存储过程的实例
- 格式:docx
- 大小:29.52 KB
- 文档页数:13
题目 1
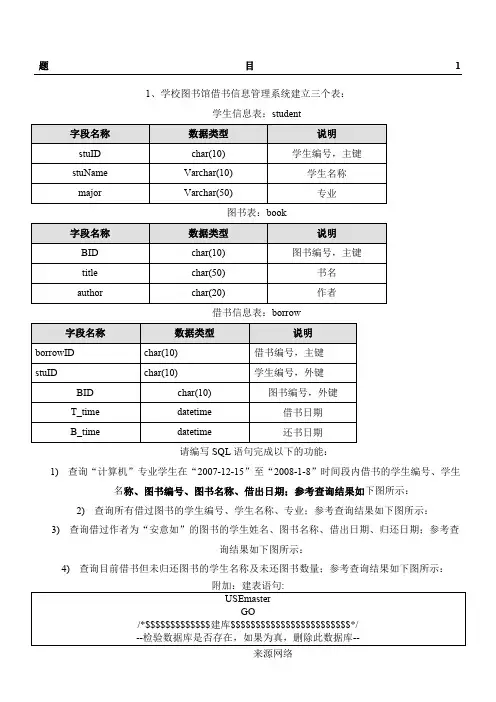
1、学校图书馆借书信息管理系统建立三个表:
学生信息表:student
3)查询借过作者为“安意如”的图书的学生姓名、图书名称、借出日期、归还日期;参考查
询结果如下图所示:
4)查询目前借书但未归还图书的学生名称及未还图书数量;参考查询结果如下图所示:
题目2
程序员工资表:ProWage
创建一个存储过程,对程序员的工资进行分析,月薪1500到10000不等,如果有百分之五十的人薪水不到2000元,给所有人加薪,每次加100,再进行分析,直到有一半以上的人大于2000元为
止,存储过程执行完后,最终加了多少钱?
元之
,3500,
题目3:
1) 查询各个学生语文、数学、英语、历史课程成绩,例如下表:
2)查询四门课中成绩低于70分的学生及相对应课程名和成绩。
3)统计各个学生参加考试课程的平均分,且按平均分数由高到底排序。
4)创建存储过程,分别查询参加1、2、3、4门考试及没有参加考试的学生名单,要求显示姓名、
学号。

mysql存储过程MySQL存储过程1. 存储过程简介我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(StoredProcedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
一个存储过程是一个可编程的函数,它在数据库中创建并保存。
它可以有SQL 语句和一些特殊的控制结构组成。
当希望在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。
数据库中的存储过程可以看做是对编程中面向对象方法的模拟。
它允许控制数据的访问方式。
存储过程通常有以下优点:(1).存储过程增强了SQL语言的功能和灵活性。
存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
(2).存储过程允许标准组件是编程。
存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。
而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
(3).存储过程能实现较快的执行速度。
如果某一操作包含大量的Transaction-SQL 代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。
因为存储过程是预编译的。
在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。
而批处理的Transaction-SQL 语句在每次运行时都要进行编译和优化,速度相对要慢一些。
(4).存储过程能过减少网络流量。
针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织程存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大增加了网络流量并降低了网络负载。
(5).存储过程可被作为一种安全机制来充分利用。
系统管理员通过执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。

DB2存储过程4类循环简单实例SET SCHEMA = 'DB2ADMIN';SET CURRENT PATH = "SYSIBM","SYSFUN","SYSPROC","SYSIBMADM","DB2ADMIN"; CREATE PROCEDURE "DB2ADMIN"."TEST_CIRCULATION" ( )DYNAMIC RESULT SETS 1LANGUAGE SQLNOT DETERMINISTICEXTERNAL ACTIONMODIFIES SQL DATAOLD SAVEPOINT LEVELp1: begindeclare aa varchar(10);declare bb varchar(10);declare a integer DEFAULT 0;-- 定义⼀个全局临时表tmp_hydeclare global temporary table session.tmp_hy(dm varchar(10),mc varchar(10))with replace -- 如果存在此临时表,则替换not logged; -- 不在⽇志⾥纪录-- 给临时表插⼊三条数据insert into session.tmp_hy values('1','01');insert into session.tmp_hy values('2','02');insert into session.tmp_hy values('3','03');--for隐式循环for cur1 as select dm,mc from session.tmp_hydoif cur1.dm='1' or cur1.dm='2' or cur1.dm='3' theninsert into session.tmp_hy values(cur1.mc,'隐式循环');end if;update session.tmp_hy set mc='0'||''||cur1.mc||'' where dm=cur1.dm;end for;p2: begin--简单循环declare cursor2 cursor forselect dm,mc from session.tmp_hy;OPEN cursor2;FETCH_LOOP: LOOPFETCH cursor2 INTO aa,bb;IF a >= 3 THEN -- loop until last row of the cursorLEAVE FETCH_LOOP;END IF;if aa='1' or aa='2' or aa='3' theninsert into session.tmp_hy values(bb,'简单循环');end if;set a=a+1;END LOOP FETCH_LOOP;close cursor2;end p2;set a=0;p3: begin--进⼊前检查条件declare cursor2 cursor forselect dm,mc from session.tmp_hy;OPEN cursor2;FETCH cursor2 INTO aa, bb;while a<3doif aa='1' or aa='2' or aa='3' theninsert into session.tmp_hy values(bb,'while循环');end if;set a=a+1;FETCH cursor2 INTO aa, bb;end while;close cursor2;end p3;set a=0;p4: begin--退出前检查条件declare cursor2 cursor forselect dm,mc from session.tmp_hy;OPEN cursor2;REPEATFETCH cursor2 INTO aa, bb;if aa='1' or aa='2' or aa='3' theninsert into session.tmp_hy values(bb,'REPEAT循环'); end if;set a=a+1;UNTIL a>=3end REPEAT;close cursor2;end p4;p5: begin--声明游标declare cursor1 cursor with return forselect * from session.tmp_hy;--游标对客户机应⽤程序保持打开open cursor1;end p5;end p1;。

存储过程案例
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,用户通过调用存储过程来执行这个程序。
以下是一个简单的存储过程案例:
案例:创建存储过程,根据用户输入的姓名查询员工信息
1. 数据库表结构
假设有一个名为`employees`的表,结构如下:
```sql
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
department VARCHAR(50)
);
```
2. 创建存储过程
```sql
DELIMITER //
CREATE PROCEDURE GetEmployeeInfo(IN empName VARCHAR(50)) BEGIN
SELECT FROM employees WHERE name = empName;
END //
DELIMITER ;
```
3. 调用存储过程
调用上述存储过程,查询名为"John"的员工信息:
```sql
CALL GetEmployeeInfo('John');
```
4. 结果
如果存在名为"John"的员工,则返回该员工的信息;否则返回空结果。
这是一个简单的存储过程示例。
在实际应用中,存储过程可以更复杂,可以包含条件、循环、多个表的联接等操作。
使用存储过程的好处是提高性能、减少网络流量、提高安全性等。

Oracle 存储过程学习目录Oracle存储过程基础知识商业规则和业务逻辑可以通过程序存储在Oracle中,这个程序就是存储过程;存储过程是SQL, PL/SQL, Java 语句的组合,它使你能将执行商业规则的代码从你的应用程序中移动到数据库;这样的结果就是,代码存储一次但是能够被多个程序使用;要创建一个过程对象procedural object,必须有 CREATE PROCEDURE 系统权限;如果这个过程对象需要被其他的用户schema 使用,那么你必须有 CREATE ANY PROCEDURE 权限;执行procedure 的时候,可能需要excute权限;或者EXCUTE ANY PROCEDURE 权限;如果单独赋予权限,如下例所示:grant execute on MY_PROCEDURE to Jelly调用一个存储过程的例子:execute MY_PROCEDURE 'ONE PARAMETER';存储过程PROCEDURE和函数FUNCTION的区别;function有返回值,并且可以直接在Query中引用function和或者使用function的返回值;本质上没有区别,都是 PL/SQL 程序,都可以有返回值;最根本的区别是:存储过程是命令, 而函数是表达式的一部分;比如:select maxNAME FROM但是不能 exec maxNAME 如果此时max是函数;PACKAGE是function,procedure,variables 和sql 语句的组合;package允许多个procedure使用同一个变量和游标;创建 procedure的语法:Sql 代码:可以使用 create or replace procedure 语句, 这个语句的用处在于,你之前赋予的excute 权限都将被保留;IN, OUT, IN OUT用来修饰参数;IN 表示这个变量必须被调用者赋值然后传入到PROCEDURE进行处理;OUT 表示PRCEDURE 通过这个变量将值传回给调用者;IN OUT 则是这两种的组合;authid代表两种权限:定义者权限difiner right 默认,执行者权限invoker right;定义者权限说明这个procedure中涉及的表,视图等对象所需要的权限只要定义者拥有权限的话就可以访问;执行者权限则需要调用这个 procedure的用户拥有相关表和对象的权限;Oracle存储过程的基本语法1.基本结构2.SELECT INTO STATEMENT将select查询的结果存入到变量中,可以同时将多个列存储多个变量中,必须有一条记录,否则抛出异常如果没有记录抛出NO_DATA_FOUND例子:3.IF 判断4.while 循环5.变量赋值6.用for in 使用cursor7.带参数的cursor8.用pl/sql developer debug连接数据库后建立一个Test WINDOW在窗口输入调用SP的代码,F9开始debug,CTRL+N单步调试9.Pl/Sql中执行存储过程在sqlplus中:/在SQL/PLUS中调用存储过程,显示结果:SQL>set serveoutput on --打开输出SQL>var info1 number; --输出1SQL>var info2 number; --输出2SQL>declarevar1 varchar220; --输入1var2 varchar220; --输入2var3 varchar220; --输入2BEGINprovar1,var2,var3,:info1,:info2;END;/SQL>print info1;SQL>print info2;注:在EXECUTE IMMEDIATE STR语句是SQLPLUS中动态执行语句,它在执行中会自动提交,类似于DP中FORMS_DDL语句,在此语句中str是不能换行的,只能通过连接字符"||",或着在在换行时加上"-"连接字符;关于Oracle存储过程的若干问题备忘1.