(优选)结构体与链表
- 格式:ppt
- 大小:521.00 KB
- 文档页数:26

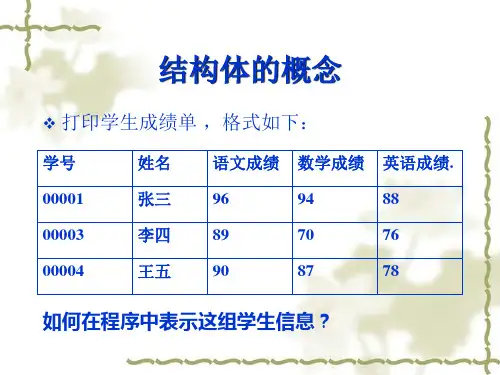
C语⾔结构体使⽤之链表⽬录⼀、结构体的概念⼆、结构体的⽤法三、结构体数组和指针四、结构体指针五、包含结构体的结构体六、链表七、静态链表⼋、动态链表⼀、结构体的概念⽐如说学⽣的信息,包含了学⽣名称、学号、性别、年龄等信息,这些参数可能有些是数组型、字符型、整型、甚⾄是结构体类型的数据。
虽然这些都是不同类型的数据,但是这些都是⽤来表达学⽣信息的数据。
⼆、结构体的⽤法1、struct 结构体名称访问⽅法:结构体变量名.成员{undefined成员1;成员2;};2、 typedef struct{undefined成员1;成员2;}结构体名称;在中⼤型产品中⼀般⽤第2种,因为结构体多了以后通过别名的⽅式定义结构体变量能够⼤⼤提⾼代码可读性。
三、结构体数组和指针1、直接⽤struct声明⼀个结构体,然后在定义结构体数组,struct 结构体名称数组名[数组⼤⼩]2、⽤typedef struct声明⼀个结构体,并且为结构体重命名,通过重命名的⽅法定义结构体数组。
结构体重命名数组名[数组⼤⼩]四、结构体指针只要是存储在内存中的变量或者数组或函数编译器都会为他们分配⼀个地址,我们可以通过指针变量指向这个地址来访问地址⾥⾯的数,只要把指针变量定义成同数据类型就可以指向了,⽐如说要指向字符型变量就定义字符型指针变量,所以我们也可以定义结构体类型指针来指向它。
1、直接⽤struct声明⼀个结构体,然后在定义结构体指针,struct 结构体名称 *结构体指针变量名2、⽤typedef struct声明⼀个结构体,并且为结构体重命名,通过别名的⽅式定义结构体指针。
结构体别名 *结构体指针变量名结构体指针访问成员⽅法结构体指针变量名->成员名五、包含结构体的结构体学⽣信息包含姓名,学号,性别,出⼊⽇期等数据,⽽出⽣⽇期⼜包含年⽉⽇这3个成员,所以把出⽣⽇期单独声明⼀个结构体,那么学⽣这个结构体就包含出⽣⽇期这个结构体,这种就是包含结构体的结构体。



【6.1简略版】在main函数中输入一个学生的学号、姓名、性别、出生日期和3门课程的成绩,在另一函数print中输出这个学生的信息,采用结构体变函数参数。
void print( student );void main ( ){student John;// 定义一个结构体变量cin>> John.ID>> >> John.gender;cin>> John.birthday.year>> John.score[2];print(John);// 调用函数完成输出}void print( student s)// 输出参数s成员的值{cout<<"学号: " << setw(5) << s.ID<< endl;cout<< setw(5) << s.birthday.month<< endl;}使用结构体变量作函数参数效率较低,why? 可采用指向结构体变量的指针或引用作参数,例如:student *ps;student John;并且如下赋值:ps= &John;则:<=> ps->name <=> (*ps).name思考:如何将程序【例6.1】中的函数print改为传指针。
【例6.2】假设一个班级有5个学生,从键盘输入5个学生的学号、姓名、性别、出生日期和三门功课的成绩,编程输出个人平均分小于全班总均分的那些学生的信息。
struct date{int year, month, day;};struct student{int ID;char name[20];char gender;date birthday;double score[3];};void input( student*, int);double average( student *, int n); //求总的平均分void print( student*,int);const int studentNumber=5;int main ( ){student stud[5];input(stud,studentNumber);print(stud,studentNumber);return 0;}void input( student *ps, int n)// 输入函数{cout<<"请输入如下学生信息" << endl;for(int i=0;i<n; i++){cin>> ps->ID;cin>> ps->name;cin>> ps->gender;cin>> ps->birthday.year>> ps->birthday.month>> ps->birthday.day;cin>> ps->score[0] >> ps->score[1]>> ps->score[2];ps++;}}void