Matlab多变量回归分析报告材料教程
- 格式:doc
- 大小:333.50 KB
- 文档页数:13

第八章 回归分析方法当人们对研究对象的内在特性和各因素间的关系有比较充分的认识时,一般用机理分析方法建立数学模型。
如果由于客观事物内部规律的复杂性及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型,那么通常的办法是搜集大量数据,基于对数据的统计分析去建立模型。
本章讨论其中用途非常广泛的一类模型——统计回归模型。
回归模型常用来解决预测、控制、生产工艺优化等问题。
变量之间的关系可以分为两类:一类叫确定性关系,也叫函数关系,其特征是:一个变量随着其它变量的确定而确定。
另一类关系叫相关关系,变量之间的关系很难用一种精确的方法表示出来。
例如,通常人的年龄越大血压越高,但人的年龄和血压之间没有确定的数量关系,人的年龄和血压之间的关系就是相关关系。
回归分析就是处理变量之间的相关关系的一种数学方法。
其解决问题的大致方法、步骤如下: (1)收集一组包含因变量和自变量的数据;(2)选定因变量和自变量之间的模型,即一个数学式子,利用数据按照最小二乘准则计算模型中的系数;(3)利用统计分析方法对不同的模型进行比较,找出与数据拟合得最好的模型; (4)判断得到的模型是否适合于这组数据; (5)利用模型对因变量作出预测或解释。
应用统计分析特别是多元统计分析方法一般都要处理大量数据,工作量非常大,所以在计算机普及以前,这些方法大都是停留在理论研究上。
运用一般计算语言编程也要占用大量时间,而对于经济管理及社会学等对高级编程语言了解不深的人来说要应用这些统计方法更是不可能。
MA TLAB 等软件的开发和普及大大减少了对计算机编程的要求,使数据分析方法的广泛应用成为可能。
MATLAB 统计工具箱几乎包括了数理统计方面主要的概念、理论、方法和算法。
运用MA TLAB 统计工具箱,我们可以十分方便地在计算机上进行计算,从而进一步加深理解,同时,其强大的图形功能使得概念、过程和结果可以直观地展现在我们面前。

matlab多个因变量回归Matlab是一种强大的科学计算软件,可以用于多个因变量回归分析。
多个因变量回归分析是一种统计方法,用于探究多个自变量对多个因变量的影响关系。
在本文中,将介绍如何使用Matlab进行多个因变量回归分析,并解释结果的含义。
我们需要准备一组数据,包括多个自变量和多个因变量。
假设我们想要研究一辆汽车的油耗情况,可能的自变量包括车速、引擎排量、重量等,而因变量则是油耗量和二氧化碳排放量。
在Matlab中,可以使用regress函数进行多个因变量回归分析。
该函数的语法如下:```[b,bint,r,rint,stats] = regress(y,X)```其中,y是因变量矩阵,每一列代表一个因变量;X是自变量矩阵,每一列代表一个自变量。
函数的输出包括回归系数b、回归系数的置信区间bint、残差r、残差的置信区间rint以及回归统计信息stats。
接下来,我们将使用一个具体的例子来说明多个因变量回归分析在Matlab中的应用。
假设我们有一组数据,包括100辆汽车的车速、引擎排量、重量以及油耗量和二氧化碳排放量。
我们的目标是探究车速、引擎排量和重量对油耗量和二氧化碳排放量的影响。
我们需要加载数据并将自变量和因变量分别存储在矩阵X和矩阵y 中。
假设数据存储在一个名为"car_data.csv"的文件中,我们可以使用readmatrix函数来读取数据:```data = readmatrix('car_data.csv');X = data(:, 1:3); % 车速、引擎排量、重量y = data(:, 4:5); % 油耗量和二氧化碳排放量```接下来,我们可以使用regress函数进行多个因变量回归分析,并获取回归系数、残差等信息:```[b,bint,r,rint,stats] = regress(y, X);```回归系数b代表了自变量对因变量的影响程度。


回归分析MATLAB 工具箱一、多元线性回归多元线性回归:p p x x y βββ+++=...110 1、确定回归系数的点估计值: 命令为:b=regress(Y, X ) ①b 表示⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=p b βββˆ...ˆˆ10②Y 表示⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n Y Y Y Y (2)1③X 表示⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=np n n p p x x x x x x x x x X ...1............ (1) (12)12222111211 2、求回归系数的点估计和区间估计、并检验回归模型:命令为:[b, bint,r,rint,stats]=regress(Y,X,alpha) ①bint 表示回归系数的区间估计. ②r 表示残差.③rint 表示置信区间.④stats 表示用于检验回归模型的统计量,有三个数值:相关系数r 2、F 值、与F 对应的概率p.说明:相关系数2r 越接近1,说明回归方程越显著;)1,(1-->-k n k F F α时拒绝0H ,F 越大,说明回归方程越显著;与F 对应的概率p α<时拒绝H 0,回归模型成立.⑤alpha 表示显著性水平(缺省时为0.05) 3、画出残差及其置信区间. 命令为:rcoplot(r,rint) 例1.如下程序. 解:(1)输入数据.x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]'; X=[ones(16,1) x];Y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]'; (2)回归分析及检验.[b,bint,r,rint,stats]=regress(Y,X) b,bint,stats得结果:b = bint =-16.0730 -33.7071 1.5612 0.7194 0.6047 0.8340 stats =0.9282 180.9531 0.0000即7194.0ˆ,073.16ˆ10=-=ββ;0ˆβ的置信区间为[-33.7017,1.5612], 1ˆβ的置信区间为[0.6047,0.834]; r 2=0.9282, F=180.9531, p=0.0000,我们知道p<0.05就符合条件, 可知回归模型 y=-16.073+0.7194x 成立. (3)残差分析,作残差图. rcoplot(r,rint)从残差图可以看出,除第二个数据外,其余数据的残差离零点均较近,且残差的置信区间均包含零点,这说明回归模型 y=-16.073+0.7194x 能较好的符合原始数据,而第二个数据可视为异常点.(4)预测及作图.z=b(1)+b(2)*xplot(x,Y,'k+',x,z,'r')二、多项式回归(一)一元多项式回归.1、一元多项式回归:1121...+-++++=m m m m a x a x a x a y(1)确定多项式系数的命令:[p,S]=polyfit(x,y,m)说明:x=(x 1,x 2,…,x n ),y=(y 1,y 2,…,y n );p=(a 1,a 2,…,a m+1)是多项式y=a 1x m +a 2x m-1+…+a m x+a m+1的系数;S 是一个矩阵,用来估计预测误差. (2)一元多项式回归命令:polytool(x,y,m) 2、预测和预测误差估计.