投影法分割字符 网上找到的
- 格式:doc
- 大小:24.50 KB
- 文档页数:3

Python+opencv实现图⽚⽂字的分割的⽅法⽰例实现步骤:1、通过⽔平投影对图形进⾏⽔平分割,获取每⼀⾏的图像;2、通过垂直投影对分割的每⼀⾏图像进⾏垂直分割,最终确定每⼀个字符的坐标位置,分割出每⼀个字符;先简单介绍⼀下投影法:分别在⽔平和垂直⽅向对预处理(⼆值化)的图像某⼀种像素进⾏统计,对于⼆值化图像⾮⿊即⽩,我们通过对其中的⽩点或者⿊点进⾏统计,根据统计结果就可以判断出每⼀⾏的上下边界以及每⼀列的左右边界,从⽽实现分割的⽬的。
下⾯通过Python+opencv来实现该功能⾸先来实现⽔平投影:import cv2import numpy as np'''⽔平投影'''def getHProjection(image):hProjection = np.zeros(image.shape,np.uint8)#图像⾼与宽(h,w)=image.shape#长度与图像⾼度⼀致的数组h_ = [0]*h#循环统计每⼀⾏⽩⾊像素的个数for y in range(h):for x in range(w):if image[y,x] == 255:h_[y]+=1#绘制⽔平投影图像for y in range(h):for x in range(h_[y]):hProjection[y,x] = 255cv2.imshow('hProjection2',hProjection)return h_if __name__ == "__main__":#读⼊原始图像origineImage = cv2.imread('test.jpg')# 图像灰度化#image = cv2.imread('test.jpg',0)image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)cv2.imshow('gray',image)# 将图⽚⼆值化retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)cv2.imshow('binary',img)#⽔平投影H = getHProjection(img)通过上⾯的⽔平投影,根据其⽩⾊⼩⼭峰的起始位置就可以界定出每⼀⾏的起始位置,从⽽把每⼀⾏分割出来。

python验证码识别教程之利⽤投影法、连通域法分割图⽚前⾔今天这篇⽂章主要记录⼀下如何切分验证码,⽤到的主要库就是Pillow和Linux下的图像处理⼯具GIMP。
⾸先假设⼀个固定位置和宽度、⽆粘连、⽆⼲扰的例⼦学习⼀下如何使⽤Pillow来切割图⽚。
使⽤GIMP打开图⽚后,按加号放⼤图⽚,然后点击View->Show Grid来显⽰⽹格线:其中,每个正⽅形边长为10像素,所以数字1切割坐标为左20、上20、右40、下70。
以此类推可以知道剩下3个数字的切割位置。
代码如下:from PIL import Imagep = Image.open("1.png")# 注意位置顺序为左、上、右、下cuts = [(20,20,40,70),(60,20,90,70),(100,10,130,60),(140,20,170,50)]for i,n in enumerate(cuts,1):temp = p.crop(n) # 调⽤crop函数进⾏切割temp.save("cut%s.png" % i)切割后得到4张图⽚:那么,如果字符位置不固定怎么办呢?现在假设⼀种随机位置宽度、⽆粘连、⽆⼲扰线的情况。
第⼀种⽅法,也是最简单的⽅法叫做”投影法”。
原理就是将⼆值化后的图⽚在竖直⽅向进⾏投影,根据投影后的极值来判断分割边界。
