第9章 Rapidminer-K-Means 聚类、辨别分析V1
- 格式:doc
- 大小:361.50 KB
- 文档页数:16
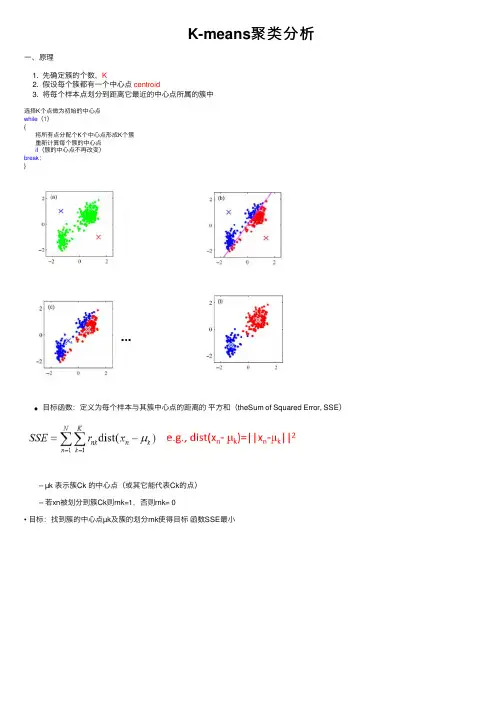
K-means聚类分析⼀、原理1. 先确定簇的个数,K2. 假设每个簇都有⼀个中⼼点centroid3. 将每个样本点划分到距离它最近的中⼼点所属的簇中选择K个点做为初始的中⼼点while(1){将所有点分配个K个中⼼点形成K个簇重新计算每个簇的中⼼点if(簇的中⼼点不再改变)break;}⽬标函数:定义为每个样本与其簇中⼼点的距离的平⽅和(theSum of Squared Error, SSE) – µk 表⽰簇Ck 的中⼼点(或其它能代表Ck的点) – 若xn被划分到簇Ck则rnk=1,否则rnk= 0• ⽬标:找到簇的中⼼点µk及簇的划分rnk使得⽬标函数SSE最⼩初始中⼼点通常是随机选取的(收敛后得到的是局部最优解)不同的中⼼点会对聚类结果产⽣不同的影响:1、2、此时你⼀定会有疑问:如何选取"较好的"初始中⼼点?1. 凭经验选取代表点2. 将全部数据随机分成c类,计算每类重⼼座位初始点3. ⽤“密度”法选择代表点4. 将样本随机排序后使⽤前c个点作为代表点5. 从(c-1)聚类划分问题的解中产⽣c聚类划分问题的代表点 结论:若对数据不够了解,可以直接选择2和4⽅法需要预先确定K Q:如何选取K SSE⼀般随着K的增⼤⽽减⼩A:emmm你多尝试⼏次吧,看看哪个合适。
斜率改变最⼤的点⽐如k=2总结:简单的来说,K-means就是假设有K个簇,然后通过上⾯找初始点的⽅法,找到K个初始点,将所有的数据分为K个簇,然后⼀直迭代,在所有的簇⾥⾯找到找到簇的中⼼点µk及簇的划分rnk使得⽬标函数SSE最⼩或者中⼼点不变之后,迭代完成。
成功把数据分为K类。
预告:下⼀篇博⽂讲K-means代码实现。

一、概述k-means聚类算法是一种常用的聚类分析方法,广泛应用于数据挖掘和机器学习领域。
该算法通过迭代的方式将n个数据点分为k个簇,使得同一簇内的点相似度较高,不同簇之间的相似度较低。
本文旨在对k-means聚类算法的原理和过程进行详细介绍,以便读者深入了解该算法的运作机制。
二、k-means聚类算法原理1. 初始质心选择在k-means算法中,首先需要选择k个初始质心作为每个簇的代表点。
初始质心可以通过随机选取数据集中的k个点来确定,也可以使用其他方法如K-means++来选择初始质心。
2. 数据点分配一旦初始质心确定,算法将每个数据点分配到与其最近的质心所代表的簇中。
这一过程可以通过计算每个数据点与各个质心之间的距离,然后将数据点分配到最近的质心所属的簇。
3. 更新质心在数据点分配完成后,每个簇的质心需要重新计算以反映簇中所有数据点的均值位置。
新的质心位置通常是簇中所有数据点的平均值,这一过程反复进行直到质心的位置不再发生变化。
4. 簇内数据点相似度算法的优化目标是使同一簇内的数据点相似度较高,也就是使同一簇内的数据点与其质心的距离最小化。
更新质心的过程是为了最小化簇内数据点与质心之间的距离。
5. 算法收敛k-means算法的终止条件通常是簇内数据点的质心位置不再发生改变,或者达到预设的迭代次数。
三、k-means聚类算法过程k-means聚类算法过程可以概括为以下几个步骤:1. 初始化:根据给定的参数k,随机选择k个数据点作为初始质心。
2. 数据点分配:根据每个数据点与初始质心的距离,将数据点分配到最近的质心所代表的簇中。
3. 更新质心:重新计算每个簇的质心位置,以反映簇中所有数据点的均值位置。
4. 重复步骤2和步骤3,直到满足终止条件。
通常情况下,终止条件是质心位置不再发生变化,或者达到预设的迭代次数。
四、k-means聚类算法的应用k-means聚类算法广泛用于各种领域,包括但不限于:1. 客户分裙分析:通过对客户数据进行聚类分析,可以识别出具有相似特征的客户裙体,为市场营销活动和客户服务提供决策支持。

k-means聚类的基本步骤
嘿,朋友们!今天咱来聊聊 k-means 聚类的那些事儿哈。
你想啊,这k-means 聚类就好比是给一堆乱七八糟的东西分类整理。
首先呢,咱得确定要分成几类,这就好比你要决定把你的玩具分成几
堆一样。
这可不是随便定的哦,得根据实际情况好好琢磨琢磨。
然后呢,就像给每个东西找个家一样,随机选几个点作为初始的聚
类中心。
这就好像你先随便找几个地方放那几堆玩具。
接下来,就是把每个数据点都归到离它最近的那个聚类中心所属的
类里。
这就好像你把每个玩具都放到离它最近的那堆里去。
哎呀,是
不是挺形象的呀!
