数据结构应用设计设计报告
- 格式:doc
- 大小:78.00 KB
- 文档页数:13

数据结构课程设计实践报告数据结构课程设计实践报告1. 实验目的本次数据结构课程设计实践的目的是帮助学生掌握数据结构的基本概念,了解常见数据结构的实现原理,提高代码实现能力和问题解决能力。
2. 实验背景数据结构是计算机科学的基础课程,它是计算机科学的重要组成部分。
在计算机科学中,数据结构是针对计算机中的数据存储、管理和操作的方法论。
数据结构中的“数据”是指计算机中存储的各种信息,而“结构”则是指这些信息之间的相互关系。
常见的数据结构包括数组、链表、栈、队列、树和图等。
3. 实验内容本次数据结构课程设计实践包括以下内容:3.1 栈和队列实现一个基于栈和队列的计算器程序,能够进行加减乘除等基本运算和括号运算。
3.2 链表与树实现一个简单的文件系统,包括文件的创建、删除、移动、复制等操作,利用链表实现文件存储,利用树来实现文件目录结构。
3.3 图实现最短路径算法,并利用Graphviz工具将结果可视化展示出来。
4. 实验过程我们小组首先进行了团队分工,每个成员负责一个模块的代码实现,同时进行代码审查。
我们使用C++语言进行编码实现,采用面向对象设计思想,将每个数据结构封装成一个类,方便日后的调用和扩展。
在实现栈和队列的计算器程序时,我们使用了双栈法来进行括号运算的处理,使用队列来实现多项式的存储和输出。
在实现文件系统时,我们构建了一颗树形结构来表示文件的目录结构,同时在每个节点处保存了一个链表,来存储该目录下的文件信息,方便进行操作。
在实现最短路径算法时,我们采用了Dijkstra算法,并使用Graphviz 工具将结果可视化展示出来。
5. 实验结果我们小组经过不断尝试和调试,最终实现了所有要求的功能,并达到了预期的效果。
我们在实验过程中遇到的问题,如链表的指针操作、树的遍历方法以及Dijkstra算法的实现等,我们通过文献资料的查阅和团队讨论得以解决。
6. 实验总结通过本次数据结构课程设计实践,我们加深了对数据结构的理解和掌握,同时也提高了我们的编程能力和问题解决能力。

数据结构课程设计实验报告完整版【正文】一、实验目的本实验主要目的是通过实践,掌握数据结构的基本概念、常见数据结构的实现方式以及在实际应用中的应用场景和效果。
二、实验背景数据结构是计算机科学与技术领域中的一个重要概念,是研究数据的组织方式、存储方式、访问方式以及操作等方面的方法论。
在计算机科学领域,数据结构是实现算法和解决问题的基础,因此对数据结构的理解和应用具有重要意义。
三、实验内容本次数据结构课程设计实验主要分为以下几个部分:1. 实验环境的准备:包括选择合适的开发平台、安装必要的软件和工具。
2. 实验数据的收集和处理:通过合适的方式收集实验所需的数据,并对数据进行处理和整理。
3. 数据结构的选择和实现:根据实验需求,选择合适的数据结构,并进行相应的数据结构实现。
4. 数据结构的测试和优化:对所实现的数据结构进行测试,包括性能测试和功能测试,并根据测试结果对数据结构进行优化和改进。
5. 实验报告的撰写:根据实验过程和结果,撰写完整的实验报告,包括实验目的、实验背景、实验内容、实验结果和结论等。
四、实验过程1. 实验环境的准备本实验选择了Visual Studio作为开发平台,安装了相应版本的Visual Studio,并根据官方指引进行了相应的配置和设置。
2. 实验数据的收集和处理本实验选取了一份包含学生信息的数据集,包括学生姓名、学号、性别、年龄等信息。
通过编写Python脚本,成功提取了所需信息,并对数据进行了清洗和整理。
3. 数据结构的选择和实现根据实验需求,我们选择了链表作为数据结构的实现方式。
链表是一种常见的动态数据结构,能够高效地插入和删除元素,适用于频繁插入和删除的场景。
在实现链表时,我们定义了一个节点结构,包含数据域和指针域。
通过指针的方式将节点连接起来,形成一个链式结构。
同时,我们还实现了相关的操作函数,包括插入、删除、查找等操作。
4. 数据结构的测试和优化在完成链表的实现后,我们对其进行了性能测试和功能测试。

第一章链表的应用线性表是数据结构中最简单、最常用的一种线性结构,也是学习数据结构全部内容的基础,其掌握的好坏直接影响着后继课程的学习。
线性表的顺序存储结构,即顺序表的概念相对比较简单,因此,本章的主要任务是使用有关单链表的操作来实现通讯录信息系统的管理。
1.1设计要求本章的设计实验要求使用有关链表的操作来实现通讯录信息系统的管理。
为了验证算法,通讯录管理包括单通讯录链表的建立、通讯者的插入、通讯者的删除、通讯者的查询及通讯录表的输出等。
主控菜单的设计要求使用数字0—5来选择菜单项,其他输入则不起作用。
程序运行后,给出6个菜单项的内容和输入提示:1.通讯录链表的建立2. 通讯者结点的插入3. 通讯者结点的查询4. 通讯者结点的删除5. 通讯录链表的输出0. 退出管理系统请选择0—5:1.2设计分析1.2.1主控菜单函数设计分析1.实现循环和功能选择首先编写一个主控菜单驱动程序,输入0—5以进入相应选择项。
假设输入选择用变量sn存储,它作为menu_select函数的返回值给switch语句。
使用for循环实现重复选择,并在主函数main()中实现。
实际使用时,只有选择大于5或小于0的值,程序才能结束运行,这就要使用循环控制。
这里使用for循环语句实现菜单的循环选择,为了结束程序的运行,使用了“return”语句,也可以使用“exit(0);”语句。
2.得到sn的合理值如前所述,应该设计一个函数用来输出提示信息和处理输入,这个函数应该返回一个数值sn,以便供给switch语句使用。
假设函数名为menu_select,对于sn的输入值,在switch 中case语句对应数字1—5,对于不符合要求的输入,提示输入错误并要求重新输入。
将该函数与主函数合在一起,编译运行程序,即可检查并验证菜单选择是否正确。
1.2.2功能函数设计分析1.建立通讯录链表的设计这里实际上是要求建立一个带头结点的单链表。
建立单链表有两种方法,一种称之为头插法,另一种称为尾插法。

数据结构课程设计报告学号:888888姓名:草丛伦学院:超神学院专业:LOL指导老师:流老师2050年9月一.要求1.必做题:编程实现希尔,快速,堆排序,归并排序算法,要求随机产生10000个数据存入磁盘文件,然后读入数据文件,分别采用不同的排序方法进行排序,并将结果存入文件中。
2.选做题:链表的维护与文件形式的保存:用链表结构的有序表表示某商场家电部的库存模型。
当有提货或进货时需要对该链表及时进行维护。
每个工作日结束之后,将该链表中的数据以文件形式保存,每日开始营业之前,需将以文件形式保存的数据恢复成链表结构的有序表。
链表结点数据域包括家电名称,品牌,单价和数量,以单价的升序体现链表的有序性。
程序功能包括:创建表,营业开始(读入文件恢复链表),进货(插入),提货(更新或删除),查询信息,更新信息,营业结束(链表数据存入文件)等。
二.算法思想描述1.排序算法的实现通过不同的算法,来对一大串随机数字进行有序的排列,是复杂的。
我主要用了在排序算法中效率比较高的几种算法,其分别是:希尔,快速,堆排序,归并排序。
通过这几种算法对由电脑随机产生的10000个数字进行由小到大的排序,并将结果存入文件中。
我的设计思想就是基于C++的面向对象,就是每一种算法对应于一个类,所以程序分别产生了4个类,来解决排序问题。
