蛋白质三级结构预测
- 格式:ppt
- 大小:1.33 MB
- 文档页数:21

蛋白质结构与功能预测蛋白质是生命活动的主要承担者,它们在细胞内执行着各种各样的功能,从催化化学反应到运输物质、传递信号,再到构成细胞结构等等。
要深入理解蛋白质的工作机制以及在生物过程中的作用,对其结构和功能的预测至关重要。
蛋白质的结构决定了其功能。
简单来说,蛋白质的结构就像是一个精心设计的机器,每个部件的形状和位置都对其整体的运行效果有着关键影响。
蛋白质的结构可以分为四个层次:一级结构、二级结构、三级结构和四级结构。
一级结构指的是蛋白质中氨基酸的线性排列顺序。
这就像是一串珠子按照特定的顺序串起来。
不同的氨基酸排列顺序决定了蛋白质后续可能形成的结构和功能。
二级结构则是在局部区域内形成的有规律的结构,比如常见的α螺旋和β折叠。
想象一下,这就像是把绳子折成特定的形状。
三级结构是整个蛋白质的三维空间构象,是由二级结构进一步折叠、盘绕形成的。
这时候,蛋白质就像是一个复杂的立体雕塑,各个部分相互作用,共同决定了其功能。
四级结构是指多个具有独立三级结构的多肽链通过非共价键相互结合形成的更复杂的结构。
那么,如何预测蛋白质的结构呢?传统的方法主要基于物理化学原理和实验技术。
例如,X 射线晶体学可以提供非常高分辨率的蛋白质结构信息,但这个方法需要获得高质量的蛋白质晶体,这往往是一个具有挑战性的步骤。
另一种常用的技术是核磁共振(NMR)光谱学,它能够在溶液状态下研究蛋白质的结构,但对于大分子量的蛋白质,其应用受到一定限制。
随着计算机技术和生物信息学的发展,基于理论计算的方法在蛋白质结构预测中发挥着越来越重要的作用。
这些方法大致可以分为同源建模、从头预测和折叠识别等。
同源建模是利用已知结构的同源蛋白质作为模板来构建目标蛋白质的结构模型。
这就好比如果我们知道了某个类似的“机器”是怎么构造的,就可以以此为参考来推测新“机器”的构造。
但这种方法的前提是要有与目标蛋白质高度相似且结构已知的同源蛋白。
从头预测则是在没有已知结构模板的情况下,完全基于物理化学原理和能量最小化原则来预测蛋白质的三维结构。

(一)摘要:利用Discover Stuido所提供的蛋白質三級結構預測之同源模擬(Homology Modeling)的方法,可以很快速及有效率的獲得離子通道蛋白之三維結構,再深入探討分析其結構所提供的資料,進一步了解離子通道蛋白的功能,可用來指引生物實驗,例如site - directed mutagenesis、rational drug design 和protein - protein interaction 等等。
模擬之後的結構再透過Discover Stuido所提供之LigandFit、LibDock 以及CDOCKER等計算方法,進行藥物與通道蛋白的對接,再經過Discover Stuido生物軟體計算預測藥物可能在通道上可能的結合位置以及可能相互作用的關鍵胺基酸。
(二)研究動機:細胞膜上的離子通道是所有生命體的基本要件,很多疾病,例如一些神經系統疾病和心血管疾病就是由於細胞上的離子通道功能發生紊亂或蛋白結構的缺陷所造成。
例如本實驗室研究項目之ㄧ的離子通道「NMDA受器」,在哺乳類動物中樞神經系統中扮演重要角色,從興奮性突觸的訊息傳遞、突觸的可塑性、到學習與記憶的整合此通道受器都參予其中,許多神經性疾病如急性腦中風或慢性的阿茲海默症、帕金森氏症、精神分裂症、癲癇等等都認為和NMDA受器有關,因此增加對它們的認識是幫助了解許多疾病狀態的重要基礎,目前許多離子通道已成為製藥界開發新藥的目標,離子通道的研究還有非常大的潛力和應用空間。
由於生物資訊近幾年來發展迅速,尤其基因體計劃的進行更增加了資料庫中的數量,包括核酸、蛋白質及結構等資料庫。
