视频会议中的各种音频技术
- 格式:docx
- 大小:22.82 KB
- 文档页数:6

视频会议技术
视频会议技术是一种通过互联网连接参与者,允许人们在
不同地理位置进行面对面交流和互动的技术。
视频会议技
术利用音频和视频传输数据,允许参与者通过计算机、智
能手机、平板电脑或专用视频会议设备进行会议。
视频会议技术包括以下主要组件和功能:
1. 视频和音频传输:视频会议技术使用音频和视频传输数据,使参与者能够看到和听到其他参与者。
2. 屏幕共享:参与者可以共享其屏幕上的内容,例如演示
文稿、电子表格或其他文件。
3. 文字聊天:视频会议技术通常包括文字聊天功能,允许
参与者通过文字进行实时交流。
4. 多方通话:视频会议技术支持多个参与者同时参与会议。
5. 会议录制:一些视频会议技术允许用户录制会议内容,
以备后续回放或分享。
6. 虚拟背景:一些视频会议技术提供虚拟背景功能,允许用户更改其出现在屏幕上的背景。
7. 控制权限:视频会议技术通常允许主持人授予或限制与会者的权限,例如禁止/启用麦克风和摄像头。
8. 移动支持:许多视频会议技术提供移动应用程序,使用户可以在智能手机或平板电脑上参加会议。
常见的视频会议技术包括Zoom、Microsoft Teams、Cisco Webex、BlueJeans、Google Meet等。
这些技术在商务会议、远程教育、远程医疗和远程团队协作等领域得到广泛应用。


视频会议的会议评估技术在现代化的办公生活中,视频会议已经成为一种非常流行和便捷的沟通方式。
随着人们日益追求高效沟通的需求,视频会议的使用范围正在逐步增加,涉及到各种行业和领域。
在这种情况下,为确保视频会议的质量,对会议的评估技术也变得异常重要。
评估视频会议的技术可以帮助用户了解会议的质量,同时有助于识别并解决各种问题。
下面,我们就来仔细了解一下视频会议的会议评估技术。
1. 会议质量的评估会议质量的评估是视频会议中最基本的评估技术之一。
它可以帮助用户了解会议的实际效果,并提供对会议的参与者的一些有用信息。
它包括:(1) 音频质量评估: 在视频会议期间,音频质量评估是至关重要的,因为它可以影响会议的参与者能否听到和理解对方的发言。
评估音频质量的方式是检查语音的清晰度、声音的强度、语速和准确性等。
(2) 视频质量评估: 视频质量评估可以帮助用户了解视频的清晰度、鲜明度和稳定性。
如果视频需要进行水平校准,这将会极大地影响到视频的质量,从而影响到参与者的视觉体验。
(3) 所有参与者的参与状况: 会议的参与者必须积极参与会话,如果有参与者没有参加会议,这将影响会议的效果。
(4) 时间延迟: 时间延迟可以影响会议的质量。
如果会议中的某些参与者因为网络信号受限而面临时间延迟的问题,那么他们将无法看到或听到会议中的其他人发言,这将影响会议的效果。
2. 验证视频会议的可靠性可靠性是评估视频会议的另一个重要方面。
可靠性评估往往得出的是会议是否达到预期目标的信息。
为评估可靠性,可以考虑以下内容:(1) 网络可用性: 网络可用性是确保视频会议流畅性的一个重要因素。
如果网络质量太差或不可用,会参会的人无法参加会议,从而导致会议的失败。
(2) 技术设备: 技术设备是视频会议中非常重要的一个点。
如果技术设备无法使用或者配置不正确,会议将会受到很大影响。
(3) 组织和管理: 组织和管理非常重要,因为没有正确管理和组织会议,参与者也无法达到预期目标。

数字音视频处理中的多媒体同步与时域处理技术随着数字音视频技术的飞速发展,多媒体同步与时域处理技术在数字音视频处理中扮演着重要角色。
本文将为您详细介绍多媒体同步与时域处理技术的原理和应用。
1. 多媒体同步技术的原理在数字音视频处理中,多媒体同步技术是指协调多个音频和视频流以使其保持时间上的一致性。
这对于实现无缝的音视频播放和多流混合具有重要意义。
多媒体同步技术一般是通过时间戳来实现的。
音频和视频流都会包含时间戳信息,用于标记每个音频和视频样本的时间。
在播放过程中,播放器会根据时间戳信息来控制音频和视频的播放顺序和时序。
播放器会根据时间戳计算出音频和视频的相对延迟,并进行相应的调整以实现同步播放。
2.时域处理技术的原理时域处理技术是指对数字音视频信号进行处理的过程,其中包括了音频的采样、压缩、降噪、均衡等处理,以及视频的帧率控制、画质调整等处理。
在时域处理中,关键是对音频和视频信号的数学处理。
常见的时域处理技术包括滤波、时域混响、降噪、增益控制等。
这些处理技术可以改善音视频信号的质量,提高音视频的表现力和逼真度。
3.多媒体同步技术的应用多媒体同步技术在日常生活中有着广泛的应用。
例如,在电影院观看电影时,电影院会使用多媒体同步技术确保音频和视频的同步播放,以提供观众最佳的观影体验。
此外,在音乐会、演唱会等大型活动中,也需要使用多媒体同步技术,确保音乐和视频的同步。
另外,多媒体同步技术也应用于网络直播和视频会议等领域。
在网络直播中,多个音频和视频流需要同时传输并保持同步,以提供实时的音视频体验。
而在视频会议中,各个会议参与者的音频和视频也需要进行同步,以实现流畅的会议体验。
4.时域处理技术的应用时域处理技术在数字音视频领域有着广泛的应用。
在音频处理中,时域处理技术可以用于降噪、均衡、混响等。