每个类中都有自己的构造函数和析构函数,还有就是自己的排序算法函数。
每个类还必须包含一个文件处理函数,因为我们的操作都是针对于文件的。
对于文件的处理,我用的是c中的格式化读写函数-----fprintf()和fscanf()。
最后就是讲结果保存在一个txt文件中(结果在排序目录下的文件中)。
2.链表的维护构建一个菜单循环,然后每个功能的实现通过其对应函数去实现,函数头调用系统中的相关函数,以确保程序运行正常。
建立一个商场的家电库存模型,有相关函数及指针等,输入信息,输出信息,查询修改删除的条件函数,用menu实现主菜单选择操作,实现一系列操作,释放所有链表,读取内存,自动创建文件夹。

《数据结构与算法》课程设计报告王婧、龚丹、宋毅编写题目:航空订票管理系统学期:秋班号:学号:姓名:成绩:哈尔滨华德学院电子与信息工程学院年月一、实训设计的目的与要求(注:正文为宋体,五号字,为单倍行距)(一)课程设计目的(不少于字).数据结构课程设计是综合运用数据结构课程中学到的几种典型数据结构,以及程序设计语言(语言),自行实现一个较为完整的应用系统。
.通过课程设计,自己通过系统分析、系统设计、编程调试,写实验报告等环节,进一步掌握应用系统设计的方法和步骤,灵活运用并深刻理解典型数据结构在软件开发中的应用。
.学会将知识应用于实际的方法,提高分析和解决问题的能力,增加综合能力。
具体的有:()熟练掌握链表存储结构及其建立过程和常用操作;()熟练掌握队列的建立过程和常用操作;()学会自己调试程序的方法并掌握一定的技巧。
(二)题目要求(不少于字).每条航线所涉及的信息有:终点站名、航班号、飞机号、飞机周日(星期几)、乘员定额、余票量、订定票的客户名单(包括姓名、订票量、舱位等级,或)以及等候替补的客户名单(包括姓名和所需数量)。
.系统能实现的操作和功能如下:()查询航线:根据客户提出的终点站名输出如下信息:航班号、飞机号、星期几飞行和余票额;()承办订票业务:根据客户提出的要求(航班号、订票数额)查询该航班票额情况,若有余票,则为客户办理订票手续,输出座位号;若已满员或余票量少余订票额,则需重新询问客户要求。
若需要,可登记排队候补;()承办退票业务:根据客户提出的情况(日期、航班号),为客户办理退票手续,然后查询该航班是否有人排队候补,首先询问排在第一的客户,若所退票额能满足他的要求,则为他办理订票手续,否则依次询问其它排队候补的客户。
二、实训环境配置系统三、设计正文.需求分析。

Guangxi University of Science and Technology 课程设计报告课程名称:算法和编程综合实习课题名称:姓名:学号:院系:计算机科学和通信工程学院专业班级:通信指导教师:完成日期:2015年1月15日目录第1部分课程设计报告 (3)第1章课程设计目的 (3)第2章课程设计内容和要求 (4)2.1 问题描述 (4)2.2 设计要求 (4)第3章课程设计总体方案及分析 (4)3.1 问题分析 (4)3.2 概要设计 (7)3.3 详细设计 (7)3.4 调试分析 (10)3.5 测试结果 (10)3.6 参考文献 (12)第2部分课程设计总结 (13)附录(源代码) (14)第1部分课程设计报告第1章课程设计目的仅仅认识到队列是一种特殊的线性表是远远不够的,本次实习的目的在于使学生深入了解队列的特征,以便在实际问题背景下灵活运用它,同时还将巩固这种数据结构的构造方………………………………………………………………………………………………………………………………………………………………………………………..(省略)第2章课程设计内容和要求2.1问题描述:迷宫问题是取自心理学的一个古典实验。
在该实验中,把一只老鼠从一个无顶大盒子的门放入,在盒子中设置了许多墙,对行进方向形成了多处阻挡。
盒子仅有一个出口,在出口处放置一块奶酪,吸引老鼠在迷宫中寻找道路以到达出口。
对同一只老鼠重复进行上述实验,一直到老鼠从入口走到出口,而不走错一步。
老鼠经过多次试验最终学会走通迷宫的路线。
设计一个计算机程序对任意设定的矩形迷宫如下图A所示,求出一条从入口到出口的通路,或得出没有通路的结论。
图A2.2设计要求:要求设计程序输出如下:(1) 建立一个大小为m×n的任意迷宫(迷宫数据可由用户输入或由程序自动生成),并在屏幕上显示出来;(2)找出一条通路的二元组(i,j)数据序列,(i,j)表示通路上某一点的坐标。

*****数据结构课程设计题目: 赫夫曼树的建立运动会分数统计订票系统猴子选大王图的建立与输出姓名:***学号 ****专业:计算机科学与技术指导教师:****2006年9月20日目录一:绪言 (3)1.1课题设计背景 (3)1.2课题研究的目的和意义…………………………….3.1.3课题研究的内容 (4)二:主菜单设计 (4)2.1主菜单 (4)2.2主菜单源代码 (4)2.3主菜单流程图 (5)三:具体程序设计 (6)3.1赫夫曼树的建立 (6)3.2运动会设计 (8)3.3订票系统 (12)3.4猴子选大王 (15)3.5图的建立及输出 (16)四:总结与展望 (19)五:参考文献 (19).1.绪言1.1 课题背景《数据结构》作为一门独立的课程最早是美国的一些大学开设的,1968年美国唐·欧·克努特教授开创了数据结构的最初体系,他所著的《计算机程序设计技巧》第一卷《基本算法》是第一本较系统地阐述数据的逻辑结构和存储结构及其操作的著作。
从60年代末到70年代初,出现了大型程序,软件也相对独立,结构程序设计成为程序设计方法学的主要内容,人们就越来越重视数据结构,认为程序设计的实质是对确定的问题选择一种好的结构,加上设计一种好的算法。
从70年代中期到80年代初,各种版本的数据结构著作就相继出现。
目前在我国,《数据结构》也已经不仅仅是计算机专业的教学计划中的核心课程之一,而且是其它非计算机专业的主要选修课程之一。
《数据结构》在计算机科学中是一门综合性的专业基础课。
数据结构的研究不仅涉及到计算机硬件(特别是编码理论、存储装置和存取方法等)的研究范围,而且和计算机软件的研究有着更密切的关系,无论是编译程序还是操作系统,都涉及到数据元素在存储器中的分配问题。
在研究信息检索时也必须考虑如何组织数据,以便查找和存取数据元素更为方便。
因此,可以认为数据结构是介于数学、计算机硬件和计算机软件三者之间的一门核心课程,在计算机科学中,数据结构不仅是一般程序设计(特别是非数值计算的程序设计)的基础,而且是设计和实现编译程序、操作系统、数据系统及其它系统程序和大型应用程序的重要基础。

数据结构实验报告本文是范文,仅供参考写作,禁止抄袭本文内容上传提交,违者取消写作资格,成绩不合格!实验名称:排序算法比较提交文档学生姓名:提交文档学生学号:同组成员名单:指导教师姓名:排序算法比较一、实验目的和要求1、设计目的1.掌握各种排序的基本思想。
2.掌握各种排序方法的算法实现。
3.掌握各种排序方法的优劣分析及花费的时间的计算。
4.掌握各种排序方法所适应的不同场合。
2、设计内容和要求利用随机函数产生30000个随机整数,利用插入排序、起泡排序、选择排序、快速排序、堆排序、归并排序等排序方法进行排序,并统计每一种排序上机所花费的时间二、运行环境(软、硬件环境)软件环境:Vc6.0编程软件运行平台: Win32硬件:普通个人pc机三、算法设计的思想1、冒泡排序:bubbleSort()基本思想: 设待排序的文件为r[1..n]第1趟(遍):从r[1]开始,依次比较两个相邻记录的关键字r[i].key和r[i+1].key,若r[i].key>r[i+1].key,则交换记录r[i]和r[i+1]的位置;否则,不交换。
