传智播客hibernate教程
- 格式:ppt
- 大小:550.00 KB
- 文档页数:50

Hibernate 学习教程第1课课程内容. 6第2课Hibernate UML图. 6第3课风格. 7第4课资源. 7第5课环境准备. 7第6课第一个示例HibernateHelloWorld 7第7课建立Annotation版本的HellWorld 9第8课什么是O/RMapping 11一、定义:. 11二、 Hibernate的创始人:. 11三、 Hibernate做什么:. 12四、 Hibernate存在的原因:. 12五、 Hibernate的优缺点:. 12六、 Hibernate使用范围:. 12第9课Hibernate的重点学习:Hibernate的对象关系映射. 12一、对象---关系映射模式. 12二、常用的O/R映射框架:. 13第10课模拟Hibernate原理(OR模拟) 13一、项目名称. 13二、原代码. 13第11课Hibernate基础配置. 15一、提纲. 15二、介绍MYSQL的图形化客户端. 16三、 Hibernate.cfg.xml:hbm2ddl.auto 16四、搭建日志环境并配置显示DDL语句. 16五、搭建Junit环境. 16六、 ehibernate.cfg.xml : show_sql 17七、 hibernate.cfg.xml :format_sql 17八、表名和类名不同,对表名进行配置. 17九、字段名和属性相同. 17十、字段名和属性名不同. 17十一、不需要(持久化)psersistence的字段. 18十二、映射日期与时间类型,指定时间精度. 18十三、映射枚举类型. 19第12课使用hibernate工具类将对象模型生成关系模型. 19第13课ID主键生成策略. 20一、 Xml方式. 20<generator>元素(主键生成策略) 20二、 annotateon方式. 211、AUTO默认. 212、IDENTITY 223、SEQUENCE 224、为Oracle指定定义的Sequence 225、TABLE - 使用表保存id值. 23三、联合主键. 241、xml方式. 242、annotation方式. 27第14课Hibernate核心开发接口(重点) 29一、 Configuration(AnnotationConfiguration) 29二、 SessionFactory 29三、 Session 291、管理一个数据库的任务单元. 292、 save(); 293、 delete() 294、 load() 295、 Get() 306、 load()与get()区别. 317、 update() 318、 saveOrUpdate() 329、 clear() 3210、 flush() 3311、 evict() 33第15课持久化对象的三种状态. 35一、瞬时对象(TransientObject):. 35二、持久化对象(PersistentObject):. 35三、离线对象(DetachedObject):. 35四、三种状态的区分:. 35五、总结:. 35第16课关系映射(重点) 36一、一对一关联映射. 36(一) 唯一外键关联-单向(unilateralism) 37(二) 唯一外键关联-双向. 40(三) 主键关联-单向(不重要) 41(四) 主键关联-双向(不重要) 44(五) 联合主键关联(Annotation方式) 44二、 component(组件)关联映射. 45(一) Component关联映射:. 45(二) User实体类:. 45(三) Contact值对象:. 46(四) xml--User映射文件(组件映射):. 46(五) annotateon注解. 46(六) 导出数据库输出SQL语句:. 47(七) 数据表结构:. 47(八) 组件映射数据保存:. 47三、多对一–单向. 48(一) 对象模型图:. 48(二) 关系模型:. 48(三) 关联映射的本质:. 48(四) 实体类. 48(五) xml方式:映射文件:. 49(六) annotation 50(七) 多对一存储(先存储group(对象持久化状态后,再保存user)):. 50(八) 重要属性-cascade(级联):. 51(九) 多对一加载数据. 51四、一对多- 单向. 51(一) 对象模型:. 52(二) 关系模型:. 52(三) 多对一、一对多的区别:. 52(四) 实体类. 52(五) xml方式:映射. 52(六) annotateon注解. 53(七) 导出至数据库(hbmàddl)生成的SQL语句:. 53(八) 一对多单向存储实例:. 53(九) 生成的SQL语句:. 54(十) 一对多,在一的一端维护关系的缺点:. 54 (十一) 一对多单向数据加载:. 54(十二) 加载生成SQL语句:. 54五、一对多- 双向. 54(一) xml方式:映射. 55(二) annotateon方式注解. 55(三) 数据保存:. 56(四) 关于inverse属性:. 56(五) Inverse和cascade区别:. 56(六) 一对多双向关联映射总结:. 57六、多对多- 单向. 57(一) 实例场景:. 