论述监督分类与非监督分类却别与联系,及各自优缺点
- 格式:doc
- 大小:27.00 KB
- 文档页数:3

机器学习知识:监督学习与非监督学习人工智能(AI)是近年来最热门的话题之一。
而机器学习是AI中重要的一环,它提供了一种让计算机从数据中学习的方法,而无需进行显式的编程。
机器学习有两种主要类型:监督学习和非监督学习。
本文将探讨这两种类型与它们的应用。
监督学习监督学习是指给机器学习算法提供已知的输入和输出数据,让计算机通过这些数据来学习。
监督学习的目的是基于训练数据集建立一个模型,以实现对新数据的预测和分类。
监督学习中最常见的算法有决策树、朴素贝叶斯、支持向量机(SVM)和神经网络等。
决策树是一种树形结构模型,可以对数据进行层层分割,得到最终的分类。
它可以以易于理解的方式将数据集分为不同的成分。
朴素贝叶斯是一种基于贝叶斯定理的概率分类算法,用于分析大量的数据并进行有效的预测。
基于这种算法可以对新的和未知的数据进行分类。
SVM是一种有监督学习算法,用于分类和预测数据。
它是一种非常强大的算法,可以处理大量的数据,例如文本和图像。
SVM被广泛应用于图像、文本、语音和语言等领域。
神经网络是一种模拟人类大脑和神经系统的算法。
它通过在一系列处理单元之间传递信息和模拟神经元之间的连接来实现分类。
神经网络是一个非常强大的算法,可以用于各种应用,包括图像和语音识别、自然语言处理和金融预测。
监督学习的一个重要应用是图像分类。
通过监督学习,可以让机器学习算法自动地从大量的图像中学习到不同类型的图像并将其分类。
例如,训练一个模型可以识别猫或狗的图片,如果输入未知的图片,该算法可以自动判断输入图片是猫还是狗。
这种应用在医学图像、自然景观图像和工业图像等领域都得到了广泛应用。
非监督学习非监督学习是指算法对未标注数据进行学习。
与监督学习不同,非监督学习没有先前设定的输出。
目标是将数据分组到不同的类别中,以发现内在的模式。
非监督学习的最常用算法有聚类和降维。
聚类是一种将数据点分组到不同簇的技术。
这些簇代表了数据集中相似的数据点。
几个常用的聚类算法包括K-means和层次聚类。

有监督学习与⽆监督学习的区别
有监督学习和⽆监督学习两者的区别:
1.有标签就是有监督学习,没有标签就是⽆监督学习,说的详细⼀点,有监督学习的⽬的是在训练集中找规律,然后对测试数据运⽤这种规律,⽽⽆监督学习没有训练集,只有⼀组数据,在该组数据集内寻找规律。
2. ⽆监督学习⽅法在寻找数据集中的规律性,这种规律性并不⼀定要达到划分数据集的⽬的,也就是说不⼀定要“分类”。
⽐如,⼀组颜⾊各异的积⽊,它可以按形状为维度来分类,也可以按颜⾊为维度来分类。
(这⼀点⽐监督学习⽅法的⽤途要⼴。
如分析⼀堆数据的主分量,或分析数据集有什么特点都可以归于⽆监督学习⽅法的范畴) ,⽽有监督学习则是通过已经有的有标签的数据集去训练得到⼀个最优模型,像我们的CNN(卷积神经⽹络)模型都是运⽤了有监督学习去训练出最优的模型,利⽤这个最优的模型就可以对⼀些图像进⾏场景分类。
3.有监督学习要实现的⽬标是“对于输⼊数据X能预测变量Y”(有答案和⽅法的学)。
⽽⽆监督学习要回答的问题是“从数据X 中能发现什么”(⾃学)。
深度学习中的监督学习/⽆监督学习算法:
深度学习是⼀种实现机器学习的技术,也包含了监督学习算法和⽆监督学习算法。
常见的卷积神经⽹络就是⼀种有监督学习⽅法,在图像分类(如⼈脸识别)上应⽤⾮常⼴泛。
⽣成对抗⽹络(GAN)是⼀种⽆监督学习⽅法,经常被⽤来做图像⽣成(如深度卷积对抗⽣成⽹络(DCGAN)可⽤于⽣成卡通图像)。


论述监督分类与非监督分类却别与联系;及各自优缺点监督分类:首先需要从研究区域选取有代表性的训练场地作为样本..根据已知训练区提供的样本;通过选择特征参数如像素亮度均值、方差等;建立判别函数;据此对样本像元进行分类;依据样本类别的特征来识别非样本像元的归属类别..非监督分类:在没有先验类别作为样本的条件下;根据像元间相似度大小进行计算机自动判别归类;无须人为干预;分类后需确定地面类别..区别与联系:根本区别在于是否利用训练场地来获取先验的类别知识..非监督分类不需要更多的先验知识;据地物的光谱统计特性进行分类..当两地物类型对应的光谱特征差异很小时;分类效果不如监督分类效果好..⏹监督分类常常用于对分类区比较了解情况下;要求用户控制.⏹1选择可以识别或可以断定其类型的像元建立模板;然后基于该模板使系统自动识别具有相同特征的像元.⏹2对分类结果进行评价后再对模板进行修改;多次反复后建立比较正确的模板;在此基础上最终进行分类.各自优缺点:监督分类的特点:主要优点:可充分利用分类地区的先验知识;预先确定分类的类别;可控制训练样本的选择;并可通过反复检验训练样本;以提高分类精度避免分类中的严重错误;可避免非监督分类中对光谱集群组的重新归类..主要缺点:人为主观因素较强;训练样本的选取和评估需花费较多的人力、时间;只能识别训练样本中所定义的类别;对于因训练者不知或因数量太少未被定义的类别;监督分类不能识别;从而影响分结果对土地覆盖类型复杂的地区需特别注意..非监督分类特点:主要优点:无需对分类区域有广泛地了解;仅需一定的知识来解释分类出的集群组;人为误差的机会减少;需输入的初始参数较少往往仅需给出所要分出的集群数量、计算迭代次数、分类误差的阈值等;可以形成范围很小但具有独特光谱特征的集群;所分的类别比监督分类的类别更均质;独特的、覆盖量小的类别均能够被识别..主要缺点:对其结果需进行大量分析及后处理;才能得到可靠分类结果;分类出的集群与地类间;或对应、或不对应;加上普遍存在的“同物异谱”及“异物同谱”现象;使集群组与类别的匹配难度大;因各类别光谱特征随时间、地形等变化;则不同图像间的光谱集群组无法保持其连续性;难以对比..。
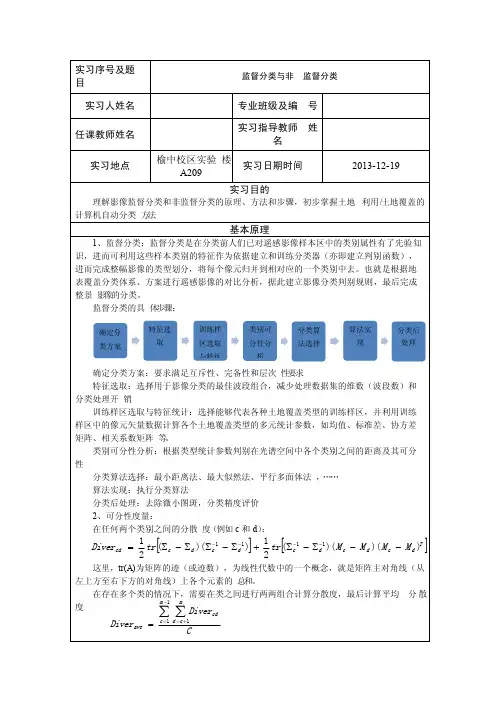