(i=1,2,...n-1)第1趟之后,n个关键字中最大的记录移到了r[n]的位置上。
第2趟:从r[1]开始,依次比较两个相邻记录的关键字r[i].key和r[i+1].key,若r[i].key>r[i+1].key,则交换记录r[i]和r[i+1]的位置;否则,不交换。
(i=1,2,...n-2)第2趟之后,前n-1个关键字中最大的记录移到了r[n-1]的位置上,作完n-1趟,或者不需再交换记录时为止。
2、选择排序:selSort()每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。
选择排序不像冒泡排序算法那样先并不急于调换位置,第一轮(k=1)先从array[k]开始逐个检查,看哪个数最小就记下该数所在的位置于minlIndex中,等一轮扫描完毕,如果找到比array[k-1]更小的元素,则把array[minlIndex]和a[k-1]对调,这时array[k]到最后一个元素中最小的元素就换到了array[k-1]的位置。
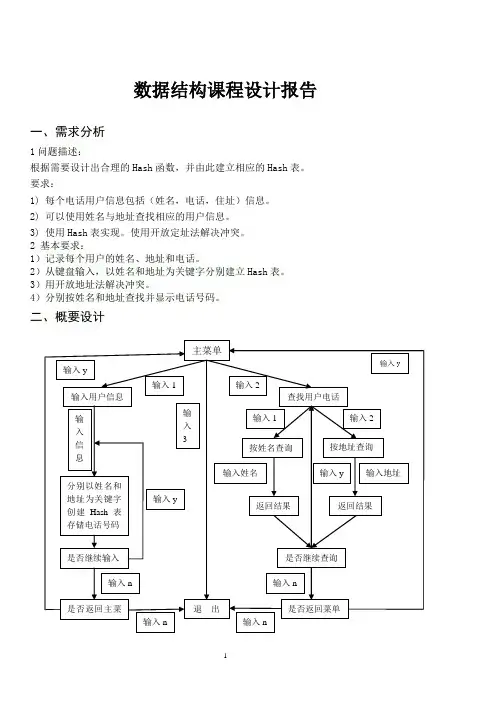
数据结构课程设计报告一、需求分析1问题描述:根据需要设计出合理的Hash函数,并由此建立相应的Hash表。
要求:1)每个电话用户信息包括(姓名,电话,住址)信息。
2)可以使用姓名与地址查找相应的用户信息。
3)使用Hash表实现。
使用开放定址法解决冲突。
2 基本要求:1)记录每个用户的姓名、地址和电话。
2)从键盘输入,以姓名和地址为关键字分别建立Hash表。
3)用开放地址法解决冲突。
4)分别按姓名和地址查找并显示电话号码。
二、概要设计三、详细设计typedef struct //定义结构Hash表{定义Hash表内的所有成员}HashTable[MaxSize];int Key(char x[])//关键字转换为数值{求字符数组x每个字符对应的asc值的绝对值之和,并返回最后结果}void CreateHT(HashTable ha)//创建Hash表{创建Hash表,并初始化它}void InsertHTna(HashTable ha,int &n,KeyType k,int d) //按姓名插入{以姓名为关键字,调用关键字转换函数将对应的电话号码存储到相应的存储空间。
若该位置已经被存储,则向后移一位(当移到最后一位,就移到头部继续)。
若还有冲突重复上一步。
当所有空间都查过一遍,发现没有空位,则输出“没有存储空间”。
}void InsertHTadd(HashTable ha,int &n,KeyType k,int d)//按地址插入{以地址为关键字,调用关键字转换函数将对应的电话号码存储到相应的存储空间。
若该位置已经被存储,则向后移一位(当移到最后一位,就移到头部继续)。
若还有冲突重复上一步。
当所有空间都查过一遍,发现没有空位,则输出“没有存储空间”。
}void InserHT(HashTable ha)//Hash表插入{输入用户姓名、地址和电话,分别调用按姓名插入和按地址插入函数进行插入。

数据结构课程设计报告(原创)设计题目:数组应用专业班级学生学号指导教师时间目录一、设计任务 (3)二、软件环境 (4)三、程序源代码 (4)四、算法设计思想及流程图 (11)4.1算法设计思想 (11)4.2流程图 (13)4.2.1主要功能模块流程图 (13)4.2.2输入函数流程图 (13)4.2.3输出函数流程图 (14)4.2.4查找函数流程图 (15)五、输入及相应运行结果 (16)六、收获及体会 (19)七、参考文献 (20)八、附录(部分截图) (21)一、设计任务题目:数组应用功能:按照行优先顺序将输入的数据建成4维数组,再按照列优先顺序输出结果,给出任意处的元素值,并给出对应的一维数组中的序号。
分步实施:1.初步完成总体设计,搭好框架,确定人机对话的界面,确定函数个数;2.完成最低要求:完成第一个功能;3.进一步要求:进一步完成后续功能。
有兴趣的同学可以自己扩充系统功能。
要求:1)界面友好,函数功能要划分好2)总体设计应画一流程图3)程序要加必要的注释4)要提供程序测试方案5)程序一定要经得起测试,宁可功能少一些,也要能运行起来,不能运行的程序是没有价值的。
二、软件环境V C ++6.0三、程序源代码#include<stdio.h>#include<malloc.h>#include<stdlib.h>#define M 100typedef struct{int data;int wei[4];}node;typedef struct{node dat[M];int max_meiwei[4];//每维的长度int m;}shu;void menu(shu *G);void input(shu *G);void output(shu *G);void find(shu *G);void introduce(shu *G); //函数声明/***********************************************************/void input(shu *G)// 输入按行{int i,j,k,l,h,b,n;G->m=1;for(i=0;i<4;i++)//依次输入第一、二、三、四维的长度{printf("\t\t\t请输入第%d维的长度:",i+1);scanf("%d",&G->max_meiwei[i]);G->m*=G->max_meiwei[i]; //维数长度积即为数据个数}n=0;for(i=0;i<G->max_meiwei[0];i++)//坐标{for(j=0;j<G->max_meiwei[1];j++)//初{for(k=0;k<G->max_meiwei[2];k++)//始{for(l=0;l<G->max_meiwei[3];l++)//化{G->dat[n].wei[0]=i;G->dat[n].wei[1]=j;G->dat[n].wei[2]=k;G->dat[n].wei[3]=l;n++;}}}}for(n=0;n<G->m;n++)//依次输入各个结点的坐标值{printf("\t\t\t请输入A[");for(b=0;b<4;b++){printf("%d,",G->dat[n].wei[b]);}printf("\b]的值\n");scanf("%d",&G->dat[n].data);}system("pause");menu(G);}/*******************************************************/void output(shu *G)// 输出按列优先顺序{int i,j,b,k,l,h,n;for(i=0;i<G->max_meiwei[3];i++) //先固定第四维,而后由里到外依次输出{for(j=0;j<G->max_meiwei[2];j++){for(k=0;k<G->max_meiwei[1];k++){for(l=0;l<G->max_meiwei[0];l++){printf("\t\t");for(h=0;h<G->m;h++){if(G->dat[h].wei[3]==i && G->dat[h].wei[2]==j && G->dat[h].wei[1]==k && G->dat[h].wei[0]==l){printf("\t%d",G->dat[h].data);}}}printf("\n");}}}printf("\n");system("pause");menu(G);}/*******************************************************//*******************************************************/void find(shu *G) // 给出任意元素值输出对应的一维数组所在的位置{int i,a,k=0,j;system("cls");printf("\n\n\t\t\t 请输入所查值:");scanf("%d",&a);for(i=0;i<G->m;i++){if(a==G->dat[i].data) //逐个比较,找出数组中和所给值相等的数{printf("\n\t\t\4 \4 \4 \4 \4 \4 \4 \4 \4 \4 \4 \4 \4 \4 \\4 \4");printf("\n\t\t\t对应第一维位置为:%d\n",i);printf("\t\t\5 \5 \5 \5 \5 \5 \5 \5 \5 \5 \5 \5 \5 \5 \5 \5\n");k=1;}}if(k==0){printf("\n\t\t\t~~~~(>_<)~~~~ 对不起,您所查询的数不存在!~~~~(>_<)~~~~ \n");printf("\n\t\t\t继续1\n\t\t\t返回2\n\t\t\t请选择:");scanf("%d",&j);if(j==1){find(G);}else if(j==2){menu(G);}}system("pause");menu(G);}/*******************************************************/ void menu(shu *G)//菜单{int i;system("cls");system("color 9a");printf("\t\t\n\n\n\n\n\n");printf("\t\t\n");printf("\t\t╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬\n"); printf("\t\t║**************************************║\n"); printf("\t\t╬* WELCOME *╬\n"); printf("\t\t║**************************************║\n"); printf("\t\t╬* *╬\n"); printf("\t\t║* *║\n"); printf("\t\t╬* ☆输入(press 1) *╬\n"); printf("\t\t║* ★输出(press 2) *║\n"); printf("\t\t║* ☆查找(press 3) *║\n"); printf("\t\t╬* ★退出(press 0) *╬\n"); printf("\t\t║* *║\n"); printf("\t\t║**************************************║\n"); printf("\t\t╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬╬\n"); printf("\t\t\t请选择");printf("\n\t\t\t");scanf("%d",&i);switch(i){case 1: input(G);break;case 2: output(G);break;case 3: find(G);break;case 0:{system("cls");printf("\n\n");printf("\t\t \n");printf("\t\t\n");printf("\t\t (.@.@) \n");printf("\t\t+-------oOOo-----(_)-----oOOo---------+\n");printf("\t\t||\n");printf("\t\t|再见! 谢谢使用!! |\n");printf("\t\t||\n");printf("\t\t+----------oooO-------Oooo--------------+\n");printf("\n\n");exit(0);break;}default:menu(G);break;}}/*******************************************************//*******************************************************/void introduce(shu *G){int i;system("cls");printf("\n\n\n\n\t\t ☆此系统的功能有☆\n\n");printf("\t\t★按照行优先顺序将输入的数据建成4维数组\n\n");printf("\t\t★按照列优先顺序输出\n\n");printf("\t\t★给出任意处的元素值,查询相应的一维数组的序号\n\n");printf("\n\n\n\t\t按1返回\n");printf("\n\n\t\t按0退出\n");scanf("%d",&i);if(i==1){menu(G);}else if(i==0){exit(0);}}/*******************************************************/main(){int i,j=1;shu *G;G=(shu *)malloc(sizeof(shu)); //开辟一段空间while(j) //利用j来实现while循环{system("cls");system("color 9e");printf("\n\n\n");printf("\t\t┏━━━━━━━━━━━━━━━━━━━┓\n"); printf("\t\t┃* * * * * * * * * * * * * * * * * * * ┃\n"); printf("\t\t┃* ※欢迎使用数组应用系统※* ┃\n"); printf("\t\t┃* * * * ** * * * * * * * * * * * * * * ┃\n"); printf("\t\t┃* * ┃\n"); printf("\t\t┃* * ┃\n"); printf("\t\t┃* ☆☆☆☆☆☆☆☆* ┃\n"); printf("\t\t┃* ★★★★★* ┃\n");printf("\t\t┃* ☆☆☆☆* ┃\n"); printf("\t\t┃* ★★★★* ┃\n"); printf("\t\t┃* ☆☆☆☆* ┃\n"); printf("\t\t┃* ★★★★* ┃\n"); printf("\t\t┃* ☆☆☆☆* ┃\n"); printf("\t\t┃* ★★★★* ┃\n"); printf("\t\t┃* ☆☆* ┃\n"); printf("\t\t┃* * ┃\n"); printf("\t\t┃* * * * * * * * * * * * * * * * * * * ┃\n");printf("\t\t┗━━━━━━━━━━━━━━━━━━━┛\n"); printf("\n\t\t\t\3\3\3\3\3\3\3\3\3 