Java网络爬虫简单实现
- 格式:doc
- 大小:82.50 KB
- 文档页数:14

网络爬虫的六种方式突然对网络爬虫特别感兴趣,所以就上网查询了下,发现这个特别好。
给大家分享下。
现在有越来越多的人热衷于做网络爬虫(网络蜘蛛),也有越来越多的地方需要网络爬虫,比如搜索引擎、资讯采集、舆情监测等等,诸如此类。
网络爬虫涉及到的技术(算法/策略)广而复杂,如网页获取、网页跟踪、网页分析、网页搜索、网页评级和结构/非结构化数据抽取以及后期更细粒度的数据挖掘等方方面面,对于新手来说,不是一朝一夕便能完全掌握且熟练应用的,对于作者来说,更无法在一篇文章内就将其说清楚。
因此在本篇文章中,我们仅将视线聚焦在网络爬虫的最基础技术——网页抓取方面。
说到网页抓取,往往有两个点是不得不说的,首先是网页编码的识别,另外一个是对网页脚本运行的支持,除此之外,是否支持以POST方式提交请求和支持自动的cookie管理也是很多人所关注的重要方面。
其实Java世界里,已经有很多开源的组件来支持各种各样方式的网页抓取了,包括上面提到的四个重点,所以说使用Java做网页抓取还是比较容易的。
下面,作者将重点介绍其中的六种方式。
HttpClientHttpClient 是 Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
以下列出的是 HttpClient 提供的主要的功能,要知道更多详细的功能可以参见 HttpClient 的主页。
(1)实现了所有 HTTP 的方法(GET,POST,PUT,HEAD 等)(2)支持自动转向(3)支持 HTTPS 协议(4)支持代理服务器(5)支持自动的Cookies管理等Java爬虫开发中应用最多的一种网页获取技术,速度和性能一流,在功能支持方面显得较为底层,不支持JS脚本执行和CSS解析、渲染等准浏览器功能,推荐用于需要快速获取网页而无需解析脚本和CSS 的场景。
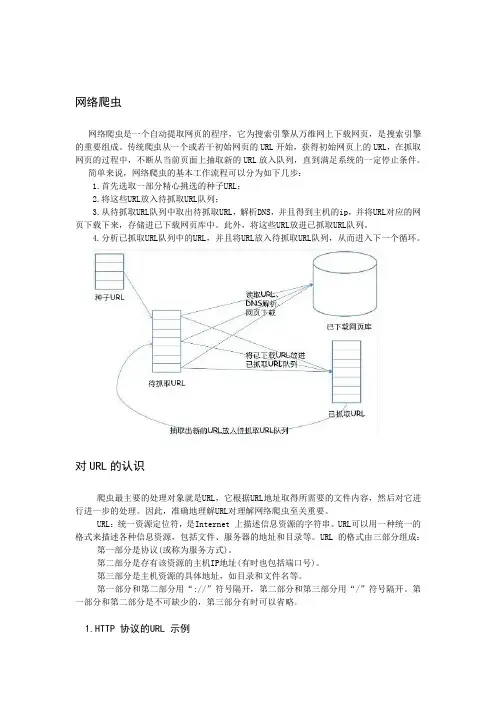
网络爬虫网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
简单来说,网络爬虫的基本工作流程可以分为如下几步:1.首先选取一部分精心挑选的种子URL;2.将这些URL放入待抓取URL队列;3.从待抓取URL队列中取出待抓取URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。
此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
对URL的认识爬虫最主要的处理对象就是URL,它根据URL地址取得所需要的文件内容,然后对它进行进一步的处理。
因此,准确地理解URL对理解网络爬虫至关重要。
URL:统一资源定位符,是Internet 上描述信息资源的字符串。
URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。
URL 的格式由三部分组成:第一部分是协议(或称为服务方式)。
第二部分是存有该资源的主机IP地址(有时也包括端口号)。
第三部分是主机资源的具体地址,如目录和文件名等。
第一部分和第二部分用“://”符号隔开,第二部分和第三部分用“/”符号隔开。
第一部分和第二部分是不可缺少的,第三部分有时可以省略。
1.HTTP 协议的URL 示例使用超级文本传输协议HTTP,提供超级文本信息服务的资源。
例:/channel/welcome.htm。
其计算机域名为。
超级文本文件(文件类型为.html)是在目录/channel 下的welcome.htm。
这是中国人民日报的一台计算机。
例:/talk/talk1.htm。
其计算机域名为。
超级文本文件(文件类型为.html)是在目录/talk 下的talk1.htm。

java爬虫框架有哪些,各有什么特点目前主流的Java爬虫框架主要有Nutch、Crawler4j、WebMagic、scrapy、WebCollector等,各有各的特点,大家可以根据自己的需求选择使用,下面为大家详细介绍常见的java爬虫框架有哪些?各有什么特点?常见的java爬虫框架有哪些1、NutchNutch是一个基于Lucene,类似Google的完整网络搜索引擎解决方案,基于Hadoop的分布式处理模型保证了系统的性能,类似Eclipse 的插件机制保证了系统的可客户化,而且很容易集成到自己的应用之中。
总体上Nutch可以分为2个部分:抓取部分和搜索部分。
抓取程序抓取页面并把抓取回来的数据做成反向索引,搜索程序则对反向索引搜索回答用户的请求。
抓取程序和搜索程序的接口是索引,两者都使用索引中的字段。
抓取程序和搜索程序可以分别位于不同的机器上。
下面详细介绍一下抓取部分。
Nutch抓取部分:抓取程序是被Nutch的抓取工具驱动的。
这是一组工具,用来建立和维护几个不同的数据结构:web database,a set of segments,and the index。
下面逐个解释这三个不同的数据结构:1、The web database,或者WebDB。
这是一个特殊存储数据结构,用来映像被抓取网站数据的结构和属性的集合。
WebDB 用来存储从抓取开始(包括重新抓取)的所有网站结构数据和属性。
WebDB 只是被抓取程序使用,搜索程序并不使用它。
WebDB 存储2种实体:页面和链接。
页面表示网络上的一个网页,这个网页的Url作为标示被索引,同时建立一个对网页内容的MD5 哈希签名。
跟网页相关的其它内容也被存储,包括:页面中的链接数量(外链接),页面抓取信息(在页面被重复抓取的情况下),还有表示页面级别的分数score 。
链接表示从一个网页的链接到其它网页的链接。
因此WebDB 可以说是一个网络图,节点是页面,链接是边。

在Web开发中,反爬虫策略主要是用来防止网站数据被恶意采集或者滥用。
一种常见的反爬虫策略是通过检测请求头中的User-Agent字段来判断请求是否来自爬虫。
下面是一个简单的Java代码示例,用于检测User-Agent并阻止爬虫:java复制代码import javax.servlet.*;import javax.servlet.http.*;import java.io.IOException;public class AntiScraperFilter implements Filter {@Overridepublic void init(FilterConfig filterConfig)throws ServletException {// 初始化方法,可以在这里进行一些初始化操作}@Overridepublic void doFilter(ServletRequest request, ServletResponseresponse, FilterChain chain)throws IOException, ServletException { HttpServletRequest httpRequest = (HttpServletRequest) request;UserAgent userAgent =UserAgent.parseUserAgentString(httpRequest.getHeader("User-Agent"));// 这里假设我们只允许浏览器访问,如果检测到非浏览器User-Agent,我们则认为是爬虫if (userAgent.getBrowser() == null) {((HttpServletResponse)response).sendError(HttpServletResponse.SC_FORBIDDEN, "Scrapers are not allowed");return;}chain.doFilter(request, response);}@Overridepublic void destroy() {// 销毁方法,可以在这里进行一些清理操作}}这段代码创建了一个过滤器,该过滤器检查每个请求的User-Agent,如果它不是一个已知的浏览器User-Agent,那么就阻止这个请求。