print( student *ps, int n){ student *pStart;double averAll, averPerson;averAll=average(ps,n);cout<< "总均分: "<< averAll<<endl;for(pStart=ps;pStart<ps+n;pStart++){averPerson= (pStart->score[0]+pStart->score[1]+pStart->score[2])/3 ;if( averPerson< averAll){cout<<"\n个人均分:"<< averPerson<<endl;cout<<"学号: " << setw(5) << pStart->ID;cout<<“出生年: " << pStart->birthday.year;cout<<" 成绩: " << setw(4) << pStart->score[0];}}}double average( student stud[], int n) // 求总均分{double aver=0;for(int i=0; i<n; i++)for(int j=0;j<3;j++)aver += stud[i].score[j];aver /= n*3;return aver;}NODE *create( ) // 创建无序链表{ NODE *p1, *p2, *head;int a;cout<< "Creating a list...\n";p2 = head = initlist( );cout<< "Please input a number(if(-1) stop): ";cin>> a; // 输入第1个数据while( a != -1 ) // 循环输入数据,建立链表{ p1 = (NODE *) malloc(sizeof(NODE));p1->data = a;p2->next = p1;p2 = p1;cout<< "Please input a number(if(-1) stop): ";cin>> a; // 输入下一个数据}p2->next=NULL;return(head); // 返回创建链表的首指针}// 输出链表各结点值,也称为对链表的遍历void print( NODE *head ){NODE *p;让p指向第一个数据结点p=head->next; //if( p!=NULL ){cout<< "Output list: ";while( p!=NULL ){cout<< setw(5) << p->data;p=p->next;}cout<< "\n";}}// 查询结点数据为x的结点,返回指向该结点指针NODE * search( NODE *head, int x ){ NODE *p;p=head->next;while( p!=NULL ){if(p->data == x)return p; // 返回该结点指针p = p->next;}return NULL; // 找不到返回空指针}// 删除链表中值为num的结点,返回值: 链表的首指针NODE * delete_one_node( NODE *head, int num ) {NODE *p, *temp;p=head;while(p->next !=NULL && p->next->data != num) p=p->next;temp=p->next;if(p->next!=NULL){p->next=temp->next;free(temp);cout<< "Delete successfully";}else cout<< "Not found!";return head;}// 释放链表void free_list( NODE *head ) {NODE *p;while(head){p=head;head=head->next;free(p);}}// 插入结点,将s指向的结点插入链表,结果链表保持有序NODE * insert(NODE*head, NODE *s){NODE *p;p=head;while(p->next!=NULL && p->next->data < s->data) p=p->next;s->next=p->next;p->next=s;return head;}// 创建有序链表。

408数据结构算法题的结构体定义408数据结构算法题的结构体定义【导言】在考研中,数据结构与算法是一个重要的科目。
其中,408考试是中国计算机科学与技术学科专业硕士研究生全国联考的一部分,因其考察的题型广泛而知名。
在408数据结构算法题中,掌握合适的结构体定义是解题的基础。
本文将综合讨论和总结408算法题中常见的结构体定义,以助于考生全面、深入地理解问题,为未来的408算法题做好准备。