一般說來,蛋白質三維結構主要以實驗方法來決定,例如X-射線繞射法或NMR光譜法。
事實上,技術上的困難使得蛋白質三維結構決定的速度相當地緩慢,因此發展出利用電腦並依據蛋白質的序列來預測其三級結構的方法。
這些方法包含以物理化學原理的ab-initio methods 及以資料庫提供的序列和結構知識衍生的蛋白質摺疊認識fold- recognition methods(亦稱threading 穿針引線法),和同源模擬法(homology modeling)。

蛋白质三级结构的预测和分析方法蛋白质是由氨基酸组成的多肽链,是生命体中重要的组成部分。
蛋白质的功能由其三级结构决定,因此蛋白质三级结构的预测和分析是生物学研究的重要课题之一。
本文将介绍蛋白质三级结构的预测和分析方法。
一、蛋白质序列的预测蛋白质的三级结构是由其氨基酸序列决定的,因此蛋白质序列的预测是蛋白质三级结构预测的第一步。
蛋白质序列的预测分为两种方法:直接预测和间接预测。
直接预测方法是通过实验手段对蛋白质进行测定,并得到其序列。
其中,蛋白质测序是最常用的方法之一,目前已经非常成熟,在实验过程中准确率很高。
但是该方法耗时长、成本高,适用性窄。
间接预测方法则基于蛋白质序列的相似性进行预测,即通过基因组学、区域同源性、数据库、机器学习算法等,对已知的蛋白质序列进行比对和分析,得出未知蛋白质的序列。
其中,BLAST、PSI-BLAST等比对方法,能够在较短时间内对蛋白质序列进行预测,并在很大程度上提高了预测准确率。
此外,还有一些基于机器学习算法的预测方法,如SVM和神经网络方法等。
二、蛋白质结构预测蛋白质结构预测是指通过已知的蛋白质序列,预测出其原子级别的三维结构。
蛋白质结构预测目前主要分为三种方法:实验法、遗传算法和分子动力学模拟法。
实验法主要是通过分析蛋白质结晶体、核磁共振法和质谱分析等实验手段来预测蛋白质的空间结构。
这种方法具有实验数据来源充足、准确性高等特点,但是往往耗时长且成本高昂。
遗传算法是利用生物进化过程的基本原理,在计算机模拟中模拟蛋白质分子构象变化的过程,最终找到能够形成最稳定结构的构象。
这种方法通过逐代优化,逐渐提高预测蛋白质结构的准确度,但是也存在时间复杂度高、无法解释性和结果可重复性差等问题。
分子动力学模拟法是运用牛顿力学原理和一些计算模型,对蛋白质分子的运动进行数值模拟,从而得到蛋白质的三维结构。
这种方法的优点在于可以对蛋白质分子动力学过程进行模拟,具有可重复性高、得出结果的信息较多等特点,但是计算时间较长,计算机模拟结果的可信度也需要进一步验证。


蛋白质结构预测Protein Structure PredictionHaibo SunDepartment of BioinformaticsMininGene BiotechnologyG h lMarch 22, 2007背景结构分类:z一级结构也就是组成蛋白质的氨基酸序列z二级结构即骨架原子间的相互作用形成的局部结构,比如alpha螺旋,beta片层和loop区等l h b t lz三级结构即二级结构在更大范围内的堆积形成的空间结构z四级结构主要描述不同亚基之间的相互作用。
结构测定的实验方法z核磁共振z X光晶体衍射两种。