这还不算完呢,等都分好类了,还得重新计算每个类的中心。
这就
好比你重新调整一下那几堆玩具的位置,让它们更整齐。
然后再重复上面的过程,一直到这些聚类中心不再变化啦。
这就像
你反复调整玩具堆,直到你觉得满意为止。
你说这 k-means 聚类是不是挺有趣的呀?就像是在玩一个整理的游戏。
而且它用处可大了去了呢!比如说在数据分析里,能帮我们发现
一些隐藏的模式和规律。
你想想看,如果没有k-means 聚类,那面对一大堆杂乱无章的数据,我们得多头疼呀!但有了它,就好像有了一双神奇的手,能把这些乱
麻一样的数据整理得井井有条。
所以说呀,学会 k-means 聚类的基本步骤可太重要啦!咱可不能小
瞧了它,得好好研究研究,把它用在该用的地方,让它发挥出最大的
作用呀!这难道不是很有意义的事情吗?。

机器学习——KMeans聚类,KMeans原理,参数详解0.聚类 聚类就是对⼤量的未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较⼤⽽类别间的数据相似度较⼩,聚类属于⽆监督的学习⽅法。
1.内在相似性的度量 聚类是根据数据的内在的相似性进⾏的,那么我们应该怎么定义数据的内在的相似性呢?⽐较常见的⽅法是根据数据的相似度或者距离来定义的,⽐较常见的有:闵可夫斯基距离/欧式距离 上述距离公式中,当p=2时,就是欧式距离,当p=1时,就是绝对值的和,当p=正⽆穷时,这个距离变成了维度差最⼤的那个值。
杰卡德相似系数 ⼀般是度量集合之间的相似性。
余弦相似度Pearson相似系数 对于n维向量的夹⾓,根据余弦定理,可到: ⼜由相关系数的计算公式,可得: 不难发现,相关系数就是将x,y坐标向量各⾃平移到原点后的夹⾓余弦。
相对熵(K-L距离)2.聚类的基本思想 1.给定⼀个有N个对象的数据集,构造数据的K个簇,k<=n,并且满⾜下列条件: 每⼀个簇⾄少包含⼀个对象。
每⼀个对象属于且仅属于⼀个簇。
将满⾜上述条件的K个簇称作⼀个合理划分。
2.基本思想:对于给定的类别K,⾸先给定初始的划分,通过迭代改变样本和簇的⾪属关系,使得每⼀次改进之后的划分⽅案都较前⼀次好。
3.K-Means算法 K-means算法,也被称为K-平均或K-均值,是⼀种⼴泛使⽤的聚类算法,或者成为其他聚类算法的基础。
假定输⼊样本为S=x1, x2, ......, xm,则算法步骤为: 选择初始的k个类别中⼼,u1, u2, ......, uk。
对于每个样本的xi,将其中标记为距离类别中⼼最近的类别,即: 将每个类别中⼼更新为⾪属该类别的所有样本的均值。
重复后⾯的两步,直到类别中⼼变化⼩于某阈值。
终⽌条件: 迭代次数,簇中⼼变化率,最⼩平⽅误差MSE。
4.K-Means的公式化解释 记K个簇中⼼为u1,u2,......,uk,每个簇的样本数⽬为N1,N2,......,Nk。

k-means聚类方法的原理和步骤k-means聚类方法是一种常用的数据聚类算法,它可以将一组数据划分成若干个类别,使得同一类别内的数据相似度较高,不同类别之间的数据相似度较低。
本文将介绍k-means聚类方法的原理和步骤。
k-means聚类方法基于数据的距离度量,具体而言,它通过最小化各个数据点与所属类别中心点之间的距离来达到聚类的目的。
其基本原理可以概括为以下几点:-定义类别中心点:在聚类开始前,需要预先设定聚类的类别数量k。
根据k的数量,在数据集中随机选取k个点作为初始的类别中心点。
-分配数据点到类别:对于每一个数据点,计算其与各个类别中心点之间的距离,并将其分配到距离最近的类别中。
-更新类别中心点:当所有数据点分配完毕后,重新计算每个类别中的数据点的均值,以此获得新的类别中心点。
-重复分配和更新过程:将新的类别中心点作为参考,重新分配数据点和更新类别中心点,直到类别中心点不再变化或达到预设的迭代次数。
按照上述原理,k-means聚类方法的步骤可以分为以下几个阶段:-第一步,随机选择k个类别中心点。
-第二步,计算每个数据点与各个类别中心点之间的距离,并将其分配到距离最近的类别中。
-第三步,重新计算每个类别中数据点的均值,以此获得新的类别中心点。
-第四步,判断新的类别中心点是否与上一次迭代的中心点相同,如果相同,则结束聚类过程;如果不同,则更新类别中心点,返回第二步继续迭代。
-第五步,输出最终的类别划分结果。
需要注意的是,k-means聚类方法对聚类的初始中心点敏感,不同的初始点可能会导致不同的聚类结果。
为了避免陷入局部最优解,通常采用多次随机初始化的方式进行聚类,然后选取最好的结果作为最终的聚类划分。
综上所述,k-means聚类方法是一种常用的数据聚类算法,它通过最小化数据点与类别中心点之间的距离来实现聚类。
按照预设的步骤进行迭代,最终得到稳定的聚类结果。
