段错误(core dumped)
- 格式:doc
- 大小:38.00 KB
- 文档页数:4

1 执行socket文件时,出现段错误 (core dumped产生段错误就是访问了错误的内存段,一般是你没有权限,或者根本就不存在对应的物理内存,尤其常见的是访问0地址.解决方法:利用gdb逐步查找段错误:首先我们需要一个带有调试信息的可执行程序,所以我们加上“-g -rdynamic"的参数进行编译,然后用gdb调试运行这个新编译的程序,具体步骤如下:1、 gcc -g -rdynamic d.c2、 gdb ./a.out3、 r这样就找到了出错位置。
然后在相应位置修改。
2 linux 段错误如何调试linux下的c程序常常会因为内存访问错误等原因造成segment fault(段错误)此时如果系统core dump功能是打开的,那么将会有内存映像转储到硬盘上来,之后可以用gdb对core文件进行分析,还原系统发生段错误时刻的堆栈情况。
这对于我们发现程序bug很有帮助。
使用ulimit -a可以查看系统core文件的大小限制;使用ulimit -c [kbytes]可以设置系统允许生成的core文件大小。
ulimit -c 0 不产生core文件ulimit -c 100 设置core文件最大为100kulimit -c unlimited 不限制core文件大小步骤:1、当发生段错误时,我们查看ulimit -a (core file size (blocks, -c 0)并没有文件,2、设置:ulimit -c unlimited 不限制core文件大小3.、运行程序,发生段错误时会自动记录在core中4、test]$ ls -al core.* 在那个文件下(-rw------- 1 leconte leconte 139264 01-06 22:3 1 core.2065)5、使用gdb 运行程序和段错误记录的文件。
(est]$ gdb ./test core.2065)6、会提哪行有错。

应用程序运行时产生coredump故障处理环境:操作系统:AIX Common 数据库:无关应用程序:32-bit症状:客户应用结息程序在运行过程中产生coredump。
程序故障与处理数据量有关,当把结息网点分成两批,可以顺利完成。
解决方法:应用程序的问题本来不属于我们维保的范畴,因为客户关系比较好,开发商太极公司也是我们的友军,抱着试试看的态度来解决。
用svmon跟踪程序的执行,发现其在运行期间,work process private部分的内存增长速度非常快,并且很明显地,接近65536页的时候即发生core dump。
这表明程序故障与内存的过度使用有关,达到256MB阀值时溢出。
work process private与用户程序的堆、栈有关,其中堆常为malloc系统调用分配的内存空间。
这里与ulimit设置无关(已经设置为unlimited),与AIX 32位程序的内存分配行为有关。
32位程序最多可以使用16个内存段,其中segment 2~C用户可用作堆栈和共享内存,默认仅使用segment 2存放程序堆栈数据,最大值为256MB,所以默认情况下用户程序最多只能分配256MB的堆内存。
而这个默认行为,可以通过在执行程序前,设置LDR_CNTRL环境变量来调节堆栈部分和共享内存的比例,例如:LDR_CNTRL=MAXDATA=0x30000000,设置了堆栈内存空间最多可使用3个内存段,共768MB 内存。
下面是一个测试的例子:# include <stdio.h>main (){int i;unsigned char *p;i=0;while ( i < 20 ){printf ( "i=%d\n", i );/* 32M */p=(unsigned char *)malloc(33554432);memset(p,'\0',33554432);i=i+1;sleep(1);}sleep(120);}直接运行该程序,在i=7之后产生coredump,采用下面的方式执行命令:# LDR_CNTRL=MAXDATA=0x3000000 ./testmalloc程序能够正常执行结束运行,同时运行的svmon显示程序已经使用到了256MB以上的堆空间。
浅析Linux下core文件当我们的程序崩溃时,内核有可能把该程序当前内存映射到core文件里,方便程序员找到程序出现问题的地方。
最常出现的,几乎所有C程序员都出现过的错误就是“段错误”了。
也是最难查出问题原因的一个错误。
下面我们就针对“段错误”来分析core文件的产生、以及我们如何利用core文件找到出现崩溃的地方。
何谓core文件当一个程序崩溃时,在进程当前工作目录的core文件中复制了该进程的存储图像。
core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。