操作方法及过程1. 选取研究区数据(512×512),通过目视解译建立分类系统及其编码体系根据实习要求,在遥感影像上确定并提取出了12种地物,分别是居民点、砾石、道路、河流、水稻田、水浇地、水库、裸地、工业区、滩地、林地。
同时确定土地的覆盖类型、编码以及色调。
居民点Town 砾石gravel desert道路Road 水稻田paddy land水浇地irrigat ed land 水库reservoi r裸地barrenl and 工业区industri al area滩地shoalyland 林地forest草地grassla nd河流stream2. 按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区,给出各个类别的特征统计表。
加载512*512影像,右击Image窗体,选择ROI Tool,进行ROI采集,在Zoom中选择样本区,根据地物的情况选择poin t、polylin e、polygon方式建立训练区。
3. 计算各个样本之间的可分离性。
说明哪些地物类型之间较易区分,哪些类型之间难以区分。
ROI Tool中选O p tions的统计训练区可分性Com pute ROI Separab ility,选择中卫影像,点击确定,选择所有训练区,统计J—M距离和分散度。
4. 监督分类:利用最大似然法完成分类。
①具体步骤:Classifi catio n|Supervi sed| Maximum Likelih ood,在Set Input File对话框中导入影像。
在打开的对话框中选Sele ct All Items,其中Set Probabi lity Threshol d设为NO,Output R ule Image设为N o,选择保存路径。

一、名词解释1. 目标解译:凭着光谱规律、地学规律和解译者的经验,通过直接观察或借助辅助判读仪器从遥感图像上获取特定目标地物的信息,从而推出地面的地物类型.此方法通常应用于高空间分辨率的图像。
2.计算机分类: 利用计算机模式识别技术,结合地学分析、遥感图像处理、地理信息系统与人工智能技术等,实现对遥感图像上的信息进行属性的识别和分类,从而达到识别图像信息所对应的实际地物3.监督分类: 首先需要从研究区域选取有代表性的一定数量的已知类别的样本(训练区),并根据这些样本的观测值(类别的先验知识)确定判别函数和相应的判别准则, 然后将未知类别的样本的观测值代入判别函数,最后再依据判别准则对该未知类别的样本的所属类别做出判定.4.非监督分类:在没有先验类别(训练区)作为样本的条件下,即事先不知道类别特征的情况下,仅依靠影像上不同类地物光谱信息(或纹理信息等)进行特征提取,再采用聚类分析方法,将所有样本划分为若干个类别。
5.同类地物对比分析法:在同一景遥感影像上,由已知地物推出未知目标地物的方法。
二、填空题1.遥感数字图像计算机分类有监督分类和非监督分类两种方法,其区别在是否使用训练场地。
2. 在遥感图像分类过程中,常使用距离和相关系数来衡量遥感图像像素之间的相似度。
三、简答题1、比较监督分类与非监督分类的优缺点?根本区别在于是否利用训练场地来获取先验的类别知识,监督分类是根据样本选择特征参数,所以训练场地要求有代表性,样本数目要满足分类的要求,有时这些不容易做到;非监督分类不需要更多的先验知识,他根据地物的光谱统计特征进行分类,所以非监督分类方法简单,且具有一定的精度。
2、影响遥感图像分类精度的因素有哪些?计算机分类的精度和可靠性与分类方法本身的优劣有关,一般说来,最大似然法的分类精度要优于最小距离法、平等多面体法等,而神经网络法、分类树法、模糊分类法又能在一些特定情况下进一步提高分类精度。
除分类方法之外,分类精度还取决于一些其它的因素:(1)训练场地和训练样本的选择问题;(2)地形因素的影响;(3)混合像元问题;(4)分类变量的选择问题;(5)空间信息在分类中的应用问题;(6)图像分类的后期处理问题。

监督学习,⽆监督学习,半监督学习区别
监督学习:
监督学习是⽬前最主流的学习⽅式,其特点是:训练过程中样本都是有标签的。
常见的监督学习任务有:分类、回归、序列标注等。
学习步骤⼤致可以分为三步(以SVM为例):
1) 在有监督数据上训练,学的⼀个判别器W;
2)然后在测试集(故意把标签P抹去)上,⽤上⼀步学的判别器W进⾏分类任务,得到⼀个预测标签PY
3) PY和P的差距,就是衡量算法好坏的标准。
⽆监督学习:
特点是:训练过程中没有样本标签。
常见的任务:聚类、降维等
常⽤算法:k-means、谱聚类等
步骤:
1)直接在全部数据上训练,得到预测标签PY
2) 之后将PY和真实标签Y进⾏对⽐,⽤的是经典的匈⽛利算法。
注意:这⾥的PY和Y并不是⼀⼀对应关系,⽽是看“类内样本”对应关系,这也是聚类指标和分类指标不同之处。
举个例⼦:样本A和样本B真实标签是“1”
经过聚类算法处理后,得到了预测标签。
若A、B标签相同,则代表这两个样本分对了(标签可能是“1”,也可能是“2”、“3”、“4”、、、) 若聚类后,A和B的标签不同,则代表这两个样本分错了(分成不同类了)。
半监督学习:
特点是:训练过程中,⽤的是全部的样本数据(和监督的区别,监督是认为的把数据划分为有标签和⽆标签),但是这些样本中只有⼀⼩部分有标签,⼤部分是没有标签的。
其原理是通过标签传播的⽅式,利⽤已有标签的样本信息去预测未知标签样本的类别信息。
典型⽅法:S3VM、S4VM、CS4VM、TSVM;。

