实验5时间序列分析解析
- 格式:doc
- 大小:511.50 KB
- 文档页数:11

应用时间序列分析实验报告实验名称第五章非平稳序列的随机分析专业班级姓名学号一、上机练习程序及其结果分析:data ex3_1;input x@@;time=_n_;cards;0.30 -0.45 0.36 0.00 0.17 0.45 2.154.42 3.48 2.99 1.74 2.40 0.11 0.960.21 -0.10 -1.27 -1.45 -1.19 -1.47 -1.34-1.02 -0.27 0.14 -0.07 0.10 -0.15 -0.36-0.50 -1.93 -1.49 -2.35 -2.18 -0.39 -0.52-2.24 -3.46 -3.97 -4.60 -3.09 -2.19 -1.210.78 0.88 2.07 1.44 1.50 0.29 -0.36-0.97 -0.30 -0.28 0.80 0.91 1.95 1.771.80 0.56 -0.11 0.10 -0.56 -1.34 -2.470.07 -0.69 -1.96 0.04 1.59 0.20 0.391.06 -0.39 -0.162.07 1.35 1.46 1.500.94 -0.08 -0.66 -0.21 -0.77 -0.52 0.05;procgplot data=ex3_1;plot x*time=1;symbol1c=red I=join v=star;run;结果分析:上图是数据对应的时序图,从图上曲线分析来看,数据并没有周期性或者趋向性规律,因而可以初步判断这是平稳数列。
procarima data=ex3_1;identifyVar=x nlag=8;run;结果分析:本过程中,我们建立了8阶自回归分析模型,图上依次是变量的描述性统计量、样本自相关图、样本逆相关图和样本偏自相关图。
由于本次实验探究的是平稳序列,因而样本逆相关图先不作分析。
从自相关图来看,自相关系数趋于0的速度是比较快的,再结合时序图来看,可以确定这组数列是属于平稳数列。

时间序列分析实验报告P185#1、某股票连续若干天的收盘价如表5-4(行数据)所示。
表5-4304 303 307 299 296 293 301 293 301 295 284 286 286 287 284 282 278 281 278 277 279 278 270 268 272 273 279 279 280 275 271 277 278 279 283 284 282 283 279 280 280 279 278 283 278 270 275 273 273 272 275 273 273 272 273 272 273 271 272 271 273 277 274 274 272 280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289选择适当模型拟合该序列的发展,并估计下一天的收盘价。
解:(1)通过SAS软件画出上述序列的时序图如下:程序:data example5_1;input x@@;time=_n_;cards;304 303 307 299 296 293 301 293 301 295 284 286 286 287 284282 278 281 278 277 279 278 270 268 272 273 279 279 280 275271 277 278 279 283 284 282 283 279 280 280 279 278 283 278270 275 273 273 272 275 273 273 272 273 272 273 271 272 271273 277 274 274 272 280 282 292 295 295 294 290 291 288 288290 293 288 289 291 293 293 290 288 287 289 292 288 288 285282 286 286 287 284 283 286 282 287 286 287 292 292 294 291288 289;proc gplot data=example5_1;plot x*time=1;symbol1c=black v=star i=join;run;上述程序所得时序图如下:上述时序图显示,该序列具有长期趋势又含有一定的周期性,为典型的非平稳序列。

时间序列分析试验报告
一、试验简介
本次试验旨在探索时间序列分析,以分析日期变化的影响与规律。
时
间序列分析是数据分析的一种,目的是预测未来正确的趋势,并且分析既
