg 参数,则必须使用占位符。
占位符被插入到%符号之后,由数字和\$组成。
如:printf(“The %2\$s book contains %1\$d pages.That’s a nice %2\$s full of %1\$d pages”,$num,$str);%2\$s 代表$str 。
5、sprintf()函数:用法和printf()一样,但它不是输出字符串,而是把格式化的字符串以返回值的形式写入到一个变量中。
三、常用的字符串格式化函数字符串的格式化就是将字符串处理为某种特定的格式。
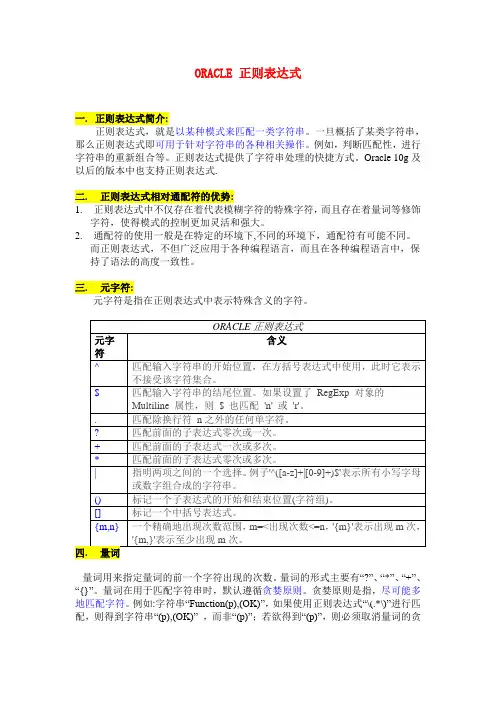
ORACLE 正则表达式一.正则表达式简介:正则表达式,就是以某种模式来匹配一类字符串。
一旦概括了某类字符串,那么正则表达式即可用于针对字符串的各种相关操作。
例如,判断匹配性,进行字符串的重新组合等。
正则表达式提供了字符串处理的快捷方式。
Oracle 10g及以后的版本中也支持正则表达式.二. 正则表达式相对通配符的优势:1.正则表达式中不仅存在着代表模糊字符的特殊字符,而且存在着量词等修饰字符,使得模式的控制更加灵活和强大。
2.通配符的使用一般是在特定的环境下,不同的环境下,通配符有可能不同。
而正则表达式,不但广泛应用于各种编程语言,而且在各种编程语言中,保持了语法的高度一致性。
三. 元字符:元字符是指在正则表达式中表示特殊含义的字符。
量词用来指定量词的前一个字符出现的次数。
量词的形式主要有“?”、“*”、“+”、“{}”。
量词在用于匹配字符串时,默认遵循贪婪原则。
贪婪原则是指,尽可能多地匹配字符。
例如:字符串“Function(p),(OK)”,如果使用正则表达式“\(.*\)”进行匹配,则得到字符串“(p),(OK)” ,而非“(p)”;若欲得到“(p)”,则必须取消量词的贪婪原则,此时只需要为量词后追加另外一个数量词“?”即可。
如上面的正则表达式应该改为“\(.*?\)”。
五. 字符转义:元字符在正则表达式中有特殊含义。
如果需要使用其原义,则需要用到字符转义。
字符转义使用字符“\”来实现。
其语法模式为:“\”+元字符。
例如,“\.”表示普通字符“.”;“\.doc”匹配字符串“.doc”;而普通字符“\”需要使用“\\”来表示。
六. 字符组.字符组是指将模式中的某些部分作为一个整体。
这样,量词可以来修饰字符组,从而提高正则表达式的灵活性。
字符组通过()来实现.许多编程语言中,可以利用“$1”、“$2”等来获取第一个、第二个字符组,即所谓的后向引用。
在Oracle中,引用格式为“\1”、“\2”。

近段涉及到了数据的解析,自然离不开对Regular Expressions(正则表达式)的温习;在jdk 官方源码中看到了对《Mastering Regular Expressions, 2nd Edition》的推荐;由Jeffrey E.F. Friedl大师主刀,O'Reilly于2002年再版。
对O'Reilly的书向有好感,像当年误入java的歧途,没看Java编程思想之类的,倒看了O'Reilly的一本影印版《java in a nutshell》,颇留记忆。
正则表达式的“祖先”可以一直上溯至对人类神经系统如何工作的早期研究。
Warren McCulloch 和Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络。
1956 年, 一位叫Stephen Kleene 的数学家在McCulloch 和Pitts 早期工作的基础上,发表了一篇标题为“神经网事件的表示法”的论文,引入了正则表达式的概念。
正则表达式就是用来描述他称为“正则集的代数”的表达式,因此采用“正则表达式”这个术语。
随后,发现可以将这一工作应用于使用Ken Thompson 的计算搜索算法的一些早期研究,Ken Thompson 是Unix 的主要发明人。
正则表达式的第一个实用应用程序就是Unix 中的qed 编辑器。
目前,正则表达式已经在很多软件中得到广泛的应用,包括*nix(Linux, Unix等),HP等操作系统;PHP,Perl,Python,C#,Java等开发环境,以及很多的应用软件中,For Example:网络上的搜索引擎,数据库的全文检索etc...本笔记是是自我学习过程的一个整理,例子或来源于书本,或自己枚举。
好了,废话一箩筐,切入正题。
1.正则表达式的介绍1.1、行开始和结束^begin line。
匹配行开头,如^cat匹配以cat开头的$end line。

正则表达式学习笔记(1)正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
列目录时,dir *.txt或ls *.txt中的*.txt就不是一个正则表达式,因为这里*与正则式的*的含义是不同的。
为便于理解和记忆,先从一些概念入手,所有特殊字符或字符组合有一个总表在后面,最后一些例子供理解相应的概念。
正则表达式是由普通字符(例如字符 a 到z)以及特殊字符(称为元字符)组成的文字模式。
正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
可以通过在一对分隔符之间放入表达式模式的各种组件来构造一个正则表达式,即/expression/普通字符由所有那些未显式指定为元字符的打印和非打印字符组成。
这包括所有的大写和小写字母字符,所有数字,所有标点符号以及一些符号。
非打印字符特殊字符所谓特殊字符,就是一些有特殊含义的字符,如上面说的"*.txt"中的*,简单的说就是表示任何字符串的意思。
如果要查找文件名中有*的文件,则需要对*进行转义,即在其前加一个\。
ls \*.txt。
正则表达式有以下特殊字符。
构造正则表达式的方法和创建数学表达式的方法一样。