简介 1 \3\3\3\3\3\3\3"); printf("\n\n\n\t\t\t\3\3\3\3\3\3\3\3\3 登录 2 \3\3\3\3\3\3\3"); printf("\n\n\n\t\t\t\3\3\3\3\3\3\3\3\3 退出 3 \3\3\3\3\3\3\3"); printf("\n\t\t\t请选择:");scanf("%d",&i);switch(i){ //case语句,控制输入情况case 1:j=0;introduce(G);break;case 2:j=0;menu(G);break;case 3:j=0;exit(0);default:printf("输入有误,请重新输入"); //增强程序健壮性j=1;}}return 0;}四、算法设计思想及流程图4.1 算法设计思想首先,在定义四维数组的数据类型时,我选择了整型以方便编程及利于数据的输入和输出。

最短距离问题数据结构课程设计报告数据结构课程设计报告题⽬:北海公园主要游览景点之间最短距离问题⼀、课程设计题⽬:北海公园主要游览景点之间最短距离问题⼆、问题定义:(由教师指定)图的最短路径问题是指从指定的某⼀点v开始,求得从该地点到图中其它各地点的最短路径。
并且给出求得的最短路径的长度及途径的地点。
除了完成最短路径的求解外,还能对该图进⾏修改,如顶点以及边的增删、边上权值的修改等。
三、需求分析1、设计北海公园的平⾯图。
选取若⼲个有代表性的景点抽象成⼀个⽆向带权图,以图中顶点表⽰公园内各景点,边上的权值表⽰两景点之间的距离。
2、输⼊的形式:整型数字输⼊值的范围:0-103、输出的形式:由⼆元组表⽰以邻接矩阵存储的图4、程序所能达到的功能;(1)输出顶点信息:将公园内各景点输出。
(2)输出边的信息:将公园内每两个位置的距离输出。
(3)修改:修改两个位置的距离,并重新输出每两个位置的距离;(4)求最短路径:输出给定两点之间的最短路径的长度及途经的地点,输出任意⼀点与其他各点的最短路径。
(5)删除:删除任意⼀条边。
(6)插⼊:插⼊任意⼀条边。
5、算法涉及的基本理论分析:定义邻接矩阵adjmatrix;⾃定义顶点结构体V ertexType;定义邻接表中的边结点类型edgenode;switch算法;狄克斯特拉法(Dijkstra)求任意两结点之间的最短路径;6、题⽬研究和实现的价值。
四、算法设计1、概要设计(1)存储结构设计本系统采⽤图结构类型存储抽象北海公园地图的信息。
其中:各景点间的邻接关系⽤图的邻接矩阵类型(adjmatrix)存储;景点(顶点)信息⽤结构数组(V ertexType)存储,其中每个数组元素是⼀个结构变量,包含景点编号、景点名称两个分量;图的顶点个数由分量MaxV ertexNum表⽰,它是整型数据。
(2)主界⾯设计为了实现公园导游系统各功能的管理,⾸先设计⼀个含有多个菜单项的主控菜单⼦程序以链接系统的各项⼦功能,⽅便⽤户使⽤本系统。
《数据结构》课程设计报告一、课程目标《数据结构》课程旨在帮助学生掌握计算机科学中数据结构的基本概念、原理及实现方法,培养其运用数据结构解决实际问题的能力。
本课程目标如下:1. 知识目标:(1)理解数据结构的基本概念,包括线性表、栈、队列、串、数组、树、图等;(2)掌握各类数据结构的存储表示和实现方法;(3)了解常见算法的时间复杂度和空间复杂度分析;(4)掌握排序和查找算法的基本原理和实现。
2. 技能目标:(1)能够运用所学数据结构解决实际问题,如实现字符串匹配、图的遍历等;(2)具备分析算法性能的能力,能够根据实际问题选择合适的算法和数据结构;(3)具备一定的编程能力,能够用编程语言实现各类数据结构和算法。
3. 情感态度价值观目标:(1)培养学生对计算机科学的兴趣,激发其探索精神;(2)培养学生团队合作意识,提高沟通与协作能力;(3)培养学生面对问题勇于挑战、善于分析、解决问题的能力;(4)引导学生认识到数据结构在计算机科学中的重要地位,激发其学习后续课程的兴趣。
本课程针对高年级学生,课程性质为专业核心课。
结合学生特点,课程目标注重理论与实践相结合,强调培养学生的实际操作能力和解决问题的能力。
在教学过程中,教师需关注学生的个体差异,因材施教,确保课程目标的达成。
通过本课程的学习,学生将具备扎实的数据结构基础,为后续相关课程学习和职业发展奠定基础。
二、教学内容根据课程目标,教学内容主要包括以下几部分:1. 数据结构基本概念:线性表、栈、队列、串、数组、树、图等;教学大纲:第1章 数据结构概述,第2章 线性表,第3章 栈和队列,第4章 串。
2. 数据结构的存储表示和实现方法:教学大纲:第5章 数组和广义表,第6章 树和二叉树,第7章 图。
3. 常见算法的时间复杂度和空间复杂度分析:教学大纲:第8章 算法分析基础。
4. 排序和查找算法:教学大纲:第9章 排序,第10章 查找。
教学内容安排和进度如下:1. 第1-4章,共计12课时,了解基本概念,学会使用线性表、栈、队列等解决简单问题;2. 第5-7章,共计18课时,学习数据结构的存储表示和实现方法,掌握树、图等复杂结构;3. 第8章,共计6课时,学习算法分析基础,能对常见算法进行时间复杂度和空间复杂度分析;4. 第9-10章,共计12课时,学习排序和查找算法,掌握各类算法的实现和应用。
数据结构课程设计报告
题目:
组长:
成员:
成员:
成员:
成员:
成员:
指导教师:
年月日
一、课程设计题目:
二、问题定义:(由教师指定)
三、需求分析
以明确的无歧义的陈述说明课程设计的任务,强调的是程序要做什么?并明确规定:
1、输入的形式和输入值的范围;
2、输出的形式;
3、程序所能达到的功能;
4、算法涉及的基本理论分析:比如对文件压缩,算法用到了
Huffman树,就要从理论上对文件压缩的几种方式、Huffman树的定义、Huffman编码的原理、解码的过程等进行分析。
5、题目研究和实现的价值。
四、算法设计
1、概要设计
阐述说明本算法中用到的所有数据结构的定义及其含义、主程序的流程以及各程序模块之间的层次(调用)关系。
3.详细设计
(1)实现概要设计中定义的所有数据类型;
(2)所有函数的接口描述;
(3)所有函数的算法描述(只需要写出伪码算法);
(3)对主程序和其他模块也都需要写出伪码算法(伪码算法达到的详细程度建议为:按照伪码算法可以在计算机键盘直接输入高级程序设计语言程序),可采用流程图、N – S 图或PAD图进行描述
(4)画出函数的调用关系图。
五、算法实现
以附件形式
六、软件测试
这里的测试主要是基于功能的黑盒测试,所以首先提出测试的功能点,然后给出测试数据(包括正确的输入及其输出结果和含有错误的输入及其输出结果。
)
要求在附件里给出软件的基本数据和测试数据。
七、技术讨论(可选)
八、收获与体会
九、软件运行的部分截图及说明。
景德镇陶瓷大学数据结构课程设计报告题目:通讯录管理院系名称:信息学院专业名称:信息与计算科学班级:学生姓名:学号:指导教师:设计起止时间:2017.06.5——2017.06.16一. 设计目的1、通过本次课程设计巩固《数据结构》中所学的内容;2、提高自己上机编程以及调试能力。
二. 设计内容建立一个通讯录,能够实现储存联系人、添加联系人、删除联系人等功能。