在实际应用中,还可以根据具体问题进行算法的改进和优化,以满足实际需求。


K-means聚类算法1. 概述K-means聚类算法也称k均值聚类算法,是集简单和经典于⼀⾝的基于距离的聚类算法。
它采⽤距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越⼤。
该算法认为类簇是由距离靠近的对象组成的,因此把得到紧凑且独⽴的簇作为最终⽬标。
2. 算法核⼼思想K-means聚类算法是⼀种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中⼼,然后计算每个对象与各个种⼦聚类中⼼之间的距离,把每个对象分配给距离它最近的聚类中⼼。
聚类中⼼以及分配给它们的对象就代表⼀个聚类。
每分配⼀个样本,聚类的聚类中⼼会根据聚类中现有的对象被重新计算。
这个过程将不断重复直到满⾜某个终⽌条件。
终⽌条件可以是没有(或最⼩数⽬)对象被重新分配给不同的聚类,没有(或最⼩数⽬)聚类中⼼再发⽣变化,误差平⽅和局部最⼩。
3. 算法实现步骤1、⾸先确定⼀个k值,即我们希望将数据集经过聚类得到k个集合。
2、从数据集中随机选择k个数据点作为质⼼。
3、对数据集中每⼀个点,计算其与每⼀个质⼼的距离(如欧式距离),离哪个质⼼近,就划分到那个质⼼所属的集合。
4、把所有数据归好集合后,⼀共有k个集合。
然后重新计算每个集合的质⼼。
5、如果新计算出来的质⼼和原来的质⼼之间的距离⼩于某⼀个设置的阈值(表⽰重新计算的质⼼的位置变化不⼤,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终⽌。
6、如果新质⼼和原质⼼距离变化很⼤,需要迭代3~5步骤。
4. 算法步骤图解上图a表达了初始的数据集,假设k=2。
在图b中,我们随机选择了两个k类所对应的类别质⼼,即图中的红⾊质⼼和蓝⾊质⼼,然后分别求样本中所有点到这两个质⼼的距离,并标记每个样本的类别为和该样本距离最⼩的质⼼的类别,如图c所⽰,经过计算样本和红⾊质⼼和蓝⾊质⼼的距离,我们得到了所有样本点的第⼀轮迭代后的类别。
此时我们对我们当前标记为红⾊和蓝⾊的点分别求其新的质⼼,如图d所⽰,新的红⾊质⼼和蓝⾊质⼼的位置已经发⽣了变动。

k-means聚类方法的原理k-means聚类方法是一种常见的无监督学习算法,用于将数据集分成预定数目的簇。
它的目标是通过最小化数据点与其所属簇中心点之间的平方距离之和来确定每个数据点所属的簇。
k-means聚类方法的原理如下:首先,根据设定的簇的数目k,随机选择k个数据点作为初始簇中心。
然后,对于其他所有的数据点,将其与这k个初始簇中心进行距离计算,并将其归类到与之最近的簇中心所属的簇。
接下来,对于每个簇,计算其所有数据点的均值,将该均值作为新的簇中心。
然后,重复以上步骤,直到达到某个停止条件,例如簇中心不再发生变化或达到最大迭代次数。
k-means聚类方法的优点包括简单易实现、计算效率高,适用于大规模数据集;缺点主要是对初始簇中心的选择较为敏感,可能陷入局部最优解,并且对于不规则形状的簇效果较差。
k-means聚类方法的流程可以总结为以下几个步骤:1.初始化簇中心:根据设定的簇的数目k,随机选择k个数据点作为初始簇中心。
2.分配数据点到簇中心:对于其他所有的数据点,计算其与这k个初始簇中心之间的距离,并将其归类到与之最近的簇中心所属的簇。
3.更新簇中心:对于每个簇,计算其所有数据点的均值,将该均值作为新的簇中心。
4.重复步骤2和步骤3,直到达到某个停止条件,例如簇中心不再发生变化或达到最大迭代次数。
5.输出最终的聚类结果。
在k-means聚类方法中,距离的度量通常使用欧氏距离,即数据点之间的直线距离。
但在某些特定的情况下,也可以使用其他距离度量方法,例如曼哈顿距离或闵可夫斯基距离。
k-means聚类方法的性能评估主要有两种方式:内部评价和外部评价。
内部评价是基于数据本身进行评估,例如簇内的紧密度和簇间的分离度;外部评价是将聚类结果与事先给定的真实分类进行比较,例如准确率、召回率和F1分数等。
总结来说,k-means聚类方法是一种常用的无监督学习算法,通过最小化数据点与其所属簇中心点之间的平方距离之和来确定每个数据点所属的簇。

K-means聚类算法是一种常用的无监督学习算法,其作用是将样本集合划分为K个类别,使得相同类别的样本之间的相似度高,不同类别样本之间的相似度低。
K-means算法具有简单高效的特点,在实际应用中被广泛使用。
下面将从算法原理、实现步骤、应用场景等方面对K-means聚类算法进行深入理解。
一、算法原理K-means聚类算法的原理基于距离度量的思想,其主要步骤如下:1.初始化:随机选择K个样本作为初始的聚类中心。
2.分配:计算每个样本点与K个聚类中心的距离,将样本分配到距离最近的聚类中心所对应的类别中。