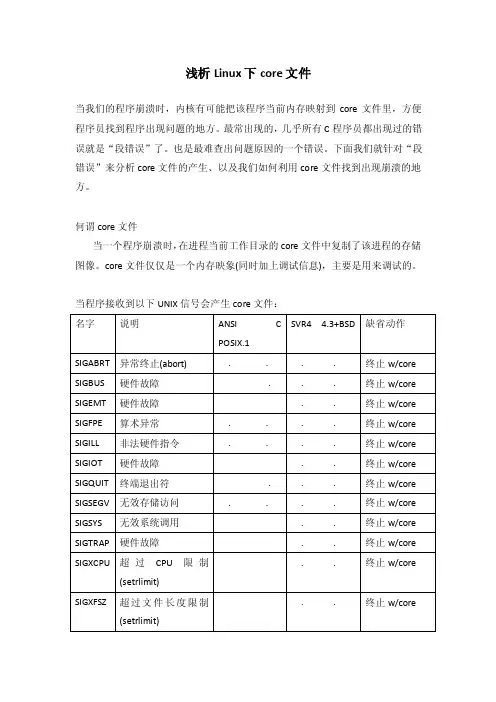
当程序接收到以下UNIX信号会产生core文件:在系统默认动作列,“终止w/core”表示在进程当前工作目录的core文件中复制了该进程的存储图像(该文件名为core,由此可以看出这种功能很久之前就是UNIX功能的一部分)。
大多数UNIX调试程序都使用core文件以检查进程在终止时的状态。
core文件的产生不是POSIX.1所属部分,而是很多UNIX版本的实现特征。
UNIX第6版没有检查条件(a)和(b),并且其源代码中包含如下说明:“如果你正在找寻保护信号,那么当设置-用户-ID命令执行时,将可能产生大量的这种信号”。
4.3 + BSD 产生名为core.prog的文件,其中prog是被执行的程序名的前1 6个字符。
它对core文件给予了某种标识,所以是一种改进特征。
表中“硬件故障”对应于实现定义的硬件故障。
这些名字中有很多取自UNIX早先在DP-11上的实现。
请查看你所使用的系统的手册,以确切地确定这些信号对应于哪些错误类型。
下面比较详细地说明这些信号。
SIGABRT 调用abort函数时产生此信号。
进程异常终止。
SIGBUS 指示一个实现定义的硬件故障。
SIGEMT 指示一个实现定义的硬件故障。
EMT这一名字来自PDP-11的emulator trap 指令。
SIGFPE 此信号表示一个算术运算异常,例如除以0,浮点溢出等。

达梦主备集群段错误(核⼼已转储)在给客户部署两套主备集群的时候,出现⼀件让我⾮常头疼的问题。
第⼀套集群在政务外⽹,第⼆套集群在互联⽹。
部署第⼀套集群的时候,启动达梦守护进程报错(段错误(核⼼已转储)),主备节点都报错,检查dm.ini 、 dmarch.ini 、 dmmal.ini和dmwatcher.ini,都没发现有任何错误。
这个时候我们猜测,会不会是安装包的问题,我们⽤的安装包如下:dm8_20210915_HWarm_centos7_64_ent_8.1.2.70.iso这是最新的安装包,我之前没⽤这个安装包部署过集群,猜测可能是安装包中有bug。
正好,在客户的第⼆套集群上试⼀下,看看会不会出现同样的问题。
吭哧吭哧部署完后,发现互联⽹上的那套集群,⼀切正常,这下傻眼了,检查了下集群配置,政务外⽹的和互联⽹的集群配置⼀模⼀样,那为什么政务外⽹那套集群会报错呢?接下来开始正式排查问题。
⼀、查看报错信息这是启动守护进程时报的错,从报错信息上看不出什么问题,后来也查看了watcher的⽇志,也没发现什么问题,最后只能⽣成core⽂件,查看core⽂件中的报错信息。
⼆、⽣成core⽂件集群出现问题,core⽂件⼀般会⾃动⽣成,可以直接查找对应的core⽂件,也可以指定core⽂件⽣成路径。
1、直接查找core⽂件因为我们是在启动dmwatcher的时候报错,所以可以直接通过守护进程的关键字进⾏查找。
1)、find查找find / -name *dmwatcher*查到的内容如下:2)、拷贝出来如果觉得直接在这⾥查看不⽅便,可以拷贝最新的core到指定⽬录,最好把名字重命名⼀下,默认的名称太长了。
cp拷贝出来拷贝最新的,⼀般最下⾯的⽐较新:cp /var/lib/systemd/coredump/core.dmwatcher.1001.88045ab03b7c437bb3b6ebbc53218cb6.16566.1631948801000000000000.lz4/home/dmdba/3)、Lz4解压lz4 core.dmwatcher.1001.88045ab03b7c437bb3b6ebbc53218cb6.16566.1631948801000000000000.lz44)、重命名mv core.dmwatcher.1001.88045ab03b7c437bb3b6ebbc53218cb6.16566.1631948801000000000000 core.165665)、查看core[root@localhost dmdba]# cd dmdbms/bin[root@localhost bin]# gdb /home/dmdba/core.16566输⼊bt6)、猜测core报错说“连接已存在”,猜测可能是ip和端⼝冲突导致的。

coredump文件生成过程
生成core dump文件通常发生在程序发生严重错误或崩溃时,
它记录了程序在崩溃时的内存状态和调用栈信息,有助于开发人员
分析问题并进行调试。
下面我会从多个角度来解释core dump文件
生成的过程。
1. 产生原因,当程序发生严重错误,比如访问非法内存、除零
错误、段错误等,操作系统会向程序发送一个信号,通常是SIGSEGV(段错误)或SIGABRT(异常终止),程序在收到信号后会
尝试生成core dump文件。
2. 操作系统设置,在大多数操作系统中,生成core dump文件
需要进行相应的设置。
