【VIP专享】Logit-4p四参数拟合科研数据处理方法
- 格式:pdf
- 大小:671.00 KB
- 文档页数:7

四参数拟合 Python1. 什么是四参数拟合?四参数拟合是一种数学方法,用于拟合一组数据点到一个四参数的数学模型上。
这个数学模型通常用一个函数表示,包含四个参数。
通过拟合这个模型,我们可以找到最佳的参数组合,使得模型与实际数据最为接近。
四参数拟合在实际应用中非常常见,特别是在曲线拟合、数据分析和预测等领域。
它可以用来拟合各种类型的数据,例如指数衰减、生长曲线、非线性回归等。
2. 四参数拟合的数学模型四参数拟合的数学模型通常采用以下形式的函数:y=a+b1+c⋅e−dx其中,a、b、c和d是四个参数,e是自然对数的底数。
这个函数是一个带有指数项的曲线函数,可以拟合各种类型的数据。
参数a控制函数的纵向平移,参数b控制函数的纵向缩放,参数c控制函数的横向缩放,参数d控制函数的横向平移。
3. 如何进行四参数拟合?在 Python 中,可以使用 SciPy 库中的curve_fit函数进行四参数拟合。
curve_fit函数是一个非线性最小二乘拟合的工具,可以拟合各种类型的非线性模型。
首先,需要导入相关的库:import numpy as npfrom scipy.optimize import curve_fit然后,准备数据。
假设我们有一组实验数据,存储在两个数组x_data和y_data 中:x_data = np.array([1, 2, 3, 4, 5])y_data = np.array([2.1, 3.8, 6.7, 9.9, 15.2])接下来,定义四参数拟合的函数模型:def func(x, a, b, c, d):return a + b / (1 + c * np.exp(-d * x))然后,使用curve_fit函数进行拟合:params, params_covariance = curve_fit(func, x_data, y_data)最后,可以打印出拟合得到的参数值:print(params)4. 示例下面是一个完整的四参数拟合的示例代码:import numpy as npfrom scipy.optimize import curve_fit# 准备数据x_data = np.array([1, 2, 3, 4, 5])y_data = np.array([2.1, 3.8, 6.7, 9.9, 15.2])# 定义四参数拟合的函数模型def func(x, a, b, c, d):return a + b / (1 + c * np.exp(-d * x))# 进行拟合params, params_covariance = curve_fit(func, x_data, y_data)# 打印拟合得到的参数值print(params)运行以上代码,将得到拟合得到的参数值。

在线曲线拟合四参数通常指的是使用四个参数来拟合一条曲线。
这四个参数通常包括:
1.斜率(Slope):表示曲线在X轴上的变化速率。
2.截距(Intercept):表示曲线在Y轴上的截距。
3.最大值(Max Value):表示曲线在某个点上的最大值。
4.最小值(Min Value):表示曲线在某个点上的最小值。
这四个参数可以根据实验数据或测量数据来拟合得到。
在线曲线拟合四参数的方法通常包括以下步骤:
1.收集实验数据或测量数据,并确定X轴和Y轴的范围。
2.根据数据分布情况,选择合适的拟合函数,例如指数函数、对数函数、幂函数等。
3.将拟合函数与数据相对应,确定四个参数的初值。
4.使用优化算法,如梯度下降法、牛顿法等,对四个参数进行迭代优化,使得拟合函
数与数据之间的误差最小。
5.重复步骤4,直到达到预设的迭代次数或误差阈值。
