《编译原理教程》课后习题答案 第五章 代码优化
- 格式:ppt
- 大小:541.50 KB
- 文档页数:39


编译原理-第5章-习题与答案2第五章习题5-1 设有文法G[S]:S→A/ A→aA∣AS∣/(1) 找出部分符号序偶间的简单优先关系。
(2) 验证G[S]不是简单优先文法。
5-2 对于算符文法G[S]:S→E E→E-T∣T T→T*F∣F F→-P∣P P→(E)∣i(1) 找出部分终结符号序偶间的算符优先关系。
(2) 验证G[S]不是算符优先文法。
5-3 设有文法G′[E]:E→E1 E1→E1+T1|T1 T1→T T→T*F|F F→(E)|i其相应的简单优先矩阵如题图5-3所示,试给出对符号串(i+i)进行简单优先分析的过程。
题图5-3 文法G′[E]的简单优先矩阵5-4 设有文法G[E]:E→E+T|TT→T*F|FF→(E)|i其相应的算符优先矩阵如题图5-4所示。
试给出对符号串(i+i)进行算符优先分析的过程。
题图5-4 文法G[E]的算符优先矩阵5-5 对于下列的文法,试分别构造识别其全部可归前缀的DFA和LR(0)分析表,并判断哪些是LR(0)文法。
(1) S→aSb∣aSc∣ab(2) S→aSSb∣aSSS∣c(3) S→A A→Ab∣a5-6 下列文法是否是SLR(1)文法?若是,构造相应的SLR(1)分析表,若不是,则阐明其理由。
(1) S→Sab∣bR R→S∣a(2) S→aSAB∣BA A→aA∣B B→b(3) S→aA∣bB A→cAd∣ε B→cBdd∣ε5-7 对如下的文法分别构造LR(0)及SLR(1)分析表,并比较两者的异同。
S→cAd∣b A→ASc∣a5-8 对于文法G[S]:S→A A→BA∣ε B→aB∣b(1) 构造LR(1)分析表;(2) 给出用LR(1)分析表对输入符号串abab的分析过程。
5-9 对于如下的文法,构造LR(1)项目集族,并判断它们是否为LR(1)文法。
(1) S→A A→AB∣ε B→aB∣b(2) S→aSa∣a第5章习题答案25-1 解:(1) 由文法的产生式和如答案图5-1(a)所示的句型A//a/的语法树,可得G中的部分优先关系如答案图5-1(b)所示。


编译原理课后习题答案第一章1.典型的编译程序在逻辑功能上由哪几部分组成?答:编译程序主要由以下几个部分组成:词法分析、语法分析、语义分析、中间代码生成、中间代码优化、目标代码生成、错误处理、表格管理。
2. 实现编译程序的主要方法有哪些?答:主要有:转换法、移植法、自展法、自动生成法。
3. 将用户使用高级语言编写的程序翻译为可直接执行的机器语言程序有哪几种主要的方式?答:编译法、解释法。
4. 编译方式和解释方式的根本区别是什么?答:编译方式:是将源程序经编译得到可执行文件后,就可脱离源程序和编译程序单独执行,所以编译方式的效率高,执行速度快;解释方式:在执行时,必须源程序和解释程序同时参与才能运行,其不产生可执行程序文件,效率低,执行速度慢。
第二章1.乔姆斯基文法体系中将文法分为哪几类?文法的分类同程序设计语言的设计与实现关系如何?答:1)0型文法、1型文法、2型文法、3型文法。
2)2. 写一个文法,使其语言是偶整数的集合,每个偶整数不以0为前导。
答:Z→SME | BS→1|2|3|4|5|6|7|8|9M→ε | D | MDD→0|SB→2|4|6|8E→0|B3. 设文法G为:N→ D|NDD→ 0|1|2|3|4|5|6|7|8|9请给出句子123、301和75431的最右推导和最左推导。
答:N?ND?N3?ND3?N23?D23?123N?ND?NDD?DDD?1DD?12D?123N?ND?N1?ND1?N01?D01?301N?ND?NDD?DDD?3DD?30D?301N?ND?N1?ND1?N31?ND31?N431?ND431?N5431?D5431?7 5431N?ND?NDD?NDDD?NDDDD?DDDDD?7DDDD?75DDD?754 DD?7543D?75431 4. 证明文法S→iSeS|iS| i是二义性文法。
答:对于句型iiSeS存在两个不同的最左推导:S?iSeS?iiSesS?iS?iiSeS所以该文法是二义性文法。

第五章习题解答5.1 设一NDPDA识别由下述CFG定义的语言,试给出这个NDPDA的完整形式描述。