这⾥我依然使⽤上⾯的验证码图⽚来进⾏演⽰:def vertical(img):"""传⼊⼆值化后的图⽚进⾏垂直投影"""pixdata = img.load()w,h = img.sizever_list = []# 开始投影for x in range(w):black = 0for y in range(h):if pixdata[x,y] == 0:black += 1ver_list.append(black)# 判断边界l,r = 0,0flag = Falsecuts = []for i,count in enumerate(ver_list):# 阈值这⾥为0if flag is False and count > 0:l = iflag = Trueif flag and count == 0:r = i-1flag = Falsecuts.append((l,r))return cutsp = Image.open('1.png')b_img = binarizing(p,200)v = vertical(b_img)通过vertical函数我们就得到了⼀个包含所有⿊⾊像素在X轴上投影后左右边界的位置。



投影分解法
投影分解法是一种常用于矩阵分解的方法,在数据分析和机器学习中经常被应用。
它的基本思想是将原始矩阵分解为两个或多个较低维度的矩阵的乘积,从而减少数据的维度,并提取出其中的主成分或潜在因子。
投影分解法主要有两种:主成分分析(PCA)和因子分析(FA)。
主成分分析(PCA)是一种无监督学习的方法,用于寻找数据中最重要的特征。
它通过找到数据中具有最大方差的线性组合,将原始数据投影到这些主成分上。
这样可以减少数据的维度,并保留主要信息。
通过PCA,可以对数据进行降维、可视化、去噪等操作。
因子分析(FA)是一种用于找到观测变量和潜在变量之间关
系的方法。
它假设观测变量由少数几个潜在因子共同决定,并尝试找到这些潜在因子的线性组合。
通过因子分析,可以了解观测变量之间的相关性、发现隐藏的因素、构建变量的新表示等。
这两种方法在实际应用中经常同时使用,以便更全面地理解数据,并提取出最有意义的特征。

结合垂直投影法与固定边界分割的车牌字符分割算法(附源码和详细解析)上⼀篇博⽂简单有效的车牌定位算法(附源码和详细解析),详细介绍了数学形态学处理车牌粗定位与蓝⾊像素统计、⾏列扫描的车牌精确定位算法。
没有看的朋友可以先看上⼀篇博⽂。
这次,在牌照字符的分割上,我结合了⽬前使⽤最多的投影法和车牌固定边界的多阈值分割算法。
它的⼤致实现过程如下:第⼀步先对上⼀节粗定位完牌照的只有⿊⽩两⾊的图像bg2实施伪彩⾊标记。
第⼆步获取标记区域各连通块的尺⼨参数,⽤作下⼀步遍历的索引。
第三步投影得直⽅图,取⼀个分割阈值,划分出背景和字符的范围,也就是在直⽅图histrow(histcol)中区分⾕底点和上升点。
第四步分析峰⾕,得到例如最⼤峰中⼼距等参数。
最后⼀步,根据上⼀步求得的参数分割字符。
具体分割流程图如下图:图5-1 字符分割流程图⼀、车牌区域彩⾊标记与特征提取 对粗定位车牌后的⼆值图像作连通区域4邻域的伪彩⾊标记的⽬的是为了⽅便计算出车牌区域的⾯积、宽⾼度以及车牌框架的⼤⼩、区域开始和结束的⾏列位置等区域特征参数,是为后续的车牌投影分析操作作预准备。
在这⼀步骤中,⾸先以4领域⼤⼩为模块对⼆值图像作区域标记,给每块连通区域块标记上序数,获取图像中连通区域的块数和图像矩阵L,初步计算出各连通区域的框架⼤⼩,然后再根据车牌的先验知识设置亮度⾼度的合理阈值筛选出真正车牌区域的连通域,记录下该连通域的序数,最后对车牌区域块作区域特征提取,获取车牌的框架⼤⼩、宽⾼度、宽⾼⽐例以及开始位置点的⾏、列数等参数。
在MATLAB中对车牌号码为粤A6ZC93和粤AC609Z两车辆的车牌粗定位⼆值图像作伪彩⾊标记效果如下图:(a)粤A6ZC93 (b)粤AC609Z图5-2 区域标记与特征参数提取⼆、车牌预处理(1) 基于Radon变换的倾斜校正 从车体侧⾯拍摄的车辆图像中提取出来的牌照会出现⾓度的倾斜,为了后续操作的⽅便,需要进⾏⾓度的校正。

字符分割算法
字符分割算法,是指将一个字符串按照一定的规则分割成若干个子串的过程。
在计算机科学中,字符分割算法被广泛应用于文本处理、信息抽取、自然语言处理等领域。
常见的字符分割算法包括:
1. 基于正则表达式的分割算法:利用正则表达式匹配字符串中的特定模式,并将其分割成子串。