有趋势的影响及其变化。
二、试验材料
本次试验使用的资料为最近12个月(即2024年1月到2024年12月)的电子商务网站销售数据。
该电子商务网站以每月总销售量、每月总销售
额及每月交易次数三个变量作为试验数据。
三、试验方法
1.首先,收集2024年1月到2024年12月的电子商务销售数据,记
录每月总销售量、总销售额及交易次数。
2.然后,编制时间序列分析图表,反映每月总销售量、总销售额及
交易次数的变化情况。
3.最后,分析每月的变化趋势,比较每月的销售数据,并进行相关
分析推断。
四、实验结果
1.通过时间序列分析图表可以看出,每月总销售量、总销售额及交
易次数均呈现出稳定上升趋势。
2.从图表中可以推断,在2024年底到2024年底,当月的总销售量、总销售额及交易次数均较上月有所增加。
3.从表中可以推断,每月的总销售量、总销售额及交易次数都在逐渐增加,最终在2024年末达到高峰。
五、结论
通过本次实验可以得出结论。

时间序列分析实验指导时间序列分析是一种常用的统计方法,用于分析时间上的变化趋势和周期性变化。
它能够帮助我们预测未来的趋势和判断时间序列数据之间的因果关系。
本文将详细介绍进行时间序列分析的实验指导,包括实验准备、数据处理和模型建立等内容。
一、实验准备1. 确定实验目标:首先需要确定想要分析的时间序列的目标,如销售额、股票价格等。
明确实验目标有助于确定实验的方向和方法。
2. 数据采集:根据实验目标,选择合适的数据源,并采集相关数据。
常见的数据源包括数据库、API接口和互联网上的公开数据等。
3. 数据预处理:对采集到的数据进行预处理,包括数据清洗、填补缺失值和去除异常值等操作。
确保数据的准确性和一致性。
二、数据处理1. 数据可视化:将采集到的数据进行可视化,以便更好地理解数据的特征和变化趋势。
可以通过绘制时间序列图、箱线图和自相关图等方式进行数据可视化。
2. 数据平稳化:时间序列分析要求数据是平稳的,即均值和方差不随时间变化。
如果数据不平稳,需要进行平稳化处理。
常见的平稳化方法包括差分和对数变换。
3. 自相关性检验:利用自相关函数(ACF)和偏自相关函数(PACF)来检验数据的自相关性。
分析自相关系数的大小和延迟的时间间隔,判断是否存在显著的自相关关系。
4. 白噪声检验:利用残差的自相关函数和偏自相关函数来检验数据是否为白噪声。
如果数据是白噪声,说明数据中不存在周期性和趋势,不适合进行时间序列分析。
三、模型建立1. 模型选择:根据数据的特征和目标确定合适的时间序列模型。
常见的时间序列模型包括AR模型、MA模型、ARMA模型和ARIMA模型等。
2. 参数估计:对选择的模型进行参数估计,可以使用极大似然估计、最小二乘法或贝叶斯估计等方法。
3. 模型诊断:对模型进行诊断,判断模型的拟合程度和残差的性质。
可以使用残差自相关函数和偏自相关函数来检验模型的拟合优度。
4. 模型预测:利用已建立的模型对未来的数据进行预测。

《时间序列分析》课程实验报告一、上机练习(P124)1.拟合线性趋势程序:data xiti1;input x@@;t=_n_;cards;;proc gplot data=xiti1;plot x*t;symbol c=red v=star i=join;run;proc autoreg data=xiti1;model x=t;output predicted=xhat out=out;run;proc gplot data=out;plot x*t=1 xhat*t=2/overlay;symbol2c=green v=star i=join;run;运行结果:分析:上图为该序列的时序图,可以看出其具有明显的线性递增趋势,故使用线性模型进行拟合:x t=a+bt+I t,t=1,2,3,…,12分析:上图为拟合模型的参数估计值,其中a=,b=,它们的检验P值均小于,即小于显著性水平,拒绝原假设,故其参数均显著。
从而所拟合模型为:x t=+.分析:上图中绿色的线段为线性趋势拟合线,可以看出其与原数据基本吻合。
2.拟合非线性趋势程序:data xiti2;input x@@;t=_n_;cards;;proc gplot data=xiti2;plot x*t;symbol c=red v=star i=none;run;proc nlin method=gauss;model x=a*b**t;parameters a= b=;=b**t;=a*t*b**(t-1);output predicted=xh out=out;run;proc gplot data=out;plot x*t=1 xh*t=2/overlay;symbol2c=green v=none i=join;run;运行结果:分析:上图为该时间序列的时序图,可以很明显的看出其基本是呈指数函数趋势慢慢递增的,故我们可以选择指数型模型进行非线性拟合:x t=ab t+I t,t=1,2,3,…,12分析:由上图可得该拟合模型为:x t=*+I t分析:图中的红色星号为原序列值,绿色的曲线为拟合后的拟合曲线,可以看出原序列值与拟合值基本上是重合的,故该拟合效果是很好的。