3.更新:对每个类别,重新计算其样本的均值向量,并作为新的聚类中心。
4.重复分配和更新步骤,直到聚类中心不再发生变化或者达到设定的迭代次数。
二、实现步骤K-means聚类算法的具体实现步骤如下:1.选择K个初始聚类中心,可以随机选择或通过其他方式确定初始值。
2.计算每个样本点与K个聚类中心的距离,并将其划分到与距离最近的聚类中心对应的类别中。
3.更新每个类别的均值向量,作为新的聚类中心。
4.重复进行第2步和第3步,直到聚类中心不再发生变化或者达到设定的迭代次数。
三、算法应用K-means聚类算法在实际应用中有着广泛的应用场景,如:1.图像压缩:利用K-means算法将图像像素点进行聚类,将相似的像素点合并为同一个类别,从而达到图像压缩的效果。
2.市场营销:根据客户的消费行为和偏好,利用K-means算法对客户进行分裙,从而为不同类别的客户提供个性化的营销服务。
3.生物学:利用K-means算法对生物学样本进行分类,识别出不同的基因表达模式或生物特征。
4.文本分类:对文本进行聚类分析,识别出相似的文档集合并进行分类管理。
K-means聚类算法是一种简单而有效的无监督学习算法,其原理和步骤也较为清晰。
在实际应用中,K-means算法可以帮助我们对数据进行有效的聚类分析,发掘数据中的潜在规律和信息。
当然,K-means 算法也有一些局限性,如对初始聚类中心的选择敏感、对异常值敏感等。

kmeans聚类算法总结
kmeans聚类算法是一种常见的无监督机器学习算法,它主要用于将数据分组并将相似的数据点归为同一类别。
下面是kmeans聚类算法的总结:
1. kmeans聚类算法通常需要指定类别数量k,在输入数据分类时会将数据分为k个类别,并且每个类别都有一个代表(即聚类中心)。
2. kmeans聚类算法是一种迭代算法,其主要步骤包括初始化聚类中心、分配数据点到最近的聚类中心、更新聚类中心并重复直到收敛。
3. kmeans聚类算法尝试最小化每个数据点到其所属聚类中心的距离平方和(即SSE),这个过程可以通过最小化聚类中心与每个数据点之间的平方欧几里得距离来实现。
4. kmeans聚类算法对数据分布的假设是数据点可以分为均匀大小的凸形小团,这也导致了其对异常值和噪声敏感。
5. kmeans聚类算法在处理大型数据集时可能会面临时间和内存限制的挑战。
6. kmeans聚类算法可以用于各种应用,如图像分割、市场细分、客户分类和信用评级等。
综上所述,kmeans聚类算法是一种经典的、简单但有效的聚类算法。
它具有易于解释、易于实现等优点,在处理一些相关应用时表现不俗。
但是,它对于数据集的分布假设较为苛刻,对于异常值和噪声敏感,并且处理大型数据集时可能会面临一些挑战。

第9章K-Means 聚类、辨别分析9.1理解聚类分析餐饮企业经常会碰到这样的问题:1)如何通过餐饮客户消费行为的测量,进一步评判餐饮客户的价值和对餐饮客户进行细分,找到有价值的客户群和需关注的客户群2)如何合理对菜品进行分析,以便区分哪些菜品畅销毛利又高,哪些菜品滞销毛利又低餐饮企业遇到的这些问题,可以通过聚类分析解决。
9.1.1常用聚类分析算法与分类不同,聚类分析是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法。
与分类模型需要使用有类标记样本构成的训练数据不同,聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。
聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将他们划分为若干组,划分的原则是组内样本最小化而组间(外部)距离最大化,如错误!未找到引用源。
所示。
图9-1 聚类分析建模原理常用聚类方法见错误!未找到引用源。
表9-1常用聚类方法类别包括的主要算法常用聚类算法见错误!未找到引用源。
2。
表9-2常用聚类分析算法9.1.2K-Means聚类算法K-Means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
1.算法过程1)从N个样本数据中随机选取K个对象作为初始的聚类中心;2)分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中;3)所有对象分配完成后,重新计算K个聚类的中心;4)与前一次计算得到的K个聚类中心比较,如果聚类中心发生变化,转2),否则转5);5)当质心不发生变化时停止并输出聚类结果。
聚类的结果可能依赖于初始聚类中心的随机选择,可能使得结果严重偏离全局最优分类。
实践中,为了得到较好的结果,通常以不同的初始聚类中心,多次运行K-Means算法。