2. 基于空格、标点符号等分隔符的分割算法:将字符串按照空格、标点符号等特定符号进行分割。
3. 基于最大匹配的分割算法:将一个字符串按照最大匹配的原则进行分割,即尽可能地匹配长的子串。
4. 基于最小编辑距离的分割算法:在字符串分割的过程中,根据最小编辑距离的原则进行拆分,使得被拆分出的子串之间的编辑距离最小。
以上算法均有其优缺点,需要根据具体应用场景进行选择。
需要注意的是,在实际应用中,字符分割算法常常需要与其他算法相结合,才能更好地完成任务。
- 1 -。

垂直投影法切割字符原理字符切割是计算机视觉领域的一个重要研究方向。
在文字识别、图像处理和人工智能等领域,字符切割技术被广泛应用。
其中,垂直投影法是一种常用的字符切割方法。
本文将介绍垂直投影法的原理和应用。
一、垂直投影法原理垂直投影法是一种基于像素值分析的字符切割方法。
其基本原理是通过统计每一列像素点的数量来确定字符的边界位置。
具体步骤如下:1. 图像预处理:将彩色图像转化为灰度图像并进行二值化处理,使字符区域变为黑色,背景为白色。
2. 统计像素点数量:对二值化后的图像,遍历每一列像素点,统计黑色像素点的数量。
3. 判断字符边界:根据每一列像素点的数量,可以确定字符的边界位置。
当某一列的黑色像素点数量大于阈值时,可以判断为字符的边界。
4. 切割字符:根据字符的边界位置,将图像进行切割,得到单个字符的图像。
二、垂直投影法的应用垂直投影法广泛应用于文字识别、验证码识别、车牌识别等领域。
下面以文字识别为例,介绍垂直投影法在实际应用中的具体过程。
1. 预处理:对待识别的文字图像进行预处理,包括灰度化、二值化等操作,使文字区域与背景区域相对明显。
2. 垂直投影:在预处理后的图像上,进行垂直投影,统计每一列像素点的数量。
3. 字符切割:根据垂直投影的结果,确定字符的边界位置,进行字符切割。
可以通过设定阈值来控制字符的切割精度。
4. 特征提取:对切割后的字符图像进行特征提取,包括形状、纹理、边缘等特征。
5. 字符识别:将提取的特征输入到字符识别模型中,进行字符识别。
三、垂直投影法的优缺点垂直投影法作为一种简单直观的字符切割方法,具有以下优点:1. 实现简单:垂直投影法的原理简单,易于实现。
2. 效果较好:对于大多数字符切割场景,垂直投影法能够得到较好的切割效果。
3. 可调节性强:通过设定阈值,可以控制字符切割的精度和召回率。
然而,垂直投影法也存在一些缺点:1. 对背景干扰敏感:当字符与背景颜色相似时,垂直投影法容易受到背景干扰,导致切割不准确。

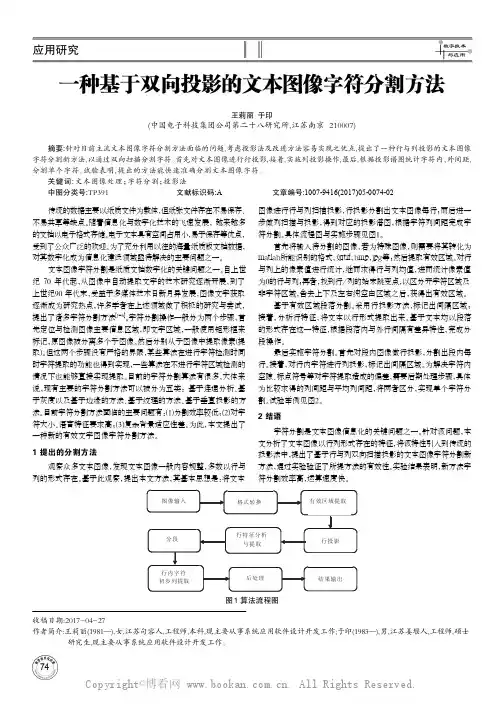

基于投影法的文档图像分割算法文档图像分割是文档处理的重要环节,有助于后续的识别、分析和利用。
投影法是一种常用的文档图像分割方法,它通过将文档图像进行投影,根据投影值的变化来进行图像分割。
本文将详细介绍基于投影法的文档图像分割算法,包括算法流程、细节、实验结果及分析。
基于投影法的文档图像分割算法主要包括以下步骤:预处理:对输入的文档图像进行预处理,包括去噪、灰度化、二值化等操作,以便于后续处理。
投影:将预处理后的图像进行水平或垂直投影,计算投影值。
分割:根据投影值的变化,将图像分割成不同的区域或对象。
数据预处理:首先对输入的文档图像进行去噪、灰度化、二值化等操作,以减小图像噪声对分割效果的影响,并使图像只包含黑白两种颜色,以便于后续处理。
特征提取:通过对图像进行水平或垂直投影,计算每个像素点的投影值,并将投影值作为图像的一个特征。
模型训练:利用训练集进行模型训练,根据训练集的特征和标签来训练分类器,用于后续的图像分割。
分割:根据训练好的分类器,对每个像素点进行分类,将其划分到相应的区域或对象中,最终得到分割后的图像。
为了验证基于投影法的文档图像分割算法的可行性和效果,我们进行了一系列实验。
实验结果表明,该算法在文档图像分割方面具有较好的效果,能够准确地将文档图像中的不同区域或对象分割出来。
同时,该算法也具有较快的运算速度,可以满足实际应用中的需求。
通过对实验结果进行分析,我们发现基于投影法的文档图像分割算法具有以下优点:简单易行:该算法流程简单明了,易于实现,不需要过多的参数调整和优化。
