ARM体系结构变化
- 格式:doc
- 大小:31.00 KB
- 文档页数:4

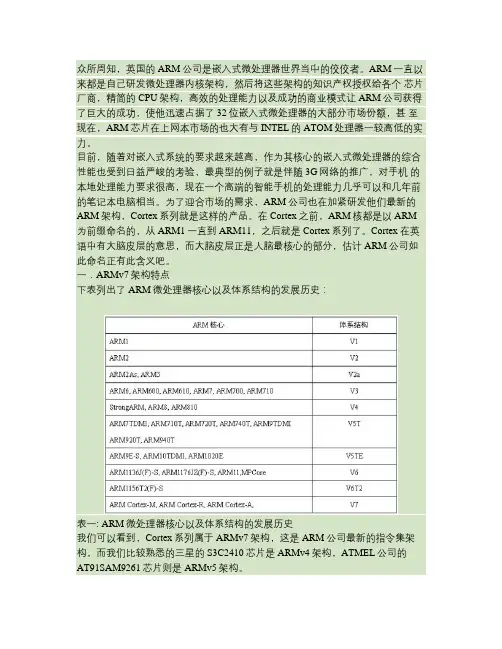
众所周知,英国的ARM公司是嵌入式微处理器世界当中的佼佼者。
ARM一直以来都是自己研发微处理器内核架构,然后将这些架构的知识产权授权给各个芯片厂商,精简的CPU架构,高效的处理能力以及成功的商业模式让ARM公司获得了巨大的成功,使他迅速占据了32位嵌入式微处理器的大部分市场份额,甚至现在,ARM芯片在上网本市场的也大有与INTEL的ATOM处理器一较高低的实力。
目前,随着对嵌入式系统的要求越来越高,作为其核心的嵌入式微处理器的综合性能也受到日益严峻的考验,最典型的例子就是伴随3G网络的推广,对手机的本地处理能力要求很高,现在一个高端的智能手机的处理能力几乎可以和几年前的笔记本电脑相当。
为了迎合市场的需求,ARM公司也在加紧研发他们最新的ARM架构,Cortex系列就是这样的产品。
在Cortex之前,ARM核都是以ARM 为前缀命名的,从ARM1一直到ARM11,之后就是 Cortex系列了。
Cortex在英语中有大脑皮层的意思,而大脑皮层正是人脑最核心的部分,估计ARM公司如此命名正有此含义吧。
一.ARMv7架构特点下表列出了ARM微处理器核心以及体系结构的发展历史:表一: ARM微处理器核心以及体系结构的发展历史我们可以看到,Cortex系列属于ARMv7架构,这是ARM公司最新的指令集架构,而我们比较熟悉的三星的S3C2410芯片是ARMv4架构,ATMEL公司的AT91SAM9261芯片则是ARMv5架构。
ARMv7架构是在ARMv6架构的基础上诞生的。
该架构采用了Thumb-2技术,Thumb-2技术是在ARM的Thumb代码压缩技术的基础上发展起来的,并且保持了对现存ARM解决方案的完整的代码兼容性。
Thumb-2技术比纯32位代码少使用 31%的内存,减小了系统开销。
同时能够提供比已有的基于Thumb技术的解决方案高出38%的性能。
ARMv7架构还采用了NEON技术,将DSP和媒体处理能力提高了近4倍,并支持改良的浮点运算,满足下一代3D图形、游戏物理应用以及传统嵌入式控制应用的需求。

ARM指令集是一种用于处理器架构的指令集体系结构。
它最初由英国公司ARM Holdings开发,并广泛应用于各种嵌入式系统、移动设备和低功耗应用中。
以下是ARM指令集的发展史:1. ARM1:ARM指令集最早出现在1985年的ARM1处理器上。
ARM1是一款32位处理器,采用精简指令集(RISC)设计理念,具有较低的能耗和成本。
2. ARM2:ARM2处理器于1987年发布,增加了对乘法指令的支持,并引入了缓存技术来提高性能。
3. ARMv3:ARMv3指令集体系结构于1992年推出,支持更多的指令和功能,如虚拟内存管理单元(VMMU)和协处理器。
4. ARMv4:ARMv4指令集体系结构于1995年发布,引入了Thumb指令集,可以以压缩的形式执行16位指令,提高了代码密度和节能效果。
5. ARMv5:ARMv5指令集体系结构于1997年推出,引入了Jazelle技术,使处理器能够直接执行Java字节码。
6. ARMv6:ARMv6指令集体系结构于2002年发布,引入了Thumb-2技术,将16位Thumb指令和32位ARM指令混合使用,提高了代码密度和性能。
7. ARMv7:ARMv7指令集体系结构于2004年发布,引入了NEON SIMD(单指令多数据)扩展指令集,提供更高的并行计算能力。
8. ARMv8:ARMv8指令集体系结构于2011年推出,是一个重要的里程碑,引入了64位处理器架构(AArch64),并保持了与之前32位指令集的向后兼容性。