摘要网络爬虫是一种自动搜集互联网信息的程序。
通过网络爬虫不仅能够为搜索引擎采集网络信息,而且可以作为定向信息采集器,定向采集某些网站下的特定信息,如招聘信息,租房信息等。
本文通过JAVA实现了一个基于广度优先算法的多线程爬虫程序。
本论文阐述了网络爬虫实现中一些主要问题:为何使用广度优先的爬行策略,以及如何实现广度优先爬行;为何要使用多线程,以及如何实现多线程;系统实现过程中的数据存储;网页信息解析等。
通过实现这一爬虫程序,可以搜集某一站点的URLs,并将搜集到的URLs 存入数据库。
【关键字】网络爬虫;JAVA;广度优先;多线程。
ABSTRACTSPIDER is a program which can auto collect informations from internet. SPIDER can collect data for search engines, also can be a Directional information collector, collects specifically informations from some web sites, such as HR informations, this paper, use JAVA implements a breadth-first algorithm multi-thread SPDIER. This paper expatiates some major problems of SPIDER: why to use breadth-first crawling strategy, and collect URLs from one web site, and store URLs into database.【KEY WORD】SPIDER; JA V A; Breadth First Search; multi-threads.目录第一章引言 (1)第二章相关技术介绍 (2)2.1JAVA线程 (2)2.1.1 线程概述 (2)2.1.2 JAVA线程模型 (2)2.1.3 创建线程 (3)2.1.4 JAVA中的线程的生命周期 (4)2.1.5 JAVA线程的结束方式 (4)2.1.6 多线程同步 (5)2.2URL消重 (5)2.2.1 URL消重的意义 (5)2.2.2 网络爬虫URL去重储存库设计 (5)2.2.3 LRU算法实现URL消重 (7)2.3URL类访问网络 (8)2.4爬行策略浅析 (8)2.4.1宽度或深度优先搜索策略 (8)2.4.2 聚焦搜索策略 (9)2.4.3基于内容评价的搜索策略 (9)2.4.4 基于链接结构评价的搜索策略 (10)2.4.5 基于巩固学习的聚焦搜索 (11)2.4.6 基于语境图的聚焦搜索 (11)第三章系统需求分析及模块设计 (13)3.1系统需求分析 (13)3.2SPIDER体系结构 (13)3.3各主要功能模块(类)设计 (14)3.4SPIDER工作过程 (14)第四章系统分析与设计 (16)4.1SPIDER构造分析 (16)4.2爬行策略分析 (17)4.3URL抽取,解析和保存 (18)4.3.1 URL抽取 (18)4.3.2 URL解析 (19)4.3.3 URL保存 (19)第五章系统实现 (21)5.1实现工具 (21)5.2爬虫工作 (21)5.3URL解析 (22)5.4URL队列管理 (24)5.4.1 URL消重处理 (24)5.4.2 URL等待队列维护 (26)5.4.3 数据库设计 (27)第六章系统测试 (29)第七章结论 (32)参考文献 (33)致谢 (34)外文资料原文 (35)译文 (51)第一章引言随着互联网的飞速发展,网络上的信息呈爆炸式增长。

⽹络爬⾍案例解析⽹络爬⾍(⼜被称为⽹页蜘蛛,⽹络机器⼈,在FOAF社区中间,更经常被称为⽹页追逐者),是⼀种按照⼀定的规则,⾃动的抓取万维⽹信息的程序或者脚本,已被⼴泛应⽤于互联⽹领域。
搜索引擎使⽤⽹络爬⾍抓取Web⽹页、⽂档甚⾄图⽚、⾳频、视频等资源,通过相应的索引技术组织这些信息,提供给搜索⽤户进⾏查询。
⽹络爬⾍也为中⼩站点的推⼴提供了有效的途径,⽹站针对搜索引擎爬⾍的优化曾风靡⼀时。
⽹络爬⾍的基本⼯作流程如下:1.⾸先选取⼀部分精⼼挑选的种⼦URL;2.将这些URL放⼊待抓取URL队列;3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的⽹页下载下来,存储进已下载⽹页库中。
此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放⼊待抓取URL队列,从⽽进⼊下⼀个循环。
当然,上⾯说的那些我都不懂,以我现在的理解,我们请求⼀个⽹址,服务器返回给我们⼀个超级⼤⽂本,⽽我们的浏览器可以将这个超级⼤⽂本解析成我们说看到的华丽的页⾯那么,我们只需要把这个超级⼤⽂本看成⼀个⾜够⼤的String 字符串就OK了。
下⾯是我的代码package main.spider;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.IOException;/*** Created by 1755790963 on 2017/3/10.*/public class Second {public static void main(String[] args) throws IOException {System.out.println("begin");Document document = Jsoup.connect("/p/2356694991").get();String selector="div[class=d_post_content j_d_post_content clearfix]";Elements elements = document.select(selector);for (Element element:elements){String word= element.text();if(word.indexOf("@")>0){word=word.substring(0,stIndexOf("@")+7);System.out.println(word);}System.out.println(word);}}}我在这⾥使⽤了apache公司所提供的jsoup jar包,jsoup 是⼀款Java 的HTML解析器,可直接解析某个URL地址、HTML⽂本内容。

爬虫的四个步骤爬虫技术是指利用程序自动化地浏览很多网页,并抓取它们的信息的过程。
爬虫技术在信息爬取、搜索引擎、商业竞争等领域应用广泛。
想要实现一个高效的爬虫程序,需要遵循一定的规范和流程,本文将介绍爬虫的四个步骤,它们是页面抓取、数据提取、数据存储和数据呈现。
第一步:页面抓取页面抓取是爬虫技术的第一步。
抓取的目标是将网站上的所有内容下载到本地,这些内容包括网页、图片、音频和视频等。
页面抓取是爬虫程序中最基本的过程之一,爬虫程序第一次访问目标网站时,会向目标服务器发送请求。
在拿到响应内容后,需要从中解析出有意义的信息,包括HTML源码、页面中的图片、JS文件、CSS文件等。
获取到这些信息后,需要判断响应状态码是否正常,是否符合预期,如果出现错误需要做出相应的处理。
在实现页面抓取过程中,可以使用多种语言和框架。
常用的语言有Python、Java、Node.js,常用的框架有Requests、Scrapy、Puppeteer等。
