流水线乘法器
- 格式:doc
- 大小:50.00 KB
- 文档页数:2

实验报告学生姓名:学号:一、实验室名称:计算机学院计算中心二、实验项目名称:加法乘法动态多功能流水线调度三、实验原理:把加法和乘法流水线分开,完成乘法流水线后再进行加法流水线。
把一个乘法任务分成三个部分,然后同时执行多个任务以模拟指令的流水线调度。
三个步骤每同时完成一次任务执行总时间就加一,直到最后一个操作数进入流水线,此时加法流水线开始工作。
把一个加法任务分成四个部分,然后同时执行多个任务以模拟指令的流水线调度。
四个步骤每同时完成一次任务执行总时间就加一,直到没有任务时停止,看此时的时间与理论上的流水线调度时间的差距来判别程序是否成功模拟了流水线指令的调度。
四、实验目的:1、掌握加法乘法动态双功能指令调度的方式,2、理解静态多功能流水线和动态多功能流水线在调度模式上的区别,3、了解指令并行度上限的概念。
五、实验内容:(一)给定要执行的任务和执行该任务的流水线结构流水线的调度方式能够提高任务的并行度,但是针对不同的任务,由于相关的存在,其并行度的提高是不一致的。
在开始程序设计前,我们首先要给定所要完成的任务:这里我们使用矩阵点积运算任务,∑=n1i aibi 。
n 的数值可以变化,通过变换n 的值用同一程序进行多次模拟。
给定流水线:流水线分五个步骤,每个步骤的执行时间均为一个单位时间;其中1-2-3-5组成加法流水线,1-4-5组成乘法流水线。
加法和乘法可以同时执行 (二)对任务进行分解动态多功能流水线不同于静态多功能流水线,流水线中同时只能有多种种操作的指令,因此不能将其划分为两个相互独立的加法流水线和乘法流水线。
我们考虑设计一个加法乘法混合运算器,加法4步,乘法三步,在送入源数据时应指明执行哪种运算。
(三)任务分解程序模拟的思路在实验二的基础上。
我们对设计进行变更。
加法乘法有一个类实现,称之为加乘法类。
乘法的数据源为两个队列,加法的数据源为一个队列。
加法器的源数据队列初始为空,乘法器的源数据队列初始分别放入A1-An 和B1-Bn 。


基于FPGA的流水线单精度浮点数乘法器设计彭章国;张征宇;王学渊;赖瀚轩;茆骥【摘要】针对现有的采用Booth算法与华莱士(Wallace)树结构设计的浮点乘法器运算速度慢、布局布线复杂等问题,设计了基于FPGA的流水线精度浮点数乘法器.该乘法器采用规则的Vedic算法结构,解决了布局布线复杂的问题;使用超前进位加法器(Carry Look-ahead Adder,CLA)将部分积并行相加,以减少路径延迟;并通过优化的4级流水线结构处理,在Xilinx(R)ISE 14.7软件开发平台上通过了编译、综合及仿真验证.结果证明,在相同的硬件条件下,本文所设计的浮点乘法器与基4-Booth算法浮点乘法器消耗时钟数的比值约为两者消耗硬件资源比值的1.56倍.【期刊名称】《微型机与应用》【年(卷),期】2017(036)004【总页数】5页(P74-77,83)【关键词】浮点乘法器;超前进位加法器;华莱士树;流水线结构;Vedic算法;Booth 算法【作者】彭章国;张征宇;王学渊;赖瀚轩;茆骥【作者单位】西南科技大学信息工程学院,四川绵阳621010;西南科技大学信息工程学院,四川绵阳621010;中国空气动力研究与发展中心,四川绵阳621000;西南科技大学信息工程学院,四川绵阳621010;西南科技大学信息工程学院,四川绵阳621010;西南科技大学信息工程学院,四川绵阳621010【正文语种】中文【中图分类】TP331.2浮点乘法器(eFloating Point Multiplier,FPM)是数字信号处理(eDigital Signal Processing,DSP)、视频图像处理以及信号识别等应用邻域重要的运算单元。
尤其是在视频图像处理领域,随着对高速海量图像数据处理的实时性要求逐渐提高,设计一种具有更高速率、低功耗、布局规律、占用面积小和集成度高的浮点乘法器极其重要。
阵列乘法器是采用移位与求和的算法而设计的一种乘法器[1]。





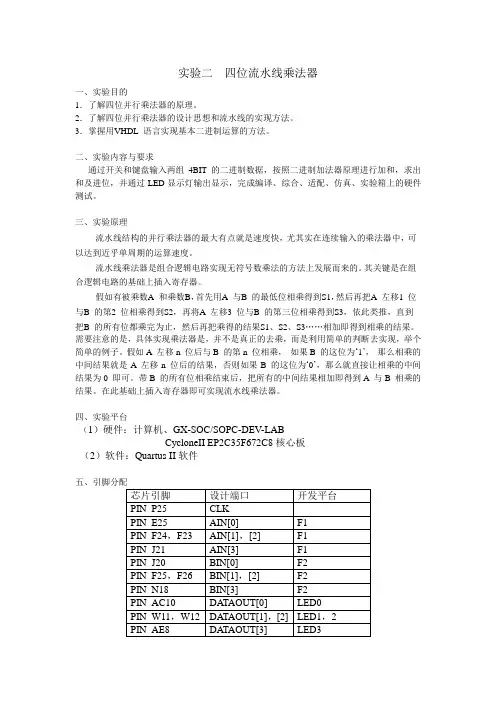
实验二四位流水线乘法器一、实验目的1.了解四位并行乘法器的原理。
2.了解四位并行乘法器的设计思想和流水线的实现方法。
3.掌握用VHDL 语言实现基本二进制运算的方法。
二、实验内容与要求通过开关和键盘输入两组4BIT的二进制数据,按照二进制加法器原理进行加和,求出和及进位,并通过LED显示灯输出显示,完成编译、综合、适配、仿真、实验箱上的硬件测试。
三、实验原理流水线结构的并行乘法器的最大有点就是速度快,尤其实在连续输入的乘法器中,可以达到近乎单周期的运算速度。
流水线乘法器是组合逻辑电路实现无符号数乘法的方法上发展而来的。
其关键是在组合逻辑电路的基础上插入寄存器。
假如有被乘数A 和乘数B,首先用A 与B 的最低位相乘得到S1,然后再把A 左移1 位与B 的第2 位相乘得到S2,再将A 左移3 位与B 的第三位相乘得到S3,依此类推,直到把B 的所有位都乘完为止,然后再把乘得的结果S1、S2、S3……相加即得到相乘的结果。
