GPU浮点性能排行
- 格式:docx
- 大小:88.09 KB
- 文档页数:38


GPU浮点性能排⾏Game Consoles GPUConsoles Name GPU Name Fab Clock GFlops NDS ARM946E-S (CPU) 180/130nm 67 MHz 0.6N3DS PICA 200 45nm 200 MHz 4.8PSP R4000 x 2 90nm 333 MHz 2.6PS VITA SGX543 MP4+ 45nm 400 MHz 51.2 Dreamcast PowerVR2 CLX2 250nm 100 MHz 1.4XBOX XGPU (NV2A) 150nm 233 MHz 20XBOX360 ATI R500 Xenos 90/65/45nm 500 MHz 240AMD Radeon GCNXBOX ONE28nm 853 MHz 1311.5(768 Cores)PlayStation 2 GS 180/150/90nm 147 MHz 6.2 (EE+GS) PlayStation 3 RSX (NVIDIA G70) 90/65/45nm 550 MHz 228.8 PlayStation 4 AMD Radeon GCN 28nm 800 MHz 1840(1152 Cores)N64 SGI RCP 350nm 62.5 MHz 0.1~0.2 GameCube Flipper 180nm 162 MHz 8Wii ATI HollyWood 90nm 243 MHz 12Wii U ATI RV770 40nm 550 MHz 352 OuyaGeforce ULP x 12(Tegra 3)40nm 520 Mhz 12.5Nvidia Shield M.O.J.O Geforce ULP x 72(Tegra 4)28nm 672 MHz 96.8Mobile GPU (Imagination PowerVR)GPU Name Chip Clock GFlopsSGX530 OMAP 3530 110 MHz 0.88 DM3730 200 MHz 1.6 --- 300 MHz 2.4SGX531 MT6513MT6573MT6575M281 MHz 2.25 R-Car E1 400 MHz 3.2SGX531 Ultra MT6515MT6575MT6517MT6517TMT6577MT6577TMT8317MT8317TMT8377522 MHz 4.2SGX535 Apple A4 200 MHz 1.6 Apple A4 (iPad) 250 MHz 2.0 --- 300 MHz 2.4SGX540Jz4780 MHzExynos 3110 200 MHz 3.2OMAP 4430 307 MHz 4.9OMAP 4460 384 MHz 6.1Atom Z2420R-Car E2R-Car M1A、M1S400 MHz 6.4ATM7021ATM7021AATM7029B500 MHz 8.0RK3168 600 MHz 9.6 SGX543 --- 200 MHz 6.4SGX543 MP2 Apple A5 200 MHz 12.8 Apple A5 (iPad2) 250 MHz 16.0 MT5327 400 MHz 25.6 R-Car H1 520 MHz 33.28 SGX543 MP3 Apple A6 266 MHz 25.5 SGX543 MP4 Apple A5X 250 MHz 32.0SGX544 MT6589M 156 MHz 5MT8117MT8121MT6589MT8389286 MHz 9.2 MT8125 300 MHz 9.6 MT6589TMT8389T357 MHz 11.4 OMAP 4470 384 MHz 12.3 Broadcom M320Broadcom M340ATM7039 450 MHz 14.4SGX544 MP2 Atom Z2520 300 MHZ 19.2 Allwinner A31Allwinner A31s350 MHz 22.4 Atom Z2560 400 MHz 25.6 R-Car M2 520 MHz 33.28 Atom Z2580 533 MHz 34.1 Allwinner A83T Allwinner H8700 MHz 44.8SGX544 MP3 Exynos 5410 533 MHz 51.1SGX545 --- 300 MHz 4.8 Atom Z2460Atom Z2760533 MHz 8.5SGX554 --- 300 MHz 19.2 SGX554 MP2 --- 300 MHz 38.4 SGX554 MP4 Apple A6X 266 MHz 68.1G6020(0.25 Clusters)--- 300 MHz 4.8G6050G6060(0.5 Clusters)--- 300 MHz 9.6G6100G6110RK3368 600 MHz 38.4(1 Clusters)G6200(2 Clusters) MT6595MMT8135450 MHz 57.6 MT6795M 550 MHz 70.4 MT6595MT6595T600 MHz 76.8 MT6793MT6795MT6795T(Helio X10)700 MHz 89.6G6230(2 Clusters) Allwinner A80Allwinner A80T533 MHz 68.0 ATM9009 600 MHz 76.8GX6240(2 Clusters)--- 650 MHz 83.2GX6250 (2 Clusters) MT8173 600 MHz 76.8 MT8176 700 MHz 89.6 MT6795X (Helio X12) 750 MHz 96 G6400(4 Clusters) --- 300 MHz 76.8 Atom Z3460Atom Z3480533 MHz 136.4 R-Car H2 600 MHz 153.6G6430(4 Clusters) --- 300 MHz 76.8 Apple A7Apple A7 (iPad Air)450 MHz 115.2 Atom Z3530 457 MHz 117 Atom Z3560Atom Z3580533 MHz 136.4 Atom Z3570Atom Z3590640 MHz 163.8GX6450 (4 Clusters) Apple A8 450 MHz 115.2 --- 600 MHz 153.6G6630(6 Clusters) --- 450 MHz 172.8 --- 600 MHz 230.4GX6650 R-Car H3 600 MHz 230.4GX6850 (8 Clusters) Apple A8X 450 MHz 230.4 --- 600 MHz 307.2GE7400(0.5 Clusters)--- 600 MHz 19.2 GE7800(1 Clusters)--- 600 MHz 38.4GT7200(2 Clusters)--- 650 MHz 83.2 GT7400(4 Clusters)--- 650 MHz 166.4 GT7600(6 Clusters)Apple A9 450 MHz 172.8 GT7800(8 Clusters)--- 650 MHz 332.8 GT7800+ Apple A9X 450 