Matlab回归分析
- 格式:docx
- 大小:71.13 KB
- 文档页数:12



利用MATLAB进行回归分析一、实验目的:1.了解回归分析的基本原理,掌握MATLAB实现的方法;2. 练习用回归分析解决实际问题。
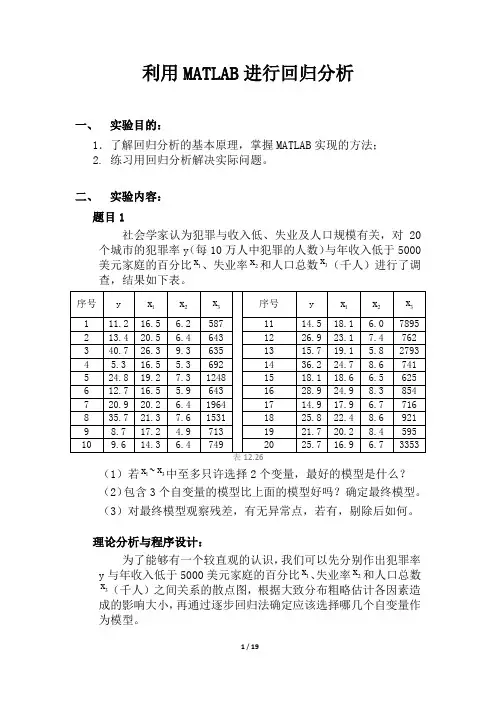
二、实验内容:题目1社会学家认为犯罪与收入低、失业及人口规模有关,对20个城市的犯罪率y(每10万人中犯罪的人数)与年收入低于5000美元家庭的百分比1x、失业率2x和人口总数3x(千人)进行了调查,结果如下表。
(1)若1x~3x中至多只许选择2个变量,最好的模型是什么?(2)包含3个自变量的模型比上面的模型好吗?确定最终模型。
(3)对最终模型观察残差,有无异常点,若有,剔除后如何。
理论分析与程序设计:为了能够有一个较直观的认识,我们可以先分别作出犯罪率y与年收入低于5000美元家庭的百分比1x、失业率2x和人口总数x(千人)之间关系的散点图,根据大致分布粗略估计各因素造3成的影响大小,再通过逐步回归法确定应该选择哪几个自变量作为模型。
编写程序如下:clc;clear all;y=[11.2 13.4 40.7 5.3 24.8 12.7 20.9 35.7 8.7 9.6 14.5 26.9 15.736.2 18.1 28.9 14.9 25.8 21.7 25.7];%犯罪率(人/十万人)x1=[16.5 20.5 26.3 16.5 19.2 16.5 20.2 21.3 17.2 14.3 18.1 23.1 19.124.7 18.6 24.9 17.9 22.4 20.2 16.9];%低收入家庭百分比x2=[6.2 6.4 9.3 5.3 7.3 5.9 6.4 7.6 4.9 6.4 6.0 7.4 5.8 8.6 6.5 8.36.7 8.6 8.4 6.7];%失业率x3=[587 643 635 692 1248 643 1964 1531 713 749 7895 762 2793 741 625 854 716 921 595 3353];%总人口数(千人)figure(1),plot(x1,y,'*');figure(2),plot(x2,y,'*');figure(3),plot(x3,y,'*');X1=[x1',x2',x3'];stepwise(X1,y)运行结果与结论:犯罪率与低收入散点图犯罪率与失业率散点图犯罪率与人口总数散点图低收入与失业率作为自变量低收入与人口总数作为自变量失业率与人口总数作为自变量在图中可以明显看出前两图的线性程度很好,而第三个图的线性程度较差,从这个角度来说我们应该以失业率和低收入为自变量建立模型。

MATLAB回归分析回归分析是统计学中常用的一种方法,用于建立一个依赖于自变量(独立变量)的因变量(依赖变量)的关系模型。
在MATLAB环境下,回归分析可以实现简单线性回归、多元线性回归以及非线性回归等。
简单线性回归是一种最简单的回归分析方法,它假设自变量和因变量之间存在线性关系。
在MATLAB中,可以通过`polyfit`函数进行简单线性回归分析。
该函数可以拟合一元数据点集和一维多项式,返回回归系数和截距。
例如:```matlabx=[1,2,3,4,5];y=[2,3,4,5,6];p = polyfit(x, y, 1);slope = p(1);intercept = p(2);```上述代码中,`x`是自变量的数据点,`y`是因变量的数据点。
函数`polyfit`的第三个参数指定了回归的阶数,这里是1,即一次线性回归。
返回的`p(1)`和`p(2)`分别是回归系数和截距。
返回的`p`可以通过`polyval`函数进行预测。
例如:```matlabx_new = 6;y_pred = polyval(p, x_new);```多元线性回归是在有多个自变量的情况下进行的回归分析。
在MATLAB中,可以使用`fitlm`函数进行多元线性回归分析。
例如:```matlabx1=[1,2,3,4,5];x2=[2,4,6,8,10];y=[2,5,7,8,10];X=[x1',x2'];model = fitlm(X, y);coefficients = model.Coefficients.Estimate;```上述代码中,`x1`和`x2`是两个自变量的数据点,`y`是因变量的数据点。
通过将两个自变量放在`X`矩阵中,可以利用`fitlm`函数进行多元线性回归分析。