在所有对象分配完成后,重新计算K个聚类的中心时,对于连续数据,聚类中心取该簇的均值,但是当样本的某些属性是分类变量时,均值可能无定义,可以使用K-众数方法。
聚类kmeans算法聚类kmeans算法是一种常用的数据挖掘算法,它利用机器学习技术进行分类,可以有效解决大数据环境中的数据挖掘问题。
这种算法具有较高的精度和准确性,因此被广泛应用于各种环境中。
k-means聚类算法的基本原理是将数据点分成K个聚类,每一个聚类都与聚类中心具有最短的距离,即该聚类中心所形成的簇是所有数据点中距离最近的。
k-means算法可以自动从原始输入数据中挖掘出有价值的信息,是进行数据聚类分析的有力工具。
k-means算法的核心是聚类中心的改变,它将数据分为K个类。
该算法的运行过程包括:(1)确定聚类中心;(2)将数据集分组;(3)求出每个聚类的损失函数;(4)设置停止迭代的条件。
在每一次迭代中,算法根据损失函数更新聚类中心,直到最优聚类中心出现或者聚类中心不再变化,聚类结果即被输出。
由于k-means算法的算法精度依赖于聚类中心的选择,因此先进的变体算法添加了许多改进措施来提高聚类的准确性,也增强了聚类中心的可靠性。
改进的k-means算法还可以避免聚类中心收敛所需时间的过长,从而使大规模数据示例聚类的效率提高。
此外,该算法对超参数的选择和调节提供了更多的灵活性,它可以更好地满足多种类型的实际应用需求。
目前,k-means聚类算法广泛应用于不同领域,如市场营销、推荐系统、影响力分析、社会网络分析、计算机视觉等。
通过使用k-means 算法,可以有效地进行分类,从而提取有价值的信息,提升数据处理的准确性和效率,节省人力成本。
然而,k-means算法也存在一些缺点。
首先,该算法的计算复杂度较高,且依赖于聚类中心的选取,容易出现局部最优解,从而导致聚类精度不高。
其次,由于k-means算法的归纳模型有一定的局限性,因此不能处理无界和多维数据集。
最后,该算法只适用于某些特定的场景,并不能满足所有数据挖掘应用中的要求。
未来,k-means算法仍然将受到更多的关注,未来的研究将继续改进该算法,提升其精度和效率,使之能更好地满足实际应用的要求。
第9章K-Means 聚类、辨别分析9.1理解聚类分析餐饮企业经常会碰到这样的问题:1)如何通过餐饮客户消费行为的测量,进一步评判餐饮客户的价值和对餐饮客户进行细分,找到有价值的客户群和需关注的客户群?2)如何合理对菜品进行分析,以便区分哪些菜品畅销毛利又高,哪些菜品滞销毛利又低?餐饮企业遇到的这些问题,可以通过聚类分析解决。
9.1.1常用聚类分析算法与分类不同,聚类分析是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法。
与分类模型需要使用有类标记样本构成的训练数据不同,聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。
聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将他们划分为若干组,划分的原则是组内样本最小化而组间(外部)距离最大化,如图9-1所示。
图9-1 聚类分析建模原理常用聚类方法见表9-1。
表9-1常用聚类方法常用聚类算法见图9-2。
表9-2常用聚类分析算法9.1.2K-Means聚类算法K-Means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
1.算法过程1)从N个样本数据中随机选取K个对象作为初始的聚类中心;2)分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中;3)所有对象分配完成后,重新计算K个聚类的中心;4)与前一次计算得到的K个聚类中心比较,如果聚类中心发生变化,转2),否则转5);5)当质心不发生变化时停止并输出聚类结果。
聚类的结果可能依赖于初始聚类中心的随机选择,可能使得结果严重偏离全局最优分类。
实践中,为了得到较好的结果,通常以不同的初始聚类中心,多次运行K-Means算法。
在所有对象分配完成后,重新计算K个聚类的中心时,对于连续数据,聚类中心取该簇的均值,但是当样本的某些属性是分类变量时,均值可能无定义,可以使用K-众数方法。
聚类分析K-means算法综述摘要:介绍K-means聚类算法的概念,初步了解算法的基本步骤,通过对算法缺点的分析,对算法已有的优化方法进行简单分析,以及对算法的应用领域、算法未来的研究方向及应用发展趋势作恰当的介绍。
关键词:K-means聚类算法基本步骤优化方法应用领域研究方向应用发展趋势算法概述K-means聚类算法是一种基于质心的划分方法,输入聚类个数k,以及包含n个数据对象的数据库,输出满足方差最小标准的k个聚类。