在Linux系统中,可以使用ulimit命令设置core文件大小限制,使用sysctl命令设置core文件的名称格式和
存储路径。
在Windows系统中,可以通过控制面板中的系统属性进
行设置。
3. 内存转储,当程序接收到信号时,操作系统会将程序的内存
状态以及相关信息写入core dump文件中。
这包括程序的内存布局、寄存器状态、堆栈信息等。
4. 存储位置,生成的core dump文件通常会被存储在当前工作目录或指定的路径下,具体存储位置取决于系统设置和程序运行时的环境变量。
5. 调试分析,生成core dump文件后,开发人员可以使用调试工具(如gdb、windbg等)加载core dump文件,重现程序崩溃时的状态,并进行分析和调试,以找出程序中的错误和异常。
总的来说,生成core dump文件是程序在发生严重错误时的一种自我保护机制,它记录了程序崩溃时的状态信息,为开发人员提供了重要的调试和分析数据,有助于快速定位和解决问题。

SegmentFault(coredump)调试方法Coredump关于程序core dump的调试方法简述:首先,在程序不正常退出时,内核会在当前工作目录下生成一个core文件(是一个内存映像,同时加上调试信息)。
使用gdb来查看core文件,可以指示出导致程序出错的代码所在文件和行数。
这个能给debug带来极大方便。
查看core dump位置方法:"gdb ./app core".故,我们需要gdb,可执行文件app,以及core文件。
下面将根据这3个需求,依次得到它们;一、1,得到gdb;其实这个是最简单的,Linux PC上gdb不用说了。
Android的是~/opt/android-ndk-r7/toolchains/arm-linux-androideabi-4.4.3/prebuilt/linux-x86/b in/arm-linux-androideabi-gdb(其中~/opt/,与个人设置有关;android-ndk-r7与编译器版本有关,貌似android-ndk-r4没有toolchains目录,不知是否可以用gdbserver 调试程序,当然这就不在本文档的讨论范围之内了).2,得到可执行文件app由于要使用gdb,所以app必须是"not stripped".Linux PC上"gcc hello.c"编译出来的a.out默认就是"not stripped".Android工程中jni目录下,我们使用"ndk-build"默认是"stripped"的。
因此需要更改编译脚本:在~/opt/android-ndk-r7/build/core/中打开default-build-commands.mk文件,将"cmd-strip = $(PRIVATE_STRIP) --strip-unneeded $(call host-path,$1)"这一行注释掉.这一行就是做的"strip"操作。

coredump文件的生成方式
Core dump文件是在程序发生严重错误(如段错误、内存访问
越界等)时,操作系统将程序当前的内存状态以文件的形式保存下
来的一种机制。
生成core dump文件的方式可以通过以下几种途径:
1. 通过ulimit命令设置core dump文件大小限制,可以使用ulimit命令来设置core dump文件的大小限制,使用ulimit -c unlimited命令可以将core dump文件的大小限制设置为无限制,
这样当程序发生错误时就会生成core dump文件。
2. 在程序中使用系统调用设置,在程序中可以通过调用系统函
数来设置生成core dump文件的方式,比如使用ulimit函数设置core dump文件大小限制,或者使用prctl函数设置生成core dump
文件的路径等。
3. 通过操作系统的配置文件设置,在一些操作系统中,可以通
过修改配置文件(如/etc/security/limits.conf)来设置生成
core dump文件的大小限制和路径等参数。
4. 使用特定的调试工具,在调试程序时,可以使用特定的调试
工具(如gdb)来设置程序发生错误时生成core dump文件,通过gdb工具可以设置生成core dump文件的路径和大小限制等参数。
总的来说,生成core dump文件的方式可以通过操作系统的设置、程序中的系统调用、配置文件的修改以及调试工具的使用等途径来实现。
不同的操作系统和调试工具可能会有不同的设置方法,需要根据具体情况进行选择和配置。

C语⾔中段错误的解决⽅法Segmentationfault(coredumped)
在C语⾔中,任何操作指令都离不开对内存的操作,所以即便编译的时候没有语法操作,但是在实际运⾏中有可能对内存进⾏⾮法操作,这种情况就会产⽣段错误Segmentation fault (core dumped)!要解决段错误就要先找到段错误的地⽅。
如何在程序中寻找段错误?