运算效率高:该算法的时间复杂度较低,运算速度较快,能够满足实际应用中的需求。
适用范围广:该算法适用于不同类型的文档图像,如文字、表格、图片等,具有较广泛的适用范围。
本文详细介绍了基于投影法的文档图像分割算法,包括算法流程、细节、实验结果及分析。
实验结果表明,该算法在文档图像分割方面具有较好的效果和运算效率,能够准确地将文档图像中的不同区域或对象分割出来,适用于不同类型的文档图像。
现代计算机(总第三一三期0引言本文利用车牌精确定位的结果,运用像素水平投影与竖直投影的方法,结合车牌字符的先验信息,在不需要设计特征函数与判决函数的条件下,就可以准确地对车牌字符进行切割。
同时,针对某些汉字如川、浙、湘、沪、津及皖、桂等易被错误分割或漏割的情况,对汉字左右边界的起始位置进行标记,利用此标记获得该汉字的原始灰度图像,对其单独进行分割及二值化,避免汉字笔画退化为噪声。
1车牌的水平投影从图1可以看出,在车牌区域中存在边框及铆钉的存在,影响车牌字符的分割,因此,在字符分割前需要消除边框及铆钉等噪声对车牌字符分割的影响。
如图2所示,由于已经对车牌区域进行了位置矫正,使得车牌区域基本保持矩形形状,因此,可以利用车牌区域像素水平投影的方法消除车牌边框及铆钉。
具体算法如下:图1车牌区域(1)对车牌区域作竖直像素差分,以消除背景的影响,如图3所示。
此步骤是消除车牌区域边框及铆钉等噪声的关键。
图2像素水平投影图3像素竖直差分(2)对车牌区域中的各点作像素水平投影pixel -Sum[i],I 为车牌区域的宽度。
(3)从开始搜索,当pixelSum[i]12时,标志flag=0,当遇到pixelSum [i]>12,记录该i 值作为结束位置end ,如果此时flag=0,那么并且记录首个使得pixel -Sum[i]>12的i 值作为开始位置start ,同时设置标志flag=1,当时,记录此时的开始位置start 与结束位置end ,作为字符的竖直区域,否则继续搜索。
图4去除车牌的边框及铆钉结果去除车牌的边框及铆钉结果如图4所示,说明经过该算法处理后,能够有效地消除车牌边框及铆钉等,,,,,,基于投影的车牌字符分割方法黄文杰(淮阴工学院交通工程系,淮安223003)摘要:关键词:车牌识别;字符分割;投影收稿日期:2009-06-22修稿日期:2009-07-26作者简介:黄文杰(1977-),男,研究方向为智能交通、模式识别、图像重构运用像素水平投影与竖直投影的方法,结合车牌字符的先验信息可以准确地对车牌字符进行切割。
投影运算符
投影运算符是一种使研究变得容易的数学工具。
投影运算符可以用来提取数据,以及帮助逐步分析复杂的模型。
这些模型称为投影。
投影运算符是一种要求积极捕捉和整理大量数据的有效工具,所有的素材均可
被精细化的聚类,以便可以进行深入的分析。
这可以涉及到各种各样的方法,从可视化到统计分析,涵盖了整个投影方法。
投影运算符可被用来建立从不同数据源收集或提取到的总结性数据集,这些数
据集可以用来对具体因素进行研究,以便可以建立有关该因素的准确和全面的认知模型。
同时,这些模型也可用来反映投影运算符能够提取信息的结果。
当使用投影运算符进行数据收集时,要确保具有良好的效率,以便可以在用最
少的时间内获得有用的信息。
为此,有关数据收集的过程的每一环节都要由专业的技术人员进行控制,以便可以获得有意义的数据。
投影运算符也是分析数据的有效工具,它可以用来研究一系列问题,从而可以
建立精确的是模型。
投影运算符相较于其他分析工具而言,拥有更多的灵活性,因为它可以帮助研究人员建立更真实的模型。
此外,投影运算符也可以用来测量不同投影模型之间的相似性,并利用这些数据来构建更精确的表达,提高研究效果。
总之,投影运算符可以说是一种十分实用的工具,它可以帮助研究者从各种复
杂的模型中提取到有用信息,有效分析各种数据,从而实现精确的研究。
由于它能够快速提取、整理信息,将投影运算符用于研究也是十分明智的选择。
Python实现投影法分割图像⽰例(⼆)在上篇博客中,我们已经实现了⽔平投影和垂直投影图的绘制。