无论使用什么语言和框架,都需要注意以下几个问题:1. 多线程和协程在进行页面抓取时,需要考虑到性能和效率,如果使用单线程,无法充分利用网络资源,导致程序运行效率低下。
因此,需要采用多线程或协程的方式来处理比较复杂的任务。
多线程可以利用CPU资源,充分发挥计算机的性能。
协程可以利用异步非阻塞技术,充分利用网络资源。
2. 反爬机制在进行页面抓取时,需要考虑到反爬机制。
目标网站可能会采取一些反爬措施,如IP封禁、验证码验证等。
为了克服这些问题,需要采用相应的技术和策略,如IP代理、验证码识别等。
3. 容错处理在进行页面抓取时,需要考虑到容错处理。
爬虫程序可能会因为网络连接问题或者目标网站的异常情况导致程序运行出现异常。
因此,需要实现一些错误处理机制,如重试机制、异常捕获处理机制等。
第二步:数据提取数据提取是爬虫过程中比较重要的一步。
在页面抓取完成之后,需要将页面中有意义的信息提取出来。

爬虫的方法和步骤在当今信息爆炸的社会中,要获取并整理特定内容的原始数据,使用爬虫成为了一种越来越流行的方法。
在这种情况下,我们希望提供一些关于爬虫的介绍,包括定义、其实现方法和步骤等。
爬虫是一种自动化程序,旨在在互联网上搜索、收集和分析信息。
爬虫程序通过互联网链接和页面之间的关系,自动地遍历和检索数据和信息。
爬虫程序可以与大量信息源进行交互,包括网站、API和数据库,并允许数据的快速收集和分析。
一.直接请求页面进行数据采集在这种情况下,爬虫程序会发送一个HTTP请求来获取特定网页的内容,然后解析返回值,处理其中的数据并挖掘出所需的信息。
HTTP请求包括URL、请求方法、HTTP头和请求正文等。
使用Python或Java等编程语言进行编程,利用第三方库如urllib库或requests库等发送HTTP请求,并对返回的应答进行解析和处理,通常使用BeautifulSoup、XPath或正则表达式库来获取和处理所需的数据信息。
二、爬虫框架这是一种将基本爬虫组件(如请求、解析和存储数据)封装为可重复使用的模块的方法。
这些模块是在不同的层次和模块中实现的,它们能够按照不同的规则组合起来调用以形成更高级别的爬虫程序。
其中比较流行的框架有Scrapy框架,它使用基于异步框架Twisted来实现并发性,并包括一些有用的固定模块,例如数据抓取、URL管理、数据处理等。
一、定义所需数据定义所需数据是爬虫的第一步。
在设计爬虫之前,以确定需要抓取的数据类型、格式、来源、数量等信息,以及需要考虑如何存储和处理采集到的数据。
二、确定数据源和爬虫方法对于某个数据源、方法、爬虫程序和其他关键因素进行评估和选择。
例如,如果我们想要查找和存储指定标记的新闻,我们就需要确定提供这些标记的新闻源,并根据需要定义爬虫程序中每个组件的实现.三、编写爬虫程序可以使用编程语言编写爬虫程序,或者在Scrapy框架下使用Python,其中包括请求管理模块、URL管理模块、页面分析模块等。

网络爬虫的基本原理和实现方法随着互联网的普及和互联网信息的爆炸式增长,如何获取网络上的有用信息成为了一项具有重要意义的任务。
网页抓取技术是获取网络信息最为重要的技术之一,而网络爬虫又是一种效率较高的网页抓取技术。
那么,什么是网络爬虫呢?1. 网络爬虫的定义网络爬虫是指在万维网上自动抓取相关数据并进行处理的程序。
它通常会按照一定的顺序自动访问网络上的信息源,自动收集、过滤、整理相关数据,然后保存到本地或者其他的数据仓库,方便后期使用。
2. 网络爬虫的工作原理网络爬虫的工作原理通常有以下几个步骤:(1) 设置起始URL: 网络爬虫首先需要设置起始的URL,即需要抓取的网页链接。
(2) 发送请求: 然后程序会模拟浏览器向目标链接发送请求,主要包括HTTP请求、GET请求、POST请求等。
(3) 获取网页数据: 服务器返回数据之后,网络爬虫就会获取网页的HTML源代码,进一步获取所需内容的XPath或CSS选择器。
(4) 解析网页: 根据获取到的XPath或CSS选择器从网页源代码中抽取所需的数据。
如获取标题、正文、图片、音视频等等。
(5) 存储数据: 网络爬虫将抓取到的数据进行存储,主要有本地数据库、Redis、Elasticsearch等存储方式。
(6) 拓展链接: 在本次抓取过程中,网络爬虫会递归地获取网页中的所有链接,再以这些链接为起点进行下一轮抓取,形成一个多层次的数据抓取过程。
3. 网络爬虫的实现方法(1) 基于Python语言的爬虫框架常见的基于Python语言的爬虫框架有Scrapy和Beautiful Soup。
Scrapy是Python语言中最受欢迎的网络爬虫框架之一,它具有强大的抓取和处理机制,可以支持多线程抓取、分布式抓取等;而Beautiful Soup则是一款非常方便的HTML和XML解析器,可以帮助我们更加方便、快捷地抽取所需数据。
(2) 基于JavaScript的爬虫技术对于一些动态生成的网站,使用Python爬虫会产生一定的困难,这时候就需要使用JavaScript技术。

JAVA爬⾍——爬取采集北京市政百姓信件内容——⾸都之窗(采⽤htmlunit,webma。
由于⾸都之窗⽹站第⼆页和第⼆页⽹址不变,已经和林⼦⾬⽼师教程相差甚远,所以现在选择htmlunit模拟点击,(跳转摁钮显⽰⽹页仍是第⼀页),所以本代码⽤的⼀直是点击下⼀页摁钮。
获取代码:1 package util;23 import java.io.IOException;4 import java.util.ArrayList;5 import java.util.LinkedList;6 import java.util.List;78 import com.gargoylesoftware.htmlunit.BrowserVersion;9 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;10 import com.gargoylesoftware.htmlunit.ImmediateRefreshHandler;11 import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;12 import com.gargoylesoftware.htmlunit.WebClient;13 import com.gargoylesoftware.htmlunit.html.HtmlElement;14 import com.gargoylesoftware.htmlunit.html.HtmlPage;1516 public class ⾸都之窗 {17 static List<String> lines_zi=new LinkedList<String>();18 static List<String> lines_jian=new LinkedList<String>();19 static List<String> lines_tou=new LinkedList<String>();2021 static String line;22 public static void Value_start()23 {24 // TODO ⾃动⽣成的⽅法存根25 WebClient webClient=new WebClient(BrowserVersion.CHROME); // 实例化Web客户端2627 System.out.println("AAAAAA");28 try {29 webClient.getOptions().setActiveXNative(false);30 //webClient.getOptions().setCssEnabled(false);31 //webClient.getOptions().setRedirectEnabled(true);32 webClient.getOptions().setJavaScriptEnabled(true);33 