第34 卷第3 期2004 年9 月河南大学学报(自然科学版)Journal of Henan U n iversity ( N at u ral Science)Vol . 34 No . 3Sep . 2004 遥感影像监督分类与非监督分类的比较赵春霞,钱乐祥3(河南大学环境与规划学院,河南开封475001)摘要: 遥感影像的分类方法按照是否有先验类别可以分为监督分类和非监督分类,这两种分类法有着本质的区别但也存在一定的联系. 从分类原理、分类过程、分类方法等不同角度分析了这两种方法的区别与联系,并展望了遥感影像分类的发展趋势与发展前景.关键词: 影像分类;监督分类;非监督分类中图分类号: P237 文献标识码: A 文章编号: 1003 - 4978 (2004) 03 - 0090 - 04Comparative Study of Supervised and U nsupervised C la s sif icationin R emote Sensing Im ageZHAO Chun2xia , Q IAN L e2xiang( Col l ege of En v i ron ment an d Pl a n n i ng , Hen a n U ni v ersi t y , Hen a n Kai f eng 475001 , Chi n a) Abstract : The classificatio n of Remote Sensing image can be divided into t he su pervised classificatio n and t he unsu pervisedto whet her t here is t he extant category. The t wo met hods have difference in essence , but t he y are co nnected wit h each ot her . The article has analyzed t he difference and relatio n of t he t wo met hods f ro m different as pect s such as t he p rinciple , t he course and ways of classificatio n , and forecasted t he tendency and p rospect of t he image classificatio n.K ey w ords : image classificatio n ; supervised classificatio n ; unsu pervised classificatio n遥感影像分类是影像分析的一个重要内容,它是利用计算机通过对影像中不同地物的空间信息和光信息进行分析,选择特征,并将特征空间划分为互不重叠的子空间,然后将影像中各个像元划归到子空间去目前国内国际上对影像分类的研究主要集中在应用具体的物理的、数学的方法等对影像进行的分类研究面1 - 8,对于影像分类方法的研究,从不同的方面可以划分为不同的类型. 按照利用图像要素的不同,影分类大体可以分为三种:一是基于图像灰度值的分类,二是基于图像纹理的分类,三是基于多源信息融合分类9 . 用计算机对影像进行分类应用的主要是模式识别技术,根据具体应用的数学方法不同又可分为:计法(决策分类法) 、语言结构法(句法方法) 、模糊法以及神经网络法. 在影像分类过程中,根据是否已知训样本的分类数据,影像分类方法又可以分为监督分类和非监督分类. 本文主要从分类原理、分类过程、分类法等方面来探讨这两种分类方法的区别与联系.1 监督分类的主要方法最大似然判别法. 也称为贝叶斯(Bayes) 分类,是基于图像统计的监督分类法,也是典型的和应用最广监督分类方法.它建立在Bayes 准则的基础上,偏重于集群分布的统计特性,分类原理是假定训练样本数在光谱空间的分布是服从高斯正态分布规律的,做出样本的概率密度等值线,确定分类,然后通过计算标收稿日期: 2004202209基金项目: 河南省高等学校创新人才培养对象基金项目;河南省杰出青年科学基金项目( 99200003) ; 河南省自然科学基项目(004070700)作者简介: 赵春霞(1980 - ) ,女,河南大学硕士研究生13 通信联系人1(像元) 属于各组(类) 的概率,将标本归属于概率最大的一组. 用最大似然法分类,具体分为三步:首先确定各类的训练样本,再根据训练样本计算各类的统计特征值,建立分类判别函数,最后逐点扫描影像各像元,将像元特征向量代入判别函数,求出其属于各类的概率,将待判断像元归属于最大判别函数值的一组. Bayes 判别分类是建立在Bayes 决策规则基础上的模式识别,它的分类错误最小精度最高,是一种最好的分类方法. 但是传统的人工采样方法由于工作量大,效率低,加上人为误差的干扰,使得分类结果的精度较差. 利用GIS 数据来辅助Bayes 分类,可以提高分类精度,再通过建立知识库,以知识来指导分类的进行,可以减少分类错误的发生1 ,这正是Bayes 分类的发展趋势和提高其分类精度的有效途径.神经元网络分类法. 是最近发展起来的一种具有人工智能的分类方法,包括B P 神经网络、K o ho nen 神经网络、径向基神经网络、模糊神经网络、小波神经网络等各种神经网络分类法. B P神经网络模型(前馈网络模型) 是神经网络的重要模型之一,也是目前应用最广的神经网络模型,它由输入层、隐含层、输出层三部分组成,所采取的学习过程由正向传播过程和反向传播过程组成. 传统的B P网络模型把一组样本的输入/ 输出问题作为一个非线性优化问题,它虽然比一般统计方法要好,但是却存在学习速度慢,不易收敛,效率不高等缺点. 采用动量法和学习率自适应调整的策略,可以提高学习效率并增加算法的可靠性3 .模糊分类法. 由于现实世界中众多的自然或半自然现象很难明确划分种类,反映在遥感影像上,也存在一些混合像素问题,并有大量的同谱异物或者同物异谱现象发生,使得像元的类别难以明确确定. 模糊分类方法忽略了监督分类的训练过程所存在的模糊性,沿用传统的方法,假定训练样本由一组可明确定义、归类, 并且具有代表性的目标(像素) 构成. 