在Oracle中,数据表别名不能加as;如:selecta.appnamefromappinfoa;-- 正确selecta.appnamefromappinfoasa;-- 错误也许,是怕和Oracle中的存储过程中的关键字as冲突的问题吧2.在存储过程中,select某一字段时,后面必须紧跟into,如果select整个记录,利用游标的话就另当别论了;selectaf.keynodeintoknfromAPPFOUNDATIONafwhereaf.appid=aidandaf.foundationid=fid; --有into,正确编译selectaf.keynodefromAPPFOUNDATIONafwhereaf.appid=aidandaf.foundationid=fid;--没有into,编译报错,提示:CompilationError:PLS-00428:anINTOclauseisexpectedinthisSELECTstatement3.在利用select...into...语法时,必须先确保数据库中有该条记录,否则会报出"no data found"异常;可以在该语法之前,先利用select count from 查看数据库中是否存在该记录,如果存在,再利用select...into...4.在存储过程中,别名不能和字段名称相同,否则虽然编译可以通过,但在运行阶段会报错selectkeynodeintoknfromAPPFOUNDATIONwhereappid=aidandfoundationid=fid;--正确运行selectaf.keynodeintoknfromAPPFOUNDATIONafwhereaf.appid=appidandaf.foundationid= foundationid;--运行阶段报错,提示:ORA-01422:exactfetchreturnsmorethanrequestednumberofrows5.在存储过程中,关于出现null的问题假设有一个表A,定义如下:createtableA idvarchar250primarykeynotnull,vcountnumber8notnull,bidvarchar250notnull--外键;如果在存储过程中,使用如下语句:selectsumvcountintofcountfromAwherebid='xxxxxx';如果A表中不存在bid="xxxxxx"的记录,则fcount=null即使fcount定义时设置了默认值,如:fcount number8:=0依然无效,fcount还是会变成null,这样以后使用fcount时就可能有问题,所以在这里最好先判断一下:iffcountisnullthenfcount:=0;end if;这样就一切ok了;6.Hibernate调用Oracle存储过程this.pnumberManager.getHibernateTemplate.executenew HibernateCallback ...{用Java调用Oracle存储过程总结一、无返回值的存储过程测试表:例: 存储过程为当然了,这就先要求要建张表TESTTB,里面两个字段I_ID,I_NAME;:在Java里调用时就用下面的代码:二、有返回值的存储过程非列表例:存储过程为:在Java里调用时就用下面的代码:注意,这里的proc.getString2中的数值2并非任意的,而是和存储过程中的out列对应的,如果out是在第一个位置,那就是proc.getString1,如果是第三个位置,就是proc.getString3,当然也可以同时有多个返回值,那就是再多加几个out参数了;三、返回列表由于Oracle存储过程没有返回值,它的所有返回值都是通过out参数来替代的,列表同样也不例外,但由于是集合,所以不能用一般的参数,必须要用pagkage了.所以要分两部分,1.建一个程序包;如下:2.建立存储过程,存储过程为:可以看到,它是把游标可以理解为一个指针,作为一个out 参数来返回值的;在Java里调用时就用下面的代码:在这里要注意,在执行前一定要先把Oracle的驱动包放到class路径里,否则会报错的;在存储过程中做简单动态查询在存储过程中做简单动态查询代码 ,例如:一般的PL/SQL程序设计中,在DML和事务控制的语句中可以直接使用SQL,但是DDL语句及系统控制语句却不能在PL/SQL中直接使用,要想实现在PL/SQL中使用DDL语句及系统控制语句,可以通过使用动态SQL来实现;首先我们应该了解什么是动态SQL,在Oracle数据库开发PL/SQL块中我们使用的SQL分为:静态SQL语句和动态SQL语句;所谓静态SQL指在PL/SQL块中使用的SQL语句在编译时是明确的,执行的是确定对象;而动态SQL是指在PL/SQL块编译时SQL语句是不确定的,如根据用户输入的参数的不同而执行不同的操作;编译程序对动态语句部分不进行处理,只是在程序运行时动态地创建语句、对语句进行语法分析并执行该语句;Oracle中动态SQL可以通过本地动态SQL来执行,也可以通过DBMS_SQL包来执行;下面就这两种情况分别进行说明:一、本地动态SQL本地动态SQL是使用EXECUTE IMMEDIATE语句来实现的;1、本地动态SQL执行DDL语句:需求:根据用户输入的表名及字段名等参数动态建表;以上是编译通过的存储过程代码;下面执行存储过程动态建表;到这里,就实现了我们的需求,使用本地动态SQL根据用户输入的表名及字段名、字段类型等参数来实现动态执行DDL语句;2、本地动态SQL执行DML语句;需求:将用户输入的值插入到上例中建好的dinya_test表中;执行存储过程,插入数据到测试表中;在上例中,本地动态SQL执行DML语句时使用了using子句,按顺序将输入的值绑定到变量,如果需要输出参数,可以在执行动态SQL的时候,使用RETURNING INTO 子句,如:二、使用DBMS_SQL包使用DBMS_SQL包实现动态SQL的步骤如下:A、先将要执行的SQL语句或一个语句块放到一个字符串变量中;B、使用DBMS_SQL包的parse过程来分析该字符串;C、使用DBMS_SQL包的bind_variable过程来绑定变量;D、使用DBMS_SQL包的execute函数来执行语句;1、使用DBMS_SQL包执行DDL语句需求:使用DBMS_SQL包根据用户输入的表名、字段名及字段类型建表;以上过程编译通过后,执行过程创建表结构:2、使用DBMS_SQL包执行DML语句需求:使用DBMS_SQL包根据用户输入的值更新表中相对应的记录;查看表中已有记录:建存储过程,并编译通过:执行过程,根据用户输入的参数更新表中的数据:执行过程后将第二条的name字段的数据更新为新值csdn_dinya;这样就完成了使用dbms_sql包来执行DML语句的功能;使用DBMS_SQL中,如果要执行的动态语句不是查询语句,使用DBMS_SQL.Execute或DBMS_SQL.Variable_Value来执行,如果要执行动态语句是查询语句,则要使用DBMS_SQL.define_column定义输出变量,然后使用DBMS_SQL.Execute, DBMS_SQL.Fetch_Rows, DBMS_SQL.Column_Value及DBMS_SQL.Variable_Value来执行查询并得到结果;总结说明:在Oracle开发过程中,我们可以使用动态SQL来执行DDL语句、DML语句、事务控制语句及系统控制语句;但是需要注意的是,PL/SQL块中使用动态SQL执行DDL语句的时候与别的不同,在DDL中使用绑定变量是非法的bind_variablev_cursor,’:p_name’,name,分析后不需要执行DBMS_SQL.Bind_Variable,直接将输入的变量加到字符串中即可;另外,DDL是在调用DBMS_SQL.PARSE时执行的,所以DBMS_SQL.EXECUTE也可以不用,即在上例中的v_row:=dbms_sql.executev_cursor部分可以不要;Oracle存储过程调用Java方法存储过程中调用Java程序段软件环境:1、操作系统:Windows2000Server2、3、数据库:8iR24、8.1.7forNT企业版5、安装路径:C:\ORACLE实现方法:1、创建一个文件为Test.java2、javac Test.java3、java Test4、SQL>connsystem/manager5、SQL>grantcreateanydirectorytoscott;SQL>connscott/tigerSQL>createorreplacedirectorytest_diras'd:\';目录已创建;SQL>createorreplacejavaclassusingbfiletest_dir,'TEST.CLASS'2/Java 已创建;SQL>selectobject_name,object_type,STATUSfromuser_objects;SQL>createorreplaceproceduretest_javaaslanguagejava/过程已创建;SQL>setserveroutputonsize5000SQL>calldbms_java.set_output5000;调用完成;SQL>executetest_java;HELLOTHISiSAJavaPROCEDUREPL/SQL 过程已成功完成;SQL>calltest_java;HELLOTHISiSAJavaPROCEDURE调用完成;Oracle 8I 9I都测试通过; Oracle高效分页存储过程实例。

SQLServer存储过程语法及实例Transact-SQL中的存储过程,⾮常类似于Java语⾔中的⽅法,它可以重复调⽤。
当存储过程执⾏⼀次后,可以将语句缓存中,这样下次执⾏的时候直接使⽤缓存中的语句。
这样就可以提⾼存储过程的性能。
Ø 存储过程的概念存储过程Procedure是⼀组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,⽤户通过指定存储过程的名称并给出参数来执⾏。
存储过程中可以包含逻辑控制语句和数据操纵语句,它可以接受参数、输出参数、返回单个或多个结果集以及返回值。
由于存储过程在创建时即在数据库服务器上进⾏了编译并存储在数据库中,所以存储过程运⾏要⽐单个的SQL语句块要快。
同时由于在调⽤时只需⽤提供存储过程名和必要的参数信息,所以在⼀定程度上也可以减少⽹络流量、简单⽹络负担。
1、存储过程的优点A、存储过程允许标准组件式编程存储过程创建后可以在程序中被多次调⽤执⾏,⽽不必重新编写该存储过程的SQL语句。
⽽且数据库专业⼈员可以随时对存储过程进⾏修改,但对应⽤程序源代码却毫⽆影响,从⽽极⼤的提⾼了程序的可移植性。
B、存储过程能够实现较快的执⾏速度如果某⼀操作包含⼤量的T-SQL语句代码,分别被多次执⾏,那么存储过程要⽐批处理的执⾏速度快得多。
因为存储过程是预编译的,在⾸次运⾏⼀个存储过程时,查询优化器对其进⾏分析、优化,并给出最终被存在系统表中的存储计划。
⽽批处理的T-SQL语句每次运⾏都需要预编译和优化,所以速度就要慢⼀些。
C、存储过程减轻⽹络流量对于同⼀个针对数据库对象的操作,如果这⼀操作所涉及到的T-SQL语句被组织成⼀存储过程,那么当在客户机上调⽤该存储过程时,⽹络中传递的只是该调⽤语句,否则将会是多条SQL语句。
从⽽减轻了⽹络流量,降低了⽹络负载。
D、存储过程可被作为⼀种安全机制来充分利⽤系统管理员可以对执⾏的某⼀个存储过程进⾏权限限制,从⽽能够实现对某些数据访问的限制,避免⾮授权⽤户对数据的访问,保证数据的安全。

复杂的存储过程实例
嘿,朋友们!今天咱来聊聊复杂的存储过程实例。
这玩意儿啊,就像是一个神秘的魔法盒子,里面装满了各种奇妙的东西。
你想想看,存储过程就像是一个经验丰富的大厨,它能把各种食材(数据)巧妙地组合在一起,做出一道道美味的菜肴(结果)。
而复杂的存储过程呢,那就是大厨中的大厨,能玩出各种高难度的花样。
比如说,有一个存储过程就像是一场精心编排的舞蹈。
它的步骤环环相扣,一个动作接着一个动作,不能有丝毫差错。
如果中间有一个步骤出错了,那整个舞蹈可就乱套啦!这就好比你在煮饺子的时候,水还没烧开就把饺子扔进去了,那能煮出好吃的饺子吗?
还有啊,有些存储过程就像是一个复杂的迷宫。
你得小心翼翼地在里面探索,稍有不慎就会迷失方向。
但一旦你找到了正确的路径,哇塞,那可真是豁然开朗,柳暗花明又一村啊!
咱再打个比方,复杂的存储过程就像是搭积木,一块一块地往上堆,要保证每一块都放得稳稳当当的,不然整个积木塔就可能轰然倒塌。
这可需要极大的耐心和细心呢!
在实际操作中,你可得对这些存储过程宝贝得很呐!要像对待自己最心爱的宝贝一样,精心呵护,仔细研究。
别小看了那些代码,它们可都有着大作用呢!
