正态总体样本标准差
- 格式:doc
- 大小:384.50 KB
- 文档页数:6


统计学中σx-概述说明以及解释1.引言1.1 概述统计学是一门研究数据收集、分析、解释和预测的学科。
它通过收集大量的数据样本,运用数理统计方法,揭示数据背后的规律和趋势,从而对现象进行推断和预测。
在进行统计学研究时,我们经常会遇到需要对数据的变异程度进行描述和分析的情况。
而在统计学中,变异程度的度量指标之一就是σx,即样本标准差。
σx是描述样本数据离散程度的一种统计参数,它通过测量样本数据与其平均值之间的差异来反映数据的分散情况。
本文将重点讨论σx在统计学中的定义、意义以及计算方法。
我们将通过详细介绍σx的概念和原理,帮助读者深入理解σx在统计学中的重要性和应用。
随着大数据时代的到来,统计学在各个领域的应用越来越广泛。
无论是市场调研、财务分析、医学研究还是社会科学领域,都需要借助统计学方法来处理和分析数据。
而在这个过程中,σx作为一种重要的统计指标,对于评估数据的稳定性和可靠性起到了至关重要的作用。
然而,虽然σx在统计学领域有着广泛的应用,但它也存在一些局限性。
在本文的后续章节中,我们将详细讨论σx的局限性以及对其进一步研究和应用的展望。
总之,本文将通过对统计学中的σx进行深入阐述和分析,旨在帮助读者更好地理解和应用这一重要的统计学指标。
通过对σx的研究,我们可以更准确地刻画数据的变异情况,为决策提供更可靠的依据,并推动统计学在不同领域的发展。
1.2 文章结构文章结构部分主要介绍本文的章节组成和内容安排。
本文按照引言、正文和结论三个部分进行组织。
在引言部分,首先会对整篇文章进行概述,简要介绍统计学中的σx的定义和意义,以及本文的目的。
然后会给出文章的结构,列出各个章节的主要内容,并指引读者快速了解本文的结构。
接下来是正文部分,正文分为三个小节。
首先会详细介绍什么是统计学,包括其定义、研究对象、方法和应用领域等。
然后会着重讲解σx的定义和意义,解释σx在统计学中的重要性和作用。
最后会详细介绍σx的计算方法,包括数学推导过程和具体计算公式。

正态分布总体总体均值已知方差的置信区间【文章开头】一、引言在统计学中,正态分布总体是相当常见的一种总体类型。
当我们需要对一个正态分布总体的总体均值进行推断时,有时候我们会面临到总体均值已知,但方差未知的情况。
对于这样的情况,我们可以使用置信区间来进行推断。
二、什么是置信区间?置信区间是指在统计推断中,对总体参数的估计范围。
通常,我们会给出一个置信水平,比如95%的置信水平,表示对总体参数的估计有95%的把握是正确的。
置信区间由一个下限和一个上限组成,表示总体参数可能落在这个范围内的概率。
三、正态分布总体的总体均值已知的情况下,方差的置信区间如何计算?当正态分布总体的总体均值已知时,我们可以使用样本标准差来作为总体方差的估计。
我们可以利用样本大小、置信水平和样本标准差来计算方差的置信区间。
四、计算步骤1. 收集样本数据:从正态分布总体中随机抽取样本,并记录样本数据。
2. 计算样本标准差:利用样本数据计算样本标准差。
样本标准差是总体方差的一个无偏估计。
3. 确定置信水平:根据需要的置信水平,确定置信水平对应的临界值。
临界值可以从统计表中查找。
4. 计算置信区间:利用样本大小、样本标准差和置信水平的临界值,计算方差的置信区间。
五、示例假设我们想研究某种药物对血压的影响。
我们从正态分布的总体中随机抽取了100个样本,并记录了每个样本的血压数据。
我们已知总体均值为120,方差未知。
现在,我们想要计算方差的95%置信区间。
1. 收集样本数据:从正态分布总体中随机抽取100个样本,并记录血压数据。
2. 计算样本标准差:利用样本数据计算样本标准差。
假设计算得到样本标准差为10。
3. 确定置信水平:我们希望得到95%的置信区间,因此置信水平为0.95。
4. 计算置信区间:根据样本大小100,样本标准差10,和置信水平0.95的临界值,我们可以计算得到方差的置信区间。