(1)Y=polyval(p,x)求polyfit 所得的回归多项式在x 处的预测值Y ;(2)[Y,DELTA]=polyconf(p,x,S,alpha)求polyfit 所得的回归多项式在x 处的预测值Y 及预测值的显著性为1-alpha 的置信区间Y ±DELTA ;alpha 缺省时为0.5.例1. 观测物体降落的距离s 与时间t 的关系,得到数据如下表,求s. (关于t 的回归方程2解法一:直接作二次多项式回归. t=1/30:1/30:14/30;s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48];[p,S]=polyfit(t,s,2) 得回归模型为:1329.98896.652946.489ˆ2++=t t s解法二:化为多元线性回归. t=1/30:1/30:14/30;s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48];T=[ones(14,1) t' (t.^2)'];[b,bint,r,rint,stats]=regress(s',T); b,stats得回归模型为:22946.4898896.651329.9ˆt t s++= 预测及作图:Y=polyconf(p,t,S)plot(t,s,'k+',t,Y,'r')(二)多元二项式回归多元二项式回归命令:rstool(x,y,’model ’, alpha)说明:x 表示n ⨯m 矩阵;Y 表示n 维列向量;alpha :显著性水平(缺省时为0.05);model 表示由下列4个模型中选择1个(用字符串输入,缺省时为线性模型):linear(线性):m m x x y βββ+++= 110purequadratic(纯二次):∑=++++=nj j jjm m x x x y 12110ββββinteraction(交叉):∑≤≠≤++++=mk j k j jkm m x x x x y 1110ββββquadratic(完全二次):∑≤≤++++=mk j k j jkm m x x x x y ,1110ββββ例1. 设某商品的需求量与消费者的平均收入、商品价格的统计数据如下,建立回归模型,预测平均收入为1000、价格为6时的商品需求量. 需求量 10075 80 70 50 65 90 100 110 60收入 1000 600 1200500 300 400 1300 1100 1300 300 价格 5 7 6 6 8 7 5 4 3 9解法一:选择纯二次模型,即2222211122110x x x x y βββββ++++=.直接用多元二项式回归:x1=[1000 600 1200 500 300 400 1300 1100 1300 300]; x2=[5 7 6 6 8 7 5 4 3 9];y=[100 75 80 70 50 65 90 100 110 60]'; x=[x1' x2'];rstool(x,y,'purequadratic')在左边图形下方的方框中输入1000,右边图形下方的方框中输入6,则画面左边的“Predicted Y ”下方的数据变为88.47981,即预测出平均收入为1000、价格为6时的商品需求量为88.4791.在画面左下方的下拉式菜单中选”all ”, 则beta 、rmse 和residuals 都传送到Matlab 工作区中.在Matlab 工作区中输入命令:beta, rmse 得结果:beta =110.5313 0.1464 -26.5709 -0.0001 1.8475 rmse =4.5362故回归模型为:2221218475.10001.05709.261464.05313.110x x x x y +--+=剩余标准差为4.5362, 说明此回归模型的显著性较好.解法二:将2222211122110x x x x y βββββ++++=化为多元线性回归:X=[ones(10,1) x1' x2' (x1.^2)' (x2.^2)'];[b,bint,r,rint,stats]=regress(y,X); b,stats结果为: b =110.5313 0.1464 -26.5709 -0.00011.8475 stats =0.9702 40.6656 0.0005三、非线性回归 1、非线性回归:(1)确定回归系数的命令:[beta,r,J]=nlinfit(x,y,’model ’, beta0)说明:beta 表示估计出的回归系数;r 表示残差;J 表示Jacobian 矩阵;x,y 表示输入数据x 、y 分别为矩阵和n 维列向量,对一元非线性回归,x 为n 维列向量;model 表示是事先用m-文件定义的非线性函数;beta0表示回归系数的初值.(2)非线性回归命令:nlintool(x,y,’model ’, beta0,alpha) 2、预测和预测误差估计:[Y,DELTA]=nlpredci(’model ’, x,beta,r,J)表示nlinfit 或nlintool 所得的回归函数在x 处的预测值Y 及预测值的显著性为1-alpha 的置信区间Y ±DELTA. 例1. 如下程序.解:(1)对将要拟合的非线性模型y=a x b e /,建立m-文件volum.m 如下:function yhat=volum(beta,x) yhat=beta(1)*exp(beta(2)./x); (2)输入数据: x=2:16;y=[6.42 8.20 9.58 9.5 9.7 10 9.93 9.99 10.49 10.59 10.60 10.80 10.60 10.90 10.76];beta0=[8 2]'; (3)求回归系数:[beta,r ,J]=nlinfit(x',y','volum',beta0); beta (4)运行结果:beta =11.6036 -1.0641 即得回归模型为:xey 10641.16036.11-=(5)预测及作图:[YY,delta]=nlpredci('volum',x',beta,r ,J); plot(x,y,'k+',x,YY,'r')四、逐步回归1、逐步回归的命令:stepwise(x,y,inmodel,alpha)说明:x 表示自变量数据,m n ⨯阶矩阵;y 表示因变量数据,1⨯n 阶矩阵;inmodel 表示矩阵的列数的指标,给出初始模型中包括的子集(缺省时设定为全部自变量);alpha 表示显著性水平(缺省时为0.5).2、运行stepwise 命令时产生三个图形窗口:Stepwise Plot,Stepwise Table,StepwiseHistory.在Stepwise Plot窗口,显示出各项的回归系数及其置信区间.(1)Stepwise Table窗口中列出了一个统计表,包括回归系数及其置信区间,以及模型的统计量剩余标准差(RMSE)、相关系数(R-square)、F值、与F对应的概率P.例1. 水泥凝固时放出的热量y与水泥中4种化学成分x1、x2、x3、 x4有关,今测得一组数据如下,试用逐步回归法确定一个线性模型.解:(1)数据输入:x1=[7 1 11 11 7 11 3 1 2 21 1 11 10]';x2=[26 29 56 31 52 55 71 31 54 47 40 66 68]';x3=[6 15 8 8 6 9 17 22 18 4 23 9 8]';x4=[60 52 20 47 33 22 6 44 22 26 34 12 12]';y=[78.5 74.3 104.3 87.6 95.9 109.2 102.7 72.5 93.1 115.9 83.8 113.3 109.4]';x=[x1 x2 x3 x4];(2)逐步回归.