通过降噪处理,可以减少环境噪音对音频信号的干扰,提升音频的清晰度和质量。
通过均衡处理,可以调整不同频率的音频信号的音量,以实现更好的音频效果。

视频会议的音视频编解码技术随着全球化的发展和工作场景的变迁,视频会议已经成为了我们日常工作和社交交流的必要方式。
而视频会议能够正常进行,离不开音视频编解码技术的支持。
本文将从编解码原理、编解码标准、编解码器选择、编解码效果等方面,探讨视频会议的音视频编解码技术。
一、编解码原理音视频编解码技术是通过压缩和解压缩实现的。
所谓压缩,是指通过算法等方式将音视频信号中的冗余内容去掉,从而降低信号的数据量,以达到传输、存储等目的;解压缩则是指将压缩后的音视频信号还原成原始信号。
在音视频编解码中,编码是通过将原始信号转换成数字信号,并将数字信号压缩来实现的。
解码则是对压缩后的信号进行还原,并将其转换为显示或播放所需的信号。
二、编解码标准编解码标准是指压缩和解压缩音视频信号所使用的数据格式、算法、参数等规范。
在视频会议中,常用的编解码标准包括H.264/AVC、H.265/HEVC、VP8、VP9等。
H.264/AVC是目前视频会议中最普及的编解码标准。
它采用了先进的压缩算法,可以在保证视频质量的前提下实现更小的数据传输量。
而H.265/HEVC则是H.264/AVC的升级版,它能够在不降低画质的情况下,实现更高的压缩比,进一步降低视频传输成本。
VP8和VP9则是由Google开发的开源编解码标准,在一些商业应用中得到一定应用。
它们的优势在于能够在低带宽情况下保证视频质量,同时在压缩比方面也有较高的表现。
三、编解码器的选择选择正确的编解码器对于视频会议的流畅程度和画质有着至关重要的影响。
目前,常见的编解码器包括x264、x265、ffmpeg 等。
x264是一款开源的H.264/AVC编码器,它的编码速度快,压缩比高,适合在较低带宽环境中进行视频会议。
x265则是x264的升级版,能够更高效地运用CPU的处理能力,同时在保证视频质量的前提下,实现更小的视频文件大小。
而ffmpeg则是一款集多种视频编解码器于一身的开源软件,能够对多种视频编码进行支持,能够应对各种视频会议场景。
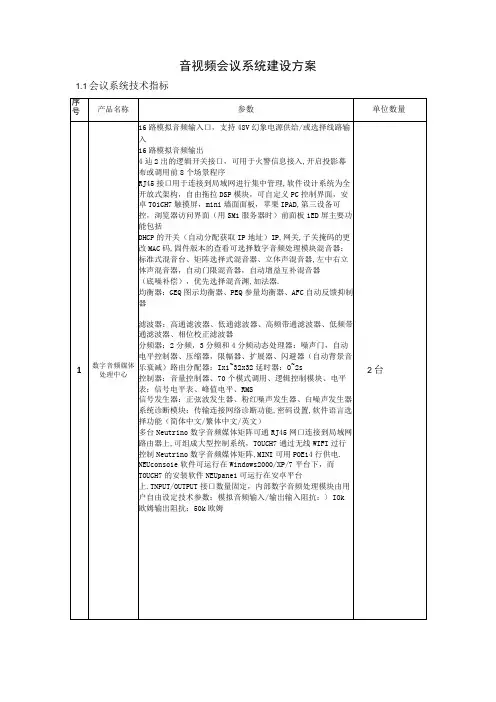
音视频会议系统建设方案1.1会议系统技术指标★1、编码后码流满足在1条千兆网线(或者千兆光纤)上传输内容各不相同的50路108OP@60视频流,,且视频流采用计算机屏幕编码技术以实现4:4:4的全色域采集和输出,达到视觉无损。
无需服务器架构;★2、一路HDMI 或者1路DV1输入,一路HDMI/DP 或者1路DV1环出,RJ45接口带POE 一个,SFP 光纤接口一个,USB3.0接口一个,USB2.0接口一个,安全可靠模块通讯接口一个,3.81凤凰端子的立体声音频输入和输出各•个,3.5mmMIC 接口一个,RS485接口一个,RS232接口一个,三组IO 接口/IR 输出/IR 学习(可配置),继电器三个(支持250V/10A 强电),带螺纹锁定防脱落电源适配器接口1个(5-12V 输入),具有防误动作功能的按键,可实现一键恢复出厂设置。
3、支持虚拟IP 功能:支持多路信号输入的节点,只占用1路网络接II 的情况下,虚拟为每路输入信号产生1路不同IP 地址和MAC 地址;便于系统接入且节省布线和网络资源;4、节点数量不受限制;具备跨网段、跨V1an 通讯能力而无需交换机或者路由渊做任何其他配置★5、在黑色背景下显示红色、蓝色、绿色以及其他颜色5号宋体字与原图无区别;在红色背景下显示黑色、蓝色、绿色以及其他颜色5号宋体字与原图无区别:在蓝色背景下显示黑色、蓝色、绿色以及其他颜色的水平、垂直、斜线极细线(单像素)与原图无区别。
6、节点支持主备(双网口或者光口+网口)热备份功能,输入节点可编码输出两路信号到主备链路,输出节点具备从两个链路接收流的能力;当主链路出现故障时,自动跳转到热备份主机链路,连上主链路后自动恢复,无需人工干预,但跳转过程可以设置信息提示以便处理故障;跳转时间不超过2秒,跳转过程无黑屏和闪屏:主备接口只占用1个IP 地址。
★7、支持综合图像校正、三维空间变换、身体关键点识别、人脸识别、手识别以及手势分类和控制行为推理等功能,无需借助穿戴任何传感器装置,可隔空通过体感控制对大屏做出相当精细、相当严格的互动工作操作。

视频会议原理视频会议是一种通过网络技术实现的实时通信方式,可以方便人们进行远程会议和交流。
视频会议的原理主要涉及以下几个方面:1. 视频传输:视频会议需要将参与者的视频内容传输到对方。
传输视频的常用技术包括流媒体传输、视频编码和解码等。
通过流媒体传输,视频会议可以实现实时的视频播放,而视频编解码则可以将视频压缩为较小的数据包进行传输,节省带宽和时间。
2. 音频传输:除了视频,视频会议还需要传输参与者的音频内容。
音频传输一般通过语音编解码技术实现,将语音信号压缩成较小的数据包进行传输,然后在接收端进行解码,使得参与者可以实时听到对方的声音。
3. 数据传输:视频会议中常常需要共享文档、图片、屏幕等其他数据。
这些数据可以通过网络进行传输,一般使用文件传输协议或者实时传输协议等技术来支持。
