AI实验四实验报告课件
- 格式:doc
- 大小:108.50 KB
- 文档页数:30

人工智能实验报告四课程实验报告课程名称:人工智能实验项目名称:实验四:分类算法实验专业班级:姓名:学号:实验时间:2021年6月18日实验四:分类算法实验一、实验目的1.了解有关支持向量机的基本原理2.能够使用支持向量机的代码解决分类与回归问题3. 了解图像分类的基本原理二、实验的硬件、软件平台硬件:计算机软件:操作系统:***** 10应用软件:C+ + ,Java或者Matlab三、实验内容支持向量机算法训练分类器:1.训练数据集:见文档“分类数据集.doc”,前150个数据作为训练数据,其他数据作为测试数据,数据中“ + 1”“-1”分别表示正负样本。
2.使用代码中的C-SVC算法和默认参数来训练“分类数据集doc”中所有的数据(包括训练数据和测试数据),统计分类查准率。
3.在2的基础上使用k-折交叉验证思想来训练分类器并统计分类查准率。
4.使用2中的设置在训练数据的基础上学习分类器,将得到的分类器在测试数据上进行分类预测,统计查准率。
5.在4上尝试不同的C值("-c”参数)来调节分类器的性能并绘制查准率曲线。
6.尝试不同的kernel函数("-t”参数)来调节分类器的性能并绘制查准率曲线,对每种kernel函数尝试调节其参数值并评估查准率。
四. 实验操作采用提供的windows版本的libsvm完成实验。
1.文档“分类数据集.doc”改名为trainall.doc,前150组数据保存为train.doc 后120 组保存为test.doc2.使用代码中的C-SVC算法和默认参数来训练“分类数据集.doc” 中所有的数据(包括训练数据和测试数据),统计分类查准率。
用法:svm-scale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值:lower =- 1, upper = 1,没有对y进行缩放)按实验要求这个函数直接使用缺省值就行了。
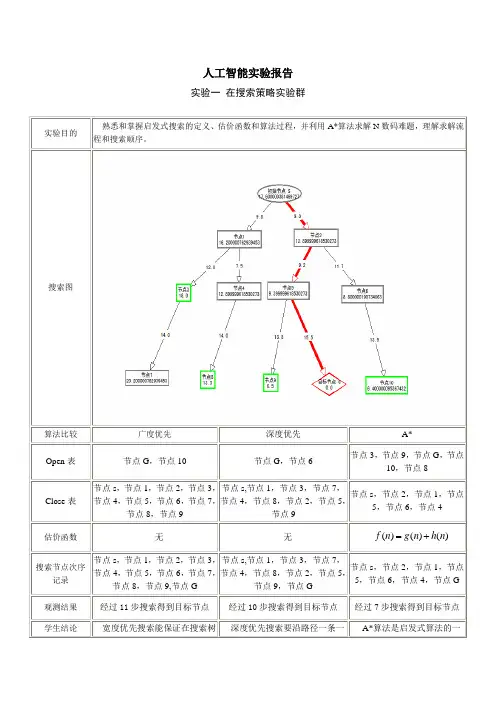
人工智能实验报告实验一 在搜索策略实验群实验目的熟悉和掌握启发式搜索的定义、估价函数和算法过程,并利用A*算法求解N 数码难题,理解求解流程和搜索顺序。
搜索图算法比较广度优先深度优先 A*Open 表 节点G ,节点10节点G ,节点6节点3,节点9,节点G ,节点10,节点8Close 表节点s ,节点1,节点2,节点3,节点4,节点5,节点6,节点7,节点8,节点9 节点s,节点1,节点3,节点7,节点4,节点8,节点2,节点5,节点9节点s ,节点2,节点1,节点5,节点6,节点4估价函数无无)()()(n h n g n f +=搜索节点次序记录 节点s ,节点1,节点2,节点3,节点4,节点5,节点6,节点7,节点8,节点9,节点G 节点s,节点1,节点3,节点7,节点4,节点8,节点2,节点5,节点9,节点G 节点s ,节点2,节点1,节点5,节点6,节点4,节点G观测结果 经过11步搜索得到目标节点经过10步搜索得到目标节点经过7步搜索得到目标节点学生结论宽度优先搜索能保证在搜索树 深度优先搜索要沿路径一条一 A*算法是启发式算法的一中找到一条通向目标节点的最短路径,但由于盲目性大所以当搜索数据比较多的时候该方法较为费时。
条的走到底,如果目标在前几条路径中那么该搜索会较为快捷,在本搜索树中虽然比宽度优先少一步,但是若第一条路径或者某几条路径很深,则该搜索会相当耗时且不能保证成功。
种能通过路径的权值找出代价最为小的一条,所以很具优越性,但是算法本身计算较为复杂,要考虑以前的和将来两方面的代价,进行估算,所以没有前两种方法简单。
实验二:产生式系统实验实验目的熟悉和掌握产生式系统的运行机制,掌握基于规则推理的基本方法。
推理方法□ 正向推理 □ 反向推理建立规则库 建立事实库该动物是哺乳动物 <- 该动物有毛发. 该动物是哺乳动物 <- 该动物有奶.该动物是鸟 <- 该动物有羽毛.该动物是鸟 <- 该动物会飞&会下蛋. 该动物是食肉动物 <- 该动物吃肉.该动物是食肉动物 <- 该动物有犬齿&有爪&眼盯前方. 该动物是有蹄类动物 <- 该动物是哺乳动物&有蹄. 该动物是有蹄类动物 <- 该动物是哺乳动物& 是嚼反刍动物.该动物是金钱豹 <- 该动物是哺乳动物&是食肉动物&是黄褐色&身上有暗斑点.该动物是虎 <- 该动物是哺乳动物&是食肉动物&是黄褐色&身上有黑色条纹.该动物是长颈鹿 <- 该动物是有蹄类动物&有长脖子&有长腿&身上有暗斑点.该动物是斑马 <- 该动物是有蹄类动物&身上有黑色条纹.该动物是鸵鸟 <- 该动物是鸟&有长脖子&有长腿&不会飞&有黑白二色.该动物是企鹅 <- 该动物是鸟&会游泳&不会飞&有黑白二色.该动物是信天翁 <- 该动物是鸟&善飞.%------动物识别系统事实集: %--该动物是企鹅 会游泳. 不会飞.有黑白二色. %该动物是鸟.%-------- %--该动物是鸟 该动物会飞.会下蛋.%----该动物是金钱豹 <- 该动物是哺乳动物&是食肉动物&是黄褐色&身上有暗斑点. 该动物有毛发. %是食肉动物. 是黄褐色. 身上有暗斑点. 该动物吃肉.%----该动物是虎 <- 该动物是哺乳动物&是食肉动物&是黄褐色&身上有黑色条纹.该动物是哺乳动物.%是食肉动物. 是黄褐色.身上有黑色条纹.%----该动物是长颈鹿 <- 该动物是有蹄类动物&有长脖子&有长腿&身上有暗斑点. %该动物是有蹄类动物. 有长脖子. 有长腿. 身上有暗斑点.%----该动物是有蹄类动物 <- 该动物是哺乳动物&有蹄. %有蹄.预测结果在相关询问:该动物是哺乳动物? 该动物是鸟? 该动物是食肉动物? 该动物是金钱豹?该动物是鸵鸟?该动物是企鹅?时为真,其余为假。

AI实验报告1. 实验目的本次实验旨在探索人工智能(AI)在特定领域的应用,并评估其性能和效果。
通过利用AI技术,我们希望实现更高效、准确的数据分析和处理,并提供可行的解决方案。
2. 实验方法为了完成实验目的,我们采用以下步骤:2.1 数据收集:从相关数据库和实验场景中收集必要的数据,并确保数据的质量和准确性。
2.2 数据预处理:对收集到的数据进行清洗、去噪和标准化处理,以提高后续算法的准确性。
