并行计算总复习之秘笈
- 格式:doc
- 大小:1.15 MB
- 文档页数:18

高性能计算(并行计算)复习提纲第一章并行计算机系统及其结构模型1.了解并行计算机系统互联网络及其分类不同带宽与距离的互连技术: 总线、SAN、LAN、MAN、WAN 1,静态互联网络:是指处理单元之间有着固定连接的一类网络,在程序执行期间,这种点到点的连接不变。
典型的静态网络有一维线性阵列、二维网孔、树连接、超立方网络、立方环、洗牌交换网、蝶形网络等。
2,动态互联网络:是用开关单元构成的,可按应用程序的要求动态的改变连接组态。
典型的动态网络包括总线、交叉开关和多级互连网络等,3,标准互联网络2.并行计算机系统结构,参见图1.20(P23)五种结构,要求理解这几种结构的硬件组成及工作方式。
2,并行计算机系统结构:行向量处理机pvp :硬件:向量处理机vp、共享存储器SM。
工作方式:高带宽的交叉开关网络将vp连向共享存储模块,存储器可以以兆字节每秒的速度想处理器提供数据。
通常使用向量寄存器和指令缓冲器。
对称多处理机SMP:硬件:商品微处理器(具有片上或外设高速缓存)、共享存储器、I/O设备。
工作方式:微处理器由总线或交叉开关连向共享存储器。
每个处理器可同等的访问共享存储器、I/O设备和操作系统服务。
MPP一般是指超大型计算机系统,它具有如下特性:①处理节点采用商品微处理器;②系统中有物理上的分布式存储器;③采用高通信带宽和低延迟的互连网络;④能扩放至成百上千乃至上万个处理器;⑤它是一种异步的MIMD机器,程序系由多个进程组成,每个都有其私有地址空间,进程间采用传递消息相互作用DSM分布式共享存储多处理机高速缓存目录DIR用以支持分布高速缓存的一致性。
DSM和SMP的主要差别是,DSM在物理上有分布在各节点中的局存从而形成了一个共享的存储器。
对用户而言,系统硬件和软件提供了一个单地址的编程空间.COW工作站机群机群往往是低成本的变形的MPP。
COW的重要界线和特征是:①每个节点都是一个完整的工作站(不包括监视器、键盘、鼠标等),一个节点也可以是一台PC或SMP;②各节点通过一种低成本的商品(标准)网络互连(;③各节点内总是有本地磁盘④节点内的网络接口是松散耦合到I/O 总线上的,⑤一个完整的操作系统驻留在每个节点中,而MPP中通常只是个微核,COW 的操作系统是工作站UNIX,加上一个附加的软件层以支持单一系统映像、并行度、通信和负载平衡等。

并行算法》课程总结与复习Ch1 并行算法基础1.1并行计算机体系结构并行计算机的分类SISD,SIMD,MISD,MIMD ; SIMD,PVP,SMP,MPP,COW,DSM 并行计算机的互连方式静态: LA(LC),MC,TC,MT,HC,BC,SE动态: Bus, Crossbar Switcher, MIN(Multistage InterconnectionNetworks)1.2并行计算模型PRAM 模型: SIMD-SM ,又分 CRCW(CPRAM,PPRAM,APRAM),CREW,EREWSIMD-IN 模型: SIMD-DM异步 APRAM 模型: MIMD-SMBSP模型:MIMD-DM,块内异步并行,块间显式同步LogP 模型: MIMD-DM ,点到点通讯1.3并行算法的一般概念并行算法的定义并行算法的表示并行算法的复杂度:运行时间、处理器数目、成本及成本最优、加速比、并行效率、工作量并行算法的 WT表示:Brent定理、WT最优加速比性能定律并行算法的同步和通讯Ch2 并行算法的基本设计技术基本设计技术平衡树方法:求最大值、计算前缀和倍增技术:表序问题、求森林的根分治策略: FFT 分治算法划分原理:均匀划分(PSRS排序)、对数划分(并行归并排序)、方根划分(Valiant归并排序)、功能划分((m,n)-选择)流水线技术:五点的 DFT 计算Ch3 比较器网络上的排序和选择算法3.1Batcher归并和排序0-1 原理的证明奇偶归并网络:计算流程和复杂性(比较器个数和延迟级数)双调归并网络:计算流程和复杂性(比较器个数和延迟级数)Batcher排序网络:原理、种类和复杂性3.2(m, n)-选择网络分组选择网络平衡分组选择网络及其改进Ch4 排序和选择的同步算法4.1一维线性阵列上的并行排序算法4.2二维Mesh上的并行排序算法ShearSort排序算法Thompson&Kung 双调排序算法及其计算示例4.3Sto ne双调排序算法4.4Akl并行k-选择算法:计算模型、算法实现细节和时间分析4.5Valia nt并行归并算法:计算模型、算法实现细节和时间分析4.7 Preparata并行枚举排序算法:计算模型和算法的复杂度Ch5 排序和选择的异步和分布式算法5.1MIMD-CREW 模型上的异步枚举排序算法5.2MIMD-TC 模型上的异步快排序算法5.3分布式k-选择算法Ch6 并行搜索6.1单处理器上的搜索6.2SIMD 共享存储模型上有序表的搜索:算法6.3SIMD 共享存储模型上随机序列的搜索:算法6.4树连接的 SIMD 模型上随机序列的搜索:算法6.5网孔连接的 SIMD 模型上随机序列的搜索:算法和计算示例Ch8 数据传输与选路8.1引言信包传输性能参数维序选路(X-Y选路、E-立方选路)选路模式及其传输时间公式8.2单一信包一到一传输SF和CT传输模式的传输时间(一维环、带环绕的Mesh、超立方)8.3一到多播送SF和CT传输模式的传输时间(一维环、带环绕的Mesh、超立方)及传输方法8.4多到多播送SF和CT传输模式的传输时间(一维环、带环绕的Mesh、超立方)及传输方法8.5贪心算法(书 8.2)二维阵列上的贪心算法蝶形网上的贪心算法8.6随机和确定的选路算法(书 8.3)Ch12 矩阵运算12.1矩阵的划分:带状划分和棋盘划分,有循环的带状划分和棋盘划分12.2矩阵转置:网孔和超立方连接的算法及其时间分析12.3矩阵向量乘法带状划分的算法及其时间分析棋盘划分的算法及其时间分析12.4矩阵乘法简单并行分块算法Cannon算法及其计算示例Fox 算法及其计算示例 DNS 算法及其计算示例 Systolic 算法Ch13 数值计算13.1稠密线性方程组求解 SIMD-CREW 的上三角方程组回代算法SIMD-CREW 上的 Gauss-Jordan算法MIMD-CREW 上的 Gauss-Seidel算法13.2稀疏线性方程组的求解三对角方程组的奇偶规约求解法Gauss-Seide迭代法的红黑着色并行算法13.3非线性方程的求根Ch14 快速傅立叶变换FFT14.1快速傅里叶变换 (FFT) 离散傅里叶变换 (DFT) 串行 FFT 递归算法及其计算原理串行 FFT 蝶式计算及其蝶式计算流图14.2DFT 直接并行算法SIMD-MT 上的并行 DFT 算法14.3并行 FFT 算法 SIMD-MC 上的 FFT 算法 SIMD-BF 上的 FFT 算法及其时间分析Ch15 图论算法15.1图的并行搜索P-深度优先搜索及其计算示例 p-宽深优先搜索及其计算示例 p-宽度优先搜索及其计算示例15.2图的传递闭包基于布尔矩阵乘积的算法原理计算示例SIMD-CC 上的传递闭包算法15.3图的连通分量基于传递闭包的算法基于顶点合并的算法15.4图的最短路径基于矩阵乘积的算法原理计算示例15.5图的最小生成树 SIMD-EREW 模型上的 Prim 算法算法的时间分析Ch17 组合搜索17.1基于分治法的与树搜索与树并行搜索过程处理器数目与搜索效率关系17.2基于分枝限界法的或树搜索串行分枝限界法示例: 0-1 背包问题,8- 谜问题及其搜索算法的并行化 TSP问题的分枝限界算法及其并行化Ch18 随机算法18.1引言基本知识:随机算法的定义、分类时间复杂性度量设计方法18.2低度顶点部分独立集串行算法随机并行算法及其正确性证明18.5多项式恒等的验证基本原理和方法矩阵乘积的验证原理。

复习要点1、Parallel computing并行计算,sequential computing串行计算,instruction指令,multiple多数据,communication通信,exclusive互斥,concurrent 并发,recursive递归,data数据,exploratory探索,speculative投机,block cyclic循环块,randomized block随机块,distribution分配,graph partitioning 图划分,speedup加速比,efficiency效率,cost费用,Amdahl’s law,architecture构架,fundimental functions基本函数,synchronization同步,matrix mulitiplication矩阵乘,matrix transposition 矩阵转置,bitonci sorting双调排序,odd-even sorting奇偶排序,Shortest path,minimum spanning tree,connected components,maximal independent set,2、SMP(对称多处理机连接)MPP (Massive Parallel Processors 大规模并行)Cluster of Workstation(工作站机群)Parallelism(并行化), pipelining(流水线技术), Network topology(网络拓扑结构), diameter of a network(网络直径), bisection width(对分宽度), data decomposition(数据分解), task dependency graphs(任务依赖图), granularity(粒度), concurrency(并发), process(进程), processor(处理器), linear array(线性阵列), mesh(格网), hypercube(超立方体), reduction(规约), prefix-sum(前缀和), gather(收集), scatter(散发), threads(线程), mutual exclusion(互斥), shared address space(共享地址空间), synchronization(同步), the degree of concurrency(并发度), Dual of a communication operation(通信操作的对偶操作)3、并行计算与串行计算在算法设计主要不同点:(1)具有强大的处理器互连关系(2)并行计算依赖并行计算模型上的,如共享内存,共享地址空间或消息传递。

并行计算:使用并行计算提高计算效率的技巧和方法并行计算是一种利用多个处理器或多个计算机同时执行多个计算任务的计算方法。
通过并行计算,我们可以将大规模的计算任务分解为多个小任务,并且在多个处理器或计算机上同时执行,以提高计算效率和加快计算速度。
在本文中,我们将介绍几种常见的并行计算技巧和方法来优化计算效率。
1.任务并行:任务并行是将一个大任务分解为多个小任务,并且同时在多个处理器或计算机上执行。
每个处理器或计算机负责执行一部分任务,然后将结果合并得到最终结果。
任务并行可以显著减少计算时间,尤其适用于大规模数据处理和复杂计算任务。
2.数据并行:数据并行是将大规模的数据分成多个小块,并且在多个处理器或计算机上同时对每个小块进行计算。
每个处理器或计算机负责处理一部分数据,并将计算结果合并得到最终结果。
数据并行可以加快计算速度,尤其适用于需要同时处理大量数据的任务,如图像处理和数据挖掘。
3.指令并行:指令并行是将一个计算任务分解为多个子任务,并且在多个处理器或计算机上同时执行。
每个处理器或计算机负责执行一部分指令,并将结果传递给下一个处理器或计算机继续执行。
指令并行可以提高计算效率,尤其适用于需要大量指令执行的任务,如矩阵运算和神经网络训练。
4.流水线并行:流水线并行是将一个计算任务分解为多个阶段,并且在多个处理器或计算机上同时执行不同的阶段。
每个处理器或计算机负责执行一个阶段,并将结果传递给下一个处理器或计算机继续执行下一个阶段。
流水线并行可以将计算任务分解为多个独立的部分,并在同时执行的情况下提高计算效率。
5.任务分解和调度:任务分解和调度是将一个大任务分解为多个小任务,并且将这些小任务分配给不同的处理器或计算机执行。
任务分解和调度可以根据任务的特性和处理器或计算机的性能自动选择最优的分解和调度策略,以提高计算效率和加快计算速度。
6.数据划分和通信:数据划分和通信是将大规模的数据划分为多个小块,并且在多个处理器或计算机之间进行数据交换和通信。

并行计算总复习题型:1.问答题;2.算法描述;3.走例子说明对算法的理解第二章SIMD 和MIMD 所代表的计算模型是什么?主要区别和各自的系统结构示意图。