9. ARMv9:目前(2024年)尚未发布,但ARM Holdings已经透露正在研发ARMv9指令集体系结构。
ARMv9预计将进一步提升性能、安全性和AI加速能力。
上述是ARM指令集的主要发展历程,每个版本都带来了新的功能和改进,使ARM成为全球最受欢迎的处理器架构之一,并广泛应用于各个领域。


ARM嵌入式系统第2章ARM体系结构ARM微处理器的编程模型♦ARM徴处理器的工作状态♦ARM体系结构的存储器格式♦ARM体系结构的指令长度及数据宽度♦ARM微处理器的处理器模式♦ARM体系结构的寄存器组织♦ARM微处理器的异常状态字、半字、字节字(Word)在ARM体系结构中,字的长度为32位半字(Half-Word)在ARM体系结构中,半字的长度为16位字节(Byg)在ARM体系结构中,字节的长度为8位。
ARM微处理器的工作状态(1)字对齐:四字节对齐半字对齐:两字节对齐两种状态:♦ARM状态:处理器执行32位的字对齐的令♦Thumb状态:处理器执行16位的、半字对齐的Thumb指令处理器工作状态的转变并不影响处理器的工作模式和相应寄存器中的内容。
I ARM微处理器的工作状态(2 )状态切换:BX {<cond>} <Rm><cond>指令的条件码。
忽略时无条件执行。
<Rm>子存器中为跳转的目标地址,当<Rm><存器的bit[O]为0时, 目标地址处的指令为ARM指令;当<Rm>^存器的bit[O]为1时,目标地址处的指令为Thumb 指令。
伪代码:if ConditionPassed(cond) thenT Flag=Rm[O]PC=Rm AND OxFFFFFFFEARM微处理器在复位或上电时处于ARM状态,发生异常时处于ARM状态。
右ARM体系结构的存储器格式(1)ARM体系结构所支持的最大寻址空间为4GB (2^字节)♦大端格式(Big Endian)字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
♦小端格式(Little Endian)低地址中存放的是字数据的低字节,高地址存放的是字数据的高字节。
字地址字地址右ARM 体系结构的存储器格式(2)(0H)=0123H (4H)=4567H (8H)=89ABHBig Endian(0H)=3210H (4H)=7654H (8H)=BA98HLittle Endian右ARM 体系结构的存储器格式(3)8 9 AB4 5 6 7 0123一 “A ・■ • rO= 0x11223344 I 11 I 22 33 : 44 ILittle endian Big endianR2 =异FI*右 ARM 体系结构的指令长度及数据宽度♦指令长度:32位(在ARM 状态下) 16位(在Thumb 状态下)♦数据宽度: 字节(8位) 半字(16位) 字(32位)三种数据宽度对存储器及外部设备的访问。




ARM处理器:“冯·诺依曼”体系结构和“哈佛”体系结构保存在存储器中的内容可以是程序,也可以是数据。
程序是ARM处理器可以运行的指令代码,数据是指令在运行中用到的操作数或者变量。
1、程序存储ARM处理器支持两种指令,一种是ARM汇编指令,一种是Thumb汇编指令。
ARM汇编指令是32位长,即每条ARM汇编指令都是由四个字节的存储空间保存,所以ARM处理器在执行地址a的ARM汇编指令时,会从地址a + 4取下一条指令。
Thumb汇编指令是16位长,即每条Thumb汇编指令都是由两个字节的存储空间保存,所以ARM处理器在执行地址a的Thumb汇编指令时,会从地址a + 2取下一条指令。
ARM处理器可以执行两种格式的指令,运行不同格式的汇编指令在执行和取指方面有很大不同。
为了区分,ARM内核可以工作在两种工作状态下。