你说,要是没有这些复杂的存储过程,我们的数据库世界得变得多么无趣啊!它们就像是夜空中最闪亮的星星,给我们的数据库增添了无尽的魅力和神秘感。
所以啊,朋友们,好好去探索那些复杂的存储过程吧!别怕困难,别怕麻烦,当你真正掌握了它们,你就会发现,哇,原来我也可以这么厉害!就像征服了一座高峰一样,那种成就感简直无与伦比。
加油吧,让我们一起在存储过程的世界里畅游!。

存储过程实例精选存储过程是一组在数据库中执行的预编译的SQL语句。
它们是用来执行一系列的数据库操作,可以减少网络通信的次数,提高数据库性能,同时也可以确保数据的一致性和完整性。
在这篇文章中,我们将介绍一些存储过程实例的精选内容。
1.添加新用户存储过程可以用于添加新用户到数据库中。
当有新用户注册时,我们可以使用存储过程来验证用户输入的数据,如用户名和密码是否符合要求,然后将用户信息插入到用户表中。
此外,存储过程还可以对用户信息进行加密,并生成唯一的用户ID。
2.计算订单总额在一个电子商务网站中,有时需要计算订单的总额。
我们可以使用存储过程来计算订单中每个商品的价格,并将这些价格相加得到订单的总额。
通过使用存储过程,我们可以只向数据库发送一条SQL查询,而不是分别查询每个商品的价格,从而提高了查询性能。
3.更新库存存储过程也可以用于更新商品库存。
当用户购买商品时,我们可以使用存储过程来减少商品的库存数量。
在更新库存的过程中,存储过程可以检查商品的库存量是否足够,如果库存不足,则不允许用户购买。
4.备份数据库定期备份数据库是非常重要的,以防止数据丢失。
我们可以创建一个存储过程来自动备份数据库。
这个存储过程可以在指定的时间间隔内运行,并将数据库备份到指定的位置。
通过使用存储过程,我们可以快速方便地完成数据库的备份工作。
5.根据条件检索数据存储过程可以接受参数,并根据这些参数来检索数据。
例如,我们可以创建一个存储过程,接受一个日期作为参数,并返回在该日期之后的所有订单。
这样,我们可以根据需要灵活地检索数据库中的数据。
6.发送电子邮件通知存储过程还可以用于发送电子邮件通知。
例如,当有新订单时,我们可以使用存储过程来生成包含订单信息的电子邮件,并将其发送给相关的人员。
通过使用存储过程,我们可以将发送电子邮件的逻辑和业务逻辑分离,使代码更易于维护。
7.执行复杂的事务存储过程可以执行复杂的事务操作,例如同时更新多个表,保证数据的一致性。

MySQL存储过程实例教程MySQL 5.0以后的版本开始支持存储过程,存储过程具有一致性、高效性、安全性和体系结构等特点,本节将通过具体的实例讲解PHP是如何操纵MySQL存储过程的。
1:存储过程的创建这是一个创建存储过程的实例实例说明为了保证数据的完整性、一致性,提高应用的性能,常采用存储过程技术。
MySQL 5.0之前的版本并不支持存储过程,随着MySQL技术的日趋完善,存储过程将在以后的项目中得到广泛的应用。
本实例将介绍在MySQL 5.0以后的版本中创建存储过程。
技术要点一个存储过程包括名字、参数列表,以及可以包括很多SQL语句的SQL语句集。
下面为一个存储过程的定义过程: create procedure proc_name (in parameterinteger)begindeclare variable varchar(20);if parameter=1 thensetvariable='MySQL';elseset variable='PHP';end if;insert into tb (name) values (variable);end;MySQL中存储过程的建立以关键字create procedure开始,后面紧跟存储过程的名称和参数。
MySQL的存储过程名称不区分大小写,例如PROCE1()和proce1()代表同一个存储过程名。
存储过程名不能与MySQL数据库中的内建函数重名。
存储过程的参数一般由3部分组成。
第一部分可以是in、out或inout。
in表示向存储过程中传入参数;out表示向外传出参数;inout表示定义的参数可传入存储过程,并可以被存储过程修改后传出存储过程,存储过程默认为传入参数,所以参数in可以省略。
第二部分为参数名。
第三部分为参数的类型,该类型为MySQL数据库中所有可用的字段类型,如果有多个参数,参数之间可以用逗号进行分割。

达梦创建存储过程实例-概述说明以及解释1.引言1.1 概述在信息化和数据化的时代背景下,数据库管理系统(DBMS)成为了管理和存储大量数据的重要工具。
达梦数据库是一种高性能、高安全性的关系型数据库管理系统,它提供了一系列强大的功能和工具,用于管理和操作数据库。
存储过程是数据库中一组预定义的SQL语句集合,可以被保存并以后被重复调用。
存储过程使得数据库的开发工作更加灵活和高效,可以通过简单的调用实现复杂的业务逻辑。
达梦数据库也支持创建存储过程,并且为开发人员提供了完善的存储过程开发和管理工具。
本文将以达梦数据库为例,介绍如何创建和使用存储过程。
首先,我们将对存储过程的概念和特点进行简要介绍。
然后,我们将详细讲解如何在达梦数据库中创建存储过程,并通过实例演示不同场景下存储过程的应用。
最后,我们将总结本文的主要内容,并展望存储过程在数据库开发中的未来发展趋势。
通过学习本文,读者将能够深入了解达梦数据库存储过程的基本原理和使用方法,提升数据库开发效率和程序性能,并为今后的数据库应用开发奠定扎实的基础。
1.2 文章结构文章结构部分的内容可以按照以下方式编写:2. 正文2.1 子章节12.1.1 要点12.1.2 要点22.2 子章节22.2.1 要点12.2.2 要点22.3 子章节32.3.1 要点12.3.2 要点2本文主要分为引言、正文和结论三个部分。
其中正文部分包含了三个子章节,分别是子章节1、子章节2和子章节3。
每个子章节下又包含了各自的要点。
通过这种层级结构,使得文章的结构更加清晰明了。
引言部分对文章的整体进行了概述,包括了概述、文章结构和目的三个方面的内容。
正文部分是文章的核心部分,具体展开了对达梦创建存储过程的实例的讲解。
结论部分对全文进行了总结,并对未来展望进行了描述。
这样的结构安排旨在使读者更好地理解文章内容,并能够按照章节的顺序逐步阅读,加深对达梦创建存储过程的理解。
同时,该结构也有助于作者更好地组织和表达思路,使文章更加清晰和条理。

oracle 存储过程优秀例子Oracle存储过程是一种在数据库中存储和执行SQL语句的过程。
它可以接受参数并返回结果,用于实现复杂的业务逻辑和数据操作。
下面是10个优秀的Oracle存储过程示例,展示了不同方面的功能和用法。
1. 创建表并插入数据```sqlCREATE PROCEDURE create_employee_table ASBEGINEXECUTE IMMEDIATE 'CREATE TABLE employee (id NUMBER, name VARCHAR2(100))';EXECUTE IMMEDIATE 'INSERT INTO employee VALUES (1, ''John Doe'')';EXECUTE IMMEDIATE 'INSERT INTO employee VALUES (2, ''Jane Smith'')';END;```这个存储过程创建了一个名为employee的表,并插入了两条数据。
2. 更新员工姓名```sqlCREATE PROCEDURE update_employee_name(p_id NUMBER,p_name VARCHAR2) ASBEGINUPDATE employee SET name = p_name WHERE id = p_id;COMMIT;END;```这个存储过程接受员工的ID和新的姓名作为参数,然后更新对应员工的姓名。
3. 删除员工记录```sqlCREATE PROCEDURE delete_employee(p_id NUMBER) AS BEGINDELETE FROM employee WHERE id = p_id;COMMIT;END;```这个存储过程接受员工的ID作为参数,然后删除对应的员工记录。
vb调用存储过程实例嘿,朋友们!今天咱就来聊聊 VB 调用存储过程实例这档子事儿。
你看啊,这 VB 就像是一个聪明的小工匠,而存储过程呢,就像是一个装满了各种奇妙工具和技巧的百宝箱。
当 VB 这个小工匠想要完成一些复杂又厉害的任务时,它就得去打开那个存储过程的百宝箱,从中挑选出合适的工具来用。
比如说吧,我们要处理一堆数据,就好像要把一堆杂乱无章的积木搭建成一个漂亮的城堡。
VB 自己一个人可能会手忙脚乱,但有了存储过程,就像是有了一套详细的搭建指南。
它可以告诉 VB 该怎么一步一步地去做,先拿哪块积木,怎么摆放,怎样才能让城堡更稳固。
那怎么让 VB 顺利地调用存储过程呢?这可得有点小窍门啦!就好像你要打开一把复杂的锁,得知道怎么摆弄钥匙一样。
首先,你得告诉 VB 那个存储过程在哪里,就像是给它指明宝藏的位置。
然后呢,VB 得知道怎么和存储过程“对话”,怎么把自己的需求传达过去,又怎么接收存储过程给它的反馈。
这就好像你和朋友之间的交流,你得把你的想法清楚地说出来,朋友才能明白,然后朋友给你回应,你才能知道接下来该怎么做。
如果VB 没和存储过程“沟通”好,那可就乱套啦,就像你和朋友说话互相听不懂一样,那还怎么合作完成任务呢?在这个过程中,可不能粗心大意哦!一个小细节没注意到,可能就会导致整个程序出问题。
这就像盖房子,一块砖没放好,说不定整面墙都会倒掉呢!而且啊,不同的存储过程就像不同的百宝箱,里面的工具和方法都不一样,VB 可得好好研究,才能找到最适合的那个。
你说这 VB 调用存储过程实例是不是很有意思?它让我们能更高效地处理数据,更轻松地完成各种复杂的任务。
想想看,如果没有这种方式,我们得写多少繁琐的代码啊!现在有了它,就像是有了一个得力的助手,帮我们把那些麻烦事儿都搞定了。
所以啊,朋友们,好好去探索 VB 调用存储过程实例吧!让它为我们的程序带来更多的精彩和便利。
别害怕遇到问题,就像走路会摔跤一样,那都是成长的过程。
达梦数据库存储过程for循环实例全文共四篇示例,供读者参考第一篇示例:在数据库开发中,存储过程是一种存储在数据库中的一系列SQL 语句的集合,可以被调用和执行。
通过存储过程,开发人员可以实现复杂的业务逻辑和数据处理,并且提高数据库的性能和安全性。
在达梦数据库中,存储过程也是一项非常重要的功能,可以帮助开发人员更好地管理和操作数据库。
在很多情况下,我们需要在存储过程中使用循环来处理数据,特别是当需要对多条记录进行相同的操作时。
在本篇文章中,我们将介绍如何在达梦数据库存储过程中实现循环功能,以及如何使用for循环来实现一些常见的业务逻辑。
我们需要了解在达梦数据库中如何创建存储过程。
以创建一个简单的存储过程为例,语法如下:```CREATE PROCEDURE proc_exampleASBEGIN-- 在此处编写存储过程的SQL语句END```在上面的代码中,我们通过CREATE PROCEDURE语句创建了一个名为proc_example的存储过程。
存储过程的主体部分在BEGIN和END之间,可以包含任意数量的SQL语句。
接下来,我们将介绍如何在达梦数据库存储过程中使用for循环来处理数据。
for循环是一种常用的循环结构,可以重复执行一组语句,直到指定条件不再成立为止。
在存储过程中,我们可以使用for循环来遍历表中的记录,或者执行一定次数的操作。
下面是一个简单的示例,演示如何在存储过程中使用for循环来输出数字1到10:WHILE @i <= 10BEGINPRINT @iSET @i = @i + 1ENDEND```在上面的代码中,我们通过DECLARE语句声明了一个变量@i,用于保存循环变量的值。
然后通过WHILE语句指定了循环的条件@i <= 10,当条件成立时,执行循环体中的PRINT语句,并将@i的值递增1。
当循环变量@i的值大于10时,循环结束。
通过上面的例子,我们可以看到在达梦数据库存储过程中使用for 循环是非常简单的。