输入的通讯录联系人包编号、姓名、性别、电话、地址等信息。
三.概要设计程序流程图四.调试情况,设计技巧及体会1.改进方案1、菜单界面可以更加优化的美观些。
2、联系人的查询太繁琐,需要改进算法。
2.体会回顾起此课程设计,至今我仍感慨颇多,从理论到实践,在这段日子里,可以说得是苦多于甜,但是可以学到很多很多的东西,同时不仅可以巩固了以前所学过的知识,而且学到了很多在书本上所没有学到过的知识。
通过这次课程设计使我懂得了理论与实际相结合是很重要的,只有理论知识是远远不够的,只有把所学的理论知识与实践相结合起来,从理论中得出结论,才能真正为社会服务,从而提高自己的实际动手能力和独立思考的能力。
五.参考文献1、《数据结构》杨剑主编清华大学出版社2、《数据结构(C语言版)》.严蔚敏_吴伟民.主编清华大学出版社3、网上相关资料六、附录:源代码#include<iostream.h>#include"stdio.h"#include "stdlib.h"#include <string>#define maxsize 10000#define overload 0#define ok 1#define error 2typedef int Status;typedef struct{char num[10];char name[5];char sex[5];char tel[15];char adj[30];}data;typedef struct{int length;data *elem;}Sqlist;Status InitList(Sqlist &L){L.elem=new data[maxsize];if(!L.elem)exit(overload);L.length=0;return ok;}Status Add(){Sqlist L;data e;int i;i=1;char chose;cout<<"请输入姓名:"<<endl;cin>>;cout<<endl;cout<<"请输入学号:"<<endl;cin>>e.num;cout<<endl;cout<<"请输入性别:"<<endl;cin>>e.sex;cout<<endl;cout<<"请输入地址:"<<endl;cin>>e.adj;cout<<endl;cout<<"请输入电话:"<<endl;cin>>e.tel;L.elem[i-1] = e;cout<<endl;cout<<"是否继续更新通讯录信息,是请输入Y,否请输入N"<<endl;cin>>chose;if(chose=='Y'){Add();}return ok;}Status ListDelete(){Sqlist L;int i;cin>>i;if((i<1)||(L.length)) return error;for(int j=i;j<=L.length;j++){L.elem[j-1]=L.elem[j];--L.length;}return ok;}Status LocationElem(Sqlist &L, char e) {cin>>e;for(int i=0;i<=L.length;i++){if(L.elem[i].adj==e)return i+1;elsereturn 0;if(L.elem[i].name==e)return i+1;elsereturn 0;if(L.elem[i].num==e)return i+1;elsereturn 0;if(L.elem[i].sex==e)return i+1;elsereturn 0;if(L.elem[i].tel==e)return i+1;elsereturn 0;if((L.elem[i].adj==e)return i+1;elsereturn 0;}}Status TraverseList(){Sqlist L;for(int i=0;i<=L.length;i++)cout<<L.elem[i].name<<endl;cout<<L.elem[i].sex<<endl;cout<<L.elem[i].num<<endl;cout<<L.elem[i].tel<<endl;cout<<L.elem[i].adj<<endl;return ok;}void Cover(){cout<<" 通讯录管理系统"<<endl;cout<<" 1、新建通讯录信息"<<endl;cout<<" 2、删除通讯录信息"<<endl;cout<<" 3、查询通讯录信息"<<endl;cout<<" 4、输出通讯录信息"<<endl;cout<<" 请选择菜单号1--4 。
目录第一章课程设计的目的和意义 (1)第二章需求分析 ...................................................................... 错误!未定义书签。
第三章系统设计 (3)3.1 概要设计 (3)3.2详细设计 (5)第四章系统测试 (5)4.1系统运行初始界面 (6)4.2录入航班、客户信息界面 (6)4.3 查看所有航班信息界面 (6)4.4 买票、退票界面 (7)第五章心得体会 (7)第六章参考文献 (8)致谢 (8)附录 (9)源程序: (9)第一章课程设计的目的和意义《数据结构》主要介绍一些最常用的数据结构,阐明各种数据结构内在的逻辑关系,讨论其在计算机中的存储表示,以及在其上进行各种运算时的实现算法,并对算法的效率进行简单的分析和讨论。
数据结构是介于数学、计算机软件和计算机硬件之间的一门计算机专业的核心课程,它是计算机程序设计、数据库、操作系统、编译原理及人工智能等的重要基础,广泛的应用于信息学、系统工程等各种领域。
学习数据结构是为了将实际问题中所涉及的对象在计算机中表示出来并对它们进行处理。
通过课程设计可以提高学生的思维能力,促进学生的综合应用能力和专业素质的提高。
通过此次课程设计主要达到以下目的:一:了解并掌握数据结构与算法的设计方法,具备初步的独立分析和设计能力;二:初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能;三:提高综合运用所学的理论知识和方法独立分析和解决问题的能力;四:训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风。
五:锻炼动手操作能力,培养我们的创新思维能力。
从编写代码,到调试程序,再到运行程序,这是设计的最重要环节,它需要我们用逻辑思维将我们所学知识和实际相结合,并在对方案的分析过程中能够有所创新,从而使运行方案更严谨更简洁。
培养好良好的思维,便要将这种思维赋予实践,即动手操作能力。
数据结构程序设计报告总结
摘要:
1.数据结构概述
2.程序设计方法
3.实际应用案例分析
4.报告总结与展望
正文:
一、数据结构概述
数据结构是计算机科学中研究数据如何存储、组织和管理的一门学科。
它为程序设计提供了基本的结构框架,使得程序能够高效地处理数据。
数据结构主要包括线性结构、树状结构、图形结构等。
在本报告中,我们将重点讨论线性结构及其应用。
二、程序设计方法
1.顺序表:顺序表是一种线性数据结构,通过一组连续的存储单元依次存储数据元素。
顺序表的插入、删除操作相对较慢,但查找操作速度较快。
在程序设计中,我们可以使用循环结构实现顺序表的操作。
2.链表:链表是一种线性数据结构,通过每个数据元素指向下一个元素的方式实现数据存储。