SPMD的含义是什么?若按通讯方式对并行算法进行分类有几种分类方法,各自的特点是什么?在理想并行计算模型中(parallel random access machine(PRAM), EREW, CREW, 和CRCW表示的意思是什么?能画出多处理机系统中处理单元的基本互连结构图,Mash, hypercube, 网络,对静态网络的测度:直径,连通性,二分宽度(bisection width), cost.能说出一种解决多处理器系统中cache和内存数据一致性问题的方法。
能给出store-and-forward routing 和cut-through routing的思想通讯费用是如何计算的?延迟时间,t s, t h, t w对Mesh 的X-Y_routing和对Hypercube的E-Cube routing的路由规则。
如何把linear array, mesh 和hypercube 相互嵌入?G(i,d)函数的计算。
把复杂网络嵌入的简单网络,能说明些什么问题?其意义是什么?一般对简单网络的带宽是怎么要求的?第三章dependency graph 的定义及画法。
对同一问题dependency graph 的画法是否唯一?并行算法的粒度定义是什么?把processes 影射到processors的基本原则是什么?减少通讯,…,在并行算法设计时,有几种把计算分解的技术?能举例说明。
能说明data parallel model, task graph model 和work pool model 的含义。
第四章Basic communication operations能画出下列操作的示意图one to all broadcast; all to one reductionall to all broadcast; all to all reductionscatter, gather, all reduce, prefix sum,all to all personalized communication. Circular shift,能写出在hypercube上的one to all broadcast/ all to one reductionall-to-all personal broadcast;all-to-all broadcast;算法以及时间复杂性的分析。

高效处理大规模并行计算的方法与技巧随着计算机系统的发展和性能的提升,大规模并行计算已经成为解决复杂问题的重要手段之一。
在进行大规模并行计算时,有一些方法与技巧可以帮助我们提高计算效率,使得计算能够更加快速和高效地完成。
本文将介绍一些高效处理大规模并行计算的方法与技巧。
一、任务划分与调度在进行大规模并行计算时,首先需要将任务进行划分,并合理地分配给不同的计算单元进行并行处理。
任务的划分可以根据问题的性质和计算资源的特点来确定,一般可以采用任务划分、数据划分或是任务数据混合划分的方式。
任务划分和调度的优化目标是尽量减少通信和同步开销,提高计算效率。
1.均衡负载在任务划分时,需要尽可能地将计算负载均衡地分配给不同的计算节点,避免计算节点间存在明显的负载不均衡。
负载不均衡会导致某些计算节点的计算任务过重,导致性能下降。
均衡负载可以通过动态调整来实现,可以根据计算节点的工作状态和负载情况,动态地将任务进行重新分配和调度。
2.任务划分策略在进行任务划分时,需要考虑任务之间的依赖关系和数据的共享情况。
可以采用自顶向下或者自底向上的划分策略,将任务分解为更小的子任务,使得子任务之间的依赖关系更加简单和清晰。
同时,还可以根据任务之间的依赖关系和通信模式,采用分层划分或互换划分的方式,减少通信和同步的开销。
二、通信与同步优化在大规模并行计算中,通信和同步操作往往是影响计算性能的重要因素,因此需要通过一些优化技巧来减小通信和同步的开销。
1.减少通信量可以通过减少通信量来减小通信的开销。
可以采用聚集通信和分散通信的方式,将多个小消息合并成一个大消息进行发送,从而减少通信的次数和开销。
此外,还可以通过数据压缩、数据过滤等方法来减小通信数据的大小,提高通信效率。
2.异步通信在进行通信操作时,可以采用异步通信的方式进行。
异步通信可以使发送和接收操作重叠,从而提高计算和通信的效率。
异步通信可以通过非阻塞操作、回调函数等方式来实现。

并行计算:使用并行计算提高计算效率的技巧和方法并行计算是一种通过同时处理多个任务或部分任务来提高计算效率的方法。
在计算机科学领域中,随着数据量不断增大和计算需求不断增加,传统的串行计算方式已经无法满足要求。
因此,并行计算技术成为了一种重要的解决方案。
并行计算的主要优点包括:提高计算效率、减少计算时间、增加计算容量、降低成本等。
利用多核处理器、集群、云计算等技术,可以实现并行计算。
以下是一些提高并行计算效率的技巧和方法:1.任务分解:将大任务分解成多个子任务,然后同时执行这些子任务,提高整体计算效率。
在任务分解过程中,要考虑到任务之间的依赖关系和数据之间的传输延迟,避免出现资源竞争和数据不一致的情况。
2.负载均衡:合理分配任务给不同的处理单元,避免出现某一处理单元负载过重而导致整体性能下降的情况。
负载均衡可以通过动态调整任务分配策略来实现,根据任务的执行情况进行监控和调整。
3.数据传输优化:在并行计算过程中,数据传输往往是影响计算效率的关键因素之一。
通过减少数据传输量、优化数据传输路径、减少数据传输延迟等方法,可以提高计算效率。
4.并行编程模型:选择合适的并行编程模型对于提高计算效率至关重要。
常见的并行编程模型包括MPI、OpenMP、CUDA等,根据具体的应用场景和硬件平台选择合适的并行编程模型可以提高计算效率。
5.并行算法设计:设计并行算法时,需要考虑到并行计算的特点,合理利用并行计算资源,减少通信开销和数据冗余,提高算法并行度和并行效率。
6.硬件优化:在进行并行计算时,选择合适的硬件设备也非常重要。
优化硬件配置、选择性能强劲的处理器和内存、使用高速网络连接等方法可以提高并行计算效率。
7.并行计算框架:利用现有的并行计算框架如Hadoop、Spark等,可以简化并行计算的开发流程,提高开发效率,同时也能够提高计算效率。
8.任务调度策略:合理的任务调度策略能够有效地利用计算资源,避免资源浪费和资源竞争,提高整体计算效率。

并行计算总复习第一章:1并行计算与串行计算在算法和编程上有哪些显著差异?答:·并行算法设计与并行计算机处理器的拓扑连接相关·并行算法设计和采用的并行计算模型有关。
·并行计算有独自的通讯函数·并行算法设计时,如何将问题分解成独立的子问题是科学研究问题,并非所有的问题都可以进行分解。
2多核与多处理机的异同点?多处理机:把多个处理器通过网络互连形成一个新机器。
可以是专用,也可以是通用。
拓扑连接是可以改变的。