6.输出最终的四个参数值,以及拟合曲线和原始数据之间的误差。
需要注意的是,在线曲线拟合四参数的方法可能受到多种因素的影响,如数据的分布情况、噪声、异常值等。
因此,在使用该方法时,需要根据实际情况进行适当的选择和调整。

4参数Logistic曲线拟合(也称为4PL拟合)是一种非线性回归方法,通常用于描述生物、化学和其他科学领域的实验数据。
4PL模型在描述生长曲线、剂量响应曲线等方面特别有用。
4PL模型的方程如下:
(y = \frac{a - d}{1 + (\frac{x}{c})^b} + d)
其中,
(y) 是响应变量(例如,生物量、浓度等)。
(x) 是解释变量(例如,时间、剂量等)。
(a) 是曲线的上渐近线。
(d) 是曲线的下渐近线。
(c) 是半饱和常数,表示响应变量达到最大变化率的一半时的(x) 值。
(b) 是曲线的形状参数,决定了曲线的陡峭程度。
4PL拟合的步骤如下:
收集数据:首先,你需要一组实验数据,包括解释变量(x) 和响应变量(y)。
初始化参数:为参数(a, b, c, d) 选择初始估计值。
这些值可以基于数据的直观分析或其他先前的研究来选择。
拟合模型:使用非线性最小二乘法(或其他优化算法)来拟合4PL模型。
目标是找到参数值,使得预测值与实际观测值之间的残差平方和最小。
评估模型:检查模型的拟合质量。
这可以通过查看残差图、计算决定系数((R^2))或进行其他统计检验来完成。
使用模型:一旦模型被拟合和评估,它就可以用于预测新的数据点或进行进一步的分析。
需要注意的是,4PL模型可能对某些数据集过拟合,因此在应用时应该小心。
此外,选择合适的初始参数值对于成功拟合4PL模型至关重要。

科研数据处理方法——四参数拟合
科研工作者必须要掌握的技能。
然而,由于数据形式的多种多样,伴随着方法也是层出不穷。
对于免疫检测的数据处理,常常会用到四参数拟合,下面介绍其具体的数据处理方法。
工具/原料
酶标仪或者紫外分光光度计
免疫分析数据
方法/步骤 N
首先在Excel中整理好数据,一部分是做标准曲线的数据,另一部分是待求的数据。
打开ELISA Calc软件,先在Excel中复制数据,再在软件中点击“粘贴”。
选择回归/拟合模型,选中“四参数”,点击“回归/拟合按钮”。
弹出的窗口中显示了曲线,可以截图下来。
别忘了X和Y分别表示的什么。
这是标准品提供一个方程。
样品有反应值,要计算X值,点击“由Y计算X”。
复制Excel中的样品的反应值,点击软件的“粘贴”按钮,即可自动计算出对应的X值,也即是样品浓度。
方程拟合的好坏,还可以查看方程来检验,主要看r^2的值,越接近1,拟合效果越好。
注意事项
本方法不限于做四参数拟合,其它拟合方法相似。

四参数拟合需求及详细算法四参数拟合是一种常用的曲线拟合方法,用于拟合一个具有四个未知参数的数学函数到已知的数据点上。
这种拟合方法通常用于解决一些实际问题,比如物理实验数据的拟合、经济学模型的拟合等。
下面将详细介绍四参数拟合的需求和算法。
1.准确性:四参数拟合的目标是尽可能准确地通过已知的数据点来拟合一个具有四个未知参数的数学函数。
因此,在进行拟合时需要选择合适的数学函数模型,并且调整参数使得该模型能够最优地拟合已知数据。
2.稳定性:拟合结果应该对输入数据的变化具有一定的稳定性,即输入数据的微小扰动不应该对拟合结果产生较大的影响。
3.可靠性:拟合算法应该在足够短的时间内得到可靠的结果,并且应该能够处理不同规模和数量级的数据。
1.选择数学函数模型:首先需要根据已知数据的特点选择合适的数学函数模型。
通常情况下,可以选择一个具有四个未知参数的函数模型作为目标函数。
2.构建目标函数:构建一个包含四个未知参数的目标函数,并将其表示为一个关于未知参数的方程。