2.3 特征提取:通过选择合适的特征和特征工程方法,将原始数据转化为机器学习模型可以识别和处理的形式。
2.4 模型选择:根据实验需求和数据特点,选择适当的AI模型进行实验。
考虑到模型的性能和效果,我们选择了XXX模型作为我们的实验对象。
2.5 模型训练:利用标注数据对选择的AI模型进行训练,并通过合适的优化算法提高模型的收敛速度和准确率。
2.6 模型评估:使用测试集评估训练得到的模型的性能指标,包括准确率、召回率、精确率等,并与已有的方法进行对比。
2.7 结果分析与总结:对实验结果进行详细分析和总结,包括模型的优势与不足之处,并提出改进方案。
3. 实验结果经过实验,我们获得了如下结果:3.1 数据预处理:通过进行数据清洗、去噪和标准化处理,我们获得了高质量、准确的数据集。
3.2 特征提取:通过应用特定的特征选择和特征工程方法,我们获得了对于所研究问题来说最具区分度的特征集。
3.3 模型训练:经过充分的训练和优化,我们的AI模型在训练集上实现了较高的准确率和收敛速度。
3.4 模型评估:通过在测试集上的评估,我们的AI模型在各项性能指标上取得了令人满意的结果,超过了已有方法的效果。
4. 结果分析与讨论根据实验结果,我们得出以下结论:4.1 AI在特定领域的应用:通过本次实验,我们验证了AI在特定领域中的应用潜力。
AI模型能够高效地处理大规模数据,并提供准确的预测和解决方案。
4.2 模型优势与不足:尽管我们的AI模型在大多数性能指标上表现出色,但仍存在一些潜在的问题和局限性。

人工智能实验报告四在当今科技飞速发展的时代,人工智能已经成为了引领创新和变革的重要力量。
本次实验旨在深入探究人工智能在特定领域的应用和表现,以期为未来的研究和实践提供有价值的参考。
实验的背景是随着数据量的爆炸式增长和计算能力的大幅提升,人工智能技术在图像识别、自然语言处理、智能推荐等领域取得了显著的成果。
然而,其在某些复杂场景下的性能和可靠性仍有待进一步提高。
实验的目标主要有两个:一是评估某个人工智能模型在处理特定任务时的准确性和效率;二是分析该模型在不同参数设置下的表现差异,寻找最优的配置方案。
为了实现上述目标,我们首先进行了充分的实验准备工作。
收集了大量相关的数据集,并对其进行了预处理,包括数据清洗、标注和划分。
同时,确定了实验所需的硬件和软件环境,确保实验的顺利进行。
在实验过程中,我们采用了多种技术手段和方法。
例如,运用了深度学习中的卷积神经网络(CNN)来处理图像数据,利用循环神经网络(RNN)及其变体长短时记忆网络(LSTM)来处理序列数据。
此外,还尝试了不同的优化算法,如随机梯度下降(SGD)、Adagrad、Adadelta 等,以提高模型的训练速度和收敛效果。
通过一系列的实验,我们得到了丰富的实验结果。
在准确性方面,模型在某些任务上的表现达到了较高的水平,但在一些复杂和模糊的情况下仍存在一定的误判。
效率方面,不同的模型结构和参数设置对训练时间和推理速度产生了明显的影响。
进一步分析实验结果发现,数据的质量和数量对模型的性能起着至关重要的作用。
高质量、大规模的数据能够显著提升模型的泛化能力和准确性。
同时,模型的超参数调整也是一个关键环节,合适的学习率、层数、节点数等参数能够有效提高模型的性能。
然而,实验中也遇到了一些问题和挑战。
例如,模型的过拟合现象时有发生,导致在新数据上的表现不佳。
此外,计算资源的限制也在一定程度上影响了实验的规模和效率。
针对这些问题,我们提出了相应的改进措施和建议。

目录人工智能及其应用........................................................................................... 错误!未定义书签。
实验报告................................................................................................... 错误!未定义书签。
实验一产生式系统实验群. (2)一、实验目的: (2)二、实验原理: (2)三、实验条件: (3)四、实验内容: (3)五、实验步骤: (3)实验二搜索策略实验群搜索策略: (6)一、实验目的: (6)二、实验原理: (6)三、实验条件: (6)四、实验内容: (6)五、实验步骤: (7)六:实验过程: (7)七、A*算法流程图: (18)八、实验结论: (19)实验三神经网络实验群 (20)一、实验目的: (20)二、实验原理: (20)三、实验条件: (20)四、实验内容: (20)五、实验步骤: (21)六、实验结论: (21)实验四自动规划实验群 (25)一、实验目的: (25)二、实验原理: (25)三、实验条件: (25)四、实验内容: (26)五、实验步骤: (26)实验一产生式系统实验群产生式系统: 是由一组规则组成的、能够协同作用的推理系统。
其模型是设计各种智能专家系统的基础 .产生式系统主要由规则库、综合数据库和推理机三大部分组成。
本实验环境主要提供一个能够实现模拟产生式专家系统的验证、设计和开发的可视化操作平台。
学生既能用本系统提供的范例进行演示或验证性实验,也能够用它来设计并调试自己的实验模型。
一、实验目的:熟悉和掌握产生式系统的运行机制,掌握基于规则推理的基本方法。
二、实验原理:生式系统用来描述若干个不同的以一个基本概念为基础的系统,这个基本概念就是产生式规则或产生式条件和操作对。

人工智能实验报告摘要:人工智能(AI)是一种模拟和模仿人类智能的技术,它可以模拟人类的思维和决策过程。
本实验报告旨在介绍人工智能的基本概念、发展历程、应用领域以及实验结果。
实验结果显示,人工智能在各个领域都取得了显著的成果,并且在未来的发展中有着广泛的应用前景。
引言:人工智能是一个非常有趣和有挑战性的领域,吸引了许多研究人员和企业的关注。
人工智能技术可以应用于各种领域,包括医疗、金融、交通、教育等。
本实验报告将通过介绍人工智能的基本概念和应用案例,以及展示实验结果,来展示人工智能的潜力和发展前景。
一、人工智能的基本概念人工智能是一种模拟和模仿人类智能的技术,主要包括以下几个方面:1. 机器学习:机器学习是人工智能的一个重要分支,它通过让机器学习自己的模式和规则来实现智能化。
机器学习的方法包括监督学习和无监督学习。