多核:在过去单个处理器芯片上实现多个“执行核”。
但这些执行核都有独立的执行命令集合和体系结构。
这些独立的执行核+超线程SMT技术组成多核处理器3对单处理器速度提高的主要限制是什么?答:晶体管的集成密度,功耗和CPU表面温度等第二章1 SIMD 和MIMD 所代表的计算模型是什么?主要区别和各自的系统结构示意图。
SPMD的含义是什么?SIMD指单指令多数据流模型;MIMD指多指令多数据流模型;SPMD指单程序多数据流模型,在SIMD中把指令改为程序表示每个处理器并行的执行程序。
SIMD MIMD硬件较少处理器较多处理器内存一个寻址系统,存储量小多个寻址系统,存储量大耗费较高,难开发易于开发(多个商业组件可用)加速高取决于应用2 若按通讯方式对并行算法进行分类有几种分类方法,各自的特点是什么?基于共享地址空间:并行平台支持一个公共的数据空间,所有处理器都可以访问这些空间。
处理器通过修改存储在共享地址空间的数据来实现交互。
基于消息传递:消息传递平台有p个处理节点构成,每个节点有自己的独立地址空间。
运行在不同节点上的进程之间的交互必须用消息来完成,称为消息传递。
这种消息交换用来传递数据、操作以及使多个进程间的行为同步。
3 在理想并行计算模型中(并行随机访问计算机parallel random access machine(PRAM), EREW, ERCW CREW, 和CRCW表示的意思是什么?EREW:互斥读互斥写,这一类的PRAM独占访问内存单元,不允许并发的读写操作。

《并行处理》总复习一、1.1、用向量语言VFORTRAN,把一维数组A(0:1000)的所有元素均置成PAI;A(0:1000)= PAI1.2、用向量语言VFORTRAN,把一维数组A(-1:1000)的第偶数号元素减少1;1.3、用向量语言VFORTRAN,把一维数组A(0:1000)的第奇数号元素置成其原值立方的正弦;A(1:1000:2)= sin( A(1:1000:2)**3)1.4、已知一维数组A(-1000:999)。
对于每个元素,倘若其正切值不超过立方值,则令原值减半;否则,令原值加倍。
用向量语言VFORTRAN的语句,描述之。
1.5、在下面的PFORTRAN 主程序段里,标记出并行语句和并行进程名,并指出可能的最大并行数目。
1 program matmul2 external init_matrix, mul_matrix, prt_matrix3 shared_distributed c : block4 parameter(SIZE=32768)5 integer a(SIZE,SIZE), b(SIZE,SIZE), c(SIZE,SIZE)6 call init_matrix(a,b)7 call m_set_procs(SIZE÷32)8 call mg_fork(mul_matrix(a,b))9 call m_kill_procs()10 call prt_matrix(a,b,c)11 end1.6、在分辨率为SIZE*SIZE(SIZE为2的幂)的黑白带灰度的显示屏幕上:左上角为坐标原点,X轴向下,Y轴向右;0为白,1为黑。
用NUMNODES(亦为2的幂,且<SIZE/4)个并行节点把现有的图象(位图表示)map[0:SIZE-1,0:SIZE-1]加以变换。
Map的初值:map[i][j]=(i+j)/(2*(SIZE-1))……0≦i,j<SIZE主进程:for (I=0,row=0;I<NUMNODES;I++,row+=SIZE/NUMNODES)send(row,Pi);for (I=0;I<SIZE**2;I++){ recv(oldrow,oldcol,newvalue,Pany);temp_map[oldrow][oldcol] = newvalue;}for (I=0;I<SIZE;I++)for (j=0;j<SIZE;j++)map[I][j]=temp_map[I][j];从进程:recv(row,Pmaster);for (oldrow=row;oldrow<(row+SIZE/NUMNODES);oldrow++)for (oldcol=0;oldcol<SIZE;oldcol++){newrow=oldrow÷4*4;newcol=oldcol÷4*4; /*÷是整除运算符*/newvalue=map[newrow][newcol];send (oldrow,oldcol,newvalue,Pmaster);}6.1、在卷面上标记出消息发送语句;6.2、在卷面上标记出消息接收语句,以及与之配对的消息发送语句。
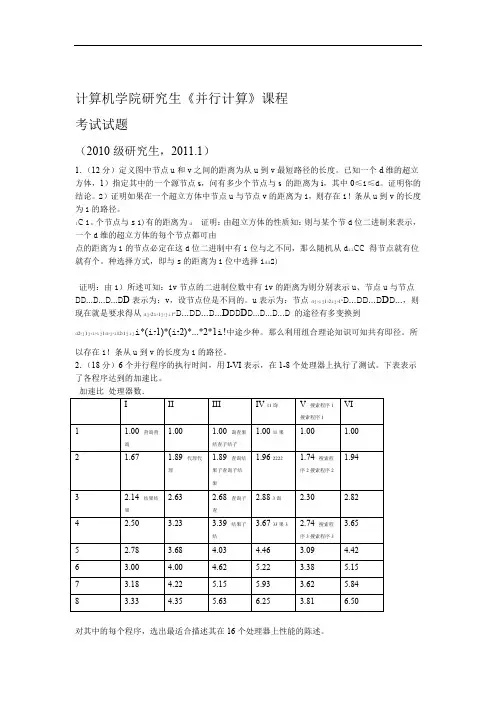
计算机学院研究生《并行计算》课程考试试题(2010级研究生,2011.1)1.(12分)定义图中节点u和v之间的距离为从u到v最短路径的长度。
已知一个d维的超立方体,1)指定其中的一个源节点s,问有多少个节点与s 的距离为i,其中0≤i≤d。
证明你的结论。
2)证明如果在一个超立方体中节点u与节点v的距离为i,则存在i!条从u到v的长度为i的路径。
i C i。
个节点与s 1)有的距离为d证明:由超立方体的性质知:则与某个节d位二进制来表示,一个d维的超立方体的每个节点都可由点的距离为i的节点必定在这d位二进制中有i位与之不同,那么随机从d ii CC得节点就有位就有个。
种选择方式,即与s的距离为i位中选择i dd2)证明:由1)所述可知:iv节点的二进制位数中有iv的距离为则分别表示u、节点u与节点DD...D...D...D D表示为:v,设节点位是不同的。
u表示为:节点dj?ij1?2ij?1''D...DD...D D D...,则现在就是要求得从dj?2i?1j?ji1''D...DD...D...D D D D D...D...D...D的途径有多变换到d2?j1j?i?ij1d?j?i12?1jij i*(i?1)*(i?2)*...*2*1i!中途少种。
那么利用组合理论知识可知共有即径。
所以存在i!条从u到v的长度为i的路径。
2.(18分)6个并行程序的执行时间,用I-VI表示,在1-8个处理器上执行了测试。
下表表示了各程序达到的加速比。
对其中的每个程序,选出最适合描述其在16个处理器上性能的陈述。
a)在16个处理器上的加速比至少比8个处理器上的加速比高出40%。
b)由于程序中的串行程序比例很大,在16个处理器上的加速比不会比8个处理器上的加速比高出40%。