【文章主体】六、方差的置信区间是如何帮助我们进行推断的?方差的置信区间为我们提供了一个总体参数可能的取值范围。



样本的标准差样本的标准差计算公式标准差(Standard Deviation ),在概率统计中最常使用作为统计分布程度(statistical dispersion )上的测量。
标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。
它反映组内个体间的离散程度。
测量到分布程度的结果,原则上具有两种性质:为非负数值,与测量资料具有相同单位。
一个总量的标准差或一个随机变量的标准差,及一个子集合样品数的标准差之间,有所差别。
标准计算公式:假设有一组数值X1,X2,X3,……XN (皆为实数),其平均值(算术平均值)为(公式如图 1 。
标准差也被称为标准偏差,或者实验标准差,公式为。
简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合{0,5,9,14} 和{5,6,8,9} 其平均值都是7 ,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。
例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。
相反,标准差数值越小,代表回报较为稳定,风险亦较小。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。
这两组的平均数都是70,但A组的标准差约为17.08分,B组的标准差约为2.16分,说明A组学生之间的差距要比B组学生之间的差距大得多。


总体参数的区间估计公式在进行区间估计时,我们首先需要收集到一个样本,并根据样本对总体参数进行估计。
然后根据样本的统计量,结合分布的性质和抽样方法,建立置信区间。
设总体参数为θ,我们希望得到它的置信水平为1-α的置信区间。
置信水平表示我们对总体参数的估计的可信程度,一般常用的置信水平有90%、95%和99%等。
参数估计的方法有很多,具体的方法选择取决于总体参数的性质、样本的大小以及其他假设条件。
常见的参数估计方法有:1.总体均值的区间估计:假设总体呈正态分布,样本大小为n,则总体均值的区间估计公式为:[样本均值-Z值(α/2)*总体标准差/√(n),样本均值+Z值(α/2)*总体标准差/√(n)]其中Z值(α/2)为标准正态分布的分位数,可以从标准正态分布表中查得。
2.总体比例的区间估计:假设总体为二项分布,样本大小为n,成功的次数为x,则总体比例的区间估计公式为:[样本比例-Z值(α/2)*√(样本比例*(1-样本比例)/n),样本比例+Z值(α/2)*√(样本比例*(1-样本比例)/n)]其中Z值(α/2)为标准正态分布的分位数,可以从标准正态分布表中查得。
3.总体方差的区间估计:假设总体呈正态分布,样本大小为n,则总体方差的区间估计公式为:[(n-1)*样本方差/卡方分布(α/2),(n-1)*样本方差/卡方分布(1-α/2])]其中卡方分布是用于描述自由度为n-1的卡方随机变量的概率分布,可以从卡方分布表中查得。
以上是常见的总体参数区间估计公式,这些公式是根据统计学理论推导而来的,适用于不同情况下的参数估计。
在实际应用中,我们根据具体问题和假设条件选择适当的参数估计方法,计算置信水平的区间估计,从而对总体参数进行估计和推断。

样本均值的标准差在统计学中,样本均值的标准差是一个重要的概念,它用来衡量样本数据的离散程度,也可以用来估计总体的离散程度。
在本文中,我们将详细讨论样本均值的标准差的计算方法,以及它在实际应用中的意义和作用。
首先,让我们来了解一下样本均值的概念。
样本均值是指一组数据中所有数据值的平均数,它是对数据集中心位置的一个重要指标。
样本均值的标准差则是用来衡量这组数据的离散程度,它可以告诉我们数据的分布情况,以及数据集中的数据与均值的偏离程度。
计算样本均值的标准差需要以下几个步骤:1. 首先,计算样本数据的均值。