4. 网络协议:视频会议的传输需要依赖于网络协议来保证数据的可靠传输和实时性。
常用的协议包括实时传输协议(RTP)、实时控制协议(RTCP)、会话发起协议(SIP)等。
这些协议能够保证视频、音频和数据的实时传输,并且支持会议控制和参与者管理等功能。
5. 系统架构:视频会议需要一套完整的系统架构来实现各种功能,并保证参与者之间的交互和通信。
系统架构包括了视频会议服务器、客户端软件、网络设备等。
服务器负责会议管理、数据传输等核心功能,客户端软件提供用户界面和交互功能,网络设备负责数据传输和网络连接等。
总的来说,视频会议的原理就是通过视频、音频和数据的传输,配合网络协议和系统架构,实现远程会议和交流的目的。
通过这种方式,人们可以在不同地点进行实时的面对面交流,提高了沟通效率和工作效率。

音视频技术的算法和应用随着互联网技术的发展,音视频技术也得到了极大的发展。
从最初的MP3格式音频到现在的高清视频,音视频技术的变革一直未停止。
随着移动互联网的普及,音视频应用也越来越多,我们生活中离不开音视频技术,比如在线音乐、在线视频、音视频会议、远程教育等等。
近年来,各项音视频应用的不断推广,使得音视频技术成为计算机和互联网领域中研究和关注的焦点。
本文将探讨音视频技术中常见的算法和应用。
一、音视频压缩算法音视频压缩算法是实现音视频数据压缩和格式转换、存储和传输的重要技术。
常见的音视频压缩算法包括MPEG、H.264、AAC、MP3等。
其中,MPEG用于视频压缩,能将原始视频码流压缩到原来的1/100左右,是网络视频传输标准之一。
H.264是视频编码的一种压缩标准,相比MPEG-4的视频编解码,H.264有更好的画质和更小的文件大小。
AAC是一种高级音频编码格式,具有高压缩比和保真度好等特点,被广泛应用于各种音频播放器中。
MP3是最常见的音频格式之一,它是对WAV格式的压缩,保留了大部分原始音频信息,而且文件容量很小,是网络音乐及其它音频传输中经常使用的格式。
二、音视频传输和流媒体技术流媒体技术是音视频应用的核心技术之一。
流媒体技术利用网络传输数据,实现音视频的边播边下载。
它是通过流的方式播放网络音频和视频资源,而不用等待整个文件的下载完成。
流媒体内容可以直接播放,无需下载至本地播放器,流畅度更佳。
常見的流媒体協议有RTMP、HLS、RTSP、RTMP等。
RTMP是著名的流媒体协议之一,最大的特点是传输快,实时性好,普及程度高。
HLS是苹果公司提出的一种流媒体传输协议,主要用于移动端的流媒体应用。
RTSP是一种标准的流媒体传输协议,它支持实时播放、流媒体文件的点播和下载。
RTCP是RTP的配套控制协议,主要用于流媒体会议中。
三、音视频处理技术音视频处理是对音视频以及相关信号处理的一项技术。
音视频处理技术是为了对声音和图像进行特定的修改、升级和实现音视频传输所需要的技术。

麦克风阵列技术在声学中的应用随着技术的不断进步,人们对于声音的需求也在不断提高。
因此,在音频领域中,麦克风阵列技术也成为了一个不可忽视的重要技术手段。
麦克风阵列技术可以通过合理的安放多个麦克风,在保证清晰捕捉声音同时降低噪音,提高对声音的分析和理解。
本篇文章将介绍麦克风阵列技术在声学中的应用和优势。
一、麦克风阵列技术的优势麦克风阵列可以将多个麦克风的信号进行合并,提高对声音的采集和识别能力,并在保证捕捉声音清晰的同时,消除环境中的噪声。
具体有以下优势:1、高质量声音麦克风阵列技术可以优化声音质量,使得声音更为清晰,减少噪声和杂音的影响,最终提高对声音的认识和分析能力。
2、大幅降低回声回声是在许多情况下降低音频质量的主要因素之一。
通过使用麦克风阵列的技术,可以有效减少回声,使得声音更为真实和自然。
3、增强方向性麦克风阵列技术还可以提高对声音的方向性,使得录音更加准确,同时降低来自周围环境的噪声,使得录音过程更加精确和方便。
二、麦克风阵列技术在语音识别中的应用麦克风阵列技术在语音识别中应用十分广泛。
由于麦克风阵列可以从不同的角度覆盖到声音的不同部位,从而准确判断声音在空间中的方向和距离,并最终提高语音识别的准确性。
比较常用的语音识别包括:语音助手、计算机自动语音录入、语音控制电子产品等,这些功能都依赖于麦克风阵列技术。
三、麦克风阵列技术在音乐领域的应用麦克风阵列技术也被广泛应用于音乐领域。
由于音乐表现需要高质量的现场效果,渐进方向性和低噪音技术可以保证音乐现场效果的高质量较低的降噪才能保证人的声音和乐器的声音保持纯净。
因此,麦克风阵列技术可以使得音乐现场表演具有更高的准确度,感觉更为强烈。
四、麦克风阵列技术在视频会议中的应用麦克风阵列技术在视频会议中同样具有不可低估的作用。
通过使用多麦克风阵列技术,可以同时识别和过滤多人的声音,在保证声音清晰的同时,避免不同位置和距离的人音频混叠给会议进行带来诸多不便。

视频会议中常出现的几种音频问题及解决方案随着视频会议的使用量不断增加,大家对视频会议的要求也越来越高,针对视频会议,大家都会说视频比较重要,其实不然,视频会议中,音频才是最重要的,以为与会者之间的交流主要是通过音频对话或者讨论实现,视频只要有图片,如果能清晰的表现当然最好,但是最有说服力的肯定是音频,具备好的视频和普通的音频比具备好的音频普通的视频要有用的多。