需要注意的是,具体实现乘法器是,并不是真正的去乘,而是利用简单的判断去实现,举个简单的例子。
假如A 左移n 位后与B 的第n 位相乘,如果B 的这位为‘1’,那么相乘的中间结果就是A 左移n 位后的结果,否则如果B 的这位为‘0’,那么就直接让相乘的中间结果为0 即可。
带B 的所有位相乘结束后,把所有的中间结果相加即得到A 与B 相乘的结果。
在此基础上插入寄存器即可实现流水线乘法器。
四、实验平台(1)硬件:计算机、GX-SOC/SOPC-DEV-LABCycloneII EP2C35F672C8核心板(2)软件:Quartus II软件PIN_AF8 DATAOUT[4] LED4PIN_AE7 DATAOUT[5] LED5PIN_AF7 DATAOUT[6] LED6PIN_AA11 DATAOUT[7] LED7PIN_AE21 BCD[0] 数码管DP4BPIN_AB20 BCD[1]PIN_AC20 BCD[2]PIN_AF20 BCD[3]PIN_AE20 BCD[4] 数码管DP5BPIN_AD19 BCD[5]PIN_AC19 BCD[6]PIN_AA17 BCD[7]PIN_AA18 BCD[8] 数码管DP6BPIN_W17 BCD[9]PIN_V17 BCD[10]PIN_AB18 BCD[11]六、仿真截图七、硬件实现八、程序代码1---clkgen.vhdlibrary IEEE;-- 1HZuse IEEE.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity clkgen isport (CLK : in std_logic;CLK1HZ: out std_logic);end entity;architecture clk_arch of clkgen issignal COUNT : integer range 0 to 50000000; --50MHZ -->1hz begin -- 50M/1=50000000 PROCESS(CLK)BEGINif clk'event and clk='1' thenIF COUNT= 50000000 thenCOUNT<=0;ELSE COUNT<=COUNT+1;END IF;END IF;END PROCESS;PROCESS(COUNT)BEGINIF COUNT= 5000000 THEN -- 1HZCLK1HZ<='1';ELSE CLK1HZ<='0';END IF;END PROCESS;end architecture;2—BCD-- 输出控制模块,把乘法器的输出转换成BCD码在数码管上显示、-- SCKZ.VHDlibrary IEEE;use IEEE.STD_LOGIC_1164.ALL;use IEEE.STD_LOGIC_ARITH.ALL;use IEEE.STD_LOGIC_UNSIGNED.ALL;entity BIN2BCD isport ( DIN: in std_logic_vector(7 downto 0); ---The input 8bit binaryBCDOUT: out std_logic_vector(11 downto 0)--输出显示, 已转换成BCD码);end entity;architecture arch of BIN2BCD issignal data2,data3,data4 :std_logic_vector(9 downto 0);-- 输出数据缓存signal hundred,ten,unit:std_logic_vector(3 downto 0);--signal bcdbuffer:std_logic_vector(11 downto 0);---2'1111_1001_11=999beginBCDOUT<= bcdbuffer;bcdbuffer(11 downto 8)<=hundred;bcdbuffer(7 downto 4)<=ten;bcdbuffer(3 downto 0)<=unit;get_hundred_value:process(data2)beginDA TA2<="00"&DIN;---get hundred valueif data2>=900 thenhundred<="1001";--9data3<=data2-900;elsif data2>=800 thenhundred<="1000";--8data3<=data2-500;elsif data2>=700 thenhundred<="0111";--7data3<=data2-700;elsif data2>=600 thenhundred<="0110";--6data3<=data2-600;elsif data2>=500 thenhundred<="0101";--5data3<=data2-500;elsif data2>=400 thenhundred<="0100";--4data3<=data2-400;elsif