MHz 345.6GT7900 (16 Clusters) --- 650 MHz 665.6 --- 800 MHz 819.2Mobile GPU (Qualcomm Adreno)GPU Name Chip Clock GFlops Adreno 130 MSM7x01MSM7x01A133 MHz 1.2Adreno 200 MSM7225MSM7625MSM7227MSM7627QSD8250QSD8650(Snapdragon S1)133 MHz 2.1MSM7225AMSM7625A(Snapdragon S1)200 MHz 3.2MSM7227AMSM7627A(Snapdragon S1)245 MHz 3.92Adreno 203 MSM8225MSM8625(Snapdragon S4 Play)245 MHz 7.84MSM8225QMSM8625Q(Snapdragon 200)294 MHz 9.4Adreno 205 MSM7230MSM7630MSM8255MSM8655APQ8055(Snapdragon S2)266 MHz 8.5266MHz 17APQ8060 (Snapdragon S3) APQ8026 (Snapdragon 400) Adreno 225 MSM8260AAPQ8060A(Snapdragon S4 Plus)200 MHz 12.8MSM8660A(Snapdragon S4 Plus)300 MHz 19.2 MSM8960(Snapdragon S4 Plus)400 MHz 25.6Adreno 302 MSM8210MSM8610MSM8212MSM8612(Snapdragon 200)400 MHz 12.8Adreno 304 (Snapdragon 208) 400 MHz 21.6 (Snapdragon 210) (Snapdragon 212) (Snapdragon Wear 2100) Adreno 305 MSM8227MSM8627(Snapdragon S4 Plus)MSM8226MSM8626MSM8230MSM8630MSM8930MSM8030ABMSM8230ABMSM8630ABMSM8930AB(Snapdragon 400)MSM8928(Snapdragon 400)450 MHz 24.3Adreno 306MSM8916(Snapdragon 410)450 MHz 24.3 Adreno 308 MSM8917(Snapdragon 425)MHzAdreno 320 (64 ALU) MSM8960T APQ8064APQ8064 1AA (Snapdragon S4 Pro)MPQ8064(Snapdragon S4 Prime)400 MHz 57.6Adreno 320 (96 ALU) APQ8064T (Snapdragon 600)400 MHz 86.4 APQ8064AB (Snapdragon 600、602A)450 MHz 97.2Adreno 330APQ8074MSM8974AA450 MHz 129.6 (Snapdragon 800)MSM8274ABMSM8974AB(Snapdragon 801)550 MHz 158.4MSM8974AC578 MHz 166.5 Adreno 405 MSM8929 (Snapdragon 415) MSM8936 (Snapdragon 610) MSM8939 (Snapdragon 615) MSM8939v2 (Snapdragon 616) MSM8952 (Snapdragon 617)550 MHz 59.4Adreno 418MSM8992 (Snapdragon 808)600 MHz 172.8 Adreno 420APQ8084 (Snapdragon 805)500~600 MHz 144~172.8 Adreno 430 APQ8094 MSM8994 (Snapdragon 810)600~630 MHz 388.8~408 Adreno 505 MSM8937 (Snapdragon 430) MSM8940 (Snapdragon 435)MHzAdreno 506MSM8953 (Snapdragon 625)MHzAdreno 510 MSM8956MSM8976(Snapdragon 652)600 MHzAdreno 530MSM8996(Snapdragon 820、820A)650~736 MHz 588Mobile GPU (Nvidia Tegra)GPU Name Chip Fab Clock GFlopsGeforce ULP x 8 Tegra 2(AP20H)40nm 300 MHz 4.8 Tegra 2(T20)40nm 333 MHz 5.6 Tegra 2(AP25、T25)40nm 400 MHz 6.7Geforce ULP x 12 Tegra 3(T30L、AP33)40nm 416 MHz 10 Tegra 3 40nm 450 MHz 10.8 Tegra 3(T30、T33、AP37)40nm 520 MHz 12.5Geforce ULP x 60 Tegra 4i 28nm 660 MHz 79.2 Geforce ULP x 72 Tegra 4 28nm 672 MHz 96.8 Kepler Cores x 192 (1xSMX) Tegra K1Tegra K1 (Denver)28nm 850 MHz 326.4Maxwell Cores x 256(2xSMM) Tegra X1 20nm850 MHz1000 MHz435.2512Pascal Cores x Tegra P1? 16nm MHzMobile GPU (Arm Mali)GPU Name Chip Clock GFlopsMali-400 --- 200 MHz 1.8 AML8726-M3 250 MHz 2.25 ST-E U8500 275 MHz 2.48 WM8950SC6815ASC7710SC8810300 MHz 2.7 SC9620Allwinner A10Allwinner A10sAllwinner A13RK292X 330 MHz 2.97 SC7715SC7727SST-E U8520Telechips TCC892x-iRk2926400 MHz 3.6 RK2928MT6290MT8638TMT6572MMT6570500 MHz 4.5 MT6572。

gpu中的流处理器和浮点运算单元GPU中的流处理器和浮点运算单元在当今计算机技术飞速发展的时代,图形处理器单位(GPU)已经成为了现代计算机体系中不可或缺的一部分。
GPU的设计和功能在不断地演变和改进,而其中的两个核心部分——流处理器和浮点运算单元更是成为了GPU性能的重要指标。
在本文中,我们将深入探讨GPU 中的流处理器和浮点运算单元,并分析它们在现代计算机中的作用和意义。
一、流处理器1. 流处理器的概念流处理器是GPU中的一个重要部分,它主要负责并行处理数据流。
它可以同时处理多个数据块,可以在同一时刻完成多个任务。
由于流处理器的并行处理性能,使得GPU在图像处理和科学计算等方面有着得天独厚的优势。
2. 流处理器的作用流处理器在GPU中扮演着核心角色。
它可以同时处理大规模的数据,并在短时间内完成复杂计算任务。