当然,由于现在对于音频产品的重视程度还不是很高,导致在视频会议过程中,音频出现问题的概率很高,这里,艾力特音频作为资深的会议音频产品专家,也将在为实践中碰到的视频会议音频问题进行一个总结,以便于有问题时能够快速地找到问题缘由。
一.音频通话过程中声音轻这个主要表现为对方传过来的声音很轻,要很费力才能听清楚对方在讲什么。
问题一般出在声音的采集方面,本方可以先测试下自身的扬声器或者喇叭,用本地电脑进行播放测试,看播放的音量是否足够大,如果确定本方音频下行是正常,则可以基本判断问题在于上行,一般可以调整设备输入(录音)音量大小,这需要特别署名,是调节录音音量,实际操作中往往很多人,只会调整喇叭的声音,而不会用录音音量的大小调节。
二.音频通话过程中噪声比较大噪声的大小,主要有两个方面的影响,一是会议过程中,可能存在风扇,空调等噪声源,而一般的会议类音频拾音产品都不会有特别的噪声处理,导致噪声都拾取进来,第二,就是音频上行,录音的音量太大,导致了轻微的动作都有较大的声音采集,引起噪声,当然,有时候会议软件中有一些功能,比如降噪,静噪等功能开启时,若和软件冲突,也容易引起噪声。
三.视频会议过程中能够听到自己的声音视频会议过程中,发现能够听到自己的声音又传回来了,例如很多手机当用免提的时候,也很容易出现该种情况,这类主要是音频设备没有选择好。
虽然现在的视频会议软件都拥有消除回声功能,但是没有一个能够真正将回声消除的,所以还需要后前端的音频设备来匹配,比如艾力特音频的全向麦克风,需要其自带回声消除功能,这样才能确保对方的声音从喇叭出来,不会从产品的拾音部位又传出,导致回声。

论视频会议系统详细技术参数视频会议系统是一种利用音视频传输技术,实现远程交流与协作的系统。
它通过网络连接远程的参与者,通过音视频传输技术实现视觉和听觉的交流。
在实际应用中,视频会议系统的性能与技术参数直接影响着用户体验和系统的可靠性。
下面将详细介绍视频会议系统的技术参数。
1.视频质量:视频质量是评估视频会议系统性能的主要指标之一、它取决于视频传输的分辨率、帧率和编解码算法。
分辨率指视频图像的清晰度,常见的分辨率有720p、1080p等。
帧率指视频播放的平滑程度,常见的帧率有30fps、60fps等。
编解码算法决定了视频压缩和解压缩的效率和质量。
视频质量的提高可以通过增加带宽、改进编解码算法和优化网络传输等方式实现。
2.音频质量:音频质量是评估视频会议系统性能的另一个重要指标。
它取决于音频传输的采样率、位深和编解码算法。
采样率指音频信号每秒钟采样的次数,常见的采样率有8kHz、16kHz等。
位深指音频信号的每个样本使用的比特数,常见的位深有8位、16位等。
编解码算法决定了音频压缩和解压缩的效率和质量。
音频质量的提高可以通过增加带宽、改进编解码算法和优化网络传输等方式实现。
3.带宽需求:视频会议系统对网络带宽的需求较高,直接影响着视频质量和音频质量的保证。
视频会议系统的带宽需求主要包括上行带宽和下行带宽。
上行带宽指本地用户向服务器发送数据的带宽,下行带宽指服务器向本地用户发送数据的带宽。
带宽需求的大小由视频质量、音频质量和用户数等因素决定。
一般来说,视频会议系统的带宽需求在2Mbps到10Mbps之间。
4.网络延迟:网络延迟是指数据从发送端到接收端所需的时间。
视频会议系统对网络延迟要求较低,以确保实时性和流畅性。
网络延迟的大小取决于网络传输的速度和传输路径的拥堵程度。
一般来说,视频会议系统的网络延迟应控制在100ms到300ms之间。
5.兼容性:视频会议系统的兼容性指其能够与不同品牌和型号的设备进行互操作的能力。
第1章.视频会议简介1.1视频会议的组成部分:1.1.1视频会议整体构架图:如上图:视频会议组成部分由核心网络构件以及终端部分组成。
1.1.2核心网络构件:多点控制单元MCU。
视频控制服务器VCS以及网络管理套件TMS。
1.1.3终端部分分为:会议室视频终端、桌面终端、软终端以及特殊应用终端。
1.2视频会议方案特点1.2.1高清视频会议(1)、高清晰度性能展现高清( H.264 ,30-60帧/秒,画面上实现 720P 1280×720像素和1080P 1920×1080像素)的分辨率使每个与会者感受到栩栩如生,身临其境的图像效果。
音频采用MPEG-4 AAC-LD,频响范围高达20KHz,支持多标准宽频音频与高分辨率数据会议。
16:9宽屏视频输出,可视面积增加33%,更加符合人眼观赏习惯高清HD标准,主要包括720P(1280×720p),1080i(1920×1080i),1080P(1920×1080P)三种标准。
相比传统意义的标清会议质量,高清HD 720P和1080P大幅度提升标清会议质量,从下图中,可以清晰的看到4:3标清(QCIF/CIF/4CIF)和高清(720P)之间的图像质量差别:(2)、极致高清1080P高清(High Definition)是视频通信业界目前提供的最为领先的视频体验。
高清主要分为两种标准:720P和1080P。
TANDBERG提供业界最为领先的,也是唯一的全套1080P解决方案。
相比720P图像质量(9.5倍CIF质量),1080P图像质量(20倍CIF质量)有了大幅度的提升。