l ARM状态此时执行32位字对齐的ARM汇编指令。
在这种状态下,ARM处理器对指令的存储、读取或者执行都是以一个字(即32位)为基本单位;l THUMB状态此时执行16位半字对齐的Thumb汇编指令。
在这种状态下,ARM处理器对指令的存储、读取或者执行都是以一个半字(即16位)为基本单位;l 这两种工作状态可以转换,但转换不影响处理器状态和寄存器的内容。
2、数据存储ARM处理器对数据操作(读或写)支持三种数据长度:字节(8位)、半字(16位)、字(32位)。
假设在地址为0x0000~0x0004的内存空间保存了如图1所示的数据,下面我们以三种数据长度从内存空间读取数据。
(假设数据的存储格式是小端存储格式)图1 内存空间的内容l 字节:从地址0x0000处取一个字节数据,则取出来的内容为12;从地址0x0001处取一个字节数据,则取出来的内容为34;l 半字:从地址0x0000处取一个半字数据,则取出来的内容为3412;从地址0x0001处取一。
ARM架构发展史及最新内核ARM架构发展史ARM 曾称进阶精简指令集机器(Advanced RISC Machine)更早称作 Acorn RISC Machine,是一个 32 位精简指令集(RISC)处理器架构,目前已经不仅是 32 位,也有部分架构是 64 位。
1983 年开始的开发计划,团队在1985 年时开发出ARM1 Sample 版,而首颗“真正”的产能型ARM2 于次年量产。
时至今日,ARM 已经开发出 9 代架构。
其主要核心见下表最新架构 Arm v9最新的 Arm v9 架构主要体现两大特性,安全与增强计算AI硬件安全性不确定性,一个漏洞可能会危及整个网络。
我们每天都面临着利用 Arm 技术的新尝试。
为了了解这个问题的普遍性,赛门铁克在 2020 年第一季度检测到近 1900 万次针对其物联网(IoT)的攻击。
这是每秒超过 100 次攻击的速度,比我们在 2019 年底看到的高出 13%。
在Arm v9 中,我们引入了旨在大规模提供机密计算(现在是行业优先事项)的新功能。
通常,设备的操作系统(OS)拥有最高权限,可以看到和做所有事情。
机密计算改变了这一点,虽然操作系统仍然决定什么时候可以运行,但应用程序位于一个单独的受硬件保护的内存区域,与系统中的所有其他内容隔离。
Arm 机密计算架构(CCA)建立在 Arm TrustZone 的基础之上,例如,您的个人银行信息可以与智能手机的社交媒体应用程序完全分离。
Arm CCA 的新安全功能意味着即使社交媒体应用确实感染了恶意软件,它也无法传播到您设备的其余部分。
机密计算对于客户端设备很重要,但它也具有普遍价值,因为它可以在传输、静止时保持数据加密,并在使用时由硬件隔离。
在云中,这也意味着保护物理 CPU 以及在第三方代码旁边运行的虚拟化处理器。
总之,Arm 上的机密计算很重要。
我们已经开发的安全功能,以及我们未来将要创建的安全功能,将在所有层级的计算应用程序中发挥作用;帮助保护物联网传感器、手机、笔记本电脑、互联网和云。
arm内核全解析_arm内核体系结构分类介绍ARM处理器是英国Acor n有限公司设计的低功耗成本的第一款RISC微处理器。
全称为Ad vanced RISC Machine。
ARM处理器本身是32位设计,但也配备16位指令集,一般来讲比等价32位代码节省达35%,却能保留32位系统的所有优势。
ARM内核特点ARM处理器为RISC芯片,其简单的结构使ARM内核非常小,这使得器件的功耗也非常低。
它具有经典RISC的特点:* 大的、统一的寄存器文件;* 简单的寻址模式;* 统一和固定长度的指令域,3地址指令格式,简化了指令的译码。