也就是用多种元字符与操作符将小的表达式结合在一起来创建更大的表达式。
正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
限定符限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。
有*或+或?或{n}或{n,}或{n,m}共6种。
*、+和?限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
正则表达式的限定符有:定位符用来描述字符串或单词的边界,^和$分别指字符串的开始与结束,\b描述单词的前或后边界,\B表示非单词边界。

正则表达式记忆方法宝子!今天咱来唠唠正则表达式咋记。
正则表达式刚瞅的时候,就像一堆乱码似的,可吓人了。
咱先从那些基本的元字符开始哈。
像那个“.”,你就把它想成是个“小百搭”,它能匹配除了换行符之外的任何单个字符呢。
就好像是一个啥都能接的小助手,特别好记。
还有那个“*”,这就像是个贪心鬼。
它表示前面的字符可以出现零次或者多次。
你就想象它是个小馋猫,能把前面的字符吃好多好多遍,也可以一口都不吃。
比如说“a*”,那就是可以有好多好多的“a”,也可以一个“a”都没有。
“+”这个呢,和“*”有点像,但它至少得出现一次。
就好比是个有点小傲娇的家伙,必须得有,不能没有。
“a+”就是至少有一个“a”。
再来说说那些字符类。
“[]”里面放的就是一群字符,它表示匹配其中的任意一个字符。
你可以把它想象成是个小盒子,里面装着各种小宝贝,只要是盒子里的,都能被选中。
比如说“[abc]”,那就是“a”或者“b”或者“c”都能匹配到。
还有那个“^”,在方括号里面的时候,它就变成了“反着来”的意思。
比如说“[^abc]”,就是除了“a”“b”“c”之外的任何字符。
这就像一个叛逆的小娃娃,专门和里面的字符对着干。
要是说匹配数字呢,“\d”就很好记啦,你就想成是“digit(数字)”的缩写,它就是专门匹配数字的。
那要是想匹配非数字呢,“\D”就闪亮登场啦,它和“\d”就是相反的。
对于字母和数字的组合,“\w”就像是个小收纳盒,它能匹配字母、数字或者下划线。
你就想象它把这些都打包在一起了。
“\W”呢,自然就是和它相反的啦。
宝子,你看这么想的话,正则表达式是不是就没那么可怕啦?其实就把它当成是一群有个性的小卡通人物,每个都有自己独特的本事,记起来就容易多啦。
咱多玩几次,多试几次,慢慢就熟练掌握这个正则表达式的小世界啦。

要想学会正则表达式,理解元字符是一个必须攻克的难关。
不用刻意记.:匹配任何单个字符。
例如正则表达式“b.g”能匹配如下字符串:“big”、“bug”、“bg”,但是不匹配“buug”,“b..g”可以匹配“buug”。
[ ] :匹配括号中的任何一个字符。
例如正则表达式“b[aui]g”匹配bug、big和bag,但是不匹配beg、baug。
可以在括号中使用连字符“-”来指定字符的区间来简化表示,例如正则表达式[0-9]可以匹配任何数字字符,这样正则表达式“a[0-9]c”等价于“a[0123456789]c”就可以匹配“a0c”、“a1c”、“a2c”等字符串;还可以制定多个区间,例如“[A-Za-z]”可以匹配任何大小写字母,“[A-Za-z0-9]”可以匹配任何的大小写字母或者数字。
( ) :将()之间括起来的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域,这个元字符在字符串提取的时候非常有用。
把一些字符表示为一个整体。
改变优先级、定义提取组两个作用。
| :将两个匹配条件进行逻辑“或”运算。
'z|food'能匹配"z"或"food"。
'(z|f)ood'则匹配"zood"或"food"。
*:匹配0至多个在它之前的子表达式,和通配符*没关系。
例如正则表达式“zo*”能匹配“z”、“zo”以及“zoo”;因此“.*”意味着能够匹配任意字符串。
"z(b|c)*"→zb、zbc、zcb、zccc、zbbbccc。
"z(ab)*"能匹配z、zab、zabab(用括号改变优先级)。
+ :匹配前面的子表达式一次或多次,和*对比(0到多次)。
例如正则表达式9+匹配9、99、999等。
“zo+”能匹配“zo”以及“zoo”,不能匹配"z"。

Python学习笔记——正则表达式⼊门# 本⽂对正则知识不做详细解释,仅作⼊门级的正则知识⽬录。
正则表达式的强⼤早有⽿闻,⼤⼀时参加⼀次选拔考试,题⽬就是⽤做个HTML解析器,正则的优势表现得淋漓尽致。
题外话不多讲,直接上⼲货:1. 元字符: 与之对应的还有反义字符,⼤部分为⼩写字母变⼤写,例如\D表⽰匹配⾮数字的字符。
2. 重复(即匹配变长的字符串): 元字符可匹配单⼀的字符类型,若想匹配长度未知或长度限定的字符串需要在后边加上限定符。
3. 范围与分组: 有时元字符并不能满⾜匹配字符的需求,这时就需要[]来圈定匹配范围,例如要匹配⼀个只带有a,s,d,f的单词,可以⽤\b[asdf]\b;正则⾥⾯还有⼩括号⽤来表⽰分组,⽐如你想重复某⼏个字符,就可以使⽤分组,例如(\d.\d){1,3}表⽰匹配⼩括号⾥的重复内容⼀到三次。
此外,⼩括号还可以⽤来后向引⽤等,此处不记。
4. 零宽断⾔: 零宽断⾔主要⽤来查找在某些断⾔(指定内容)之前或之后的内容,例如(?=exp)匹配表达式exp前⾯出现的内容(不匹配exp),(?<=exp)匹配表达式exp后⾯出现的内容,还有负向零宽断⾔等此处不记。
5. 贪婪与懒惰: 当正则表达式中包含能接受重复的限定符时,通常的⾏为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符,即贪婪匹配。
如表达式a.*b,搜索aabab的话,它会匹配整个字符串aabab。