57(二) 对象模型:. 57(三) 关系模型:. 57(四) 实体类. 57(五) xml方式:映射. 58(六) annotation注解方式. 58(七) 生成SQL语句. 59(八) 数据库表及结构:. 59(九) 多对多关联映射单向数据存储:. 59(十) 多对多关联映射单向数据加载:. 61七、多对多- 双向. 61(一) xml方式:映射. 61(二) annotation注解方式. 62八、关联关系中的CRUD_Cascade_Fetch 63九、集合映射. 63十、继承关联映射. 64(一) 继承关联映射的分类:. 64(二) 对象模型:. 64(三) 单表继承SINGLE_TABLE:. 64(四) 具体表继承JOINED:. 70(五) 类表继承TABLE_PER_CLASS 72(六) 三种继承关联映射的区别:. 74第17课hibernate树形结构(重点) 75一、节点实体类:. 75二、 xml方式:映射文件:. 75三、 annotation注解. 76四、测试代码:. 76五、相应的类代码:. 76第18课作业-学生、课程、分数的映射关系. 79一、设计. 79二、代码:. 79三、注意. 80第19课Hibernate查询(Query Language) 80一、 Hibernate可以使用的查询语言. 80二、实例一. 80三、实体一测试代码:. 82四、实例二. 86五、实例二测试代码. 87第20课Query by Criteria(QBC) 89一、实体代码:. 89二、 Restrictions用法. 90三、工具类Order提供设置排序方式. 91四、工具类Projections提供对查询结果进行统计与分组操作. 91五、 QBC分页查询. 92六、 QBC复合查询. 92七、 QBC离线查询. 92第21课Query By Example(QBE) 92一、实例代码. 92第22课Query.list与query.iterate(不太重要) 93一、 query.iterate查询数据. 93二、 query.list()和query.iterate()的区别. 94三、两次query.list() 94第23课性能优化策略. 95第24课hibernate缓存. 95一、 Session级缓存(一级缓存) 95二、二级缓存. 951、二级缓存的配置和使用:. 962、二级缓存的开启:. 963、指定二级缓存产品提供商:. 964、使用二级缓存. 975、应用范围. 996、二级缓存的管理:. 997、二级缓存的交互. 1008、总结. 102三、查询缓存. 102四、缓存算法. 103第25课事务并发处理. 104一、数据库的隔离级别:并发性作用。


Hibernate教程---看这⼀篇就够了1 Hibernate概述1.1什么是hibernate框架(重点)1 hibernate框架应⽤在javaee三层结构中 dao层框架2 在dao层⾥⾯做对数据库crud操作,使⽤hibernate实现crud操作,hibernate底层代码就是jdbc,hibernate对jdbc进⾏封装,使⽤hibernate好处,不需要写复杂jdbc代码了,不需要写sql语句实现3 hibernate开源的轻量级的框架4 hibernate版本Hibernate3.xHibernate4.xHibernate5.x(学习)1.2 什么是orm思想(重点)1 hibernate使⽤orm思想对数据库进⾏crud操作2 在web阶段学习 javabean,更正确的叫法实体类3 orm:object relational mapping,对象关系映射⽂字描述:(1)让实体类和数据库表进⾏⼀⼀对应关系让实体类⾸先和数据库表对应让实体类属性和表⾥⾯字段对应(2)不需要直接操作数据库表,⽽操作表对应实体类对象画图描述2 Hibernate⼊门2.1 搭建hibernate环境(重点)第⼀步导⼊hibernate的jar包因为使⽤hibernate时候,有⽇志信息输出,hibernate本⾝没有⽇志输出的jar包,导⼊其他⽇志的jar包不要忘记还有mysql驱动的jar包第⼆步创建实体类package cn.itcast.entity;public class User {/*hibernate要求实体类有⼀个属性唯⼀的*/// private int uid;private String uid;private String username;private String password;private String address;// public int getUid() {// return uid;// }// public void setUid(int uid) {// this.uid = uid;// }public String getUsername() {return username;}public String getUid() {return uid;}public void setUid(String uid) {this.uid = uid;}public void setUsername(String username) {ername = username;}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}public String getAddress() {return address;}public void setAddress(String address) {this.address = address;}}(1)使⽤hibernate时候,不需要⾃⼰⼿动创建表,hibernate帮把表创建第三步配置实体类和数据库表⼀⼀对应关系(映射关系)使⽤配置⽂件实现映射关系(1)创建xml格式的配置⽂件- 映射配置⽂件名称和位置没有固定要求- 建议:在实体类所在包⾥⾯创建,实体类名称.hbm.xml(2)配置是是xml格式,在配置⽂件中⾸先引⼊xml约束- 学过约束dtd、schema,在hibernate⾥⾯引⼊的约束dtd约束(3)配置映射关系<hibernate-mapping><!-- 1 配置类和表对应class标签name属性:实体类全路径table属性:数据库表名称--><class name="er" table="t_user"><!-- 2 配置实体类id和表id对应hibernate要求实体类有⼀个属性唯⼀值hibernate要求表有字段作为唯⼀值--><!-- id标签name属性:实体类⾥⾯id属性名称column属性:⽣成的表字段名称--><id name="uid" column="uid"><!-- 设置数据库表id增长策略native:⽣成表id值就是主键⾃动增长--><generator class="native"></generator></id><!-- 配置其他属性和表字段对应name属性:实体类属性名称column属性:⽣成表字段名称--><property name="username" column="username"></property><property name="password" column="password"></property><property name="address" column="address"></property></class></hibernate-mapping>第四步创建hibernate的核⼼配置⽂件(1)核⼼配置⽂件格式xml,但是核⼼配置⽂件名称和位置固定的- 位置:必须src下⾯- 名称:必须hibernate.cfg.xml(2)引⼊dtd约束(3)hibernate操作过程中,只会加载核⼼配置⽂件,其他配置⽂件不会加载第⼀部分:配置数据库信息必须的第⼆部分:配置hibernate信息可选的第三部分:把映射⽂件放到核⼼配置⽂件中<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD 3.0//EN""/dtd/hibernate-configuration-3.0.dtd"><hibernate-configuration><session-factory><!-- 第⼀部分:配置数据库信息必须的 --><property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property> <property name="hibernate.connection.url">jdbc:mysql:///hibernate_day01</property> <property name="ername">root</property><property name="hibernate.connection.password">root</property><!-- 第⼆部分:配置hibernate信息可选的--><!-- 输出底层sql语句 --><property name="hibernate.show_sql">true</property><!-- 输出底层sql语句格式 --><property name="hibernate.format_sql">true</property><!-- hibernate帮创建表,需要配置之后update: 如果已经有表,更新,如果没有,创建--><property name="hibernate.hbm2ddl.auto">update</property><!-- 配置数据库⽅⾔在mysql⾥⾯实现分页关键字 limit,只能使⽤mysql⾥⾯在oracle数据库,实现分页rownum让hibernate框架识别不同数据库的⾃⼰特有的语句--><property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property><!