c)由于处理器增加时开销也会很大,在16个处理器上的加速比不会比8个处理器上的加速比高出40%。

1 •并行算法:一些可同时执行的诸进程的集合,这些进程相互作用和相互协调。
2•并行与并发的关系:并行v并发并发是指两个或者多个事件在同一时间间隔内发生。
在单处理机系统中,每一时刻仅能有一道程序执行,宏观上多道程序在同时运行,微观上这些程序是分时交替执行。
3•并行与分布式的关系:网络;并行更注重性能,而分布式更注重透明共享。
4•并行与网格计算(普适计算)的关系:网格通过网络连接地理上分布的各类计算资源、存储资源、通信资源、软件资源、信息资源、知识资源等,形成对用户相对透明的虚拟的高性能计算环境,让人们透明地使用这些资源和功能。
它们•并行计算存在规模上的差显。
5•并行与云计算的关系:云计算以开放的标准和服务为基础,以互联网为中心,提供安全、快速、便捷的数据存储和网络计算服务,让互联网这片“云”上的各种计算机共同组成数个庞大的数据中心及计算屮心。
云计算把计算及存储以服务的形式提供给互联网用户,用户所使用的数据、服务器、应用软件、开发平台等资源都來自互联网上的虚拟化计算中心,该数据中心负责対分布在互联网上的各种资源进行分配、负载的均衡、软件的部署、安全的控制等。
6•为什么要研究并行算法?(1)CPU 的发展速度:Moore Law0(2)“深蓝”计算机以3.5:2.5战胜卡斯帕罗夫。
(3)需求:快速(天气预报),提高计算精度,与理论、实验并重的科学方法(代替核武器实验)7•并行计算机分类1.SISD,Single Instruction Stream & Single Data Stream:特征:串行的和确定的。
指令系统:CISC, RISC2.SIMD,Single Instruction Stream & Multiple Data Stream:特征:同步的;确定的;适合于指令/操作级并行。
1)阵列处理机(资源重复);2)流水线处理机(时间重叠).3・ MISD,Multiple Instruction Stream & Single Data Stream :4.MIMD,Multiple Instruction Stream & Multiple Data Stream共享存储MIMD,也称对称多处理机(SMP, Symmetry MultiProcessors),属于紧密耦合的多处理机系统适合于小粒度并行分布式共享存储MIMD,也称为非一致内存访问(NUMA, Non-Uniform Memory Access),属于松耦合的多处理机系统(共享虚拟存储技术),适合于屮小粒度并行分布式存储MIMD1).大规模并行系统MPP (Massively Parallel Processing)CM・5、曙光1000、神州・II巨型机可以最大限度地增加处理机的数量,但结点间需要依赖消息传递进行通信,适合于中小粒度并行2)・群集系统Cluster特点:适合于粗粒度并行8•网络直径(network diameter):网络中最远的两台处理机间的距离,即处理机间通信所需要跨越的网络边的条数的最人值。
1.并行计算(parallel computing)是指,在并行机上,将一个应用分解成多个子任务,分配给不同的处理器,各个处理器之间相互协同,并行地执行子任务,从而达到加速求解速度,或者求解应用问题规模的目的。
2.并行计算的基本条件:并行机、应用问题必须具有并行度、并行编程3.并行计算的主要研究目标:加速求解问题的速度、提高求解问题的规模4.并行计算的主要研究内容:并行机的高性能特征抽取、并行算法设计与分析、并行实现技术、并行应用5.推动并行计算发展的主要动力:大规模科学与工程计算应用对并行计算的需求、微电子技术与大规模集成电路VLSI 的发展、6.并行算法分类(a按运算基本对象的不用分为:数值并行算法、非数值并行算法。
B按并行进程间相互执行顺序关系的不同分为:同步并行算法、异步并行算法、独立并行算法。
C按各进程承担的计算任务粒度的不同分为:细粒度并行算法、中粒度并行算法、大粒度并行算法。
)7.并行算法的发展阶段:基于向量运算的并行算法设计阶段、基于多向量处理机的并行算法设计阶段、SIMD 类并行机上的并行算法设计阶段、MIMD 类并行机上的并行算法设计阶段、现代并行算法设计8.当前流行的并行编程环境:消息传递、共享存储和数据并行。
9.标准消息传递接口MPI将消息传递并行编程环境分解为两部分:构成该环境的所有消息传递函数的标准接口说明,它们是根据并行应用程序对消息传递功能的不同要求而制定的,不考虑该函数能否具体实现、各并行机厂商提供的对这些函数的具体实现。
10.MPI 系统就是指所有这些具有标准接口说明的消息传递函数所构成的函数库。
11.在标准串行程序设计语言(C、Fortran、C++)的基础上,再加入实现进程间通信的MPI 消息传递库函数,就构成了MPI 并行程序设计所依赖的并行编程环境。
标准消息传递接口MPI优点:具有很好的可移植性,被当前所有并行环境支持;具有很好的可扩展性,是目前高效率的大规模并行计算(数百个处理器)最可信赖的平台;比其他消息传递系统好用;有完备的异步通信功能;有精确的定义,从而为并行软件的发展提供了必要的条件。
并行计算复习主要知识点1.并行计算具体的计算方法?a)将被求解的问题分解为若干部分b)每个部分分别由不同的处理器同时进行计算(课件一、2)2.并行计算能力的衡量单位?3.高性能计算解决的问题?高性能计算机用来解决国民经济建设、社会发展进步、国防建设与国家安全等方面一系列的挑战性的计算问题(课件一、22)4.将程序并行化的目的?原因:a)应用问题的串行程序可以在单节点机上(如PC、服务器等)运行,但机器执行速度太慢,执行时间过长;b)应用问题除了对计算速度的要求外,其对内存的要求等,都无法用串行计算机完成。
(课件一、36)5.多处理机之间协同解决问题需要做到什么?处理机之间协同解决问题需要数据传输和同步(课件一、44)6.并行计算应用的主要形式?7.并行计算的战略地位?从战略高度上讲,它是一个国家综合国力的体现,是支撑国家实力持续发展的关键技术之一,在国家安全、高技术发展和国民经济建设中占有重要的地位。
正是因为如此,世界各发达国家非常重视高性能并行计算的发展。
(书本26)8.并行计算对计算机的要求是什么?9.当代科学与工程的研究方法?10.大型计算系统一般分为哪六类?11.MPI的绑定语言?FORTRAN、C/C++12.MPI最基本的函数有哪些?MPI_Init 初始化;MPI_Finalize 终止;MPI_Comm_size 确定进程个数;MPI_Comm_rank 确定被叫进程的标号;MPI_send 发送;MPI_Recv 接收13.教材P413页,15.2.3节。