CREATE OR REPLACE PROCEDURE TOOLD_T_JZZYW_YX_ALL IS/*****************************************功能:把新市库中的t_jzzyw_yx\t_jzzxx_yx\t_jzzyw_qtxx_yx增量转换到旧市库的T_JZZ_YW,T_JZZ_XX数据;时间:2013-02-25*****************************************/V_ERRORS VARCHAR2(200);V_N VARCHAR2(2);C_TABLE_NAME CONSTANT VARCHAR2(32) := 'T_JZZYW_YX';BEGINBEGIN/***************************判断新市库到旧市库的链路是否联通如果不通,则退出当次转换***************************/SELECT * INTO V_N FROM DUAL@KYXX;EXCEPTIONWHEN OTHERS THENV_ERRORS := SQLERRM;INSERT INTO T_ERROR_LOG_TOOLD(TYPE, ERRORMSG, XRSJ, YWID)VALUES(C_TABLE_NAME, V_ERRORS, SYSDATE, '链路不通,退出转换');COMMIT;RETURN;END;/*\*更新XZQ字段*\UPDATE KY_T_JZZYW_YX YXSET XZQ =(SELECT T3.XZQDM XZQFROM T_JZZXX_YX T, T_FWXX T1, T_FWXX_MPXX T2, V_XZQH_ZZJG T3 WHERE T.FWID = T1.IDAND T1.MPDM = T2.DMAND T2.XZQHDM = T3.DMAND JZZYWID = YX.ID);COMMIT;*/FOR I IN (SELECT A.ID AS ID,A.DJBID AS DJBID,C.DQYWHJ AS DQYWHJ,C.DQYWZT AS DQYWZT,A.SLLB AS SLLB,A.SLYY AS SLYY,A.SLRQ AS SLRQ,A.SLDWDM AS SLDWDM,A.SLR AS SLR,A.SFKS AS SFKS,A.SFDYLQPZ AS SFDYLQPZ, A.DYLQPZRQ AS DYLQPZRQ, A.SFYJF AS SFYJF,A.HZBH AS HZBH,A.HZFFRQ AS HZFFRQ,A.HZFFR AS HZFFR,A.SFSH AS SFSH,A.SHSFTG AS SHSFTG,A.SHBTGYY AS SHBTGYY, C.SHR AS SHR,A.SHRQ AS SHRQ,A.SHDW AS SHDW,A.SFZZ AS SFZZ,C.ZZDWDM AS ZZDWDM,A.ZZRQ AS ZZRQ,A.SFCXZZ AS SFCXZZ,A.BLSFFF AS BLSFFF,A.BLFFPH AS BLFFPH,A.BLFFDWDM AS BLFFDWDM, A.BLFFR AS BLFFR,A.BLFFRQ AS BLFFRQ,A.JSDWDM AS JSDWDM,A.JSR AS JSR,A.JSRQ AS JSRQ,A.SFFF AS SFFF,C.FFR AS FFR,A.FFDWDM AS FFDWDM,A.FFRQ AS FFRQ,B.XM AS LQR,A.LQRQ AS LQRQ,A.CXLX AS CXLX,A.CXNR AS CXNR,A.CXDW AS CXDW,A.CXR AS CXR,A.CXRQ AS CXRQ,A.SJCSPH AS SJCSPH,A.CJR AS CJR,A.CJSJ AS CJSJ,A.GXR AS GXR,A.GXSJ AS GXSJ,A.SFTH AS SFTH,A.SFZZYW AS SFZZYW,A.SFDCL AS SFDCL,A.SFCX AS SFCX,A.ZZSFCG AS ZZSFCG,A.ZZSBYY AS ZZSBYY,A.SFDZZ AS SFDZZ,A.DZZRQ AS DZZRQ,A.ZZPH AS ZZPH,A.CXZZCS AS CXZZCS,A.SLBH AS SLBH,B.GMSFHM AS LQRSFZH,A.KZZD1 AS KZZD1,A.KZZD2 AS KZZD2,A.KZZD3 AS KZZD3,A.KZZD4 AS KZZD4,A.KZZD5 AS KZZD5,A.KZZD6 AS KZZD6,C.FLAG AS FLAG,C.OPERATION AS OPERATION,C.XZQ AS XZQFROM KY_T_JZZYW_YX C, T_JZZXX_YX B, T_JZZYW_YX AWHERE A.ID = B.JZZYWIDAND A.ID = C.ID/*AND XZQ IS NOT NULL*/AND FLAG IS NULL) LOOP/***************************根据不同的操作类型,应用到新市库上***************************/BEGINIF I.OPERATION = 'DE'THEN/* DELETE FROM T_JZZ_YW@KYXX WHERE ID = I.ID;DELETE FROM T_JZZ_XX@KYXX WHERE ID = I.ID;*/NULL;ELSIF I.OPERATION = 'IN'THEN/*当t_jzzyw_yx的shsftg不为空且dqywhj为03、04、05、07、08、09、10时,如果id不存在于t_jzz_yw_sh ,就新增一条记录到t_jzz_yw_sh,如果存在,则修改*/IF I.SHR IS NOT NULL ANDI.DQYWHJ IN('03', '04'/*, '05', '07', '08', '09', '10'*/) THENINSERT INTO T_JZZ_YW_SH@KYXX(ID, SHR, SHDW, SHRQ, SHJG, SHBTGYY, CJR, CJSJ, ZHXGR, ZHXGSJ) SELECT ID, SHR, SHDW, SHRQ, SHJG, SHBTGYY, CJR, CJSJ, GXR, GXSJFROM T_JZZYW_SHWHERE ID = I.KZZD2;END IF;/*当t_jzzyw_yx的zzdwdm不为空且dqywhj为07、08、09、10时,如果id不存在于t_jzz_yw_zzxx,就新增一条记录到t_jzz_yw_zzxx,如果存在,则修改该记录*/IF I.ZZDWDM IS NOT NULL ANDI.DQYWHJ IN ('07', '08', '09'/*, '10'*/) THEN--V_ZZXXID := 'ZZXX' || ID_JZZ.NEXTVAL;INSERT INTO T_JZZ_YW_ZZXX@KYXX(ID, ZZDW, ZZRQ, ZZSFCG, ZZCWLXMC, CJR, CJSJ, ZHXGR, ZHXGSJ) SELECT ID,ZZDW,ZZRQ,ZZSFCG,ZZCWLXMC,CJR,CJSJ,ZHXGR,ZHXGSJFROM T_JZZ_YW_ZZXXWHERE ID = I.KZZD4;END IF;/* 当t_jzzyw_yx的FFR不为空且dqywhj为10时,新增一条记录到t_jzz_yw_ff*/IF I.FFR IS NOT NULL AND I.DQYWHJ = '10'THEN--V_FFID := 'FFID' || ID_JZZ.NEXTVAL;INSERT INTO T_JZZ_YW_FF@KYXX(ID, FFR, FFDW, FFSJ, LQRXM, LQRSFZH, CJR, CJSJ, ZHXGR, ZHXGSJ) VALUES(I.KZZD3,I.FFR,I.FFDWDM,I.FFRQ,I.LQR,I.LQRSFZH,I.CJR,I.CJSJ,I.GXR,I.GXSJ);END IF;INSERT INTO T_JZZ_YW@KYXX(ID,RYYWLSH,RYID,YWHJ,DQYWZT,SLLB,SLYY,SLRQ,SLDW,SLR,SFKS,SFDYLQPZ,DYLQPZSJ,SFYJF,SFZXZZ,CXRQ,CZZZCS,SLBH,CJR,CJSJ,ZHXGR,ZHXGSJ,JZZBH,XM,ZJHM,XB,CSRQ,MZ,DZ,ZZDZXZ,HZBH,JZZYXQX,JZZYXQSRQ, JZZYXJZRQ, BZRQ,JZZXPH,SFSCSB,SHENG,SHI,FWID,XIAN,ZYSCBZRQ, ZALFFJE,GBFJE,SHIJB,XZQ,JZ,FWZ,JWH,PQ,GAFJ,PCS,JDDM,MPDM,CZWBH,FWCSDZ,DWDZ,YDDH,ZZSY,DYHDZ,ZZMM,ZJXY,WHCD,QYBH,XZ,JTGJ,CPHM,LSRQ,HYZK,JHRQ,POXM,POZJLX,POZJHM,SFTZ,JSZLX,JSZHM,YZRQ,JSZYXRQ,BZ,JYZK,HDQK,CZHKSZD,QH,NANGS,NUGS,SFCB,ZY,PODZ,SG,RZRQ,FJH,ZZCS,JZFS,TBR,TBRQ,DWDH,ZZID,SHID,FFID,ZZXXID,JCID,DBID,HJDH,DQYWHJ)SELECT A.ID,A.DJBID,A.RYID,A.DQYWHJ,NVL(A.DQYWZT, '2') AS DQYWZT,A.SLLB,A.SLYY,A.SLRQ,t6.xzqmc||t6.jzmc||t6.fwzmc||t6.jwhmc||t6.cmxzmc SLDW, A.SLR,A.SFKS,A.SFDYLQPZ,A.DYLQPZRQ,A.SFYJF,A.SFCXZZ,A.CXRQ,A.CXZZCS,A.SLBH,A.CJR,A.CJSJ,A.GXR,A.GXSJ,A.SLBH,B.XM,B.GMSFHM,B.XBDM,B.CSRQ,B.MZDM,B.HJDZ,B.JZDZ,NVL(T.HZBH, T.BZ),B.YXQX,B.YXQSRQ,B.YXJZRQ,B.SLRQ,B.XPH,B.SFSCSB,SUBSTR(B.GMSFHM, 0, 2), SUBSTR(B.GMSFHM, 0, 4), B.FWID,B.HJQXDM,B.ZYSCBZRQ,B.ZALFFJE,B.GBFJE,'4406',T4.XZQDM XZQ,T4.JZDM JZ,T4.FWZDM FWZ,T4.JWHDM JWH,T4.CMXZDM PQ,T5.GAFJ,T2.PCS,T2.JLXDM JDDM,T1.MPDM,T1.DABH CZWBH,C.FWCSDZ,C.YDDH,NVL(C.ZZSY, '99'),NVL(D.DYHDZ, E.DYHDZ),COALESCE(D.ZZMM, E.ZZMM,'13'),NVL(D.ZJXY, E.ZJXY),COALESCE(D.WHCD, E.WHCD,'80'),NVL(D.DWID, E.DWID),NVL(D.HJXZ, E.HJXZ),NVL(D.JTGJ, '03') AS JTGJ,NVL(D.CPHM, E.CPHM),COALESCE(D.LSRQ, E.LSRQ,D.TBSJ,SYSDATE), COALESCE(D.HYZK, E.HYZK,'1'),NVL(D.JHRQ, E.JHRQ),NVL(D.POXM, E.POXM),NVL(D.POZJLX, E.POZJLX),NVL(D.POZJHM, E.POZJHM),NVL(D.SFTZ, E.SFTZ),NVL(D.JSZLX, E.JSZLX),NVL(D.JSZHM, E.JSZHM),NVL(D.YZRQ, E.YZRQ),NVL(D.JSZYXRQ, E.JSZYXRQ),NVL(D.BZ, E.BZ),COALESCE(D.JYZK, E.JYZK,'2'),NVL(D.HDQK, E.HDQK),NVL(D.CZHKSZD, E.CZHKSZD),NVL(D.HJQH, E.HJQH),NVL(D.NANGS, E.NANGS),NVL(D.NUGS, E.NUGS),NVL(D.SFCB, E.SFCB),NVL(D.ZY, E.ZY),NVL(D.POHJDZ, E.POHJDZ),NVL(D.SG, E.SG),NVL(D.RZRQ, E.RZRQ),NVL(D.FJH, E.FJH),NVL(D.ZZCS, '无'),COALESCE(D.JZFS, E.JZFS,'05'),NULL,NULL,NULL,NULL,I.KZZD2,I.KZZD4,NULL,NULL,NULL,(CASEWHEN A.DQYWHJ IN ('01', '02') THEN'1'WHEN A.DQYWHJ IN('03', '04', '05', '07', '08', '09') THEN'2'WHEN A.DQYWHJ = '06'THEN'8'WHEN A.DQYWHJ = '10'THEN'7'END) DQYWHJFROM T_JZZYW_YX A,T_JZZXX_YX B,T_JZZYW_QTXX_YX C,T_LDRK_DJB D,T_LDRK_DJB_ZXQK E,T_LDRK_XP T,T_FWXX T1,T_FWXX_MPXX T2,T_FWXX_JLX T3,V_XZQH_ZZJG T4,T_XZQH_QX T5,V_XZQH_ZZJG t6WHERE A.ID = B.JZZYWIDAND A.ID = C.JZZYWIDAND A.DJBID = D.ID(+)AND A.DJBID = E.ID(+)AND T.ID(+) = B.XPIDAND B.FWID = T1.IDAND T1.MPDM = T2.DMAND T2.JLXDM = T3.DMAND T2.XZQHDM = T4.DMAND T4.XZQDM = T5.DMAND a.sldwdm= t6.dmAND A.ID = I.ID;IF I.DQYWHJ = '10'THENINSERT INTO T_JZZ_XX@KYXX(ID,SLRQ,SLDW,SLR,SLBH,JZZBH,ZZDW,ZZRQ,FFR,FFDW,FFSJ,XM,ZJHM,XB,CSRQ,MZ,DZ,ZZDZXZ,HZBH,CJR,CJSJ,ZHXGR,ZHXGSJ,JZZYXQX,JZZYXQSRQ, JZZYXJZRQ, BZRQ,JZZXPH,SFSCSB,SHENG,SHI,JZZZT,FWID,XIAN,ZYSCBZRQ, SHIJB,XZQ,JZ,FWZ,JWH,PQ,GAFJ,PCS,JDDM,CZWBH,FWCSDZ, DWDZ,YDDH,ZZSY,DYHDZ,ZZMM,ZJXY,WHCD,QYBH,XZ,JTGJ,CPHM,LSRQ,HYZK,JHRQ,POXM,POZJLX, POZJHM, SFTZ,JSZLX,JSZHM,YZRQ,JSZYXRQ, BZ,JYZK,HDQK,CZHKSZD, QH,NANGS,NUGS,SFCB,ZY,PODZ,SG,RZRQ,FJH,ZZCS,JZFS,TBR,TBRQ,DWDH,HJDH,SELECT A.ID,A.RYID,A.SLRQ,t6.xzqmc||t6.jzmc||t6.fwzmc||t6.jwhmc||t6.cmxzmc SLDW,A.SLR,A.SLBH,A.SLBH,A.ZZDWDM,A.ZZRQ,A.FFR,A.FFDWDM,A.FFRQ,B.XM,B.GMSFHM,B.XBDM,B.CSRQ,B.MZDM,B.HJDZ,B.JZDZ,NVL(T.HZBH, T.BZ),B.CJR,B.CJSJ,B.GXR,B.GXSJ,B.YXQX,B.YXQSRQ,B.YXJZRQ,B.SLRQ,B.XPH,B.SFSCSB,SUBSTR(B.GMSFHM, 0, 2),SUBSTR(B.GMSFHM, 0, 4),B.JZZZT,B.FWID,B.HJQXDM,B.ZYSCBZRQ,'4406',T4.XZQDM,T4.JZDM,T4.FWZDM,T4.JWHDM,T4.CMXZDM