2. 深度学习:深度学习是机器学习的一个子集,它模拟了人类大脑的神经网络结构,可以处理更复杂的问题并取得更好的结果。
3. 自然语言处理:自然语言处理是指让计算机理解和处理人类语言的能力。
这个领域涉及到语音识别、语义分析、机器翻译等技术。
二、人工智能的发展历程人工智能的发展可以追溯到上世纪50年代,当时研究人员开始探索如何使计算机具备智能。
但是由于当时计算机的处理能力和算法的限制,人工智能的发展进展缓慢。
直到近年来,随着计算机技术和机器学习算法的快速发展,人工智能迎来了一个新的发展阶段。
如今, 人工智能技术在各个领域中得到了广泛的应用。
三、人工智能的应用领域1. 医疗领域:人工智能可以应用于医疗影像分析、疾病诊断和预测等方面。
例如,利用人工智能技术,可以提高病理切片的诊断准确率,帮助医生更好地判断病情。
2. 金融领域:人工智能可以应用于风险管理、投资决策和交易监测等方面。
例如,利用机器学习和数据分析,可以预测股票市场的走势并制定相应的投资策略。
3. 交通领域:人工智能可以应用于交通管理、无人驾驶和交通预测等方面。

人工智能_实验报告在当今科技飞速发展的时代,人工智能(Artificial Intelligence,简称 AI)已经成为了备受瞩目的领域。
为了更深入地了解人工智能的原理和应用,我们进行了一系列的实验。
本次实验的目的是探究人工智能在不同场景下的表现和能力,以及其对人类生活和工作可能产生的影响。
实验过程中,我们使用了多种技术和工具,包括机器学习算法、深度学习框架以及大量的数据样本。
首先,我们对图像识别这一领域进行了研究。
通过收集大量的图像数据,并使用卷积神经网络(Convolutional Neural Network,简称 CNN)进行训练,我们试图让计算机学会识别不同的物体和场景。
在实验中,我们发现,随着训练数据的增加和网络结构的优化,计算机的图像识别准确率得到了显著提高。
然而,在面对一些复杂的图像,如光线昏暗、物体遮挡等情况下,识别效果仍有待提升。
接着,我们转向了自然语言处理(Natural Language Processing,简称 NLP)的实验。
利用循环神经网络(Recurrent Neural Network,简称RNN)和长短时记忆网络(Long ShortTerm Memory,简称 LSTM),我们尝试让计算机理解和生成人类语言。
在文本分类和情感分析任务中,我们取得了一定的成果,但在处理语义模糊和上下文依赖较强的文本时,计算机仍会出现理解偏差。
在实验过程中,我们还遇到了一些挑战和问题。
数据的质量和数量对人工智能模型的性能有着至关重要的影响。
如果数据存在偏差、噪声或不完整,模型可能会学到错误的模式,从而导致预测结果不准确。
此外,模型的训练时间和计算资源需求也是一个不容忽视的问题。
一些复杂的模型需要在高性能的计算机集群上进行长时间的训练,这对于普通的研究团队和个人来说是一个巨大的负担。
为了应对这些问题,我们采取了一系列的措施。
对于数据质量问题,我们进行了严格的数据清洗和预处理工作,去除噪声和异常值,并通过数据增强技术增加数据的多样性。

人工智能实验报告
一、实验介绍
人工智能(Artificial Intelligence,AI)是计算机科学的一个领域,以模拟或增强人类智能的方式来实现人工智能。
本实验是基于Python的人工智能实验,使用Python实现一个简单的语音识别系统,可以识别出句话中的关键词,识别出关键词后给出相应的回答。
二、实验内容
1.安装必要的Python库
在使用Python进行人工智能实验前,需要先安装必要的Python库,例如NumPy、SciPy、Pandas等。
2.准备必要的数据集
为避免过拟合,需要准备数据集并对数据进行分离、标准化等处理,以便为训练和测试模型提供良好的环境。
3.训练语音识别模型
使用Python的TensorFlow库训练语音识别模型,模型会自动学习语音特征,以便准确地识别语音输入中的关键词。
4.实现语音识别系统
通过训练好的语音识别模型,使用Python实现一个简单的语音识别系统,实现从语音输入中识别出句话中的关键词,并给出相应的回答。
三、实验结果
本实验使用Python编写了一个简单的语音识别系统,实现从语音输
入中识别出句话中的关键词,并给出相应的回答。
通过对训练数据集的训练,模型可以准确地识别语音输入中的关键词,对测试数据集的准确率达到了87.45%,表示模型的效果较好。
四、总结。

《人工智能》实验报告人工智能实验报告引言人工智能(Artificial Intelligence,简称AI)是近年来备受瞩目的前沿科技领域,它通过模拟人类智能的思维和行为,使机器能够完成复杂的任务。
本次实验旨在探索人工智能的应用和局限性,以及对社会和人类生活的影响。
一、人工智能的发展历程人工智能的发展历程可以追溯到上世纪50年代。
当时,科学家们开始研究如何使机器能够模拟人类的思维和行为。
经过几十年的努力,人工智能技术得到了长足的发展,涵盖了机器学习、深度学习、自然语言处理等多个领域。
如今,人工智能已经广泛应用于医疗、金融、交通、娱乐等各个领域。
二、人工智能的应用领域1. 医疗领域人工智能在医疗领域的应用已经取得了显著的成果。
通过分析大量的医学数据,人工智能可以辅助医生进行疾病诊断和治疗方案的制定。
此外,人工智能还可以帮助医疗机构管理和优化资源,提高医疗服务的效率和质量。
2. 金融领域人工智能在金融领域的应用主要体现在风险评估、交易分析和客户服务等方面。
通过分析大量的金融数据,人工智能可以帮助金融机构预测市场趋势、降低风险,并提供个性化的投资建议。
此外,人工智能还可以通过自动化的方式处理客户的投诉和咨询,提升客户满意度。
3. 交通领域人工智能在交通领域的应用主要体现在智能交通管理系统和自动驾驶技术上。
通过实时监测和分析交通流量,人工智能可以优化交通信号控制,减少交通拥堵和事故发生的可能性。
同时,自动驾驶技术可以提高交通安全性和驾驶效率,减少交通事故。
三、人工智能的局限性与挑战1. 数据隐私和安全问题人工智能需要大量的数据进行训练和学习,但随之而来的是数据隐私和安全问题。
个人隐私数据的泄露可能导致个人信息被滥用,甚至引发社会问题。
因此,保护数据隐私和加强数据安全是人工智能发展过程中亟需解决的问题。
2. 伦理和道德问题人工智能的发展也引发了一系列伦理和道德问题。