监督分类中的模糊分类可以利用神经元网络所具有的良好学习归纳机制、抗差能力和易于扩展成为动态系统等特点,设计一个基于神经元网络技术的模糊分类法来实现. 模糊神经网络模型由A R T 发展到A R TMA P 再到FasA R T 、简化的FasA R T 模型4 ,使得模糊神经网络的监督分类功能不断完善、分类精确度不断增加.最小距离分类法和Fisher 判别分类法. 它们都是基于图像统计的常用的监督分类法,偏重于几何位置.最小距离分类法的原则是各像元点划归到距离它最近距离的类别中心所在的类, Fisher 判别分类采用Fisher 准则即“组间最大距离”的原则,要求组间距离最大而组内的离散性最小,也就是组间均值差异最大而组内离差平方和最小. 用这两种分类法进行分类,其分类精度取决于对已知地物类别的了解和训练统计的精度,也与训练样本数量有关. 针对最小距离分类法受模式散布影响、分类精度不高的缺点,人们提出了一种自适应的最小距离分类法,在训练过程中,将各类样本集合自适应地分解为子集树,定义待分类点到子集树的距离作为分类依据2 ,这种方法有效地提高了最小距离法的分类正确率和分类速度,效率较高. Fisher 判别分类也可以通过增加样本数量进行严密的统计分类来增加分类精度.2 非监督分类的主要方法动态聚类. 它是按某些原则选择一些代表点作为聚类的核心,然后将其余待分点按某种方法(判据准则)分到各类中去,完成初始分类,之后再重新计算各聚类中心,把各点按初始分类判据重新分到各类,完成第一次迭代. 然后修改聚类中心进行下一次迭代,对上次分类结果进行修改,如此反复直到满意为止. 动态聚类的方法是目前非监督分类中比较先进、也较为常用的方法.典型的聚类过程包括以下几步:选定初始集群中心; 用一判据准则进行分类;循环式的检查和修改;输出分类结果.聚类的方法主要有基于最邻近规则的试探法、K - means 均值算法、迭代自组织的数据分析法( ISODA TA) 等.其中比较成熟的是K - means 和ISODA TA 算法,它们较之其他分类方法的优点是把分析判别的统计聚类算法和简单多光谱分类融合在一起,使聚类更准确、客观. 但这些传统的建立在统计方法之上的分类法存在着一定的缺点:很难确定初始化条件;很难确定全局最优分类中心和类别个数;很难融合地学专家知识. 基于尺度空间的分层聚类方法( SSHC) 是一种以热力学非线性动力机制为理论基础的新型聚类算法10 ,它与传统聚类算法相比最大的优点是其样本空间可服从自由分布,可获取最优聚类中心点及类别,可在聚类过程中融合后验知识,有更多的灵活性和实用性.模糊聚类法. 模糊分类根据是否需要先验知识也可以分为监督分类和非监督分类. 事实上,由于遥感影92 河南大学学报(自然科学版) ,2004 年,第34 卷第3 期关系的模糊聚类分析法、基于最大模糊支撑树的模糊聚类分析法等11 ,最典型的模糊聚类法是模糊迭代组织的数据分析法———Fussy - ISODA TA . 但纯粹的非监督分类对影像一无所知的情况下进行所得到的果往往与实际特征存在一定的差异,因此聚类结果的精度并不一定能够满足实际应用的要求,还需要地学识的辅助,也就是部分监督的Fussy - ISODA TA 聚类.系统聚类. 这种方法是将影像中每个像元各自看作一类,计算各类间均值的相关系数矩阵,从中选择相关的两类进行合并形成新类,并重新计算各新类间的相关系数矩阵,再将最相关的两类合并,这样继续去,按照逐步结合的方法进行类与类之间的合并. 直到各个新类间的相关系数小于某个给定的阈值为止.分裂法. 又称等混合距离分类法,它与系统聚类的方法相反,在开始时将所有像元看成一类,求出各变的均值和均方差,按照一定公式计算分裂后两类的中心,再算出各像元到这两类中心的聚类,将像元归并距离最近的那一类去,形成两个新类. 然后再对各个新类进行分类,只要有一个波段的均方差大于规定的值,新类就要分裂.两种分类方法原理及过程的比较遥感影像的监督分类是在已知类别的训练场地上提取各类别训练样本,通过选择特征变量、确定判别数或判别式把影像中的各个像元点划归到各个给定类的分类. 它的基本思想是:首先根据类别的先验知识定判别函数和相应的判别准则,利用一定数量的已知类别样本的观测值确定判别函数中的待定参数,然后未知类别的样本的观测值代入判别函数,再根据判别准则对该样本的所属类别做出判定. 遥感影像的非监分类也称为聚类,它是事先无法知道类别的先验知识,在没有类别先验知识的情况下将所有样本划分为若类别的方法. 它的基本思想是事先不知道类别的先验知识,仅根据地物的光谱特征的相关性或相似性来进分类,再根据实地调查数据比较后确定其类别属性. 二者分类流程如图1 所示.3图1 影像监督分类与非监督分类流程图影像监督分类法与非监督分类法是针对影像具体分类时是否有先验知识而产生的两种方法,二者的用范围、使用条件不同,因而在具体分类时各有一定的优缺点,监督分类与非监督分类的比较如表1 所示.表1 影像不同分类方法的适用范围及优缺点优点缺点适用范围精确度高,准确性好,与实际类别吻合较好监督分类工作量大有先验知识时使用该方法分类结果与实际类别相差较大,准确性差在没有类别先验知识时使用该方法非监督分类工作量小,易于实现影像分类方法的发展前景遥感影像的监督分类和非监督分类方法,是影像分类的最基本、最概括的两种方法. 传统的监督分类非监督分类方法虽然各有优势,但是也都存在一定的不足. 新方法、新理论、新技术的引入,为遥感影像分提供了广阔的前景,监督分类与非监督分类的混合使用更是大大的提高了分类的精度.计算机技术对影像分类的促进与发展. 计算机技术的引进,解决了影像分类中海量数据的计算与管理题;计算机技术支持下的GIS 用来辅助影像分类,主要通过四种模式进行12 : GIS 数据作为影像分析的训样本和先验信息;利用GIS 技术对研究区域场景和影像分层分析; GIS 建立面向对象的影像分类; 提取和掘GIS 中的知识进行专家分析. 