①先在初始模型中取全部自变量:stepwise(x,y)得图Stepwise Plot 和表Stepwise Table.图Stepwise Plot中四条直线都是虚线,说明模型的显著性不好.从表Stepwise Table中看出变量x3和x4的显著性最差.②在图Stepwise Plot中点击直线3和直线4,移去变量x3和x4.移去变量x3和x4后模型具有显著性虽然剩余标准差(RMSE)没有太大的变化,但是统计量F的值明显增大,因此新的回归模型更好.(3)对变量y和x1、x2作线性回归.X=[ones(13,1) x1 x2];b=regress(y,X)得结果:b =52.57731.46830.6623故最终模型为:y=52.5773+1.4683x1+0.6623x2或这种方法4元二次线性回归clc;clear;y=[1.84099 9.67 23.00 38.12 1.848794 6.22 12.22 19.72 1.848794 5.19 10.09 15.31 ];X1=[60.36558 59.5376 58.89861 58.74706 60.59389 60.36558 59.2 58.2 60.36558 59.97068 59.41918 58. X2=[26.1636 26.35804 26.82438 26.91521 25.90346 25.9636 27.19256 27.42153 26.1636 26.07212 26.5872 X3=[0.991227 0.994944 0.981322 0.98374 1.011865 0.991227 1.074772 1.107678 0.991227 0.917904 1.06043 X4=[59.37436 58.54265 57.91729 57.69332 59.58203 59.37436 57.76722 57.42355 59.37436 59.05278 58.3587format short gY=y'X11=[ones(1,length(y));X1;X2;X3;X4]'B1=regress(Y,X11)% 多元一次线性回归[m,n]=size(X11)X22=[];for i=2:nfor j=2:nif i<=jX22=([X22,X11(:,i).*X11(:,j)]);elsecontinueendendendX=[X11,X22];B2=regress(Y,X)% 多元二次线性回归[Y X*B2 Y-X*B2]plot(Y,X11*B1,'o',Y,X*B2,'*')hold on,line([min(y),max(y)],[min(y),max(y)]) axis([min(y) max(y) min(y) max(y)])legend('一次线性回归','二次线性回归')xlabel('实际值');ylabel('计算值')运行结果:Y =1.8419.672338.121.84886.2212.2219.721.84885.1910.0915.31X11 =1 60.366 26.164 0.99123 59.3741 59.538 26.358 0.99494 58.5431 58.899 26.824 0.98132 57.9171 58.747 26.915 0.98374 57.6931 60.594 25.903 1.0119 59.5821 60.366 25.964 0.99123 59.3741 59.2 27.193 1.0748 57.7671 58.2 27.422 1.1077 57.4241 60.366 26.164 0.99123 59.3741 59.971 26.072 0.9179 59.0531 59.419 26.587 1.0604 58.3591 58.891 27.061 1.1239 57.767B1 =1488.9-4.3582-9.6345-61.514-15.359m =12n =5B2 =3120.4-7129.2-622.23-362.71-105.061388.1120.25199.25379.58170.48-796.41ans =1.841 1.8449 -0.0039029.67 9.67 1.0058e-00923 23 1.397e-00938.12 38.12 3.539e-0101.8488 1.8488 1.6394e-0096.22 6.227.2643e-01012.22 12.22 2.6077e-01019.72 19.72 -2.0489e-0101.8488 1.8449 0.0039025.19 5.19 1.4529e-00910.09 10.09 1.0803e-00915.31 15.31 4.0978e-010由图形可以看出,多元二次线性回归效果非常好,即,相当于Y=3120.4*X1 -7129.2 *X2 + 0*X3+ 0*X4 -622.23*X1*X1 -362.71*X1*X2 -105.06*X1*X3 + 1388.1*X1*X4 +120.25*X2*X2+ 199.25 *X2*X3+ 379.58*X2*X4 + 170.48*X3*X3+ 0*X3*X4 -796.4。

利用MATLAB进行回归分析一、实验目的:1.了解回归分析的基本原理,掌握MATLAB实现的方法;2. 练习用回归分析解决实际问题。
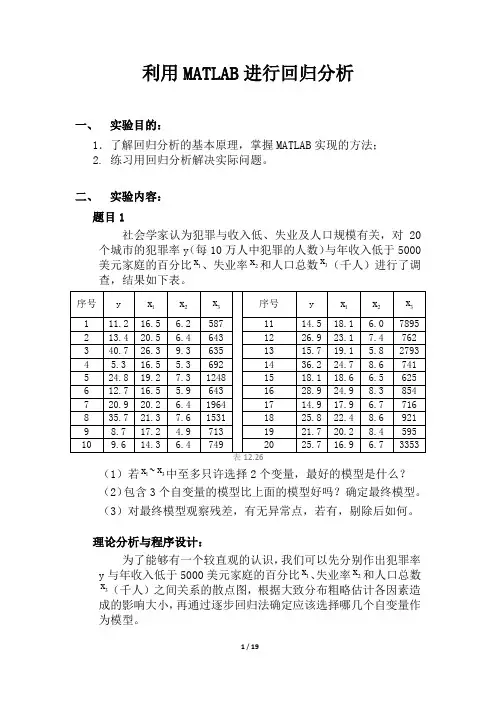
二、实验内容:题目1社会学家认为犯罪与收入低、失业及人口规模有关,对20个城市的犯罪率y(每10万人中犯罪的人数)与年收入低于5000美元家庭的百分比1x、失业率2x和人口总数3x(千人)进行了调查,结果如下表。
(1)若1x~3x中至多只许选择2个变量,最好的模型是什么?(2)包含3个自变量的模型比上面的模型好吗?确定最终模型。
(3)对最终模型观察残差,有无异常点,若有,剔除后如何。
理论分析与程序设计:为了能够有一个较直观的认识,我们可以先分别作出犯罪率y与年收入低于5000美元家庭的百分比1x、失业率2x和人口总数x(千人)之间关系的散点图,根据大致分布粗略估计各因素造3成的影响大小,再通过逐步回归法确定应该选择哪几个自变量作为模型。
编写程序如下:clc;clear all;y=[11.2 13.4 40.7 5.3 24.8 12.7 20.9 35.7 8.7 9.6 14.5 26.9 15.736.2 18.1 28.9 14.9 25.8 21.7 25.7];%犯罪率(人/十万人)x1=[16.5 20.5 26.3 16.5 19.2 16.5 20.2 21.3 17.2 14.3 18.1 23.1 19.124.7 18.6 24.9 17.9 22.4 20.2 16.9];%低收入家庭百分比x2=[6.2 6.4 9.3 5.3 7.3 5.9 6.4 7.6 4.9 6.4 6.0 7.4 5.8 8.6 6.5 8.36.7 8.6 8.4 6.7];%失业率x3=[587 643 635 692 1248 643 1964 1531 713 749 7895 762 2793 741 625 854 716 921 595 3353];%总人口数(千人)figure(1),plot(x1,y,'*');figure(2),plot(x2,y,'*');figure(3),plot(x3,y,'*');X1=[x1',x2',x3'];stepwise(X1,y)运行结果与结论:犯罪率与低收入散点图犯罪率与失业率散点图犯罪率与人口总数散点图低收入与失业率作为自变量低收入与人口总数作为自变量失业率与人口总数作为自变量在图中可以明显看出前两图的线性程度很好,而第三个图的线性程度较差,从这个角度来说我们应该以失业率和低收入为自变量建立模型。