data2>=300 thenhundred<="0011";--3data3<=data2-300;elsif data2>=200 thenhundred<="0010";--2data3<=data2-200;elsif data2>=100 thenhundred<="0001";--1data3<=data2-100;else data3<=data2;hundred<="0000";end if;end process; ---get_thousand_valueget_tens_value:process(data3) begin---get tens placeif data3>=90 thenten<="1001";--9data4<=data3-90;elsif data3>=80 thenten<="1000";--8data4<=data3-50;elsif data3>=70 thenten<="0111";--7data4<=data3-70;elsif data3>=60 thenten<="0110";--6data4<=data3-60;elsif data3>=50 thenten<="0101";--5data4<=data3-50;elsif data3>=40 thenten<="0100";--4data4<=data3-40;elsif data3>=30 thenten<="0011";--3data4<=data3-30;elsif data3>=20 thenten<="0010";--2data4<=data3-20;elsif data3>=10 thenten<="0001";--1data4<=data3-10;else data4<=data3;ten<="0000";end if;end process; ---get_ten_valueget_unit_value:process(data4)begin--unit's orderif (data4>0) thenunit<=data4(3 downto 0);else unit<="0000";end if;end process;end arch;3 multi4b --------------------------------------------------------------------------------/ -- DESCRIPTION : Signed mulitplier:-- AIN (A) input width : 4-- BIN (B) input width : 4-- Q (data_out) output width : 8-- 并行流水乘法器--------------------------------------------------------------------------------/--10 × 9 = 90-- 1 0 1 0-- 1 0 0 1 =-- --------------- 1 0 1 0-- 0 0 0 0 --partial products-- 0 0 0 0-- 1 0 1 0-- -------------------- 1 0 1 1 0 1 0--parallel : process all the inputs at the same time--pipeline : use several stages with registers to implement it----关键思想,插入寄存器library IEEE;use IEEE.STD_LOGIC_1164.ALL;use IEEE.STD_LOGIC_ARITH.ALL;use IEEE.STD_LOGIC_UNSIGNED.ALL;entity multi4b isport ( CLK: in STD_LOGIC; ---system clockAIN: in STD_LOGIC_VECTOR (3 downto 0); ---one inputBIN: in STD_LOGIC_VECTOR (3 downto 0);-- the other inputdata_out: out STD_LOGIC_VECTOR (7 downto 0)---the result ---make sure the biggest value ,i,e. 1111x1111=1110_0001 can be held in the register );end multi4b;architecture multi_arch of multi4b issignal A,B :std_logic_vector(3 downto 0); --input register---registers to hold the result of the first processing---registers added to make use of pipeline, the 