PQ,T2.PCS,T2.JLXDM,T1.MPDM,T1.DABH,C.FWCS,C.FWCSDZ,C.YDDH,NVL(C.ZZSY, '99'),NVL(D.DYHDZ, E.DYHDZ),COALESCE(D.ZZMM, E.ZZMM,'13'),NVL(D.ZJXY, E.ZJXY),COALESCE(D.WHCD, E.WHCD,'80'),NVL(D.DWID, E.DWID),NVL(D.HJXZ, E.HJXZ),NVL(D.JTGJ, '03') AS JTGJ,NVL(D.CPHM, E.CPHM),COALESCE(D.LSRQ, E.LSRQ,D.TBSJ,SYSDATE), COALESCE(D.HYZK, E.HYZK,'1'),NVL(D.JHRQ, E.JHRQ),NVL(D.POXM, E.POXM),NVL(D.POZJLX, E.POZJLX),NVL(D.POZJHM, E.POZJHM),NVL(D.SFTZ, E.SFTZ),NVL(D.JSZLX, E.JSZLX),NVL(D.JSZHM, E.JSZHM),NVL(D.YZRQ, E.YZRQ),NVL(D.JSZYXRQ, E.JSZYXRQ),NVL(D.BZ, E.BZ),COALESCE(D.JYZK, E.JYZK,'2'),NVL(D.HDQK, E.HDQK),NVL(D.CZHKSZD, E.CZHKSZD),NVL(D.HJQH, E.HJQH),NVL(D.NANGS, E.NANGS),NVL(D.NUGS, E.NUGS),NVL(D.SFCB, E.SFCB),NVL(D.ZY, E.ZY),NVL(D.POHJDZ, E.POHJDZ),NVL(D.SG, E.SG),NVL(D.RZRQ, E.RZRQ),NVL(D.FJH, E.FJH),NVL(D.ZZCS, '无'),COALESCE(D.JZFS, E.JZFS,'05'),B.XM,NULL,NULL,NULLFROM T_JZZYW_YX A,T_JZZXX_YX B,T_JZZYW_QTXX_YX C,T_LDRK_DJB D,T_LDRK_DJB_ZXQK E,T_LDRK_XP T,T_FWXX T1,T_FWXX_MPXX T2,T_FWXX_JLX T3,V_XZQH_ZZJG T4,T_XZQH_QX T5,V_XZQH_ZZJG T6WHERE A.ID = B.JZZYWIDAND A.ID = C.JZZYWIDAND A.DJBID = D.ID(+)AND A.DJBID = E.ID(+)AND T.ID(+) = B.XPIDAND B.FWID = T1.IDAND T1.MPDM = T2.DMAND T2.JLXDM = T3.DMAND T2.XZQHDM = T4.DMAND T4.XZQDM = T5.DMAND a.sldwdm = t6.dmAND A.ID = I.ID;END IF;ELSIF I.OPERATION = 'UN'THEN/*当t_jzzyw_yx的shsftg不为空且dqywhj为03、04、05、07、08、09、10时,如果id不存在于t_jzz_yw_sh ,就新增一条记录到t_jzz_yw_sh,如果存在,则修改*/IF I.SHR IS NOT NULL ANDI.DQYWHJ IN('03', '04'/*, '05', '07', '08', '09', '10'*/) THENINSERT INTO T_JZZ_YW_SH@KYXX(ID, SHR, SHDW, SHRQ, SHJG, SHBTGYY, CJR, CJSJ, ZHXGR, ZHXGSJ) SELECT ID, SHR, SHDW, SHRQ, SHJG, SHBTGYY, CJR, CJSJ, GXR, GXSJFROM T_JZZYW_SHWHERE ID = I.KZZD2;END IF;/*当t_jzzyw_yx的zzdwdm不为空且dqywhj为07、08、09、10时,如果id不存在于t_jzz_yw_zzxx,就新增一条记录到t_jzz_yw_zzxx,如果存在,则修改该记录*/IF I.ZZDWDM IS NOT NULL ANDI.DQYWHJ IN ('07', '08', '09'/*, '10'*/) THEN--V_ZZXXID := 'ZZXX' || ID_JZZ.NEXTVAL;INSERT INTO T_JZZ_YW_ZZXX@KYXX(ID, ZZDW, ZZRQ, ZZSFCG, ZZCWLXMC, CJR, CJSJ, ZHXGR, ZHXGSJ) SELECT ID,ZZDW,ZZRQ,ZZSFCG,ZZCWLXMC,CJR,CJSJ,ZHXGR,ZHXGSJFROM T_JZZ_YW_ZZXXWHERE ID = I.KZZD4;END IF;/* 当t_jzzyw_yx的FFR不为空且dqywhj为10时,新增一条记录到t_jzz_yw_ff*/IF I.FFR IS NOT NULL AND I.DQYWHJ = '10'THEN--V_FFID := 'FFID' || ID_JZZ.NEXTVAL;INSERT INTO T_JZZ_YW_FF@KYXX(ID, FFR, FFDW, FFSJ, LQRXM, LQRSFZH, CJR, CJSJ, ZHXGR, ZHXGSJ) VALUES(I.KZZD3,I.FFR,I.FFDWDM,I.FFRQ,I.LQR,I.LQRSFZH,I.CJR,I.CJSJ,I.GXR,I.GXSJ);END IF;UPDATE T_JZZ_YW@KYXXSET (ID,RYYWLSH,RYID,YWHJ,DQYWZT,SLLB,SLYY,SLRQ,SLDW,SLR,SFKS,SFDYLQPZ,DYLQPZSJ,SFYJF,SFZXZZ,CXRQ,CZZZCS,SLBH,CJR,CJSJ,ZHXGR,ZHXGSJ,JZZBH,XM,ZJHM,XB,CSRQ,MZ,DZ,ZZDZXZ,HZBH,JZZYXQX,JZZYXQSRQ,JZZYXJZRQ,BZRQ,JZZXPH,SFSCSB,SHENG,SHI,FWID,ZYSCBZRQ, ZALFFJE, GBFJE,SHIJB,XZQ,JZ,FWZ,JWH,PQ,GAFJ,PCS,JDDM,MPDM,CZWBH,FWCSDZ,DWDZ,YDDH,ZZSY,DYHDZ,ZZMM,ZJXY,WHCD,QYBH,XZ,JTGJ,CPHM,LSRQ,HYZK,JHRQ,POXM,POZJLX,POZJHM,SFTZ,JSZLX,JSZHM,YZRQ,JSZYXRQ, BZ,JYZK,HDQK,CZHKSZD, QH,NANGS,SFCB,ZY,PODZ,SG,RZRQ,FJH,ZZCS,JZFS,TBR,TBRQ,DWDH,ZZID,SHID,FFID,ZZXXID,JCID,DBID,HJDH,DQYWHJ) =(SELECT A.ID,A.DJBID,A.RYID,A.DQYWHJ,NVL(A.DQYWZT, '2') AS DQYWZT,A.SLLB,A.SLYY,A.SLRQ,t6.xzqmc||t6.jzmc||t6.fwzmc||t6.jwhmc||t6.cmxzmc SLDW,A.SLR,A.SFKS,A.SFDYLQPZ,A.DYLQPZRQ,A.SFYJF,A.SFCXZZ,A.CXRQ,A.CXZZCS,A.SLBH,A.CJR,A.CJSJ,A.GXR,A.GXSJ,A.SLBH,B.XM,B.GMSFHM,B.XBDM,B.CSRQ,B.MZDM,B.HJDZ,B.JZDZ,NVL(T.HZBH, T.BZ),B.YXQX,B.YXQSRQ,B.YXJZRQ,B.SLRQ,B.XPH,B.SFSCSB,SUBSTR(B.GMSFHM, 0, 2),SUBSTR(B.GMSFHM, 0, 4),B.FWID,B.HJQXDM,B.ZYSCBZRQ,B.ZALFFJE,B.GBFJE,'4406',T4.XZQDM XZQ,T4.JZDM JZ,T4.FWZDM FWZ,T4.JWHDM JWH,T4.CMXZDM PQ,T5.GAFJ,T2.PCS,T2.JLXDM JDDM,T1.MPDM,T1.DABH CZWBH,C.FWCS,C.FWCSDZ,C.YDDH,NVL(C.ZZSY, '99'),NVL(D.DYHDZ, E.DYHDZ),COALESCE(D.ZZMM, E.ZZMM,'13'), NVL(D.ZJXY, E.ZJXY),COALESCE(D.WHCD, E.WHCD,'80'), NVL(D.DWID, E.DWID),NVL(D.HJXZ, E.HJXZ),NVL(D.JTGJ, '03') AS JTGJ,NVL(D.CPHM, E.CPHM),COALESCE(D.LSRQ, E.LSRQ,D.TBSJ,SYSDATE),COALESCE(D.HYZK, E.HYZK,'1'),NVL(D.JHRQ, E.JHRQ),NVL(D.POXM, E.POXM),NVL(D.POZJLX, E.POZJLX),NVL(D.POZJHM, E.POZJHM),NVL(D.SFTZ, E.SFTZ),NVL(D.JSZLX, E.JSZLX),NVL(D.JSZHM, E.JSZHM),NVL(D.YZRQ, E.YZRQ),NVL(D.JSZYXRQ, E.JSZYXRQ),NVL(D.BZ, E.BZ),COALESCE(D.JYZK, E.JYZK,'2'),NVL(D.HDQK, E.HDQK),NVL(D.CZHKSZD, E.CZHKSZD),NVL(D.HJQH, E.HJQH),NVL(D.NANGS, E.NANGS),NVL(D.NUGS, E.NUGS),NVL(D.SFCB, E.SFCB),NVL(D.ZY, E.ZY),NVL(D.POHJDZ, E.POHJDZ),NVL(D.SG, E.SG),NVL(D.RZRQ, E.RZRQ),NVL(D.FJH, E.FJH),NVL(D.ZZCS, '无'),COALESCE(D.JZFS, E.JZFS,'05'),NULL,NULL,NULL,NULL,I.KZZD2,I.KZZD3,I.KZZD4,NULL,NULL,NULL,(CASEWHEN A.DQYWHJ IN ('01', '02') THEN'1'WHEN A.DQYWHJ IN('03', '04', '05', '07', '08', '09') THEN'2'WHEN A.DQYWHJ = '06'THEN'8'WHEN A.DQYWHJ = '10'THEN'7'END) DQYWHJFROM T_JZZYW_YX A,T_JZZXX_YX B,T_JZZYW_QTXX_YX C,T_LDRK_DJB D,T_LDRK_DJB_ZXQK E,T_LDRK_XP T,T_FWXX T1,T_FWXX_MPXX T2,T_FWXX_JLX T3,V_XZQH_ZZJG T4,T_XZQH_QX T5,v_xzqh_zzjg t6WHERE A.ID = B.JZZYWIDAND A.ID = C.JZZYWIDAND A.DJBID = D.ID(+)AND A.DJBID = E.ID(+)AND T.ID(+) = B.XPIDAND B.FWID = T1.IDAND T1.MPDM = T2.DMAND T2.JLXDM = T3.DMAND T2.XZQHDM = T4.DMAND T4.XZQDM = T5.DMAND a.sldwdm = t6.dmAND A.ID = I.ID)WHERE ID = I.ID;IF I.DQYWHJ = '10'THENINSERT INTO T_JZZ_XX@KYXX(ID,RYID,SLRQ,SLDW,SLR,SLBH,JZZBH,ZZDW,ZZRQ,FFR,FFDW,XM,ZJHM,XB,CSRQ,MZ,DZ,ZZDZXZ,HZBH,CJR,CJSJ,ZHXGR,ZHXGSJ,JZZYXQX,JZZYXQSRQ, JZZYXJZRQ, BZRQ,JZZXPH,SFSCSB,SHENG,SHI,JZZZT,FWID,XIAN,ZYSCBZRQ, SHIJB,XZQ,JZ,FWZ,JWH,PQ,GAFJ,PCS,JDDM,MPDM,CZWBH,FWCSDZ,DWDZ,YDDH,ZZSY,DYHDZ,ZZMM,ZJXY,WHCD,XZ,JTGJ,CPHM,LSRQ,HYZK,JHRQ,POXM,POZJLX,POZJHM,SFTZ,JSZLX,JSZHM,YZRQ,JSZYXRQ,BZ,JYZK,HDQK,CZHKSZD,QH,NANGS,NUGS,SFCB,ZY,PODZ,SG,RZRQ,FJH,ZZCS,JZFS,TBR,TBRQ,DWDH,HJDH,ZXBZ)SELECT A.ID,A.RYID,A.SLRQ,t6.xzqmc||t6.jzmc||t6.fwzmc||t6.jwhmc||t6.cmxzmc SLDW,A.SLR,A.SLBH,A.SLBH,A.ZZDWDM,A.ZZRQ,A.FFR,A.FFDWDM,A.FFRQ,B.XM,B.GMSFHM,B.XBDM,B.CSRQ,B.MZDM,B.HJDZ,B.JZDZ,NVL(T.HZBH, T.BZ),B.CJR,B.CJSJ,B.GXR,B.GXSJ,B.YXQX,B.YXQSRQ,B.YXJZRQ,B.SLRQ,B.XPH,B.SFSCSB,SUBSTR(B.GMSFHM, 0, 2), SUBSTR(B.GMSFHM, 0, 4), B.JZZZT,B.FWID,B.HJQXDM,B.ZYSCBZRQ,'4406',T4.XZQDM,T4.JZDM,T4.FWZDM,T4.JWHDM,T4.CMXZDM