这可以通过将所有数据值相加,然后除以数据的个数来得到。
2. 然后,计算每个数据值与均值的差值。
这可以通过将每个数据值减去均值来得到。
3. 接下来,计算这些差值的平方。
这一步是为了消除正负号对计算结果的影响,同时突出数据与均值的偏离程度。
4. 最后,将这些差值的平方求和,然后除以数据的个数,再取平方根,就得到了样本均值的标准差。
样本均值的标准差在实际应用中有着广泛的意义和作用。
首先,它可以帮助我们理解数据的分布情况。
通过标准差,我们可以知道数据集中的数据是集中在均值附近,还是分散在均值附近,从而可以更好地理解数据的特征和规律。
其次,样本均值的标准差也可以用来比较不同数据集之间的离散程度。
通过比较不同数据集的标准差,我们可以判断它们的离散程度,从而可以进行更深入的分析和研究。
此外,样本均值的标准差还可以用来进行统计推断。
在统计推断中,我们经常需要对总体的特征进行估计,而样本均值的标准差可以作为总体标准差的估计值,从而帮助我们进行统计推断的分析。
总之,样本均值的标准差是统计学中一个重要的概念,它可以帮助我们理解数据的分布情况,比较不同数据集的离散程度,以及进行统计推断的分析。
通过对样本均值的标准差的计算方法和实际应用进行深入的了解,我们可以更好地运用它来分析和解释数据,为实际问题的解决提供有力的支持。
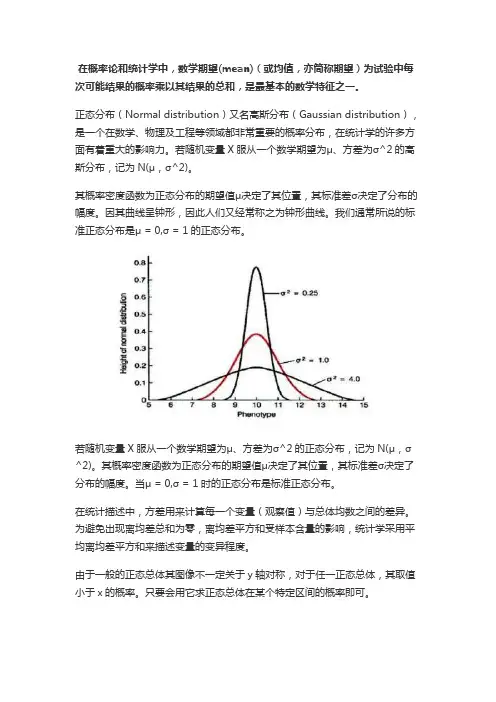
在概率论和统计学中,数学期望(mean)(或均值,亦简称期望)为试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。
若随机变量X服从一个数学期望为μ、方差为σ^2的高斯分布,记为N(μ,σ^2)。
其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。
因其曲线呈钟形,因此人们又经常称之为钟形曲线。
我们通常所说的标准正态分布是μ = 0,σ = 1的正态分布。
若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。
其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。
当μ = 0,σ = 1时的正态分布是标准正态分布。
在统计描述中,方差用来计算每一个变量(观察值)与总体均数之间的差异。
为避免出现离均差总和为零,离均差平方和受样本含量的影响,统计学采用平均离均差平方和来描述变量的变异程度。
由于一般的正态总体其图像不一定关于y轴对称,对于任一正态总体,其取值小于x的概率。
只要会用它求正态总体在某个特定区间的概率即可。
为了便于描述和应用,常将正态变量作数据转换。
将一般正态分布转化成标准正态分布。
对于连续型随机变量X,若其定义域为(a,b),概率密度函数为f(x),连续型随机变量X方差计算公式:D(X)=(x-μ)^2 f(x) dx方差刻画了随机变量的取值对于其数学期望的离散程度。
(标准差、方差越大,离散程度越大)若X的取值比较集中,则方差D(X)较小,若X的取值比较分散,则方差D (X)较大。
因此,D(X)是刻画X取值分散程度的一个量,它是衡量取值分散程度的一个尺度。

如何确定正态分布总体均值已知的方差的置信区间在统计学中,置信区间是一种用来估计参数真实值范围的方法。
当我们知道总体均值,但方差未知时,我们需要确定正态分布总体总体均值已知的方差的置信区间。
在本文中,我将以从简到繁的方式来探讨这个主题,让您能更深入地理解。
1. 正态分布总体的概念让我们简要回顾一下正态分布总体的概念。
正态分布是最为常见的概率分布之一,其特点是呈钟形曲线,均值和标准差决定了曲线的中心位置和宽度。
在统计学中,我们常常使用正态分布来描述连续型随机变量的分布情况。
2. 总体均值已知的情况当我们已经知道正态分布总体的均值时,我们可以通过样本来估计总体的方差。
我们可以利用样本方差来估计总体方差,然后构建置信区间来确定总体方差的范围。