3.拟合参数:使用最小二乘法或其他优化方法,将目标函数中的未知参数调整为最优值。
最小二乘法是一种常见的参数拟合方法,其基本思想是通过最小化目标函数与已知数据的残差平方和来确定最优参数值。
4.参数优化:根据最小二乘法的思想,可以通过对目标函数进行偏导数运算,将其转化为一个带有未知参数的线性方程组。
然后,可以使用数值方法(如矩阵计算或梯度下降法)来求解该线性方程组,进而得到最优的未知参数值。
5.拟合结果评估:拟合参数后,需要对拟合结果进行评估,包括残差分析、R方值(决定系数)、均方根误差等。
通过这些指标可以评估拟合结果的准确性和稳定性,从而判断拟合模型的合理性。
6.结果优化:如果拟合结果不满足要求,可以尝试优化算法参数,或者改变模型函数,进一步优化拟合结果。
总结:四参数拟合是一种常用的曲线拟合方法,通过选择合适的数学函数模型,并使用最小二乘法或其他优化方法来拟合数据,从而得到最优的未知参数值。

一、介绍log-logit拟合方法log-logit拟合方法是一种常用的统计技术,它用于分析二分类问题中的非线性关系。
在许多领域,如医学、生态学和市场营销等,研究人员经常需要对因变量和自变量之间的关系进行建模。
log-logit拟合方法可以帮助研究人员理解并预测这些关系。
二、log-logit拟合方法的原理1. log-logit拟合方法基于逻辑回归模型,它假设因变量和自变量之间的关系可以用逻辑函数来描述。
逻辑函数可以将自变量的线性组合转换成0和1之间的概率值,从而对两个类别进行分类。
2. log-logit拟合方法通过对数据进行最大似然估计,寻找最优的模型参数,使得模型的预测值与实际观测值之间的差异最小。
3. 与线性拟合方法不同,log-logit拟合方法考虑了因变量取值的非线性特征,能够更准确地描述复杂的分类关系。
三、log-logit拟合方法的优势1. 可处理非线性关系:log-logit拟合方法适用于因变量和自变量之间的非线性关系,能够更准确地描述实际情况。
2. 高度灵活性:log-logit拟合方法可以灵活地适应不同的数据特征,对不同领域的问题提供了一种通用的建模技术。
3. 可解释性强:通过log-logit拟合方法得到的模型参数具有很强的解释性,可以帮助研究人员理解因变量和自变量之间的关系。
四、log-logit拟合方法的应用1. 医学领域:log-logit拟合方法常常用于疾病风险预测和生物医学数据分析,可以帮助医生和研究人员理解疾病发生的概率与影响因素之间的关系。
2. 生态学领域:log-logit拟合方法可以用于分析生态系统中的物种分布、种裙动态和种间关系,为生态保护和环境管理提供科学依据。
3. 市场营销领域:log-logit拟合方法可以帮助企业预测用户的购物行为和偏好,优化营销策略和产品定位。
五、总结log-logit拟合方法是一种强大的统计工具,它能够处理非线性关系,具有高度灵活性和解释性强的优势。
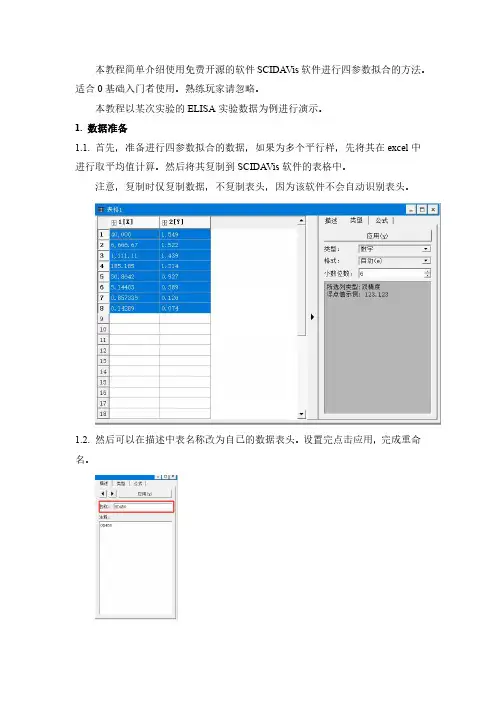
本教程简单介绍使用免费开源的软件SCIDAVis软件进行四参数拟合的方法。
适合0基础入门者使用。
熟练玩家请忽略。
本教程以某次实验的ELISA实验数据为例进行演示。
1.数据准备1.1.首先,准备进行四参数拟合的数据,如果为多个平行样,先将其在excel中进行取平均值计算。
然后将其复制到SCIDAVis软件的表格中。
注意,复制时仅复制数据,不复制表头,因为该软件不会自动识别表头。
1.2.然后可以在描述中表名称改为自己的数据表头。
设置完点击应用,完成重命名。
2.绘制散点图2.1.选择列,右键,【绘图】——【散点图】得到非常朴素的散点图。
3.非线性拟合3.1.在图中空白区域右键——【分析】——【拟合向导】进入拟合界面。