流处理器通过并行计算的方式提高了计算效率,使得GPU在处理图形和计算密集型任务时能够发挥出更强大的性能。
3. 流处理器的发展趋势随着计算机技术的发展,流处理器的数量和性能不断提升。
未来的GPU将会集成更多的流处理器,并且优化并行计算算法,以满足更加复杂和多样化的计算需求。
二、浮点运算单元1. 浮点运算单元的概念浮点运算单元是GPU中的另一个重要组成部分,它主要负责浮点数的运算。
在现代科学计算中,浮点数是一种非常重要的数据类型,因此浮点运算单元在GPU中的作用非常重要。
2. 浮点运算单元的作用浮点运算单元可以进行高速的浮点数运算,这对于科学计算等领域有着非常重要的意义。
在图形处理中,浮点运算单元可以加速复杂的图形计算,使得GPU在处理图形任务时表现得更加出色。
3. 浮点运算单元的发展趋势随着科学计算和图形处理的需求不断增加,GPU中的浮点运算单元也在不断演进和优化。
未来的GPU将会拥有更多的浮点运算单元,并且在性能和功耗上进行更加平衡的设计。
总结回顾无论是流处理器还是浮点运算单元,在现代GPU中都扮演着非常重要的角色。
GPGPU 简介:近年来,GPU (Graphic Processing Unit ) 得到了高速的发展,GPU 非常适合于高效率低成本的高性能并行数值计算。
而GPGPU (General-purpose computing on graphics processing units) 是一种使用处理图形任务的专业图形处理器来从事原本由中央处理器处理的通用计算任务,这些通用计算常常与图形处理没有任何关系。
现代图形处理器强大的并行处理能力和可编程流水线,使得用流处理器处理非图形数据成为可能。
特别是在面对单指令流多数据流(SIMD )且数据处理的运算量远大于数据调度和传输的需要时,通用图形处理器在性能上大大超越了传统的中央处理器应用程序。
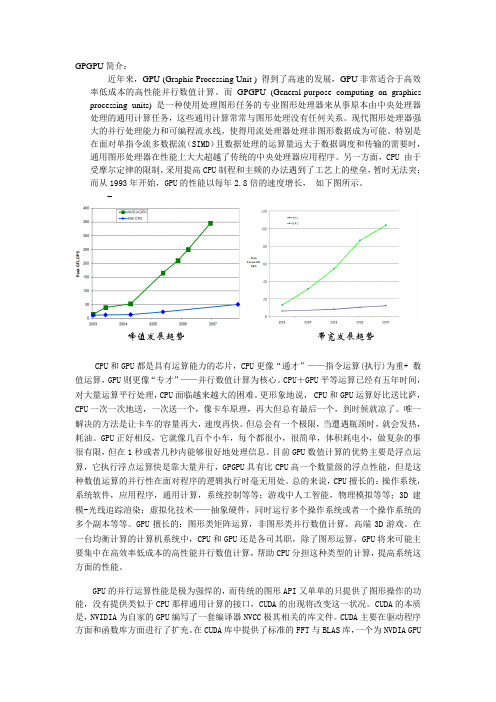
另一方面,CPU 由于受摩尔定律的限制,采用提高CPU 制程和主频的办法遇到了工艺上的壁垒,暂时无法突;而从1993年开始,GPU 的性能以每年2.8倍的速度增长, 如下图所示。
–CPU 和GPU 都是具有运算能力的芯片,CPU 更像“通才”——指令运算(执行)为重+ 数值运算,GPU 则更像“专才”——并行数值计算为核心。
CPU +GPU 平等运算已经有五年时间,对大量运算平行处理,CPU 面临越来越大的困难。
更形象地说, CPU 和GPU 运算好比送比萨,CPU 一次一次地送,一次送一个,像卡车原理,再大但总有最后一个,到时候就凉了。
唯一解决的方法是让卡车的容量再大,速度再快。
但总会有一个极限,当遭遇瓶颈时,就会发热,耗油。
GPU 正好相反,它就像几百个小车,每个都很小,很简单,体积耗电小,做复杂的事很有限,但在1秒或者几秒内能够很好地处理信息。
目前GPU 数值计算的优势主要是浮点运算,它执行浮点运算快是靠大量并行,GPGPU 具有比CPU 高一个数量级的浮点性能,但是这种数值运算的并行性在面对程序的逻辑执行时毫无用处。
总的来说,CPU 擅长的:操作系统,系统软件,应用程序,通用计算,系统控制等等;游戏中人工智能,物理模拟等等;3D 建模-光线追踪渲染;虚拟化技术——抽象硬件,同时运行多个操作系统或者一个操作系统的多个副本等等。

gpu优化建议●?GPU硬件特性存储层次◆?Global memory:●?大小一般为几GB●?chip-off的DRAM介质存储器●?访问速度慢(是shared memory的上百倍)●?对于是否对齐和连续访问敏感(由DRAM的性质决定)●?可以被所有的线程访问◆?Shared memory:●?每个SM中一般几十KB●?chip-on的SRAM介质存储器●?访问速度快(与register相当)●?对于是否对其和连续访问不敏感,但是对bank conflict敏感(由bank设计决定)●?只对自身block中的线程可见◆?Register●?每个SM中一般为几千个(约30K)●?Chip-on的寄存器●?访问速度最快●?只对每个thread本身可见◆?Other●?Local memory每个线程有512KB(计算能力2.x),或者16KB(计算能力1.x)Chip-off的存储器,与global memory类似访问速度慢(与global memory类似)由编译器控制,存放寄存器溢出的自动变量只对每个thread本身可见●?Texture memory大小为6-8KB●?Constant memory大小为64KB执行层次◆?逻辑●?Grid:由block构成,维数及维度可以设置,所有的block在Grid中并行执行●?Block:由thread够层,维数及维度可以设置,同一个block 中的thread并行执行●?Thread:由threadId识别,每个thread有自己的寄存器,私有变量,共享同一个block中的shared memory◆?物理●?SM:由多个流处理器组成,每个SM有独立的资源,包括:block槽,warp槽,thread槽,shared memory,register●?Warp:由32个thread组成,每次执行的时候,32个thread 动作一致,如果有分支,则串行执行●?Thread:物理上属于warp,与其他thread一同,组成最小的执行单元warp,拥有自己的寄存器●?GPU优化原则访存方式◆?Global memory:尽量让一个warp中的线程访问连续的一个内存块,实现级联访问(合并访问)◆?Shared memory:尽量减少bank conflict,让同一个warp中的线程访问不同的bank数据分块◆?Shared memory block:在SM能够支持的情况下,尽量多地利用此资源提高局部重用性◆?Register memory:在shared memory之上可以多加一层寄存器层,进一步提高重用性(寄存器的带宽和延迟都优于共享内存)限制分支◆?Warp divergence:尽量减少分支判断,将同一个分支中的thread尽量放在同一个warp中提高计算密度◆?Instruction throughput:一方面提高warp的效率,让warp 充分用到function unit,尽量接近理论峰值;另一方面可以降低非运算类的比例,使得指令更多地用于计算●?GPU优化策略级联访存◆?Global memory:将线程组织称为可以一次性访问一个warp 中内容的形式共享内存◆?Shared memory:减少bank conflict来加快对shared memory的访问重组线程◆?将各个分支中的线程进行重组,让同一个warp中的线程尽量地走同一个分支指令流水线◆?对指令进行分类,分析每一类指令的吞吐量,减少混合指令指令调度◆?将长延迟的指令插入到与该指令独立的计算密集点处,使用计算来隐藏延迟(一般为访存造成的延迟)●?GPU优化实现《实战》◆?CGMA:compute to global memory access●?计算:浮点数操作/访存操作,能够比较准确地体现kernel的性能,在访存性能一定的时候,通过提高CGMA的值可以使得浮点操作的性能大幅提升(浮点操作的峰值性能远远超过访存的峰值带宽)●?例子:CGMA=1.0,则浮点操作的性能最好的时候也就跟访存性能一致,而G80的global memory的带宽为86.4GB/s,但是其浮点计算的峰值性能却为367Gflops,这样,性能将被访存速度所约束◆?减少global memory的流量●?