编译开销大,尽可能优化,采用三地址指令格式、较多寄存器和对称的指令格式便于生成优化代码;* 单周期操作,ARM指令系统中的指令只需要执行简单的和基本的操作,因此其执行过程在一个机器周期内完成;* 固定的32位长度指令,指令格式固定为32位长度,这样使指令译码结构简单,效率提高;* 采用指令流水线技术。
ARM内核体系结构ARM架构自诞生至今,已经发生了很大的演变,至今已定义了7种不同的版本:V1版架构:该架构只在原型机ARM1出现过,其基本性能包括基本的数据处理指令(无乘法)、字节、半字和字的Load/Store指令、转移指令,包括子程序调用及链接指令、软件中断指令、寻址空间64MB。
V2版架构:该版架构对V1版进行了扩展,如ARM2与ARM3(V2a版)架构,增加的功能包括乘法和乘加指令、支持协处理器操作指令、快速中断模式、SWP/SWPB的最基本存储器与寄存器交换指令、寻址空间64MB。
V3版架构:该版对ARM体系结构作了较大的改动,把寻址空间增至32位(4G B),增加了当前程序状态寄存器CPSR和程序状态保存寄存器 SPSR以便于异常处理。
增加了中止和未定义2种处理器模式。
ARM6就采用该版结构。
指令集变化包括增加了M RS/MSR指令,以访问新增的CPSR /SPSR寄存器、增加了从异常处理返回的指令功能。
处理器的体系结构定义了指令集(ISA)和基于这一体系结构下处理器的程序员模型。
尽管每个处理器性能不同,所面向的应用不同,每个处理器的实现都要遵循这一体系结构。
ARM 体系结构为嵌入系统发展商提供很高的系统性能,同时保持优异的功耗和面积效率。
ARM体系结构的发展ARM体系结构为满足ARM合作者以及设计领域的一般需求正稳步发展。
每一次ARM体系结构的重大修改,都会添加极为关键的技术。
在体系结构作重大修改的期间,会添加新的性能作为体系结构的变体。
下面的名字表明了系统结构上的提升,后面附加的关键字表明了体系结构的变体。
V3结构 32位地址。
T ? Thumb状态:16位指令。
M ? 长乘法支持(32*32=>64或者32*32+64=>64)。
这一性质已经变成V4结构的标准配置。
V4结构加入了半字存储操作。
D ? 对调试的支持(Debug)I ? 嵌入的ICE(In Circuit Emulation)属于V4体系结构的处理器(核)有ARM7,ARM7100(ARM7核的处理器),ARM7500(ARM7核的处理器)。
属于V4T(支持Thumb指令)体系结构的处理器(核)有 ARM7TDMI,ARM7TDMI-S (ARM7TDMI可综合版本),ARM710T(ARM7TDMI核的处理器),ARM720T(ARM7TDMI 核的处理器),ARM740T(ARM7TDMI核的处理器),ARM9TDMI,ARM910T(ARM9TDMI 核的处理器),ARM920T(ARM9TDMI核的处理器),ARM940T(ARM9TDMI核的处理器),StrongARM(Intel公司的产品)。
V5结构提升了ARM和Thumb指令的交互工作能力。
E ? DSP指令支持。
J ? Java指令支持。
属于V5T(支持Thumb指令)体系结构的处理器(核)有ARM10TDMI,ARM1020T (ARM10TDMI核处理器)。
属于V5TE(支持Thumb,DSP指令)体系结构的处理器(核)有ARM9E,ARM9E-S(ARM9E 可综合版本),ARM946(ARM9E核的处理器),ARM966(ARM9E核的处理器),ARM10E,ARM1020E(ARM10E核处理器),ARM1022E(ARM10E核的处理器), Xscale(Intel公司产品)。
属于V5TEJ(支持Thumb,DSP指令,Java指令)体系结构的处理器(核)有ARM9EJ,ARM9EJ-S(ARM9EJ可综合版本),ARM926EJ(ARM9EJ核的处理器),ARM10EJ。