S→SASCS→εA→AaA→bC→DcDD→d5.2 消除下列文法的左递归:① G[A]:A→BX∣CZ∣WB→Ab∣BcC→Ax∣By∣Cp② G[E]:E→ET+∣ET–∣TT→TF*∣TF/FF→(E)∣i③ G[X]:X→Ya∣Zb∣cY→ Zd∣Xe∣fZ→X e∣Yf∣a④ G[A]:A→Ba|Aa|cB→Bb|Ab|d5.3 设文法G[<语句>]:<语句>→<变量>: = <表达式>|if<表达式>then<语句>|if<表达式>then<语句>else<语句> <变量>→i<表达式>→<项>|<表达式>+<项><项>→<因子>|<项>*<因子><因子>→<变量>|′(′<表达式>′)′试构造该文法的递归下降子程序。
5.4 设文法G[E]:E→ TE'E'→ + E∣εT→ FT'T'→ T∣εF→ PF'F'→ *F∣εP→ (E)∣ a∣^①构造该文法的递归下降分析程序;②求该文法的每一个非终结符的FIRST集合和FOLLOW集合;③构造该文法的LL(1)分析表,并判断此文法是否为LL(1)文法。
5.5 设文法G[S]:S→ SbA∣aAB→ SbA→ Bc①将此文法改写为LL(1)文法;②求文法的每一个非终结符的FIRST集合和FOLLOW集合;③构造相应的LL(1)分析表。
5.6 设文法G[S]:S→ aABbcd∣εA→ ASd∣εB→ SAh∣eC∣εC→ Sf∣Cg∣εD→ aBD∣ε①求每一个非终结符的FOLLOW集合;②对每一个非终结符的产生式选择,构造FIRST集合;③该文法是LL(1)文法。




第五章代码优化5.1 完成以下选择题:(1) 优化可生成的目标代码。
a. 运行时间较短b. 占用存储空间较小c. 运行时间短但占用内存空间大d. 运行时间短且占用存储空间小(2) 下列优化方法不是针对循环优化进行的。
a. 强度削弱b. 删除归纳变量c. 删除多余运算d. 代码外提(3) 基本块内的优化为。
a. 代码外提,删除归纳变量b. 删除多余运算,删除无用赋值c. 强度削弱,代码外提d. 循环展开,循环合并(4) 在程序流图中,我们称具有下述性质的结点序列为一个循环。
a. 它们是非连通的且只有一个入口结点b. 它们是强连通的但有多个入口结点c. 它们是非连通的但有多个入口结点d. 它们是强连通的且只有一个入口结点(5) 关于必经结点的二元关系,下列叙述中不正确的是。
a. 满足自反性b. 满足传递性c. 满足反对称性d. 满足对称性【解答】(1) d (2) c (3) b (4) d (5) d5.2 何谓局部优化、循环优化和全局优化?优化工作在编译的哪个阶段进行?【解答】优化根据涉及的程序范围可分为三种。
(1) 局部优化是指局限于基本块范围内的一种优化。
一个基本块是指程序中一组顺序执行的语句序列(或四元式序列),其中只有一个入口(第一个语句)和一个出口(最后一个语句)。
对于一个给定的程序,我们可以把它划分为一系列的基本块,然后在各个基本块范围内分别进行优化。
通常应用DAG方法进行局部优化。
(2) 循环优化是指对循环中的代码进行优化。
例如,如果在循环语句中某些运算结果不随循环的重复执行而改变,那么该运算可以提到循环外,其运算结果仍保持不变,但程序运行的效率却提高了。
循环优化包括代码外提、强度削弱、删除归纳变量、循环合并和循环展开。
5.3 将下面程序划分为基本块并作出其程序流图。
read(A,B)F=1C=A*AD=B*Bif C<D goto L1E=A*AF=F+1E=E+Fwrite(E)haltL1: E=B*BF=F+2E=E+Fwrite(E)if E >100 goto L2haltL2: F=F-1goto L1【解答】先求出四元式程序中各基本块的入口语句,即程序的第一个语句,或者能由条件语句或无条件转移语句转移到的语句,或者条件转移语句的后继语句。

《编译原理》习题参考答案(六)第五章5.4 为下列类型写类型表达式:(a) 指向实数的指针数组,数组的下标从1到100。
(b) 两位数组(即数组的数组),他的行下标从1到10,列下标从1到20。
(c) 函数,他的定义域是从整数到整数的指针的函数,它的值域是从一个整数和一个字符组成的纪录。