接下来,我们可以根据获得的投影数据进⾏图像的分割,该法⽤于⽂本分割较多,所以此处依然以上次的图为例。
先把上次的两幅图搬过来,⽅便讲解。
上⾯两图分别从垂直和⽔平⽅向描述了图像中⽂本的分布。
我们想象⼀下,将两幅图重叠起来(当然这⾥⽐例要调整下),那么我们就能得到四个重叠的⽩块,⽽这些⽩块所处的位置正是原图中⽂本的位置。
所以接下来的任务就是,找出这些⽩块的坐标,此处⽩块近似矩形,所以我们要求矩形的四个坐标。
下⾯看代码。
#根据⽔平投影值选定⾏分割点inline = 1start = 0j = 0for i in range(0,height):if inline == 1 and z[i] >= 150 : #从空⽩区进⼊⽂字区start = i #记录起始⾏分割点print iinline = 0elif (i - start > 3) and z[i] < 150 and inline == 0 : #从⽂字区进⼊空⽩区inline = 1hfg[j][0] = start - 2 #保存⾏分割位置hfg[j][1] = i + 2j = j + 1确定⾏分割点的原理就是判断每⼀⾏的像素点数是否⾜够。
我们可以从⽔平投影图中看出,⽩块是有⽂字的地⽅(原图是⿊字⽩底,只是画投影图时选⽤⽩块⿊底),即前⾯⼏⾏,灰度值为0的点的个数N很少,所以当遇到⽂字区时,N会很⼤,根据这⼀点,我们确定进⼊⽂字区的坐标(A1,B1)。
然后,当从⽂字区出来时,N⼜变的很⼩,我们再记下它的坐标(A1,B2)。
同理,我们可以确定列分割点。
incol = 1start1 = 0j1 = 0z1 = hfg[p][0]z2 = hfg[p][1]for i1 in range(0,width):if incol == 1 and v[i1] >= 20 : #从空⽩区进⼊⽂字区start1 = i1 #记录起始列分割点incol = 0elif (i1 - start1 > 3) and v[i1] < 20 and incol == 0 : #从⽂字区进⼊空⽩区incol = 1lfg[j1][0] = start1 - 2 #保存列分割位置lfg[j1][1] = i1 + 2l1 = start1 - 2l2 = i1 + 2j1 = j1 + 1最后根据矩形的坐标将⽂本在图中框出来。
%计算车牌水平投影,并对水平投影进行峰谷分析
histcoll=sum(sbw2);
histrow=sum(sbw2');
figure;subplot(2,1,1);bar(histcoll);title('垂直投影(含边框)');
subplot(2,1,2),bar(histrow);title('水平投影(含边框)');
figure;subplot(2,1,1);bar(histrow);title('水平投影(含边框)');
subplot(2,1,2);imshow(sbw2);title('车牌二值子图');
%对水平投影进行投影分析
meanrow=mean(histrow);
minrow=min(histrow);
levelrow=(meanrow+minrow)/2;
count1=0;
l=1
for k=1:hight
if histrow(k)<=levelrow
count1=count1+1;
else
if countl>=l
markrow(l)=k; %上升点
markrow1(l)=countl; %谷宽度(下降点至下一个上升点)l=l+1;
end
count1=0;
end
end
markrow2=diff(markrow); %峰距离(上升点至下一个上升点)
[ml,nl]=size(markrow2);
nl=nl+1;
markrow(l)=hight;
markrow(l)=count1;
markrow2(nl)=markrow(l)-markrow(l-1);
l=0;
for k=1:nl
markrow3(k)=markrow(k+1)-markrow1(k+1); %下降点