将具有局部重用性的数据块加载到每个block中的shared memory中,减少对global memory的频繁访问,提高读取数据的性能●?例子:矩阵乘法的分块实现,利用shared memory来存储每一小块所需的数据及结果◆?存储器的使用需要谨慎●?如果每个线程使用得存储器过多,将会直接导致每个SM上可以驻留的线程数减少,造成并行度不足的问题●?例子:G80中每个SM有8K的寄存器,16K的sharedmemory,如果每个块分配的shared memory超过了2K,则SM中驻留的块将无法达到全部的8个,降低并行度,寄存器也是同样的道理◆?Warp divergence的问题●?一个warp中的线程存在分支的时候,会造成串行执行不同分支,降低性能,可以通过调整线程执行内容来减少warp中存在的分支,提高性能●?例子:tid % 2造成了每个warp中都有分支,换成了tid < stride后,将直接消除了几乎所有分支◆?Global memory带宽●?由于global memory是有DRAM组成,所以,访问的速度慢,而每次访问将会返回连续的一段数据(硬件设计决定),所以,为了接近峰值,应该坚持每次访问都对连续的单元进行访问(即合并访问)●?例子:矩阵的行优先转换成列优先,可以一次性读取连续的单元,提高效率;如果warp访问的是global memory中的连续单元,则该访问将会被合并成一次性访问◆?SM资源的动态划分(分块大小的策略)●?GT200中,每个SM最多驻留1024个线程,8个块,可以划分为4*256,也可以划分成8*128,但是后者更能充分地利用线程槽和块槽,效率将会更高●?寄存器数目可能造成的性能悬崖:GT200种每个SM有8192个寄存器,对于16*16的线程块,如果每个线程用到的寄存器为10个,那么可以容纳3个块,如果每个线程用到的寄存器为11个,则只能容纳2个块,这种情况可能极大地降低并行度,造成性能退化说明:上面描述的情况也不一定降低性能,如果一个寄存器能够使得独立的浮点操作数大幅提高,那么,就算少了一个块,也能够有充分的warp来隐藏延迟问题:寄存器溢出是在寄存器不够用的情况下出现的,按照上面的说法,寄存器如果不够用,会减少块的个数来避免这个问题,那么什么时候将会溢出?另一方面,寄存器溢出会造成对local memory的访问,降低性能,但是没有想象中的低,因为Fermi已经为local memory提供了缓冲◆?数据预取●?当所有的线程都在等待存储器访问结果的时候,延迟将没有办法被隐藏,这个时候,可以调整处理过程为:使用当前元素时,预取下一个元素,隐藏延迟(书中观点是:在读取global memory到shared memory中的这个过程中间,插入了独立的计算指令,有效地隐藏延迟)●?例子:将原来读取global memory到shared memory的过程拆分成global memory到register,再从register到shared memory,这样,从global memory读取下一块到register的时候,就可以同时计算当前块,隐藏延迟了◆?混合指令的消除●?对于循环,往往混合了多种指令:取址,分支,计数,运算,而指令的混合将会降低执行效率,可以通过消除这种混合来提高指令的执行效率●?例子:将循环次数不多的循环体直接展开称为长的表达式,消除指令的混合◆?线程粒度调整●?提高线程的粒度有时候能够降低访存的次数,因为其提高了数据的重用性,当然,期间不可避免地用到了更多的寄存器和shared memory●?例子:矩阵分块乘法中,每个块计算C的几个块,可以减少对输入矩阵的加载,但是,使用更多的register和shared memory可能降低性能◆?总结:调整好块的大小是最重要的,其次考虑数据预取和指令展开,最后调整线程粒度,找到最好的平衡点论文一◆?文章内容:提出了一个定量的性能分析模型,衡量CUDA程序的三个主要组成部分:指令流水线,共享存储器访问,全局存储器访问;用于统计数据的工具:barra simulator◆?建模分析:传统分析:计算限制/访存限制;替代分析:指令吞吐量限制/内存层次限制;将模糊的“算法,计算量”量化为清晰的“指令吞吐量,内存分层”◆?模型建立:●?指令层次:将指令按照执行代价进行分类,然后利用一般化的代码在不同warp数目情况下执行,收集信息并估算出每一类指令的流水线吞估量●?共享存储层次:对于一般化代码,利用bank conflict信息更正内存事务的数量,在不同warp数目情况下执行,利用吞吐量估算访问共享存储器所用的时间●?全局存储层次:使用一个内存事务模拟器来计算硬件层次上的事务数量,从而计算时间●?大致过程:Barra生成一个关于指令执行次数的动态程序执行信息,然后用这个信息来生成每一类动态指令的数目,共享内存事务的数目,全局内存事物的数目,被同步所分开的阶段的数目◆?模型的作用●?定量地分析每一部分的性能,找出瓶颈,检测瓶颈是否消除,给出确切的瓶颈原因●?指令瓶颈:计算密集度低,高代价的指令多,warp并行效率低●?共享内存瓶颈:bank conflict,bookkeeping 指令引起的内存拥塞,warp并行效率低●?全局内存瓶颈:并行化隐藏延迟的效率低,非级联的内存放访问和内存事务粒度过大◆?详细建模过程:●?利用Barra生成动态指令,通过信息收集器输出三部分信息:每种指令的个数,共享存储器的事务数目,全局存储器的事务数目(通过同步将程序分成单个的阶段,对单个的阶段进行分析,找出这些数据)●?内建一个工具修改原有的指令,将修改后的指令重新编译成二进制代码嵌入到执行文件中●?对指令流水线的建模:通过可以执行该指令的FU(function unit)数量不同,将指令进行分类,对每一类指令可以通过收集的信息计算出其理论的吞吐量峰值(#FU*Freq*#SM/warpSize)●?对共享存储器事务的建模:已知shared memory带宽,通过调整SM中的warp数目,找出带宽饱和时最少需要的warp数目;利用自动程序导出不同程度的bank conflict所对应的有效共享存储器事务的数量●?对全局存储器事物的建模:运行一个综合标准测试程序(同样的数目的块,块内线程,线程的存储事件个数),然后根据级联规则将这些存储事务分成几个硬件层次上的事件,估算全局存储器事务的数量CUDA的级联访问规则:◆?对于每个存储事件,找出最小下标线程所请求的内存段地址◆?找出所有其他也请求该内存段的线程◆?尽可能归约缩小该内存段的大小◆?重复以上三步直到处于同一个half-warp中的线程都获得服务论文二◆?文章内容:warp divergence对性能的影响表现为branch的串行执行,一个warp可能执行1次,也可能执行32次,需要对这个问题进行分析,建立评估模型,并且进行优化◆?问题分析:warp divergence可以从硬件和软件两个方面进行优化:硬件方面:动态warp形成技术(提供有限的线程重组);动态warp子划分,让不同分支的线程重叠执行,意在减小这些分支对性能的影响;软件方面:线程重新组织技术,减少分支;综合分析这些技术,没有任何技术能够完全消除分支的影响,这里致力于减小分支对性能的影响(具体表现为最小化没有用到计算资源的那些时钟周期)◆?建立模型:●?介绍两个常用的标准:divergence branches,用于记录warp 中的分支数;divergence warp ratio,用于记录存在分支的warp占所有warp 的百分比●?考虑三种类型的估算:BBV(basic block vector),EV (edge vector),PV(path vector),精确性递增,计算复杂性递增,本文选择了BBV●?估算过程:找出每个basic block中执行次数最多的thread,记录其次数,所有的次数加起来作为metric:,该matric可以衡量一个warp中basic block的执行次数,但是无法对执行次数相同的basic block 进行区分考虑basic block执行的指令数目,乘上次数,再做加法,可以衡量更为精细的线程性能,metric:加入block的动态调度,最终形成metric为:BBV-Weighted-scheduled,测试结果可以说明不同线程组成的操作之间的性能差别◆?性能优化:●?大致流程(包括下面三个部分):利用GPGPU-Sim模拟器简历程序控制流程图,获得每个线程的BBV个数,然后通过重组算法对线程进行重组,新的组合将被用来提高应用的性能,而主程序和kernel程序都会作出响应的修改(参见论文Figure4)。