评定标准:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算。
解释:基于质心的划分方法就是将簇中的所有对象的平均值看做簇的质心,然后根据一个数据对象与簇质心的距离,再将该对象赋予最近的簇。
k-means 算法基本步骤(1)从n个数据对象任意选择k 个对象作为初始聚类中心(2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分(3)重新计算每个(有变化)聚类的均值(中心对象)(4)计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则回到步骤(2)形式化描述输入:数据集D,划分簇的个数k输出:k个簇的集合(1)从数据集D中任意选择k个对象作为初始簇的中心;(2)Repeat(3)For数据集D中每个对象P do(4)计算对象P到k个簇中心的距离(5)将对象P指派到与其最近(距离最短)的簇;(6)End For(7)计算每个簇中对象的均值,作为新的簇的中心;(8)Until k个簇的簇中心不再发生变化对算法已有优化方法的分析(1)K-means算法中聚类个数K需要预先给定这个K值的选定是非常难以估计的,很多时候,我们事先并不知道给定的数据集应该分成多少个类别才最合适,这也是K一means算法的一个不足"有的算法是通过类的自动合并和分裂得到较为合理的类型数目k,例如Is0DAIA算法"关于K一means算法中聚类数目K值的确定,在文献中,根据了方差分析理论,应用混合F统计量来确定最佳分类数,并应用了模糊划分嫡来验证最佳分类数的正确性。
一、介绍K-means聚类算法是一种常见的无监督学习算法,用于将数据集划分成多个不相交的子集,从而使每个子集内的数据点都彼此相似。
这种算法通常被用于数据挖掘、模式识别和图像分割等领域。
在本文中,我们将介绍K-means聚类算法的步骤,以帮助读者了解该算法的原理和实现过程。
二、算法步骤1. 初始化选择K个初始的聚类中心,这些聚类中心可以从数据集中随机选择,也可以通过一些启发式算法进行选择。
K表示用户事先设定的聚类个数。
2. 聚类分配对于数据集中的每个数据点,计算其与K个聚类中心的距离,并将其分配到距离最近的聚类中心所属的子集中。
3. 更新聚类中心计算每个子集中所有数据点的均值,将均值作为新的聚类中心。
4. 重复第二步和第三步重复进行聚类分配和更新聚类中心的步骤,直到聚类中心不再发生变化,或者达到预设的迭代次数。
5. 收敛当聚类中心不再发生变化时,算法收敛,聚类过程结束。
三、算法变体K-means算法有许多不同的变体,这些变体可以根据特定的场景和需求进行调整。
K-means++算法是K-means算法的一种改进版本,它可以更有效地选择初始的聚类中心,从而提高聚类的准确性和效率。
对于大规模数据集,可以使用Mini-batch K-means算法,它可以在迭代过程中随机选择一部分数据进行计算,从而加快算法的收敛速度。
四、总结K-means聚类算法是一种简单而有效的聚类算法,它在各种领域都得到了广泛的应用。
然而,该算法也存在一些局限性,例如对初始聚类中心的选择比较敏感,对异常值比较敏感等。
在实际使用时,需要根据具体情况进行调整和改进。
希望本文对读者有所帮助,让大家对K-means聚类算法有更深入的了解。
K-means聚类算法作为一种经典的无监督学习算法,在进行数据分析和模式识别时发挥着重要作用。
在实际应用中,K-means算法的步骤和变体需要根据具体问题进行调整和改进。
下面我们将进一步探讨K-means聚类算法的步骤和变体,以及在实际应用中的注意事项。
第9章K-Means 聚类、辨别分析9.1理解聚类分析餐饮企业经常会碰到这样的问题:1)如何通过餐饮客户消费行为的测量,进一步评判餐饮客户的价值和对餐饮客户进行细分,找到有价值的客户群和需关注的客户群?2)如何合理对菜品进行分析,以便区分哪些菜品畅销毛利又高,哪些菜品滞销毛利又低?餐饮企业遇到的这些问题,可以通过聚类分析解决。
9.1.1常用聚类分析算法与分类不同,聚类分析是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法。
与分类模型需要使用有类标记样本构成的训练数据不同,聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。
聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将他们划分为若干组,划分的原则是组内样本最小化而组间(外部)距离最大化,如图9-1所示。
图9-1 聚类分析建模原理常用聚类方法见表9-1。