1st stagesignal A_MULT_B0: STD_LOGIC_VECTOR (3 downto 0);signal A_MULT_B1: STD_LOGIC_VECTOR (3 downto 0);signal A_MULT_B2: STD_LOGIC_VECTOR (3 downto 0);signal A_MULT_B3: STD_LOGIC_VECTOR (3 downto 0);---register to hold the result of the multipliersignal C_TEMP : STD_LOGIC_VECTOR (7 downto 0);beginPROCESS(CLK,AIN,BIN)beginif CLK'EVENT AND CLK='1' THEN-- multiplier operand inputs are registeredA<= AIN;B<= BIN;-----------------Fist stage of the multiplier------------------here we get the axb(0),axb(1),axb(2),axb(3),i.e.partial products---put them into the responding registersA_MULT_B0(0) <= A (0) and B (0);----- multi 1 , get the a(0) and b(0), & put it into the register A_MULT_B0(0)A_MULT_B0(1) <= A (1) and B (0);A_MULT_B0(2) <= A (2) and B (0);A_MULT_B0(3) <= A (3) and B (0);--10 × 9 = 90-- 1 0 1 0-- 1 0 0 1 =-- --------------- 0 0 0 0 1 0 1 0-- 0 0 0 0 0 0 0 0 --partial products-- 0 0 0 0-- 1 0 1 0-- -------------------- 1 0 1 1 0 1 0A_MULT_B1(0) <= A (0) and B (1);A_MULT_B1(1) <= A (1) and B (1);A_MULT_B1(2) <= A (2) and B (1);A_MULT_B1(3) <= A (3) and B (1);A_MULT_B2(0) <= A (0) and B (2);A_MULT_B2(1) <= A (1) and B (2);A_MULT_B2(2) <= A (2) and B (2);A_MULT_B2(3) <= A (3) and B (2);A_MULT_B3(0) <= A (0) and B (3);A_MULT_B3(1) <= A (1) and B (3);A_MULT_B3(2) <= A (2) and B (3);A_MULT_B3(3) <= A (3) and B (3);end if;end process;--------------------Second stage of the multiplier---------------add the all the partial products ,then get the result of the multiplier C_TEMP<=( "0000" & A_MULT_B0 )+( "000"& A_MULT_B1 &'0' )+( "00" & A_MULT_B2 & "00" )+( '0'&A_MULT_B3 & "000" );--build a signal register output---输出寄存,利于实现流水data_out <= C_TEMP; --output registerend multi_arch;九、实验总结。

fpga中做乘法
(实用版)
目录
1.FPGA 简介
2.FPGA 中实现乘法的方法
3.乘法器的设计与实现
4.FPGA 中乘法的优势与应用
正文
【FPGA 简介】
FPGA(现场可编程门阵列)是一种集成电路,用户可以编程其功能和逻辑。
FPGA 具有灵活性高、速度快、资源可重配置等特点,广泛应用于数字信号处理、通信、图像处理等领域。
【FPGA 中实现乘法的方法】
在 FPGA 中实现乘法有多种方法,常见的有:级联乘法器、流水线乘法器、二维阵列乘法器等。
【乘法器的设计与实现】
1.级联乘法器:将多个 1 位乘法器级联起来,实现多位数的乘法运算。
2.流水线乘法器:通过将乘法过程分为多个阶段,利用流水线技术实现高速乘法。
3.二维阵列乘法器:利用二维阵列结构,实现高效的大规模乘法运算。
【FPGA 中乘法的优势与应用】
1.并行处理:FPGA 可以同时执行多个乘法操作,大大提高运算速度。
2.灵活性高:FPGA 可以根据需求调整乘法器的规模和数量,满足不同应用场景的需求。