一级结构级结构预测基础预测基础:z 实验:在体外无任何其他物质存在的条件下,使得蛋白质去折叠,然后复性,蛋白质将立刻重新折叠回原来的空间结构z 物理学的角度讲,系统的稳定状态通常是能量最小的状态二级结构反向β-折叠α-螺旋β-转角三级结构Turn or coilAlpha-helix Beta-sheetLoop and Turn蛋白质结构预测•Sequence secondary structure 3D structure Sequence →secondary structure →3D structure →functionProtein Structure PredictionProtein Structure Prediction •Prediction is possible because–Sequence information uniquely determines 3D structure–Sequence similarity (>50%) tends to imply structuralsimilarity•Prediction is necessary because–DNA sequence data »protein sequence data »structuredata199419972002.102007.3 Sequence (Swiss Port)40,00068,000114,033261,513 Sequence(Swiss-Port)4000068000114033261513 Structure (PDB)4,0457,00018,83842,474Methods预测方法Comparative (homology) modeling (同源建模法) Construct 3D model from alignment to proteinithsequences withknown structureg(g)(折识别法)Threading (fold recognition) (折叠识别法Pick best fit to sequences of known 2D / 3D structures (folds)Ab initio / de novo methods (从头预测法)Ab initio/de novo methods(Methods(1)同源性(Homology)方法:理论依据:如果两个蛋白质的序列比较相似,则其结构理论依据如果两个蛋白质的序列比较相似则其结构也有很大可能比较相似。

蛋白质三维结构预测及其功能鉴定蛋白质是生命的基本组成部分,具有多种生物学功能,如催化酶、结构蛋白、运输蛋白等。
了解蛋白质的结构和功能对于理解生命活动和研究相关疾病具有重要意义。
然而,实验方法获得蛋白质的三维结构所需的时间和资源较多,因此发展一种高效的蛋白质结构预测方法变得尤为重要。
蛋白质的结构主要由其氨基酸序列决定,即一维的氨基酸序列通过折叠作用形成其三维结构。
蛋白质折叠过程包括形成二级结构(α-螺旋、β-折叠)、三级结构(折叠成具有特定空间构象的形状)和四级结构(多个蛋白质相互作用形成的复合物)。
蛋白质预测的关键是预测其三级结构。
蛋白质三维结构预测有两种主要方法:实验方法和计算模型。
实验方法包括X射线晶体学、核磁共振和电子显微镜等,它们能够直接测定蛋白质的结构,但需要昂贵的设备和大量的时间。
相反,计算模型通过计算机算法估计蛋白质的结构,是一种高效的方式。
计算模型可以分为抽象建模和模拟折叠两种方法。
抽象建模方法根据已知的蛋白质结构去预测新蛋白质的结构,其中常用的方法是比对和比较。
比对方法根据已知的蛋白质结构和氨基酸序列的相似度进行预测。
比较方法则通过比较待测蛋白质的氨基酸序列与已知蛋白质结构数据库中的序列进行预测。
而模拟折叠方法则根据物理原理模拟蛋白质的折叠过程。
这些方法使用力场、动力学模拟和蒙特卡洛方法等来模拟蛋白质分子的运动和相互作用。
然而,模拟折叠方法仍然有许多挑战,例如计算复杂度高、时间和空间的限制以及准确性的限制。
在预测蛋白质结构的同时,功能鉴定也是重要的。
蛋白质的结构决定其功能,因此通过预测结构可以间接预测蛋白质的功能。
功能鉴定可以通过计算方法、结构比对和基因敲除等实验方法来实现。