14.教材P118页,4.1.1节。
15.教材P7页,1.2.1节。
16.教材P4页,1.1.1节。
17.教材P7页,1.2.2节。
18.教材P149页,5.1.4节。
计算机基础知识培训了解计算机系统中的并行计算技术计算机基础知识培训:了解计算机系统中的并行计算技术一、引言计算机系统中的并行计算技术是当前计算机发展的重要趋势之一。
通过并行计算,可以使计算机系统实现更高的性能和更强的计算能力。
本文将介绍计算机系统中的并行计算技术,包括并行计算的概念、分类、应用领域和优势等内容。
二、并行计算的概念1.1 定义并行计算是指在同一时间内,多个计算任务同时进行的一种计算方式。
它是通过同时处理多个任务,将计算负载分布到多个计算单元上,从而提高计算效率和性能。
1.2 分类根据计算任务的特点和并行计算方式的不同,可以将并行计算分为以下几种类型:1.2.1 任务并行:将一个大的计算任务划分为若干个小任务,分配给不同的计算单元并行处理。
1.2.2 数据并行:将大规模数据划分为多个小规模数据,分配给不同的计算单元并行处理。
1.2.3 算法并行:将一个算法分解为多个子算法,由不同的计算单元并行执行。
1.2.4 进程并行:将一个计算任务分解为多个子进程,在不同的计算机节点上并行执行。
三、并行计算的应用领域2.1 科学计算并行计算在科学计算领域有着广泛的应用。
例如,在气候模拟、地震波传播模拟等领域,需要进行大规模的计算和数据处理,利用并行计算可以加快计算速度,提高计算精度。
2.2 金融领域在金融领域,需要进行大规模的风险评估、交易分析等计算任务。
并行计算可以帮助金融机构提高交易速度和风险分析的准确性,提升业务处理能力。
2.3 生物信息学生物信息学是一个数据密集型的领域,需要处理大量的生物数据和进行模拟和分析。
利用并行计算技术,可以加速生物数据处理和分析的过程,为生物学研究提供更强大的计算支持。
四、并行计算的优势3.1 提高计算性能通过并行计算,可以将计算任务分配给多个计算单元并行执行,充分利用计算资源,提高系统的计算性能和效率。
3.2 增强系统扩展性并行计算使得系统可以通过增加计算节点的数量来扩展计算能力,从而满足处理大规模计算任务的需求。
掌握并行与分布式计算的编程技巧随着信息技术的不断发展和进步,计算机领域的并行与分布式计算技术变得越来越重要。
掌握并行与分布式计算的编程技巧对于提高程序性能和解决复杂问题至关重要。
本文将介绍并行与分布式计算的概念,以及一些常用的编程技巧。
一、并行与分布式计算并行计算是指将一个大问题分解成多个小问题,并行地处理这些小问题,最后将结果合并起来得到最终结果的计算方式。
分布式计算则是将大问题分解成多个子问题,由多个计算机或处理器同时处理这些子问题,最后将各个子问题的结果进行合并得到最终结果。
二、并行计算的编程技巧1.任务拆分与调度在并行计算中,首先需要将任务拆分成多个可并行执行的子任务。
任务拆分的策略可以根据问题的性质和计算资源的情况进行选择。
拆分后的任务需要进行调度,确保各个任务能够得到充分的执行时间,并且执行的顺序符合逻辑要求。
2.数据分割与同步并行计算中,数据的分割和同步也是非常重要的。
对于大规模数据的处理,可以将数据切分成多个子集,每个子集由一个并发任务处理。
对于需要同步操作的情况,可以使用同步机制,如互斥锁、信号量等,确保各个任务之间的数据一致性。
3.负载均衡在并行计算中,负载均衡是指将任务均匀地分配到多个处理单元上,使得各个处理单元的负载尽量均衡。
负载均衡可以通过动态调整任务的分配策略来实现,以避免某个处理单元过载或空闲。
三、分布式计算的编程技巧1.通信与消息传递在分布式计算中,不同的计算节点之间需要进行通信和消息传递。
常用的通信方式包括消息队列、消息中间件等。
在编程时,需要定义好消息的格式和传递协议,确保各个计算节点能够正确地接收和处理消息。
2.任务调度与协同处理分布式计算中,可以通过任务调度和协同处理来实现各个计算节点之间的协作。
任务调度需要根据节点的计算能力和负载情况对任务进行优化分配,以提高整体的计算性能。
协同处理则是指各个节点之间相互协作,共同完成复杂的计算任务。
3.容错与可靠性在分布式计算中,由于计算节点分布在不同的物理机上,可能会出现计算节点故障或通信故障的情况。
掌握编程技术中的并行计算方法在当今信息时代,计算机技术的发展日新月异。
并行计算作为一种重要的计算方法,已经成为了提高计算机性能的关键。
掌握并行计算方法,对于从事编程工作的人来说,是一项必备的技能。
一、并行计算的定义和意义并行计算是指在同一时间内,多个计算任务同时进行,以提高计算机的运算速度和效率。
与之相对的是串行计算,即一次只能执行一个任务。
并行计算的意义在于它能够加快计算速度,提高计算机的性能。
二、并行计算的基本原理并行计算的基本原理是将一个大问题分解成多个小问题,然后通过多个处理器同时处理这些小问题,最后将结果合并得到最终的解决方案。
这种分而治之的思想使得计算机能够同时处理多个任务,从而提高计算效率。
三、并行计算的分类并行计算可以分为两种类型:共享内存并行计算和分布式并行计算。
共享内存并行计算是指多个处理器共享同一块内存,它们之间可以直接读写内存中的数据。
这种方式适用于多线程编程,可以有效地提高程序的运行速度。
分布式并行计算是指多个处理器通过网络连接,彼此之间进行通信和协作。
每个处理器都有自己的独立内存,它们通过消息传递的方式进行通信。
这种方式适用于大规模的计算任务,可以将任务分配给不同的处理器进行并行计算。
四、并行计算的应用领域并行计算在各个领域都有广泛的应用。
在科学研究中,它可以用于模拟天气预报、分子动力学模拟等复杂计算。
在工程领域,它可以用于模拟飞行器的飞行、汽车的碰撞等。
在金融领域,它可以用于高频交易、风险管理等。
五、掌握并行计算的方法和技巧要掌握并行计算,首先需要了解并行计算的基本原理和分类。
其次,需要学习并行编程语言和工具,如OpenMP、MPI等。
此外,还需要了解并行算法和并行计算模型,如分治法、MapReduce等。
最重要的是,需要不断实践和积累经验,通过参与并行计算项目来提高自己的技能。
六、并行计算的挑战和未来发展虽然并行计算可以提高计算机的性能,但也面临着一些挑战。
首先是并行算法的设计和优化,需要考虑负载均衡、通信开销等问题。