回归分析MATLAB 工具箱一、多元线性回归多元线性回归:p p x x y βββ+++=...110 1、确定回归系数的点估计值: 命令为:b=regress(Y, X ) ①b 表示⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=p b βββˆ...ˆˆ10②Y 表示⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n Y Y Y Y (2)1③X 表示⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=np n n p p x x x x x x x x x X (1)............ (1) (12)12222111211 2、求回归系数的点估计和区间估计、并检验回归模型: 命令为:[b, bint,r,rint,stats]=regress(Y,X,alpha) ①bint 表示回归系数的区间估计. ②r 表示残差. ③rint 表示置信区间.④stats 表示用于检验回归模型的统计量,有三个数值:相关系数r 2、F 值、与F 对应的概率p.说明:相关系数2r 越接近1,说明回归方程越显著;)1,(1-->-k n k F F α时拒绝0H ,F 越大,说明回归方程越显著;与F 对应的概率p α<时拒绝H 0,回归模型成立. ⑤alpha 表示显著性水平(缺省时为0.05)3、画出残差及其置信区间. 命令为:rcoplot(r,rint) 例1.如下程序. 解:(1)输入数据.x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]'; X=[ones(16,1) x];Y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]'; (2)回归分析及检验.[b,bint,r,rint,stats]=regress(Y,X) b,bint,stats得结果:b = bint =-16.0730 -33.7071 1.5612 0.7194 0.6047 0.8340 stats =0.9282 .9531 0.0000即7194.0ˆ,073.16ˆ10=-=ββ;0ˆβ的置信区间为[-33.7017,1.5612], 1ˆβ的置信区间为[0.6047,0.834]; r 2=0.9282, F=180.9531, p=0.0000,我们知道p<0.05就符合条件, 可知回归模型 y=-16.+0.7194x 成立. (3)残差分析,作残差图. rcoplot(r,rint)从残差图可以看出,除第二个数据外,其余数据的残差离零点均较近,且残差的置信区间均包含零点,这说明回归模型 y=-16.+0.7194x 能较好的符合原始数据,而第二个数据可视为异常点. (4)预测及作图.z=b(1)+b(2)*x plot(x,Y,'k+',x,z,'r')二、多项式回归 (一)一元多项式回归.1、一元多项式回归:1121...+-++++=m m m m a x a x a x a y (1)确定多项式系数的命令:[p,S]=polyfit(x,y,m)说明:x=(x 1,x 2,…,x n ),y=(y 1,y 2,…,y n );p=(a 1,a 2,…,a m+1)是多项式y=a 1x m +a 2x m-1+…+a m x+a m+1的系数;S 是一个矩阵,用来估计预测误差. (2)一元多项式回归命令:polytool(x,y,m) 2、预测和预测误差估计.(1)Y=polyval(p,x)求polyfit 所得的回归多项式在x 处的预测值Y ;(2)[Y,DELTA]=polyconf(p,x,S,alpha)求polyfit 所得的回归多项式在x 处的预测值Y 及预测值的显著性为1-alpha 的置信区间Y ±DELTA ;alpha 缺省时为0.5.例1. 观测物体降落的距离s 与时间t 的关系,得到数据如下表,求s. (关于t 的回归方程2ˆct bt a s++=)解法一:直接作二次多项式回归. t=1/30:1/30:14/30;s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48]; [p,S]=polyfit(t,s,2) 得回归模型为:1329.98896.652946.489ˆ2++=t t s解法二:化为多元线性回归. t=1/30:1/30:14/30;s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48];T=[ones(14,1) t' (t.^2)']; [b,bint,r,rint,stats]=regress(s',T);b,stats 得回归模型为:22946.4898896.651329.9ˆt t s++= 预测及作图: Y=polyconf(p,t,S) plot(t,s,'k+',t,Y,'r')(二)多元二项式回归多元二项式回归命令:rstool(x,y,’model ’, alpha)说明:x 表示n ⨯m 矩阵;Y 表示n 维列向量;alpha :显著性水平(缺省时为0.05);model 表示由下列4个模型中选择1个(用字符串输入,缺省时为线性模型):linear(线性):m m x x y βββ+++=Λ110purequadratic(纯二次):∑=++++=nj j jjm m x x x y 12110ββββΛinteraction(交叉):∑≤≠≤++++=mk j k j jkm m x x x x y 1110ββββΛquadratic(完全二次):∑≤≤++++=mk j k j jkm m x x x x y ,1110ββββΛ例1. 设某商品的需求量与消费者的平均收入、商品价格的统计数据如下,建立回归模型,预测平均收入为1000、价格为6时的商品需求量. 需求量 100 75 80 70 50 65 90 100 110 60 收入10006001200500300400130011001300300价格5766875439解法一:选择纯二次模型,即2222211122110x x x x y βββββ++++=.直接用多元二项式回归:x1=[1000 600 1200 500 300 400 1300 1100 1300 300]; x2=[5 7 6 6 8 7 5 4 3 9];y=[100 75 80 70 50 65 90 100 110 60]'; x=[x1' x2'];rstool(x,y,'purequadratic')在左边图形下方的方框中输入1000,右边图形下方的方框中输入6,则画面左边的“Predicted Y ”下方的数据变为88.47981,即预测出平均收入为1000、价格为6时的商品需求量为88.4791.在画面左下方的下拉式菜单中选”all ”, 则beta 、rmse 和residuals 都传送到Matlab 工作区中.