-- 第三部分:把映射⽂件放到核⼼配置⽂件中必须的--><mapping resource="cn/itcast/entity/User.hbm.xml"/></session-factory></hibernate-configuration>2.2 实现添加操作第⼀步加载hibernate核⼼配置⽂件第⼆步创建SessionFactory对象第三步使⽤SessionFactory创建session对象第四步开启事务第五步写具体逻辑 crud操作第六步提交事务第七步关闭资源@Testpublic void testAdd() {// 第⼀步加载hibernate核⼼配置⽂件// 到src下⾯找到名称是hibernate.cfg.xml//在hibernate⾥⾯封装对象Configuration cfg = new Configuration();cfg.configure();// 第⼆步创建SessionFactory对象//读取hibernate核⼼配置⽂件内容,创建sessionFactory//在过程中,根据映射关系,在配置数据库⾥⾯把表创建SessionFactory sessionFactory = cfg.buildSessionFactory(); // 第三步使⽤SessionFactory创建session对象// 类似于连接Session session = sessionFactory.openSession();// 第四步开启事务Transaction tx = session.beginTransaction();// 第五步写具体逻辑 crud操作//添加功能User user = new User();user.setUsername("⼩王");user.setPassword("250");user.setAddress("⽇本");//调⽤session的⽅法实现添加session.save(user);// 第六步提交事务mit();// 第七步关闭资源session.close();sessionFactory.close();}3 内容⽬录1 实体类编写规则2 hibernate主键⽣成策略(1)native(2)uuid3 实体类操作(1)crud操作(2)实体类对象状态4 hibernate的⼀级缓存5 hibernate的事务操作(1)事务代码规范写法6 hibernate其他的api(查询)(1)Query(2)Criteria(3)SQLQuery3.1 实体类编写规则1 实体类⾥⾯属性私有的2 私有属性使⽤公开的set和get⽅法操作3 要求实体类有属性作为唯⼀值(⼀般使⽤id值)4 实体类属性建议不使⽤基本数据类型,使⽤基本数据类型对应的包装类(1)⼋个基本数据类型对应的包装类- int – Integer- char—Character、- 其他的都是⾸字母⼤写⽐如 double – Double(2)⽐如表⽰学⽣的分数,假如 int score;- ⽐如学⽣得了0分,int score = 0;- 如果表⽰学⽣没有参加考试,int score = 0;不能准确表⽰学⽣是否参加考试l 解决:使⽤包装类可以了, Integer score = 0,表⽰学⽣得了0分,表⽰学⽣没有参加考试,Integer score = null;3.2 Hibernate主键⽣成策略1 hibernate要求实体类⾥⾯有⼀个属性作为唯⼀值,对应表主键,主键可以不同⽣成策略2 hibernate主键⽣成策略有很多的值3 在class属性⾥⾯有很多值(1)native:根据使⽤的数据库帮选择哪个值(2)uuid:之前web阶段写代码⽣成uuid值,hibernate帮我们⽣成uuid值3.3 实体类操作对实体类crud操作添加操作1 调⽤session⾥⾯的save⽅法实现根据id查询1 调⽤session⾥⾯的get⽅法实现修改操作1 ⾸先查询,修改值(1)根据id查询,返回对象删除操作1 调⽤session⾥⾯delete⽅法实现3.4 实体类对象状态(概念)1 实体类状态有三种(1)瞬时态:对象⾥⾯没有id值,对象与session没有关联(2)持久态:对象⾥⾯有id值,对象与session关联(3)托管态:对象有id值,对象与session没有关联2 演⽰操作实体类对象的⽅法(1)saveOrUpdate⽅法:实现添加、实现修改3.5 Hibernate的⼀级缓存什么是缓存1 数据存到数据库⾥⾯,数据库本⾝是⽂件系统,使⽤流⽅式操作⽂件效率不是很⾼。


hibernate3.0用法hibernate教程非hibernate基础教程HQL查询:Criteria查询对查询条件进行了面向对象封装,符合编程人员的思维方式,不过HQL(Hibernate Query Lanaguage)查询提供了更加丰富的和灵活的查询特性,因此Hibernate将HQL查询方式立为官方推荐的标准查询方式,HQL查询在涵盖Criteria查询的所有功能的前提下,提供了类似标准SQL语句的查询方式,同时也提供了更加面向对象的封装。
完整的HQL语句形势如下:Selec t/update/delete…… from …… where …… group by …… having …… order by …… asc/desc其中的update/delete为Hibernate3中所新添加的功能,可见HQL查询非常类似于标准SQL 查询。
由于HQL查询在整个Hibernate实体操作体系中的核心地位,这一节我将专门围绕HQL操作的具体技术细节进行讲解。
1、实体查询:有关实体查询技术,其实我们在先前已经有多次涉及,比如下面的例子:String hql=”from User user ”;List list=session.CreateQuery(hql).list();上面的代码执行结果是,查询出User实体对象所对应的所有数据,而且将数据封装成User 实体对象,并且放入List中返回。