段错误不是语法错误,所以在编译时不会提⽰出错,只有等到运⾏时才会提⽰出现段错误,但是段错误不会提⽰在哪⼀⾏,可以通过printf()函数来寻找段错误位置,只要发⽣段错误,那么程序就会马上结束。
举个例⼦:
printf("11111!\n");
xxxx;
printf("22222!\n");
yyyy;
printf("33333!\n");
zzzz;
假如运⾏上述代码得到的执⾏结果为:
11111!
22222!
Segmentation fault (core dumped) -> 说明段错误是出现"yyyy;"
段错误⼀般是指针指向有问题,找到段错误的地⽅最好打印出指针内容看看是不是⾃⼰预期的指针内容再进⾏修改,如果是链表就画图查看⾃⼰的链表逻辑有没有出问题
总结解决段错误的步骤:
1.使⽤printf()函数寻找段错误的地⽅
2.打印出现段错误的指针,链表或者打开⽂件⽬录的返回值看看是不是⾃⼰的预期结果
3.根据结果现在修改代码重新编译。

Segmentationfault(coredumped)错误的⼀种解决场景错误类型Segmentation fault (core dumped)产⽣原因Segmentation fault 段错误。
Core Dump 核⼼转储(是操作系统在进程收到某些信号⽽终⽌运⾏时,将此时进程地址空间的内容以及有关进程状态的其他信息写出的⼀个磁盘⽂件。
这种信息往往⽤于调试),其实“吐核”这个词形容的很恰当,就是核⼼内存吐出来。
出现这种错误可能的原因(其实就是访问了内存中不应该访问的东西):1,内存访问越界:(1)数组访问越界,因为下标出超出了范围。
(2)搜索字符串的时候,通过字符串的结尾符号来判断结束,但是实际上没有这个结束符。
(3)使⽤strcpy, strcat, sprintf, strcmp,strcasecmp等字符串操作函数,超出了字符中定义的可以存储的最⼤范围。
使⽤strncpy, strlcpy, strncat, strlcat, snprintf, strncmp, strncasecmp等函数防⽌读写越界。
2,多线程程序使⽤了线程不安全的函数。
3,多线程读写的数据未加锁保护。
对于会被多个线程同时访问的全局数据,应该注意加锁保护,否则很容易造成核⼼转储4,⾮法指针(1)使⽤NULL指针(2)随意使⽤指针类型强制转换,因为在这种强制转换其实是很不安全的,因为在你不确认这个类型就应该是你转化的类型的时候,这样很容易出错,因为就会按照你强制转换的类型进⾏访问,这样就有可能访问到不应该访问的内存。
5,堆栈溢出不要使⽤⼤的局部变量(因为局部变量都分配在栈上),这样容易造成堆栈溢出,破坏系统的栈和堆结构,导致出现莫名其妙的错误。
解决场景在linux的虚拟机上跑了⼀个数据结构,在虚拟机上出现上述错误,在Windows的宿主机弹出错误。
于是试运⾏⼀个相似的较简单的哈希函数,虚拟机上出现相同错误,,注意到以下代码:// generates a hash value for a sting// same as djb2 hash functionunsigned int CountMinSketch::hashstr(const char *str) {unsigned long hash = 5381;int c;while (c = *str++) {hash = ((hash << 5) + hash) + c; /* hash * 33 + c */}return hash;}这是⼀个针对字符串的哈希函数,其中⼀⾏hash = ((hash << 5) + hash) + c; /* hash * 33 + c */是问题所在,针对较长的字符串,这个hash变量会不断变⼤,甚⾄溢出。

Linux下的段错误产生的原因及调试方法&&Core Dump简而言之,产生段错误就是访问了错误的内存段,一般是你没有权限,或者根本就不存在对应的物理内存,尤其常见的是访问0地址.一般来说,段错误就是指访问的内存超出了系统所给这个程序的内存空间,通常这个值是由gdtr来保存的,他是一个48位的寄存器,其中的32位是保存由它指向的gdt表,后13位保存相应于gdt的下标,最后3位包括了程序是否在内存中以及程序的在cpu中的运行级别,指向的gdt是由以64位为一个单位的表,在这张表中就保存着程序运行的代码段以及数据段的起始地址以及与此相应的段限和页面交换还有程序运行级别还有内存粒度等等的信息。
一旦一个程序发生了越界访问,cpu就会产生相应的异常保护,于是segmentation fault就出现了.在编程中以下几类做法容易导致段错误,基本是是错误地使用指针引起的1)访问系统数据区,尤其是往系统保护的内存地址写数据最常见就是给一个指针以0地址2)内存越界(数组越界,变量类型不一致等) 访问到不属于你的内存区域解决方法我们在用C/C++语言写程序的时侯,内存管理的绝大部分工作都是需要我们来做的。