V6结构增加了媒体指令属于V6体系结构的处理器核有ARM11。
ARM体系结构中有四种特殊指令集:Thumb指令(T),DSP指令(E),Java指令(J),Media指令,V6体系结构包含全部四种特殊指令集。
为满足向后兼容,ARMv6也包括了ARMv5的存储器管理和例外处理。
这将使众多的第三方发展商能够利用现有的成果,支持软件和设计的复用。
新的体系结构并不是想取代现存的体系结构,使它们变得多余。
新的CPU核和衍生产品将建立在这些结构之上,同时不断与制造工艺保持同步。
例如基于V4T体系结构的ARM7TDMI核还在广泛被新产品所使用。
新体系结构的发展动力下一代体系结构的发展是由不断涌现的新产品和变化的市场来推动的。
关键的设计约束是显而易见的,功能,性能,速度,功耗,面积和成本必须与每一种应用的需求相平衡。
保证领先的性能/功耗(MIPS/Watt)在过去是ARM成功的基石,在将来的应用中它也是一个重要衡量标准。
随着计算和通讯持续覆盖许多消费领域,功能也变得愈来愈复杂,消费者期望有高级的用户界面,多媒体以及增强的产品性能。
ARMv6将更有效的对这些新性质和技术进行有效的支持。
驱动RMv6体系结构发展的市场主要有无线,网络,自动化和消费娱乐市场。
ARM在过去与体系结构的受权者和主要合作者像Intel,Microsoft,Symbian和TI共同定义了ARMv6体系结构的需求。
ARMv6体系结构的提升发展ARMv6体系结构的过程中,精力主要集中在五个方面:存储器管理存储器管理方式严重影响系统设计和性能。
存储器结构的提升将大大提高处理器的整体性能-尤其是对于面向平台的应用。
ARMv6体系结构可以提高取指(数据)效能。
处理器将花费更少的时间在等待指令和缓存未命中数据重装载上面。
存储器管理的提升将使系统性能提升30%。
而且,存储器管理的提升也会提高总线的使用效率。
更少的总线活动意味着功耗方面的节省。
多处理器应用覆盖驱动系统实现向多处理器方向发展。
无线平台,尤其是2。
5G和3G,都是典型的需要整合多个ARM处理器或ARM与DSP的应用。
多处理器材通过共享内存来有效的共享数据。
新的ARMv6在数据共享和同步方面的能力将使它更容易实现多处理器,以及提高它们的性能。
新的指令使能复杂的同步策略,更大的提升了系统效能。
多媒体支持单指令流多数据流(SIMD)能力使得软件更有效地完成高性能的媒体应用像声音和图像编码器。
ARMv6指令集合中加入了超过60个SIMD指令。
加入SIMD指令将使性能提高2倍到4倍。
SIMD能力使发展商可以完成高端的像图象编码,语音识别,3D图象,尤其是与下一代无线应用相关的。
数据处理数据的大小端问题是指数据以何种方式在存储器中被存储和引用。
随着更多的SOC集成,单芯片不仅包含小端的OS环境和界面(像USB,PCI),也包含大端的数据(TCP/IP包,MPEG流)。
ARMv6体系结构,支持混合。
结果,数据处理问题在ARMv6体系结构中更为有效。
未对齐数据是指数据未与自然边界对齐。
例如,在DSP应用中有时需要将字数据半字对齐。
处理器更有效处理这种情形需要能够装载字到任何半字边界。
当前版本的体系结构需要大量指令处理未对齐数据。
ARMv6兼容结构处理未对齐数据更有效。
对于严重依赖未对齐数据的DSP算法,ARMv6体系结构将有性能的提高以及代码数量的缩减。
未对齐数据支持将使ARM处理器在仿真其它处理器像Motorola的68000系列方面更有效。
与ARMv5的实现像ARM10和Xscale,ARMv6是基于32位处理器。
ARMv6可以实现64位或64位以上的总线宽度。
这使得总线等于甚至超过64位处理器,但功耗和面积却比64位CPU要低。