在Matlab 工作区中输入命令:beta, rmse 得结果:beta = 110.5313 0.1464 -26.5709 -0.0001 1.8475 rmse = 4.5362故回归模型为:2221218475.10001.05709.261464.05313.110x x x x y +--+=剩余标准差为4.5362, 说明此回归模型的显著性较好.解法二:将2222211122110x x x x y βββββ++++=化为多元线性回归:X=[ones(10,1) x1' x2' (x1.^2)' (x2.^2)']; [b,bint,r,rint,stats]=regress(y,X); b,stats 结果为: b =110.5313 0.1464 -26.5709 -0.0001 1.8475 stats =0.9702 40.6656 0.0005三、非线性回归 1、非线性回归:(1)确定回归系数的命令:[beta,r,J]=nlinfit(x,y,’model ’, beta0)说明:beta 表示估计出的回归系数;r 表示残差;J 表示Jacobian 矩阵;x,y 表示输入数据x 、y 分别为矩阵和n 维列向量,对一元非线性回归,x 为n 维列向量;model 表示是事先用m-文件定义的非线性函数;beta0表示回归系数的初值. (2)非线性回归命令:nlintool(x,y,’model ’, beta0,alpha) 2、预测和预测误差估计:[Y,DELTA]=nlpredci(’model ’, x,beta,r,J)表示nlinfit 或nlintool 所得的回归函数在x 处的预测值Y 及预测值的显著性为1-alpha 的置信区间Y ±DELTA. 例1. 如下程序.解:(1)对将要拟合的非线性模型y=a x b e /,建立m-文件volum.m 如下: function yhat=volum(beta,x) yhat=beta(1)*exp(beta(2)./x); (2)输入数据: x=2:16;y=[6.42 8.20 9.58 9.5 9.7 10 9.93 9.99 10.49 10.59 10.60 10.80 10.60 10.90 10.76];beta0=[8 2]'; (3)求回归系数:[beta,r ,J]=nlinfit(x',y','volum',beta0); beta (4)运行结果:beta =11.6036 -1.0641 即得回归模型为:xey 10641.16036.11-=(5)预测及作图:[YY,delta]=nlpredci('volum',x',beta,r ,J);plot(x,y,'k+',x,YY,'r')四、逐步回归1、逐步回归的命令:stepwise(x,y,inmodel,alpha)n⨯阶矩阵;y表示因变量数据,1⨯n阶矩阵;inmodel表示矩说明:x表示自变量数据,m阵的列数的指标,给出初始模型中包括的子集(缺省时设定为全部自变量);alpha表示显著性水平(缺省时为0.5).2、运行stepwise命令时产生三个图形窗口:Stepwise Plot,Stepwise Table,Stepwise History.在Stepwise Plot窗口,显示出各项的回归系数及其置信区间.(1)Stepwise Table窗口中列出了一个统计表,包括回归系数及其置信区间,以及模型的统计量剩余标准差(RMSE)、相关系数(R-square)、F值、与F对应的概率P.例1. 水泥凝固时放出的热量y与水泥中4种化学成分x1、x2、x3、x4有关,今测得一组数据如下,试用逐步回归法确定一个线性模型.解:(1)数据输入:x1=[7 1 11 11 7 11 3 1 2 21 1 11 10]';x2=[26 29 56 31 52 55 71 31 54 47 40 66 68]';x3=[6 15 8 8 6 9 17 22 18 4 23 9 8]';x4=[60 52 20 47 33 22 6 44 22 26 34 12 12]';y=[78.5 74.3 104.3 87.6 95.9 109.2 102.7 72.5 93.1 115.9 83.8 113.3 109.4]'; x=[x1 x2 x3 x4];(2)逐步回归.①先在初始模型中取全部自变量:stepwise(x,y)得图Stepwise Plot 和表Stepwise Table.图Stepwise Plot中四条直线都是虚线,说明模型的显著性不好.从表Stepwise Table中看出变量x3和x4的显著性最差.②在图Stepwise Plot中点击直线3和直线4,移去变量x3和x4.移去变量x3和x4后模型具有显著性虽然剩余标准差(RMSE)没有太大的变化,但是统计量F的值明显增大,因此新的回归模型更好.(3)对变量y和x1、x2作线性回归.X=[ones(13,1) x1 x2];b=regress(y,X)得结果:b =52.57731.46830.6623故最终模型为:y=52.5773+1.4683x1+0.6623x2或这种方法4元二次线性回归clc;clear;y=[1.84099 9.67 23.00 38.12 1.848794 6.22 12.22 19.72 1.848794 5.19 10.09 15.31 ];X1=[60.36558 59.5376 58.89861 58.74706 60.59389 60.36558 59.2 58.2 60.36558 59.97068 59.41918 5 X2=[26.1636 26.35804 26.82438 26.91521 25.90346 25.9636 27.19256 27.42153 26.1636 26.07212 26.27.06063];X3=[0.991227 0.994944 0.981322 0.98374 1.011865 0.991227 1.074772 1.107678 0.991227 0.917904 1 1.1239];X4=[59.37436 58.54265 57.91729 57.69332 59.58203 59.37436 57.76722 57.42355 59.37436 59.05278 57.76687];format short gY=y'X11=[ones(1,length(y));X1;X2;X3;X4]'B1=regress(Y,X11)% 多元一次线性回归[m,n]=size(X11)X22=[];for i=2:nfor j=2:nif i<=jX22=([X22,X11(:,i).