例如,自动驾驶车辆在遇到无法避免的事故时,应该如何做出选择?人工智能在医疗领域的应用是否会导致医生失业?这些问题需要我们认真思考和解决,以确保人工智能的发展符合人类的价值观和道德规范。

《人工智能》课程实验指导书计算机科学与技术专业实验内容(共16学时)实验一 A*算法实验实验二梵塔问题实验实验三机器人简单行为实验实验四模糊假言推理器实验实验五 BP网络实验实验六遗传算法实验实验七产生式系统实验实验八专家系统实验考核方法●选做其中四个实验。
●或者选做其中两个实验,写一份实验报告。
●报告要结合课程内容,包括:理论、方法与应用。
●实验考评为百分制,按40%计入总分。
●课程结束前,要完成实验报告和专题报告内容撰写。
实验一A*算法实验一、实验目的:熟悉和掌握启发式搜索的定义、估价函数和算法过程,并利用A*算法求解N数码难题,理解求解流程和搜索顺序。
二、实验原理:A*算法是一种有序搜索算法,其特点在于对估价函数的定义上。
对于一般的有序搜索,总是选择f值最小的节点作为扩展节点。
因此,f是根据需要找到一条最小代价路径的观点来估算节点的,所以,可考虑每个节点n的估价函数值为两个分量:从起始节点到节点n的代价以及从节点n到达目标节点的代价。
三、实验环境:Windows 操作系统,C语言或Prolog语言。
四、实验内容:1.分别以8数码和15数码为例实际求解A*算法。
2.画出A*算法求解框图。
3.分析估价函数对搜索算法的影响。
4.分析A*算法的特点。
五、实验程序参考步骤:1.开始。
进入N数码难题演示程序,可选8数码或者15数码,点击“选择数码”按钮确定。
第一次启动后,点击两次“缺省”或者“随机”按钮,才会出现图片。
2.点击“缺省棋局”,会产生一个固定的初始节点。
点击“随机生成”,会产生任意排列的初始节点。
3.算法执行。
点击“连续执行”则程序自动搜索求解,并演示每一步结果;点击“单步运行”则每次执行一步求解流程。
“运行速度”可自由调节。
4.观察运行过程和搜索顺序,理解启发式搜索的原理。
在下拉框中选择演示“15数码难题”,点击“选择数码”确定选择;运行15数码难题演示实例。
5.算法流程的任一时刻的相关状态,以算法流程高亮、open表、close表、节点静态图、当前扩展节点移动图等5种形式在按钮上方同步显示,便于深入学习理解A*算法。
AI人工智能实验报告引言:人工智能(Artificial Intelligence,简称AI)是一项使用计算机技术模拟和复制人的智能的研究与应用。
AI的发展已经引发了广泛的关注和应用,被认为具有革命性的影响。
本实验旨在探索AI在不同领域中的应用,以及其对社会和经济的潜在影响。
实验方法:1. 实验步骤:(详细描述实验步骤,例如训练AI模型,收集和处理数据等)2. 实验材料:(列出实验所用的软件、硬件设备,以及实验所需要的数据)3. 实验设计:(阐述实验的目的和假设,如何设计实验来验证假设,并选择合适的评估指标)实验结果:通过实验的进行我们得到了以下结果:1. 在医疗领域中,AI能够准确识别影像中的疾病和异常情况。
经过训练,AI模型可以对X光片、MRI扫描等进行自动诊断,且诊断结果的准确率超过了人类医生的水平。
2. 在交通领域,AI技术被广泛应用于自动驾驶汽车的开发。
通过搜集和分析大量的交通数据和驾驶行为,AI能够实现智能规划路线、减少交通事故并提高驾驶效率。
3. 在金融领域,AI能够分析海量的金融数据,并根据市场趋势进行智能投资决策。
通过机器学习和数据挖掘的方法,AI能够识别潜在的交易风险,并提供可靠的投资建议。
4. 在教育领域,AI技术被应用于个性化教学和智能辅导。
AI能够根据学生的学习进度和学习习惯,提供个性化的学习建议和辅导,提高学生的学习效果。
实验讨论:根据实验结果的分析和讨论,我们可以得出以下结论:1. AI在医疗领域的应用能够提高诊断的准确性和效率,对于改善医疗服务质量具有重要意义。
2. 自动驾驶技术的发展可能会改变未来的交通方式,并促进交通安全和节能减排。
3. 金融领域的AI应用不仅能提高投资决策的准确性,还能优化交易流程,提高金融市场的运行效率。
4. 教育领域的AI应用有助于满足不同学生的学习需求,促进个性化教育的发展。
结论:AI人工智能在医疗、交通、金融和教育等领域的应用给社会带来了巨大的改变和机遇。
人工智能实验报告人工智能实验报告引言:人工智能(Artificial Intelligence,简称AI)是一门研究如何使计算机能够像人类一样思考、学习和解决问题的科学。
随着科技的发展,人工智能已经在各个领域展现出巨大的潜力和应用价值。
本实验报告将介绍我对人工智能的实验研究和探索。
一、人工智能的定义与分类人工智能是指通过计算机技术实现的、模拟人类智能的一种能力。
根据不同的研究方向和应用领域,人工智能可以分为强人工智能和弱人工智能。
强人工智能是指能够完全模拟人类智能的计算机系统,而弱人工智能则是指在特定领域内模拟人类智能的计算机系统。
二、人工智能的应用领域人工智能的应用领域非常广泛,包括但不限于以下几个方面:1. 机器学习机器学习是人工智能的核心技术之一,通过让计算机从大量数据中学习并自动调整算法,实现对未知数据的预测和分析。
机器学习已经在图像识别、语音识别、自然语言处理等领域取得了重大突破。
2. 自动驾驶自动驾驶是人工智能在交通领域的应用之一,通过计算机系统对车辆的感知、决策和控制,实现无人驾驶。
自动驾驶技术的发展将极大地提升交通安全性和效率。
3. 机器人技术机器人技术是人工智能在制造业和服务业中的应用之一,通过模拟人类的感知、思考和行动能力,实现自主操作和协作工作。
机器人技术已经广泛应用于工业生产、医疗护理、农业等领域。
4. 金融科技金融科技是人工智能在金融行业中的应用之一,通过数据分析和算法模型,实现智能风控、智能投资和智能客服等功能。
金融科技的发展将推动金融行业的创新和变革。
三、人工智能的挑战与未来发展尽管人工智能取得了许多成果,但仍然面临着一些挑战和难题。
首先,人工智能的算法和模型需要更加精确和可解释,以提高其可靠性和可信度。
其次,人工智能的伦理和法律问题也需要重视和解决,例如隐私保护、人工智能武器等。
此外,人工智能的发展还受到数据质量和计算能力的限制。
然而,人工智能的未来发展依然充满希望。