这里需要注意的是,Hibernate的实体查询存在着对继承关系的判定,比如我们前面讨论映射实体继承关系中的Employee实体对象,它有两个子类分别是HourlyEmployee,SalariedEmployee,如果有这样的HQL语句:“from Employee”,当执行检索时Hibernate会检索出所有Employee类型实体对象所对应的数据(包括它的子类HourlyEmployee,SalariedEmployee对应的数据)。

传智播客-jpa与hibernate(1)-实体和主键生成-那一抹云-CSDN博客传智播客-jpa与hibernate(1)-实体和主键生成收藏jpa全称是Java Persistence API,是sun公司出台的面向数据持久化层的规范,即面向接口编程,以达到“平台”无关性(这个“平台”是指jpa产品,例如hibernate,toplink,openjpa等)。
hibernate是符合jpa规范的产品之一。
说到数据持久化,先说一下以下几点:1、对于数据持久化的思想而言,内存只是一个交换数据的地方,这意味着如果断电或者进程被杀,数据就会丢失。
2、为了防止数据丢失,所以需要将数据保存到外层(硬盘,U盘或其他存储设备等)。
3、能够实现数据持久化保存的技术就称之为数据持久化。
除了jpa,还有jdbc、io等都是。
4、应用系统里的数据持久化层是从业务逻辑层分离出来的。
关于实体:1、在jpa规范里,被托管的对象都是实体,但是是用实体名来区分实体的,如果没有显示声明,默认的实体名即不包含全路径的类名,所以如果不同包下有相同类名,应该显示声明实体名予以区分,例如@Entity(name="XXX")。
2、在jpa规范出来前,hibernate等数据持久化层技术产品早已大行其道,鱼龙混杂,jpa的出现可以说对这个市场进行了规范。
hibernate在 jpa出来前是用配置文件注册托管实体的(还有一些辅助工具帮助实现实体和表模式的相互转换,可以参见《深入浅出Hibernate》),但是jpa只支持注解方式(jpa支持配置文件方式,只是很少有人这么用,就当它没有吧。
)。
所以hibernate有两种方式注册托管实体:xml配置文件和注解。
3、如果用的jpa产品是hibernate,则在persistence.xml配置文件中不用注册实体类名也能被hibernate识别,因为hibernate有扫描机制,但是其它jpa产品不一定有,所以为了提高程序的可移植性,还是在文件中加上比较好,而且这样写也比较规范。

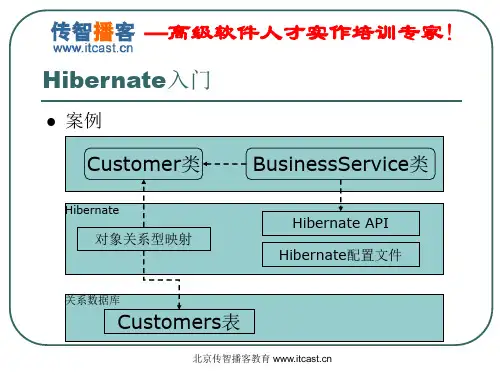

Hibernate教程前言1、 java对象持久化技术1.1 、hibernate是什么1.2、软件模型1.2.1、概念模型1.2.2、关系数据模型1.2.3、域模型1.2.4、域对象1.2.5、域对象之间的关系1.2.6、域对象的持久化概念提示:1.3、数据库访问模式1.3.1、ORM模式1.3.2、主动域对象模式1.3.3、JDO模式1.3.4、CMP模式一、数据源层-O/R Mapping主要介绍三层架构,如何分层?(逻辑上的分层,二个原则)数据层技术的选择:直接使用1.1、SQL/JDBC:优点:很多开发者熟悉关系数据库管理系统,理解SQL,也知道如何使用表和外键进行工作。
此外,他们可以始终使用众所周知并广泛使用的DAO设计模式对业务逻辑隐藏复杂的JDBC代码和不可移植的SQL。
缺点:为域中的每个类手工编写持续性代码的工作是非常可观的,特别是需要支持多种SQL方言时。
这项工作通常会消耗很大一部分的开发努力。
此外,当需求改变时,一个手工编码的解决方案总是需要更多的注意和维护努力。
1.2、序列化:Java有一个内建的持久化机制:序列化提供了将对象图(应用状态)写到字节流中的能力,然后它可能被持久化到文件或数据库中。
持久化也被Java的远程方法调用(RMI)使用来为复杂对象传递值语义。
持久化的另一种用法是在机器集群中跨节点复制应用状态。
缺点:很不幸,一个相互连接的对象图在序列化之后只能被当作一个整体访问,如果不反序列化整个流就不可能从流中取出任何数据。
这样,结果字节流肯定会被认为不适合进行任意的检索或聚合。
甚至不可能独立地访问或更新一个单独的对象或子图。
非常明显,因为当前特定的技术,序列化不适合于作为高并发性的Web和企业应用的持久化机制。
在特定的环境中它被作为桌面应用的适当的持久化机制。
1.3EJB entity beansEJB1.1实体Bean在实践中彻底地失败了。
EJB规范的设计缺陷阻碍了Bean管理的持续性(BMP)实体Bean有效地执行。

传智播客-jpa与hibernate(3)-继承映射-那一抹云-CSDN博客传智播客-jpa与hibernate(3)-继承映射收藏Hibernate支持三种基本的继承映射策略:每个类分层结构一张表(table per class hierarchy),每个子类一张表(table per subclass),每个具体类一张表(table per concrete class),此外,Hibernate还支持第四种稍有不同的多态映射策略--隐式多态(implicit polymorphism) 。