⽽懒惰匹配会匹配尽可能少的字符串,只需要在限定符后⾯加⼀个?,例如a.*?b会匹配aab(第⼀到第三个字符)和ab(第四到第五个字符)。
6. Python的re模块: python 提供re模块,提供正则的所有功能。
下⾯只记两个⽅法和⼀个注意的地⽅。
6.1 match⽅法: match()⽅法判断是否匹配,如果匹配成功,返回⼀个Match对象,否则返回None。
1 >>> import re2 >>> re.match(r'^\d{3}\-\d{3,8}$', '010-12345')3 <_sre.SRE_Match object at 0x1026e18b8>4 >>> re.match(r'^\d{3}\-\d{3,8}$', '010 12345')5 >>> 如果正则表达式中定义了组,就可以在Match对象上⽤group()⽅法提取出⼦串来。

正则表达式(Regularexpressions)使⽤笔记Regular expressions are a powerful language for matching text patterns. This page gives a basic introduction to regularexpressions themselves sufficient for our Python exercises and shows how regular expressions work in Python. ThePython "re" module provides regular expression support.In Python a regular expression search is typically written as:match = re.search(pat, str)The re.search() method takes a regular expression pattern and a string and searches for that pattern within the string. Ifthe search is successful, search() returns a match object or None otherwise. Therefore, the search is usually immediatelyfollowed by an if-statement to test if the search succeeded, as shown in the following example which searches for thepattern 'word:' followed by a 3 letter word (details below):str = 'an example word:cat!!'match = re.search(r'word:\w\w\w', str)# If-statement after search() tests if it succeededif match:print 'found', match.group() ## 'found word:cat'else:print 'did not find'The code match = re.search(pat, str) stores the search result in a variable named "match". Then the if-statement tests thematch -- if true the search succeeded and match.group() is the matching text (e.g. 'word:cat'). Otherwise if the match isfalse (None to be more specific), then the search did not succeed, and there is no matching text.The 'r' at the start of the pattern string designates a python "raw" string which passes through backslashes withoutchange which is very handy for regular expressions (Java needs this feature badly!). I recommend that you always writepattern strings with the 'r' just as a habit.Note: match.group() returns a string of matched expression(type:str)Basic PatternsThe power of regular expressions is that they can specify patterns, not just fixed characters. Here are the most basicpatterns which match single chars:a, X, 9, < -- ordinary characters just match themselves exactly. The meta-characters which do not match themselves because they have special meanings are: . ^ $ * + ? { [ ] \ | (). (a period) -- matches any single character except newline '\n'\w -- (lowercase w) matches a "word" character: a letter or digit or underbar [a-zA-Z0-9_]. Note that although "word" is the mnemonic for this, it only matches a single word char, not a whole word. \W (upper case W) matches any non-word character.