不仅仅是点对点的1080P高清视频体验,TANDBERG提供业界顶尖的1080P 高清视频会议编解码器 C90、C40、C40、C20;以及真正的高清1080P MCU:TANDBERG MSE8000,从而提供用户真正的全套高清1080P解决方案。
音视频会议接入方案1. 引言在当今信息化的时代,音视频会议已经成为企业协作和沟通的重要方式。
通过音视频会议可以实现远程的会议、培训和沟通,提高工作效率和团队协作能力。
本文将介绍一种音视频会议接入方案,详细说明其技术原理和实施步骤。
2. 技术原理音视频会议接入方案基于互联网和网络通信技术,实现了远程的音频和视频传输。
其主要技术原理包括:2.1 网络传输:音视频数据通过Internet网络传输,可以使用传统的局域网连接或者云端服务提供商的专用网络连接。
2.2 编解码:音视频数据需要经过编解码处理,以便在网络上传输和播放。
常用的编解码协议包括H.264和AAC等。
2.3 QoS保证:为了确保音视频数据的实时性和稳定性,需要使用合适的网络协议和机制,如RTP/RTCP、SRTP等。
3. 实施步骤3.1 网络规划:根据企业实际情况规划网络架构,确保网络的稳定性和带宽的充足性。
可以考虑引入云端服务提供商,利用其专用网络连接。
3.2 选型和设备配置:根据会议需求和实际预算,选择合适的音视频会议平台和终端设备。
可以考虑部署会议室终端、个人终端和移动终端等。
3.3 系统集成:将音视频会议平台和终端设备与企业现有的通信系统进行集成,确保各个系统的兼容性和流畅度。
3.4 安全保障:加强网络安全防护,使用防火墙和加密通信等手段,保护音视频会议的机密性和稳定性。
3.5 培训和推广:对企业员工进行音视频会议的培训和推广,提高其使用技巧和意识,确保会议效果的提升。
4. 实施效果通过实施音视频会议接入方案,企业可以获得以下实施效果:4.1 节约成本:远程会议减少了出差和住宿等费用,节约了企业的成本开支。
4.2 提高效率:音视频会议可以随时随地进行,无需等待和调整日程安排,提高了会议的效率和灵活性。
4.3 加强协作:团队成员可以远程参与会议和共享文件,提高了跨地域协作的能力。
4.4 降低碳排放:减少了长途出差和交通拥堵等问题,对环境保护有积极意义。
华为会议系统技术方案华为会议系统技术方案随着大数据、人工智能等新一代信息技术的发展,企业需要更加高效、协作、智能的会议系统来提高沟通和决策效率。
华为作为全球领先的信息通信技术解决方案供应商之一,不断推出创新性的会议系统技术方案,满足用户的多种需求,提升用户体验。
本文将介绍华为会议系统技术方案的主要特点和优势。
1. 视频会议技术华为视频会议技术支持多方视频会议、远程协作、云端会议等多种会议场景,可以在不同地点的用户之间进行高清晰度视频会议,支持多种终端设备接入,包括PC、手机、平板等,用户可以随时随地参与会议。
华为的视频会议技术采用智能码流算法,可根据网络条件自适应码流,确保视频质量稳定流畅。
2. 会场音频技术华为的会场音频技术采用DSP数字语音处理技术,能够自动消除环境噪声,减少回声和啸叫,让会议音质更加清晰、自然,提高音质体验。
此外,华为会议系统还支持远距离麦克风和自动跟踪摄像机技术,在大型会议场合能够自动识别发言人,实现全场景语音音质升级。
3. 视频会议控制平台技术华为的视频会议控制平台技术支持集中管理和控制多个视频会议终端,可以实现远程开启、关闭、修改会议设置等控制功能,提升了会议组织和管理的效率。
此外,华为的控制平台还支持多个视频会议终端之间的互通性,实现多地点视频会议协作,创新的混合组网技术支持私有云模式和公有云模式的混合组网,满足不同用户的需求。
4. 人工智能技术华为的人工智能技术探索智能语音助手、图像识别等技术应用于会议系统中。
例如,智能语音助手可以实现语音控制会议开启和关闭等功能,为用户创造便捷的控制体验;图像识别技术则可以自动识别并标注参与会议的人员等信息,提高信息整合能力和智能化协作效率。
总之,华为会议系统技术方案综合运用了多种前沿技术,满足了企业和用户对高效、协作、智能会议的需求。
在未来,随着技术的不断更新迭代,华为将继续不断创新,为用户提供更加出色的会议体验。
音视频信号处理技术的原理与实践应用随着科技的不断发展,音视频信号处理技术越来越成熟,也变得越来越重要。
在我们的生活中,音视频信号处理技术无处不在,它已经深入我们的生活,大大改变了我们的生活方式。
本文将从原理与实践两个方面来探讨这个话题。
一、音视频信号处理技术的原理音视频信号处理技术是一种将音频和视频信号进行编解码以及处理的技术。
音频和视频信号制作原理基本相同,都是由一系列模拟信号组成的。
音频信号是由一系列声波产生的剖面图像,在接受者接收到信号后,通过解码进行转换,然后被放大到我们能够听见的音量。
视频信号同样是由一系列图像产生的,被发送者编码后再传输,接收者解码后再将图像显示在屏幕上。
音视频信号处理技术的原理可以概括为:先将模拟信号转换为数字信号,再将数字信号进行编解码、压缩等处理,最后在接收端再将信号还原为模拟信号。
在音频信号处理中,最常见的编码方式是PCM编码方式。
PCM编码将音频模拟信号转换为数字信号,然后以一定的速率传输数据。
传输数据时,会根据声音的频率和音量将数据分成多个小块,每个小块的数据都能被用来还原原始的声音信号。