返回值`model`是回归模型对象,可以通过`model.Coefficients.Estimate`获得回归系数。


1、 regress命令用于一元及多元线性回归,本质上是最小二乘法。
在Matlab 2014a中,输入help regress ,会弹出和regress的相关信息,一一整理。
调用格式:B = regress(Y,X)[B,BINT] = regress(Y,X)[B,BINT,R] = regress(Y,X)[B,BINT,R,RINT] = regress(Y,X)B,BINT,R,RINT,STATS] = regress(Y,X)[...] = regress(Y,X,ALPHA)参数解释:B:回归系数,是个向量(“the vector B of regression coefficients in the linear model Y = X*B”)。
BINT:回归系数的区间估计(“a matrix BINT of 95% confidence intervals for B”)。
R:残差(“a vector R of residuals”)。
RINT:置信区间(“a matrix RINT of intervals that can be used to diagnose outliers”)。
STATS:用于检验回归模型的统计量。
有4个数值:●判定系数R^2: 指回归直线对观测值的拟合程度。
R^2的取值范围是[0,1]。
R^2的值越接近1,说明回归直线对观测值的拟合程度越好;反之,R^2的值越接近0,说明回归直线对观测值的拟合程度越差。
●F统计量观测值: F值越大通过检验的可能性就越大F值表示回归模型的方差与残差的比值(残差就是总方差减去回归模型的方差),可以想象F越大表示残差越小,模拟的精度越高(从方差方面考虑).不过只要F的值大于你所需要的显著性检验的临界值就可以了.●检验的p的值: 就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。
如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。

Matlab技术回归分析方法简介:回归分析是一种常用的数据分析方法,用于建立变量之间的关系模型。
Matlab是一种功能强大的数值计算软件,提供了丰富的函数和工具包,用于实现回归分析。
本文将介绍几种常见的Matlab技术回归分析方法,并探讨其应用场景和优缺点。
一、线性回归分析:线性回归分析是回归分析的经典方法之一,用于研究变量之间的线性关系。
在Matlab中,可以使用`fitlm`函数来实现线性回归分析。
该函数通过最小二乘法拟合出最优的线性模型,并提供了各种统计指标和图形展示功能。
线性回归分析的应用场景广泛,例如预测销售额、研究市场需求等。
然而,线性回归假设自变量和因变量之间存在线性关系,当数据呈现非线性关系时,线性回归会失效。
为了解决非线性关系的问题,Matlab提供了多种非线性回归分析方法,如多项式回归、指数回归等。
二、多项式回归分析:多项式回归分析是一种常见的非线性回归方法,用于建立多项式模型来描述变量之间的关系。
在Matlab中,可以使用`fitlm`函数中的`polyfit`选项来实现多项式回归分析。
多项式回归在处理非线性关系时具有很好的灵活性。
通过选择不同的多项式次数,可以适应不同程度的非线性关系。
然而,多项式回归容易过拟合,导致模型过于复杂,对新数据的拟合效果不佳。
为了解决过拟合问题,Matlab提供了正则化技术,如岭回归和Lasso回归,可以有效控制模型复杂度。
三、岭回归分析:岭回归是一种正则化技术,通过添加L2正则项来控制模型的复杂度。
在Matlab中,可以使用`fitlm`函数的`Regularization`选项来实现岭回归分析。
岭回归通过限制系数的大小,减少模型的方差,并改善模型的拟合效果。
然而,岭回归不能自动选择最优的正则化参数,需要通过交叉验证等方法进行调优。
四、Lasso回归分析:Lasso回归是另一种常用的正则化技术,通过添加L1正则项来控制模型的复杂度。
在Matlab中,可以使用`fitlm`函数的`Regularization`选项来实现Lasso回归分析。