引言概述:
时间序列分析是一种用于研究时间数据的统计方法,主要关注数据随时间的变化趋势、季节性和周期性等特征。
时间序列分析应用广泛,可以用于金融预测、经济分析、气象预测等领域。
本实验报告旨在介绍时间序列分析的基本概念和方法,并通过实例分析来展示其应用。
正文内容:
1.时间序列分析基本概念
1.1时间序列的定义
1.2时间序列的模式
1.3时间序列分析的目的
2.时间序列分析方法
2.1随机游走模型
2.2移动平均模型
2.3自回归移动平均模型
2.4季节性模型
2.5ARCH和GARCH模型
3.时间序列数据预处理
3.1数据平稳性检验
3.2数据平滑
3.3缺失值填补
3.4离群值检测
3.5数据变换
4.时间序列模型建立与评估
4.1模型的选择
4.2参数估计
4.3拟合优度检验
4.4模型诊断
4.5预测准确性评估
5.实例分析:某公司销售数据时间序列分析
5.1数据收集与预处理
5.2模型建立与评估
5.3预测分析与结果解释
5.4预测精度评估
5.5结果讨论与进一步改进方向
总结:
时间序列分析是一种重要的统计方法,可用于预测和分析时间相关的数据。
本报告介绍了时间序列分析的基本概念和方法,并通
过实例分析展示了其应用过程。
通过时间序列分析,可以更好地理解数据的趋势和周期性,并进行准确的预测。
时间序列分析也面临着多样的挑战,如数据质量问题和模型选择困难等。
因此,在实际应用中,需要综合考虑多种因素,灵活运用合适的方法和技巧,以提高预测准确性和分析可靠性。

生命科学中的时间序列数据分析方法随着生命科学研究的深入,越来越多的实验数据被收集和存储下来。
这些数据通常是在一段时间内进行收集并记录下来的。
由此,时间序列数据成为生命科学领域中数据分析研究的重要内容。
时间序列数据分析方法是科学家们应对这种大量生命科学数据的一个必备工具。
时间序列数据分析方法可以帮助科学家们从大量的数据中分辨出有用的信息。
比如,生命科学领域中的一些实验需要大量的数据来观察细胞、物种、环境等的变化。
这些变化通常是随时间发生的。
例如,在细胞实验中,可以观察到细胞的生长速度、细胞质的变化等等。
所有这些数据都可以被视为时间序列数据。
然后,通过时间序列数据分析方法,科学家们可以发现其中变化的规律性,从而为生物学、生态学、环境科学等研究提供支持。
时间序列数据分析方法已经在各种生命科学领域中应用。
例如,在生态学中,时间序列数据可以被使用来预测种群动态、物种的遗传变异等等。
在医学中,时间序列数据可以被用来分析病人的电生理、生化数据等。
不同的分析方法可以被使用来处理时间序列数据。
第一种方法是采用频谱分析法。
这种方法将时间序列数据转化为频谱数据(幅度和相位),然后分析序列中的频率。
采用这种方法,科学家们可以了解样本中其中的周期性、频率和振幅分布情况。
然而,这种方法只适用于具有规律性和周期性的数据。
另外,采用频谱分析法分析大量数据时,需要较长的计算时间。
第二种方法是使用自回归模型。
这种方法使用时间序列数据中先前时间点的信息来预测未来的值。
在预测时,较早的时间点数据对未来的预测值的贡献相对较小,而较近的时间点数据则贡献较大。
自回归模型适合预测没有规律性但是有自相似性的数据。
不过,这种方法只能处理相对较小数据集,以达到高准确性的预测结果和较短的计算时间。
第三种方法是使用市场模型。
市场模型是用来预测时间序列数据的变化范围和分布情况的。
市场模型可以建模样本间的关系,提供市场呼吸动态中的均值、方差和协方差等。
通常情况下,这种方法用于预测有随机性但是有序的数据。

统计学原理教案中的时间序列分析解析学生如何分析和预测时间序列数据的趋势和模式时间序列分析是统计学中一种重要的数据分析方法,主要用于研究时间上的连续观测数据,了解其变化趋势和模式。
在统计学原理教案中,时间序列分析是一个关键的内容,可以帮助学生掌握分析和预测时间序列数据的方法和技巧。
一、时间序列分析的概念与应用场景时间序列分析是指对一系列按时间顺序排列的数据进行统计分析的方法。
它可以用于解析时间序列数据中所蕴含的趋势、周期性等信息,进而进行预测和决策。