计算方法利用统计学和模式识别来鉴定蛋白质的功能,例如通过分析氨基酸序列中的保守区域和功能域来预测。
结构比对方法则通过比较目标蛋白质的结构与已知功能蛋白质的结构相似性来预测功能。
基因敲除实验方法则通过对目标蛋白质基因进行敲除,观察蛋白质缺失后生物体的表型变化,从而推测其功能。

蛋白质结构预测和分子对接技术蛋白质是构成生物体的基础分子之一,包括酶、激素、抗体等各种生物大分子都是由蛋白质组成。
蛋白质具有多个级别的结构,通常被称为一级、二级、三级和四级结构。
一级结构指的是蛋白质的氨基酸序列,即在蛋白质分子中氨基酸的排列方式。
二级结构是指蛋白质中氨基酸残基在空间中的排列方式,通常包括α-螺旋和β-折叠。
三级结构是指蛋白质空间构型的整体结构。
四级结构则指蛋白质分子与其他蛋白质小分子之间的相互作用。
在蛋白质结构预测方面,具有重要意义的方法是基于比对的方法和基于物理学原理的方法。
基于比对的方法是通过对已知结构的蛋白质序列和目标蛋白质的序列进行比对,找出最接近的已知结构,并将该结构作为目标的预测结果。
这种方法的优点是速度快,但是预测精度较低。
基于物理学原理的方法则是通过模拟蛋白质分子内部的物理过程来得出蛋白质的结构,其精度比基于比对的方法更高,但计算量也更大。
在分子对接技术方面,分子对接技术是指通过计算机模拟来研究分子之间的相互作用,常用于新药研发和分子设计中。
目前常用的分子对接技术包括基于体积网格方法、基于可调节作用位点的对接方法和基于分子动力学模拟的方法。
基于体积网格方法通过将药物分子和蛋白质分子放置在一个三维空间网格中,以模拟药物分子与蛋白质分子之间的相互作用。
这种方法的优点是计算速度快,但往往忽略了蛋白质分子的柔性,导致预测结果可能不够准确。
基于可调节作用位点的对接方法则考虑到了蛋白质的柔性,将蛋白质的某些部分设定为可调节的作用位点,使得蛋白质可以自由地移动。
这种方法的优点是准确性比基于体积网格的方法更高。
基于分子动力学模拟的方法则是将蛋白质和药物分子看作一个整体,通过模拟它们的运动、相互作用等来研究它们的相互作用。
这种方法的优点是可以考虑到分子的柔性和运动过程,因此预测结果更加准确。
但是,这种方法的计算量也更大,需要使用超级计算机等大规模计算设备。
尽管蛋白质结构预测和分子对接技术现在已经取得了不少进展,但仍然存在许多问题和挑战。

SWISS-MODEL 蛋白质结构预测SWISS-MODEL是一项预测蛋白质三级结构的服务,它利用同源建模的方法实现对一段未知序列的三级结构的预测。
该服务创建于1993年,开创了自动建模的先河,并且它是讫今为止应用最广泛的免费服务之一。
同源建模法预测蛋白质三级结构一般由四步完成:1.从待测蛋白质序列出发,搜索蛋白质结构数据库(如PDB,SWISS-PROT等),得到许多相似序列(同源序列),选定其中一个(或几个)作为待测蛋白质序列的模板;2.待测蛋白质序列与选定的模板进行再次比对,插入各种可能的空位使两者的保守位置尽量对齐;3.建模:调整待测蛋白序列中主链各个原子的位置,产生与模板相同或相似的空间结构——待测蛋白质空间结构模型;4.利用能量最小化原理,使待测蛋白质侧链基团处于能量最小的位置。
最后提供给用户的是经过如上四步(或重复其中某几步)后得到的蛋白质三级结构。
SWISS-MODEL工作模式SWISS-MODEL服务器是以用户输入信息的最小化为目的设计的,即在最简单的情况下,用户仅提供一条目标蛋白的氨基酸序列。
由于比较建模程序可以具有不同的复杂性,用户输入一些额外信息对建模程序的运行有时是有必要的,比如,选择不同的模板或者调整目标模板序列比对。
该服务主要有以下三种方式:First Approach mode(简捷模式):这种模式提供一个简捷的用户介面:用户只需要输入一条氨基酸序列,服务器就会自动选择合适的模板。