webClient.getOptions().setDoNotTrackEnabled(true);34 webClient.getOptions().setThrowExceptionOnScriptError(false);35 webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);36 webClient.getCache().setMaxSize(100);37 webClient.getOptions().setJavaScriptEnabled(true);//运⾏js脚本执⾏38 webClient.setAjaxController(new NicelyResynchronizingAjaxController());//设置⽀持AJAX39 webClient.getOptions().setCssEnabled(false);//忽略css40 webClient.getOptions().setUseInsecureSSL(true);//ssl安全访问41 webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常42 //webClient.getOptions().setTimeout(50000); //超时时间 ms43 webClient.getCookieManager().setCookiesEnabled(true);44 webClient.getCache().clear();45 webClient.setRefreshHandler(new ImmediateRefreshHandler());46 webClient.getOptions().setTimeout(2*1000); //⽹页多少ms超时响应47 webClient.setJavaScriptTimeout(600*1000); //javaScript多少ms超时48 webClient.setAjaxController(new NicelyResynchronizingAjaxController());49 //webClient.setJavaScriptTimeout(600*1000);50 //webClient.getOptions().setRedirectEnabled(true);51 webClient.waitForBackgroundJavaScript(60*1000);5253 HtmlPage page=webClient.getPage("/hudong/hdjl/com.web.search.mailList.flow"); // 解析获取页⾯54 HtmlElement a=page.getElementByName("nextPage");55 int j=1,lastj=0;56 FileHandle fh=new FileHandle();57 StringHandle sh=new StringHandle();58 List<String> lastInfo_zi=new ArrayList<String>();59 List<String> lastInfo_jian=new ArrayList<String>();60 List<String> lastInfo_tou=new ArrayList<String>();61 System.out.println("asdfsdaf");62 fh.outFile(""+"\r\n", "E:\\578095023\\FileRecv\\寒假作业\\⼤三寒假作业\\北京市政百姓信件分析实战\\list.txt", false);6364 while(j!=600)65 {6667 String nowInfo=page.asXml();6869 List<String> infoList_zi=sh.getExpString("letterdetail\\('.*?','.*?'\\)", nowInfo);70 int g_size_zi=infoList_zi.size();71 if(sh.StringListSameOutStringList(infoList_zi, lastInfo_zi).size()!=g_size_zi&&g_size_zi==7)72 {73 //System.out.println(g_size);74 for(int i=0;i<g_size_zi;i++)75 {76 String theWeb=infoList_zi.get(i).replaceAll("letterdetail\\('.*?','", "").replace("')", "");77 System.out.println(theWeb);78 lines_zi.add(theWeb);79 fh.outFile(theWeb+"\r\n", "E:\\578095023\\FileRecv\\寒假作业\\⼤三寒假作业\\北京市政百姓信件分析实战\\list.txt", true);8081 if(i==g_size_zi-1)82 {83 lastInfo_zi=infoList_zi;84 System.out.println(j);85 j++;86 break;87 }8889 }90 page=a.click();91 }92 //page=a.click();93 }949596 }catch (FailingHttpStatusCodeException | IOException e) {97 // TODO Auto-generated catch block98 e.printStackTrace();99 } finally{100 webClient.close(); // 关闭客户端,释放内存101 }102103 }104 public static void main(String[] args) {105 Value_start();106 }107108 }getPass爬取详细数据:1 package util;2 import java.io.*;3 import java.util.List;45 import org.jsoup.Connection;6 import org.jsoup.Jsoup;7 import org.jsoup.nodes.Document;8 import org.jsoup.nodes.Element;9 import org.jsoup.select.Elements;1011 import java.io.IOException;12 import java.util.ArrayList;13 import java.util.List;1415 import org.jsoup.Connection;16 import org.jsoup.Jsoup;17 import org.jsoup.nodes.Document;18 import org.jsoup.nodes.Element;19 import org.jsoup.select.Elements;2021 import util.SslUtils;2223 import us.codecraft.webmagic.Page;24 import us.codecraft.webmagic.Site;25 import us.codecraft.webmagic.Spider;26 import us.codecraft.webmagic.processor.PageProcessor;2728 import Bean;29 import Dao;30 public class pa2 implements PageProcessor {31 static int num=0;32 static String Id;33 static String Question;34 static String Question_user;35 static String Question_date;36 static String Question_info;37 static String Answer;38 static String Answer_user;39 static String Answer_date;40 static String Answer_info;41 static String Url;42 //static String regEx="[\n`~!@#$%^&()+=|{}':;',\\[\\].<>/?~!@#¥%……&*()——+|{}【】‘;:”“’。