这些模式促进了GIS 与遥感的结合,提高了影像分类精确性和准确性,使影像分类迈入了新的天地.数学方法的引入和模型研究的进展为影像分类注入了新的活力. 不同的数学方法被引用到模型研究来,为模型研究的发展提供了广阔的天地,相应地,在遥感影像分类中也产生了大量不同形式的分类模型. 径向基函数( RB F) 与粗糙理论结合的基于粗糙理论的RB F网络模型应用于遥感分类5 ,对于提供分类4度 、增加收敛性都有很好的作用 ;而基于 RB F 映射理论的神经网络模型更是融合了参数化统计分布模型和 非参数化线性感知器映射模型的优点 ,不仅学习速度快 ,而且有高度复杂的映射能力6 . 又如模糊数学理论 应用于影像分类产生模糊聚类 ,对影像中混合像元的分类有很好的效果 ;模糊理论与各种模型结合 ,更使得 影像分类方法的不断完善 ,分类精度不断提高. 人工智能技术对影像分类的促进. 专家分类系统被用于影像分类中 ,利用地学知识和专家系统来辅助遥 感影像分类12 ,大大提高了影像分类和信息提取的精度. 人工神经网络由大量神经元相互连接构成网络结 构 ,通过模拟人脑神经系统的结构和功能应用于影像分类 ,具有一定的智能推理能力 . 同时 ,它还引入了动量 法和学习自适率调整的策略 ,并与地学知识集成 ,很好的解决了专一的 B P 神经网络法分类的缺点和不足 , 提高了分类效率和分类精度.监督分类与非监督分类的结合. 由于遥感数据的数据量大 、类别多以及同物异谱和同谱异物现象的存 在 ,用单一的分类方法对影像进行分类其精确度往往不能满足应用目的要求 . 用监督分类与非监督分类相结 合的方法来对影像进行分类 ,却常常可以到达需要的目的. 利用这种方法分类时首先用监督分类法如多层神 经网络的 B P 算法将遥感图像概略地划分为几个大类 ,再用非监督分类法如 K - Means 聚类和 ISODA TA 聚 类对第一步已分出的各个大类进行细分 ,直到满足要求为止13 . 监督分类与非监督分类的结合的复合分类 方法 ,改变了传统的单一的分类方法对影像进行分类的弊端 ,弥补了其不足 ,为影像分类开辟了广阔的前景. 结论遥感影像的监督分类与非监督分类从内涵 、过程以及具体的分类方法上都不相同 ,它们在分类思路上有 着本质的差别 . 但是 ,作为影像分类的方法 ,它们都有着相同的目的和功效. 因此 ,在影像分类中 ,这两种方法 并不能够完全割裂开来 ,而应该根据实际分类的需要 ,合理科学灵活的运用这两种方法 ,甚至混合使用监督 5 分类与非监督分类 ,以使影像分类达到预期的目的要求. 监督分类与非监督分类方法灵活的使用 ,新的理论 、新的模型 、新技术的运用 ,使得遥感影像分类技术得到长足发展 ,影像分类结果的准确度 、精确度都不断提 高 ,从而更好的为应用服务.参考文献 :游代安 ,蒋定华 ,余旭初 . GIS 辅助下的 Bayes 法遥感影像分类 J . 测绘学院学报 ,2001 ,18 (2) :113 - 117 . 朱建华 ,刘政凯 ,俞能海 . 一种多光谱遥感图象的自适应最小距离分类方法 J . 中国图象图形学报 ,2000 ,5 (1) :22 - 24 . 贾永红 ,张春森 ,王爱平 . 基于 B P 神经网络的多源遥感影像分类 J . 西安科技学院学报 ,2001 ,21 (1) :58 - 60 . 林剑 ,鲍光淑 ,敬荣中 ,等 . FasAR T 模糊神经网络用于遥感图象监督分类的研究 J . 中国图象图形学报 , 2002 , 7 ( 12) : 1263 - 1268 . 巫兆聪 . 基于粗糙理论的 RB F 网络及其遥感影像分类应用 J . 测绘学报 ,2003 ,32 (1) :53 - 57 . 骆剑承 ,周成虎 ,杨艳. 基于径向基函 ( RB F ) 映射理论的遥感影像分类模型研究 J . 中国图象图形学报 ,2000 ,5 ( 2) : 94 - 99 .123456 7 Olivier Debeir , Pat r ice L a tinne , Isabelle Vanden Steen. Remote Sensin g Classificatio n Of S pect r al , spatial And Co n text u al DataU s ing Multiple Classifier System J . Ima ge Anal Stereol , 2001 ,20 ( S uppl 1) : 584 - 589 .8 L a kshmanan V , DeBrunner V , Rabin R. An U n su pervised , Agglo m erative , S patially Aware Text u re Segmentatio n TechniqueE . ht t p :/ / www . cimms. ou. edu/ ~lakshman/ Papers/ diss - t r ansip . p d f曾生根 ,王小敏 ,范瑞彬 ,等 . 基于独立量分析的遥感图像分类技术 J . 遥感学报 ,2004 ,8 (2) :150 - 157 .骆剑承 ,梁怡 ,周成虎. 基于尺度空间的分层聚类方法及其在遥感影像分类中的应用 J . 测绘学报 , 1999 , 28 ( 4) : 319 - 324 .徐建华 . 现代地理学中的数学方法 M . 北京 :高等教育出版社 ,2002 . 王莹 ,刘敏莺 ,黄文骞 . GIS 对遥感影像分类判读的辅助作用 J . 海洋测绘 ,2002 ,22 (3) :12 - 15 . 杨存建 ,周成虎 . 基于知识的遥感图像分类方法的探讨 J . 地理学与国土研究 ,2001 ,17 (1) :72 - 77 . 靳文戟 ,刘政凯 . 多类别遥感图像的复合分类方法 J . 环境遥感 ,1995 ,10 (4) :298 - 302 . 9 10 11121213。