链表的插入、删除操作较快,但查找操作相对较慢。
链表的程序设计可以使用递归或循环结构。
3.栈与队列:栈和队列都是线性数据结构,分别支持后进先出(LIFO)和先进先出(FIFO)的操作。
在程序设计中,我们可以使用循环或条件语句实现
栈和队列的操作。
4.树状结构:树状结构是一种层次化的数据结构,由一个根节点和若干子节点组成。
二叉树、B树、红黑树等都是常见的树状结构。
树状结构的程序设计可以使用递归算法。
5.图形结构:图形结构是一种更为复杂的数据结构,由多个节点和边组成。
图形的程序设计通常使用深度优先搜索(DFS)和广度优先搜索(BFS)算法。
数据结构应用设计设计报告题目名称:___基于哈夫曼编码的文件压缩器_设计环境:____ __VC6.0 ____________指导教师:_____ _蔡茂蓉______________专业班级:______软件工程0601班__ ___姓名:__ _ __杨文辉_____________学号:___ ____ _____联系电话:_ _电子邮件:设计日期:年月日至年月日设计报告日期:年月日1 .题目................................................................................................... 错误!未定义书签。
2 .需求分析........................................................................................... 错误!未定义书签。
2.1文件压缩过程:......................................................................... 错误!未定义书签。
2.2文件解压过程:......................................................................... 错误!未定义书签。
2.3压缩文件的存储结构设计图:................................................. 错误!未定义书签。
2.4HAF文件示例:...................................................................... 错误!未定义书签。
3 .详细设计........................................................................................... 错误!未定义书签。
3.1压缩流程图:............................................................................. 错误!未定义书签。
3.2解压流程图:............................................................................. 错误!未定义书签。
3.3节点类设计:............................................................................. 错误!未定义书签。
3.4编码和译码时的控制结构的实现............................................. 错误!未定义书签。
4.调试分析........................................................................................... 错误!未定义书签。
6 .测试结果........................................................................................... 错误!未定义书签。
6.1文件压缩..................................................................................... 错误!未定义书签。
6.2文件解压..................................................................................... 错误!未定义书签。
7.实验总结........................................................................................... 错误!未定义书签。
8 .参考文献........................................................................................... 错误!未定义书签。
1 .题目基于哈夫曼编码的文件压缩器2 .需求分析哈夫曼编码在文件压缩中有其独特一点,它的编码方式特殊。
在通信领域可以得到应用。
本程序使用C++编写,在VC6.0上调试,完成了文件的读取,文件字符的统计,哈夫曼树的建立,哈夫曼编码的实现,文件转换为哈夫曼编码成为压缩文件以及文件从压缩状态进行解码。
2.1文件压缩过程:1、找出一个待压缩文件,进行读取,并且统计其每种字节出现的频率。
2、根据已经统计的频率,进行哈夫曼树的构建。
3、对已经构建的哈夫曼树进行哈夫曼编码,将这个文件读入到一个新的文件中4、再次读取文件并且对每一个字符编码,并继续读入到这个新的文件中,这个新的文件就是压缩后的文件5、压缩时函数调用关系为,使用类CHaffmanCode,所有的程度操作函数集中在该类中。
float CHaffmanCode::OpenandCloseFile(char *OpenFile,char *CloseFile){//这个函数压缩函数,把所有要用的操作函数都集中在该函数中。
……CreateHaffmanTree(hArray); //使用得到的权值构建哈夫曼树,这里用矩阵实现EnHaffmanCode(hArray,codes);//对已经构建好的哈夫曼树的每个叶结点进行编码fCompre = ChangtoCode(OpenFile,CloseFile);//把所有的内容都按照编码存入一个新文件,返回文件压缩率return fCompre;//这是返回文件压缩率}2.2文件解压过程:1、从压缩文件读出前部分,就是压缩到文件中的各个节点的权值。
2、使用这些权值再次构建一个哈夫曼树。
3、再读入文件其他的压缩信息,并且使用递推的方式,找到文件中应该有的字符4、把这些字读入一个新文件,完成解压5、解压时函数调用关系,使用类CHaffmanCode,所有的程度操作函数集中在该类中void CHaffmanCode::TranslateCodes(char* OpenFile,char *CloseFile){//这是个解压函数,把相关的操着都封装在其中……CreateHaffmanTree(hArray); //再次使用这些权值建立一个哈夫曼树//再读出压缩文件中存储的原文件的后缀名,且保存在CloseFile的尾部//使用递推的办法在建立的哈弗曼树中找出各个压缩后字符的原子符//将其保存在CloseFile中}2.3压缩文件的存储结构设计图:HAF文件的组成结构2.4HAF文件示例:这是文件压缩时候产生的头部信息,存储的是每个节点的权值的信息,主要为256个节点的权值信息,每个节点的权值是由1个整数表示(即8*4个二进制位)。