最简单的爬虫代码
最简单的爬虫代码通常涉及使用Python和一个网络请求库,如`requests`,来获取网页内容。
以下是一个非常简单的示例,使用Python中的`requests`库爬取一个网页:
首先,确保你已经安装了`requests`库。
你可以通过以下命令安装:
```bash
pip install requests
```
然后,使用以下代码实现一个简单的爬虫:
```python
import requests
# 目标网页的URL
url = ''
# 发送HTTP GET请求获取页面内容
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 打印页面内容
print(response.text)
else:
print('Failed to retrieve the page. Status code:', response.status_code)
```
这段代码执行以下步骤:
1. 导入`requests`库。
2. 指定目标网页的URL。
3. 使用`requests.get(url)`发送HTTP GET请求获取网页内容。
4. 检查响应的状态码,如果为200表示成功,打印页面内容;否则,打印错误信息。
请注意,这只是一个非常简单的例子。
实际的爬虫可能需要更复杂的处理,包括处理页面内容、解析HTML、处理网页链接等。
在实际应用中,你可能会考虑使用更强大的爬虫框架,如Scrapy。
java⽹络爬⾍,乱码问题终于完美解决第⼀次写爬⾍,被乱码问题困扰两天,试了很多⽅法都不可以,今天随便⼀试,居然好了。
在获取⽹页时创建了⼀个缓冲字节输⼊流,问题就在这个流上,添加标红代码即可BufferedReader in = null;in = new BufferedReader(new InputStreamReader(connection.getInputStream(),"utf-8"));附上代码,以供参考。
1public String sendGet(String url) {2 Writer write = null;3// 定义⼀个字符串⽤来存储⽹页内容4 String result = null;5// 定义⼀个缓冲字符输⼊流6 BufferedReader in = null;7try {8// 将string转成url对象9 URL realUrl = new URL(url);10// 初始化⼀个链接到那个url的连接11 URLConnection connection = realUrl.openConnection();12// 开始实际的连接13 connection.connect();14// 初始化 BufferedReader输⼊流来读取URL的响应15 in = new BufferedReader(new InputStreamReader(16 connection.getInputStream(),"utf-8"));17// ⽤来临时存储抓取到的每⼀⾏的数据18 String line;1920 File file = new File(saveEssayUrl, fileName);21 File file2 = new File(saveEssayUrl);2223if (file2.isDirectory() == false) {24 file2.mkdirs();25try {26 file.createNewFile();27 System.out.println("********************");28 System.out.println("创建" + fileName + "⽂件成功!!");2930 } catch (IOException e) {31 e.printStackTrace();32 }3334 } else {35try {36 file.createNewFile();37 System.out.println("********************");38 System.out.println("创建" + fileName + "⽂件成功!!");39 } catch (IOException e) {40 e.printStackTrace();41 }42 }43 Writer w = new FileWriter(file);4445while ((line = in.readLine()) != null) {46// 遍历抓取到的每⼀⾏并将其存储到result⾥⾯47// line = new String(line.getBytes("utf-8"),"gbk");48 w.write(line);49 w.write("\r\n");50 result += line;51 }52 w.close();53 } catch (Exception e) {54 System.out.println("发送GET请求出现异常!" + e);55 e.printStackTrace();56 }57// 使⽤finally来关闭输⼊流58finally {59try {60if (in != null) {61 in.close();62 }6364 } catch (Exception e2) {65 e2.printStackTrace();66 }67 }68return result;69 }。
java程序设计实践题目
Java程序设计实践题目可以涵盖各个方面,包括基本语法、面向对象编程、数据结构、算法等。
下面是一些常见的Java程序设计实践题目:
1. 实现一个学生管理系统,包括学生信息的录入、查询、修改和删除功能。
2. 编写一个简单的计算器程序,实现基本的加减乘除运算。
3. 设计一个图书管理系统,包括图书的录入、借阅、归还和查询功能。
4. 实现一个简单的银行账户管理系统,包括开户、存款、取款和查询余额功能。
5. 编写一个简单的日程管理程序,可以添加、删除和查询日程安排。
6. 设计一个简单的电商平台,包括商品的展示、购买和结算功
能。
7. 实现一个简单的迷宫游戏,用户通过键盘操作控制角色移动
并找到出口。
8. 编写一个简单的网络爬虫程序,可以爬取指定网站上的信息
并保存到本地。
9. 设计一个简单的在线聊天室,可以实现多人聊天和私聊功能。
10. 实现一个简单的文件管理器,包括文件的创建、复制、移
动和删除功能。
以上题目只是一些示例,你可以根据自己的兴趣和需求进行扩
展和修改。
在解决这些题目时,可以考虑代码的可读性、模块化设计、异常处理等方面,以提高程序的质量和可维护性。
希望这些题
目能够帮助你提升Java程序设计的实践能力。
Java爬⾍⼯具Jsoup详解Java 爬⾍⼯具Jsoup详解Jsoup是⼀款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML ⽂本内容。
它提供了⼀套⾮常省⼒的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作⽅法来取出和操作数据。