*X11(:,j)]);elsecontinueendendendX=[X11,X22];B2=regress(Y,X)% 多元二次线性回归[Y X*B2 Y-X*B2]plot(Y,X11*B1,'o',Y,X*B2,'*')hold on,line([min(y),max(y)],[min(y),max(y)]) axis([min(y) max(y) min(y) max(y)]) legend('一次线性回归','二次线性回归') xlabel('实际值');ylabel('计算值')运行结果:Y =1.8419.672338.121.84886.2212.2219.721.84885.1910.0915.31X11 =1 60.366 26.164 0.99123 59.3741 59.538 26.358 0.99494 58.5431 58.899 26.824 0.98132 57.9171 58.747 26.915 0.98374 57.6931 60.594 25.903 1.0119 59.5821 60.366 25.964 0.99123 59.3741 59.2 27.193 1.0748 57.7671 58.2 27.422 1.1077 57.4241 60.366 26.164 0.99123 59.3741 59.971 26.072 0.9179 59.1 59.419 26.587 1.0604 58.3591 58.891 27.061 1.1239 57.767 B1 =1488.9-4.3582-9.6345-61.514-15.359m =12n =5B2 =3120.4-7129.2-622.23-362.71-105.061388.1120.25.25379.58170.48-796.41ans =1.841 1.8449 -0.0039029.67 9.67 1.0058e-00923 23 1.397e-00938.12 38.12 3.539e-1.8488 1.8488 1.6394e-0096.22 6.227.2643e-12.22 12.22 2.6077e-19.72 19.72 -2.0489e-1.8488 1.8449 0.0039025.19 5.19 1.4529e-00910.09 10.09 1.0803e-00915.31 15.31 4.0978e-由图形可以看出,多元二次线性回归效果非常好,即,相当于Y=3120.4*X1 -7129.2 *X2 + 0*X3 + 0*X4 -622.23*X1*X1 -362.71*X1*X2 -105.06*X1*X3 + 1388 120.25*X2*X2+ .25 *X2*X3+ 379.58*X2*X4 + 170.48*X3*X3+ 0*X3*X4 -796.41*X4*X4。


本次教程的主要内容包含:一、多元线性回归 2#多元线性回归:regress二、多项式回归 3#一元多项式:polyfit或者polytool 多元二项式:rstool或者rsmdemo三、非线性回归 4#非线性回归:nlinfit四、逐步回归 5#逐步回归:stepwise一、多元线性回归多元线性回归:1、b=regress(Y, X ) 确定回归系数的点估计值2、[b, bint,r,rint,stats]=regress(Y,X,alpha)求回归系数的点估计和区间估计、并检验回归模型①bint表示回归系数的区间估计.②r表示残差③rint表示置信区间④stats表示用于检验回归模型的统计量,有三个数值:相关系数r2、F值、与F对应的概率p说明:相关系数r2越接近1,说明回归方程越显著;时拒绝H0,F越大,说明回归方程越显著;与F对应的概率p<α时拒绝H0⑤alpha表示显著性水平(缺省时为0.05)3、rcoplot(r,rint)画出残差及其置信区间具体参见下面的实例演示4、实例演示,函数使用说明(1)输入数据1.>>x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]';2.>>X=[ones(16,1) x];3.>>Y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]';复制代码(2)回归分析及检验1. >> [b,bint,r,rint,stats]=regress(Y,X)2.3. b =4.5. -16.07306.0.71947.8.9.bint =11. -33.7071 1.561212.0.6047 0.834013.14.15.r =16.17. 1.205618. -3.233119. -0.952420. 1.328221.0.889522. 1.170223. -0.987924.0.292725.0.573426. 1.854027.0.134728. -1.584729. -0.304030. -0.023431. -0.462132.0.099233.34.35.rint =36.37. -1.2407 3.652038. -5.0622 -1.404039. -3.5894 1.684540. -1.2895 3.945941. -1.8519 3.630942. -1.5552 3.895543. -3.7713 1.795544. -2.5473 3.132845. -2.2471 3.393946. -0.7540 4.462147. -2.6814 2.950848. -4.2188 1.049449. -3.0710 2.463050. -2.7661 2.719351. -3.1133 2.189252. -2.4640 2.662453.55.stats =56.57.0.9282 180.9531 0.0000 1.7437复制代码运行结果解读如下参数回归结果为,对应的置信区间分别为[-33.7017,1.5612]和[0.6047,0.834]r2=0.9282(越接近于1,回归效果越显著),F=180.9531,p=0.0000,由p<0.05, 可知回归模型y=-16.073+0.7194x成立(3)残差分析作残差图1.rcoplot(r,rint)复制代码从残差图可以看出,除第二个数据外,其余数据的残差离零点均较近,且残差的置信区间均包含零点,这说明回归模型y=-16.073+0.7194x能较好的符合原始数据,而第二个数据可视为异常点。


利用 Matlab 作回归分析一元线性回归模型:2,(0,)y x N αβεεσ=++求得经验回归方程:ˆˆˆyx αβ=+ 统计量: 总偏差平方和:21()n i i SST y y ==-∑,其自由度为1T f n =-; 回归平方和:21ˆ()n i i SSR y y ==-∑,其自由度为1R f =; 残差平方和:21ˆ()n i i i SSE y y ==-∑,其自由度为2E f n =-;它们之间有关系:SST=SSR+SSE 。
一元回归分析的相关数学理论可以参见《概率论与数理统计教程》,下面仅以示例说明如何利用Matlab 作回归分析。
【例1】为了了解百货商店销售额x 与流通费率(反映商业活动的一个质量指标,指每元商品流转额所分摊的流通费用)y 之间的关系,收集了九个商店的有关数据,见下表1.试建立流通费率y 与销售额x 的回归方程。
表1 销售额与流通费率数据【分析】:首先绘制散点图以直观地选择拟合曲线,这项工作可结合相关专业领域的知识和经验进行,有时可能需要多种尝试。
选定目标函数后进行线性化变换,针对变换后的线性目标函数进行回归建模与评价,然后还原为非线性回归方程。
【Matlab数据处理】:【Step1】:绘制散点图以直观地选择拟合曲线x=[1.5 4.5 7.5 10.5 13.5 16.5 19.5 22.5 25.5];y=[7.0 4.8 3.6 3.1 2.7 2.5 2.4 2.3 2.2];plot(x,y,'-o')输出图形见图1。