或者,用户也可以自己指定模板(最多5条),这些模板可以来自ExPDB模板数据库(也可以是用户选择的含坐标参数的模板文件)。
如果一条模板与提交的目标序列相似度大于25%,建模程序就会自动开始运行。
但是,模板的可靠性会随着模板与目标序列之间的相似度的降低而降低,如果相似度不到50%往往就需要用手工来调整序列比对。
这种模式只能进行大于25个残基的单链蛋白三维结构预测。
∙Alignment Interface(比对界面):这种模式要求用户提供两条已经比对好的序列,并指定哪一条是目标序列,哪一条是模板序列(模板序列应该对应于ExPDB模板数据库中一条已经知道其空间结构的蛋白序列)。
《生物信息学》第五章:蛋白质结构预测与分析(第二部分) 计算方法预测三级结构:同源建模法SWISS-MODEL预测蛋白质三级结构的首选方法是同源建模法(homolog modeling)。
该方法基于原理:相似的氨基酸序列对应着相似的蛋白质结构。
比如三个蛋白质,它们在序列水平上十分相似,解析出的结构也十分相似。
第四个蛋白质的序列和前面三个也高度相似,那么就可以比着前三个结构的样子“画”出第四个的样子。
所以同源建模法的关键就是找到一个好的模板。
好的模板要求,在序列水平上模板(template)要与目标(target)蛋白质具有超过30%的一致度。
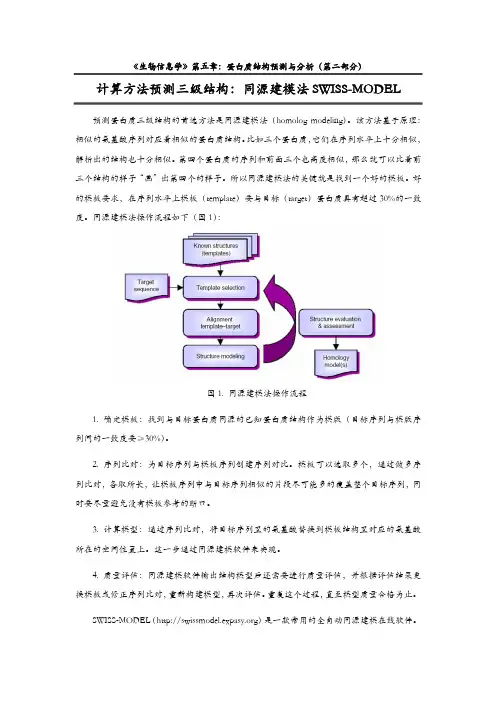
同源建模法操作流程如下(图1):图1. 同源建模法操作流程1. 确定模板:找到与目标蛋白质同源的已知蛋白质结构作为模版(目标序列与模版序列间的一致度要≥30%)。
2. 序列比对:为目标序列与模板序列创建序列对比。
模板可以选取多个,通过做多序列比对,各取所长,让模板序列中与目标序列相似的片段尽可能多的覆盖整个目标序列,同时要尽量避免没有模板参考的断口。
3. 计算模型:通过序列比对,将目标序列里的氨基酸替换到模板结构里对应的氨基酸所在的空间位置上。
这一步通过同源建模软件来实现。
4.换模板或修正序列比对,重新构建模型,再次评估。
SWISS-MODEL()它能帮助完成上述步骤中从模板选取到创建序列比对,再到计算模型,以及最后的质量评估的全部过程。
你需要做的只是:输入目标序列,点Build Model(创建模型)(图2左)。
大约三到五分钟之后就会返回结果。
如果这种自动挡模式不能满足你的要求,可以通过点击Search For Templates切换成手动挡,以便指定模板。
也可以直接把做好的目标序列与模板序列之间的序列比对按照指定格式黏贴到输入框里,再点击Build Model(创建模型)(图2右)。
这时,SWISS-MODEL会根据输入的特定格式的序列比对,识别出哪个是目标序列,哪个是模板,并自动从PDB数据库下载模板结构,最后根据输入的比对计算结构模型。
利用同源建模预测蛋白质的三级结构首先声明一下,以下纯属个人观点,方法步骤仅供参考,不可作为规范标准,结果出来之后请自行分析结果。
我用的是SWISS-MODEL同源建模的方法进行的蛋白质高级结构预测,其实这个方法是有限制条件的,不过作为一个选修课作业,我们不用深入探究,所以有时不够严谨,大家知道就行!对于一个未知结构的蛋白质,白质建立结构模型。
那么,我们首先要做的就是找到和我们空格和“—”的氨基酸序列,例如:【字母大小写没有影响】vlqdsigyirilsmmdpvvdefdrayqqvkdfpdlmvdvrengggnsgngkkiceylihkpqphcvspdweiiprkd)同源的、相似度最高的、已知三级结构的蛋白质作为模版。