3. 方差的置信区间估计为了确定正态分布总体均值已知的方差的置信区间,我们可以利用卡方分布来进行估计。
卡方分布是一种特殊的概率分布,用于描述正态分布总体方差的抽样分布。
通过卡方分布的性质,我们可以构建出方差的置信区间,从而对总体方差做出估计。
4. 个人观点和理解在我的个人观点中,确定正态分布总体总体均值已知的方差的置信区间是统计学中非常重要的一部分。
这不仅可以帮助我们对总体方差进行估计,还可以为我们后续的推断统计提供重要的依据。
通过合理地构建置信区间,我们可以更准确地对总体参数进行推断,并且可以对我们的结论进行更加可靠的评估。
总结通过本文的阐述,我们可以深刻理解确定正态分布总体总体均值已知的方差的置信区间的方法。
我们需要对正态分布总体及其性质有一个清晰的认识。
我们可以利用样本数据来对总体方差进行估计,并且通过卡方分布来构建置信区间。
我也共享了我个人的观点和理解,希望可以为您对这个主题提供更多的思考。
在知识的文章格式中,可以使用序号标注来清晰地展示每个步骤的逻辑关系。
我希望本文的内容能够帮助您更好地理解正态分布总体总体均值已知的方差的置信区间的确定方法。
在统计学中,确定正态分布总体均值已知的方差的置信区间是一项重要的任务。
统计学常识标准差,正态分布,西格玛为非负数值,与测量资料具有相同单位。
一个总量的标准差或一个随机变量的标准差,及一个子集合样品数的标准差之间,有所差别。
标准差的观念是由卡尔·皮尔逊(KarlPearson)引入到统计中。
标准差可以当作不确定性的一种测量。
例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。
相反,标准差数值越小,代表回报较为稳定,风险亦较小。
在真实世界中,除非在某些特殊情况下,找到一个总体的真实的标准差是不现实的。
大多数情况下,总体标准差是通过随机抽取一定量的样本并计算样本标准差估计的。
在实际应用上,常考虑一组数据具有近似于正态分布的机率分布。
若其假设正确,则约68%数值分布在距离平均值有1个标准差之内的范围,约95%数值分布在距离平均值有2个标准差之内的范围,以及约99.7%数值分布在距离平均值有3个标准差之内的范围。
称为68-95-99.7法则。
从几何学的角度出发,标准差可以理解为一个从n维空间的一个点到一条直线的距离的函数。
举一个简单的例子,一组数据中有3个值,X1,X2,X3。
它们可以在3维空间中确定一个点P=(X1,X2,X3)。
想像一条通过原点的直线。
如果这组数据中的3个值都相等,则点P就是直线L上的一个点,P到L的距离为0,所以标准差也为0。
若这3个值不都相等,过点P作垂线PR垂直于L,PR交L于点R,则R的坐标为这3个值的平均数,运用一些代数知识,不难发现点P与点R之间的距离(也就是点P到直线L的距离)是。
样本的标准差样本的标准差计算公式标准差(Standard Deviation),在概率统计中最常使用作为统计分布程度(statistical dispersion)上的测量。
标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。
它反映组内个体间的离散程度。
测量到分布程度的结果,原则上具有两种性质:为非负数值,与测量资料具有相同单位。
一个总量的标准差或一个随机变量的标准差,及一个子集合样品数的标准差之间,有所差别。
标准计算公式:假设有一组数值X1,X2,X3,......XN(皆为实数),其平均值(算术平均值)为μ,公式如图1。
标准差也被称为标准偏差,或者实验标准差,公式为。
简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合{0,5,9,14} 和 {5,6,8,9} 其平均值都是 7 ,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。
例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。