举例理解监督学习、⽆监督学习、半监督学习和强化学习的区别Machine learning机器学习是Artificial inteligence的核⼼,分为四类:1、Supervised learning监督学习是有特征(feature)和标签(label)的,即便是没有标签的,机器也是可以通过特征和标签之间的关系,判断出标签。
举例⼦理解:⾼考试题是在考试前就有标准答案的,在学习和做题的过程中,可以对照答案,分析问题找出⽅法。
在⾼考题没有给出答案的时候,也是可以给出正确的解决。
这就是监督学习。
⼀句话概括:给定数据,预测标签。
通过已有的⼀部分输⼊数据与输出数据之间的对应关系,⽣成⼀个函数,将输⼊映射到合适的输出,例如分类。
2、Unsupervised learning⽆监督学习只有特征,没有标签。
举例⼦理解:⾼考前的⼀些模拟试卷,是没有标准答案的,也就是没有参照是对还是错,但是我们还是可以根据这些问题之间的联系将语⽂、数学、英语分开,这个过程就叫做聚类。
在只有特征,没有标签的训练数据集中,通过数据之间的内在联系和相似性将他们分成若⼲类。
⼀句话概括:给定数据,寻找隐藏的结构。
直接对数据集建模。
以上两者的区别:监督学习只利⽤标记的样本集进⾏学习,⽽⽆监督学习只利⽤未标记的样本集。
3、Semi-Supervised learning半监督学习使⽤的数据,⼀部分是标记过的,⽽⼤部分是没有标记的。
和监督学习相⽐较,半监督学习的成本较低,但是⼜能达到较⾼的准确度。
综合利⽤有类标的和没有类标的数据,来⽣成合适的分类函数。
半监督学习出现的背景:实际问题中,通常只有少量的有标记的数据,因为对数据进⾏标记的代价有时很⾼,⽐如在⽣物学中,对某种蛋⽩质的结构分析或者功能鉴定,可能会花上⽣物学家很多年的⼯作,⽽⼤量的未标记的数据却很容易得到。
4、Reinforcement learning强化学习强化学习也是使⽤未标记的数据,但是可以通过⼀些⽅法知道你是离正确答案越来越近还是越来越远(奖惩函数)。

福师1203考试批次《遥感导论》复习题及参考答案一本课程复习题所提供的答案仅供学员在复习过程中参考之用,有问题请到课程论坛提问。
一、填空题(每空1分,共10分)1.大气对电磁波的反射作用主要发生在顶部,因此应尽量选天气接收遥感信号。
参考答案:云层;无云2.散射现象的实质是电磁波在传输总遇到大气微粒而产生的一种衍射现象。
这种现象只有当大气中的分子或其他威力的直径小于或相当于辐射波长时才会发生。
大气散射的三种情况是、、。
参考答案:瑞利散射;米氏散射;无选择性散射3.遥感图像计算机分类是技术在遥感领域中的具体应用。
该技术的关键是提取待识别模式的一组,所依赖的是地物的。
参考答案:统计模式识别;统计特征值;光谱特征4.航空像片的像点位移量与地形高差成比,与航高成比。
参考答案:正;反二、选择题(每题备选答案中只有一个正确选项,选对得3分,共15分)1.有关航空像片比例尺的描述,正确的是()。
A、是像片上两点间距离与地面上相应两点间实际距离之比;B、像片上的实际比例尺可以用焦距除以航高来计算;C、地形起伏会产生像点位移,但不影响图像上两点间比例尺计算;D、倾斜摄影不会引起像片比例尺变化。
参考答案:A2.对于Landsat-7 上ETM+数据的描述,正确的是()。
A、TM2是蓝色波段,对水体有一定透射能力;B、TM6是热红外波段,空间分辨率120米;C、TM3是红色波段,可用来测量绿色素吸收率并进行植物分类;D、TM5是短波红外,可探测浅水水下特征。
参考答案:C3.在可见光波段有一个小的反射峰(0.55微米附近),两侧(0.45和0.67微米附近)有两个吸收带,近红外波段(0.7—0.8微米)有一反射“陡坡”,至1.1微米附近有一峰值。
具有这种反射波谱特征的是()。
A、植被;B、土壤;C、水体;D、岩石参考答案:A4.太阳辐射和地球辐射的峰值波长为:()A、0.48μm和9.66μmB、9.66μm和0.48μmC、2.5μm和5μmD、0.5μm和0.8μm参考答案:A5.BIL是遥感数字图像的()A、按波段顺序依次排列的数据格式B、逐行按波段次序排列的数据格式C、每个像元按波段次序交叉排列的数据格式D、以上都不是参考答案:B三、名词解释(每词3分,共15分)1.大气窗口参考答案:电磁波通过大气层时较少被反射、吸收或散射,透过率较高的波长范围。
人工智能技术的监督学习与无监督学习区别解析人工智能技术的发展日新月异,其中的监督学习和无监督学习是两种常见的学习方式。
监督学习和无监督学习在数据处理和模型构建上存在显著的差异,本文将对这两种学习方式进行区别解析。
监督学习是一种通过已知输入和输出数据的样本对模型进行训练的学习方式。
在监督学习中,我们将输入数据和对应的输出数据作为训练样本,通过训练模型来建立输入和输出之间的映射关系。
监督学习的目标是通过学习到的模型,对未知输入数据进行预测或分类。
常见的监督学习算法包括线性回归、决策树、支持向量机等。
与监督学习相比,无监督学习则不需要标记的输出数据。
无监督学习是一种从未标记的数据中学习模型的方式。
在无监督学习中,我们只有输入数据,目标是通过学习到的模型,发现数据中的潜在结构和模式。
无监督学习的应用领域广泛,包括聚类分析、降维、异常检测等。
常见的无监督学习算法有K均值聚类、主成分分析等。
监督学习和无监督学习在数据处理上存在明显的差异。
在监督学习中,我们需要有标记的数据作为训练样本,这要求我们事先对数据进行标记或者依赖专家知识进行标记。
而无监督学习则不需要标记的数据,可以直接使用未标记的数据进行模型训练。
这使得无监督学习在大规模数据处理上更具优势,因为标记数据的获取通常是耗时且昂贵的。
另外,监督学习和无监督学习在模型构建上也有不同。
监督学习通常采用有监督的模型,通过已知输入和输出数据的样本进行训练,从而建立输入和输出之间的关系。