3.2.在【名称】中可以输入自己要拟合的方程名字,例如“4PL”3.3.在【参数】中输入:a,b,c,d3.4.在下面的文本框输入函数的表达式:(a-d)/(1+(x/c)^b)+d3.5.再单击【保存】。
(保存后,下次使用就可以在用户自定义的中调用该函数表达式)3.6.再单击【拟合】。
3.7.在拟合的算法中,在下拉框选择“Nelder-Mead单形”或【未调整的Levenberg-Marquardt】或【未调整的Levenberg-Marquardt】。
三者拟合在3位小数点时,精度一致,小数点越多,差异越大,但是精度均满足数据处理需求,因此任选一即可。
可以自己尝试不同的算法拟合结果有何差异。
3.8.单击下方的【拟合】。
3.9.拟合结果查看。
可以看到【初始猜测】已经更新为结果值。
左上角的【结果日志】中也可以看到各参数。
关于精度:按上述步骤进行操作,和酶标仪拟合的结果会有一些差异。
但是当保留3位有效数字的情况下,与酶标仪的拟合结果基本一致。
下图为本软件和酶标仪拟合的结果比较。
因此,该条件基本可以满足日常数据处理的需要。
4.图片美化看到拟合的图片非常粗糙丑陋。
该软件默认的图形中X轴坐标的数据是按照正常数值设置的,因此图形不是S形曲线。

四参数法拟合
四参数法是一种数据拟合的方法,它可以将实验数据用一个函数
进行拟合。
这种方法需要确定四个参数,分别是平移量、旋转角度、
缩放比例和水平方向的偏移量。
四参数法的公式如下:
x' = x*cosθ - y*sinθ + a
y' = x*sinθ + y*cosθ + b
其中,x和y是原始数据的坐标,x'和y'是拟合数据的坐标,θ
表示旋转角度,a和b分别是平移和偏移参数,它们都是待拟合的参数。
四参数法的拟合步骤如下:
1. 将原始数据点(x, y)转换为以一个点为原点的坐标系;
2. 利用平移量a和b将数据点移动到坐标系原点;
3. 利用旋转角度θ对数据点进行旋转调整;
4. 利用缩放比例对数据点进行缩放调整;
5. 利用平移量将数据点还原到原来的坐标系。
四参数法的优点是可以较好地适应非线性数据,并且比较简单,
但是缺点是只能适用于平面数据拟合,而且当数据分布范围较大时,
拟合效果可能不够理想。

第1章 概述本文档之目的是利用已知的几组数据通过现有数学模型,求出数学模型中的四个参数,并确保拟合后的数学模型中自变量和因变量的相关度≥0.997.第二章 设计需求及详细算法2.1 设计需求通过已知的吸光度值x 和浓度值y ,进行四参数对数拟合,求出四参数模型中的对应参数a,b,c,d 。
四参数数学模型如下所示:d bc xd a y +⎪⎭⎫ ⎝⎛+-=1需求1:通过已知数据(x,y )数组拟合后,求出数学模型中的a,b,c,d ; 需求2:要求所计算出的四个参数,能够保证x,y 的相关度≥0.997.需求3:和软件现有的其他算法如半对数、二参数等算法并行存在于软件中;并在软件后续的数据转换和图像显示中可以调度该功能模块;2.2 四参数拟合算法详解数学模型:具体算法实现:整个算法基于高斯牛顿迭代法:其基本思想是使用泰勒级数展开式去近似地代替非线性回归模型,然后通过多次迭代,多次修正回归系数,使回归系数不断逼近非线性回归模型的最佳回归系数,最后使原模型的残差平方和达到最小。
(在软件算法的实现上,可以进一步参照教程《计算方法》)第一步:求a, b, c 和d 的初值。
(此时x 不能为0值,若输入的x 有0值,则在软件实现过程中设定:x=0.0001)对上述模型(1)进行数学变换后得到:在计算的过程中,具体算法进行如下处理:将d 的初值设为输入的y 值的最大值加1,a 的初值设为输入的y 值的最小值减0.1。
通过简单的直线拟合即可求出b 和c 的初值。
第二步:对方程(2)中的四个参数分别求偏微分。