Solution:(a) array ( 1 . . 100 , pointer ( real ) )(b) array ( 1 . . 10 , array ( 1 . . 20 , type ) )(c) ( integer →pointer(integer) )→record((i : integer) * ( c : char )) 假定作为值域的记录类型的两个域分别叫i和c。
5.6 下列文法定以字面常量表的表。
符号的解释和图5.2文法的那些相同,增加了类型list,它表示类型T的元素表。
→ D ; EP→ D ; D | id : TD→ list of T | char | integerTE→ ( L ) | literal | num | id→ E , L | EL写一个类似5.3节中的翻译方案,以确定表达式( E )和表( L )的类型。
P→ D ; ED→ D ; DD→ id : T { addtype ( id.entry , T.type ) }T→ char { T.type := char }T→ integer { T.type := integer }T→ list of T1 { T.type := list ( T1.type ) }E→ literal { E.type := char }E→ num { E.type := integer }E→ id { E.type := lookup ( id.entry ) }E→ ( L ) { E.type := list ( L.type ) }L→E{L.type:=E.type}L→ E , L1 { L.type := if L1.type = E.type then E.typeelse type_error }5.16 对下面的每对表达式,找出最一般的合一代换:(a) α1 → ( α2 →α1 )(b) array ( β1 ) → ( pointer( β1 ) →β2 )(c) γ1 →γ2(d) δ1 →(δ1 →δ2 )Solution:S(α1) = array ( β1 ) S(α2) = pointer ( β1 ) S(β2) = array ( β1 ) (a)(c):S(γ1) = α1 S(γ2) = α2 → α1 (a)(d):S(α1) = S(α2) = S(δ1) = S(δ2) = α (b)(c):S(γ1) = array ( β1 ) S(γ2) = pointer ( β1 ) → β2 (b)(d): 无 (c)(d):S(γ1) = δ1 S(γ2) = δ1 → δ25.17 仿效例5.5,推到下面map 的多态类型: map: ∀ α . ∀ β . ( ( α → β ) * list ( α ) ) → list ( β ) map 的ML 定义是 fun map ( f , l ) = if null ( l ) then nilelse cons ( f ( hd ( l ) ) , map ( f , tl ( l ) ) );在这个函数体中,内部定义的标识符的类型是: null : ∀α . list (α ) → boolean ; nil : ∀α . list (α ) ;cons : ∀α . ( α * list (α ) ) → list (α ) ;hd:∀α . list (α ) →α;∀α . list (α ) → list (α ) ;tl:Solution:行定型断言代换规则(1) f : α( Exp Id )(2) l : β( Exp Id )(3) map : γ( Exp Id )(4) map ( f , l ) : δγ = ( α * β ) →δ(Exp Funcall)(5) null : list (α0) → boolean ( Exp Id ) 和( Type Fresh )(6) null ( l ) : boolean β = list (α0) (Exp Funcall)(7) nil : list (α1) ( Exp Id ) 和( Type Fresh )(8) l : list (α0) 由(2)可得(9) hd : list (α2) →α2( Exp Id ) 和( Type Fresh )(10) hd ( l ) : α0α2 = α0(Exp Funcall)(11) f ( hd ( l ) ) : α3α = α0→α3( Exp Id )(12) f : α0→α3由(1)可得(13) tl : list (α4)→ list (α4) ( Exp Id ) 和( Type Fresh )(14) tl ( l ) : list (α0) α4 = α0(Exp Funcall)(15) map : ((α0→α3)*list(α0))→δ由(3)可得(16) map ( f , tl ( l ) ) : δ(Exp Funcall)(17) cons : α5 * list(α5) → list(α5) ( Exp Id ) 和( Type Fresh ) (18) cons (…) : list (α3) α5 = α3 , δ=list(α3) (Exp Funcall)(19) if : boolean *α6 * α6→α6( Exp Id ) 和( Type Fresh )(20) if (…) : list (α1) α6 = α1 , α3 = α1(Exp Funcall)(21) match : α7 *α7 →α7( Exp Id ) 和( Type Fresh ) (22) match (…) : list (α1) α7 = list (α1) (Exp Funcall)至此有map : ( (α0→α1)*list(α0) )→list(α1)所以map : ∀α . ∀β . ( ( α→β ) * list ( α ) ) → list ( β )5.18 假定类型名link和cell如5.5节那样定义,下面的表达式中,那些结构等价?那些名字等价?(a) link(b) pointer ( cell )(c) pointer ( link )(d) pointer ( record ( ( info : integer ) * ( next : pointer ( cell ) ) ) ) Solution:(a)、(b)、(d)结构等价,无名字等价。
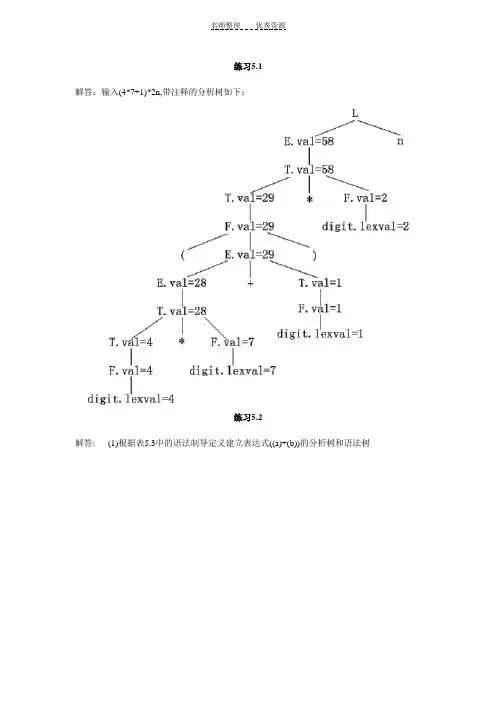
练习5.1解答:输入(4*7+1)*2n,带注释的分析树如下:练习5.2解答: (1)根据表5.3中的语法制导定义建立表达式((a)+(b))的分析树和语法树(2)根据图5.17的翻译模式构造((a)+(b))的分析树和语法树练习5.3解答:设置下面的函数和属性:expr1||expr2:把表达式expr2拼写在表达式expr1后面。
deletep(expr):去掉表达式expr左端的‘(’和右端的‘)’。
E.expr,T.expr,F.expr:属性变量,分别表示E,T,F的表达式。
E.add,T.add,F.add,属性变量,若为true,则表示其表达式中外层有‘+’号,否则无‘+’号。
E.pmark,T.pmark,F.pmark,属性变量,若为true,表示E,T,F的表达式中左端为‘(’,右端是‘)’。
语法制导定义如下:产生式语义规则E -> E1 +T if(T.pmark==true)THEN E.expr=E1.expr||'+'||deletep(T.expr) ELSE E.expr:=E1.expr||'+'||T.expr;E.add:=true;E.pmark:=false;E -> T if(T.pmark==true)THEN E.expr:=deletep(T.expr)ELSE E.expr:=T.expr;E.add:=T.add;E.pmark:=false;T -> T1*F T.expr:=T1.expr||'*'||F.expr; T.add:=false;T.pmark:=false;T -> F T.expr:=F.expr; T.add:=F.add;T.pmark:=F.pmark;F -> (E) if(E.add==false)THEN BEGINF.expr:=E.expr;F.add:=false;F.pmark:=false;ENDELSE BEGINF.expr:='('||E.expr||')';F.add:=true;F.pmark:=true;END;F -> id F.expr:=id.lexval;F.add:=false;F.pmark:=false;练习5.4解答: (1)语法制导定义如下:产生式语义规则E -> E1+T if(E1.type==int) AND (T.type==int) THEN E.type:=intELSE E.type:=real;E -> T E.type:=T.type;T -> num T.type:=int;T -> num.num T.type:=real;(2)设E.pf和T.pf分别是E和T的前缀形式,||是两个字符串的连接,语法制导定义如下:产生式语义规则E -> E1+T if(E1.type==int) AND (T.type==int)THEN E.type:=intELSE BEGINE.type:=real;if(E1.type==int) AND (T.type==real)THEN E1.pf:='inttoreal'||E1.pfELSE if(E1.type==real)AND(T.type==int)THEN T.pf:='inttoreal'||T.pfEND;E.pf:='+'||E1.pf||T.pf;E -> T E.type:=T.type; E.pf:=T.pf;T -> num T.type:=int; T.pf:=int.lexval;T ->num.numT.type:=real; T.pf:=real.lexval;练习5.5解答: (1)用综合属性决定s.val的语法制导定义:产生式语义规则S -> L S.val:=L.val;S ->L1.L2S.val:=L1.val+L2.val*L2.p;L -> B L.val:=B.val; L.p:=2-1;L -> L1B L.val:=L1.val*2+B.val; L.p:=L.p*2-1;B -> 0 B.val:=0;B -> 1 B.val:=1;注:L.p表示恢复L.val的因子。
第五章自顶向下语法分析方法1.对文法G[S]S→a|∧|(T)T→T,S|S(1)给出(a,(a,a))和(((a,a),∧,(a)),a)的最左推导。
(2)对文法G,进行改写,然后对每个非终结符写出不带回溯的递归子程序。
(3)经改写后的文法是否是LL(1)的?给出它的预测分析表。
(4)给出输入串(a,a)#的分析过程,并说明该串是否为G的句子。
解:(1) (a,(a,a))的最左推导为S→(T)→(T,S)→(S,S)→(a,(T))→(a,(T,S))→(a,(S,a))→(a,(a,a))(((a,a),∧,(a)),a)的最左推导为S→(T)→(T,S)→(S,a)→((T),a)→((T,S),a)→((T,S,S),a)→((S,∧,(T)),a)→(((T),∧,(S)),a) →(((T,S),∧,(a)),a)→(((S,a),∧,(a)),a)→(((a,a),∧,(a)),a)(2)由于有T→T,S的产生式,所以消除该产生式的左递归,增中一个非终结符U有新的文法G/[S]:S→a|∧|(T)T→SUU→,SU|ε分析子程序的构造方法对满足条件的文法按如下方法构造相应的语法分析子程序。
(1) 对于每个非终结号U,编写一个相应的子程序P(U);(2) 对于规则U::=x1|x2|..|xn,有一个关于U的子程序P(U),P(U)按如下方法构造:IF CH IN FIRST(x1) THEN P(x1)ELSE IF CH IN FIRST(x2) THEN P(x2)ELSE ......IF CH IN FIRST(xn) THEN P(xn)ELSE ERROR其中,CH存放当前的输入符号,是一个全程变量;ERROR是一段处理出错信息的程序;P(xj)为相应的子程序。
(3) 对于符号串x=y1y2...yn;p(x)的含义为:BEGINP(y1);P(y2);...P(yn);END如果yi是非终结符,则P(yi)代表调用处理yi的子程序;如果yi是终结符,则P(yi)为形如下述语句的一段子程序IF CH=yi THEN READ(CH) ELSE ERROR即如果当前文法中的符号与输入符号匹配,则继续读入下一个待输入符号到CH中,否则表明出错。
Lw.《编译原理》课后习题答案第一章第 1 章引论第 1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第 2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
盛威网()专业的计算机学习网站1《编译原理》课后习题答案第一章目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。