相反,标准差数值越小,代表回报较为稳定,风险亦较小。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。
这两组的平均数都是70,但A组的标准差约为17.08分,B组的标准差约为2.16分,说明A组学生之间的差距要比B组学生之间的差距大得多。
正态总体参数的假设检验 正态总体中有两个参数:正态均值与正态⽅差。
有关这两个参数的假设检验问题经常出现,现逐⼀叙述如下。
(⼀) 正态均值的假设检验 ( 已知情形) 建⽴⼀个检验法则,关键在于前三步l,2,3。
5.判断(同前) 注:这个检验法称为u检验。
(⼆) 正态均值的假设检验 ( 未知情形) 在未知场合,可⽤样本标准差s去替代总体标准差,这样⼀来,u统计量变为t统计量,具体操作如下: 1.关于正态均值常⽤的三对假设为 5.判断 (同前) 注:这个检验法称为t检验。
(三)正态⽅差的假设检验 检验正态⽅差有关命题成⽴与否,⾸先想到要⽤样本⽅差。
在基础上依据抽样分布特点可构造统计量作为检验之⽤。
具体操作如下: 1.关于正态⽅差常⽤的三对假设为 5.判断(同前) 注:这个检验法称为检验。
注:关于正态标准差的假设与上述三对假设等价,不另作讨论。
(四) ⼩结与例⼦ 上述三组有关正态总体参数的假设检验可综合在表1.5-1上,以供⽐较和查阅。
续表 [例1.5-2] 某电⼯器材⼚⽣产⼀种云母带,其厚度在正常⽣产下服从N(0.13,0.0152)。
某⽇在⽣产的产品中抽查了10次,发现平均厚度为0.136,如果标准差不变,试问⽣产是否正常?(取 =0.05)来源:考试通 解:①⽴假设:②由于已知,故选⽤u检验。
③~④根据显著性⽔平 =0.05及备择假设可确定拒绝域为{ >1.96}。
⑤由样本观测值,求得检验统计量: 由于u未落在拒绝域中,所以不能拒绝原假设,可以认为该天⽣产正常。
[例1.5-3] 根据某地环境保护法规定,倾⼊河流的废⽔中⼀种有毒化学物质的平均含量不得超过3ppm。
已知废⽔中该有毒化学物质的含量X服从正态分布。
该地区环保组织对沿河的⼀个⼯⼚进⾏检查,测定每⽇倾⼊河流的废⽔中该物质的含量,15天的记录如下(单位:ppm)3.2,3.2,3.3,2.9,3.5,3.4,2.5,4.3,2.9,3.6,3.2,3.0,2.7,3.5,2.9 试在⽔平上判断该⼚是否符合环保规定? 解:①如果符合环保规定,那么应该不超过3ppm,不符合的话应该⼤于3ppm。
第十九讲 正态总体均值及方差的区间估计1. 单个正态总体方差的区间估计设总体),(~2σμN X , ),,(21n X X X 为来自X 的一个样本,已给定置信度(水平)为α-1,求2σ的置信区间。
①当μ已知时,由于),(~2σμN X i ,因此,)1,0(~N X i σμ-(,2,1=i n , )。
由2χ分布的定义知:∑=-ni i n X 1222)(~)(χσμ,据)(2n χ分布上α分位点的定义,有:αχσμχαα-=<-<∑=-1)}()()({21222122n X n P ni i从而αχμσχμαα-=⎪⎪⎭⎪⎪⎬⎫-<<⎪⎪⎩⎪⎪⎨⎧--=-∑∑1)()()()(2112221222n X n X P ni i ni i 故2σ的置信度为α-1的置信区间为:⎪⎪⎪⎪⎭⎫ ⎝⎛---==∑∑)()(,)()(211221222n X n X ni i n i i ααχμχμ ②当μ未知时,据抽样分布有:)1(~)1(222--n S n χσ类似以上过程,得到第七章 参数估计第5节 正态总体均值及方差的区间估计单个正态总体均值的区间估计 ①当2σ已知时,μ的置信水平为α-1的置信区间为:⎪⎪⎭⎫ ⎝⎛±2ασz n X (5.1) ②当2σ未知时,μ的置信水平为α-1的置信区间为⎪⎪⎭⎫ ⎝⎛-±)1(2n t n SX α.(5.4)注意:当分布不对称时,如2χ分布和F 分布,习惯上仍然取其对称的分位点,来确定置信区间,但所得区间不是最短的。