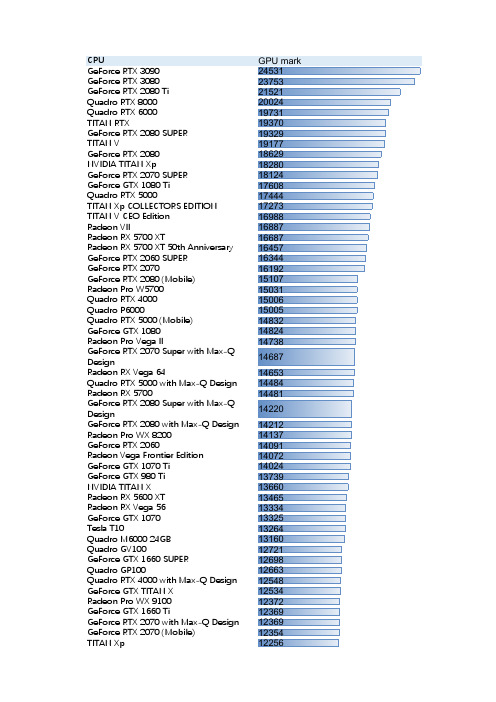
GeForce RTX 3080GeForce RTX 2080 TiQuadro RTX 8000Quadro RTX 6000TITAN RTXGeForce RTX 2080 SUPERTITAN VGeForce RTX 2080NVIDIA TITAN XpGeForce RTX 2070 SUPERGeForce GTX 1080 TiQuadro RTX 5000TITAN Xp COLLECTORS EDITIONTITAN V CEO EditionRadeon VIIRadeon RX 5700 XTRadeon RX 5700 XT 50th AnniversaryGeForce RTX 2060 SUPERGeForce RTX 2070GeForce RTX 2080 (Mobile)Radeon Pro W5700Quadro RTX 4000Quadro P6000Quadro RTX 5000 (Mobile)GeForce GTX 1080Radeon Pro Vega IIGeForce RTX 2070 Super with Max-QDesignRadeon RX Vega 64Quadro RTX 5000 with Max-Q DesignRadeon RX 5700GeForce RTX 2080 Super with Max-QDesignGeForce RTX 2080 with Max-Q DesignRadeon Pro WX 8200GeForce RTX 2060Radeon Vega Frontier EditionGeForce GTX 1070 TiGeForce GTX 980 TiNVIDIA TITAN XRadeon RX 5600 XTRadeon RX Vega 56GeForce GTX 1070Tesla T10Quadro M6000 24GBQuadro GV100GeForce GTX 1660 SUPERQuadro GP100Quadro RTX 4000 with Max-Q DesignGeForce GTX TITAN XRadeon Pro WX 9100GeForce GTX 1660 TiGeForce RTX 2070 with Max-Q DesignGeForce RTX 2070 (Mobile)Radeon Pro Vega 56Quadro M6000Quadro P4200Quadro P4200 with Max-Q DesignRadeon Pro 5700Quadro P4000Radeon Pro Vega 48Quadro P5200GeForce GTX 1080 with Max-Q DesignGeForce GTX 1660Quadro P5000Radeon Pro Vega 64GeForce RTX 2060 (Mobile)Quadro RTX 3000Radeon RX5600GeForce GTX 980Radeon Pro 5700 XTRadeon RX 5600Radeon Pro SSGRadeon Instinct MI25 MxGPUGeForce GTX 1070 (Mobile)GeForce GTX 1060GeForce GTX 1070 with Max-Q DesignGeForce GTX 1660 Ti (Mobile)GeForce GTX 1650 SUPERGeForce RTX 2060 with Max-Q DesignQuadro P5200 with Max-Q DesignRadeon R9 Fury + Fury XRadeon Pro DuoGeForce GTX 970GeForce GTX 1060 3GBRadeon R9 FuryRadeon R9 Fury XRadeon R9 390XRadeon RX 590Radeon Pro W5500Quadro M5000GeForce GTX 780 TiQuadro P2200GeForce GTX TITAN BlackQuadro P4000 with Max-Q DesignRadeon RX 5500 XTQuadro P3200 with Max-Q DesignRadeon RX 580Radeon R9 390GeForce GTX TitanRadeon RX590 GMEGeForce GTX 1660 Ti with Max-Q DesignRadeon RX 480Quadro K6000Radeon RX 5500Radeon R9 290Radeon R9 290XRadeon R9 290X / 390XRadeon R9 295X2Quadro RTX 3000 with Max-Q DesignGeForce GTX TITAN ZGeForce GTX 1060 (Mobile)Radeon R9 290 / 390GeForce GTX 1060 with Max-Q DesignQuadro M5500Radeon RX 470GeForce GTX 780GeForce GTX 1650Radeon RX 580XRadeon RX 580 2048SPRadeon Pro WX 7100Radeon Pro 580FirePro W9100GeForce GTX 1650 TiQuadro P3200Tesla M6Radeon Pro 580XGeForce GTX 980MTesla M60Quadro P2000Tesla P100-PCIE-16GBFirePro W8100GeForce GTX 1650 (Mobile)Radeon RX 570Quadro T1000 with Max-Q DesignQuadro T2000Radeon RX Vega M GHTesla T4Radeon Pro 5500MGeForce GTX 970XM FORCEQuadro P3000Quadro M5000MQuadro M4000MQuadro T1000Quadro M4000GeForce GTX 1050 TiQuadro T2000 with Max-Q DesignRadeon Pro 570Radeon RX 5600MFirePro S7150Radeon R9 280XRadeon R9 380GeForce GTX 1650 Ti