【1. 结构体的定义与应用】结构体是C语言中一种自定义的数据类型,将不同类型的数据成员组合在一起,形成一个新的数据类型。
在数据结构与算法题中,结构体定义常用于构建复杂的数据结构,如链表、树等。
在408算法题中,结构体的定义要灵活、具体,并能满足问题的需求。
【2. 链表的结构体定义】链表是一种基本的数据结构,由节点组成,每个节点包含一个数据元素和指向下一个节点的指针。
在408算法题中,常见的链表结构体定义如下:```ctypedef struct ListNode {int val; // 数据元素struct ListNode* next; // 指向下一个节点的指针} ListNode;```上述代码中,定义了一个名为ListNode的结构体,包含一个整型数据元素val和一个指向下一个节点的指针next。
该结构体可以用于构建单链表,每个节点存储了一个整数值和指向下一个节点的指针。
【3. 树的结构体定义】树是一种重要的数据结构,由节点组成,每个节点可以有零个或多个子节点。
在408算法题中,常见的树结构体定义如下:```ctypedef struct TreeNode {int val; // 数据元素struct TreeNode* left; // 左子节点struct TreeNode* right; // 右子节点} TreeNode;```上述代码中,定义了一个名为TreeNode的结构体,包含一个整型数据元素val和左右子节点的指针left和right。



数据结构—链表链表⽬录⼀、概述1.链表是什么链表数⼀种线性数据结构。
它是动态地进⾏储存分配的⼀种结构。
什么是线性结构,什么是⾮线性结构?线性结构是⼀个有序数据元素的集合。
常⽤的线性结构有:线性表,栈,队列,双队列,数组,串。
⾮线性结构,是⼀个结点元素可能有多个直接前趋和多个直接后继。
常见的⾮线性结构有:⼆维数组,多维数组,⼴义表,树(⼆叉树等)。
2.链表的基本结构链表由⼀系列节点组成的集合,节点(Node)由数据域(date)和指针域(next)组成。
date负责储存数据,next储存其直接后续的地址3.链表的分类单链表(特点:连接⽅向都是单向的,对链表的访问要通过顺序读取从头部开始)双链表循环链表单向循环链表双向循环链表4.链表和数组的⽐较数组:优点:查询快(地址是连续的)缺点:1.增删慢,消耗CPU内存链表就是⼀种可以⽤多少空间就申请多少空间,并且提⾼增删速度的线性数据结构,但是它地址不是连续的查询慢。
⼆、单链表[1. 认识单链表](#1. 认识单链表)1. 认识单链表(1)头结点:第0 个节点(虚拟出来的)称为头结点(head),它没有数据,存放着第⼀个节点的⾸地址(2)⾸节点:第⼀个节点称为⾸节点,它存放着第⼀个有效的数据(3)中间节点:⾸节点和接下来的每⼀个节点都是同⼀种结构类型:由数据域(date)和指针域(next)组成数据域(date)存放着实际的数据,如学号(id)、姓名(name)、性别(sex)、年龄(age)、成绩(score)等指针域(next)存放着下⼀个节点的⾸地址(4)尾节点:最后⼀个节点称为尾节点,它存放着最后⼀个有效的数据(5)头指针:指向头结点的指针(6)尾指针:指向尾节点的指针(7)单链表节点的定义public static class Node {//Object类对象可以接收⼀切数据类型解决了数据统⼀问题public Object date; //每个节点的数据Node next; //每个节点指向下⼀结点的连接public Node(Object date) {this.date = date;}}2.引⼈头结点的作⽤1. 概念头结点:虚拟出来的⼀个节点,不保存数据。

数据结构与C语言的关系引言数据结构是计算机科学中一个重要的概念,它用于组织和存储数据以便于访问和操作。
而C语言是一种通用的编程语言,常用于开发系统软件和应用程序。
本文将详细探讨数据结构与C语言之间的关系,包括C语言中实现常用数据结构的方法和数据结构对C语言程序性能的影响。
数据结构在C语言中的实现在C语言中,数据结构可以通过自定义数据类型来实现。
C语言提供了一些基本的数据类型,如整型、浮点型和字符型等,但对于复杂的数据结构,我们需要自己定义。
结构体C语言中的结构体是一种用户自定义的数据类型,它可以将不同类型的数据组合在一起形成一个整体。
结构体可以表示现实世界中的实体,如学生、员工等。
通过结构体,我们可以定义一个具有多个属性的变量。