αχσχαα-=⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧--<<---1)1()1()1()1(21222222n S n n S n P 2σ的置信度为α-1的置信区间为:⎪⎪⎭⎫⎝⎛-----)1()1(,)1()1(2122222n S n n S n ααχχ σ的置信度为α-1的置信区间为:⎪⎪⎪⎭⎫ ⎝⎛-----)1()1(,)1()1(2122222n S n n S n ααχχ 例2 有一大批袋装糖果, 现从中随机地取出16袋, 称得重量(以克计)如下:506 508 499 503 504 510 497 512 514 505 493 496 506 502 509 496 设袋装糖果的重量近似地服从正态分布, 求总体标准差σ的置信水平为0.95的置信区间.解:总体均值μ未知,σ的置信度为α-1的置信区间为:⎪⎪⎪⎭⎫ ⎝⎛-----)1()1(,)1()1(2122222n S n n S n ααχχ 此时,,975.021,025.02,05.0=-==ααα16=n ,查表得,488.27)15(025.0=χ,262.6)15(975.0=χ由给出的数据算得.4667.382=s 因此,σ的一个置信度为0.95的置信区间为(4.58,9.60).2. 两个正态总体均值差的区间估计设总体),(~),,(~222211σμσμN Y N X ,且X 与Y 相互独立,),,(21m X X X 来自X 的一个样本,),,,(21n Y Y Y 为来自Y 的一个样本,且设2221,,,S S Y X 分别为总体X 与Y 的样本均值与样本方差,对给定置信水平α-1,求21μμ-的一个置信区间。
抽样理论中的公式总结中心极限定理标准误差等抽样理论中的公式是进行统计推断和数据分析的重要工具,其中包括中心极限定理和标准误差等概念。
本文将对抽样理论中的公式进行总结和探讨。
一、中心极限定理中心极限定理是抽样理论中的重要概念,它告诉我们,当样本容量足够大时,样本均值的抽样分布将近似服从正态分布。
中心极限定理可以用如下公式表示:Z = (X - μ) / (σ / √n)其中,Z表示标准正态分布的随机变量,X为样本均值,μ为总体均值,σ为总体标准差,n为样本容量。
中心极限定理的应用十分广泛,它为我们进行统计推断提供了重要的依据。
通过将样本均值与总体均值的差异标准化,我们可以计算出该差异发生的概率,从而作出合理的推断。
二、标准误差在抽样理论中,标准误差用于衡量样本统计量的不确定性,它反映了样本统计量与总体参数之间的差异。
标准误差的计算公式如下:SE = σ / √n其中,SE表示标准误差,σ为总体标准差,n为样本容量。
标准误差越大,意味着样本统计量与总体参数之间的差异越大,样本的代表性就越差。
因此,在进行数据分析和推断时,我们一般希望标准误差越小,以提高推断的准确性。
三、样本容量的确定进行抽样调查时,确定合适的样本容量非常重要。
样本容量的大小决定了样本统计量的稳定性和准确性,也影响了所得到的推断结果的可靠性。
在抽样理论中,通过样本容量计算标准误差可以帮助我们确定合适的样本容量。
一般来说,当样本容量越大时,标准误差越小,样本统计量与总体参数之间的差异越小。
因此,我们可以根据抽样目的和实际情况,选择适当的样本容量以达到推断的要求。
四、其他公式与应用除了中心极限定理和标准误差之外,抽样理论中还涉及到其他一些重要的公式和概念,如置信区间、假设检验等。
这些公式和概念在实际应用中具有广泛的使用。
置信区间是对总体参数的范围估计,常用的计算公式为:CI = X ± Z * (σ / √n)其中,CI表示置信区间,X为样本均值,Z为临界值,σ为总体标准差,n为样本容量。
正态总体样本标准差S 不是总体标准差σ的无偏估计量设12,,,n X X X ⋅⋅⋅是来自正态总体2(,)N μσ的一个样本,11ni i X X n==∑为样本均值,2211()1nii S X X n ==--∑为样本方差。
众所周知,对任何总体来说样本方差2S 是总体方差2σ的无偏估计两,正态总体更不是例外。