表9-1常用聚类方法类别包括的主要算法划分(分裂)方法K-Means算法(K-平均)、K-MEDOIDS算法(K-中心点)、CLARANS 算法(基于选择的算法)层次分析方法BIRCH算法(平衡迭代规约和聚类)、CURE算法(代表点聚类)、CHAMELEON算法(动态模型)基于密度的方法DBSCAN算法(基于高密度连接区域)、DENCLUE算法(密度分布函数)、OPTICS算法(对象排序识别)基于网格的方法STING算法(统计信息网络)、CLIOUE算法(聚类高维空间)、WA VE-CLUSTER算法(小波变换)基于模型的方法统计学方法、神经网络方法常用聚类算法见图9-2。
表9-2常用聚类分析算法算法名称算法描述K-Means K-均值聚类也叫快速聚类法,在最小化误差函数的基础上将数据划分为预定的类数K。
该算法原理简单并便于处理大量数据。
K-中心点K-均值算法对孤立点的敏感性,K-中心点算法不采用簇中对象的平均值作为簇中心,而选用簇中离平均值最近的对象作为簇中心。
系统聚类系统聚类也叫多层次聚类,分类的单位由高到低呈树形结构,且所处的位置越低,其所包含的对象就越少,但这些对象间的共同特征越多。
该聚类方法只适合在小数据量的时候使用,数据量大的时候速度会非常慢。
9.1.2K-Means聚类算法K-Means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
1.算法过程1)从N个样本数据中随机选取K个对象作为初始的聚类中心;2)分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中;3)所有对象分配完成后,重新计算K个聚类的中心;4)与前一次计算得到的K个聚类中心比较,如果聚类中心发生变化,转2),否则转5);5)当质心不发生变化时停止并输出聚类结果。
聚类的结果可能依赖于初始聚类中心的随机选择,可能使得结果严重偏离全局最优分类。
实践中,为了得到较好的结果,通常以不同的初始聚类中心,多次运行K-Means算法。
在所有对象分配完成后,重新计算K个聚类的中心时,对于连续数据,聚类中心取该簇的均值,但是当样本的某些属性是分类变量时,均值可能无定义,可以使用K-众数方法。
2. 数据类型与相似性的度量 (1) 连续属性对于连续属性,要先对各属性值进行零-均值规范,再进行距离的计算。
K-Means 聚类算法中,一般需要度量样本之间的距离、样本与簇之间的距离以及簇与簇之间的距离。
度量样本之间的相似性最常用的是欧几里得距离、曼哈顿距离和闵可夫斯基距离;样本与簇之间的距离可以用样本到簇中心的距离(,)i d e x ;簇与簇之间的距离可以用簇中心的距离(,)i j d e e 。
用p 个属性来表示n 个样本的数据矩阵如下:1111p n n p x x x x ⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦欧几里得距离2221122(,)()+()++()i j i j ip jp d i j x x x x x x =--- (9-1)曼哈顿距离1122(,)||+||++||i j i j ip jp d i j x x x x x x =--- (9-2)闵可夫斯基距离1122(,)|(|)+(||)++(||)q q q q i j i j ip jp d i j x x x x x x =--- (9-3)q 为正整数,=1q 时即为曼哈顿距离;=2q 时即为欧几里得距离。
(2) 文档数据对于文档数据使用余弦相似性度量,先将文档数据整理成文档—词矩阵格式,如表9-3。
表9-3 文档—词矩阵lost win team score music happy sad … coach 文档一 14 2 8 0 8 7 10 … 6 文档二 1 13 3 4 1 16 4 … 7 文档三 96773148…5两个文档之间的相似度的计算公式为:(,)cos(,)||||i jd i j i j i j⋅== (9-4)3. 目标函数使用误差平方和SSE 作为度量聚类质量的目标函数,对于两种不同的聚类结果,选择误差平方和较小的分类结果。
连续属性的SSE 计算公式为:21(,)iKi i x E SSE dist e x =∈=∑∑ (9-5)文档数据的SSE 计算公式为:21cos(,)iKii x E SSE e x =∈=∑∑ (9-6)簇i E 的聚类中心i e 计算公式为:1ii x E ie x n ∈=∑ (9-7)表9-4 符号表符号 含义 K聚类簇的个数 i E第i 个簇 x 对象(样本) i e 簇i E 的聚类中心 i n第i 个簇中样本的个数下面结合具体案例来实现本节开始提出问题。
部分餐饮客户的消费行为特征数据如表9-5。
根据这些数据将客户分类成不同客户群,并评价这些客户群的价值。