PQ,T5.GAFJ,T2.PCS,T2.JLXDM,T1.MPDM,T1.DABH,C.FWCS,C.FWCSDZ,C.YDDH,NVL(C.ZZSY, '99'),NVL(D.DYHDZ, E.DYHDZ),COALESCE(D.ZZMM, E.ZZMM,'13'),NVL(D.ZJXY, E.ZJXY),COALESCE(D.WHCD, E.WHCD,'80'),NVL(D.DWID, E.DWID),NVL(D.HJXZ, E.HJXZ),NVL(D.JTGJ, '03') AS JTGJ,NVL(D.CPHM, E.CPHM),COALESCE(D.LSRQ, E.LSRQ,D.TBSJ,SYSDATE), COALESCE(D.HYZK, E.HYZK,'1'),NVL(D.JHRQ, E.JHRQ),NVL(D.POXM, E.POXM),NVL(D.POZJLX, E.POZJLX),NVL(D.POZJHM, E.POZJHM),NVL(D.SFTZ, E.SFTZ),NVL(D.JSZLX, E.JSZLX),NVL(D.JSZHM, E.JSZHM),NVL(D.YZRQ, E.YZRQ),NVL(D.JSZYXRQ, E.JSZYXRQ),NVL(D.BZ, E.BZ),COALESCE(D.JYZK, E.JYZK,'2'),NVL(D.HDQK, E.HDQK),NVL(D.CZHKSZD, E.CZHKSZD),NVL(D.HJQH, E.HJQH),NVL(D.NANGS, E.NANGS),NVL(D.NUGS, E.NUGS),NVL(D.SFCB, E.SFCB),NVL(D.ZY, E.ZY),NVL(D.POHJDZ, E.POHJDZ),NVL(D.SG, E.SG),NVL(D.RZRQ, E.RZRQ),NVL(D.FJH, E.FJH),NVL(D.ZZCS, '无'),COALESCE(D.JZFS, E.JZFS,'05'),B.XM,B.SLRQ,NULL,NULL,NULLFROM T_JZZYW_YX A,T_JZZXX_YX B,T_JZZYW_QTXX_YX C,T_LDRK_DJB D,T_LDRK_DJB_ZXQK E,T_LDRK_XP T,T_FWXX T1,T_FWXX_MPXX T2,T_FWXX_JLX T3,V_XZQH_ZZJG T4,T_XZQH_QX T5,V_XZQH_ZZJG T6WHERE A.ID = B.JZZYWIDAND A.ID = C.JZZYWIDAND A.DJBID = D.ID(+)AND A.DJBID = E.ID(+)AND T.ID(+) = B.XPIDAND B.FWID = T1.IDAND T1.MPDM = T2.DMAND T2.JLXDM = T3.DMAND T2.XZQHDM = T4.DMAND T4.XZQDM = T5.DMAND a.sldwdm = t6.dmAND A.ID = I.ID;END IF;END IF;/*打上标志,确认该条数据已经转换成功*/UPDATE KY_T_JZZYW_YX SET FLAG = 'Y'WHERE ID = I.ID;EXCEPTIONWHEN OTHERS THENROLLBACK;V_ERRORS := SUBSTR(SQLERRM, 1, 200);UPDATE KY_T_JZZYW_YX SET FLAG = 'N'WHERE ID = I.ID;INSERT INTO T_ERROR_LOG_TOOLD(TYPE, ERRORMSG, XRSJ, YWID)VALUES(C_TABLE_NAME, V_ERRORS, SYSDATE, I.ID);END;COMMIT;END LOOP;/*删除OPERATION='DE'的数据*/UPDATE KY_T_JZZYW_YX SET FLAG = 'Y'WHERE OPERATION = 'DE';DELETE FROM T_JZZ_YW@KYXXWHERE ID IN (SELECT ID FROM KY_T_JZZYW_YX A WHERE OPERATION = 'DE');DELETE FROM T_JZZ_XX@KYXXWHERE ID IN (SELECT ID FROM KY_T_JZZYW_YX A WHERE OPERATION = 'DE'); COMMIT;/*把已经转换到新库的数据放到历史表中,进行归档*/INSERT INTO KY_T_JZZYW_YX_GD(ID,DJBID,RYID,DQYWHJ,DQYWZT,SLLB,SLYY,SLRQ,SLDWDM,SLR,SFKS,SFDYLQPZ,DYLQPZRQ,SFYJF,HZBH,HZFFRQ,HZFFR,SFSH,SHSFTG,SHBTGYY,SHR,SHRQ,SHDW,SFZZ,ZZDWDM,ZZRQ,SFCXZZ,BLSFFF,BLFFPH,BLFFDWDM,BLFFR,BLFFRQ,JSDWDM,JSR,JSRQ,SFFF,FFR,FFDWDM,FFRQ,LQR,LQRQ,CXLX,CXNR,CXDW,CXR,CXRQ,BZ,SJCSPH,CJR,CJSJ,GXR,GXSJ,SFTH,SFZZYW,SFDCL,SFCX,ZZSFCG,ZZSBYY,SFDZZ,DZZRQ,ZZPH,CXZZCS,SLBH,LQRSFZH,KZZD1,KZZD2,KZZD3,KZZD4,KZZD5,KZZD6,FLAG,OPERATION, XZQ,XRSJ)SELECT ID,DJBID,RYID,DQYWHJ,DQYWZT,SLLB,SLYY,SLRQ,SLDWDM,SLR,SFKS,SFDYLQPZ, DYLQPZRQ, SFYJF,HZBH,HZFFRQ,HZFFR,SFSH,SHSFTG,SHBTGYY, SHR,SHRQ,SHDW,SFZZ,ZZDWDM,ZZRQ,SFCXZZ,BLSFFF,BLFFPH,BLFFDWDM, BLFFR,BLFFRQ,JSDWDM,JSR,JSRQ,SFFF,FFR,FFDWDM,FFRQ,LQR,LQRQ,CXLX,CXNR,CXDW,CXR,CXRQ,BZ,SJCSPH,CJR,CJSJ,GXR,GXSJ,SFTH,SFZZYW,SFDCL,SFCX,ZZSFCG,ZZSBYY,SFDZZ,DZZRQ,ZZPH,CXZZCS,SLBH,LQRSFZH,KZZD1,KZZD2,KZZD3,KZZD4,KZZD5,KZZD6,FLAG,OPERATION,XZQ,SYSDATEFROM KY_T_JZZYW_YXWHERE FLAG = 'Y';DELETE FROM KY_T_JZZYW_YX WHERE FLAG = 'Y'; COMMIT;END TOOLD_T_JZZYW_YX_ALL;。
oracle⽆参数和带参数的存储过程实例SQL中调⽤存储过程语句:call procedure_name();注:调⽤时”()”是不可少的,⽆论是有参数还是⽆参数.定义对数据库存储过程的调⽤时1、⽆参数存储过程:{call procedure_name}2、仅有输⼊参数的存储过程:{call procedure_name(?,?...)}。
这⾥?表⽰输⼊参数,创建存储过程时⽤in表⽰输⼊参数3、仅有输出参数的存储过程:{call procedure_name(?,?...)}。
这⾥的?表⽰输出参数,创建存储过程时⽤out表⽰输出参数4、既有输⼊参数⼜有输出参数的存储过程{call procedure_name(?,?...)}。
这⾥的?有表⽰输出参数的,也有表⽰输⼊参数的下⾯将会对这4种情况分别举出实例!!!1、⽆参数存储过程CREATE OR REPLACE PROCEDURE stu_proc AS--声明语句段v_name VARCHAR2(20);BEGIN--执⾏语句段SELECT o.sname INTO v_name FROM student o WHERE o.id=4;dbms_output.put_line(v_name);EXCEPTION--异常处理语句段WHEN NO_DATA_FOUND THEN dbms_output.put_line('NO_DATA_FOUND');END;2、仅带⼊参的存储过程CREATE OR REPLACE PROCEDURE stu_proc(v_id IN student.id%type) AS--声明语句段v_name varchar2(20);BEGIN--执⾏语句段SELECT o.sname INTO v_name FROM student o where o.id=v_id;dbms_output.put_line(v_name);EXCEPTION--异常处理语句段WHEN NO_DATA_FOUND THEN dbms_output.put_line('NO_DATA_FOUND');END;3、仅带出参的存储过程--此种存储过程不能直接⽤call来调⽤,这种情况的调⽤将在下⾯oracle函数调⽤中说明CREATE OR REPLACE PROCEDURE stu_proc(v_name OUT student.sname%type) AS--声明语句段BEGIN--执⾏语句段SELECT o.sname INTO v_name FROM student o where o.id=1;dbms_output.put_line(v_name);EXCEPTION--异常处理语句段WHEN NO_DATA_FOUND THEN dbms_output.put_line('NO_DATA_FOUND');END;4、带⼊参和出参的存储过程--此种存储过程不能直接⽤call来调⽤,这种情况的调⽤将在下⾯oracle函数调⽤中说明CREATE OR REPLACE PROCEDURE stu_proc(v_id IN student.id%type, v_name OUT student.sname%type) AS --声明语句段BEGIN--执⾏语句段SELECT o.sname INTO v_name FROM student o where o.id=v_id;dbms_output.put_line(v_name);EXCEPTION--异常处理语句段WHEN NO_DATA_FOUND THEN dbms_output.put_line('NO_DATA_FOUND'); END;。
存储过程1.定义:将常用的或很复杂的工作,预先用SQL语句写好并用一个指定的名称存储起来, 那么以后要叫数据库提供与已定义好的存储过程的功能相同的服务时,只需调用execute,即可自动完成命令。
CREATE PR OCEDURE procedure_name 或者Create proc procedure_name优点1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3.存储过程可以重复使用,可减少数据库开发人员的工作量4.安全性高,可设定只有某此用户才具有对指定存储过程的使用权2.参数,输入参数,输出参数、@parameter_name1 int, //输入参数定义,包括名称,类型及长度@parameter_name2= defual_value varchar(80) //输入参数,带默认值@parameter_out int output //输出的参数AS //as后面部分是存储过程具体内容3.内部参数定义,定义方式如2,需定义名称及,类型,长度Declare@Parameter_inter1 int,@Parameter_inter2 varchar(30)4.初始化内部参数:Set @Parameter_inter1 =5, //可以取得需要的值以存在內部参数中:SELECT @parameter_inter2=table.column FROM table WHERE …….5.具体操作语句,一般都包括以下几种流程控制语句(if else | select case | while ):===============Select ... CASE(多条件)实例:============DECLARE @iRet INT, @PKDisp VARCHAR(20)SET @iRet = '1'Select @iRet =CASEWHEN @PKDisp = '一' THEN 1WHEN @PKDisp = '二' THEN 2WHEN @PKDisp = '三' THEN 3WHEN @PKDisp = '四' THEN 4WHEN @PKDisp = '五' THEN 5ELSE 100END========== While(循环)实例:====================DECLARE @i INTSET @i = 1WHILE @i<1000000BEGINset @i=@i+1 //更改条件,比做END-- 打印 PRINT @i============= If(单条件)处理例子:================IF @strTO<>'' //条件BEGINUPDATE UNIT SET UNIT_NAME=REPLACE(UNIT_NAME,'*','')WHERE UNIT_CODE=@strTOENDELSE BEGINUPDATE UNIT SET UNIT_NAME=UNIT_NAME+'*' WHERE UNIT_CODE='011'END6.最后是:Go使用存储过程:Execute procedure_name带参数为:Execute procedure_name ‘parameter1_value’,’paramerter2_ value’或者:Exec procedure_name paramerter1=’parameter1_value’,parameter2=’ paramerter2_ value’Eg:该存储过程一共有7个参数,其中最后一个参数的OUTPUT,用于返回一共得页数set ANSI_NULLS ONset QUOTED_IDENTIFIER ONgoALTER PR OCEDURE [dbo].