例外(EXCEPTION)与中断对于实时系统来说,对于中断的效率是要求严格的。
像硬盘控制器,引擎管理应用,这些应用中如果中断没有及时得到响应,那后果将是严重的。
更有效的处理中断与例外也能提高系统整体表现。
在降低系统时尤为重要。
在ARMv6体系结构中,新的指令被加入了指令集合来提升中断与例外的实现。
这些将有效提升特权模式下例外处理。
ARM11主要性能ARM11是ARMv6体系结构的第一个实现,ARM11微结构的设计目的是为了高性能,而实现这一目的流水线是关键。
ARM11微结构的流水线与以前的ARM核不同,它包含8级流水,使贯通率比以前的核提高40%。
单指令发射ARM11微结构的流水线是标量的(SCALAR),即每次只发射一条指令(单发射)。
有些流水线结构可以同时发射多条指令,例如,可以同时向ALU和MAC流水线发射指令。
理论上,多发射微结构会有更高的效能,但实践上,多发射微结构无疑会增加前段指令译码级的复杂程度,因为需要更多的逻辑来处理指令相关(DEPENDENCY),这将使处理器的面积和功耗变得更大。
分支预测分支指令通常是条件指令,它们在跳到新指令前需要进行一些条件的测试。
由于条件指令译码需要的条件码要三四个周期后才可能有结果,分支有可能引起流水线的延迟。
但分支预测将会有助于避免这种延迟。
ARM11微结构使用两种技术来预测分支。
首先,动态的预测器使用历史记录来判断分支是最频繁发生,还是最不频繁发生。
动态预测器是一个64个分录,4状态(StronglyTaken,WeaklyTaken,Strongly notTaken,Weakly notTaken)的分支目标地址缓存(BTAC)。
表格大小足够保持最近的分支情况,分支预测就基于以前的结果。
其次,如果动态的分支预测器没有发现记录,就使用静态的分支算法。
很简单,静态预测检查分支是向前跳转还是向后跳转。
假如是向后跳转,就假定它是一个循环,预测该分支发生,假如是向前跳转,就预测该分支不发生。
通过使用动态和静态的分支预测,ARM11微结构中分支指令中的85%被正确预测。
存储器访问ARM11微结构存储器系统的提高之一就是非阻塞(NON-BLOCKING)和缺失命中(HIT-UNDER-MISS)操作。
当指令取的数据不在缓存中时,一般处理器的流水线会停止下来,但ARM11则进行非阻塞操作,缓存开始读取缺失的数据,而流水线可以继续执行下一指令(NON-BLOCKING),并且允许该指令读取缓存中的数据(HIT-UNDER-MISS)。
并行流水线尽管流水线是单发射的,在流水线的后端还是使用了三个并行部件结构,ALU,MAC(乘加),LS(存取)。
LS流水线是专门用于处理存取操作指令。
把数据的存取操作与数据算术操作的藕合性分隔开来可以更有效的处理执行指令。
在流水线中包含LS部件的ARM11微结构中,ALU或者MAC指令不会由于LS指令的等待而停止下来。
这也使得编译工具有更大的自由度通过重新安排代码来提高性能。
为使并行流水线获得更大的效能,ARM11微结构使用了乱序完成(OUT-OF-ORDER COMPLETION)。
64位数据路径对于目前的许多应用来说,由于成本与功耗的问题,真64位处理器并不十分必要。
ARM11微结构在局部合理使用64位结构,通过32位的成本来实现64位的性能。
ARM11微结构在处理器整数部件与缓存之间,整数部件与协处理器之间使用了64位数据总线。
64位的路径可以在一个周期内从缓存中读取两条指令,允许每周期传送两个ARM寄存器的数据。
这使得许多数据移动操作与数据加工操作变得更为高性能。
浮点处理ARM11微结构支持浮点处理。
ARM11微结构产品线将浮点处理单元作为一个选项。
这可以方便发展商根据需求需用合适的产品。