打开SWISS-MODEL网站:/,选择“Template Identification,提交蛋白质序列进行模板识别,如图所示,注意:邮箱必填,名称随便填写,序列粘贴过去就行,下面会有很多选项,建议不知道的不要乱动,直接提交(Sbumit)吧。
这个东东跟BLAST差不多,你等它自动刷新吧,它会返回结果的,在结果页面,你会看到跟BLAST差不多的结果,选择相似度最高的那个蛋白作为下一步的三维模版(一般是第一个蛋白就是),如图:大家看红线标出的部分(是我标的),那个就是我们要找的模版,大家也可以在结果页面的下面仔细看看,找到最匹配的蛋白。
这里还有一点要作说明,就是上图标出的代码是PDB编号,前四个表示PDB- Code,最后一位表示Chain-ID,具体什么意思,大家有兴趣就去了解一些吧。
接下来,去NCBI串串门吧,在NCBI中搜索上面查到的蛋白的PDB号,一般输入前四位就行啦,注意:搜索蛋白库(Protein)。
找到以后,以FASTA格式显示。
接下来,我们再回到SWISS-MODEL,接下来就是重点和难点啦,在线提交序列进行同源建模分析,这个在线提交不是大家想象的那么容易,这个耗费了我大部分的时间,说到这里我就想画个圈圈诅咒它,大家注意啦~~~~~~~~~~~SWISS-MODEL 是一个自动化的蛋白质比较建模服务器,该服务器提供用户三种模式可选择:Automatic mode(简捷模式): 用于建模的氨基酸序列或是Swiss-Prot/TrEMBL (/sprot )编目号(accession)可以直接通过web界面提交。
SWISS-MODEL 蛋白质结构预测SWISS-MODEL是一项预测蛋白质三级结构的服务,它利用同源建模的方法实现对一段未知序列的三级结构的预测。
该服务创建于1993年,开创了自动建模的先河,并且它是讫今为止应用最广泛的免费服务之一。
同源建模法预测蛋白质三级结构一般由四步完成:1.从待测蛋白质序列出发,搜索蛋白质结构数据库(如PDB,SWISS-PROT等),得到许多相似序列(同源序列),选定其中一个(或几个)作为待测蛋白质序列的模板;2.待测蛋白质序列与选定的模板进行再次比对,插入各种可能的空位使两者的保守位置尽量对齐;3.建模:调整待测蛋白序列中主链各个原子的位置,产生与模板相同或相似的空间结构——待测蛋白质空间结构模型;4.利用能量最小化原理,使待测蛋白质侧链基团处于能量最小的位置。
最后提供给用户的是经过如上四步(或重复其中某几步)后得到的蛋白质三级结构。
SWISS-MODEL工作模式SWISS-MODEL服务器是以用户输入信息的最小化为目的设计的,即在最简单的情况下,用户仅提供一条目标蛋白的氨基酸序列。
由于比较建模程序可以具有不同的复杂性,用户输入一些额外信息对建模程序的运行有时是有必要的,比如,选择不同的模板或者调整目标模板序列比对。
该服务主要有以下三种方式:?First Approach mode(简捷模式):这种模式提供一个简捷的用户介面:用户只需要输入一条氨基酸序列,服务器就会自动选择合适的模板。
或者,用户也可以自己指定模板(最多5条),这些模板可以来自ExPDB模板数据库(也可以是用户选择的含坐标参数的模板文件)。
如果一条模板与提交的目标序列相似度大于25%,建模程序就会自动开始运行。
但是,模板的可靠性会随着模板与目标序列之间的相似度的降低而降低,如果相似度不到50%往往就需要用手工来调整序列比对。
这种模式只能进行大于25个残基的单链蛋白三维结构预测。
?Alignment Interface(比对界面):这种模式要求用户提供两条已经比对好的序列,并指定哪一条是目标序列,哪一条是模板序列(模板序列应该对应于ExPDB模板数据库中一条已经知道其空间结构的蛋白序列)。
蛋白质三级结构预测方法原理
蛋白质三级结构预测是指在蛋白质氨基酸序列已知的情况下,根据各种算法和模型预测出蛋白质的空间结构。