今天,除了PCM编码外,还出现了一些更高效的音频编码器,如MP3、AAC、WMA等。
视频信号很大一部分是由RGB三种原色组成的,这三种颜色的不同比例就可以形成各种图像。
通常视频信号的处理步骤中,先对RGB信号进行采样、量化等处理,然后对视频进行编码压缩,再将压缩后的视频数据通过网络实时传输。
总之,音视频信号处理技术的原理就是数字化和压缩图像,以便更有效地传输和存储信号。
二、音视频信号处理技术的实践应用音视频信号处理技术及其应用非常广泛,下面列举几个我们常见生活中的例子:1. 视频会议技术随着全球化的发展,视频会议技术逐渐被广泛接受。
视频会议技术通过音视频信号处理,将会议的每个参与者显示在屏幕上面。
视频会议还可以通过共享桌面、文件等多种方式演示资料。
2. 录音、录像技术在音视频信号处理技术的帮助下,我们可以很方便地进行录音、录像。
视频会议系统中的音频质量影响因素分析与优化音频质量在视频会议系统中扮演着至关重要的角色,它直接影响着会议参与者之间的沟通效果和会议的顺利进行。
本文将对视频会议系统中的音频质量影响因素进行分析,并探讨如何进行优化以提高音频质量。
一、网络带宽网络带宽是视频会议系统中最基本的影响音频质量的因素之一。
带宽决定了音频数据传输的速度和稳定性。
当网络带宽不足时,音频数据传输可能会出现延迟、丢包或抖动,从而导致音频质量下降。
为了解决这个问题,可以通过提高网络带宽或采用更先进的网络传输技术来优化音频质量。
二、网络延迟网络延迟指的是音频数据从发送端到接收端所经历的时间。
高延迟会导致会议参与者之间的通话出现明显的延迟感,降低沟通效果。
减小网络延迟可以通过以下方法进行优化:优化网络拓扑结构、采用更快速的传输协议、提高网络设备的性能等。
三、音频编解码算法音频编解码算法对音频质量具有重大影响。
常见的音频编解码算法包括G.711、G.729、AAC等。
这些算法根据不同的压缩率和音质要求来选择。
较低的压缩率可以提高音频质量,但会占用更多的网络带宽。
在选择音频编解码算法时,需要根据实际需求进行权衡。
四、麦克风和扬声器麦克风和扬声器是音频输入和输出的关键设备。
低质量的麦克风和扬声器会导致音频信号的失真、噪音或回音。
为了提高音频质量,应选择质量良好的麦克风和扬声器,并进行适当的位置设置和音量调节。
五、环境噪音环境噪音会干扰音频信号的传输和接收,影响音频质量。
在视频会议中,环境噪音可能来自其他参与者的语音、键盘声等。
为了降低环境噪音的影响,可以采用降噪技术或提供良好的会议环境,减少干扰源。
六、网络抖动网络抖动指的是音频数据传输过程中出现的不连续性,表现为音频声音忽大忽小或中断的情况。
网络抖动严重影响音频的连续性和清晰度。
优化网络抖动可以通过使用网络传输协议中的抖动缓冲区、进行网络阻塞管理等方法来实现。
七、网络丢包网络丢包是指音频数据在传输过程中丢失的现象。
高清视频会议系统技术方案目录一、视讯技术发展及应用需求 (2)1.1视频 (2)1.2音频 (2)1.3组网 (2)二、系统技术设计方案 (3)2.1建设目标 (3)2.2系统拓扑结构图 (4)2.3、网点建设方案 (6)2.4、会议管理 (7)2.5网络质量及带宽的要求 (7)2.6设备清单 (8)2.7投资估算 (11)三、高清视频系统会议室布置及装修建议 (11)3.1会议室的布局 (11)3.2会议室照度 (12)3.3会议室的音响效果 (13)3.4会议室的电声设计 (13)3.5会议室供电系统 (14)一、视讯技术发展及应用需求视频会议系统通过传输音频、视频和数据信息,实现了远程的实时沟通。
随着高清、超高清、眼对眼、多声道音频等高临场感技术的发展,高清视频会议在各大行业得到大规模应用,提升了企业沟通效率,节省了运营成本,提高了管理成效。
1.1视频视频协议从H.261、H.263发展到主流的H.264HP协议,图像分辨率从90年代的VCD 级(CIF)发展到超高清(1080P),图像帧率由30帧/秒提高到60帧/秒,使得视频会议的图像质量有了质的飞跃。
1.2音频音频协议从G.711、G.722、G.728发展到宽频语音协议。
宽频语音技术具有高保真、低延时、多声道等特点,给视频会议用户带来了高临场感体验。
1.3组网主流的多媒体通信协议有:H.320、H.323和SIP,能够实现高清、标清、桌面视频、PC或移动视频等混合视频会议,随着通信协议的发展,视频会议的组网也越来越丰富。
以下介绍一下几个主流的组网协议:H.320:H.320系统是适合电路交换网络的专用解决方案,采用E1或ISDN线路,专网专用,确保系统稳定性、可靠性和图像的高质量。
该方案价格高,属于专用系统,适合会场点数少,会议业务量大的企业、政府单位。
⏹H.323:H.323系统是适合分组交换网络的开放式解决方案,采用IP线路,具有良好的兼容性和互通性。
视频系统术语---音频技术音频技术视频通讯过程是视频和音频的实时双向完整通讯过程。
在这个过程中我们为了获得高清晰视频图像,有时却忽略了另外一个重要的过程——音频通讯过程。
如果我们在观看高清晰视频图像的时候,不能得到一个更清晰、连续的音频效果。
那么这个过程实际上就没有任何意义,所以其重要性甚至超过视频。