得到y 对给定系数的增量(△a, △b, △c △d )的泰勒级数展开式。
bc x ay ⎪⎭⎫ ⎝⎛+=∂∂11bc x dy⎪⎭⎫ ⎝⎛+-=∂∂111bb cx c x d a c b c y ⎪⎭⎫ ⎝⎛⎥⎥⎦⎤⎢⎢⎣⎡⎪⎭⎫ ⎝⎛+-=∂∂21 21ln ⎥⎥⎦⎤⎢⎢⎣⎡⎪⎭⎫ ⎝⎛+-⎪⎭⎫ ⎝⎛⎪⎭⎫ ⎝⎛-=∂∂b bc xd a c x c x b y泰勒级数展开式为:由此,将曲线回归转化为多元线性回归,通过迭代计算,得到四个参数的变量△a, △b, △c, △d ,逐步修正四参数的值。

四参数拟合python摘要:1.介绍四参数拟合的概念和应用场景2.阐述使用Python 进行四参数拟合的方法3.举例说明如何使用Python 实现四参数拟合4.总结四参数拟合在Python 中的应用优势正文:四参数拟合是一种数学方法,主要用于描述和拟合数据集中的四个变量之间的关系。
在数据分析和建模领域,四参数拟合有着广泛的应用,例如经济学、生物学、社会科学等领域。
在Python 中,有多种方法可以实现四参数拟合,如使用numpy 库、scipy 库等。
首先,我们需要了解四参数拟合的基本概念。
四参数拟合是指在给定数据集中,寻找四个变量之间最佳的数学关系式。
这四个变量可以是连续型或离散型,通常用四元组(x, y, z, w) 表示。
四参数拟合的目标是最小化预测误差,以达到最佳拟合效果。
接下来,我们来探讨如何在Python 中实现四参数拟合。
一种常见的方法是使用numpy 库的polyfit 函数。
polyfit 函数可以对一组数据进行多项式拟合,从而实现四参数拟合。
以下是一个使用numpy 实现四参数拟合的示例:```pythonimport numpy as np# 创建模拟数据集x = np.array([0, 1, 2, 3, 4, 5])y = np.array([1, 3, 2, 5, 8, 10])z = np.array([0, 1, 2, 3, 4, 5])w = np.array([1, 4, 9, 16, 25, 36])# 使用numpy 的polyfit 函数进行四参数拟合p = np.polyfit(x, y, z, w)# 输出拟合结果print("拟合结果:", p)```在这个示例中,我们首先创建了一个包含四个变量x、y、z 和w 的模拟数据集。
然后,我们使用numpy 的polyfit 函数对这些数据进行四参数拟合。
最后,我们输出了拟合结果。
需要注意的是,numpy 的polyfit 函数仅适用于连续型变量。

四参数拟合曲线数据四参数拟合通常用于拟合带有四个参数的函数形式。
这可以通过使用MATLAB或其他数学软件来实现。
以下是一个在MATLAB中使用lsqcurvefit函数进行四参数拟合的简单例子。
假设你的数据是 x_data 和 y_data:% 示例数据x_data = [1, 2, 3, 4, 5];y_data = [2.1, 3.8, 6.3, 8.2, 10.1];% 参数方程的初始猜测值param_guess = [1, 1, 1, 1];% 使用 lsqcurvefit 进行四参数拟合options = optimset('Display', 'iter'); % 设置优化选项,可选param_fit = lsqcurvefit(@four_param_fun, param_guess, x_data, y_data, [], [], options);% 输出拟合的参数disp('拟合的参数值:');disp(param_fit);% 绘制拟合结果x_fit = linspace(min(x_data), max(x_data), 100);y_fit = four_param_fun(param_fit, x_fit);figure;plot(x_data, y_data, 'o', 'DisplayName', '原始数据'); hold on;plot(x_fit, y_fit, '-', 'DisplayName', '拟合曲线'); xlabel('X轴');ylabel('Y轴');title('四参数拟合');legend('show');grid on;% 定义四参数拟合的函数function y = four_param_fun(param, x)a = param(1);b = param(2);c = param(3);d = param(4);y = a * exp(b * x) + c * x + d;end在这个例子中,我使用了一个包含指数项和线性项的四参数函数作为拟合的模型。
四参数拟合四参数拟合,是一种常用的数学方法,它可以通过拟合解决复杂的数学问题,尤其是拟合不规则的数据。
四参数拟合通过将给定的数据表示为一个假想的函数,然后使用参数拟合的方法来最大化该函数的准确性。
四参数拟合的函数式如下:y=A+Bx+Ce^(Dx)其中,A、B、C、D是待求的四个参数,x是自变量,y 是应变量。
此函数是由三部分组成,即线性部分、对数部分和指数部分。
线性部分是当x=0时,函数的常数项,即A;对数部分是当x趋近于无穷大时,函数的系数项,即B;指数部分是在x变动的过程中,函数的变化系数,即C和D。
四参数拟合的本质是将给定的数据用一个函数来表示,并且使该函数的参数能够最好地拟合这些数据,找到了最优的拟合参数。
为了找到最优的参数,必须要计算出误差值,以便衡量拟合精度。
这叫做“误差平方和”,简称SSE,也叫做“平方和残差”,而误差平方和最小时,拟合参数也是最优的。
四参数拟合的实现过程如下:1.先将给定的数据表示为函数;2.根据误差平方和(SSE)的原理计算出拟合误差;3.使用最小二乘法或牛顿法等优化算法,逐步搜索最小的拟合误差,找到最优的四参数;4.根据最优参数,求出拟合函数的图像,并将拟合效果可视化出来。
四参数拟合的优点是:1.可以拟合大量不规则的数据,具有较高的数据处理能力;2.拟合函数的灵敏度更高,可以更好地把握数据变化;3.可以很好地表示非线性数据,可以有效分析复杂的数据关系;4.拟合精度较高,拟合函数更加精确。
四参数拟合的应用范围很广,可以用于各种有关数据分析的场景,比如天气预报、财务数据分析、科学数据模拟等等。
此外,它也可以用于物理、化学等学科,可以帮助我们更好地分析数据,从而获得更多的科学结论和技术应用。
Guangzhou ZYCDNA science technology Co., LTD校准及其注意事项在生化(终点法,速率法等)、免疫(比浊,荧光及发光法等)、血液及分子诊断(荧光,发光法等)分析中,均涉及校准,如何有效选择或设计校准个数、浓度及校准类型会直接影响到分析结果的可靠性。
下面我们对校准品基质、校准使用个数、校准品浓度及校准类型相关信息做些简单的分享。
序号 事项 选择原则1 校准品基质理想的校准品基质应当与被分析物基质一致或类同,尤其是在临床血液样品或体液样品分析中。
理论上讲越高级的方法或检测系统,基质相应越小,但实际商品试剂(包括校准品、质控品和试剂),既使选定是参考方法或参考检测系统,由于考虑商品试剂的货架寿命及消除来源于血清基质的干扰,少不了会有诸多添加剂的加入及主要成分浓度调整,造成原有的参考方法本身基质及浓度发生改变,这样必然造成以临床样品为基准,试剂本身表露出固有基质效应(基质偏差),同时不同分析仪器系统相比样品而言也存在基质效应(包括随机和系统性的偏差)。
目前绝大部分临床分析项目均缺乏对应的参考方法,参考物及参考测量系统,这方面在免疫及分子诊断分析中表现极为明显。