常用的预测方法包括构象搜索、分子动力学模拟、能量优化和机器学习等。
其中,构象搜索的思路是将空间构象看作是一系列的节点,搜索最稳定的构象;分子动力学模拟通过模拟蛋白质分子在一定温度、压力下的运动过程,逐渐寻找最稳定的构象;能量优化则是基于各种力场函数对蛋白质进行优化,最终得到最稳定的构象;机器学习的方法则是基于已知蛋白质的三级结构信息,通过大量数据训练预测模型,从而对新的蛋白质结构进行预测。
总的来说,蛋白质三级结构预测方法涉及到物理化学,生物信息学,计算机科学等领域,需要综合运用多种算法和模型,结合实验数据和生物学知识进行分析,不断改进和提升预测准确率。
蛋白质三级结构的分析和预测蛋白质是构成生命的重要物质之一。
其三级结构包括原生结构、二级结构和三级结构。
这些结构决定了蛋白质的功能和性质。
目前,已有许多方法可以分析和预测蛋白质的三级结构。
本文将就这些方法进行探讨。
一、蛋白质二级结构的分析和预测蛋白质的二级结构包括α-螺旋、β-折叠、无规卷曲等。
分析和预测蛋白质二级结构的方法主要有以下几种:1. X射线晶体衍射:通过对蛋白质的晶体进行X射线衍射,可以确定蛋白质的三维原子结构,进而得到蛋白质的二级结构。
2. 核磁共振:该方法通过将蛋白质放入强磁场中,利用不同原子核的不同磁共振信号来确定蛋白质的二级结构。
3. 红外光谱:该方法可以检测蛋白质样品和红外光的相互作用,从而确定蛋白质的二级结构。
4. 桥水铝质谱:该方法可以通过测量蛋白质分子离子化后的质荷比和分子碎片的相互作用来确定蛋白质的二级结构。
以上方法虽然可以准确测定蛋白质的二级结构,但需要高昂的成本和耗时的操作。
而预测蛋白质二级结构的方法主要有以下几种:1. 基于相似性比对的方法:该方法利用已知二级结构的蛋白质序列与待预测蛋白质序列进行比对,从而预测其二级结构。
缺点是需要已知的蛋白质序列作为比对对象。
2. 基于机器学习的方法:该方法利用已知蛋白质序列和其二级结构的数据集进行机器学习,从而预测未知蛋白质的二级结构。
缺点是需要大量的数据集。
3. 基于物理和化学性质的方法:该方法利用蛋白质分子内部的物理和化学性质,如氨基酸的电荷、氢键等,从而推断蛋白质的二级结构。
缺点是准确性有限。
二、蛋白质原生结构的分析和预测蛋白质的原生结构决定了其完整三级结构的构建和稳定性。
分析和预测蛋白质原生结构的方法主要有以下几种:1. X射线晶体衍射:该方法已经成为分析蛋白质原生结构的黄金标准。
通过分析蛋白质晶体的衍射图,可以精确地确定蛋白质分子的原生结构。
2. 高分辨率电子显微镜:该方法可以直接观察蛋白质分子的三维结构,从而确定其原生结构。
蛋白质结构与功能的预测蛋白质结构预测:蛋白质结构预测相关概念:“折叠(fold)”的概念“折叠(fold)”是近年来蛋白质研究中应用较广的一个概念,它是介与二级和三级结构之间的蛋白质结构层次,它描述的是二级结构元素的混合组合方式。
二级结构的预测方法介绍:Chou-Fasman算法:是单序列预测方法中的一种,它是使用氨基酸物理化学数据中派生出来的规律来预测二级结构。
首先统计出20种氨基酸出现在α螺旋、β折叠和无规则卷曲中出现频率的大小,然后计算出每一种氨基酸在这几种构象中的构象参数Px.构象参数值的大小反映了该种残基出现在某种构象中的倾向性的大小。
按照构象参数值的大小可以把氨基酸分为六个组:Ha(强螺旋形成者)、ha(螺旋形成者)、Ia(弱螺旋形成者)、ia(螺旋形成不敏感者)、ba(螺旋中断者)、Ba(强螺旋中断者)。
Chou和Fasman根据残基的倾向性因子提出二级结构预测的经验规则,要点是沿蛋白序列寻找二级结构的成核位点和终止位点。
这种方法可能能够正确反映蛋白质二级结构的形成过程,但预测成功率并不高,仅有50%左右。