利用 Matlab 作回归分析一元线性回归模型:2,(0,)y x N αβεεσ=++求得经验回归方程:ˆˆˆyx αβ=+ 统计量: 总偏差平方和:21()n i i SST y y ==-∑,其自由度为1T f n =-; 回归平方和:21ˆ()n i i SSR y y ==-∑,其自由度为1R f =; 残差平方和:21ˆ()n i i i SSE y y ==-∑,其自由度为2E f n =-;它们之间有关系:SST=SSR+SSE 。
一元回归分析的相关数学理论可以参见《概率论与数理统计教程》,下面仅以示例说明如何利用Matlab 作回归分析。
【例1】为了了解百货商店销售额x 与流通费率(反映商业活动的一个质量指标,指每元商品流转额所分摊的流通费用)y 之间的关系,收集了九个商店的有关数据,见下表1.试建立流通费率y 与销售额x 的回归方程。
表1 销售额与流通费率数据【分析】:首先绘制散点图以直观地选择拟合曲线,这项工作可结合相关专业领域的知识和经验进行,有时可能需要多种尝试。
选定目标函数后进行线性化变换,针对变换后的线性目标函数进行回归建模与评价,然后还原为非线性回归方程。
【Matlab数据处理】:【Step1】:绘制散点图以直观地选择拟合曲线x=[1.5 4.5 7.5 10.5 13.5 16.5 19.5 22.5 25.5];y=[7.0 4.8 3.6 3.1 2.7 2.5 2.4 2.3 2.2];plot(x,y,'-o')输出图形见图1。
510152025图1 销售额与流通费率数据散点图根据图1,初步判断应以幂函数曲线为拟合目标,即选择非线性回归模型,目标函数为:(0)b y ax b =< 其线性化变换公式为:ln ,ln v y u x == 线性函数为:ln v a bu =+【Step2】:线性化变换即线性回归建模(若选择为非线性模型)与模型评价% 线性化变换u=log(x)';v=log(y)';% 构造资本论观测值矩阵mu=[ones(length(u),1) u];alpha=0.05;% 线性回归计算[b,bint,r,rint,states]=regress(v,mu,alpha)输出结果:b =[ 2.1421; -0.4259]表示线性回归模型ln=+中:lna=2.1421,b=-0.4259;v a bu即拟合的线性回归模型为=-;y x2.14210.4259bint =[ 2.0614 2.2228; -0.4583 -0.3934]表示拟合系数lna和b的100(1-alpha)%的置信区间分别为:[2.0614 2.2228]和[-0.4583 -0.3934];r =[ -0.0235 0.0671 -0.0030 -0.0093 -0.0404 -0.0319 -0.0016 0.0168 0.0257]表示模型拟合残差向量;rint =[ -0.0700 0.02300.0202 0.1140-0.0873 0.0813-0.0939 0.0754-0.1154 0.0347-0.1095 0.0457-0.0837 0.0805-0.0621 0.0958-0.0493 0.1007]表示模型拟合残差的100(1-alpha)%的置信区间;states =[0.9928 963.5572 0.0000 0.0012] 表示包含20.9928SSR R SST==、 方差分析的F 统计量/963.5572//(2)R E SSR f SSR F SSE f SSE n ===-、 方差分析的显著性概率((1,2))0p P F n F =->≈; 模型方差的估计值2ˆ0.00122SSE n σ==-。
第八章回归分析方法当人们对研究对象的内在特性和各因素间的关系有比较充分的认识时,一般用机理分析方法建立数学模型.如果由于客观事物内部规律的复杂性及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型,那么通常的办法是搜集大量数据,基于对数据的统计分析去建立模型。
本章讨论其中用途非常广泛的一类模型——统计回归模型。
回归模型常用来解决预测、控制、生产工艺优化等问题。
变量之间的关系可以分为两类:一类叫确定性关系,也叫函数关系,其特征是:一个变量随着其它变量的确定而确定。
另一类关系叫相关关系,变量之间的关系很难用一种精确的方法表示出来.例如,通常人的年龄越大血压越高,但人的年龄和血压之间没有确定的数量关系,人的年龄和血压之间的关系就是相关关系。
回归分析就是处理变量之间的相关关系的一种数学方法。