\b -- boundary between word and non-word\s -- (lowercase s) matches a single whitespace character -- space, newline, return, tab, form [ \n\r\t\f]. \S (upper case S) matches any non-whitespace character.\t, \n, \r -- tab, newline, return\d -- decimal digit [0-9]^ = start, $ = end -- match the start or end of the string\ -- inhibit the "specialness" of a character. So, for example, use \. to match a period or \\ to match a slash. If you are unsure if a character has special meaning, such as '@', you can put a slash in front of it, @, to make sure it is treated just as a character.Basic FeaturesThe basic rules of regular expression search for a pattern within a string are:The search proceeds through the string from start to end, stopping at the first match foundAll of the pattern must be matched, but not all of the stringIf match = re.search(pat, str) is successful, match is not None and in particular match.group() is the matching text RepetitionThings get more interesting when you use + and * to specify repetition in the pattern+ -- 1 or more occurrences of the pattern to its left, e.g. 'i+' = one or more i's'*' -- 0 or more occurrences of the pattern to its left? -- match 0 or 1 occurrences of the pattern to its leftLeftmost & LargestFirst the search finds the leftmost match for the pattern, and second it tries to use up as much of the string as possible --i.e. + and * go as far as possible (the + and * are said to be "greedy").## i+ = one or more i's, as many as possible.match = re.search(r'pi+', 'piiig') => found, match.group() == "piii"## Finds the first/leftmost solution, and within it drives the +## as far as possible (aka 'leftmost and largest').## In this example, note that it does not get to the second set of i's.match = re.search(r'i+', 'piigiiii') => found, match.group() == "ii"## \s* = zero or more whitespace chars## Here look for 3 digits, possibly separated by whitespace.match = re.search(r'\d\s*\d\s*\d', 'xx1 2 3xx') => found, match.group() == "1 2 3"match = re.search(r'\d\s*\d\s*\d', 'xx12 3xx') => found, match.group() == "12 3"match = re.search(r'\d\s*\d\s*\d', 'xx123xx') => found, match.group() == "123"## ^ = matches the start of string, so this fails:match = re.search(r'^b\w+', 'foobar') => not found, match == None## but without the ^ it succeeds:match = re.search(r'b\w+', 'foobar') => found, match.group() == "bar"Emails ExampleSuppose you want to find the email address inside the string 'xyz alice-b@ purple monkey'. We'll use this as a running example to demonstrate more regular expression features. Here's an attempt using the pattern r'\w+@\w+':str = 'purple alice-b@ monkey dishwasher'match = re.search(r'\w+@\w+', str)if match:print match.group() ## 'b@google'The search does not get the whole email address in this case because the \w does not match the '-' or '.' in the address. We'll fix this using the regular expression features below.Square BracketsSquare brackets can be used to indicate a set of chars, so [abc] matches 'a' or 'b' or 'c'. The codes \w, \s etc. work insidesquare brackets too with the one exception that dot (.) just means a literal dot. For the emails problem, the square brackets are an easy way to add '.' and '-' to the set of chars which can appear around the @ with the pattern r'[\w.-]+@[\w.-]+' to get the whole email address:match = re.search(r'[\w.-]+@[\w.-]+', str)if match:print match.group() ## 'alice-b@'You can also use a dash to indicate a range, so1. [a-z] matches all lowercase letters.2. To use a dash without indicating a range, put the dash last, e.g. [abc-].3. An up-hat (^) at the start of a square-bracket set inverts it, so [^ab] means any char except 'a' or 'b'.Group ExtractionThe "group" feature of a regular expression allows you to pick out parts of the matching text. Suppose for the emails problem that we want to extract the username and host separately. To do this, add parenthesis ( ) around the username and host in the pattern, like this: r'([\w.-]+)@([\w.-]+)'. In this case, the parenthesis do not change what the pattern will match, instead they establish logical "groups" inside of the match text. On a successful search, match.group(1) is the match text corresponding to the 1st left parenthesis, and match.group(2) is the text corresponding to the 2nd left parenthesis. The plain match.group() is still the whole match text as usual.str = 'purple alice-b@ monkey dishwasher'match = re.search('([\w.-]+)@([\w.