时间序列分析广泛应用于金融、经济学、环境科学、天气预报等领域,对于理解数据的变化规律和趋势具有重要意义。
二、时间序列分析的基本步骤1. 数据收集与整理:首先需要收集与时间相关的数据,并按照时间顺序进行整理,确保数据的连续性和完整性。
2. 描述性统计分析:对时间序列数据进行描述性统计,包括均值、方差、自相关性等指标的计算,以获得数据的基本统计特征。
3. 趋势分析:通过绘制时间序列数据的图表,观察数据的趋势变化,判断数据是否存在明显的上升或下降趋势。
4. 季节性分析:对时间序列数据进行季节性分解,将原始数据分解为趋势、季节和残差三个部分,以便进一步了解季节性变化的规律。
5. 预测与模型选择:根据过去的时间序列数据,选择合适的模型对未来的数据进行预测,常用的模型包括移动平均、指数平滑和ARIMA 模型等。
三、常用的时间序列分析方法1. 移动平均法:该方法是通过计算一定时间段内数据的平均值,来判断数据的变化趋势。
可以使用简单移动平均法或加权移动平均法进行计算。
2. 指数平滑法:该方法假设未来的数值主要由过去的数值决定,通过给不同时间段的数据赋予不同的权重,来预测未来的数值。
常用的指数平滑方法有简单指数平滑法和二次指数平滑法。
3. ARIMA模型:ARIMA模型是一种常用的时间序列分析方法,可以用来描述数据的自相关性和随机性,并进行预测。
ARIMA模型包括自回归项(AR)、差分项(I)和移动平均项(MA)。


时间序列分析(实验指导)时间序列分析实验指导随着计算机技术的飞跃发展以及应⽤软件的普及,对⾼等院校的实验教学提出了越来越⾼的要求。
为实现教育思想与教学理念的不断更新,在教学中必须注重对⼤学⽣动⼿能⼒的培训和创新思维的培养,注重学⽣知识、能⼒、素质的综合协调发展。
为此,我们组织统计与应⽤数学学院的部分教师编写了系列实验教学指导书。
这套实验教学指导书具有以下特点:①理论与实践相结合,书中的⼤量经济案例紧密联系我国的经济发展实际,有利于提⾼学⽣分析问题解决问题的能⼒。
②理论教学与应⽤软件相结合,我们根据不同的课程分别介绍了SPSS、SAS、MATLAB、EVIEWS等软件的使⽤⽅法,有利于提⾼学⽣建⽴数学模型并能正确求解的能⼒。
这套实验教学指导书在编写的过程中始终得到安徽财经⼤学教务处、实验室管理处以及统计与应⽤数学学院的关⼼、帮助和⼤⼒⽀持,对此我们表⽰衷⼼的感谢!限于我们的⽔平,欢迎各⽅⾯对教材存在的错误和不当之处予以批评指正。
统计与数学模型分析实验中⼼ 2007年2⽉⽬录实验⼀ EVIEWS中时间序列相关函数操作 ·································· - 1 - 实验⼆确定性时间序列建模⽅法··············································· - 8 - 实验三时间序列随机性和平稳性检验 ····································· - 18 - 实验四时间序列季节性、可逆性检验 ····································· - 21 - 实验五 ARMA模型的建⽴、识别、检验 ···································· - 27 - 实验六 ARMA模型的诊断性检验 ················································ - 30 - 实验七 ARMA模型的预测···························································· - 31 - 实验⼋复习ARMA建模过程······················································· - 33 - 实验九时间序列⾮平稳性检验 ················································· - 35 -实验⼀ EVIEWS中时间序列相关函数操作【实验⽬的】熟悉Eviews的操作:菜单⽅式,命令⽅式;练习并掌握与时间序列分析相关的函数操作。
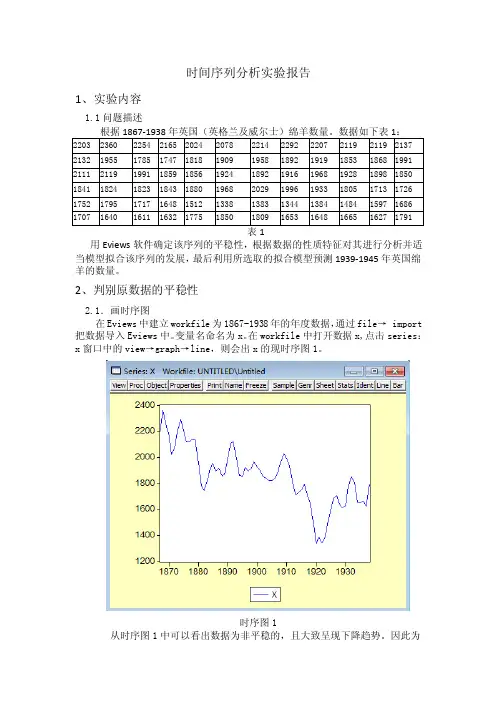
时间序列分析实验报告1、实验内容1.1问题描述用Eviews软件确定该序列的平稳性,根据数据的性质特征对其进行分析并适当模型拟合该序列的发展,最后利用所选取的拟合模型预测1939-1945年英国绵羊的数量。
2、判别原数据的平稳性2.1.画时序图在Eviews中建立workfile为1867-1938年的年度数据,通过file→ import 把数据导入Eviews中。
变量名命名为x。