这里只介绍前三种,最后一种请参阅相关文档。
代码示例为注解方式,配置方式请参阅文档。
每个类分层结构一张表(table per class hierarchy)也称单表策略,就是一棵继承树映射为一张表,或者说将一棵继承树里所有类的信息不重复地放到一张表里。
因为所有的父子类都在一张表里体现,所以还需要一个额外的字段以区分每条记录代表的具体的类别。
举例来说,有父类Employee(雇员),子类HE(钟点工),同级子类SE(正式员工);HE和SE的区别在于薪资,HE以时效计,字段为rate,SE以月薪计,字段为salary;还有一个字段etype作为具体类别信息的区分标识。
很明显,rate和salary是互斥的。
所以这两个字段应当允许为空,而且实际操作的时候必然会有一个字段列的冗余。
etype对于每个类别信息自身而言,也可以视为是一个冗余字段。
所以这个策略一般在父类的属性字段占总字段的权重大的时候较为适用。
示例代码:@Entity@Table(name="jpa_inherit_single_ess")@Inheritance(strategy=InheritanceType.SINGLE_TABLE)@DiscriminatorColumn(name="etype",discriminatorType=D iscriminatorType.STRING)@DiscriminatorValue(value="ee")public class Employee {...}@Entity@DiscriminatorValue(value="he")public class HE extends Employee {...}@Entity@DiscriminatorValue(value="se")public class SE extends Employee {...}NOTE: 查询的时候不是用entityManager.find(XXX.class, serialable)。

hibernate官方入门教程第一部分-第一个Hibernate程序首先我们将创建一个简单的控制台(console-based)Hibernate程序。
我们使用内置数据库(in-memory database) (HSQL DB),所以我们不必安装任何数据库服务器。
让我们假设我们希望有一个小程序可以保存我们希望关注的事件(Event)和这些事件的信息。
(译者注:在本教程的后面部分,我们将直接使用Event而不是它的中文翻译“事件”,以免混淆。
)我们做的第一件事是建立我们的开发目录,并把所有需要用到的Java库文件放进去。
从Hibernate网站的下载页面下载Hibernate分发版本。
解压缩包并把/lib下面的所有库文件放到我们新的开发目录下面的/lib目录下面。
看起来就像这样:.+lib antlr.jar cglib-full.jar asm.jar asm-attrs.jars commons-collections.jar commons-loggin g.jar ehcache.jar hibernate3.jar jta.jar dom4j.jar log4j.jarThis is the minimum set of required libraries (note that we also copied hibernate3.jar, the main archive) for Hibernate. See the README.txt file in the lib/ directory of the Hibernate distribution for more information about required and optional third-party libraries. (Actually, Log4j is not required but preferred by many developers.) 这个是Hibernate运行所需要的最小库文件集合(注意我们也拷贝了Hibernate3.jar,这个是最重要的库)。
Hibernate的一对多操作(重点)一对多映射配置(重点)以客户和联系人为例:客户是一,联系人是多第一步创建两个实体类,客户和联系人第二步让两个实体类之间互相表示(1)在客户实体类里面表示多个联系人- 一个客户里面有多个联系人(2)在联系人实体类里面表示所属客户- 一个联系人只能属于一个客户第三步配置映射关系(1)一般一个实体类对应一个映射文件(2)把映射最基本配置完成(3)在映射文件中,配置一对多关系- 在客户映射文件中,表示所有联系人- 在联系人映射文件中,表示所属客户第四步创建核心配置文件,把映射文件引入到核心配置文件中测试:一对多级联操作级联操作1 级联保存(1)添加一个客户,为这个客户添加多个联系人2 级联删除(1)删除某一个客户,这个客户里面的所有的联系人也删除一对多级联保存1 添加客户,为这个客户添加一个联系人(1)复杂写法://演示一对多级联保存@Testpublicvoid testAddDemo1() {SessionFactory