3.资源可重配置:FPGA 中的乘法器可以与其他逻辑功能共享资源,提高资源利用率。

乘法器vhdl课程设计一、课程目标知识目标:1. 理解乘法器的原理及其在数字信号处理中的应用。
2. 掌握VHDL语言的基本语法和结构,能够使用VHDL进行简单的程序编写。
3. 学习并掌握利用VHDL设计乘法器的方法,理解其位运算和结构设计。
技能目标:1. 能够运用所学知识,独立设计并实现一个简单的乘法器VHDL程序。
2. 培养学生利用电子设计自动化(EDA)工具进行代码编写、仿真和测试的能力。
3. 提高学生的问题分析能力,学会使用VHDL解决实际的数字电路设计问题。
情感态度价值观目标:1. 培养学生对于电子信息和数字电路设计的兴趣,激发学生创新精神和探索欲望。
2. 增强团队合作意识,通过小组讨论和协作,提高学生之间的沟通能力和协作解决问题的能力。
3. 强化学生的工程伦理观念,了解所学技术在国家经济发展和国防建设中的重要性,树立正确的价值观。
本课程针对高年级电子信息工程及相关专业学生设计,结合学生已具备的基础知识和课程性质,以实践性和应用性为导向,旨在通过具体的乘法器VHDL课程设计,将理论知识与实践技能相结合,提升学生解决实际工程问题的能力。
通过本课程的学习,学生应能够展示出上述具体的学习成果。
二、教学内容1. 乘法器原理回顾:包括乘法器的基本工作原理,不同类型的乘法器结构对比,以及乘法器在数字信号处理中的应用。
- 相关教材章节:第三章“数字电路基础”,第5节“算术逻辑单元”。
2. VHDL语言基础:VHDL的基本语法,数据类型,信号与变量,运算符,顺序与并行语句,进程,实体和架构等。
- 相关教材章节:第五章“硬件描述语言VHDL”,第1-3节。
3. 乘法器的VHDL设计方法:- 位运算乘法器设计原理与实现。
- 流水线乘法器设计原理与实现。
- 相关教材章节:第五章“硬件描述语言VHDL”,第4节“VHDL设计实例”;第六章“数字信号处理器的硬件实现”,第2节“乘法器的硬件实现”。
4. EDA工具的应用:利用EDA工具进行VHDL代码的编写、编译、仿真和测试。
实验五LPM乘法器模块设置调用一、实验目的熟悉LPM模块,并学会调用流水线乘法器LPM模块。
二、实验原理8位乘法器MULT8是通过宏模块输入方式直接从元器库中调用,修改相应的参数,包括四个端口:clock是一个时钟端口,作用是接收给定的特定时序脉冲,当来一个上升沿脉冲时,将接收到的数据进行相应逻辑运算;dataa、datab是两个8位标准逻辑位的输入端口,接收来自两个8位锁存器FF0的数据;result[15..0]是一个16位标准逻辑位的数据输出端。
三、实验仪器配套计算机及Quartus II 软件四、实验步骤与内容1.LPM_COUNTER计数器模块的调用(1)首先打开一个原理编辑窗,存盘取名为MULT8B, 然后将它创建成工程。
再次进入本工程的原理图后,单击左下的打开宏功能快调用管理器 MegaWizard Plug-In Mannager管理器按钮。
图1 从原理图编辑窗进入MegaWizard Plug-In Mannager管理器(2)单击Next->Arithmetic—>LPM-MULT并命名为MULT8B到下图图2 LPM宏观能块设定(3)单击next 并选择相应的东西得到如下图3图3(4)单击next 并选择相应的东西得到如下图4图4 选择有符号乘法模式,并用专用乘法器模块构建乘法器(5)单击next 并选择相应的东西得到如下图5图5 选择二级流水线乘法模式(6)单击next 并选择相应的东西得到如下图6图6(7)单击next 并选择相应的东西得到如下图7图7(8)点击finsih->project MULT8B得到MULT8B symbol如下图8图8 MULT8B symbol图(9) 综合运行,检查设计是否正确。
图9 全程编译无错后的报告信息(10) 建立波形编辑文件进行功能仿真,仿真结果如下图所示。
图10 MULT8B的仿真波形(11)查看RTL电路。
天津城建大学
课程设计任务书
2012 —2013 学年第1 学期
电子与信息工程系电子信息工程专业
课程设计名称:EDA技术及应用
设计题目:流水线乘法器设计
完成期限:自2013 年1月31 日至2013 年 1 月 4 日共 1 周
一.课程设计依据
在掌握常用数字电路原理和技术的基础上,利用EDA技术和硬件描述语言,EDA开发软件(QuartusⅡ)和硬件开发平台(达盛试验箱CycloneⅡFPGA)进行初步数字系统设计。
二.课程设计内容
采用时序电路,流水线结构,加法树式算法设计实现16位输入数据的乘法,并显示结果。
提示:字节间分块,1字节内8×8为加法数。
扩展部分:每个输入数据宽度为8bit,一个16bit数据分两次输入。
三.课程设计要求
1. 要求独立完成设计任务。
2. 课程设计说明书封面格式要求见《天津城建大学课程设计教学工作规范》附表1
3. 课程设计的说明书要求简洁、通顺,计算正确,图纸表达内容完整、清楚、规范。
4. 测试要求:根据题目的特点,采用相应的时序仿真或者在实验系统上观察结果。
