第7章方差分析课件说课材料
- 格式:ppt
- 大小:647.00 KB
- 文档页数:25






第七章方差分析(Analysis of Variance, ANOVA)7.1 方差分析概述7.2 单因素方差分析7.3 无重复双因素方差分析7.4 可重复双因素方差分析7.5 案例研究7.6 试验设计初步7-17.1 方差分析概述⒈方差分析的概念⒉方差分析中的基本术语⒊ANOVA:对比多个总体的均值⒋方差分析中的基本假定7-27-3方差分析的概念方差分析:通过检验多个总体均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。
解决:①A 、B 、C 是否Y 的重要影响因素;②如果为重要影响因素,最优水平?研究系统A B C分类型自变量Y数值型因变量A (a 1,a 2,a 3,…)B (b 1,b 2,b 3,…)C (c 1,c 2,c 3,…)7-4方差分析中的基本术语第1周第9周第14周第2周第7周第16周第4周第12周第17周第5周第10周第13周第3周第8周第18周第6周第11周第15周AB品牌底部中部顶部货架位置因素因素水平实验单元:“一周”响应变量:“每周销售量”处理:品牌—货架位置组合随机安排试验例:一项市场营销研究。
考察品牌和货架位置对咖啡周销售量的影响。
试验单元(experiment unit )、响应变量(responsevariable )、因素(factor )、因素水平(factor level )、处理(treatment )。
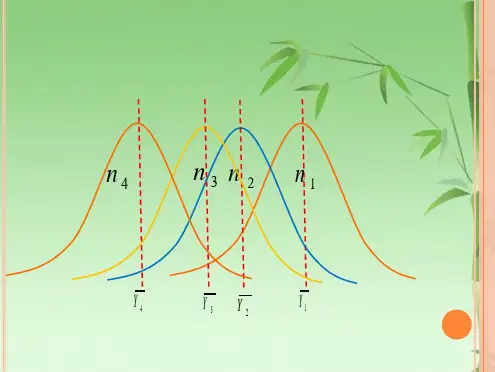
ANOVA:对比多个总体的均值佣金固定薪金佣金加固定薪金165120140981151561309022021012611219510713418715523524080总平均样本均值175.00113.29166.17151.48三类报酬构成的推销人员的月销售额(千美元)问题:(1)三种报酬类型销售人员的销售业绩是否存在显著差异?(2)如果存在差异,哪类销售人员的业绩最佳?三个总体的均值是否相等?7-57-6散点图佣金固定薪金佣金+固定薪金50100150200250300分类型自变量销售业绩均值差异分析:(1)同一总体内部的差异(随机差异)?(2)不同总体之间的差异(随机差异+系统差异)?(3)两类差异大小分析?7-71x 2x 3x ()f x x31x 2x 3x ()f x x2 1 H 0为真时,样本均值的抽样分布H 0为假时,样本均值的抽样分布方差分析中的基本假定•基本假定:•(1)每个总体均服从正态分布;•(2)每个总体的方差相等;•(3)来自每一总体的样本都是独立随机样本三个总体均值是否相等?012311::H H 23,,不全相等7.2 单因素方差分析(One-way Analysis of Variance)⒈基本概念与数据结构表⒉ANOVA:k个总体均值的检验⒊ANOVA表:单因素方差分析⒋最佳方案的选择7-87-9基本概念与数据结构研究一个分类型自变量对一个数值型因变量的影响。


试验模型属固定模型或随机模型的区别仅在于F 测验和统计推断上,而与自由度、平方和的分解无关。
二、 方差分析的期望均方线性可加模型将每一观察值看作是几个分量的总和。
最简单的情况是平均数μ加随机误差ε。
但平均数μ又可以是另一些分量的总和,对于完全随机设计,各处理观察值数目相等资料而言,即有ij i ij x ετμ++= (k i ,,2,1 =;n j ,,2,1 =)对于ij ε部分的假定已于上节说明,即它是彼此独立的,以零为平均数的正态分布,且不同处理内具有同质的方差。
本节要说明的是关于i τ部分的假定。
固定模型(模型Ⅰ)和随机模型(模型Ⅱ)是由于对效应τ有不同的解释而产生的。
从理论上讲,固定模型是指各个处理的平均效应)(μμτ-=i i 是固定的一个常量,且满足0=∑i τ (或0=i i n τ∑)。
随机模型是指各个处理效应i τ不是一个常量,而是从平均数为零、方差为2τσ的正态总体中得到的一个随机样本的结果。
在实际工作中,我们可以这样理解这两种模型的区别。
例如在田间试验中,若我们的目的仅在于了解某几个特定处理的效应,如要了解水稻新品种的产量或几种密度、几种肥料、几种农药的效应等,则处理效应i τ为固定的处理效应。
换言之,固定模型仅在于了解供试处理范围内处理间的不同效应,其结论是不能推广应用于范围以外的其他处理的。
如果我们的目的不是研究选出供试的那几个处理的效应,而是要对这些处理所属的总体作出推断,例如,为研究东北地区大豆地方品种的生态类型和特性,我们从大量地方品种中随机抽取一部分品种作为代表进行试验,以便通过这部分供试品种的试验结果推论整个东北地区大豆地方品种的情况,这种处理效应便是随机模型的处理效应。
在随机模型中,因为各处理仅是所属总体的随机样本,故总体方差2τσ是重要的研究对象。
由上可知,固定模型和随机模型,在设计思想和统计推断上是明显不同的。
对于固定模型,如进行重复试验,则一定包括同样组别的τ在新试验里,我们的注意力是集中于研究这些τ(效应)的大小上。