其解决问题的大致方法、步骤如下:(1)收集一组包含因变量和自变量的数据;(2)选定因变量和自变量之间的模型,即一个数学式子,利用数据按照最小二乘准则计算模型中的系数;(3)利用统计分析方法对不同的模型进行比较,找出与数据拟合得最好的模型;(4)判断得到的模型是否适合于这组数据;(5)利用模型对因变量作出预测或解释。
应用统计分析特别是多元统计分析方法一般都要处理大量数据,工作量非常大,所以在计算机普及以前,这些方法大都是停留在理论研究上.运用一般计算语言编程也要占用大量时间,而对于经济管理及社会学等对高级编程语言了解不深的人来说要应用这些统计方法更是不可能.MATLAB等软件的开发和普及大大减少了对计算机编程的要求,使数据分析方法的广泛应用成为可能。
MATLAB统计工具箱几乎包括了数理统计方面主要的概念、理论、方法和算法。
运用MATLAB统计工具箱,我们可以十分方便地在计算机上进行计算,从而进一步加深理解,同时,其强大的图形功能使得概念、过程和结果可以直观地展现在我们面前。
本章内容通常先介绍有关回归分析的数学原理,主要说明建模过程中要做的工作及理由,如模型的假设检验、参数估计等,为了把主要精力集中在应用上,我们略去详细而繁杂的理论。
MATLAB 回归分析regress,nlinfit,stepwise函数matlab回归分析regress,nlinfit,stepwise函数回归分析1.多元线性重回在matlab统计工具箱中使用命令regress()实现多元线性回归,调用格式为b=regress(y,x)或[b,bint,r,rint,statsl=regess(y,x,alpha)其中因变量数据向量y和自变量数据矩阵x按以下排列方式输入对一元线性重回,挑k=1即可。
alpha为显著性水平(缺省时预设为0.05),输入向量b,bint为回归系数估计值和它们的置信区间,r,rint为残差及其置信区间,stats就是用作检验重回模型的统计数据量,存有三个数值,第一个就是r2,其中r就是相关系数,第二个就是f统计数据量值,第三个就是与统计数据量f对应的概率p,当p拒绝h0,回归模型成立。
图画出来残差及其置信区间,用命令rcoplot(r,rint)实例1:已知某湖八年来湖水中cod浓度实测值(y)与影响因素湖区工业产值(x1)、总人口数(x2)、捕鱼量(x3)、降水量(x4)资料,建立污染物y的水质分析模型。
(1)输出数据x1=[1.376,1.375,1.387,1.401,1.412,1.428,1.445,1.477]x2=[0.450,0.475,0.485,0.50 0,0.535,0.545,0.550,0.575]x3=[2.170,2.554,2.676,2.713,2.823,3.088,3.122,3.262]x4=[0.8922,1.1610,0.5346,0.9589,1.0239,1.0499,1.1065,1.1387]y=[5.19,5.30,5.60,5.82,6.00,6.06,6.45,6.95](2)留存数据(以数据文件.mat形式留存,易于以后调用)savedatax1x2x3x4yloaddata(抽出数据)(3)继续执行重回命令x=[ones(8,1),];[b,bint,r,rint,stats]=regress得结果:b=(-16.5283,15.7206,2.0327,-0.2106,-0.1991)’stats=(0.9908,80.9530,0.0022)即为=-16.5283+15.7206xl+2.0327x2-0.2106x3+0.1991x4r2=0.9908,f=80.9530,p=0.00222.非线性重回非线性回归可由命令nlinfit来实现,调用格式为[beta,r,j]=nlinfit(x,y,'model’,beta0)其中,输人数据x,y分别为n×m矩阵和n维列向量,对一元非线性回归,x为n维列向量model是事先用m-文件定义的非线性函数,beta0是回归系数的初值,beta是估计出的回归系数,r是残差,j是jacobian矩阵,它们是估计预测误差需要的数据。
回归分析1.多元线性回归在Matlab统计工具箱中使用命令regress()实现多元线性回归,调用格式为b=regress(y,x)或[b,bint,r,rint,statsl = regess(y,x,alpha)其中因变量数据向量y和自变量数据矩阵x按以下排列方式输入对一元线性回归,取k=1即可。