with Max-Q DesignRadeon Pro WX Vega M GLRadeon R9 380XGeForce GTX 960GRID P100-16QQuadro K5200GeForce GTX 1050 Ti (Mobile)FirePro W9000GeForce GTX 770GeForce GTX 690GeForce GTX 1650 with Max-Q DesignRadeon Pro Vega 20GeForce GTX 970MRadeon Pro 5300MGeForce GTX 1050 Ti with Max-Q DesignGeForce GTX 680Radeon R9 285 / 380GRID M60-8AGeForce GTX 1050Quadro M3000MRadeon Pro WX 5100GeForce GTX 950GeForce GTX 670GRID M60-2QRadeon HD 7970 / R9 280XFirePro S10000GeForce GTX 760 Ti OEMRadeon HD 8990Q12U-1Radeon R9 M295XGeForce GTX 760 TiFirePro S9000P106-100Quadro P2000 with Max-Q DesignEIZO Quadro MED-XN51LPFirePro W7100Radeon R9 M395Barco MXRT 7600Radeon Sky 500Radeon R9 M485XRadeon R9 270XRadeon R9 M395XRadeon HD 7950 / R9 280GeForce GTX 760GRID P40-24QRadeon R9 370Radeon Pro Vega 16Radeon HD 7870B8DKMDAPRadeon Pro 465GeForce GTX 580Quadro M2200Radeon HD 7870 XTGeForce GTX 1050 (Mobile)GRID M60-1BCitrix Indirect Display AdapterGRID P6-4QRadeon R7 370GeForce GTX 660 TiRadeon R9 M390XQuadro P1000Barco MXRT 7500GRID P40-2QGeForce GTX 680MXRadeon R9 270 / R7 370GRID M60-1QGeForce GTX 775MQuadro K4200Radeon R9 270FirePro S7000GRID V100D-8QGeForce GTX 1060 5GBFirePro W7000Radeon RX 5500MRadeon HD 7800-serieQuadro M2000GRID P6-2QGeForce GTX 480GeForce GTX 780MGeForce GTX 1050 with Max-Q DesignGeForce GTX 660GeForce GTX 750 TiQuadro K5000Quadro K2200MGRID M60-8QRadeon HD 8970MGeForce GTX 570FirePro W7170MGRID P100-8QGeForce GTX 965MGRID M60-4QRadeon HD 7850GeForce GTX 880MRadeon Pro 560XQuadro P620Radeon RX 560Radeon Pro WX 4100Radeon HD 7970MRadeon RX Vega M GLQuadro M2000MQuadro M1200GeForce GTX 680M KY_Bullet EditionGRID M6-8QQuadro K2200Radeon RX 560XTesla C2050Quadro 7000GeForce GTX 960MTesla M10FirePro M6100 FireGL VRadeon Pro 560FirePro W8000Radeon Pro 460GeForce GTX 870MTesla C2050 / C2070Quadro P600GeForce GTX 750Radeon R9 M470XRadeon HD8970MRadeon E8870PCIeTesla C2075Intel Iris XeGRID P40-2BGRID M10-1QGeForce GTX 590Radeon R9 M290XTesla C2070GeForce 770MGRID M10-4QGeForce GTX 650 Ti BOOSTGeForce GTX 470GRID K520GRID K2RadeonT RX 5500MFirePro V7000Radeon Pro 555Radeon Pro 455Radeon R7 360Radeon HD 7790GeForce GTX 560 TiRadeon R7 260XRadeon R9 M380Radeon R9 360Radeon R9 260Quadro M1000MFirePro W5000GeForce MX350GeForce GTX 680MGRID K260QRadeon HD 6990Radeon HD 6970FirePro W5100Intel UHD P630P106-090Radeon R7 260Quadro K1200Radeon Ryzen 7 PRO 4750G withQuadro M620Radeon Pro V340 MxGPUQuadro K5000MQuadro K5100MGeForce GTX 465Radeon Pro W5500MFirePro 3D V9800Quadro 6000GeForce GTX 770MRadeon Pro WX 3100Radeon Pro WX 7130FirePro W4300Radeon HD 6950FirePro V9800Radeon Pro 450GeForce MX330GeForce GTX 560Barco MXRT 5500Quadro K4000GRID M10-2QFirePro R5000MONSTER GeForce GTX 675MGeForce GT 1030GeForce GTX 950MGRID M10-8QGeForce GTX 850MGeForce MX250Radeon Pro WX 3200Radeon Ryzen 7 PRO 4750GE withRadeon HD 6850 X2FireStream 9370N18E-Q1Radeon Ryzen 5 PRO 4650G withRadeon Ryzen 7 4700GE withRyzen 5 Pro 4650G with Radeon GraphicsRadeon Ryzen 5 PRO 4650GE withFirePro 3D V8800Radeon R9 M470GeForce GTX 950AGRID M10-2BRadeon RX 550GeForce GTX 960ARadeon RX Vega 11 PRDGeForce GTX 485MRyzen 7 4800U with Radeon GraphicsQuadro K4100MRyzen 7 4800H with Radeon GraphicsRyzen 7 Pro 4750G