[PagingProc]@PageIndex INT, --当前页码从0开始@PageSize INT, --每页的大小@TableName NVARCHAR(100), --表名称@Orders NVARCHAR(100), --排序@Columns NVARCHAR(100), --需要检索的列集合,中间用英文逗号隔开e.g.:ID,NAME@Filters NVARCHAR(100), --过滤条件语句@TotalPages INT OUTPUTASBEGINDECLARE @SQL NVARCHAR(200) --查询当前页所有记录的sql语句DECLARE @PAGESSQL NVARCHAR(200) --查询行数的sql语句DECLARE @TOTALCOUNT INT --一共得行数,用于计算所总页数SET NOCOUNT ONIF @Filters <> ''SET @PAGESSQL = 'SELECT @TOTALCOUNT = COUNT(*) FROM ' + @TableName + ' WHERE ' + @Filters ELSESET @PAGESSQL = 'SELECT @TOTALCOUNT = COUNT(*) FROM ' + @TableNameEXEC SP_EXECUTESQL @PAGESSQL, N'@TOTALCOUNT INT OUT',@TOTALCOUNT OUTSET @TotalPages = Ceiling(CONVERT(REAL,@TOTALCOUNT) / CONVERT(REAL,@PageSize))--计算页数SET @SQL='SELECT TOP ' + CAST(@PageSize as varchar(10)) + ' ' + @Columns + ' FROM ' + @TableName + ' WHERE ID NOT IN(SELECT TOP ' + CAST(@PageIndex * @PageSize as varchar(10)) + ' IDFROM ' + @TableNameIF @Filters <> ''SET @SQL = @SQL + ' WHERE ' + @FiltersIF @Orders <> ''SET @SQL = @SQL + ' ORDER BY ' + @ORDERSSET @SQL = @SQL + ')'IF @Filters <> ''SET @SQL = @SQL + ' AND ' + @FiltersIF @Orders <> ''SET @SQL = @SQL + ' ORDER BY ' + @ORDERSEXEC(@SQL)END下面是C#代码using System;using System.Collections.Generic;using System.Linq;using System.Text;namespace PagingProcedure{class Program{static void Main(string[] args){System.Data.SqlClient.SqlConnection conn = new System.Data.SqlClient.SqlConnection();conn.ConnectionString = @"Data Source=.\SQLEXPRESS;Initial Catalog=Rap_Kevin;Integrated Security=True;";System.Data.SqlClient.SqlCommand cmd = conn.CreateCommand();mandText = "pagingproc";mandType = mandType.StoredProcedure;cmd.Parameters.Add(new System.Data.SqlClient.SqlParameter("@PageIndex", System.Data.SqlDbType.Int));cmd.Parameters["@PageIndex"].Value = 0;cmd.Parameters.Add(new System.Data.SqlClient.SqlParameter("@PageSize", System.Data.SqlDbType.Int));cmd.Parameters["@PageSize"].Value = 5;cmd.Parameters.Add(new System.Data.SqlClient.SqlParameter("@TableName", System.Data.SqlDbType.VarChar, 100)); cmd.Parameters["@TableName"].Value = "Sells";cmd.Parameters.Add(new System.Data.SqlClient.SqlParameter("@Orders", System.Data.SqlDbType.VarChar, 100));cmd.Parameters["@Orders"].Value = "LastModifyTime DESC";cmd.Parameters.Add(new System.Data.SqlClient.SqlParameter("@Columns", System.Data.SqlDbType.VarChar, 100)); cmd.Parameters["@Columns"].Value = "*";cmd.Parameters.Add(new System.Data.SqlClient.SqlParameter("@Filters", System.Data.SqlDbType.VarChar, 100));cmd.Parameters["@Filters"].Value = "";cmd.Parameters.Add(new System.Data.SqlClient.SqlParameter("@TotalPages", System.Data.SqlDbType.Int));cmd.Parameters["@TotalPages"].Value = 0;cmd.Parameters["@TotalPages"].Direction = System.Data.ParameterDirection.InputOutput;conn.Open();System.Data.SqlClient.SqlDataReader reader = cmd.ExecuteReader();while (reader.Read()){System.Console.WriteLine((Guid)reader[0]);}reader.Close();System.Console.WriteLine(cmd.Parameters["@TotalPages"].Value);conn.Close();}}}SQL SERVER存储过程存储过程的种类:1.系统存储过程:以sp_开头,用来进行系统的各项设定.取得信息.相关管理工作,如sp_help就是取得指定对象的相关信息2.扩展存储过程以XP_开头,用来调用操作系统提供的功能exec master..xp_cmdshell 'ping 10.8.16.1'3.用户自定义的存储过程,这是我们所指的存储过程常用格式Create PR OCEDURE procedue_name[@parameter data_type][output][with]{recompile|encryption}asql_statement解释:output:表示此参数是可传回的with {recompile|encryption}recompile:表示每次执行此存储过程时都重新编译一次encryption:所创建的存储过程的内容会被加密如:表book的内容如下编号书名价格001 C语言入门$30002 PowerBuilder报表开发$52实例1:查询表Book的内容的存储过程create proc query_bookasselect * from bookgoexec query_book实例2: 加入一笔记录到表book,并查询此表中所有书籍的总金额Create proc insert_book@param1 char(10),@param2 varchar(20),@param3 money,@param4 money outputwith encryption ---------加密asinsert book(编号,书名,价格)Values(@param1,@param2,@param3)select @param4=sum(价格) from bookgo执行例子:declare @total_price moneyexec insert_book '003','Delphi 控件开发指南',$100,@total_priceprint '总金额为'+convert(varchar,@total_price)go存储过程的3种传回值:1.以Return传回整数2.以output格式传回参数3.Recordset传回值的区别:output和return都可在批次程式中用变量接收,而recordset则传回到执行批次的客户端中实例3:设有两个表为Product,Order,其表内容如下:Product产品编号产品名称客户订数001 钢笔30002 毛笔50003 铅笔100Order产品编号客户名客户订金001 南山区$30002 罗湖区$50003 宝安区$4请实现按编号为连接条件,将两个表连接成一个临时表,该表只含编号.产品名.客户名.订金.总金额,总金额=订金*订数,临时表放在存储过程中代码如下:Create proc temp_saleasselect a.产品编号,a.产品名称,b.客户名,b.客户订金,a.客户订数* b.客户订金as总金额into #temptable from Product a inner join Order b on a.产品编号=b.产品编号if @@error=0print 'Good'elseprint 'Fail'后台运行一个主存储过程,主存储过程通过管道同前端过程通信的例子beginmaX PR o为提交主存储过程起动的程序maxpro 为主存储过程readmaxpro 为主存佳话使用Oracle中的DBMS_P ip E管道能力,注重要明文给于用户EXECUTE ANY PROCEDURE 权力才可以在sqlpus用设定set serveroutput ON 进行测试通过@testmaxpro.sql 创始程序包测试过程如下SQL> call beginmaxpro();JOB=62调用完成。
sqlserver存储过程例子SQL Server是一种关系型数据库管理系统,它支持存储过程,存储过程是一组预编译的SQL语句,可以接收参数并返回结果。
它可以用于实现复杂的业务逻辑,提高数据库的性能和安全性。
下面列举了10个符合要求的存储过程例子。
1. 查询指定部门的员工数量该存储过程接收部门ID作为参数,然后使用COUNT函数查询该部门的员工数量,并返回结果。
2. 插入新员工信息该存储过程接收员工的姓名、部门ID等信息作为参数,然后使用INSERT语句将员工信息插入到数据库中。
3. 更新员工信息该存储过程接收员工ID和要更新的信息作为参数,然后使用UPDATE语句将指定员工的信息更新到数据库中。
4. 删除员工信息该存储过程接收员工ID作为参数,然后使用DELETE语句将指定员工的信息从数据库中删除。
5. 查询员工薪水排名该存储过程使用RANK函数查询员工薪水排名,并返回结果。
6. 查询员工平均薪水该存储过程使用AVG函数计算员工的平均薪水,并返回结果。
7. 查询员工工资总和该存储过程使用SUM函数计算员工的工资总和,并返回结果。
8. 查询员工工龄该存储过程使用DATEDIFF函数计算员工的工龄,并返回结果。
9. 查询员工信息及其所在部门名称该存储过程使用JOIN语句连接员工表和部门表,查询员工信息及其所在部门名称,并返回结果。
10. 查询员工信息及其直接上级该存储过程使用自连接查询,查询员工信息及其直接上级的信息,并返回结果。
以上是10个符合要求的SQL Server存储过程例子。
它们可以用于实现各种不同的业务逻辑,提高数据库的性能和安全性。
通过合理使用存储过程,可以减少重复的代码编写,提高开发效率,同时还可以提高系统的可维护性和可扩展性。
存储过程如同一门程序设计语言,同样包含了数据类型、流程控制、输入和输出和它自己的函数库。