alpha为显著性水平(缺省时设定为0.05),输出向量b,bint为回归系数估计值和它们的置信区间,r,rint为残差及其置信区间,stats是用于检验回归模型的统计量,有三个数值,第一个是R2,其中R是相关系数,第二个是F统计量值,第三个是与统计量F对应的概率P,当P<α时拒绝H0,回归模型成立。
画出残差及其置信区间,用命令rcoplot(r,rint)实例1:已知某湖八年来湖水中COD浓度实测值(y)与影响因素湖区工业产值(x1)、总人口数(x2)、捕鱼量(x3)、降水量(x4)资料,建立污染物y的水质分析模型。
(1)输入数据x1=[1.376, 1.375, 1.387, 1.401, 1.412, 1.428, 1.445, 1.477]x2=[0.450, 0.475, 0.485, 0.500, 0.535, 0.545, 0.550, 0.575]x3=[2.170 ,2.554, 2.676, 2.713, 2.823, 3.088, 3.122, 3.262]x4=[0.8922, 1.1610 ,0.5346, 0.9589, 1.0239, 1.0499, 1.1065, 1.1387]y=[5.19, 5.30, 5.60,5.82,6.00, 6.06,6.45,6.95](2)保存数据(以数据文件.mat形式保存,便于以后调用)save data x1 x2 x3 x4 yload data (取出数据)(3)执行回归命令x =[ones(8,1),];[b,bint,r,rint,stats] = regress得结果:b = (-16.5283,15.7206,2.0327,-0.2106,-0.1991)’stats = (0.9908,80.9530,0.0022)即= -16.5283 + 15.7206xl + 2.0327x2 - 0.2106x3 + 0.1991x4R2 = 0.9908,F = 80.9530,P = 0.00222.非线性回归非线性回归可由命令nlinfit来实现,调用格式为[beta,r,j] = nlinfit(x,y,'model’,beta0)其中,输人数据x,y分别为n×m矩阵和n维列向量,对一元非线性回归,x 为n维列向量model是事先用m-文件定义的非线性函数,beta0是回归系数的初值,beta是估计出的回归系数,r是残差,j是Jacobian矩阵,它们是估计预测误差需要的数据。
在MATLAB中使用高斯过程进行回归分析随着数据科学和机器学习的发展,回归分析成为了一种非常常见和有用的数据分析工具。
而高斯过程作为一种统计建模工具,在回归分析中具有广泛的应用。
在本文中,我们将介绍如何在MATLAB中使用高斯过程进行回归分析。
高斯过程,也被称为基于核函数的回归(Kriging)或者高斯过程回归(Gaussian Process Regression,简称GPR),是一种概率模型,广泛应用于回归分析中。
它通过对数据进行建模,将数据与潜在函数之间的关系进行学习和预测。
在MATLAB中,可以使用Statistics and Machine Learning Toolbox来进行高斯过程回归分析。
首先,我们需要准备一些数据来进行回归分析。
假设我们想要预测一个物体的重量,我们可以将物体的尺寸作为输入变量,将物体的重量作为输出变量。
我们可以通过测量一系列物体的尺寸和重量来获得这些数据。
在MATLAB中,我们可以使用`fitrgp`函数来进行高斯过程回归的建模和预测。
首先,我们需要将数据拆分成输入变量和输出变量。
假设我们的输入变量存储在一个名为`X`的矩阵中,输出变量存储在一个名为`Y`的向量中。
我们可以使用以下代码进行拆分:```matlabX = [尺寸1; 尺寸2; 尺寸3; ...; 尺寸n];Y = [重量1; 重量2; 重量3; ...; 重量n];```接下来,我们可以使用`fitrgp`函数来建立高斯过程回归模型:```matlabmodel = fitrgp(X, Y);```在这个过程中,`fitrgp`函数将自动选择核函数和其他参数,来对输入变量和输出变量之间的关系进行建模。
但是,我们也可以通过指定自定义的核函数和参数来调整建模的过程。
建立了模型之后,我们可以使用`predict`函数来对新的数据进行预测。
假设我们想要预测一个新物体的重量,我们可以将其尺寸作为输入变量传递给`predict`函数:```matlabnew_size = [新物体的尺寸];predicted_weight = predict(model, new_size);````predict`函数将返回一个预测的重量值,这个值可以帮助我们了解新物体的重量。