with Radeon GraphicsGeForce MX150GRID K280QRadeon Ryzen 3 PRO 4350G withRyzen 5 4600G with Radeon GraphicsRyzen 7 Extreme EditionRyzen 3 PRO 4350GE with RadeonGraphicsGRID M10-1BRadeon Pro WX 4130Radeon HD 5970GeForce GTX 460Quadro K3100MGeForce GTX 580MQuadro K620Radeon HD 6970MRadeon R7 250XRadeon Ryzen 3 PRO 4350GE withRyzen 3 Pro 4350G with Radeon GraphicsRadeon HD 5870Ryzen 5 4600H with Radeon GraphicsRadeon Ryzen 7 4800U withFirePro V7900GRID P100-1BGeForce GTX 745Radeon HD 6870RadeonT R7 450Ryzen 3 4300G with Radeon GraphicsQuadro P520Intel Iris Pro P580Radeon HD 7770GRID K240QGeForce 945MRadeon RX Vega 11Intel Iris Pro 580Quadro K4000MRadeon TM R9 A360FirePro M5100Radeon HD 8950Ryzen 7 PRO 4750U with Radeon GraphicsGRID M6-1QRadeon R9 350Quadro 5000MGeForce GTX 480MRyzen 7 4700U with Radeon GraphicsFirePro M6100GeForce GTX 675MRadeon Ryzen 5 4600U withGeForce GTX 460 v2Intel UHDRadeon HD 6850Ryzen 5 PRO 4500U with Radeon GraphicsGeForce GT 645Quadro 5010MGeForce GTX 570MEmbedded Radeon E9173Quadro 5000Ryzen 5 4600U with Radeon GraphicsRadeon Pro WX 4150Radeon Ryzen 7 4700U withRadeon R7 + R7 350 DualRadeon HD 5850Radeon R7 + HD 7700 DualRadeon R9 M375XRadeon HD 7660D + HD 7700 DualGeForce GTX 765MQuadro M520GeForce GTX 645GeForce MX230GeForce GTX 470MRadeon Ryzen 7 PRO 4750U withGeForce GTX 460 SEGeForce GTX 555Quadro M600MRadeon RX 570XGeForce MX450Radeon Ryzen 5 4600H withGeForce MX130Radeon HD 7560D + 7700 DualRadeon R7 450Radeon Ryzen 7 4800H withRadeonMatrox C680 PCIe x16Radeon HD 7700-serieRadeon Vega 11Radeon HD 8670D + HD 7700 DualIntel Iris PlusGeForce GTX 560 SEFirePro 3D V7800Radeon RX 540GeForce 945ARyzen 5 4500U with Radeon GraphicsFirePro M5100 FireGL VGRID M60-0BRadeon HD 8570D + HD 7700 DualMxGPUGeForce GTX 670MXRadeon Ryzen 5 4500U withFirePro M6000Intel Iris Plus 645Matrox C900 PCIe x16RadeonT RX 560XIntel Iris Plus 655Radeon HD 8870M / R9 M270X / M370XIntel Iris 650Radeon R9 M360Radeon HD 8670D + 7700 DualRyzen 5 PRO 4650U with Radeon GraphicsRadeon HD 6900MRadeon Ryzen 5 PRO 4650U withGeForce GTX 650Radeon RX Vega11Radeon R9 M385XRadeon HD 5830Quadro P500GeForce GTX 670MFirePro W600Radeon HD 6790FirePro W5130MRadeon RX 550XRadeon R7 M465XFirePro M4000 Mobility ProRadeon HD 7750Quadro P400Radeon Vega 9Quadro K3000MRadeon HD HD7850MQuadro K2000DFirePro M4000Radeon Pro WX 2100Radeon HD 8870MGeForce GTX 760MGeForce GT 755MRyzen 7 2700U with Radeon VegaSeria Radeon HD 7700Radeon RX Vega 8Intel Iris Plus 650Quadro K2000Ryzen 3 PRO 4450U with Radeon GraphicsRadeon E8860Radeon R9 M275X / M375Radeon Vega 8Radeon 550XGeForce GTX 550 TiIntel UHD 630GeForce GTX 285Radeon HD 7560D + HD 6670 DualRadeon HD 8470D + HD 7500 DualGeForce GT 740Ryzen 3 PRO 4300U with Radeon GraphicsIntel Iris Pro Graphics 6200FirePro V8700FirePro M6000 Mobility ProGeForce 940MXRadeon RX Vega 10GeForce GTX 675MXFirePro W4100Radeon HD 7870MRyzen 5 2500U with Radeon VegaRadeon HD 4890Quadro 4000Radeon R7 FX-9830P RADEONRadeon HD 6670 + 7660D Dual。
GPU中的流处理器和浮点运算单元一、引言在当今的计算机领域,GPU(Graphics Processing Unit,图形处理器)已经成为了不可或缺的一部分。
作为处理图形和影像数据的专用处理器,GPU在游戏、计算机辅助设计(CAD)、视频编辑等领域扮演着至关重要的角色。
而GPU中的流处理器和浮点运算单元则是GPU中最为核心的组成部分,它们决定了GPU的性能和运算能力。
二、流处理器1. 流处理器的定义流处理器,又称为流处理单元,是GPU中负责执行各种图形和通用计算任务的处理单元。