实际上,内存管理是一个比较繁琐的工作,无论你多高明,经验多丰富,难免会在此处犯些小错误,而通常这些错误又是那么的浅显而易于消除。
但是手工“除虫”(debug),往往是效率低下且让人厌烦的,本文将就"段错误"这个内存访问越界的错误谈谈如何快速定位这些"段错误"的语句。
作地址为0的内存区域,而这个内存区域通常是不可访问的禁区,当然就会出错1.利用gdb逐步查找段错误:这种方法也是被大众所熟知并广泛采用的方法,首先我们需要一个带有调试信息的可执行程序,所以我们加上“-g -rdynamic"的参数进行编译,然后用gdb调哦?!如此的简单。
从这里我们还发现进程是由于收到了SIGSEGV信号而结束的。

什么是coredump?以及如何使⽤gdb对coredumped进⾏调试什么是core dump?(down = 当) core的意思是:内存,dump的意思是:扔出来、堆出来。
开发和使⽤linux程序时,有时程序莫名其妙的down掉了,却没有任何的提⽰(有时候会提⽰core dumped)。
这时候可以查看⼀下有没有形如:core的⽂件⽣成,这个⽂件便是操作系统把程序down掉时的内存的内容扔出来⽣成的,它可以做为调试程序的参考。
core dump⼜叫核⼼转储,当程序运⾏过程中发⽣异常,程序异常退出时,由操作系统把程序当前的内存状况存储在⼀个core⽂件中,叫core dump。
为什么没有core⽂件⽣成呢? 有时候程序down掉了,但是core⽂件却没有⽣成。
⾸先,就是要知道错误发⽣的地⽅。
⽽Linux系统可以产⽣core⽂件,配合gdb就可以解决这个问题。
core⽂件的⽣成跟你当前系统的环境设置有关系,可以⽤下⾯的语句设置⼀下,然后再运⾏程序便成⽣成core⽂件了。
第⼀步:让系统在信号中断造成的错误时产⽣core⽂件: ulimit -c unlimited // 设置core⼤⼩为⽆限 ulimit unlimited //设置⽂件⼤⼩为⽆限第⼆步:编译原来的程序: gcc -o xxx xxx.c -g (-g选项的作⽤是在可执⾏⽂件中加⼊源码信息,⽐如可执⾏⽂件中第⼏条机器指令对应源代码的第⼏⾏,但并不是把整个源⽂件嵌⼊到可执⾏⽂件中,⽽是在调试时必须保证gdb能找到源⽂件。
)第三步:运⾏编译后的的程序: ./xxx(或者 xxx) 运⾏后,然后 ls 发现多出来了core⽂件。
core⽂件⽣成的位置⼀般与运⾏程序的路径相同,⽂件名⼀般为core。
第四步:⽤gdb查看core⽂件: 安装完成后使⽤如下命令: gdb xxx core第五步:输⼊bt或者where,就会出现错误的位置,就可以显⽰程序在哪⼀⾏dowm掉的,在哪个函数中down掉的。
segmentation fault (core dumped)的意思
segmentation fault (core dump) 是指计算机程序中出现内存泄漏或者访问未分配内存的异常,导致程序崩溃并向操作系统发送一个内存错误信号(例如SegmentationFault)。
在计算机操作系统中,内存管理是由硬件和软件共同完成的。
当程序尝试访问未分配给它的内存地址时,操作系统会发出信号以指示程序尝试访问无效内存,从而引起程序崩溃。
Segmentation fault 是一个重要的错误信号,标志着程序出现了内存访问异常,通常会导致程序崩溃和停止执行。
这个错误通常由程序员在编写程序时没有正确处理内存分配和释放,或者使用了错误的内存访问操作引起。
解决 segmentation fault 的方法通常包括检查代码中是否存在内存泄漏,正确分配和管理内存,以及使用正确的内存访问策略。
linux coredump机制-回复Linux操作系统提供了一种机制,用于捕获并存储应用程序或进程在运行过程中遇到的错误。
这个机制被称为coredump(核心转储),它能够生成一个包含程序状态的二进制文件,以便我们可以在后续时间对错误进行分析和调试。
在本文中,我们将详细介绍coredump的机制,它的用途以及如何使用它进行故障排除。
首先,让我们了解一下coredump是什么。
Coredump是一个二进制文件,包含了程序在异常终止时的内存映像。
当一个程序由于例如段错误、非法指令、除以零等错误而崩溃时,操作系统会自动生成一个coredump 文件。
这个文件通常被放置在程序当前工作目录下,并且文件名以程序名加上一个“core.”前缀开头,例如“core.1234”。
那么为什么我们需要coredump?Coredump文件保存了程序崩溃时的堆栈跟踪信息、变量值以及其他与程序状态相关的信息。
通过分析这些信息,我们可以了解程序崩溃的原因,并且更容易地找到和修复bug。
对于大型软件项目来说,故障排除是一个繁琐而复杂的任务,而coredump 可以提供一个快速有效的方式来定位问题。
接下来,我们将详细讨论Linux coredump机制是如何工作的。
在默认情况下,Linux系统不会生成coredump文件,而是将内存映射到一个特殊的文件“/proc/sys/kernel/core_pattern”中。