1、 考察温度x 对产量y 的影响,测得下列10组数据:区间(置信度95%).x=[20:5:65]';Y=[13.2 15.1 16.4 17.1 17.9 18.7 19.6 21.2 22.5 24.3]'; X=[ones(10,1) x]; plot(x,Y,'r*');[b,bint,r,rint,stats]=regress(Y,X); b,bint,stats;rcoplot(r,rint) %残差分析,作残差图结果: b =9.1212 0.2230 bint =8.0211 10.2214 0.1985 0.2476 stats =0.9821 439.8311 0.0000 0.2333即01ˆˆ9.1212,0.2230ββ==;0ˆβ的置信区间为[8.0211,10.2214]1ˆβ的置信区间为[0.1985,0.2476]; 2r =0.9821 , F=439.831, p=0.0000 ,p<0.05, 可知回归模型y=9.1212+0.2230x 成立.将x=42带入得到18.4872.从残差图可以看出,所有数据的残差离零点均较近,且残差的置信区间均包含零点,这说明回归模型y=9.1212+0.2230x能较好的符合原始数据。
2某零件上有一段曲线,为了在程序控制机床上加工这一零件,需要求这段曲线的解析表达式,在曲线横坐标xi处测得纵坐标yi共11对数据如下:求这段曲线的纵坐标y关于横坐标x的二次多项式回归方程。
t=0:2:20;s=[0.6 2.0 4.4 7.5 11.8 17.1 23.3 31.2 39.6 49.7 61.7];T=[ones(11,1) ,t',(t.^2)'];[b,bint,r,rint,stats]=regress(s',T);b,stats;Y=polyconf(p,t,S)plot(t,s,'k+',t,Y,'r') %预测及作图b =1.01050.19710.1403stats =1.0e+04 *0.0001 1.3773 0.0000 0.00002ˆ 1.01050.19710.1403st t =++ 图形为:3混凝土的抗压强度随养护时间的延长而增加,现将一批混凝土作成12个试块,记录了养护试求ˆln ya b x =+型回归方程。
%建立volum.m 文件 function yhat=volum(beta,x); yhat=beta(1)+beta(2)*log(x);%输入x=[2 3 4 5 7 9 12 14 17 21 28 56]; y=[35 42 47 53 59 65 68 73 76 82 86 99]; beta0=[5 1]';[beta,r,J]=nlinfit(x',y','volum',beta0); beta结果: beta =21.0058 19.5285所得回归模型为:21.05819.5285ln y x =+ 画线:plot(x,y,'r-')x=[2 3 4 5 7 9 12 14 17 21 28 56]';u=log(x);u=[ones(12,1) u];y=[35 42 47 53 59 65 68 73 76 82 86 99]'; [b,bint,r,rint,stats]=regress(y,u);b,bint,stats结果为:b =21.005819.5285bint =19.4463 22.565318.8943 20.1627stats =1.0e+03 *0.0010 4.7069 0.0000 0.0009做残差图:rcoplot(r,rint)预测及作图:z=b(1)+b(2)*log(x); plot(x,y,'k+',x,z,'r')1. 设有五个样品,每个只测量了一个指标,分别是1,2,6,8,11,试用最短距离法将它们分类。
(样品间采用绝对值距离。