510152025图1 销售额与流通费率数据散点图根据图1,初步判断应以幂函数曲线为拟合目标,即选择非线性回归模型,目标函数为:(0)b y ax b =< 其线性化变换公式为:ln ,ln v y u x == 线性函数为:ln v a bu =+【Step2】:线性化变换即线性回归建模(若选择为非线性模型)与模型评价% 线性化变换u=log(x)';v=log(y)';% 构造资本论观测值矩阵mu=[ones(length(u),1) u];alpha=0.05;% 线性回归计算[b,bint,r,rint,states]=regress(v,mu,alpha)输出结果:b =[ 2.1421; -0.4259]表示线性回归模型ln=+中:lna=2.1421,b=-0.4259;v a bu即拟合的线性回归模型为=-;y x2.14210.4259bint =[ 2.0614 2.2228; -0.4583 -0.3934]表示拟合系数lna和b的100(1-alpha)%的置信区间分别为:[2.0614 2.2228]和[-0.4583 -0.3934];r =[ -0.0235 0.0671 -0.0030 -0.0093 -0.0404 -0.0319 -0.0016 0.0168 0.0257]表示模型拟合残差向量;rint =[ -0.0700 0.02300.0202 0.1140-0.0873 0.0813-0.0939 0.0754-0.1154 0.0347-0.1095 0.0457-0.0837 0.0805-0.0621 0.0958-0.0493 0.1007]表示模型拟合残差的100(1-alpha)%的置信区间;states =[0.9928 963.5572 0.0000 0.0012] 表示包含20.9928SSR R SST==、 方差分析的F 统计量/963.5572//(2)R E SSR f SSR F SSE f SSE n ===-、 方差分析的显著性概率((1,2))0p P F n F =->≈; 模型方差的估计值2ˆ0.00122SSE n σ==-。
本次教程的主要内容包含:一、多元线性回归 2#多元线性回归:regress二、多项式回归 3#一元多项式:polyfit或者polytool 多元二项式:rstool或者rsmdemo三、非线性回归 4#非线性回归:nlinfit四、逐步回归 5#逐步回归:stepwise一、多元线性回归多元线性回归:1、b=regress(Y, X ) 确定回归系数的点估计值2、[b, bint,r,rint,stats]=regress(Y,X,alpha)求回归系数的点估计和区间估计、并检验回归模型①bint表示回归系数的区间估计.②r表示残差③rint表示置信区间④stats表示用于检验回归模型的统计量,有三个数值:相关系数r2、F值、与F对应的概率p说明:相关系数r2越接近1,说明回归方程越显著;时拒绝H0,F越大,说明回归方程越显著;与F对应的概率p<α时拒绝H0⑤alpha表示显著性水平(缺省时为0.05)3、rcoplot(r,rint)画出残差及其置信区间具体参见下面的实例演示4、实例演示,函数使用说明(1)输入数据1.>>x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]';2.>>X=[ones(16,1) x];3.>>Y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]';复制代码(2)回归分析及检验1. >> [b,bint,r,rint,stats]=regress(Y,X)2.3. b =4.5. -16.07306.0.71947.8.9.bint =11. -33.7071 1.561212.0.6047 0.834013.14.15.r =16.17. 1.205618. -3.233119. -0.952420. 1.328221.0.889522. 1.170223. -0.987924.0.292725.0.573426. 1.854027.0.134728. -1.584729. -0.304030. -0.023431. -0.462132.0.099233.34.35.rint =36.37. -1.2407 3.652038. -5.0622 -1.404039. -3.5894 1.684540. -1.2895 3.945941. -1.8519 3.630942. -1.5552 3.895543. -3.7713 1.795544. -2.5473 3.132845. -2.2471 3.393946. -0.7540 4.462147. -2.6814 2.950848. -4.2188 1.049449. -3.0710 2.463050. -2.7661 2.719351. -3.1133 2.189252. -2.4640 2.662453.55.stats =56.57.0.9282 180.9531 0.0000 1.7437复制代码运行结果解读如下参数回归结果为,对应的置信区间分别为[-33.7017,1.5612]和[0.6047,0.834]r2=0.9282(越接近于1,回归效果越显著),F=180.9531,p=0.0000,由p<0.05, 可知回归模型y=-16.073+0.7194x成立(3)残差分析作残差图1.rcoplot(r,rint)复制代码从残差图可以看出,除第二个数据外,其余数据的残差离零点均较近,且残差的置信区间均包含零点,这说明回归模型y=-16.073+0.7194x能较好的符合原始数据,而第二个数据可视为异常点。
(4)预测及作图1.z=b(1)+b(2)*x2.plot(x,Y,'k+',x,z,'r')二、多项式回归一元多项式回归1、一元多项式回归函数(1)[p,S]=polyfit(x,y,m) 确定多项式系数的MATLAB命令说明:x=(x1,x2,…,x n),y=(y1,y2,…,y n);p=(a1,a2,…,a m+1)是多项式y=a1x m+a2x m-1+…+a m x+a m+1的系数;S是一个矩阵,用来估计预测误差(2)polytool(x,y,m) 调用多项式回归GUI界面,参数意义同polyfit2、预测和预测误差估计(1)Y=polyval(p,x) 求polyfit所得的回归多项式在x处的预测值Y(2)[Y,DELTA]=polyconf(p,x,S,alpha) 求polyfit所得的回归多项式在x处的预测值Y及预测值的显著性为1-alpha的置信区间Y±DELTA,alpha缺省时为0.53、实例演示说明观测物体降落的距离s与时间t的关系,得到数据如下表,求s的表达式(即回归方程s=a+bt+ct2)t (s) 1/30 2/30 3/30 4/30 5/30 6/30 7/30s (cm) 11.86 15.67 20.60 26.69 33.71 41.93 51.13t (s) 8/30 9/30 10/30 11/30 12/30 13/30 14/30s (cm) 61.49 72.90 85.44 99.08 113.77 129.54 146.48解法一:直接作二次多项式回归1.>>t=1/30:1/30:14/30;2.>>s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48];3.>>[p,S]=polyfit(t,s,2)4.5.p =6.7. 489.2946 65.8896 9.13298.9.10.S =11.12. R: [3x3 double]13. df: 1114. normr: 0.1157复制代码故回归模型为解法二:化为多元线性回归1.>>t=1/30:1/30:14/30;2.>>s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48];3.>>T=[ones(14,1) t' (t.^2)'];4.>>[b,bint,r,rint,stats]=regress(s',T)5.6. b =7.8. 9.13299. 