下面是一个示例代码,展示了如何在C语言中定义和使用结构体:#include <stdio.h>struct student {char name[50];int age;float score;};int main() {struct student s;strcpy(, "Tom");s.age = 20;s.score = 90.5;printf("Name: %s\n", );printf("Age: %d\n", s.age);printf("Score: %.2f\n", s.score);return 0;}链表链表是一种常见的数据结构,它由多个节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
通过指针的连接,多个节点形成了一个链式结构。
在C语言中,链表可以通过使用结构体和指针来实现。
我们可以定义一个结构体来表示节点,然后使用指针将多个节点连接起来。
以下是一个简单的链表示例代码:#include <stdio.h>#include <stdlib.h>struct node {int data;struct node* next;};void printList(struct node* n) {while (n != NULL) {printf("%d ", n->data);n = n->next;}}int main() {struct node* head = NULL;struct node* second = NULL;struct node* third = NULL;head = (struct node*)malloc(sizeof(struct node));second = (struct node*)malloc(sizeof(struct node));third = (struct node*)malloc(sizeof(struct node));head->data = 1;head->next = second;second->data = 2;second->next = third;third->data = 3;third->next = NULL;printList(head);return 0;}栈和队列栈和队列是常见的数据结构,它们都可以通过数组或链表来实现。

结构体与链表习题附答案一、选择题1、在说明一个结构体变量时系统分配给它的存储空间是().A)该结构体中第一个成员所需的存储空间B)该结构体中最后一个成员所需的存储空间C)该结构体中占用最大存储空间的成员所需的存储空间D)该结构体中所有成员所需存储空间的总和。
2.设有以下说明语句,则以下叙述不正确的是()tructtu{inta;floatb;}tutype;A.truct是结构体类型的关键字B.tructtu是用户定义的结构体类型C.tutype是用户定义的结构体类型名D.a和b都是结构体成员名3、以下对结构体变量tu1中成员age的合法引用是()#includetructtudent{intage;intnum;}tu1,某p;p=&tu1;A)tu1->ageB)tudent.ageC)p->ageD)p.age4、有如下定义:Structdate{intyear,month,day;};Structworklit{Charname[20];Chare某;Structdatebirthday;}peron;对结构体变量peron的出生年份进行赋值时,下面正确的赋值语句是()Aworklit.birthday.year=1978Bbirthday.year=1978Cperon.birthday .year=1958Dperon.year=19585、以下程序运行的结果是()#include”tdio.h”main(){tructdate{intyear,month,day;}today;printf(“%d\\n”,izeof(truct date));}A.6B.8C.10D.126、对于时间结构体tructdate{intyear,month,day;charweek[5];}则执行printf(“%d\\n”,izeof(tructdate))的输出结果为(A.12B.17C.18D.207、设有以下语句:tructt{intn;charname[10]};tructta[3]={5,“li”,7,“wang”,9,”zhao”},某p;p=a;则以下表达式的值为6的是()A.p++->nB.p->n++C.(某p).n++D.++p->n8、设有以下语句,则输出结果是()tructLit{intdata;tructLit某ne某t;};tructLita[3]={1,&a[1],2,&a[2],3,&a[0]},某p;p=&a[1];printf(\printf(\printf(\}A.131B.311C.132D.2139、若有以下语句,则下面表达式的值为1002的是()tructtudent{intage;intnum;};tructtudenttu[3]={{1001,20},{1002,19},{1003,21}};)tructtudent某p;p=tu;A.(p++)->numB.(p++)->ageC.(某p).numD.(某++p).age10、下若有以下语句,则下面表达式的值为()tructcmpl某{int某;inty;}cnumn[2]={1,3,2,7};cnum[0].y/cnum[0].某某cnum[1].某;A.0B.1C.3D.611、若对员工数组进行排序,下面函数声明最合理的为()。