而无监督学习则更加注重数据的内在结构和模式,常常采用无监督的模型进行训练,通过发现数据中的相似性或者潜在结构来进行模型构建。
此外,监督学习和无监督学习在应用场景上也有所不同。
监督学习通常适用于需要预测或分类的问题,如图像识别、自然语言处理等。
无监督学习则适用于探索数据中的模式和结构,如市场分析、社交网络分析等。
综上所述,监督学习和无监督学习是人工智能技术中常见的学习方式。
监督学习通过已知输入和输出数据的样本对模型进行训练,用于预测和分类问题;而无监督学习则从未标记的数据中学习模型,用于发现数据中的潜在结构和模式。
各自优缺点:监督分类的特点:主要优点:可充分利用分类地区的先验知识,预先确定分类的类别;可控制训练样本的选择,并可通过反复检验训练样本,以提高分类精度(避免分类中的严重错误);可避免非监督分类中对光谱集群组的重新归类。
主要缺点:人为主观因素较强;训练样本的选取和评估需花费较多的人力、时间;只能识别训练样本中所定义的类别,对于因训练者不知或因数量太少未被定义的类别,监督分类不能识别,从而影响分结果(对土地覆盖类型复杂的地区需特别注意)。
非监督分类特点:主要优点:无需对分类区域有广泛地了解,仅需一定的知识来解释分类出的集群组;人为误差的机会减少,需输入的初始参数较少(往往仅需给出所要分出的集群数量、计算迭代次数、分类误差的阈值等);可以形成范围很小但具有独特光谱特征的集群,所分的类别比监督分类的类别更均质;独特的、覆盖量小的类别均能够被识别。
主要缺点:对其结果需进行大量分析及后处理,才能得到可靠分类结果;分类出的集群与地类间,或对应、或不对应,加上普遍存在的“同物异谱”及“异物同谱”现象,使集群组与类别的匹配难度大;因各类别光谱特征随时间、地形等变化,则不同图像间的光谱集群组无法保持其连续性,难以对比。
一、什么是监督分类与非监督分类?非监督分类:没有训练样本,通过计算哪些相似,划分出不同类别。
先定义光谱可分性,再定义信息类。
是指人们事先对分类过程不施加任何的先验知识,而仅凭数据(遥感影像地物的光谱特征的分布规律),即自然聚类的特性,进行“盲目”的分类;其分类的结果只是对不同类别达到了区分,但并不能确定类别的属性。
监督分类:根据已知训练区提供的样本,通过计算选择特征参数,建立判别函数以对各待分类影像进行的图像分类。
先定义信息类,再定义光谱可分性。
二、它们包括什么?非监督分类包括:1.波谱图形识别分类2.聚类分析监督分类包括:1.最小距离法2.线形判别分析3.最大似然比分类4.最近邻域分类法5.特征曲线窗口法三、二者的优缺点:非监督分类优点:1.人为干预较少,自动化程度较高。
监督分类和非监督分类的异同监督分类是纪检监察机关的一项重要职责,是对监督对象开展监督的依据。
实践中经常会遇到两类监督分类的概念表述问题,如何准确把握这两类监督分类界定?如果两者不能区分清楚,容易出现问题。
本文将从二者的关系入手进行阐述。
•一、界定对监督分类,《中华人民共和国监察法》第四十三条第一款明确规定,监督是指国家行政机关、检察机关及其工作人员在行使权力、履行职责过程中,对公职人员行使职权情况进行监督,发现公职人员违纪违法问题线索,及时向有关部门移送或者采取其他必要措施以加强对公职人员监督。
监察机关应当在监察调查终结后五个工作日内将审查调查结论、处分决定等文书送达被调查人,并抄送被调查人所在单位党组织。
对监察对象实施监督的同时,监察机关应当会同有关部门建立健全协调机制,加强信息共享,实现监督资源共享与共用。
根据监督分类规则,《中国共产党纪律检查机关监督执纪工作规则》第二十一条规定“监督对象可以通过谈话、函询、要求说明材料等方式被监督对象如实向纪检监察机关反映问题,或者被监督对象因特殊情况不能如实说明问题而进行询问、质询、检查、问责等方式进行询问、质询或者进行检查;对涉及党和国家工作人员利益的其他方式进行监督的”以及《中华人民共和国监察法》第三十一条规定“监察机关应当依照法定权限和程序对监察对象进行工作评议后认为存在不应当被监督问题的”等情形下组织开展监督或者开展其他监督时可以采取相应措施实现监督目的或目标,属于监督分类规定的情形之一。
”由此可见,监督分类并非仅限于对纪检监察机关工作人员进行监督或者进行其他形式监督那么简单。
•二、特征这两类监督分类的特征表现在:一是“监督”是纪委监委履行监督责任中,运用监督执纪“四种形态”的重要内容,体现了对腐败行为的有效遏制,体现了“四种形态”协同作用;二是“监督”是纪检监察机关履行监督职责的主要方式之一,是纪检监察机关工作规范化、科学化的重要内容。
“监督”的主要区别在于:“监督”重在“发现问题”,是纪检监察机关开展监督的基本方式之一;“监督”重在“督促整改”,是纪检监察机关开展监督的主要方式之一。
监督学习与⾮监督学习
1、监督学习
是有特征和标签的,即便是没有标签的,机器也是可以通过特征和标签之间的关系,判断出标签。
监督学习是通过训练让机器⾃⼰找到特征和标签之间的联系,在以后⾯对只有特征⽽没有标签的数据时可以⾃⼰判别出标签。
相当于给定数据,预测标签。
常见的有监督学习算法:回归分析和统计分类。
2、⾮监督学习
由于训练数据中只有特征没有标签,所以就需要⾃⼰对数据进⾏聚类分析,然后就可以通过聚类的⽅式从数据中提取⼀个特殊的结构。
输⼊的数据没有标记,也没有确定的结果,只有特征,没有标签。
⽆监督学习的⽅法分为两⼤类:
(1) ⼀类为基于概率密度函数估计的直接⽅法:指设法找到各类别在特征空间的分布参数,再进⾏分类。
(2) 另⼀类是称为基于样本间相似性度量的简洁聚类⽅法:其原理是设法定出不同类别的核⼼或初始内核,然后依据样本与核⼼之间的相似性度量将样本聚集成不同的类别。
3、区别
两者的根本区别是训练数据中是否有标签,监督学习的数据既有特征⼜有标签,⽽⾮监督学习的数据中只有特征⽽没有标签。
有监督学习和⽆监督学习的区别有监督学习和⽆监督学习的区别如今机器学习和⼈⼯智能是⼤家⽿熟能详的两个词汇,在我们⽇常⽣活中也是被⾼频的提到。