markrow4(k)=markrow3(k)-markrow(k); %峰宽度(上升点至下降点)markrow5(k)=markrow3(k)-double(unit16(markrow4(k)/2)); %峰中心位置end
%去水平(上下)边框,获取字符高度
maxhight=max(markrow2);
findc=find(markrow2==maxhight);
rowtop=markrow(findc);
rowbot=markrow(findc+1)-markrow1(findc+1);
sbw2=sbw(rowtop:rowbot,:); %子图为(rowbot-rowtop+1)行
maxhight=rowbot-towtop+1; %字符高度(rowbot-rowtop+1)
%计算车牌垂直投影,去掉车牌垂直边框,获取车牌和字符平均宽度
histcol=sum(A); %计算垂直投影
figure,subplot(2,1,1),bar(histco l);title(‘垂直投影(去水平边框后)‘);
subplot(2,1,2),imshow(sbw2);
title([‘车牌字符高度:‘,int2str(maxhight)],’Color’,’r’)
meancol=mean(histcol);
mincol=min(histcol);
levelcol=(meancol+mincol)/4;
countl=0;
l=1;
for k=1:width
if histcol(k)<=levelcol
countl=countl+1;
else
if countl>=1
markcol(l)=k; %字符上升点
markcol1(l)=countl; %谷宽度(下降点至下一个上升点)
l=l+1;
end
count1=0;
end
end
markcol2=diff(markcol); %字符距离(上升点至下一个上升点)
[ml,nl]=size(markcol2);
nl=nl+1;
markcol(1)=width;
markcol1(1)=count1;
markcol2(nl)=markcol(1)-markcol(l-1);
%计算车牌上每个字符中心位置,计算最大字符宽度maxwidth
l=0;
for k=1:nl
markcol3(k)=markcol(k+1)-markcol1(k+1); %字符下降点
markcol4(k)=markcol3(k)-markcol(k); %字符宽度(上升点至下降点)
markcol5(k)=markcol3(k)-double(unit16(markcol4(k)/2)); %字符中心位置
end
markcol6=diff(markcol5); %字符中心距离(字符中心点至下一个字符中心点)maxs=max(markcol6); %查找最大值,即为第二个字符与第三个字符中心距离findmax=find(markcol6==maxs);
markcol6(findmax)=0; %将最大值清0
maxwidth=max(markcol6); %查找最大值,即为最大字符宽度
%提取分割字符,并变换为40*20的标准子图
l=1;
[m2,n2]=size(subcol);
figure;
for k=findmax-1:findmax+5
cleft=markcol5(k)-maxwidth/2;
cright=markcol5(k)+maxwidth/2-2;
SegGray=subcol(rowtop:rowbot,cleft:cright);
SegBw1=sbw(rowtop:rowbot,cleft:cright);
SegBw2=imresize(SegBw1,[40 20]); %变换为32行*16列标准子图Subplot(2,nl,1),imshow(SegGray);
if l==7
title([‘车牌字符宽度:‘,int2str(maxwidth)],’Color’,’r’);
end
subplot(2,nl,nl+1),imshow(SegBw2);
l=l+1;
end。