表9-5消费行为特征数据ID R (最近一次消费时间间隔) F (消费频率)M (消费总金额)1 37 4 5792 353 616 3 25 10 394 4 52 2 1115 367 521 6 41 5 225 7 56 3 118 83757939 54 2 111 105181086采用K-Means 聚类算法,设定聚类个数K 为3,距离函数默认为欧氏距离。
执行K-Means 聚类算法输出的结果见表9-6。
表9-6聚类算法输出结果分群类别 分群1 分群2 分群3 样本个数 352 370 218 样本个数占比37.45% 39.36% 23.19% 聚类中心R18.47727 11.355114 1198.3034 F 15.48919 7.316216 429.8898 M16.0917410.7110091913.3965以下是绘制的不同客户分群的概率密度函数图,通过这些图能直观地比较不同客户群的价值。
020601000.0000.0100.0200.030RN = 211 Bandwidth = 3.685D e n s i t y102030400.000.010.020.030.040.050.06FN = 211 Bandwidth = 2.187D e n s i t y2000500080000.00000.00100.0020MN = 211 Bandwidth = 53.53D e n s i t y图9-2分群1的概率密度函数图040801200.0000.0100.0200.030RN = 357 Bandwidth = 3.524D e n s i t y1020300.000.010.020.030.040.05FN = 357 Bandwidth = 2.094D e n s i t y600100014000.00000.00050.00100.0015MN = 357 Bandwidth = 60.49D e n s i t y图9-3分群2的概率密度函数图040800.000.010.020.03RN = 372 Bandwidth = 2.878D e n s i t y1020300.000.020.040.060.08FN = 372 Bandwidth = 1.838D e n s i t y-20020060010000.00000.00040.00080.0012MN = 372 Bandwidth = 62.69D e n s i t y图9-4分群3的概率密度函数图客户价值分析:分群1特点:R 主要集中在10~30天之间;消费次数集中在5~30次;消费金额在1600~2000。
分群2特点:R 分布在20~45天之间;消费次数集中在5~25次;消费金额在800~1600。
分群3特点:R 分布在30~60天之间;消费次数集中在1~10次;消费金额在200~800。
对比分析:分群1时间间隔较短,消费次数多,而且消费金额较大,是高消费高价值人群。
分群2的时间间隔、消费次数和消费金额处于中等水平。
分群3的时间间隔较长,消费次数和消费金额处于较低水平,是价值较低的客户群体。
9.1.3 聚类分析算法评价聚类分析仅根据样本数据本身将样本分组。
其目标是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。
组内的相似性越大,组间差别越大,聚类效果就越好。
(1) purity 评价法purity 方法是极为简单的一种聚类评价方法,只需计算正确聚类数占总数的比例:1(,)max ||k i ik purity X Y x y n =⋂∑ (9-8)其中,()12,,,k x x x x = 是聚类的集合。
k x 表示第k 个聚类的集合。
()12,,,k y y y y = 表示需要被聚类的集合,i y 表示第i 个聚类对象。
n 表示被聚类集合对象的总数。
(2) RI 评价法实际上这是一种用排列组合原理来对聚类进行评价的手段,RI 评价公式如下:R WRI R M D W+=+++ (9-10)其中R 是指被聚在一类的两个对象被正确分类了,W 是指不应该被聚在一类的两个对象被正确分开了,M 指不应该放在一类的对象被错误的放在了一类,D 指不应该分开的对象被错误的分开了。
(3) F 值评价法这是基于上述RI 方法衍生出的一个方法,F 评价公式如下:22(1)p rF p rααα+=+ (9-11)其中R p R M =+,Rr R D=+。
实际上RI 方法就是把准确率p 和召回率r 看得同等重要,事实上有时候我们可能需要某一特性更多一点,这时候就适合使用F 值方法。
9.2实例1—利用K-Means 聚类确定患冠心病的高风险人群9.2.1 背景和概要说明Sonia 在一家主要健康保险公司担任项目总监。