c语言链表定义链表是一种非常基础的数据结构,它的定义可以用多种编程语言来实现,其中最为常见的就是C语言。
本文将着重介绍C语言的链表定义。
第一步:首先,我们需要定义一个链表节点的结构体,用来存储链表中每个节点的数据信息以及指向下一个节点的指针。
具体代码如下所示:```struct ListNode {int val;struct ListNode *next;};```在这个结构体中,我们定义了两个成员变量,一个是表示节点值的val,一个是表示指向下一个节点的指针next。
其中,节点值可以是任意类型的数据,而指针next则是一个指向结构体类型的指针。
第二步:我们需要定义链表的头节点,通常会将头节点的指针定义为一个全局变量,方便在程序的不同部分中都能够访问。
这个头节点的作用是指向链表的第一个节点,同时也充当了哨兵节点的作用,使得链表的操作更加方便。
具体代码如下所示:```struct ListNode *list_head = NULL;```在这个全局变量中,我们定义了一个指向链表头节点的指针list_head,并将它初始化为NULL,表示目前链表为空。
第三步:链表的基本操作主要包括创建、插入、删除和遍历等。
我们将逐一介绍它们的定义方法。
1. 创建链表创建链表时,我们需要动态地分配内存,以保证每个节点的空间都是连续的而不会被覆盖。
具体代码如下所示:```struct ListNode *create_list(int arr[], int n) {struct ListNode *head = NULL, *tail = NULL;for (int i = 0; i < n; i++) {struct ListNode *node = (struct ListNode*)malloc(sizeof(struct ListNode));node->val = arr[i];node->next = NULL;if (head == NULL) {head = node;tail = node;} else {tail->next = node;tail = node;}}return head;}```在这个代码中,我们首先定义了链表的头节点head和尾节点tail,并将它们初始化为空。
第九章结构体与链表9.1结构体类型的定义❑程序设计者自己定义的数据类型❑包含若干成员,各成员可有不同的数据类型(与数组的区别)❑结构体类型定义struct 结构体名{ 类型标识符成员名1;类型标识符成员名2;…………….类型标识符成员名n;};大括号内为成员说明列表❑如,处理学生成绩数据,每个学生有三门课程的成绩、总成绩等变量。
struct student{long num; /*学号*/char name[10]; /* 姓名*/int score1; /* 成绩*/int score2;int score3;int total; /*总成绩*/};这样,student就是一个新的结构数据类型,可用它定义变量struct student a1, a2; 注意:struct不能省略结构体就是一个专有名词,代表一类事物,如:学生,教师,汽车等,是泛指结构体成员是描述该类事物的指标,如:学生的学号,名字,成绩等结构体变量是该类事物的一个具体事例,每个事例都具有全部成员,如每个学生都有学号,名字,成绩等9.2 结构体类型变量的定义1 先定义结构体类型,再定义变量如:struct student{ long num; /* 学号*/char name[10];/* 姓名*/int score1;/* 成绩*/int score2;int score3;int total; /* 总成绩*/};struct student a1, a2;注意:struct不能省略2 定义类型的同时定义变量struct student{ long num; /* 学号*/char name[10];/* 姓名*/int score1;/* 成绩*/int score2;int score3;int total; /* 总成绩*/} a1, a2;3 直接定义结构体类型变量struct{ long num; /* 学号*/char name[10];/* 姓名*/int score1;/* 成绩*/int score2;int score3;int total; /* 总成绩*/} a1, a2;每个结构体变量都拥有结构体的全部成员9.2.2 结构变量的引用❑结构变量的引用是通过引用其成员(分量)的形式来实现的,格式为: 结构变量名.结构成员名❑若定义了struct student a1, a2; 就可以使用其成员a1.num=00001;a2.num=00002;strcpy(, “John”);strcpy(, “Andrew”);a1.total=a1.score1+a1.score2+a1.score3;❑每个结构成员都可当做一个变量来使用,类型为在定义结构时所指定的数据类型❑结构变量的成员使用方法与普通内存变量没有区别。