这个文件包含一个字符串,用于指定生成coredump文件的位置和格式。
例如,“/tmp/coredump/core.e.p.t”指定coredump文件将被放置在“/tmp/coredump/”目录下,文件名以程序名、进程ID和时间戳为后缀。
获取coredump的关键在于设置coredump的大小限制。
通常情况下,Linux系统默认将coredump文件大小限制为0,即禁用coredump。
要启用coredump,我们可以通过设置“ulimit -c unlimited”命令来取消对coredump的大小限制。
关于Segmentationfault(coredumped)有的程序可以通过编译,但在运⾏时会出现Segment fault(段错误)。
这通常都是指针错误引起的。
但这不像编译错误⼀样会提⽰到⽂件⼀⾏,⽽是没有任何信息。
⼀种办法是⽤gdb的step, ⼀步⼀步寻找。
但要step⼀个上万⾏的代码让⼈难以想象。
我们还有更好的办法,这就是core file。
如果想让系统在信号中断造成的错误时产⽣core⽂件, 我们需要在shell中按如下设置:#设置core⼤⼩为⽆限 ulimit -c unlimited#设置⽂件⼤⼩为⽆限 ulimit unlimited发⽣core dump之后,⽤gdb进⾏查看core⽂件的内容, 以定位⽂件中引发core dump的⾏:gdb [exec file] [core file]如: gdb ./test test.core 在进⼊gdb后,⽤bt命令查看backtrace以检查发⽣程序运⾏到哪⾥,来定位core dump的⽂件->⾏。
另外需要注意的是,如果你的机器上跑很多的应⽤,你⽣成的core⼜不知道是哪个应⽤产⽣的,你可以通过下列命令进⾏查看:file core⼏个问题:1. 什么是Core:在使⽤半导体作为内存的材料前,⼈类是利⽤线圈当作内存的材料(发明者为王安),线圈就叫作 core ,⽤线圈做的内存就叫作 core memory。
如今,半导体⼯业澎勃发展,已经没有⼈⽤core memory 了,不过,在许多情况下,⼈们还是把记忆体叫作 core 。
2. 什么是Core Dump:我们在开发(或使⽤)⼀个程序时,最怕的就是程序莫明其妙地当掉。
虽然系统没事,但我们下次仍可能遇到相同的问题。
于是这时操作系统就会把程序当掉时的内存内容 dump 出来(现在通常是写在⼀个叫 core 的 file ⾥⾯),让我们或是 debugger 做为参考。
这个动作就叫作 core dump。
Linux下的C程序常常会因为内存访问错误等缘故造成segment fault(段错误),现在若是系统core dump功能是打开的,那么将会有内存映像转储到硬盘上来,以后能够用gdb对core文件进行分析,还原系统发生段错误时刻的堆栈情形。
这关于咱们发觉程序bug很有帮忙。
利用ulimit -a能够查看系统core文件的大小限制;利用ulimit -c [kbytes]能够设置系统许诺生成的core 文件大小,例如ulimit -c 0 不产生core文件ulimit -c 100 设置core文件最大为100kulimit -c unlimited 不限制core文件大小先看一段会造成段错误的程序:#include <>int main(){char *ptr="";*ptr=0;}编译运行后结果如下:[leconte@localhost test]$ gcc -g -o test[leconte@localhost test]$ ./test段错误现在并无产生core文件,接下来利用ulimit -c设置core文件大小为无穷制,再执行./te st程序,结果如下:[leconte@localhost ~]$ ulimit -acore file size (blocks, -c) 0[leconte@localhost test]$ ulimit -c unlimited[leconte@localhost test]$ ulimit -acore file size (blocks, -c) unlimited[leconte@localhost test]$ ./test段错误(core dumped)[leconte@localhost test]$ ls -al core.