在workfile中打开数据x,点击series:x窗口中的view→graph→line,则会出x的现时序图1。
时序图1从时序图1中可以看出数据为非平稳的,且大致呈现下降趋势。
因此为经一步说明该数据的平稳性,做相关分析。
2.2.自相关分析继续在该时序图窗口中点击view→correlogram,在弹出的correlogram Specification 的对话框中的lags to include中输入12,点击OK。
则x的自相关图2如下。
自相关图2从自相关图的autocorrelation的一栏可以看出自相大部分都关超出了(至少第三个自相关值要落入两倍的标准差中则为平稳的)两倍的标准差。
则可以进一步认为该数据为非平稳的。
为作出最终的判断,对数进行单位根检验。
2.3.单位根检验同样在自相关图2的窗口中点击view→unit root test在弹出的unit root test 的对话空中的automatic selection的下拉框中选择Schwarz Info,并在Include in test equation中选择intercept点击ok则有如下结果输出单位根表3。
单位根表3从表3中以看所有的ADF值没有都小于值临界值,因此结合时序图和自相关图可以判断出该数据为非平稳的。
3、对数据进行平稳化3.1.对数据做一阶差分在代码窗口中输入genr dx=d(x)并按回车键则在workfile窗体中新生成变量为dx的数据该数据即为x的一阶差分。
时间序列分析实验报告一、实验目的时间序列分析是一种用于处理和分析随时间变化的数据的统计方法。
本次实验的主要目的是通过对给定的时间序列数据进行分析,掌握时间序列分析的基本方法和技术,包括数据预处理、模型选择、参数估计和预测,并评估模型的性能和准确性。
二、实验数据本次实验使用了一组某商品的月销售量数据,数据涵盖了过去两年的时间范围,共 24 个观测值。
数据的具体形式为一个时间序列,其中每个观测值表示该商品在相应月份的销售量。
三、实验方法1、数据预处理首先,对数据进行了可视化,绘制了时间序列图,以便直观地观察数据的趋势、季节性和随机性。
然后,对数据进行了平稳性检验。
采用了 ADF(Augmented DickeyFuller)检验来判断数据是否平稳。
如果数据不平稳,则需要进行差分处理,使其达到平稳状态。
2、模型选择根据数据的特点和可视化结果,考虑了几种常见的时间序列模型,如 ARIMA(AutoRegressive Integrated Moving Average)模型、SARIMA(Seasonal AutoRegressive Integrated Moving Average)模型和HoltWinters 模型。
通过对不同模型的参数进行估计,并比较它们在训练数据上的拟合效果和预测误差,选择了最适合的模型。
3、参数估计对于选定的模型,使用最大似然估计或最小二乘法等方法来估计模型的参数。
通过对参数的估计值进行分析,判断模型的合理性和稳定性。
4、预测使用估计得到的模型参数,对未来一段时间内的销售量进行预测。
为了评估预测的准确性,采用了均方根误差(RMSE)、平均绝对误差(MAE)等指标来衡量预测值与实际值之间的差异。
四、实验过程1、数据可视化通过绘制时间序列图,发现数据呈现出明显的季节性和上升趋势。
同时,数据的波动范围也较大,存在一定的随机性。
2、平稳性检验对原始数据进行 ADF 检验,结果表明数据是非平稳的。
第1篇一、实验目的1. 了解时间序列的基本概念和特性;2. 掌握时间序列的常用分析方法;3. 学会运用时间序列分析方法解决实际问题。
二、实验内容1. 时间序列数据收集2. 时间序列描述性分析3. 时间序列平稳性检验4. 时间序列模型构建5. 时间序列预测三、实验方法1. 时间序列数据收集:通过查阅相关文献、统计数据网站等方式获取实验所需的时间序列数据。
2. 时间序列描述性分析:对时间序列数据进行统计分析,包括均值、标准差、偏度、峰度等。
3. 时间序列平稳性检验:运用单位根检验(ADF检验)判断时间序列的平稳性。
4. 时间序列模型构建:根据时间序列的平稳性,选择合适的模型进行构建,如ARIMA模型、季节性分解模型等。
5. 时间序列预测:利用构建好的时间序列模型进行预测,并评估预测结果的准确性。
四、实验步骤1. 数据收集:选取我国某地区近十年的GDP数据作为实验数据。
2. 描述性分析:计算GDP数据的均值、标准差、偏度、峰度等统计量。
3. 平稳性检验:对GDP数据进行ADF检验,判断其平稳性。
4. 模型构建:根据ADF检验结果,选择合适的模型进行构建。
5. 预测:利用构建好的模型对GDP数据进行预测,并评估预测结果的准确性。