考试题型:名词解释(5~6个),简答(4~5),画图(17分),并行算法(40分) 第一章 绪论1.什么是并行计算?并行计算(parallel computing )是指,在并行机上,将一个应用分解成多个子任务,分配给不同的处理器,各个处理器之间相互协同,并行地执行子任务,从而达到加速求解速度,或者求解应用问题。
基本条件:硬件(并行机)、并行算法设计、并行编程环境 主要目标: 提高求解速度,扩大问题规模 并行计算的三个基本条件:(1) 并行机。
并行机至少包含两台或两台以上处理机,这些处理机通过互连网络相互连接,相互通信。
(2) 应用问题必须具有并行度。
也就是说,应用可以分解为多个子任务,这些子任务可以并行地执行。
将一个应用分解为多个子任务的过程,称为并行算法的设计。
(3) 并行编程。
在并行机提供的并行编程环境上,具体实现并行算法、编制并行程序,并运行该程序,达到并行求解应用问题的目的。
并行计算的主要研究内容:(1) 并行机的高性能特征抽取。
(2) 并行算法设计与分析。
(3) 并行实现技术,主要包含并行程序设计和并行性能优化。
基于并行机提供的并行编程环境,例如消息传递平台MPI 或者共享存储平台OpenMP ,具体实现并行算法,研制求解应用问题的并行程序。
(4) 并行应用。
2.并行计算和分布式计算的区别,不同:并行计算不同于分布式计算(distributedcomputing )分布式计算主要是指,通过网络相互连接的两个以上的处理机相互协调,各自执行相互依赖的不同应用,从而达到协调资源访问,提高资源使用效率的目的。
但是,它无法达到并行计算所倡导的提高求解同一个应用的速度,或者提高求解同一个应用的问题规模的目的。
对于一些复杂应用系统,分布式计算和并行计算通常相互配合,既要通过分布式计算协调不同应用之间的关系,又要通过并行计算提高求解单个应用的能力。
3.各种结构画图,概念,特点,以及两两之间的差异:大型并行计算机(scalable-parallel Computer )可分为: a) 单指令多数据流机 SIMD b) 并行向量处理机 PVP c) 对称多处理机 SMP d) 大规模并行处理机 MPP e) 分布式共享存储DSM 多处理机 f)工作站机群 COW(1)DSM (Distributed Shared Memory )分布式共享存储大任务快速求解协同合作(2)MPP(Massively Parallel Processing)大规模并行处理结构每个结点相对独立,有一个或多个微处理器每个结点均有自己的操作系统各个结点自己独立的内存,避免内存访问瓶颈各个结点只能访问自己的内存模块扩展性较好(3)对称多处理机SMP:采用商用微处理器,通常有片上和片外Cache,基于总线连接,集中式共享存储,UMA结构。
并行计算总复习第一章:1并行计算与串行计算在算法和编程上有哪些显著差异?答:·并行算法设计与并行计算机处理器的拓扑连接相关·并行算法设计和采用的并行计算模型有关。
·并行计算有独自的通讯函数·并行算法设计时,如何将问题分解成独立的子问题是科学研究问题,并非所有的问题都可以进行分解。
2多核与多处理机的异同点?多处理机:把多个处理器通过网络互连形成一个新机器。
可以是专用,也可以是通用。
拓扑连接是可以改变的。
多核:在过去单个处理器芯片上实现多个“执行核”。
但这些执行核都有独立的执行命令集合和体系结构。
这些独立的执行核+超线程SMT技术组成多核处理器3对单处理器速度提高的主要限制是什么?答:晶体管的集成密度,功耗和CPU表面温度等第二章1 SIMD 和MIMD 所代表的计算模型是什么?主要区别和各自的系统结构示意图。
SPMD的含义是什么?SIMD指单指令多数据流模型;MIMD指多指令多数据流模型;SPMD指单程序多数据流模型,在SIMD中把指令改为程序表示每个处理器并行的执行程序。
SIMD MIMD硬件较少处理器较多处理器内存一个寻址系统,存储量小多个寻址系统,存储量大耗费较高,难开发易于开发(多个商业组件可用)加速高取决于应用2 若按通讯方式对并行算法进行分类有几种分类方法,各自的特点是什么?基于共享地址空间:并行平台支持一个公共的数据空间,所有处理器都可以访问这些空间。
处理器通过修改存储在共享地址空间的数据来实现交互。
基于消息传递:消息传递平台有p个处理节点构成,每个节点有自己的独立地址空间。
运行在不同节点上的进程之间的交互必须用消息来完成,称为消息传递。
这种消息交换用来传递数据、操作以及使多个进程间的行为同步。
3 在理想并行计算模型中(并行随机访问计算机parallel random access machine(PRAM), EREW, ERCW CREW, 和CRCW表示的意思是什么?EREW:互斥读互斥写,这一类的PRAM独占访问内存单元,不允许并发的读写操作。
最弱的PRAM模型,对内存访问提供最小的并发性。
CREW:并发读互斥写。
对内存单元允许多读,但对内存位置多写是串行的ERCW:互斥读并发写。
对内存单元允许多写,但多读是串行的。
CRCW:并发读并发写。
对内存单元允许多读多写。
最强大4 能画出多处理机系统中处理单元的基本互连结构图,Mesh, hypercube, 网络,注意对顶点编号的要求。
Mesh:二维网格中每个维有sqrt(p)个节点,p为处理器的数目。
hypercube:p为处理器数目,超立方体结构有logP维,每维上有两个节点一个前面加1实现,这样标号0110的节点和标号0101的节点相隔两个链路因为他们有两位不同,性质以此类推。
网络:设p个处理器processor(输入),p个存储区bank(输出);该网络有sqrt(p)级输入:i;输出:jj=2i,0<=i<=p/2-1;j=2i+1-p, p/2<=i<=p-1.数据选路时,假设从s(二进制表示)传送到t,从最高位起开始比较,相同的位走直通,不同的位走交叉。
5 知道对静态网络的常用测度:直径,连通性,二分宽度(bisection width), cost.直径:网络中两个处理节点之间的最长距离称为网络直径。
(越小越好)连通性:网络中任意两个节点间路径多重性的度量。
连通性的一个度量是把一个网络分成两个不连通的网络需要删除的最少弧数目。
(越大越好)二分宽度:把网络分成两个相等网络时必须删去的最小通信链路数目。
(越大越好)cost:网络中所需的通信链路的数量或线路数量。
6 能说出一种解决多处理器系统中cache和内存数据一致性问题的方法。
(侦听和基于目录)用无效协议维持一致性,并用基于目录的系统来实现一致性协议。
基于目录:为全局内存增加一个目录,维护一个bitmap,表示已缓存的处理器及相应的数据项状态。