这对制造商建立厂家工作测量系统和临床常规分析系统增加了不少难度,对于这类方法,如何有效提高临床样品分析的准确度就是制造商的“金标准”。
在实际的研究中我们发现纯物质与含基质的纯物质在同一反应中会存在差异,基质效应解决得越好的商品试剂,这种差异会越小;在免疫分析中,使用单抗、多抗及使用不同来源单抗、多抗在同一试剂基质中表观反应会有明显差异,这就要求我们必须以被分析物基质作为我们校准品基质,以减小试剂、仪器或样品的未知基质干扰。
理想的校准基质是含被分析物的新不含任何添加剂或已知添加剂不确定度的新鲜血液或体液,但实际商品基本不可能做到这一点。
但在方Guangzhou ZYCDNA science technology Co., LTD法学研究或质量监测中不难做到。
四参数拟合处理elisa
四参数拟合是一种常用的方法,用于处理ELISA(酶联免疫吸附实验)数据。
ELISA是一种常用的生物化学实验方法,用于检测蛋白质、抗体等的浓度。
在ELISA中,通常会制备一系列不同浓度的标准品,并测量它们的吸光度值。
这些吸光度值与标准品的浓度之间存在一种关系,可以通过拟合曲线来确定未知样品的浓度。
四参数拟合是一种常用的拟合方法,可以通过最小二乘法来拟合曲线。
它的基本原理是,在四个参数的调整下,拟合曲线与实际数据点的误差最小。
四个参数分别是:最大吸光度(Max),最小吸光度(Min),曲线斜率(Slope)和EC50(半最大抑制浓度)。
其中,最大吸光度和最小吸光度分别表示曲线的上限和下限,曲线斜率表示曲线的陡峭程度,EC50表示曲线上吸光度达到最大值一半的浓度。
拟合曲线的方程通常是:
y = Min + (Max - Min) / (1 + (x / EC50) ^ Slope)
其中,x表示标准品的浓度,y表示吸光度值。
通过四参数拟合,可以得到曲线的参数值,并据此计算未知样品的浓度。
通常可以使用统计软件(如Excel、GraphPad Prism等)进
行拟合和计算。
需要注意的是,四参数拟合是一种常用的方法,但并不一定适用于所有ELISA数据。
在实际应用中,可能需要根据实验情况和数据特点选择适合的拟合方法。
利用logistic曲线拟合四参数回归绘制标准曲线SOP
logistic曲线拟合四参数回归适用于双抗夹心ELISA和竞争ELISA实验标准曲线的绘制,为了实验室技术人员及客户能利用本公司提供的ELISACalc软件绘制标准曲线及计算样本浓度,特制定本SOP。
1. 从酶标仪上导出原始的450nm波长下,读取的样本及标准品的吸光度,以EXCEL格式文件保存;
2.原始数据处理计算稀释液空白孔平均OD(若空白孔未设置平行样,则无需计算),利用excel对所有样本及标准品OD扣除空白平均OD,得到一组新的数据。
3. 在excel里选取两个单元格,分别填入standard Con 以及Mean OD.在Standard Con下方写上标准品浓度,然后从上步中copy与标准品浓度对应的数据粘贴到Mean OD列中。
选中浓度与平均OD数据,复制。
4. 双击打开ELISACalc 软件,选择logistic四参数拟合,然后点击ELISACalc程序中的‘粘贴’键,再点击‘回归/拟合’,即可看到自动生成的标准曲线图形。
点击回归方程即可看到标准曲线的方程。
5. 若想计算浓度则先复制计划计算浓度的样本的OD,点击软件中的由Y 计算X,然后点击软件中的‘粘贴’,即可看到两列数据,左边为样本OD,右
边为所OD对应的浓度。
再直接点击复制,即可将OD与对应的浓度复制到Word 或excel文件中。
6. 程序的退出直接关闭软件即可退出程序。
y 的最大值; y 的最小值;第一步:做Logit-Ln 线性回归,求 x有0值,则将其设为一小值(例如:4参数Logistic 拟合算法详解曲线形状:S 型递增或递减。