五、实验结果与分析1. 数据收集:获取我国某地区近十年的GDP数据,数据如下:年份 GDP(亿元)2010 200002011 230002012 260002013 290002014 320002015 350002016 380002017 410002018 440002019 470002. 描述性分析:计算GDP数据的均值、标准差、偏度、峰度等统计量,结果如下:均值:39600亿元标准差:4900亿元偏度:-0.2峰度:-1.83. 平稳性检验:对GDP数据进行ADF检验,结果显示ADF统计量在1%的显著性水平下拒绝原假设,说明GDP数据是非平稳的。
4. 模型构建:由于GDP数据是非平稳的,我们可以对其进行差分处理,使其变为平稳序列。
应用时间序列分析实验手册时间序列分析是分析和预测时间序列数据的一种重要方法。
它可以用来研究时间序列数据中的趋势、季节性、周期性和随机性等特征,并通过建立适当的时间序列模型来对未来的数据进行预测。
为了进行时间序列分析,需要按照一定的步骤进行实验。
下面是一个应用时间序列分析的实验手册,它包括了以下几个步骤:1. 收集数据:首先需要收集时间序列数据。
时间序列可以是连续的,比如每天、每周或每月的数据,也可以是离散的,比如每小时或每分钟的数据。
数据可以来自不同的来源,如统计局、公司、网站等。
2. 数据预处理:在进行时间序列分析之前,需要对数据进行预处理。
预处理的目的是去除异常值、平滑数据、填补缺失值等。
常用的预处理方法包括平滑法、插值法、滤波法等。
3. 数据可视化:在进行时间序列分析之前,需要对数据进行可视化。
可以使用折线图、柱状图、散点图等方法展示时间序列数据的趋势和季节性。
4. 应用时间序列模型:时间序列模型是用来描述时间序列数据的数学模型。
常用的时间序列模型包括平稳ARMA模型、非平稳ARIMA模型、指数平滑模型等。
根据数据的不同特点选择合适的模型。
5. 模型诊断:在应用时间序列模型后,需要对模型进行诊断。
诊断的目的是检查模型的拟合程度和预测能力。
常用的诊断方法包括残差分析、模型的稳定性检验等。
6. 模型预测:基于已建立的时间序列模型,可以对未来的数据进行预测。
预测的方法包括单步预测、多步预测、滚动预测等。
7. 模型评估:在进行时间序列预测之后,需要对预测结果进行评估。
常用的评估指标包括均方误差、平均绝对误差、相对误差等。
评估结果可以用来评估模型的预测准确性和稳定性。
总结:时间序列分析是一种重要的数据分析方法,可以用来研究和预测时间序列数据的趋势、季节性、周期性和随机性等特征。
通过按照上述步骤进行实验,可以有效地应用时间序列分析方法,提高对时间序列数据的理解和预测能力。
8. 趋势分析:在时间序列分析中,趋势是指数据中的长期变化。
一、实验目的1. 了解时间序列分析的基本原理和方法;2. 掌握时间序列数据的平稳性检验、模型识别和参数估计等基本操作;3. 通过实例,学习使用ARIMA模型进行时间序列预测。
二、实验环境1. 操作系统:Windows 102. 软件环境:EViews 9.0、R3.6.1三、实验数据1. 数据来源:某城市1980年1月至2020年12月每月的GDP数据;2. 数据格式:Excel表格。
四、实验步骤1. 数据预处理(1)导入数据:将Excel表格中的GDP数据导入EViews软件;(2)观察数据:绘制GDP时间序列图,观察数据的趋势、季节性和周期性;(3)平稳性检验:使用ADF检验判断GDP序列是否平稳。
2. 模型识别(1)自相关函数(ACF)和偏自相关函数(PACF)图:观察ACF和PACF图,初步确定ARIMA模型的阶数;(2)模型选择:根据ACF和PACF图,选择合适的ARIMA模型。
3. 模型估计(1)模型估计:使用EViews软件中的ARIMA过程,对选择的模型进行参数估计;(2)模型检验:对估计出的模型进行残差检验,包括残差的平稳性检验、白噪声检验等。
4. 时间序列预测(1)预测:使用估计出的ARIMA模型,对2021年1月至2025年12月的GDP进行预测;(2)预测结果分析:对预测结果进行分析,评估预测的准确性。
五、实验结果与分析1. 数据预处理(1)导入数据:将Excel表格中的GDP数据导入EViews软件;(2)观察数据:绘制GDP时间序列图,发现GDP序列存在明显的上升趋势和季节性;(3)平稳性检验:使用ADF检验,发现GDP序列在5%的显著性水平下拒绝原假设,序列是平稳的。
2. 模型识别(1)自相关函数(ACF)和偏自相关函数(PACF)图:根据ACF和PACF图,初步确定ARIMA模型的阶数为(1,1,1);(2)模型选择:根据ACF和PACF图,选择ARIMA(1,1,1)模型。