jsoup 的主要功能如下:1. 从⼀个 URL,⽂件或字符串中解析 HTML;2. 使⽤ DOM 或 CSS 选择器来查找、取出数据;3. 可操作 HTML 元素、属性、⽂本;jsoup 是基于 MIT 协议发布的,可放⼼使⽤于商业项⽬。
jsoup 可以从包括字符串、URL 地址以及本地⽂件来加载 HTML ⽂档,并⽣成 Document 对象实例。
简单⽽⾔,Jsoup就是先取html页⾯代码然后解析这些页⾯通过Jsoup携带的满⾜我们绝⼤多数需求的各种选择器从这个页⾯中获取我们所需要的重要数据的⼀款功能强⼤的html解析器,但也只是相对⽽⾔,这⾥的页⾯这是死的静态页⾯,如果你想获取动态⽣成的页⾯数据那么你得⽤到其他的java 爬⾍技术,我会不定时更新这些技术⼀起探讨。
下⾯我们来具体谈谈如何运⽤Jsoup⼀、如何取页⾯Jsoup提供了⽤来解析html页⾯的⽅法 parse(),我们通过解析它可以获取整个页⾯的dom对象,通过这个对象来获取你所需要的页⾯所须有的参数。
获取页⾯的⽅法有很多,这⾥就简单的列举⼏个:①通过Jsoup携带的connect()⽅法String htmlPage = Jsoup.connect("https://").get().toString();这个⽅法说需要的参数就是⼀个String类型的url链接,但是你的注意把这些链接的protrol加上,以免问题,其实这个⽅法解决了我们很多问题,我们完全可以把Jsoup解析html抽取成⼀段通⽤⼯具类,然后通过改变拼接的url参数获取到很多我们想要的东西,举个例⼦:京东和淘宝的商品链接都是固定的,通过改变其三⽅商品ID来获取商品详情参数。
值得苦练的55个java小项目Java是一种广泛应用于软件开发的编程语言,它在各个行业都有着重要的地位。
为了提升自己的编程能力和项目经验,苦练Java小项目是一个非常不错的选择。
在这篇文章中,我将为大家介绍55个值得苦练的小项目,帮助大家提升对Java的理解和应用能力。
1.电子商务网站:搭建一个简单的电子商务网站,包括用户注册、商品展示、购物车管理等功能。
2.个人博客系统:构建一个个人博客网站,实现博客文章的发布、评论、分类等功能。
3.在线图书馆:搭建一个基于Java的在线图书馆系统,实现图书的借阅和管理功能。
4.聊天程序:开发一个简单的聊天程序,用户可以通过网络进行文字聊天。
5.简单的计算器:实现一个基本的计算器,具备加减乘除等基本运算功能。
6.学生成绩管理系统:开发一个学生成绩管理系统,可以录入学生的成绩并进行查询和统计。
7.网络爬虫:编写一个网络爬虫程序,可以自动获取指定网页上的信息。
8.手机通讯录:开发一个手机通讯录程序,可以实现联系人的添加、删除和查询功能。
9.在线考试系统:实现一个在线考试系统,包含题库管理、试卷生成和考试成绩统计等功能。
10.简单的文件管理器:编写一个基本的文件管理器,可以对文件和文件夹进行增删改查操作。
11.在线点餐系统:开发一个在线点餐系统,用户可以通过网络浏览菜单并下单。
12.天气预报程序:实现一个天气预报程序,可以查询指定城市的天气情况。
13.音乐播放器:编写一个简单的音乐播放器,可以播放本地音乐文件。
14.简单的人事管理系统:开发一个简单的人事管理系统,可以对员工的基本信息进行管理。
15.在线留言板:构建一个在线留言板,用户可以发表留言并进行回复。
16.简单的照片编辑器:编写一个简单的照片编辑器,实现基本的图片处理功能。
17.在线音乐库:开发一个在线音乐库,用户可以搜索和播放音乐。
18.网页爬虫:编写一个网页爬虫程序,可以自动下载指定网页上的图片或文件。
19.游戏扫雷:开发一个经典的扫雷游戏程序,实现游戏界面和游戏规则。
184 •电子技术与软件工程 Electronic Technology & Software Engineering数据库技术• Data Base Technique【关键词】数据分析 爬虫 分布式1 引言京东是一家电商平台,本文通过爬虫技术获取相关商品信息。
JA V A 是一门具备数据处理能力和并发多线程机制的成熟语言。
本文通过爬虫系统获取商品信息,将数据保存到本地数据库,最后进行数据分析。
本系统可快速获取商品信息,使用户快速寻找心仪商品。
分布基于JAVA 的京东商品分布式爬虫系统的设计与实现文/曹根源 董斌智式的技术也可供企业进行大规模数据爬取使用。
2 分布式爬虫系统设计2.1 设计需求主要解决问题:2.1.1 数据获取和异常处理通过URL 爬取商品ID ;分析页面源码,提取所需信息;建立数据字典并将数据存入数据库。
当某ID 没有爬取到时使用查错机制。
2.1.2 分布式通信和多线程技术前者用Socket 实现;后者使用Java 线程池。
2.1.3 可复用技术和内存优化前者用心跳检查机制,释放失效主机;后者采用数据库去重。
2.1.4 负载均衡检测每台主机的性能,分发合适的任务。
2.1.5 反爬应对和数据库优化前者使用cookies 替换、IP 代理等手段。
后者采用水平划分将ID 独立成表,为数据库添加索引等。
2.2 相关JAVA模块2.2.1 网址管理实现网址管理的方法有以下2类:(1)JA V A 内存:分析网站结构,减少重复URL 的爬取。
采用排队机制,减少内存开销。
(2)数据库存储和URL 去重:前者采用数据库去重。
后者使用HashSet 等进行去重。
2.2.2 分布式通信分布式通信是爬虫的主要模块。
(1)Socket :采用JA V A 的Socket 包,让客户机在同一局域网内基于TCP 进行通信。
(2)负载均衡:每次通信时检测客户机状态,根据LoadBalance 算法计算出分配任务量。
Java爬⾍-WebMagic-WebClient-⽹页js渲染内容⼤多数都是python,但是Java爬⾍的优势就是可以使⽤多线程;Java爬⾍主要有WebMagic和WebClient,WebMagic框架⽐较好操作⼀些WebMagic但是在爬取js渲染的页⾯内容时,会⽆法解析该部分内容;也可能是我还没有了解到解决办法;⽬前使⽤WebClient解决的WebClientWebClient内容很多,这⾥只放爬⾍的代码:<!-- https:///artifact/org.jsoup/jsoup --><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.13.1</version></dependency><!-- https:///artifact/net.sourceforge.htmlunit/htmlunit --><dependency><groupId>net.sourceforge.htmlunit</groupId><artifactId>htmlunit</artifactId><version>2.43.0</version></dependency>@Slf4j@Componentpublic class SpiderUtils {/** 爬取后的页⾯初始页⾯内容 */public static String pageCon;/** 需要爬取页⾯:*** */public static String url = "http://******爬取的页⾯*****";// 每⼩时爬取⼀次@Scheduled(initialDelay = 1000, fixedDelay = 60 * 60 * 1000)public static void spiderRun() {("======>爬取URL{}",url);final WebClient webClient = new WebClient(BrowserVersion.CHROME); // 新建⼀个模拟⾕歌Chrome浏览器的浏览器客户端对象webClient.getOptions().setThrowExceptionOnScriptError(false); // 