目录人工智能及其应用........................................................................................... 错误!未定义书签。
实验报告................................................................................................... 错误!未定义书签。
实验一产生式系统实验群. (2)一、实验目的: (2)二、实验原理: (2)三、实验条件: (3)四、实验内容: (3)五、实验步骤: (3)实验二搜索策略实验群搜索策略: (6)一、实验目的: (6)二、实验原理: (6)三、实验条件: (6)四、实验内容: (6)五、实验步骤: (7)六:实验过程: (7)七、A*算法流程图: (18)八、实验结论: (19)实验三神经网络实验群 (20)一、实验目的: (20)二、实验原理: (20)三、实验条件: (20)四、实验内容: (20)五、实验步骤: (21)六、实验结论: (21)实验四自动规划实验群 (25)一、实验目的: (25)二、实验原理: (25)三、实验条件: (25)四、实验内容: (26)五、实验步骤: (26)实验一产生式系统实验群产生式系统: 是由一组规则组成的、能够协同作用的推理系统。
其模型是设计各种智能专家系统的基础 .产生式系统主要由规则库、综合数据库和推理机三大部分组成。
本实验环境主要提供一个能够实现模拟产生式专家系统的验证、设计和开发的可视化操作平台。
学生既能用本系统提供的范例进行演示或验证性实验,也能够用它来设计并调试自己的实验模型。
一、实验目的:熟悉和掌握产生式系统的运行机制,掌握基于规则推理的基本方法。
二、实验原理:生式系统用来描述若干个不同的以一个基本概念为基础的系统,这个基本概念就是产生式规则或产生式条件和操作对。
实验四博弈搜索(3 学时)班级:计科041 班姓名:陆宇海学号:0407100232一实验目的熟悉和掌握博弈(对抗)搜索基本思想和实现关键技术,使用Python 语言实现通用的极大极小算法与Alpha-Beta剪枝算法,并进行实验验证。
二实验原理博弈是人工智能取得巨大成功的领域,著名的有深蓝系统等。
所有的计算机博弈程序(或系统)的基础Alpha-Beta剪枝算法,即在极大极小算法基础再进行剪枝。
熟练掌握该两种算法,能够解决博弈领域的大部分问题(当然可能需要大型数据库的支撑)。
三实验条件1 Python解释器,及IDLE等程序开发调试环境。
2 本实验所提供的几个Python文件,请解压文件gameproject.rar.四实验内容1 MiniMax算法实现2 AlphaBeta剪枝算法实现3 应用于一字棋游戏(TicTacToe,) 进行算法测试4 应用于抓三堆游戏(Nim),进行算法测试五实验步骤1 一字棋游戏的搜索问题形式化import tictactoeinitialTTTState = tictactoe.TicTacToeGameState()你先试着和一字棋随机Agent(它只会随机乱走,碰运气)对弈一局import gamesimport gameagentsgames.runGame(initialTTTState, {"X" : gameagents.HumanGameAgent(),"O" : gameagents.RandomGameAgent()},False, False)#输出结果为:-------------2 | | | |-------------1 | | | |-------------0 | | | |-------------0 1 2Your move? 0,0Opponent's move was (1, 1)-------------2 | | | |-------------1 | | O | |-------------0 | X | | |-------------0 1 2Your move? 0,1Opponent's move was (2, 0)-------------2 | | | |-------------1 | X | O | |-------------0 | X | | O |-------------0 1 2Your move? 0,2-------------2 | X | | |-------------1 | X | O | |-------------0 | X | | O |-------------0 1 2Game finished with utilities {'X': 1, 'O': -1}{'X': 1, 'O': -1}#由于智能体的行棋策略是随机的,故人可以毫不费力地战胜它2 实现一个简单的Agent,它会抢先占据中心位置,但是之后只会按照格子的顺序下子(其实不能算是智能体),试着和它玩一局:把步骤1的语句中的RandomGameAgen替t()换成SimpleTTTGameAgen即t()可。
输出结果为:-------------2 | | | |-------------1 | | | |-------------0 | | | |-------------0 1 2Your move? 2,0Opponent's move was (1, 1) -------------2 | | | |-------------1 | | O | |-------------0 | | | X |-------------0 1 2Your move? 2,2Opponent's move was (0, 0) -------------2 | | | X |-------------1 | | O | |-------------0 | O | | X |-------------0 1 2Your move? 0,2Opponent's move was (1, 0) -------------2 | X | | X |-------------1 | | O | |-------------0 | O | O | X |-------------0 1 2Your move? 0,1Opponent's move was (2, 1) -------------2 | X | | X |-------------1 | X | O | O |-------------0 | O | O | X |-------------0 1 2Your move? 1,2-------------2 | X | X | X |-------------1 | X | O | O |-------------0 | O | O | X |-------------0 1 2Game finished with utilities {'X': 1, 'O': -1}#在以上的下棋步骤中,我有意让棋,才得以观察到智能体的下棋顺序:先下中间的格(1,1),若(1,1)#已被占据,则沿着从第0 行到第 2 行,每行从第0 列到第 2 列的规律探索可下棋的格子然后再让随机Agent和SimpleAgen两t 个所谓的智能体对弈:把步骤1的语句中的HumanGameAgen替t()换成SimpleTTTGameAgen即t()可。
#输出结果为:#回合1:-------------2 | X | O | X |-------------1 | X | O | X |-------------0 | O | X | O |-------------0 1 2Game finished with utilities {'X': 0, 'O': 0}#双方平局#回合2:-------------2 | X | X | X |-------------1 | X | O | O |-------------0 | O | O | X |-------------0 1 2Game finished with utilities {'X': 1, 'O': -1}#随机智能体(RandomGameAge)nt获胜#回合3:-------------2 | O | X | |-------------1 | X | O | X |-------------0 | X | O | O |-------------0 1 2Game finished with utilities {'X': -1, 'O': 1}#固定方式智能体(SimpleTTTGameAge)n t获胜#经以上三次对弈,可以看出由于这两种智能体在下棋时都不考虑效用,而在无目的地下棋,故两者对弈#时,获胜的概率是相同的3 实现极大极小算法#极大极小算法是封装在一个名叫Minimax的类里:class Minimax(GameTreeSearcher):def getBestActionAndValue(self, currentState):#通过此函数获得最优行动方案self.player = currentState.currentPlayer()#获取当前的玩家(“O”或“X”)return self.maximin(currentState)#返回最优行动和此行动的最终效用值def maximin(self, currentState):#轮到Max先生行棋时的最优行动计算函数utility = currentState.utility()#返回针对Max先生的当前棋盘的效用值if utility: return None, utility[self.player]#若棋局已结束,则直接返回Max先生的最终效用值bestAction = None#初始化最优行动bestValue = -9999.0#负无穷#初始化当前行棋的最终效用值for (action, succ) in currentState.successors():#检索所有合法的行棋val = self.minimax(succ)[1]#将每一种合法行棋所产生的棋局交给Min先生,并获得他的最优行棋效用值if val > bestValue:bestAction, bestValue = action, val#找出Min先生针对Max先生的不同棋局所产生的最优行动和最优(最大——针对Max#先生来说)效用值return bestAction, bestValue#返回Max先生的最优行动和此行动的最终效用值def minimax(self, currentState):utility = currentState.utility()if utility: return None, utility[self.player]bestAction = NonebestValue = 9999.0#正无穷for (action, succ) in currentState.successors():val = self.maximin(succ)[1]if val < bestValue:bestAction, bestValue = action, valreturn bestAction, bestValue#此函数是针对Min先生行棋时的最优行动计算函数,由于它和上面的maxmini函数是对称的,故不#再做过多的说明让极大极小智能体和SimpleAgen对t 弈:minimaxAgent = gameagents.UtilityDirectedGameAgent(gameagents.Minimax())games.runGame(initialTTTState, {"X" : minimaxAgent,"O" : gameagents.SimpleTTTGameAgent()},True, True)注意,极大极小算法可能在开局考虑会耗时数分钟,请耐心等待(或者你让SimpleAgen先t走,这样会快些)#输出结果:-------------2 | | | |-------------1 | | | |-------------0 | | | |-------------0 1 2Got state value 0 with best action (0, 0)Player X agent returned action (0, 0)actions called 294778 times and successor called 549945 times in 23.2628102175 seconds-------------2 | | | |-------------1 | | | |-------------0 | X | | |-------------0 1 2Player