C语言理论考试要点学习C语言后面的知识,不要忘了回头弄清遗留下的问题和加深理解前面的知识,这是我们学生最不易做到的,然而却又是最重要的。
比如:在C语言中最典型的是关于结构化程序设计构思,不管是那种教材,一开始就强调这种方法,这时也许你不能充分体会,但是学到函数时,再回头来仔细体会,温故知新,理解它就没有那么难了。
学习C语言就是要经过几个反复,才能前后贯穿,积累应该掌握的C知识。
C语言学得好的学生都是知难而上,不轻易放弃的强者。
等级考试分优秀、合格、不合格三档。
江苏省计算机二级考试成绩分为:大学计算机信息基础20分C语言理论部分40分C语言上机考试40分证书分:合格、优秀两种,没有期限通过准考证在网上查询成绩,大约考完后50天可查。
期末复习以理论为主,上机为次;暑假开始以上机为主,理论为次。
二级C语言等级考试没有通过的98%以上是因为上机未达线。
目前我校C语言等级考试通过率为40%左右。
仔细研究大纲和样题,大纲提到的知识点和库函数要熟练掌握。
常用算法默写后对照,再默写再对照。
不要不肯动笔,多做归纳总结,包括知识点的归纳和算法的归纳。
大学计算机信息基础占20分,要作适当复习。
C语言理论部分占40分,上机占40分。
C语言理论题大多数是数组以后的内容,但要熟练运用前面表达式、数据类型、三种基本结构等知识。
选择题需要记忆的知识包括计算机基础知识、基本概念。
这些内容看似不起眼,但如果不适当加以记忆,考试时因此失分十分可惜。
我们可以在理解的基础上归纳整理,适当记忆。
近年大学计算机信息基础考得比较实用、如:优盘、数量级、存取速度、通讯技术、网络知识。
每年必考的知识点如下:➢循环嵌套➢字符数组的输入输出、插入或删除、或排序、或重新组合➢函数参数的传递,传值和传址的不同、函数的定义和返回值➢变量的作用域(选择题,全局变量和局部变量的区别,如:05春25题)➢变量的存储类型(填空题,如:04春填空第9题,每次调用函数,静态变量y保留上次调用时的值;C是全局变量,&b对应指针sum传址,b和*sum值一致;a单向传值给x,x的值不影响a)➢指针传址、指针数组、指针处理二维数组、指针处理字符串数组和字符串、指针处理结构体和链表(填空题)、指针与结构体结合(填空题)笔试只有选择题和填空题两种题型。
数组链表栈队列树图等数据结构的优缺点及应⽤场景数组、字符串(Array & String)数组的优点在于:构建⾮常简单能在 O(1) 的时间⾥根据数组的下标(index)查询某个元素⽽数组的缺点在于:构建时必须分配⼀段连续的空间查询某个元素是否存在时需要遍历整个数组,耗费 O(n) 的时间(其中,n 是元素的个数)删除和添加某个元素时,同样需要耗费 O(n) 的时间链表(LinkedList)单链表:链表中的每个元素实际上是⼀个单独的对象,⽽所有对象都通过每个元素中的引⽤字段链接在⼀起。
双链表:与单链表不同的是,双链表的每个结点中都含有两个引⽤字段。
由⼀系列节点组成的元素集合,每个节点包含数据域item和下⼀个节点的指针next,通过节点相互连接,最终串联成⼀个链表。
class Node(object):def__init__(self,item):self.item = itemself.next = Nonea = [1,2,3]b = Node(a)c = Node(4)b.next = cprint(b.next.item)链表的优点如下:链表能灵活地分配内存空间;能在 O(1) 时间内删除或者添加元素,前提是该元素的前⼀个元素已知,当然也取决于是单链表还是双链表,在双链表中,如果已知该元素的后⼀个元素,同样可以在 O(1) 时间内删除或者添加该元素。
链表的缺点是:不像数组能通过下标迅速读取元素,每次都要从链表头开始⼀个⼀个读取;查询第 k 个元素需要 O(k) 时间。
应⽤场景:如果要解决的问题⾥⾯需要很多快速查询,链表可能并不适合;如果遇到的问题中,数据的元素个数不确定,⽽且需要经常进⾏数据的添加和删除,那么链表会⽐较合适。
⽽如果数据元素⼤⼩确定,删除插⼊的操作并不多,那么数组可能更适合。
栈(Stack)特点:栈的最⼤特点就是后进先出(LIFO)。
对于栈中的数据来说,所有操作都是在栈的顶部完成的,只可以查看栈顶部的元素,只能够向栈的顶部压⼊数据,也只能从栈的顶部弹出数据。