在存入节点信息的末尾,存入了4个字符型(即8*4个二进制位),用以存入文件的后缀名。
综上,如果压缩的是空文件(即没有任何字符),那么在压缩文件头部(即haf 文件组成前两部分)应该存储的是一个(4 * 256 + 4 * 1 = 1028(字节))。
这是文件压缩的信息部分,是对待压缩文件每个节点的编码,然后存储的信息。
设计时每种叶子节点的编码为24个整型数据的组成的数组。
用这24个整数表示24个二进制位。
但是由于编码的长度不等,所以字符存入的 长度不等,因此,设计一个数组(暂定1024位),当数组被每个节点的编码(即24位整数中有效的整数位)填满了以后,对这个数组以8位为单位进行转换。
最后一次会由的编码可能不足1024位,这时又对其单独处理。
如果最后剩下的位数不是8位,那么就以加0的方式补充为8位,并在文件的末尾加上补0的个数。
如果未补零,自然这个补0的个数为0。
3 .详细设计3.1压缩流程图:3.2 3.3{int iParent;int iFlag;HaffNode(){iWeight = 0;iLeftChild = -1; iRightChild = -1; iParent = -1; iFlag = 0; }};struct HaffNode设计的作用是使用该节点类构建256个叶子节点,255个非叶子节点。
最终构建成为一个哈夫曼树。
struct Code //用于存每个叶子节点的编码{int iStart;//编码在数组中的开始端int Bit[24];//每个都设置为24位的整数struct Code类的设计旨在构建存储哈夫曼编码后的编码class CHaffmanCode{private:HaffNode *hArray ;Code *codes;char Temp[iMax];int iNumofBits;public:void CreateHaffmanTree(HaffNode *p);//建立哈夫曼树void EnHaffmanCode(HaffNode *p,Code *cd);//对哈夫曼树的每个节点编码float OpenandCloseFile(char *OpenFile,char *CloseFile);//打开文件,调用函数进行编码压float ChangtoCode(char *OpenFile,char *CloseFile);//使用已有的编码,压缩文件,返回压缩率void TranslateCodes(char *OpenFile, char *CloseFile);//译码,解压缩CHaffmanCode();virtual ~CHaffmanCode();};3.4编码和译码时的控制结构的实现class CHaffmanCode是整个编码和译码的控制类,将函数封装在其中。
CHaffmanCode::CHaffmanCode(){hArray = new HaffNode[iNumofCode];//一共申请了511个节点,其中256个叶子节点codes= new Code[256];//对每个叶子节点相应的编码}//////////////////////////////////////////////////////////////////////////float CHaffmanCode::OpenandCloseFile(char *OpenFile,char *CloseFile){//打开一个待压缩文件,提供压缩后存储的地址ifstream infile(OpenFile, ios::in | ios::binary);do{//统计每个节点在ASCII中的出现频率} while(iNumofBits == iMax); //每次读入1024个字节CreateHaffmanTree(hArray); //使用得到的权值构建哈夫曼树,这里用矩阵实现EnHaffmanCode(hArray,codes);//对已经构建好的哈夫曼树的每个叶结点进行编码reutrn ChangtoCode(OpenFile,CloseFile);//把所有的内容都按照编码存入一个新文件}////////////////////////////////////////////////////////////////////////// void CHaffmanCode::CreateHaffmanTree(HaffNode *p){//构建哈夫曼树}////////////////////////////////////////////////////////////////////////// void CHaffmanCode::EnHaffmanCode(HaffNode *p,Code *cd){//使用已经构建的哈夫曼树对每个叶子节点进行编码}////////////////////////////////////////////////////////////////////////// float CHaffmanCode::ChangtoCode(char *OpenFile,char *CloseFile){ifstream ifile(OpenFile,ios::in | ios::binary); //再次读入待压缩的文件ofstream outfile(CloseFile, ios::out | ios::binary);//保存压缩文件for(int iWright = 0; iWright < 256; ++iWright){ //在压缩文件中存入每个叶子节点的权值}outfile.write(FileName,4);//读入文件后缀名do{ //压缩后的文件读入到文件中} while(iNumofBits == iMax); //读入1024个字节ifile.seekg(0,ios::end);long double ldOriginSize = ifile.tellg();outfile.seekp(0,ios::end);long double ldChangedSize = outfile.tellp();return (float)((ldOriginSize - ldChangedSize)/ldOriginSize)*100;//计算压缩率}////////////////////////////////////////////////////////////////////////// void CHaffmanCode::TranslateCodes(char* OpenFile,char *CloseFile){ifstream infile(OpenFile,ios::in | ios::binary);int iRead;for (iRead = 0; iRead < 256; ++iRead){ //把每个节点的权值读出文件}CreateHaffmanTree(hArray); //再次使用这些权值建立一个哈夫曼树infile.read(FileName,4); //文件的后缀名一共存了4个字节,读出文件后缀名。