A1: x 趋近于无穷大或无穷小时,A0: x 趋近于无穷大或无穷小时, X :曲线拐点;P:与拐点处曲线斜率相关2.拟合算法:高斯牛顿迭代法A1, A0, x 和p 的初值。
此时x 不能为0值,若输入的 0.00001)。
首选将原方程变形为如下线性形式: y _ A 。
ln ----- =plnx 0 — plnxl A i + y J将A0的初值设为输入的 y 值的最大值加1, A1的初值设为输入的y 值的最小值减0.1。
通过简单的直线拟合即可求出 p 和x0的初值。
第二步:对Logistic 方程四个参数求偏微分,得到y 对给定系数的增量 (△ A1, △ A2, △ x, △ p)的泰勒级数展开式。
1.方程形式:A 1 "0 1泰勒级数展开式为:;:y ;:y ;:y ;:yy = y0(已Ai A0- 、x0一<p)A :A。
::xo :p由此,将曲线回归转化为多元线性回归,通过迭代计算,得到四个参数的变量△A1, △A2, △ x, △ p,逐步修正四参数的值。
多元线性回归与多项式拟合方法相同,具体步骤如附录流程图所示。
每一次迭代可计算出参数变量值,新的参数值为原参数值与变量值的叠加。
第三步:为保证迭代收敛,在计算相关系数时,引入一系数a,初值设为2,将a与参数的变量矩阵相乘,计算相关系数。
a=a/2,循环10次,每次a的值减半。
取循环中得到的相关系数最大的变量矩阵[△A1, △ A2, △ x, △ p]。
第四步:默认总的迭代次数为1000次,或者当相关系数不再减小时,则迭代停止。
返回得到的四参数值。
附录:直线拟合和多项式拟合计算流程。
b=(ME-BN)/(AE-BD), K=(AN-MD)/(AE-BD) 矛盾方程左乘C T ,得到正规方程,及其增 广矩阵高斯消去法得到三角形线性方程组 删除无效点 生成系数矩阵C= 1, X 0 1, X 1 . . . 1, X n 是 V 求C 的转置矩阵C T C T C,得到矩阵 A, B D, E C T Y 得到矩阵 M N。
四参数法拟合范文四参数法(Four Parameter Model)是一种常用的非线性拟合方法,主要用于拟合具有指数增长或指数衰减趋势的数据。
该模型通过引入四个参数来描述数据的曲线特征,即参数a、b、c和d。
四参数法模型的数学表达式如下:y = a + b * exp(c * x) + d其中,y表示因变量的观测值,x表示自变量的观测值,a、b、c、d 为拟合参数,exp为自然指数函数。
四参数法的拟合过程主要包括以下几个步骤:1.数据预处理:根据实际情况对原始数据进行预处理,包括去除异常值、处理缺失值等。
2.参数初始化:对拟合参数进行初始化,常见的初始化方法包括随机初始化、人工调整等。
3. 拟合过程:利用拟合算法对模型进行参数估计。
最常用的算法为最小二乘法(Least Squares Method),通过最小化残差平方和来寻找最优参数。
4.模型评估:根据拟合结果对模型进行评估,主要包括计算残差平方和、确定拟合优度等指标。
若拟合效果不佳,可以调整参数初始化或选择其他拟合方法。
四参数法的优势在于可以较好地描述指数增长或指数衰减趋势,并能够兼顾曲线的灵活性和拟合精度。
然而,该方法也存在一些限制,比如对数据分布的要求较高,对异常值较敏感等。
在实际应用中,四参数法广泛用于拟合生物学、经济学、物理学等领域的数据,比如拟合细胞生长曲线、人口增长曲线、化学反应速率曲线等。
总之,四参数法是一种常用的非线性拟合方法,通过引入四个参数来描述数据的曲线特征。
在拟合过程中,需要进行数据预处理、参数初始化、拟合过程和模型评估等步骤。
该方法具有较好的拟合效果,广泛应用于各个学科领域。