实验五时间序列分析【实验项目】419023003-05【实验目的与要求】1、掌握利用Excel和SPSS 软件进行移动平均、滑动平均的基本方法2、掌握利用Excel和SPSS 软件进行自相关分析和自回归分析的基本方法【实验内容】1、移动平均法2、滑动平均法3、自相关分析4、自回归分析【实验步骤】时间序列,也叫时间数列或动态数列,是要素(变量)的数据按照时间顺序变动排列而形成的一种数列,它反映了要素(变量)随时间而变化的发展过程。
常规时间序列分析方法包括移动平均法、滑动平均法、指数平滑法、自回归分析方法。
本实验以教材P75表3.3.1 “某地区1990-2004年粮食产量”说明应用Excel 和SPSS软件进行移动平均、滑动平均、指数平滑和自回归分析的基本方法。
在实验之前需要将表3.3.1录入到Excel里(表5.1)。
表5.1某地区1990-2004年粮食产量一、移动平均法(一)应用Excel进行移动平均计算在“数据分析”里可以直接进行计算操作步骤1、打开表5.1。
2、【工具】→【数据分析】→【移动平均】,在弹出的“移动平均”对话框中,分别作如图5.1和图5.2的设置:图5.1 “移动平均”对话框(三点移动)图5.2 “移动平均”对话框(五点移动)3、在原数据表格的C1和D1单元格分别输入“三点移动平均”和“五点移动平均”(图5.3),得到“三点移动平均”和“五点移动平均”计算结果(注意和教材中的结果进行比较.............)。
图5.3 三点和五点移动平均计算结果(二)应用SPSS进行移动平均计算操作步骤1、启动SPSS,打开表5.1。
2、【转换】→【创建时间序列】,在弹出的“创建时间序列”对话框中,“函数”选项列举了创建新变量的方法,其中“先前移动平均”即为通常所说的“移动平均”,“中心移动平均”则为“滑动平均”。
图5.4 “创建时间序列”对话框“函数”选项3、在“创建时间序列”对话框“函数”选项中选择“先前移动平均”,在“跨度”方框中填写“3”,然后将“粮食产量”通过箭头输入到右边的“变量:新名称”中,再在“名称”方框中改成“粮食产量三点移动”,点击“更改”按钮。
再在“跨度”方框中填写“5”,然后将“粮食产量”通过箭头输入到右边的“变量:新名称”中,再在“名称”方框中改成“粮食产量五点移动”,点击“更改”按钮。
单击“确定”。
图5.5 “创建时间序列”对话框中的设置5、在数据视图中自动得到“三点移动平均”和“五点移动平均”的结果(图5.6)。
(比..较图.....中要得到与图......5.6....Excel...相同的结果,该如何进行计..............5.3.....,思考在...和图...结果的差异..5.6算?..).图5.6 “三点移动平均”和“五点移动平均”结果二、滑动平均法(一)应用Excel进行滑动平均计算操作步骤1、打开表5.1。
2、在C2中输入三点滑动平均计算公式如图5.7所示,点击“确定”。
然后用鼠标左键拖动C2右下角的黑色方块直到C15释放,得到三点滑动平均结果。
同理得到五点滑动平均结果(图5.8)。
图5.7 三点滑动平均计算所用的函数参数图5.8 三点滑动平均和五点滑动平均计算结果(二)应用SPSS进行滑动平均计算操作步骤1、启动SPSS,打开表5.1。
2、【转换】→【创建时间序列】,在弹出的“创建时间序列”对话框“函数”选项中选择“中心移动平均”,在“跨度”方框中填写“3”,然后将“粮食产量”通过箭头输入到右边的“变量:新名称”中,再在“名称”方框中改成“粮食产量三点滑动”,点击“更改”按钮。
再在“跨度”方框中填写“5”,然后将“粮食产量”通过箭头输入到右边的“变量:新名称”中,再在“名称”方框中改成“粮食产量五点滑动”,点击“更改”按钮。
单击“确定”。
图5.9 “创建时间序列”对话框中的设置3、在数据视图中自动得到“三点移动平均”和“五点移动平均”的结果(图5.10)图5.10 “三点滑动平均”和“五点滑动平均”结果三、自相关分析自相关分析是建立自回归模型的基础。
(一)应用Excel进行自相关分析操作步骤1、打开表5.1。
2、在C1-H1分别输入如图5.11所示的文字,将B2-B16复制到C2-C16和F2-F16,B2-B15复制到D3-D16,B2-B14复制到E4-E16,B3-B16复制到G2-G15,B4-B16复制到H2-H14(图5.11)。
图5.11 创建时间序列分析所用的数据3、【工具】→【数据分析】→【相关系数】,在“相关系数”对话框中进行如图5.12和图5.13的设置,分别点击“确定”,得到该时间序列的一阶和二阶自相关系数(图5.14)。