--------------------基本语法--------------------一.创建存储过程create procedure sp_name()begin.........end二.调用存储过程1.基本语法:call sp_name()注意:存储过程名称后面必须加括号,哪怕该存储过程没有参数传递三.删除存储过程1.基本语法:drop procedure sp_name//2.注意事项(1)不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程四.其他常用命令1.show procedure status显示数据库中所有存储的存储过程基本信息,包括所属数据库,存储过程名称,创建时间等2.show create procedure sp_name显示某一个mysql存储过程的详细信息--------------------数据类型及运算符--------------------一、基本数据类型:略二、变量:自定义变量:DECLARE a INT ; SET a=100; 可用以下语句代替:DECLARE a INT DEFAULT 100;变量分为用户变量和系统变量,系统变量又分为会话和全局级变量用户变量:用户变量名一般以@开头,滥用用户变量会导致程序难以理解及管理1、在mysql客户端使用用户变量mysql> SELECT 'Hello World' into @x;mysql> SELECT @x;mysql> SET @y='Goodbye Cruel World';mysql> select @y;mysql> SET @z=1+2+3;mysql> select @z;2、在存储过程中使用用户变量mysql> CREATE PROCEDURE GreetWorld( ) SELECT CONCAT(@greeting,' World'); mysql> SET @greeting='Hello';mysql> CALL GreetWorld( );3、在存储过程间传递全局范围的用户变量mysql> CREATE PROCEDURE p1( ) SET @last_procedure='p1'; mysql> CREATE PROCEDURE p2( ) SELECT CONCAT('Last procedure was ',@last_procedure);mysql> CALL p1( );mysql> CALL p2( );三、运算符:1.算术运算符+ 加 SET var1=2+2; 4- 减 SET var2=3-2; 1* 乘 SET var3=3*2; 6/ 除 SET var4=10/3; 3.3333DIV 整除 SET var5=10 DIV 3; 3% 取模 SET var6=10%3 ; 12.比较运算符> 大于 1>2 False< 小于 2<1 False<= 小于等于 2<=2 True>= 大于等于 3>=2 TrueBETWEEN 在两值之间 5 BETWEEN 1 AND 10 TrueNOT BETWEEN 不在两值之间 5 NOT BETWEEN 1 AND 10 FalseIN 在集合中 5 IN (1,2,3,4) FalseNOT IN 不在集合中 5 NOT IN (1,2,3,4) True= 等于 2=3 False<>, != 不等于 2<>3 False<=> 严格比较两个NULL值是否相等 NULL<=>NULL TrueLIKE 简单模式匹配 "Guy Harrison" LIKE "Guy%" TrueREGEXP 正则式匹配 "Guy Harrison" REGEXP "[Gg]reg" FalseIS NULL 为空 0 IS NULL FalseIS NOT NULL 不为空 0 IS NOT NULL True3.逻辑运算符4.位运算符| 或& 与<< 左移位>> 右移位~ 非(单目运算,按位取反)注释:mysql存储过程可使用两种风格的注释双横杠:--该风格一般用于单行注释c风格:/* 注释内容 */ 一般用于多行注释--------------------流程控制--------------------一、顺序结构二、分支结构ifcase三、循环结构for循环while循环loop循环repeat until循环注:区块定义,常用begin......end;也可以给区块起别名,如:lable:begin...........end lable;可以用leave lable;跳出区块,执行区块以后的代码begin和end如同C语言中的{ 和 }。
--------------------输入和输出--------------------mysql存储过程的参数用在存储过程的定义,共有三种参数类型,IN,OUT,INOUT Create procedure|function([[IN |OUT |INOUT ] 参数名数据类形...])IN 输入参数表示该参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值OUT 输出参数该值可在存储过程内部被改变,并可返回INOUT 输入输出参数调用时指定,并且可被改变和返回IN参数例子:CREATE PROCEDURE sp_demo_in_parameter(IN p_in INT)BEGINSELECT p_in; --查询输入参数SET p_in=2; --修改select p_in;--查看修改后的值END;执行结果:mysql> set @p_in=1mysql> call sp_demo_in_parameter(@p_in)略mysql> select @p_in;略以上可以看出,p_in虽然在存储过程中被修改,但并不影响@p_id的值OUT参数例子创建:mysql> CREATE PROCEDURE sp_demo_out_parameter(OUT p_out INT)BEGINSELECT p_out;/*查看输出参数*/SET p_out=2;/*修改参数值*/SELECT p_out;/*看看有否变化*/END;执行结果:mysql> SET @p_out=1mysql> CALL sp_demo_out_parameter(@p_out)略mysql> SELECT @p_out;略INOUT参数例子:mysql> CREATE PROCEDURE sp_demo_inout_parameter(INOUT p_inout INT) BEGINSELECT p_inout;SET p_inout=2;SELECT p_inout;END;执行结果:set @p_inout=1call sp_demo_inout_parameter(@p_inout) //略select @p_inout;略附:函数库mysql存储过程基本函数包括:字符串类型,数值类型,日期类型一、字符串类CHARSET(str) //返回字串字符集CONCAT (string2 [,… ]) //连接字串INSTR (string ,substring ) //返回substring首次在string中出现的位置,不存在返回0 LCASE (string2 ) //转换成小写LEFT (string2 ,length ) //从string2中的左边起取length个字符LENGTH (string ) //string长度LOAD_FILE (file_name ) //从文件读取内容LOCATE (substring , string [,start_position ] ) 同INSTR,但可指定开始位置LPAD (string2 ,length ,pad ) //重复用pad加在string开头,直到字串长度为length LTRIM (string2 ) //去除前端空格REPEAT (string2 ,count ) //重复count次REPLACE (str ,search_str ,replace_str ) //在str中用replace_str替换search_str RPAD (string2 ,length ,pad) //在str后用pad补充,直到长度为lengthRTRIM (string2 ) //去除后端空格STRCMP (string1 ,string2 ) //逐字符比较两字串大小,SUBSTRING (str , position [,length ]) //从str的position开始,取length个字符, 注:mysql中处理字符串时,默认第一个字符下标为1,即参数position必须大于等于1 mysql> select substr ing(’abcd’,0,2);+———————–+| substring(’abcd’,0,2) |+———————–+| |+———————–+1 row in set (0.00 sec)mysql> select substring(’abcd’,1,2);+———————–+| substring(’abcd’,1,2) |+———————–+| ab |+———————–+1 row in set (0.02 sec)TRIM([[BOTH|LEADING|TRAILING] [padding] FROM]string2) //去除指定位置的指定字符UCASE (string2 ) //转换成大写RIGHT(string2,length) //取string2最后length个字符SPACE(count) //生成count个空格二、数值类型ABS (number2 ) //绝对值BIN (decimal_number ) //十进制转二进制CEILING (number2 ) //向上取整CONV(number2,from_base,to_base) //进制转换FLOOR (number2 ) //向下取整FORMAT (number,decimal_places ) //保留小数位数HEX (DecimalNumber ) //转十六进制注:HEX()中可传入字符串,则返回其ASC-11码,如HEX(’DEF’)返回4142143也可以传入十进制整数,返回其十六进制编码,如HEX(25)返回19LEAST (number , number2 [,..]) //求最小值MOD (numerator ,denominator ) //求余POWER (number ,power ) //求指数RAND([seed]) //随机数ROUND (number [,decimals ]) //四舍五入,decimals为小数位数]注:返回类型并非均为整数,如:(1)默认变为整形值mysql> select round(1.23);+————-+| round(1.23) |+————-+| 1 |+————-+1 row in set (0.00 sec)mysql> select round(1.56);+————-+| round(1.56) |+————-+| 2 |+————-+1 row in set (0.00 sec)(2)可以设定小数位数,返回浮点型数据mysql> select round(1.567,2);+—————-+| round(1.567,2) |+—————-+| 1.57 |+—————-+1 row in set (0.00 sec)SIGN (number2 ) //返回符号,正负或0SQRT(number2) //开平方三、日期类型ADDTIME (date2 ,time_interval ) //将time_interval加到date2CONVERT_TZ (datetime2 ,fromTZ ,toTZ ) //转换时区CURRENT_DATE ( ) //当前日期CURRENT_TIME ( ) //当前时间CURRENT_TIMESTAMP ( ) //当前时间戳DATE (datetime ) //返回datetime的日期部分DATE_ADD (date2 , INTERVAL d_value d_type ) //在date2中加上日期或时间DATE_FORMAT (datetime ,FormatCodes ) //使用formatcodes格式显示datetime DATE_SUB (date2 , INTERVAL d_value d_type ) //在date2上减去一个时间DATEDIFF (date1 ,date2 ) //两个日期差DAY (date ) //返回日期的天DAYNAME (date ) //英文星期DAYOFWEEK (date ) //星期(1-7) ,1为星期天DAYOFYEAR (date ) //一年中的第几天EXTRACT (interval_name FROM date ) //从date中提取日期的指定部分MAKEDATE (year ,day ) //给出年及年中的第几天,生成日期串MAKETIME (hour ,minute ,second ) //生成时间串MONTHNAME (date ) //英文月份名NOW ( ) //当前时间SEC_TO_TIME (seconds ) //秒数转成时间STR_TO_DATE (string ,format ) //字串转成时间,以format格式显示TIMEDIFF (datetime1 ,datetime2 ) //两个时间差TIME_TO_SEC (time ) //时间转秒数]WEEK (date_time [,start_of_week ]) //第几周YEAR (datetime ) //年份DAYOFMONTH(datetime) //月的第几天HOUR(datetime) //小时LAST_DAY(date) //date的月的最后日期MICROSECOND(datetime) //微秒MONTH(datetime) //月MINUTE(datetime) //分注:可用在INTERVAL中的类型:DAY ,DAY_HOUR ,DAY_MINUTE ,DAY_SECOND ,HOUR ,HOUR_MINUTE ,HOUR_SE COND ,MINUTE ,MINUTE_SECOND,MONTH ,SECOND ,YEARDECLARE variable_name [,variable_name...] datatype [DEFAULT value];其中,datatype为mysql的数据类型,如:INT, FLOAT, DATE, VARCHAR(length)例:DECLARE l_int INT unsigned default 4000000;DECLARE l_numeric NUMERIC(8,2) DEFAULT 9.95;DECLARE l_date DATE DEFAULT '1999-12-31';DECLARE l_datetime DATETIME DEFAULT '1999-12-31 23:59:59';DECLARE l_varchar VARCHAR(255) DEFAULT 'This will not be padded';SQL Server版语法为了方便说明,数据库使用SQL Server的示例数据库,Northwind和pubs,如果SQL Server中没有的话,可以按下面的方法安装1,下载SQL2000SampleDb.msi,下载地址是:/downloads/details.aspx?FamilyId=06616212-0356-46A0-8DA2-EEBC53A68034&displaylang=en2,安装后,到默认目录C:\SQL Server 2000 Sample Databases 有instnwnd.sql ,instpubs.sql两个文件3,在sql server中运行这两个sql 就可以创建你Northwind和pubs数据库。