*-rw------- 1 leconte leconte 139264 01-06 22:31可见core文件已经生成,接下来能够用gdb分析,查看堆栈情形:[leconte@localhost test]$ gdb ./testGNU gdb Fedora (C) 2020 Free Software Foundation, Inc.License GPLv3+: GNU GPL version 3 or later <>This is free software: you are free to change and redistribute it.There is NO WARRANTY, to the extent permitted by law. Type "show copying "and "show warranty" for details.This GDB was configured as "i386-redhat-linux-gnu"...warning: exec file is newer than core file.warning: Can't read pathname for load map: Input/output error.Reading symbols from /lib/ symbols for /lib/ symbols from /lib/ symbols for / lib/ was generated by `./test'.Program terminated with signal 11, Segmentation fault.[New process 2065]#0 0x0804836f in main () at :66 *ptr=0;从上述输出能够清楚的看到,段错误出此刻的第6行,问题已经清楚地定位到了。
Linux下运⾏C++程序出现段错误(核⼼已转储)的原因 今天写程序出现了“段错误(核⼼已转储)"的问题,查了⼀下资料,加上⾃⼰的实践,总结了以下⼏个⽅⾯的原因。
1.内存访问出错
这类问题的典型代表就是数组越界。
2.⾮法内存访问
出现这类问题主要是程序试图访问内核段内存⽽产⽣的错误。
3.栈溢出
Linux默认给⼀个进程分配的栈空间⼤⼩为8M。
c++申请变量时,new操作申请的变量在堆中,其他变量⼀般在存储在栈中。
因此如果你数组开的过⼤变会出现这种问题。
⾸先我们先看⼀下系统默认分配的资源:
1 ulimit -a
可以看到默认分配的栈⼤⼩为8M。
如果真的需要更⼤的栈空间,可以⽤指令ulimit -s XXXX来申请更⼤的栈空间。
段错误 (core dumped)
当我们的程序崩溃时,内核有可能把该程序当前内存映射到core文件里,方便程序员找到程序出现问题的地方。
最常出现的,几乎所有C程序员都出现过的错误就是“段错误”了。
也是最难查出问题原因的一个错误。
下面我们就针对“段错误”来分析core文件的产生、以及我们如何利用core文件找到出现崩溃的地方。
何谓core文件
当一个程序崩溃时,在进程当前工作目录的core文件中复制了该进程的存储图像。
core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。
使用core文件调试程序
看下面的例子:
#include
char *str = "test";
void core_test(){
str[1] ='T';
}
int main(){
core_test();
return0;
}
编译:
gcc –g core_dump_test.c -o core_dump_test
如果需要调试程序的话,使用gcc编译时加上-g选项,这样调试core文件的时候比较容易找到错误的地方。
执行:
./core_dump_test
段错误
运行core_dump_test程序出现了“段错误”,但没有产生core文件。
这是因为系统默认core文件的大小为0,所以没有创建。
可以用ulimit命令查看和修改core文件的大小。
ulimit -c 0
ulimit -c 1000
ulimit -c 1000
-c指定修改core文件的大小,1000指定了core文件大小。
也可以对core文件的大小不做限制,如:
ulimit -c unlimited
ulimit -c unlimited
如果想让修改永久生效,则需要修改配置文件,如.bash_profile、/etc/profile或
/etc/security/limits.conf。
再次执行:
./core_dump_test
段错误 (core dumped)
ls core.*
core.6133
可以看到已经创建了一个core.6133的文件.6133是core_dump_test程序运行的进程ID。
调式core文件
core文件是个二进制文件,需要用相应的工具来分析程序崩溃时的内存映像。
file core.6133
core.6133: ELF 32-bit LSB core file Intel 80386, version 1 (SYSV),SVR4-style, from 'core_dump_test'
在Linux下可以用GDB来调试core文件。
gdb core_dump_test core.6133
GNU gdb Red Hat Linux(5.3post-0.20021129.18rh)
Copyright 2003 Free Software Foundation,Inc.