但样本标准差S 却不是总体标准差σ的无偏估计量。
证明: 由于222(1)~(1)n Sn χσ--,若令22(1)n SY σ-=,则2~(1)Y n χ-的概率密度为11()2211022()200n n n y y e y P y y --Γ-⎧->⎪=⎨⎪≤⎩从而112222122()112()11()2()2()222nyny n nnE y dy y e dy yedy n n n+∞+∞+∞------∞===--ΓΓΓ⎰⎰⎰①()21()2n n =-Γ 另一方面,)()E E E S σσ==,所以有1()2n E S E C σσ===≠,所以,样本标准差S 却不是总体标准差σ的无偏估计量。
如果进行修正,则可以得到σ的无偏估计量 nC S σ=,其中2n C =评注:1. 理论依据:正态总体样本的抽样分布,2χ分布与Γ分布的有关性质。
2. 应用与推广:无论总体X 服从什么分布,修正的样本方差2211()1nii S XX n ==--∑是总体方差()D X 的无偏估计量,但是样本方差S 不是总体标准差()X σ=的无偏估计量。
只有在正态总体的情况下才有确定性的修正方法,使得nC S σ= 是总体标准差的无偏估计量,对于非正态总体,情况极为复杂,一般不对其进行讨论。
参考文献:茆诗松等,概率论与数理统计。
本经:中国统计出版社,2000参数估计方法在捕鱼问题中的应用设湖中有鱼N 条,做上记号后放回湖中(记号不消失),一段时间后让湖中的鱼(做上记号的和没做记号的)混合均匀,再从湖中捕出鱼数s 条()s r ≥ ,其中有t 条(0)t r ≤≤标有记号。
试根据这些信息,估计湖中鱼数的N 值。
(1)根据概率的统计定义:湖中有记号的鱼的比例应是r N(概率),而在捕出的s条中有记号的鱼为t 条,有记号的鱼的比例是t s(频率)。
设想捕鱼是完全随机的,每条鱼被捕的机会都相等,于是根据用频率来近似概率的道理,便有r t Ns= 即 rs N t=故 rs Nt≈(取最接近的整数)。
(2)用矩估计法:设捕出的s 条鱼中,标有记号的鱼为ξ,因为ξ是超几何分布,而超几何分布的数学期望是()rs E Nξ=。
捕s 条鱼得到有标记的鱼的总体平均数,而现在只捕一次,出现t 条有标记的鱼,故由矩估计法,令总体一阶原点矩等于样本一阶原点矩,即rst N =,于是也得 rs N t≈(取最接近的整数)。
(3)根据二项分布与极大似然估计:若再加上一点条件,及假定捕出的鱼数s 与湖中的鱼数N 的比很小,即s N,这样的假定对实际来说一般是可以满足的,这样我们可以认为每捕一条鱼出现有标记的概率为r p N=,且认为在s 次捕鱼(每次捕一条)中p 不变。
把捕s 条鱼近似地看做s 重贝努力实验,于是,根据二项分布,s 条鱼有t 条有标记的,就相当于s 次试验中有t 次成功。
故1()(1)()(1)()tts ttts tt t s ts s s s sr r p t C p p C C r N r NNN---=-=-=-同样地,我们取使N 概率()s p t 达到最大,为此我们将N 作为非负实数看待,求()s p t 关于的N 最大值。
为方便,求 ln ()s p t 关于N 的最大值。
于是ln ()()ln ()ln ln ln ()ln()0ts s s d p t s s t p t s N C t r s t N r dNNN r-=-+++--=-+=-令ln ()()0s d p t s s t dNNN r-=-+=-同样可得 rs Nt≈(取最接近的整数)。
(4)根据超几何体分布鱼最大似然估计法:设捕出的s 条鱼中,标有记号放入鱼为ξ,则 ξ是一个随机变量,显然ξ只能取{}0,1,2,(min ,)l l s r ⋯=。
令先考虑s 条中有i 条有标记的鱼的概率,即()p i ξ=。