5. 课设说明书要求:
1) 说明题目的设计原理和思路、采用方法及设计流程。
2) 对各子模块的功能以及各子模块之间的关系作明确的描述。
3) 对实验和调试过程,仿真结果和时序图进行说明和分析。
4) 包含系统框图、电路原理图、HDL设计程序、仿真测试图。
指导教师(签字):
教研室主任(签字):
批准日期:2012 年12 月22 日。
一种高速近似乘法器设计吴德祥; 班恬【期刊名称】《《计算机工程》》【年(卷),期】2019(045)012【总页数】5页(P289-293)【关键词】近似计算; 容错; 乘法器; 流水线; 图像处理【作者】吴德祥; 班恬【作者单位】南京理工大学电子工程与光电技术学院南京210094【正文语种】中文【中图分类】TP3090 概述由于人类感官的固有局限性,如对图像、声音的细微变化不敏感,因此诸如图像变换、音频处理等许多应用就可以采用近似计算[1],而无需得到精确的计算结果。
近似计算的关键思想是通过牺牲少量的精度来换取性能的大幅提升。
在许多应用中存在乘法运算,采用近似乘法器可以提升处理速度,减少资源消耗。
本文在研究现有近似乘法器的基础上,设计一种新的高速近似乘法器,并将其应用到图像处理中。
1 相关工作乘法器对于给定2个n位的操作数进行乘法操作,其主要步骤为:1)将操作数按位相与,产生一系列n位部分乘积项(Partial Product,PP)[2]。
2)通过一些特定方式如全加、4-2压缩[2]进行累加,将n位PP压缩为2行。
3)对最后2行求和,得到最终乘积。
乘法器的近似可以从上述3个步骤入手。
文献[3]提出一种根据设计的乘法器(Under Designed Multiplier,UDM),通过2乘2近似乘法器子模块来产生PP。
对PP压缩是近似研究的重点方向,主要方法包括截断、4-2压缩[4-5]以及近似全加器累加等。
文献[4-7]提出不同的4-2压缩方法来压缩PP。
文献[8-9]利用或门来压缩低位的PP,高位用精确加法器累加避免误差距离过大。
除了上述近似方法之外,文献[10]使用米切尔对数算法及其改进形式来近似乘法操作,获得的改进乘法器性能较好。
2 近似乘法器结构2.1 近似加法结构对绝大部分乘法器来说,加法器是基本元素。
低位或门加法器(Lower-part-OR Adder,LOA)与容错加法器(Error-Tolerant Adder,ETA)可以对加法器低位进行不精确计算。
流水线乘法器
一般的快速乘法器通常采用逐位并行的迭代阵列结构,将每个操作数的N位都并行地提交给乘法器。
但是一般对于FPGA来讲,进位的速度快于加法的速度,这种阵列结构并不是最优的。
所以可以采用多级流水线的形式,将相邻的两个部分乘积结果再加到最终的输出乘积上,即排成一个二叉树形式的结构,这样对于N位乘法器需要log2(N)级来实现。
一个8位乘法器,如图所示。
module mux_4(mul_a,mul_b,mul_out,clk,rst_n);
parameter MUL_WIDTH = 4;
parameter MUL_RESULT = 8;
input [MUL_WIDTH-1:0] mul_a;
input [MUL_WIDTH-1:0] mul_b;
input clk;
input rst_n;
output [MUL_RESULT-1:0] mul_out;
reg [MUL_RESULT-1:0] mul_out;
reg [MUL_RESULT-1:0] stored0;
reg [MUL_RESULT-1:0] stored1;
reg [MUL_RESULT-1:0] stored2;
reg [MUL_RESULT-1:0] stored3;
reg [MUL_RESULT-1:0] add01;
reg [MUL_RESULT-1:0] add23;
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
mul_out <= 8'b0000_0000;
stored0 <= 8'b0000_0000;
stored1 <= 8'b0000_0000;
stored2 <= 8'b0000_0000;
stored3 <= 8'b0000_0000;
add01 <= 8'b0000_0000;
add23 <= 8'b0000_0000;;
end
else
begin
stored3 <= mul_b[3] ? {1'b0,mul_a,3'b0} : 8'b0;
stored2 <= mul_b[2] ? {2'b0,mul_a,2'b0} : 8'b0;
stored1 <= mul_b[1] ? {3'b0,mul_a,1'b0} : 8'b0;
stored0 <= mul_b[0] ? {4'b0,mul_a} : 8'b0;
add01 <= stored1 + stored0;
add23 <= stored3 + stored2;
mul_out <= add01 + add23;
end
end
endmodule。