-]+)', str)if match:print match.group() ## 'alice-b@' (the whole match)print match.group(1) ## 'alice-b' (the username, group 1)print match.group(2) ## '' (the host, group 2)A common workflow(⼯作流程) with regular expressions is that you write a pattern for the thing you are looking for, adding parenthesis groups to extract the parts you want.Note: match.group(1) is the match text corresponding to the 1st left parenthesis, and match.group(2) is the text corresponding to the 2nd left parenthesisfindallfindall() is probably the single most powerful function in the re module. Above we used re.search() to find the first match for a pattern. findall() finds all the matches and returns them as a list of strings(list), with each string representing one match.## Suppose we have a text with many email addressesstr = 'purple alice@, blah monkey bob@ blah dishwasher'## Here re.findall() returns a list of all the found email stringsemails = re.findall(r'[\w\.-]+@[\w\.-]+', str) ## ['alice@', 'bob@']for email in emails:# do something with each found email stringprint emailfindall With FilesFor files, you may be in the habit of writing a loop to iterate over the lines of the file, and you could then call findall() on each line. Instead, let findall() do the iteration for you -- much better! Just feed the whole file text into findall() and let it return a list of all the matches in a single step (recall that f.read() returns the whole text of a file in a single string):# Open filef = open('test.txt', 'r')# Feed the file text into findall(); it returns a list of all the found stringsstrings = re.findall(r'some pattern', f.read())findall and GroupsThe parenthesis ( ) group mechanism can be combined with findall(). If the pattern includes 2 or more parenthesis groups, then instead of returning a list of strings, findall() returns a list of tuples. Each tuple represents one match of the pattern, and inside the tuple is the group(1), group(2) .. data. So if 2 parenthesis groups are added to the email pattern, then findall() returns a list of tuples, each length 2 containing the username and host, e.g. ('alice', '').str = 'purple alice@, blah monkey bob@ blah dishwasher'tuples = re.findall(r'([\w\.-]+)@([\w\.-]+)', str)print tuples ## [('alice', ''), ('bob', '')]for tuple in tuples:print tuple[0] ## usernameprint tuple[1] ## hostOnce you have the list of tuples, you can loop over it to do some computation for each tuple. If the pattern includes no parenthesis, then findall() returns a list of found strings as in earlier examples. If the pattern includes a single set of parenthesis, then findall() returns a list of strings corresponding to that single group.Obscure optional feature:Sometimes you have paren ( ) groupings in the pattern, but which you do not want to extract. In that case, write the parens with a ?: at the start, e.g. (?: ) and that left paren will not count as a group result.Reference:1.2.Thanks!<完>。