sessionFactory = null;Session session = null;Transaction tx = null;try {//得到sessionFactorysessionFactory = HibernateUtils.getSessionFactory();//得到sessionsession = sessionFactory.openSession();//开启事务tx = session.beginTransaction();// 添加一个客户,为这个客户添加一个联系人//1 创建客户和联系人对象Customer customer = new Customer();customer.setCustName("传智播客");customer.setCustLevel("vip");customer.setCustSource("网络");customer.setCustPhone("110");customer.setCustMobile("999");LinkMan linkman = new LinkMan();linkman.setLkm_name("lucy");linkman.setLkm_gender("男");linkman.setLkm_phone("911");//2 在客户表示所有联系人,在联系人表示客户// 建立客户对象和联系人对象关系//2.1 把联系人对象放到客户对象的set集合里面customer.getSetLinkMan().add(linkman);//2.2 把客户对象放到联系人里面linkman.setCustomer(customer);//3 保存到数据库session.save(customer);session.save(linkman);//提交事务mit();}catch(Exception e) {tx.rollback();}finally {session.close();//sessionFactory不需要关闭sessionFactory.close();}}(2)简化写法- 一般根据客户添加联系人第一步在客户映射文件中进行配置- 在客户映射文件里面set标签进行配置第二步创建客户和联系人对象,只需要把联系人放到客户里面就可以了,最终只需要保存客户就可以了//演示一对多级联保存@Testpublicvoid testAddDemo2() {SessionFactory sessionFactory = null;Session session = null;Transaction tx = null;try {//得到sessionFactorysessionFactory = HibernateUtils.getSessionFactory();//得到sessionsession = sessionFactory.openSession();//开启事务tx = session.beginTransaction();// 添加一个客户,为这个客户添加一个联系人//1 创建客户和联系人对象Customer customer = new Customer();customer.setCustName("百度");customer.setCustLevel("普通客户");customer.setCustSource("网络");customer.setCustPhone("110");customer.setCustMobile("999");LinkMan linkman = new LinkMan();linkman.setLkm_name("小宏");linkman.setLkm_gender("男");linkman.setLkm_phone("911");//2 把联系人放到客户里面customer.getSetLinkMan().add(linkman);//3 保存客户session.save(customer);//提交事务mit();}catch(Exception e) {tx.rollback();}finally {session.close();//sessionFactory不需要关闭sessionFactory.close();}}一对多级联删除1 删除某个客户,把客户里面所有的联系人删除2 具体实现第一步在客户映射文件set标签,进行配置(1)使用属性cascade属性值 delete第二步在代码中直接删除客户(1)根据id查询对象,调用session里面delete方法删除3 执行过程:(1)根据id查询客户(2)根据外键id值查询联系人(3)把联系人外键设置为null(4)删除联系人和客户一对多修改操作(inverse属性)1 让lucy联系人所属客户不是传智播客,而是百度2 inverse属性(1)因为hibernate双向维护外键,在客户和联系人里面都需要维护外键,修改客户时候修改一次外键,修改联系人时候也修改一次外键,造成效率问题(2)解决方式:让其中的一方不维护外键- 一对多里面,让其中一方放弃外键维护- 一个国家有总统,国家有很多人,总统不能认识国家所有人,国家所有人可以认识总统(3)具体实现:在放弃关系维护映射文件中,进行配置,在set标签上使用inverse属性。