其实机器学习只是⼈⼯智能的⼀部分,是⼈⼯智能的⼀个⼦集,它往往是通过⽰例和经验模型让计算机去执⾏⼀些操作任务,研究⼈员和开发⼈员⽐较⽐较热衷于它。
在⽣活中,我们应⽤的很多东西其实都使⽤的是机器学习算法,例如我们使⽤的好多APP,包括AI助⼿、web搜索、⼿机翻译等,现在你⼿机社交媒体新闻的推荐由机器学习算法提供⽀持,你在视屏⽹站上推荐的视频、影视剧也是机器学习模型的结果,你现在听歌软件的每⽇歌曲推荐也是利⽤机器学习算法的强⼤功能来创建推荐你喜欢的歌曲列表等等,但是机器学习有许??多不同的风格的应⽤。
在这篇⽂章中,我们将探讨有监督和⽆监督学习,这是机器学习算法的两个主要类别。
⼀、监督学习如果你有关注有关于⼈⼯智能的新闻,你可能已经听说过AI算法需要很多⼈⼯标记的⽰例。
这些故事指的是监督学习,这是机器学习算法中⽐较流⾏的类别。
监督式机器学习适⽤于你知道输⼊数据结果的情况。
假设你要创建⼀个图像分类机器学习算法,该算法可以检测猫,狗和马的图像。
要训练AI模型,你必须收集猫,狗和马照⽚的⼤型数据集。
但是在将它们输⼊机器学习算法之前,你必须使⽤它们各⾃类的名称对其进⾏注释。
注释可能包括使⽤⽂件命名约定将每个类的图像放在单独的⽂件夹中,或将元数据附加到图像⽂件中,这是⼀项费⼒的⼿动任务。
标记数据后,机器学习算法(例如卷积神经⽹络或⽀持向量机)将处理⽰例,并开发可将每个图像映射到其正确类别的数学模型。
如果对AI模型进⾏⾜够的带有标签的⽰例训练,它将能够准确地检测出包含猫,狗,马的新图像类别。
监督机器学习解决了两种类型的问题:分类和回归。
上⾯说明的⽰例是⼀个分类问题,其中机器学习模型必须将输⼊放⼊特定的存储桶或类别中。
分类问题的另⼀个⽰例是语⾳识别。
回归机器学习模型不限于特定类别。
论述监督分类与非监督分类却别与联系及各自优缺点监督分类和非监督分类是机器学习中常用的两种分类方法。
它们之间的区别与联系主要体现在训练数据的标记情况、算法的目标和应用场景上。
以下是它们的具体区别与联系以及各自的优缺点。
1. 数据标记情况:- 监督分类:监督分类算法使用已标记的训练数据,其中每个样本都有所属的类别标签。
算法通过学习输入特征和对应的类别标签之间的关系,来构建分类模型。
- 非监督分类:非监督分类算法使用未标记的训练数据,其中没有给定每个样本的类别标签。
算法通过学习数据本身的内在结构和模式,来对数据进行聚类或分组。
2. 算法目标:- 监督分类:监督分类算法的目标是根据已有的训练数据,建立一个能够对未知数据进行准确分类的模型。
具体目标可以是最大化分类准确率、最小化分类错误率等。
- 非监督分类:非监督分类算法的目标是为了揭示数据中的内在结构和模式,将相似的数据点聚类或分组在一起。
具体目标可以是最大化组内相似度、最小化组间差异度等。
3. 应用场景:- 监督分类:监督分类算法常用于需要根据给定标签对新数据进行分类预测的场景,如垃圾邮件分类、图像识别等。
- 非监督分类:非监督分类算法常用于探索性数据分析、发现数据中的隐藏模式、特征提取等场景,如市场分割、社交网络分析等。
4. 优缺点:- 监督分类的优点是能够利用标签信息进行有监督的学习,可以达到较高的分类准确率。
缺点是需要标记大量的训练数据,且在面对未知类别或类别不平衡的情况下表现不稳定。
- 非监督分类的优点是无需标记训练数据,可以自动发现数据中的结构和模式。
缺点是算法的评价相对主观,结果的解释性较低,且对数据质量较为敏感。
监督分类和非监督分类在数据标记情况、算法目标和应用场景上存在明显的差异。
它们各自有着适用的优势和限制,需要根据具体需求和数据特点选择合适的方法。
论述监督分类与非监督分类却别与联系,及各自
优缺点
监督分类:首先需要从研究区域选取有代表性的训练场地作为样本。
根据已知训练区提供的样本,通过选择特征参数(如像素亮度均值、方差等),建立判别函数,据此对样本像元进行分类,依据样本类别的特征来识别非样本像元的归属类别。
非监督分类:在没有先验类别作为样本的条件下,根据像元间相似度大小进行计算机自动判别归类,无须人为干预,分类后需确定地面类别。
区别与联系:
根本区别在于是否利用训练场地来获取先验的类别知识。
非监督分类不需要更多的先验知识,据地物的光谱统计特性进行分类。
当两地物类型对应的光谱特征差异很小时,分类效果不如监督分类效果好。
⏹监督分类常常用于对分类区比较了解情况下,要求用户控制.
⏹1)选择可以识别或可以断定其类型的像元建立模板,然后基于该模板使系统自动识别具有相同特征的像元.
⏹2)对分类结果进行评价后再对模板进行修改,多次反复后建立比较正确的模板,在此基础上最终进行分类.
各自优缺点:
监督分类的特点:
主要优点:可充分利用分类地区的先验知识,预先确定分类的类别;可控制训练样本的选择,并可通过反复检验训练样本,以提高分类精度(避免分类中的严重错误);可避免非监督分类中对光谱集群组的重新归类。
主要缺点:人为主观因素较强;训练样本的选取和评估需花费较多的人力、时间;只能识别训练样本中所定义的类别,对于因训练者不知或因数量太少未被定义的类别,监督分类不能识别,从而影响分结果(对土地覆盖类型复杂的地区需特别注意)。
非监督分类特点:
主要优点:无需对分类区域有广泛地了解,仅需一定的知识来解释分类出的集群组;人为误差的机会减少,需输入的初始参数较少(往往仅需给出所要分出的集群数量、计算迭代次数、分类误差的阈值等);可以形成范围很小但具有独特光谱特征的集群,所分的类别比监督分类的类别更均质;独特的、覆盖量小的类别均能够被识别。
主要缺点:对其结果需进行大量分析及后处理,才能得到可靠分类结果;分类出的集群与地类间,或对应、或不对应,加上普遍存在的“同物异谱”及“异物同谱”现象,使集群组与类别的匹配难度大;因各类别光谱特征随时间、地形等变化,则不同图像间的光谱集群组无法保持其连续性,难以对比。