正则表达式概要笔记个人学习时记下的笔记,包含主要的正则表达式语法,适合正则表达学习和复习,有需要的下载下。
//---正则表达式界定符,声明正则表达式的边界,正则表达式写在边界之中。
\ ---转义字符,如果要匹配的正则表达中有对和关键字相同的字符进行转义[]---匹配括号中任何一个字符,和逻辑运算符“或”相似(括号中只能写原子或原子的集合),可以使用‘|’‘-’如运算符[a-z|A-Z]表示匹配任意一个英文字母,如[a-z0-9]表示匹配任意一个英文字母或数字。
|----匹配两个或多个分支选择,两边必须是连续的多个原子,两边连续的子串做整体匹配[^]--匹配方括号中原子之外的任意原子,和[]互逆;^必须放最左边;原子-正则表达式最小匹配单位,Unicode编码的最小单位,有可见原子和不可见原子(空格'',换行'\r',tab'\t',回车'\n'为不可见原子)原子集合--------------------------------------------------------------.----匹配换行符之外的任意字符\d---匹配任意一个十进制数字\D---匹配任意一个非十进制数字,与\d互补\s---匹配一个不可见原子\S---匹配一个可见原子\w---匹配任意一个数字字母下划线\W---匹配任意一个非数字字母下划线;量词----------------------------------------------------------------------可以匹配原子和原子集合{n}--前面元素匹配n次{n,m}匹配最少n次,最多m次{n,}-前面最少出现n次*----匹配0,1,或多次+----最少出现一次?---匹配0,1次边界控制--------------------------------------------------------------^----匹配字符串开始的位置$----匹配字符串结尾的位置模式单元----------------------------------------------------()-匹配其中的整体作为一个原子修正模式--------------------------------------------------------------/末尾加模式修正标志,默认是贪婪模式;多模式可以并写;U----懒惰模式i----忽略英文大小写x----忽略空白,包括制表符,tab等s----让元字符.匹配包括换行符在内所有字符。
正则表达式笔记
正则表达式是一种用于匹配和处理文本的工具,它可以用来搜索、替换和提取文本信息。
在编程和数据处理中,正则表达式是非常重要的工具之一。
正则表达式由一系列字符和操作符组成,用于描述文本模式。
例如,字符串“hello”可以用正则表达式“h.*o”来匹配。
这个正则
表达式中的“.*”表示可以匹配任意字符。
正则表达式在不同的编程语言中都有支持,常用的语言有Python、Java、JavaScript等。
在使用正则表达式时,需要注意一些常见的
操作符和语法规则。
一些常见的操作符包括“*”、“+”、“.”、“^”、“$”等。
其中,“*”表示匹配0个或多个前面的字符,“+”表示匹配1个或多个前
面的字符,“.”表示匹配任意一个字符,“^”表示匹配行首,“$”表示匹配行尾。
使用正则表达式时,还需要注意一些语法规则。
例如,可以使用“[]”表示一个字符集合,使用“”来转义特殊字符,使用“()”表示一个子表达式等。
正则表达式在文本处理中有很多应用,例如搜索、替换、提取等。
在实际应用中,需要根据具体的需求来选择合适的正则表达式。
总之,正则表达式是一种非常强大的工具,可以帮助我们更方便地处理文本数据。
学习并掌握正则表达式是程序开发和数据处理中的必备技能之一。
zabbix笔记正则表达式
⽬录
⼀.正则表达式(Regx)
概述
在zabbix中,正则表达式经常使⽤的地⽅应该就是LLD,⽐如,你发现的⽹卡或磁盘有⼀⼤堆,但是有⼀些不是你想要的。
⽐较典型的⽐如lo(回环地址),VLAN、Tunnel、InLoopBack0、NULL0等交换机⽹⼝,这时,你就可以通过正则表达式进⾏过滤掉。
配置
1.点击基础配置
2.选择正则表达式
3.新建正则表达式
4.测试
正则表达式写好以后,可以直接在线进⾏测试。
例⼦:交换机接⼝过滤掉不需要的端⼝
例⼦:磁盘⾃动发现时过滤盘符
磁盘⾃动发现时,我只需要hda|hdb|sda|sdb|sdc|sdd|sde|sdf|sdg|sdh|xvda|xvdb|vda|vdb|vdc|cciss/c0d0p[1-9] 这些开头的盘符。
例⼦:mysql屏蔽端⼝
⽐如在mysql多实例发现的过程中,我⽤3308来进⾏测试,⽽3306和3307则为线上正常使⽤的实例,这时,我就可以屏蔽3308实例就⾏。
操作如下:
1.写正则
2.在Host上应⽤
注意:引⽤正则表达式的时候,需要使⽤ @ + 正则表达式名。
三.表达式类型
1.字符串已包含(Character string included) - 匹配⼦字符串
2.字符串未包含(Character string not included) - 匹配除了⼦字符串之外的任何字符串
3.结果为真(Result is TRUE) - 匹配正则表达式
4.结果为假(Result is FALSE) - 不匹配正则表达式。
正则表达式学习笔记——常⽤的20个正则表达式校验1 . 校验密码强度密码的强度必须是包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间。