三状态协议含有无效、脏以及共享三种状态。
工作原理:当一个处理器P1修改了共享数据,P1修改bitmap,state 为dirty,它自己可以继续修改。
当另一处理器P2需要读该数据,目录告诉它p1目前拥有该数据,并通知p1更新状态,并把数据送给P2.优点:减少数据无谓的移动和更新(把空间分的更细)缺点:连接复杂性高O(mp)7 能给出store-and-forward routing 和cut-through routing的思想。
通讯费用是如何计算的?延迟时间,t s, t h, t wstore-and-forward routing :在此过程中,消息穿过有多个链路的路径时,路径上的每个中间节点接受和存储完整的消息后,就把消息转发给下一个节点。
T = t s+(m t w+ t h )l ,t h 为消息头导致的开销。
l 为链路数。
m 为消息字长。
cut-through routing :在此过程中,消息被分成固定大小的单元,称为数据片。
首先从源节点向目的节点发送跟踪程序以建立两点间的连接。
连接完成后,数据片就一个接一个的发送。
中间节点无需等待所有消息到达就可以发送数据片。
当某一数据片被中间节点接收后,该数据片被传到下一节点。
与store-and-forward routing 不同,每个中间节点无需用缓冲区空间存储完整的信息。
因此,中间节点只需要使用更少的内存和带宽,速度也快得多。
T = t s + m t w + t h*l ,t h 为消息头导致的开销。
l 为链路数。
m 为消息字长。
Tcomm= ts+lth+mtw ;1)startuptime (Ts): 在数据包上加上必要的头、尾信息,错误检测矫正信息、执行路由算法时间以及建立节点与路由器之间的接口。
2)per-hop time (Th): node latency from u to v;3 )per-word-transfer time(Tw)(每个字的传输时间),如果通道带宽为r 个字符每秒,每个字符的传输时间为Tw=1/r8 对Mesh 的X-Y_routing 和对Hypercube 的E-Cube routing 的路由规则。
Mesh 的X-Y_routing :消息首先沿X 为出发,直到到达目标节点的列,再沿Y 维到达目的节点。
其路径长度为L = |Sx-Dx|+|Sy-Dy|;Sx ,Sy 为源节点坐标;Dx ,Dy 为目标节点坐标。
Hypercube 的E-Cube routing :考虑节点数为p 的d 维超立方体。
令Ps 和Pd 分别为源节点和目标节点的编号。
在E-Cube 算法中,节点Ps 计算Ps (+) Pd 的值并沿k 维发送消息,其中k 是Ps (+) Pd 中的最低非零有效位的位置。
每个中间节点Ps 收到信息,计算出Ps (+) Pd ,再将消息沿着与最低非零有效位对应的维转发,直到消息到达目标节点。
9 如何把linear array, mesh 和hypercube 相互嵌入?G(i,d)函数的计算。
·linear array 嵌入到hypercube :含2d 个节点的linear array 可以嵌入到d 维超立方体中,只需把linear array 中的节点i 映射到hypercube 的节点G (i,x )上。
函数G (i ,x )定义如下: G (0,1)=0; G (1,1)=1;G (i ,x+1)= G (i ,x ) i<2x G (i ,x+1)=2x +G(21+x -1-i,x) i ≥2x(已知d 位葛莱码,对原项加前缀0,反映项加前缀1,可得到d+1位葛莱码)·mesh 嵌入到hypercube :将s r 22⨯mesh 嵌入到到s r +2个节点的hypercube 中,只须将mesh 上的节点(i,j )映射到hypercube 的节点G(i,r-1)||G(j,s-1)上,即node(i,j) —>G(i,r-1)||G(j,s-1)·mesh 嵌入到linear array10把复杂网络嵌入的简单网络,能说明些什么问题?其意义是什么?一般对简单网络的带宽是怎么要求的?意义:高维上的网络一般布线复杂,有线的交叉和长短不一等问题。
而加宽通讯带宽后的低维互连网络,可以取代高维复杂网络。
如果带宽增加到可以抵消互连拥塞,就可按稠密网络一样运行。
第三章11 dependency graph 的定义及画法。
对同一问题dependency graph 的画法是否唯一?dependency graph表示任务间的依赖关系和任务的执行次序关系。
是一种有向无环图,节点表示任务,边表示节点间的依赖性。
边<u,v>表示u任务执行完后v任务才能执行。
.不唯一13 并行算法的粒度定义是什么?粒度大小在理论上和在实际上对并行算法的影响。
分解问题得到的任务数量和大小决定了分解的粒度,将任务分解成大量的细小任务称为细粒度,而将任务分解成少量的大任务称为粗粒度。
14在进程调度中,把processes 影射到processors的基本原则是什么?减少通讯,…,1)设法将相互独立的任务映射到不同的进程中以获得最大并发度;2)确保关键路径上的任务一旦可执行就去执行它们,以使得总计算时间最短3)映射相互交互的任务到同一进程以便最小化进程间的交互。
15在并行算法设计时,有几种把计算分解的技术?能给出名称并能举例说明。
·Recursive decomposition (递归分解):可能产生太多任务使程序变慢or 快速排序·Data decomposition : based on the independency of data(基于数据独立性分解):根据对输出数据的划分来划分任务。
例如:矩阵相乘·Exploration decomposition(探索分解):对应于人工智能中基于解空间探索方法的问题求解,例如迷宫游戏·Speculative decomposition (投机分解):用于分支语句中,在未能决定分支转向时,并行的计算多个分支,当最终决定转向时,正确的分支对应的计算将被利用,其他的被丢弃。
·混合分解,将前面的分解方法组合应用,在计算的不同阶段使用不同的分解方法。
例如,快速排序,先数据分解然后再使用递归分解16为了解决由于数据分布密度不均匀问题,能说出3种以上可以帮助使并行任务的负载接近平衡的方法或思路。
循环块分配、随机块分配、图划分17 能说明data parallel model, task graph model 和work pool model 的含义。