从图5.14可以看出粮食产量与滞后一期、提前一期的一阶和二阶自相关系数是相等的,但要注意的是进行自回归分析时需要用到的是滞后数据,即用已有的时间序列数据对未来时期的变量进行预测计算。
图5.12 粮食产量与滞后一期和两期粮食产量自相关系数计算图5.13 粮食产量与提前一期和两期粮食产量自相关系数计算图5.14 一阶和二阶自相关系数计算结果4、自相关系数显著性检验(参考教材P78,此处略)。
(二)应用SPSS进行自相关分析操作步骤1、启动SPSS,打开表5.1。
2、【转换】→【创建时间序列】,在弹出的“创建时间序列”对话框“函数”选项中选择“滞后”,在“顺序”方框中填写“1”,然后将“粮食产量”通过箭头输入到右边的“变量:新名称”中,再在“名称”方框中改成“粮食产量yt减1”,点击“更改”按钮。
再在“顺序”方框中填写“2”,然后将“粮食产量”通过箭头输入到右边的“变量:新名称”中,再在“名称”方框中改成“粮食产量yt减2”,点击“更改”按钮。
在“创建时间序列”对话框“函数”选项中选择“提前”,在“顺序”方框中填写“1”,然后将“粮食产量”通过箭头输入到右边的“变量:新名称”中,再在“名称”方框中改成“粮食产量yt加1”,点击“更改”按钮。
在“顺序”方框中填写“2”,然后将“粮食产量”通过箭头输入到右边的“变量:新名称”中,再在“名称”方框中改成“粮食产量yt加2”,点击“更改”按钮。
单击“确定”(图5.15)。
图5.15 “创建时间序列”对话框图5.16 创建的用于时间序列分析的数据4、【分析】→【相关】→【双变量…】,在“双变量相关”对话框中进行如图5.17的设置,点击“确定”。
图5.17 粮食产量与滞后一期、二期自相关系数计算5、在输出窗口中得到粮食产量与滞后一期、二期粮食产量的一阶、二阶自相关系数(表5.2)。
从表5.2中可知,粮食产量的一阶、二阶自相关系数分别是0.860和0.806,在0.01水平上显著相关。
表5.2 相关性粮食产量y/104t LAGS(粮食产量y104t,1)LAGS(粮食产量y104t,2)粮食产量y/104t Pearson 相关性 1 .860**.806**显著性(双侧).000 .001N 15 14 13 LAGS(粮食产量y104t,1) Pearson 相关性.860** 1 .836**显著性(双侧).000 .000N 14 14 13 LAGS(粮食产量y104t,2) Pearson 相关性.806**.836** 1显著性(双侧).001 .000N 13 13 13**. 在 .01 水平(双侧)上显著相关。
6、同理可以求得粮食产量与提前一期、二期粮食产量的一阶、二阶自相关系数,且与滞后一阶、二阶自相关系数相等(过程略)。
四、自回归分析(一)应用Excel进行自回归分析操作步骤1、打开图5.11所示的表格。
2、【工具】→【数据分析】→【回归】,在“回归”对话框中进行如图5.18的设置(注意Y值和X值输入区域的设置),点击“确定”,得到自回归结果(图5.19)。
图5.18 “回归”对话框设置图5.19 自回归分析结果从图5.19可以看出,二阶自回归模型的参数分别是:常数项312.7693、y t-1的系数为0.5998、y t-2的系数为0.3467,则该地区粮食产量的自回归模型为^12312.76930.59980.3467t t y y y --=++应用这个公式可以对2004年后的年份的粮食产量进行预测。
(二)应用SPSS 进行自回归分析 操作步骤1、启动SPSS ,打开图5.16所示的表格。
11 / 112、【分析】→【回归】→【线性…】,在弹出的“线性回归”对话框中进行如图5.18的设置(因变量为原粮食产量序列,自变量为滞后一期、二期的粮食产量),点击“确定”。
图5.19 “线性回归”对话框设置3、在输出窗口中给出了建立的自回归模型的信息,其中模型参数如表5.3所示:表5.3 系数a模型 非标准化系数标准系数 t Sig. B 标准 误差 试用版1(常量)312.769642.909.486.637 LAGS(粮食产量y104t,1) .600 .302 .574 1.988 .075 LAGS(粮食产量y104t,2).347.307.3261.131.285a. 因变量: 粮食产量y/104t常数项312.7693、y t-1的系数为0.600、y t-2的系数为0.347,则该地区粮食产量的自回归模型为^12312.7690.6000.347t t y y y --=++同样可以应用这个公式可以对2004年后的年份的粮食产量进行预测。
【练习】教材P116 第14题。