因湖中鱼数设为N 条,捕出s 条,故{}(),0,1,2(m in ,)is ir N rs NC C p i i l l s r C ξ--===⋯,=因为捕出s 条出现t 条有标记的鱼的概率为()()ts tr N rsN C C p t L N Cξ--==≡根据最大似然估计法,今捕s 条出现有标记的鱼t 条,那么参数N 应该使得()()p t L N ξ==达到最大,即参数N 的估计值N 使得()m ax ()NL NL N = 由比值111111()!(1)!()()!()!!(1)!()!(1)!(1)!()!()!(1)!t s tss sr N rN N N s t s t s s t Nr N r N N rN r N C C C C C L N s t N r s t s N s R N N N r L N CC C C C s N s s t N r s t -----------------+--====--------+22()()()N r N s N N r N s rs N N r s t N N r N s N t----+==--+--+看出,当rs N t <时,()1R N <,这表明如果0rs t t>>,N 时,()L N 是N 的下降函数;当rs N t >时,R ()1N >,这表明0,rs t N t><时,()L N 是N 的上升函数。
于是rs N t=时,()L N 达到最大值,但由于N 时整数,故取 rs Nt≈(取最接近的整数)如果0t =,就加大s ;若仍有0t =,可认为 N=+∞。
评注:1. 理论依据:二项分布、超几何体分布的概率计算,矩法计与极大似然估计。
应用参数估计的思想和方法分析、处理问题。
2. 应用与推广:此例说明,对同一个问题可以采用不同的方法解决。
例如,估计一个城市的人口总素,也可以采用同样的方法去考虑。
参考文献:孙荣恒⋅趣味随机问题⋅北京:科学出版社,2004平均值的质量控制图在工业质量控制中,常需要每隔一定的时间就检验一次同样的假设0H 。
例如,在制造某种弹簧的过程中,需要控制弹簧的自由长度具有平均值 1.5μ=厘米。
设弹簧的自由长度(总体)服从正态分布,且标准差0.02σ=,为检验生产过程是否正常,每隔一定时间(例如一小时)取样n 件,根据抽测的自由长度的平均值x 来检验假设0: 1.5H μ=(厘米)。
为简化这项工作即便于了解生产过程中统计规律性,制作了如下的图表。
图中的纵坐标是x 的大小,中心线在 1.5μ=,控制上限和控制下限分别在00μμ+-,每个样本平均值都画在图上,用黑点表示。
如果x 都落在控制线之间,则表明生产过程处于正常的控制之下;否则,就要检查原因,适当地调整机器,显著性水平σ不超过0.003。
图中的控制限中的3就是取0.0027σ=得到的。
这是根据3σ规则得到的检验方法。
如果总体2~(,)X N μσ,则 {}32(3)120.9986510.9973P X μσ-<=Φ-=⨯-=在X 中抽取容量为n 的样本12,,,nX X X ⋅⋅⋅,则样本均值2~(,),~(0,1)X X N N nσμμ-。
当总体方差2σ已知时,在显著性水平0.027σ=之下,假设00:H μμ=的接受域是:33X μ--≤≤。
那么,如果以X为检验统计量的接受域为:003Xμμ-≤≤+。
所以,做出的控制图分别以00μμ-+作为控制下限和控制上限。
如果每隔一小时的时间间隔内采样(容量为5)的样本均值如下:1.510,1.495,1.521,1.505,1.524,1.488,1.465,1.529,1.520,1.4441.531,1.502,1.490,1.531,1.475,1.478,1.522,1.491,1.491,1.482由0 1.50.02μσ==及作出样本容量5n =的样本平均值控制图,可以作出质量控制图。
评注:1.理论依据:正态总体均值的置信区间,根据样本构造置信上限与下限,从而作出质量控制图。
2.应用于推广:根据正态总体分布与数理统计的知识,进行质量管理与质量控制是概率统计应用的一个和重要的方面,特别是用在质量控制的法则,目前在全球最先进的企业都采用管理法,已经形成一种企业管理文化。
而正态总体参数。