它的设计初衷是为了并行处理大规模的图形数据,但随着计算需求的不断增加,流处理器也开始承担起了通用计算任务。
2. 流处理器的作用流处理器的主要作用是执行程序中的并行计算任务,它可以同时处理大量的数据,并且在处理图形数据和通用计算任务时表现出色。
在GPU中,流处理器的数量决定了其并行处理能力的强弱,也直接影响了GPU的整体性能表现。
3. 流处理器的设计流处理器通常采用SIMD(Single Instruction, Multiple Data,单指令多数据)架构,这意味着它可以同时对多个数据进行相同的操作。
这种并行计算的特点使得流处理器能够在处理图形和通用计算任务时更加高效。
三、浮点运算单元1. 浮点运算单元的定义浮点运算单元是GPU中负责执行浮点运算的处理单元,它的设计初衷是为了处理图形渲染和物理模拟等工作。
但随着通用计算需求的不断增加,浮点运算单元也开始承担起了更多的计算任务。
2. 浮点运算单元的作用浮点运算单元主要用于执行浮点运算,包括加减乘除、开方、三角函数等数学运算。
在GPU中,浮点运算单元的数量和性能直接影响了GPU在科学计算、深度学习等领域的计算能力。
3. 浮点运算单元的设计浮点运算单元通常采用SIMD(Single Instruction, Multiple Data,单指令多数据)架构,这使得它能够同时对多个数据进行相同类型的浮点运算。
GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”。
我们通常就叫它显卡,GPU是显示卡的“大脑”,它决定了该显卡的档次和大部分性能,对于传统PC上来说,GPU同时也是2D显示卡和3D 显示卡的区别依据。
2D显示芯片在处理3D图像和特效时主要依赖CPU的处理能力,称为“软加速”。
3D 显示芯片是将三维图像和特效处理功能集中在显示芯片内,也即所谓的“硬件加速”功能。
显示芯片通常是显示卡上最大的芯片(也是引脚最多的)。
现在市场上的显卡大多采用NVIDIA和AMD-ATI两家公司的图形处理芯片。
GPU,是一块高度集成的芯片,其中包含了图形处理所必须的所有元件,GPU和CPU之间通过RAM内存进行数据交换。
在手机主板上,GPU芯片一般都是紧挨着CPU芯片的。
(gpu不是独立存在的,要有好的cpu的配合才能把作用发挥到极致)目前主流的gpu品牌也就4个,现在用得最多的是:英国Imagination Technologies日前正式发布Powe rVRSGX芯片(主要苹果系列的),然后是高通的,Adreno,(高通cpu的机子,基本都用)然后是英伟达的,NVIDIA GeForce ULV(这个用得比较少,主要给自家的用)三星主打的Maili系列的,都是三星Exynos 这个用的多先给大家解释两个关于gpu的专业术语:·GPU多边形生成能力:其实手机上面,不管任何一幅画面,都是无数个大小不一的多边形互相拼接、遮盖而成的。
不仅是游戏,包括常规的系统界面,都是无数个多边形组成的图案。
所以,多边形生成速度的快慢,决定了GPU对图形处理的速度。
每秒钟生成的多边形越多,表明GPU的性能越高·GPU像素渲染能力众所周知,手机的屏幕是一个一个像素构成的。
像素渲染的作用,就是决定每个像素是什么颜色,它的位置在哪里,具有什么图形属性等等。
只有经过像素渲染过的图,才能显示在屏幕上被我们看到,否则都是一行行枯燥的颜色及属性代码,没有任何视觉意义,也无法被我们看到。
深度学习和人工智能技术的迅速发展,对计算能力有着越来越高的需求。
对于现代科技公司和研究机构来说,选择合适的GPU是至关重要的。
而在选择GPU时,理解和评估GPU的能力表现参数,特别是Mali GPU的浮点运算性能,是至关重要的。
让我们来了解一下GPU的能力表现参数。
GPU的能力表现参数主要包括浮点运算性能、带宽、功耗等。
而在这些参数中,浮点运算性能是衡量GPU性能的重要指标之一。
它代表了GPU在处理浮点运算任务时的速度和效率。
而对于Mali GPU来说,其浮点运算性能一直备受关注。
Mali GPU是由Arm公司设计的一种图形处理器。
其浮点运算性能在不同型号中有所不同,主要通过浮点运算能力(FLOPS)来衡量。
而FLOPS代表着GPU每秒钟可以执行的浮点运算次数,可以直接反映出GPU的计算速度。
当评估Mali GPU的浮点运算性能时,首先需要考虑的是其FLOPS的数值。
通过对比不同型号Mali GPU的FLOPS数值,可以直观地了解其计算速度的差异。
也需要考虑到GPU的篇幅阈值和能耗等因素。
因为虽然浮点运算速度快是但在实际应用中,能耗也是需要考虑的重要因素之一。
除了考虑这些技术参数外,我们也应该看到Mali GPU在行业中的影响。
作为一款被广泛应用于移动设备、物联网和嵌入式设备的GPU,其浮点运算性能更加直接地影响着这些领域的发展。
评估Mali GPU 的浮点运算性能,除了从技术角度出发,也需要从市场和应用角度进行深入的分析。
Mali GPU的浮点运算性能对于各类设备的性能和应用性都有着举足轻重的影响。
对于科技公司和研究机构而言,充分理解和评估Mali GPU 的浮点运算性能,能够更好地选择合适的GPU,提高计算效率,加速科研和产品的研发进程。
这对于推动深度学习和人工智能技术的快速发展有着积极的促进作用。
Mali GPU的浮点运算性能作为其重要的能力表现参数之一,对移动设备、物联网和嵌入式设备的发展起着举足轻重的作用。
⼿机GPU性能天梯榜,差距最⾼可达10倍,你的⼿机处在哪个段位?⽂/⼩伊评科技前⾔:在⼿机SOC⾏业,除了苹果之外,不同IC芯⽚⼚商的同级别芯⽚在CPU⽅⾯的差距其实并没有特别⼤。
原因也很简单,因为⼤家全部都回归了ARM的Cortex核⼼的怀抱。
曾经,⾼通和三星也都尝试过⾃研CPU的核⼼架构,也就是⾼通的Kyro架构和三星的猫鼬架构(⾼通⽬前对外宣传还⾃称⾃⼰使⽤的是Kyro,但是实际上就是Cortex)但是⼤多都不太成功,在能效⽐,IPC⽅⾯也都跑不赢ARM公版的架构,尤其是在⼀代“神核”Cortex A76(基于ARM V8指令集)核⼼架构发布之后,⾼通和三星全部回归ARM怀抱。
⾄于苹果,由于财⼤⽓粗以及在产品终端价格的天然优势,在CPU架构核⼼的堆料和架构设计⽅⾯可以不惜成本(前端多发射,超⼤缓存等),其在IPC性能⽅⾯始终能够跑赢ARM的公版架构,所以,⽬前苹果A系列处理器在CPU性能⽅⾯⼀骑绝尘。
⾄于华为海思,联发科,紫光等⼀直采⽤的都是ARM的公版架构。
但是和CPU领域不同的是,在GPU领域各家IC芯⽚设计商的差距则⽐较巨⼤,⾼通和苹果的实⼒可以归为同⼀档,⾼通的GPU架构师承⾃AMD,也就是⼤名⿍⿍的A卡,当年AMD收购ATI之后,曾经也要进军移动GPU领域,但是由于摊⼦铺得太⼤,⾃顾不暇,所以只能把架构卖给了⾼通,这就是adreno系列GPU架构的由来。
⽽苹果这边原本的GPU供应商是⼤名⿍⿍的Imagination,这也是世界上最⼤的移动GPU公司之⼀,但是在2017年,苹果收购Imagination失败,于是把该公司⾻⼲团队全部挖⾛之后,开始了⾃研GPU的脚步,⼀直到现在,实⼒也是有⽬共睹的。
⾄于剩下的IC芯⽚⼚商则⼀直是ARM Mali的忠实⽤户,包括华为海思,联发科等,⽽ARM在GPU领域的技术沉淀较少,能效⽐⽐较⼀般,所以在很长⼀段时间⾥,这些使⽤ARM公版架构的IC设计⼚商的产品在GPU领域和⾼通以及苹果的差距都⽐较⼤,不过随着Mali G78架构的出现,ARMMali架构的能效⽐得到了不错的提升,未来可期。