当JS执⾏出错的时候是否抛出异常, 这⾥选择不需要webClient.getOptions().setThrowExceptionOnFailingStatusCode(false); // 当HTTP的状态⾮200时是否抛出异常, 这⾥选择不需要webClient.getOptions().setActiveXNative(false); // 不启⽤ActiveXwebClient.getOptions().setCssEnabled(false); // 是否启⽤CSS, 因为不需要展现页⾯, 所以不需要启⽤webClient.getOptions().setJavaScriptEnabled(true); // 很重要,启⽤JSwebClient.getOptions().setDownloadImages(false); // 不下载图⽚webClient.setAjaxController(new NicelyResynchronizingAjaxController()); // 很重要,设置⽀持AJAXwebClient.waitForBackgroundJavaScript(5 * 1000); // 异步JS执⾏需要耗时,所以这⾥线程要阻塞30秒,等待异步JS执⾏结束HtmlPage page = null;try {page = webClient.getPage(url); // 尝试加载给出的⽹页} catch (Exception e) {("======>【严重】爬取失败:{}",url);e.printStackTrace();} finally {webClient.close();}String pageXml = page.asXml(); // 直接将加载完成的页⾯转换成xml格式的字符串pageCon = pageXml;}}。
首先介绍每个类的功能:DownloadPage.java的功能是下载此超链接的页面源代码.FunctionUtils.java 的功能是提供不同的静态方法,包括:页面链接正则表达式匹配,获取URL链接的元素,判断是否创建文件,获取页面的Url并将其转换为规范的Url,截取网页网页源文件的目标内容。
HrefOfPage.java 的功能是获取页面源代码的超链接。
UrlDataHanding.java 的功能是整合各个给类,实现url到获取数据到数据处理类。
UrlQueue.java 的未访问Url队列。
VisitedUrlQueue.java 已访问过的URL队列。
下面介绍一下每个类的源代码:DownloadPage.java 此类要用到HttpClient组件。
1.package com.sreach.spider;2.3.import java.io.IOException;4.import org.apache.http.HttpEntity;5.import org.apache.http.HttpResponse;6.import org.apache.http.client.ClientProtocolException;7.import org.apache.http.client.HttpClient;8.import org.apache.http.client.methods.HttpGet;9.import org.apache.http.impl.client.DefaultHttpClient;10.import org.apache.http.util.EntityUtils;11.12.public class DownloadPage13.{14.15. /**16. * 根据URL抓取网页内容17. *18. * @param url19. * @return20. */21. public static String getContentFormUrl(String url)22. {23. /* 实例化一个HttpClient客户端 */24. HttpClient client = new DefaultHttpClient();25. HttpGet getHttp = new HttpGet(url);26.27. String content = null;28.29. HttpResponse response;30. try31. {32. /*获得信息载体*/33. response = client.execute(getHttp);34. HttpEntity entity = response.getEntity();35.36. VisitedUrlQueue.addElem(url);37.38. if (entity != null)39. {40. /* 转化为文本信息 */41. content = EntityUtils.toString(entity);42.43. /* 判断是否符合下载网页源代码到本地的条件 */44. if (FunctionUtils.isCreateFile(url)45. && FunctionUtils.isHasGoalContent(content) !=-1)46. {47. FunctionUtils.createFile(FunctionUtils48. .getGoalContent(content), url);49. }50. }51.52. } catch (ClientProtocolException e)53. {54. e.printStackTrace();55. } catch (IOException e)56. {57. e.printStackTrace();58. } finally59. {60. client.getConnectionManager().shutdown();61. }62.63. return content;64. }65.66.}复制代码FunctionUtils.java 此类的方法均为static方法1.package com.sreach.spider;2.3.import java.io.BufferedWriter;4.import java.io.File;5.import java.io.FileOutputStream;6.import java.io.IOException;7.import java.io.OutputStreamWriter;8.import java.util.regex.Matcher;9.import java.util.regex.Pattern;10.11.public class FunctionUtils12.{13.14. /**15. * 匹配超链接的正则表达式16. */17. private static String pat ="http://www\\.oschina\\.net/code/explore/.*/\\w+\\.