65.889610. 489.294611.12.13.bint =14.15. 9.0614 9.204416. 65.2316 66.547617. 488.0146 490.574718.19.20.r =21.22. -0.012923. -0.030224. -0.014825. 0.073226. 0.004027. 0.047428. -0.016529. -0.007830. -0.036331. -0.022232. 0.004633. -0.005934. -0.023735. 0.041136.37.38.rint =39.40. -0.0697 0.043941. -0.0956 0.035242. -0.0876 0.058043. 0.0182 0.128344. -0.0709 0.078945. -0.0192 0.113946. -0.0894 0.056347. -0.0813 0.065848. -0.1062 0.033549. -0.0955 0.051150. -0.0704 0.079651. -0.0793 0.067552. -0.0904 0.042953. -0.0088 0.091054.55.56.stats =57.58. 1.0e+007 *59.60. 0.0000 1.0378 0 0.0000复制代码故回归模型为:预测及作图1.Y=polyconf(p,t,S);2.plot(t,s,'k+',t,Y,'r')复制代码多元二项式回归1、多元二项式回归Matlab命令rstool(x,y,'model',alpha)输入参数说明:x:n*m矩阵;Y:n维列向量;alpha:显著性水平(缺省时为0.05);mode:由下列4个模型中选择1个(用字符串输入,缺省时为线性模型)2、实例演示说明设某商品的需求量与消费者的平均收入、商品价格的统计数据如下,建立回归模型,预测平均收入为1000、价格为6时的商品需求量需求量 100 75 80 70 50 65 90 100 110 60收入 1000 600 1200 500 300 400 1300 1100 1300 300价格 5 7 6 6 8 7 5 4 3 9解法一:选择纯二次模型1.%直接用多元二项式回归如下2.x1=[1000 600 1200 500 300 400 1300 1100 1300 300];3.x2=[5 7 6 6 8 7 5 4 3 9];4.y=[100 75 80 70 50 65 90 100 110 60]';5.x=[x1' x2'];6.rstool(x,y,'purequadratic')复制代码在x1对应的文本框中输入1000,X2中输入6,敲回车键,此时图形和相关数据会自动更新此时在GUI左边的“Predicted Y1”下方的数据变为88.47981,表示平均收入为1000、价格为6时商品需求量为88.4791点击左下角的Export按钮,将会导出回归的相关参数beta、rmse和residuals到工作空间(workspace) 在Export按钮下面可以选择回归类型在Matlab命令窗口中输入1.>>beta, rmse复制代码将得到如下结果1.beta =2. 110.53133. 0.14644. -26.57095. -0.00016. 1.84757. rmse =8. 4.5362复制代码故回归模型为解法二:将上面的模型转换为多元线性回归1.>>X=[ones(10,1) x1' x2' (x1.^2)' (x2.^2)'];2.>>[b,bint,r,rint,stats]=regress(y,X);3.>>b,stats4.5. b =6.7. 110.53138. 0.14649. -26.570910. -0.000111. 1.847512.13.14.stats =15.16. 0.9702 40.6656 0.0005 20.5771三、非线性回归1、非线性回归[beta,r,J]=nlinfit(x,y,'modelfun', beta0) 非线性回归系数的命令nlintool(x,y,'modelfun', beta0,alpha) 非线性回归GUI界面参数说明beta:估计出的回归系数;r:残差;J:Jacobian矩阵;x,y:输入数据x、y分别为矩阵和n维列向量,对一元非线性回归,x为n维列向量;modelfun:M函数、匿名函数或inline函数,定义的非线性回归函数;beta0:回归系数的初值;2、预测和预测误差估计[Y,DELTA]=nlpredci('modelfun', x,beta,r,J)获取x处的预测值Y及预测值的显著性为1-alpha的置信区间Y±DELTA3、实例演示说明解:(1)对将要拟合的非线性模型,建立M函数如下1.function yhat=modelfun(beta,x)2.%beta是需要回归的参数3.%x是提供的数据4.yhat=beta(1)*exp(beta(2)./x);复制代码(2)输入数据1.x=2:16;2.y=[6.42 8.20 9.58 9.5 9.7 10 9.93 9.99 10.49 10.59 10.60 10.80 10.60 10.90 10.76];3.beta0=[8 2]';复制代码(3)求回归系数1.[beta,r ,J]=nlinfit(x',y',@modelfun,beta0);2.beta3.4.beta =5. 11.60366. -1.0641复制代码即得回归模型为(4)预测及作图1.[YY,delta]=nlpredci('modelfun',x',beta,r ,J);2.plot(x,y,'k+',x,YY,'r')复制代码四、逐步回归1、逐步回归的命令stepwise(x,y,inmodel,alpha) 根据数据进行分步回归stepwise 直接调出分步回归GUI界面输入参数说明x:自变量数据,阶矩阵;y:因变量数据, 阶矩阵;inmodel:矩阵的列数的指标,给出初始模型中包括的子集(缺省时设定为全部自变量);alpha:显著性水平(缺省时为0.5);2、实例演示分析水泥凝固时放出的热量y与水泥中4种化学成分x1、x2、x3、 x4有关,今测得一组数据如下,试用逐步回归法确定一个线性模型序号 1 2 3 4 5 6 7 8 9 10 11x1 7 1 11 11 7 11 3 1 2 21 1 x2 26 29 56 31 52 55 71 31 54 47 40 66 68 x3 6 15 8 8 6 9 17 22 18 4 23 9x4 60 52 20 47 33 22 6 44 22 26 34 12 12y 78.5 74.3 104.3 87.6 95.9 109.2 102.7 72.5 93.1 115.9 83.8 113.3 109.(1)数据输入1.x1=[7 1 11 11 7 11 3 1 2 21 1 11 10]';2.x2=[26 29 56 31 52 55 71 31 54 47 40 66 68]';3.x3=[6 15 8 8 6 9 17 22 18 4 23 9 8]';4.x4=[60 52 20 47 33 22 6 44 22 26 34 12 12]';5.y=[78.5 74.3 104.3 87.6 95.9 109.2 102.7 72.5 93.1 115.9 83.8 113.3 109.4]';6.x=[x1 x2 x3 x4];复制代码(2)逐步回归①先在初始模型中取全部自变量1.stepwise(x,y)复制代码。