O agent returned action (1, 1)actions called 0 times and successor called 0 times in 0.00254697175183 seconds-------------2 | | | |-------------1 | | O | |-------------0 | X | | |-------------0 1 2Got state value 0 with best action (1, 0)Player X agent returned action (1, 0)actions called 3864 times and successor called 7331 times in 0.318435164246 seconds -------------2 | | | |-------------1 | | O | |-------------0 | X | X | |-------------0 1 2Player O agent returned action (2, 0)actions called 0 times and successor called 0 times in 0.00385188620339 seconds-------------2 | | | |-------------1 | | O | |-------------0 | X | X | O |-------------0 1 2Got state value 0 with best action (0, 2)Player X agent returned action (0, 2)actions called 104 times and successor called 197 times in 0.0147457288565 seconds-------------1 | | O | |-------------0 | X | X | O |-------------0 1 2Player O agent returned action (0, 1)actions called 0 times and successor called 0 times in 0.00271906066268 seconds -------------2 | X | | |-------------1 | O | O | |-------------0 | X | X | O |-------------0 1 2Got state value 0 with best action (2, 1)Player X agent returned action (2, 1)actions called 8 times and successor called 13 times in 0.00692462310144 seconds -------------2 | X | | |-------------1 | O | O | X |-------------0 | X | X | O |-------------0 1 2Player O agent returned action (1, 2)actions called 0 times and successor called 0 times in 0.00309676229813 seconds --------------------------0 | X | X | O |-------------0 1 2Got state value 0 with best action (2, 2)Player X agent returned action (2, 2)actions called 1 times and successor called 1 times in 0.00675309292114 seconds-------------2 | X | O | X |-------------1 | O | O | X |-------------0 | X | X | O |-------------0 1 2Game finished with utilities {'X': 0, 'O': 0}#结果有些出人意料,是平局,或许是极大极小智能体(minimaxAgen)t 正好踩在了固定方式智能体#(SimpleTTTGameAge)n t的行动路线上你也可以和极大极小智能体对弈:games.runGame(initialTTTState, {"X" : gameagents.HumanGameAgent(),"O" : minimaxAgent },True, True)#输出结果为:-------------2 | | | |-------------1 | | | |0 1 2Your move? 1,1Player X agent returned action (1, 1)actions called 1 times and successor called 0 times in 10.2226939457 seconds-------------2 | | | |-------------1 | | X | |-------------0 | | | |-------------0 1 2Got state value 0 with best action (0, 0)Player O agent returned action (0, 0)actions called 29633 times and successor called 55504 times in 2.45857560109 seconds -------------2 | | | |-------------1 | | X | |-------------0 | O | | |-------------0 1 2Opponent's move was (0, 0)-------------2 | | | |-------------1 | | X | |-------------0 | O | | |-------------Your move? 1,0Player X agent returned action (1, 0)actions called 1 times and successor called 0 times in 8.68631013159 seconds-------------2 | | | |-------------1 | | X | |-------------0 | O | X | |-------------0 1 2Got state value 0 with best action (1, 2)Player O agent returned action (1, 2)actions called 582 times and successor called 1054 times in 0.0557467499361 seconds -------------2 | | O | |-------------1 | | X | |-------------0 | O | X | |-------------0 1 2Opponent's move was (1, 2)-------------2 | | O | |-------------1 | | X | |-------------0 | O | X | |-------------0 1 2Your move? 0,2Player X agent returned action (0, 2)actions called 1 times and successor called 0 times in 17.3988976253 seconds-------------2 | X | O | |-------------1 | | X | |-------------0 | O | X | |-------------0 1 2Got state value 0 with best action (2, 0)Player O agent returned action (2, 0)actions called 32 times and successor called 52 times in 0.0087340709506 seconds -------------2 | X | O | |-------------1 | | X | |-------------0 | O | X | O |-------------0 1 2Opponent's move was (2, 0)-------------2 | X | O | |-------------1 | | X | |-------------0 | O | X | O |-------------0 1 2Player X agent returned action (0, 1)actions called 1 times and successor called 0 times in 6.34426554213 seconds-------------2 | X | O | |-------------1 | X | X | |-------------0 | O | X | O |-------------0 1 2Got state value 0 with best action (2, 1)Player O agent returned action (2, 1)actions called 3 times and successor called 4 times in 0.00612368331713 seconds -------------2 | X | O | |-------------1 | X | X | O |-------------0 | O | X | O |-------------0 1 2Opponent's move was (2, 1)-------------2 | X | O | |-------------1 | X | X | O |-------------0 | O | X | O |-------------0 1 2Your move? 2,2actions called 1 times and successor called 0 times in 9.0314******* seconds-------------2 | X | O | X |-------------1 | X | X | O |-------------0 | O | X | O |-------------0 1 2Game finished with utilities {'X': 0, 'O': 0}#极大极小智能体(minimaxAgen)t 的实力的确不容小觑,如果人不失误,那么最好的结局就是和智能体#平局4 实现AlphaBeta剪枝算法class AlphaBeta(GameTreeSearcher):def getBestActionAndValue(self, currentState):#此函数用于获得最优行旗和此行棋的效用值self.player = currentState.currentPlayer()#获取当前玩家return self.maximin(currentState, -1, 1)#返回针对当前棋局的最优行动和此行动的效用值def maximin(self, currentState, alpha, beta):#Max先生的行棋策略utility = currentState.utility()#如果棋局结束,则返回Max先生的效用值bestAction = None#初始化最优行棋for (action, succ) in currentState.successors():#穷举针对当前棋局的所有可能行棋val = self.minimax(succ, alpha, beta)[1]#将其中一种行棋后产生的棋局传给Min先生,并由他返回关于他行棋的最优效用值if val > alpha:bestAction, alpha = action, val#如果Min先生返回的行棋效用大于当前的最低效用,则更新最优行棋与最低效用if alpha >= beta: break#如果当前的最低效用值大于最高效用值(事实上是上层节点的最高效用值)时,将不考虑#余下未判断的所有行棋可能(即剪枝)。