[a-zA-Z]+";18. private static Pattern pattern = pile(pat);19.20. private static BufferedWriter writer = null;21.22. /**23. * 爬虫搜索深度24. */25. public static int depth = 0;26.27. /**28. * 以"/"来分割URL,获得超链接的元素29. *30. * @param url31. * @return32. */33. public static String[] divUrl(String url)34. {35. return url.split("/");36. }37.38. /**39. * 判断是否创建文件40. *41. * @param url42. * @return43. */44. public static boolean isCreateFile(String url)45. {46. Matcher matcher = pattern.matcher(url);47.48. return matcher.matches();49. }50.51. /**52. * 创建对应文件53. *54. * @param content55. * @param urlPath56. */57. public static void createFile(String content, String urlPath)58. {59. /* 分割url */60. String[] elems = divUrl(urlPath);61. StringBuffer path = new StringBuffer();62.63. File file = null;64. for (int i = 1; i < elems.length; i++)65. {66. if (i != elems.length - 1)67. {68.69. path.append(elems[i]);70. path.append(File.separator);71. file = new File("D:" + File.separator + path.toString());72.73. }74.75. if (i == elems.length - 1)76. {77. Pattern pattern = pile("\\w+\\.[a-zA-Z]+");78. Matcher matcher = pattern.matcher(elems[i]);79. if ((matcher.matches()))80. {81. if (!file.exists())82. {83. file.mkdirs();84. }85. String[] fileName = elems[i].split("\\.");86. file = new File("D:" + File.separator +path.toString()87. + File.separator + fileName[0] + ".txt");88. try89. {90. file.createNewFile();91. writer = new BufferedWriter(newOutputStreamWriter(92. new FileOutputStream(file)));93. writer.write(content);94. writer.flush();95. writer.close();96. System.out.println("创建文件成功");97. } catch (IOException e)98. {99. e.printStackTrace();100. }101.102. }103. }104.105. }106. }107.108. /**109. * 获取页面的超链接并将其转换为正式的A标签110. *111. * @param href112. * @return113. */114. public static String getHrefOfInOut(String href)115. {116. /* 内外部链接最终转化为完整的链接格式 */117. String resultHref = null;118.119. /* 判断是否为外部链接 */120. if (href.startsWith("http://"))121. {122. resultHref = href;123. } else124. {125. /* 如果是内部链接,则补充完整的链接地址,其他的格式忽略不处理,如:a href="#" */126. if (href.startsWith("/"))127. {128. resultHref = "" + href;129. }130. }131.132. return resultHref;133. }134.135. /**136. * 截取网页网页源文件的目标内容137. *138. * @param content139. * @return140. */141. public static String getGoalContent(String content) 142. {143. int sign = content.indexOf("<pre class=\"");144. String signContent = content.substring(sign);145.146. int start = signContent.indexOf(">");147. int end = signContent.indexOf("</pre>");148.149. return signContent.substring(start + 1, end);150. }151.152. /**153. * 检查网页源文件中是否有目标文件154. *155. * @param content156. * @return157. */158. public static int isHasGoalContent(String content) 159. {160. return content.indexOf("<pre class=\"");161. }162.163.}复制代码HrefOfPage.java 此类为获取页面的超链接1.package com.sreach.spider;2.3.public class HrefOfPage4.{5. /**6. * 获得页面源代码中超链接7. */8. public static void getHrefOfContent(String content)9. {10. System.out.println("开始");11. String[] contents = content.split("<a href=\"");12. for (int i = 1; i < contents.length; i++)13. {14. int endHref = contents[i].indexOf("\"");15.16. String aHref =FunctionUtils.getHrefOfInOut(contents[i].substring(17. 0, endHref));18.19. if (aHref != null)20. {21. String href = FunctionUtils.getHrefOfInOut(aHref);22.23. if (!UrlQueue.isContains(href)24. && href.indexOf("/code/explore") != -125. && !VisitedUrlQueue.isContains(href))26. {27. UrlQueue.addElem(href);28. }29. }30. }31.32. System.out.println(UrlQueue.size() + "--抓取到的连接数");33. System.out.println(VisitedUrlQueue.size() + "--已处理的页面数");34.35. }36.37.}复制代码UrlDataHanding.java 此类主要是从未访问队列中获取url,下载页面,分析url,保存已访问url等操作,实现Runnable接口1.package com.sreach.spider;2.3.public class UrlDataHanding implements Runnable4.{5. /**6. * 下载对应页面并分析出页面对应的URL放在未访问队列中。