)clc clear b=[1;2;6;8;11]; d=pdist(b,'cityblock'); D=squareform(d); z=linkage(d); H=dendrogram(z); T=cluster(z,2);结果:各样品之间的绝对距离为:[]1,5,7,10,4,6,9,2,5,3d =距离矩阵01571010469=5402576203109530D ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦,样品间的最短距离为: 1 2 13 4 25 7 36 8 4z ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦;2.表1是1999 年中国省、自治区的城市规模结构特征的一些数据,试通过聚类分析将这些整理a=[699.7000 1.4371 0.9364 0.7804 10.8800 179.4600 1.8982 1.0006 0.5870 11.7800 111.1300 1.4180 0.6772 0.5158 17.7750 389.6000 1.9182 0.8541 0.5762 26.3200 211.3400 1.7880 1.0798 0.4569 19.7050 259 2.3059 0.3417 0.5076 23.4800923.1900 3.7350 2.0572 0.6208 22.1600整理139.2900 1.8712 0.8858 0.4536 12.6700102.7800 1.2333 0.5326 0.3798 27.3750108.5000 1.7291 0.9325 0.4687 11.1200129.2000 3.2454 1.1935 0.4519 17.0800173.3500 1.0018 0.4296 0.4503 21.2150151.5400 1.4927 0.6775 0.4738 13.9400434.4600 7.1328 2.4413 0.5282 19.1900139.2900 2.3501 0.8360 0.4890 14.2500336.5400 3.5407 1.3863 0.4020 22.195096.1200 1.2288 0.6382 0.5000 14.340045.4300 2.1915 0.8648 0.4136 8.7300365.0100 1.6801 1.1486 0.5720 18.6150146 6.6333 2.3785 0.5359 12.2500136.2200 2.8279 1.2918 0.5984 10.470011.7900 4.1514 1.1798 0.6118 7.3150244.0400 5.1194 1.9682 0.6287 17.8000145.4900 4.7515 1.9366 0.5806 11.650061.3600 8.2695 0.8598 0.8098 7.420047.6000 1.5078 0.9587 0.4843 9.7300128.6700 3.8535 1.6216 0.4901 14.4700];d1=pdist(a); %欧氏距离:d1=pdist(a);,%b中每行之间距离z1=linkage(d1) %作谱系聚类图:H= dendrogram(z1)T=cluster(z1,3) %% 输出分类结果结果为:(1)z1 =8.0000 15.0000 1.652120.0000 24.0000 2.087718.0000 26.0000 2.488011.0000 27.0000 2.765421.0000 28.0000 3.919929.0000 32.0000 6.99263.0000 10.0000 7.167313.0000 33.0000 7.352831.0000 35.0000 8.61252.0000 12.0000 11.29169.0000 34.0000 12.726217.0000 38.0000 12.805125.0000 30.0000 15.50846.0000 23.0000 16.329136.0000 39.0000 18.038837.0000 42.0000 22.99794.0000 19.0000 25.771716.0000 44.0000 28.75595.0000 43.0000 32.850841.0000 46.0000 32.936822.0000 40.0000 33.728847.0000 48.0000 36.136714.0000 45.0000 45.749049.0000 50.0000 77.56761.0000 7.0000 223.789151.0000 52.0000 265.4356(2)输出分类结果:T =133333233333333333333333333表明,若分三类,3是一类,2是一类,其它的是一类。
(3)做谱系聚类图:。