在传统的视频会议系统中音频技术发展极其缓慢,原因在于目前应用于视频通讯的音频编解码压缩标准都是为了保持传输时的低带宽占用和较高的编解码效率,从而将音频信号的采样频率、采样精度和采样范围指标做了极大的降低,使得所能提供的音频清晰度和还原性都有很大程度上的衰减。
与用于存储和回放非实时压缩协议的标准(如OGG、MP3等)相比,音频的保真度非常低。
这样就在某种程度上对现场声音的还原达不到要求。
目前传统视频通讯过程中主要采用的是G.711、G.722、G.721、G.728等音频标准,音频宽度仅有50Hz-7KHz单声道,而人耳所能感知的自然界的频响能力可以达到20Hz-20KHz,因此,在对现场环境音的还原过程中过多的音频信息的丢失造成了无法真实表现现场情况。
所以在高清晰视频通讯过程中我们势必要有一种相辅助的音频处理方式解决此问题。
使整个高清晰通讯过程更去近于完美。
目前国际上对音频处理技术上标准较多,在对下一代实时交互音频处理上可以采用MPEG-1 Layer 2或AAC 系列音频,对选用标准的原则是,音频频响范围要达到22KHz,这样就几乎可以覆盖了人耳听觉的全部范围,甚至在高频方面还有所超越,能够使现场音频得到真实自然的还原,并且在还原时可以采用双声道立体声回放,使整个视频通讯的声音有更强的临近感,达到CD级音质。
同时在对链路带宽的适应和编解码效率上达到最佳。
下面是各种音频编码标准的说明:1G.711类型:Audio制定者:ITU-T所需频宽:64Kbps特性:算法复杂度小,音质一般优点:算法复杂度低,压缩比小(CD音质>400kbps),编解码延时最短(相对其它技术)缺点:占用的带宽较高备注:70年代CCITT公布的G.711 64kb/s脉冲编码调制PCM。
2G.721制定者:ITU-T所需带宽:32Kbps音频频宽:3.4KHZ特性:相对于PCMA和PCMU,其压缩比较高,可以提供2:1的压缩比。
优点:压缩比大缺点:声音质量一般备注:子带ADPCM(SB-ADPCM)技术。
G.721标准是一个代码转换系统。
它使用ADPCM转换技术,实现64 kb/s A律或μ律PCM速率和32 kb/s速率之间的相互转换。
3G.722制定者:ITU-T所需带宽:64Kbps音频宽度:7KHZ特性:G722能提供高保真的语音质量优点:音质好缺点:带宽要求高备注:子带ADPCM(SB-ADPCM)技术4G.721制定者:ITU-T所需带宽:32Kbps/24Kbps音频宽度:7KHZ特性:可实现比G.722 编解码器更低的比特率以及更大的压缩。
目标是以大约一半的比特率实现 G.722 大致相当的质量。
优点:音质好缺点:带宽要求高备注:目前大多用于电视会议系统。
5G.721附录C制定者:ITU-T所需带宽:48Kbps/32Kbps/4Kbps音频宽度:14KHZ特性:采用自Polycom 的Siren™14 专利算法,与早先的宽频带音频技术相比具有突破性的优势,提供了低时延的14 kHz 超宽频带音频,而码率不到MPEG4 AAC-LD 替代编解码器的一半,同时要求的运算能力仅为十分之一到二十分之一,这样就留出了更多的处理器周期来提高视频质量或者运行因特网应用程序,并且移动设备上的电池续航时间也可延长。
优点:音质更为清晰,几乎可与CD 音质媲美,在视频会议等应用中可以降低听者的疲劳程度。
缺点:是Polycom的专利技术。
备注:目前大多用于电视会议系统6G.723(低码率语音编码算法)制定者:ITU-T所需带宽:5.3Kbps/6.3Kbps音频宽度:3.4KHZ特性:语音质量接近良,带宽要求低,高效实现,便于多路扩展,可利用C5402片内16kRAM实现53coder。
达到ITU-TG723要求的语音质量,性能稳定。
可用于IP电话语音信源编码或高效语音压缩存储。
优点:码率低,带宽要求较小。
并达到ITU-TG723要求的语音质量,性能稳定。
缺点:声音质量一般备注:G.723语音编码器是一种用于多媒体通信,编码速率为5.3kbits/s和6.3kbit/s的双码率编码方案。
G.723标准是国际电信联盟(ITU)制定的多媒体通信标准中的一个组成部分,可以应用于IP电话等系统中。
其中,5.3kbits/s码率编码器采用多脉冲最大似然量化技术(MP-MLQ),6.3kbits/s码率编码器采用代数码激励线性预测技术。
7G.723.1(双速率语音编码算法)制定者:ITU-T所需带宽:5.3Kbps(29)音频宽度:3.4KHZ特性:能够对音乐和其他音频信号进行压缩和解压缩,但它对语音信号来说是最优的。
G.723.1采用了执行不连续传输的静音压缩,这就意味着在静音期间的比特流中加入了人为的噪声。
除了预留带宽之外,这种技术使发信机的调制解调器保持连续工作,并且避免了载波信号的时通时断。
优点:码率低,带宽要求较小。
并达到ITU-TG723要求的语音质量,性能稳定,避免了载波信号的时通时断。
缺点:语音质量一般备注:G.723.1算法是ITU-T建议的应用于低速率多媒体服务中语音或其它音频信号的压缩算法,其目标应用系统包括H.323、H.324等多媒体通信系统。
目前该算法已成为IP电话系统中的必选算法之一。
8G.728制定者:ITU-T所需带宽:16Kbps/8Kbps音频宽度:3.4KHZ特性:用于IP电话、卫星通信、语音存储等多个领域。