GOR算法:也是单序列预测方法中的一种,因其作者Garnier, Osguthorpe和 Robson而得名。
这种方法是以信息论为基础的,也属于统计学方法的一种,GOR方法不仅考虑被预测位臵本身氨基酸残基种类对该位臵构象的影响,也考虑到相邻残基种类对该位臵构象的影响。
这样使预测的成功率提高到 65% 左右。
GOR方法的优点是物理意义清楚明确,数学表达严格,而且很容易写出相应的计算机程序,但缺点是表达式复杂。
多序列列线预测:对序列进行多序列比对,并利用多序列比对的信息进行结构的预测。
调查者可找到和未知序列相似的序列家族,然后假设序列家族中的同源区有同样的二级结构,预测不是基于一个序列而是一组序列中的所有序列的一致序列。
基于神经网络的序列预测:利用神经网络的方法进行序列的预测,BP (Back-Propagation Network) 网络即反馈式神经网络算法是目前二级结构预测应用最广的神经网络算法,它通常是由三层相同的神经元构成的层状网络,使用反馈式学习规则,底层为输入层,中间为隐含层,顶层是输出层,信号在相邻各层间逐层传递,不相邻的各层间无联系,在学习过程中根据输入的一级结构和二级结构的关系的信息不断调整各单元之间的权重,最终目标是找到一种好的输入与输出的映象,并对未知二级结构的蛋白进行预测。
蛋白质是生命体内的重要组成成分,它们具有多种功能,包括传递信号、催化化学反应和提供结构支持。
蛋白质的功能与其三维结构密切相关,因此对蛋白质三维结构的预测成为生物信息学中的重要课题之一。
在蛋白质三维结构预测领域,主要方法包括以下几种:1. 基于序列比对的模板建模方法这是目前蛋白质结构预测中最准确和最常用的方法之一。
它利用已知结构的蛋白质作为模板,通过序列比对找到与待预测蛋白质相似的结构,然后用模板蛋白质的结构作为预测结果。
这种方法在已知结构蛋白质序列与待预测蛋白质序列非常相似的情况下效果最好,但是对于没有已知结构模板的蛋白质来说,预测结果可能不够准确。
2. 基于物理模型的能量函数方法这种方法是通过物理化学原理,利用分子力学模拟蛋白质的结构,通过计算能量最低的构型来预测蛋白质的三维结构。
这种方法的优势在于能够考虑到蛋白质内部的相互作用力和构象约束,从而提高了预测的准确性。
但是这种方法需要耗费大量的计算资源和时间,并且对蛋白质的结构特征有一定的要求,对于大蛋白质的结构预测会面临更大的挑战。
3. 基于机器学习的方法随着人工智能和机器学习技术的发展,越来越多的研究开始尝试利用机器学习算法来预测蛋白质的三维结构。
这种方法通过训练大量的蛋白质序列和结构数据,使得计算机能够通过学习蛋白质序列和其对应结构的关联性,从而对新的蛋白质序列进行结构预测。
由于机器学习方法的高效性和灵活性,这种方法在蛋白质结构预测领域具有广阔的应用前景。
总结起来,蛋白质的三维结构预测是一个复杂而困难的课题,在不同的方法中各有优势和局限性。
未来随着生物信息学和计算机科学的不断发展,相信会有更多更准确的蛋白质结构预测方法涌现出来,为人类揭开蛋白质奥秘提供更多可能。
4. 强化学习在蛋白质三维结构预测中的应用强化学习是一种重要的机器学习方法,近年来开始在蛋白质三维结构预测中得到应用。
强化学习通过与环境的交互学习来寻找最优的决策策略,其优势在于能够在不断的试验中进行优化,可以有效应对蛋白质结构预测中的复杂问题。
简述蛋白质三级结构预测方法的选择流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor.I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!简述蛋白质三级结构预测方法的选择流程蛋白质是生命活动的基础,其三维结构对功能的实现至关重要。