GDB is free software, covered by the GNU General Public License,and you are welcome to change it and/or distribute copies of it under certainconditions. Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type"show warranty" for details.
This GDB was configured as"i386-redhat-linux-gnu"...
Core was generated by `./core_dump_test'.
Program terminated with signal 11, Segmentationfault.
Reading symbols from/lib/tls/libc.so.6...done.
Loaded symbols for /lib/tls/libc.so.6
Reading symbols from/lib/ld-linux.so.2...done.
Loaded symbols for /lib/ld-linux.so.2
#0 0x080482fd in core_test () atcore_dump_test.c:7
7 str[1] = 'T';
(gdb) where
#0 0x080482fd in core_test () atcore_dump_test.c:7
#1 0x08048317 in main () atcore_dump_test.c:12
#2 0x42015574 in __libc_start_main () from/lib/tls/libc.so.6
GDB中键入where/backtrace/info stack,就会看到程序崩溃时堆栈信息(当前函数之前的所有已调用函数的列表(包括当前函数),gdb只显示最近几个),我们很容易找到我们的程序在最后崩溃的时候调用了core_dump_test.c第7行的代码,导致程序崩溃。
注意:在编译程序的时候要加入选项-g。
frame命令可以用来在不同的调用上下文中切换。
如下:
(gdb) where
#0 0x0000000000400e18 in threadhander (arg=0x0) at pool.c:54
#1 0x00000031184079d1 in pthread_create()
(gdb) frame 0
#0 0x0000000000400e18 in threadhander (arg=0x0) at pool.c:54
54 while (cur->run_flag != READY)
core文件创建在什么位置
在进程当前工作目录的下创建。
通常与程序在相同的路径下。
但如果程序中调用了chdir 函数,则有可能改变了当前工作目录。
这时core文件创建在chdir指定的路径下。
有好多程序崩溃了,我们却找不到core文件放在什么位置。
和chdir函数就有关系。
当然程序崩溃了不一定都产生core文件。
什么时候不产生core文件
在下列条件下不产生core文件:
( a )进程是设置-用户-ID,而且当前用户并非程序文件的所有者;
( b )进程是设置-组-ID,而且当前用户并非该程序文件的组所有者;
( c )用户没有写当前工作目录的许可权;
( d)文件太大。
core文件的许可权(假定该文件在此之前并不存在)通常是用户读/写,组读和其他读。
常用的gdb命令
backtrace 显示程序中的当前位置和表示如何到达当前位置的栈跟踪(同义词:where)
breakpoint 在程序中设置一个断点
cd 改变当前工作目录
clear 删除刚才停止处的断点
commands 命中断点时,列出将要执行的命令
continue 从断点开始继续执行
delete 删除一个断点或监测点;也可与其他命令一起使用
display 程序停止时显示变量和表达时
down 下移栈帧,使得另一个函数成为当前函数
frame 选择下一条continue命令的帧
info 显示与该程序有关的各种信息
jump 在源程序中的另一点开始运行
kill 异常终止在gdb 控制下运行的程序
list 列出相应于正在执行的程序的原文件内容
next 执行下一个源程序行,从而执行其整体中的一个函数
print 显示变量或表达式的值
pwd 显示当前工作目录
pype 显示一个数据结构(如一个结构或C++类)的内容
quit 退出gdb
reverse-search 在源文件中反向搜索正规表达式
run 执行该程序
search 在源文件中搜索正规表达式
set variable 给变量赋值
signal 将一个信号发送到正在运行的进程
step 执行下一个源程序行,必要时进入下一个函数
undisplay display命令的反命令,不要显示表达式
until 结束当前循环
up 上移栈帧,使另一函数成为当前函数
watch 在程序中设置一个监测点(即数据断点)
whatis 显示变量或函数类型
写于2015/5/12。