G.728是一种低时延编码器,但它比其它的编码器都复杂,这是因为在编码器中必须重复做50阶LPC分析。
G.728还采用了自适应后置滤波器来提高其性能。
优点:后向自适应,采用自适应后置滤波器来提高其性能缺点:比其它的编码器都复杂备注:G.728 16kb/s短延时码本激励线性预测编码(LD-CELP)。
1996年ITU公布了G.728 8kb/s的CS-ACELP算法,可以用于IP电话、卫星通信、语音存储等多个领域。
16 kbps G.728低时延码激励线性预测。
G.728是低比特线性预测合成分析编码器(G.729和G.723.1)和后向ADPCM编码器的混合体。
G.728是LD-CELP编码器,它一次只处理5个样点。
对于低速率(56~128 kbps)的综合业务数字网(ISDN)可视电话,G.728是一种建议采用的语音编码器。
由于其后向自适应特性,因此G.728是一种低时延编码器,但它比其它的编码器都复杂,这是因为在编码器中必须重复做50阶LPC分析。
G.728还采用了自适应后置滤波器来提高其性能。
9G.729制定者:ITU-T所需带宽:8Kbps音频宽度:3.4KHZ特性:在良好的信道条件下要达到长话质量,在有随机比特误码、发生帧丢失和多次转接等情况下要有很好的稳健性等。
这种语音压缩算法可以应用在很广泛的领域中,包括IP电话、无线通信、数字卫星系统和数字专用线路。
G.729算法采用“共轭结构代数码本激励线性预测编码方案”(CS-ACELP)算法。
这种算法综合了波形编码和参数编码的优点,以自适应预测编码技术为基础,采用了矢量量化、合成分析和感觉加权等技术。
G.729编码器是为低时延应用设计的,它的帧长只有10ms,处理时延也是10ms,再加上5ms的前视,这就使得G.729产生的点到点的时延为25ms,比特率为8 kbps。
优点:语音质量良,应用领域很广泛,采用了矢量量化、合成分析和感觉加权,提供了对帧丢失和分组丢失的隐藏处理机制。
缺点:在处理随机比特错误方面性能不好。
备注:国际电信联盟(ITU-T)于1995年11月正式通过了G.729。
ITU-T建议G.729也被称作“共轭结构代数码本激励线性预测编码方案”(CS-ACELP),它是当前较新的一种语音压缩标准。
G.729是由美国、法国、日本和加拿大的几家著名国际电信实体联合开发的。
10G.729A制定者:ITU-T所需带宽:8Kbps(34.4)音频宽度:3.4KHZ特性:复杂性较G.729低,性能较G.729差。
优点:语音质量良,降低了计算的复杂度以便于实时实现,提供了对帧丢失和分组丢失的隐藏处理机制缺点:性能较G.729差备注:96年ITU-T又制定了G.729的简化方案G.729A,主要降低了计算的复杂度以便于实时实现,因此目前使用的都是G.729A。
11 MPEG-1 audio layer 1制定者:MPEG所需带宽:384kbps(压缩4倍)音频宽度:特性:编码简单,用于数字盒式录音磁带,2声道,VCD中使用的音频压缩方案就是MPEG-1层Ⅰ。
优点:压缩方式相对时域压缩技术而言要复杂得多,同时编码效率、声音质量也大幅提高,编码延时相应增加。
可以达到“完全透明”的声音质量(EBU音质标准)缺点:频宽要求较高备注:MPEG-1声音压缩编码是国际上第一个高保真声音数据压缩的国际标准,它分为三个层次:--层1(Layer 1):编码简单,用于数字盒式录音磁带--层2(Layer 2):算法复杂度中等,用于数字音频广播(DAB)和VCD等--层3(Layer 3):编码复杂,用于互联网上的高质量声音的传输,如MP3音乐压缩10倍12MPEG-1 audio layer 2,即MP2制定者:MPEG所需带宽:256~192kbps(压缩6~8倍)音频宽度:特性:算法复杂度中等,用于数字音频广播(DAB)和VCD等,2声道,而MUSICAM由于其适当的复杂程度和优秀的声音质量,在数字演播室、DAB、DVB等数字节目的制作、交换、存储、传送中得到广泛应用。
优点:压缩方式相对时域压缩技术而言要复杂得多,同时编码效率、声音质量也大幅提高,编码延时相应增加。
可以达到“完全透明”的声音质量(EBU音质标准)缺点:备注:同MPEG-1 audio layer 113MPEG-1 audio layer 3(MP3)制定者:MPEG所需带宽:128~112kbps(压缩10~12倍)音频宽度:特性:编码复杂,用于互联网上的高质量声音的传输,如MP3音乐压缩10倍,2声道。
MP3是在综合MUSICAM 和ASPEC的优点的基础上提出的混合压缩技术,在当时的技术条件下,MP3的复杂度显得相对较高,编码不利于实时,但由于MP3在低码率条件下高水准的声音质量,使得它成为软解压及网络广播的宠儿。
优点:压缩比高,适合用于互联网上的传播缺点:MP3在128KBitrate及以下时,会出现明显的高频丢失备注:同MPEG-1 audio layer 114MPEG-2 audio layer制定者:MPEG所需带宽:与MPEG-1层1,层2,层3相同音频宽度:特性:MPEG-2的声音压缩编码采用与MPEG-1声音相同的编译码器,层1, 层2和层3的结构也相同,但它能支持5.1声道和7.1声道的环绕立体声。