/^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$/2. 校验中⽂字符串仅能是中⽂。
/^[\\u4e00-\\u9fa5]{0,}$/3. 由数字、26个英⽂字母或下划线组成的字符串/^\\w+$/4. 校验E-Mail 地址同密码⼀样,下⾯是E-mail地址合规性的正则检查语句。
/[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?/5. 校验⾝份证号码下⾯是⾝份证号码的正则校验。
15 或 18位。
15位:/^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$/18位:/^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$/6. 校验⽇期“yyyy-mm-dd“格式的⽇期校验,已考虑平闰年。
/^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468] [048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$/7. 校验⾦额⾦额校验,精确到2位⼩数。
/^[0-9]+(.[0-9]{2})?$/8. 校验⼿机号下⾯是国内 13、15、18开头的⼿机号正则表达式。
思源笔记是一种常见的笔记软件,支持多种文本处理功能,其中正则表达式是一种强大的文本匹配和处理工具。
在思源笔记中,你可以使用正则表达式来查找、替换、提取等操作文本。
以下是一些常见的正则表达式语法和示例,可以帮助你在思源笔记中进行文本处理:
1. 查找文本:
* 查找单个字符:`a` 查找字母“a”
* 查找多个字符:`ab` 查找字母“a”后跟字母“b”
* 查找数字:`\d` 查找数字字符
* 查找任意字符:`.` 查找除换行符之外的任意字符
2. 替换文本:
* 替换单个字符:`a -> b` 将所有字母“a”替换为字母“b”
* 替换多个字符:`ab -> xy` 将所有字母“a”后跟字母“b”替换为字母“x”后跟字母“y”
* 替换特定模式:`(\d) -> \1` 将所有数字字符替换为其前面匹配到的内容(例如,将“123”替换为“123”前面匹配到的内容)
3. 提取文本:
* 提取单行文本:`^匹配内容$` 提取以匹配内容开头和结尾的行
* 提取多行文本:`^匹配行开始内容.*^匹配行结束内容` 提取以匹配行开始内容和匹配行结束内容分隔的文本块
* 提取数字:`\d+` 提取一个或多个数字字符
* 提取特定模式:`(\d)(\d)(\d)` 提取一个以三个数字字符组成的模式(例如,提取“123”)
以上只是正则表达式的一些基本语法和示例,你可以根据具体需求进行更复杂的文本处理操作。
请注意,具体的语法和功能可能因软件版本和平台而有所不同,建议查阅思源笔记的官方文档或使用在线正则表达式测试工具进行学习和验证。
正则表达式知识总结正则表达式知识总结一简单举例认识正则表达式1名词解释:正则表达式就是用于描述这些规则的工具,即记录文本规则的代码注意事项:处理正则表达式的工具会提供一个忽略大小写的选项eg:\bhi\b解释:\b是正则表达式规定的一个特殊代码,为元字符(metacharacter),代表单词的开头或结尾,为分界处,是一个位置的分界点eg:查找hi后不远处一个lucy,写法为:\bhi\b.*\blucy\beg:"."为元字符,匹配不换行的任意字符。
"*"为元字符,代表不是字符,也不是位置,而是数量---是指*前面的内容可以连续重复的使用任意次数已使整个表达式得到匹配。
*连在一起,意味着任意数量的不包含换行的字符,eg:0\d\d-\d\d\d\d\d\d\d\d解释:以0开头,然后是两个数字,中间位一个连字符"-",最后为8个数字简写为:0\d{2}-\d{8}表示连续重复多少次;\s 匹配任意的空白符包括空格,制表符(tab)换行符中文全角空格\w匹配字母或数字或下划线或汉字等eg:\ba\w*\b解释:已字母(\b)a开头的单词。
然后是(\w*)任意的字母,数字,下划线,最后为单词的结束处eg:\d+解释:匹配一个或更多连续的数字。
这里的+与*是类似的元字符,不同点:+匹配一个或更多连续的数字;*匹配任意的次数。
eg:\b\w{6}\b解释:匹配6个字符的单词^匹配字符串的开始$匹配字符串的结束,这两个元字符在验证输入的内容时非常有用eg:要求输入5到12个数字:^{5,12}$注意事项:政策表达式的处理工具还有个处理多行的选项二字符转义,特指"\"如果要查元字符本身,就必须使用转义符例如:\\,\*,\$等eg:c:\\windows解释:匹配的是c:\windowseg:deerchao\.net解释:匹配的是/doc/995920093.html,三重复匹配重复方式有:* + {5} {2,12}{1,}二测试正则表达式(.Net Framework4.0)/doc/995920093.html,/tools/zhengze. html/^-?:\d+|\d{1,3}(?:,\d{3})+)(?:\.\d+)?$/^匹配字符串开头匹配减号,问号表示减号是可选的,可以没有\d+匹配任意位的数字| 表示‘或’关系\d{1,3} 匹配1-3位数字:,\d{3})+ 匹配一个逗号加一个3位数字,+号表示可以重复多个:\.\d+)?匹配一个小数点和多位数字$匹配结尾综合起来,这个正则表达式用于匹配数字可以是整数,也可以是小数12345和12345.6789都可以可以是负数也可以是正数-12345和-12345.6789也行整数部分还可以有逗号做分割符12,345,678,901.123456也可以匹配当然-12,345,678,901.123456也可以等价:等价是等同于的意思,表示同样的功能,用不同符号来书写。