superset用户使用步骤说明材料
- 格式:doc
- 大小:2.86 MB
- 文档页数:31

Superset 的功能介绍1、我们可以通过连接数据库,去对数据库中的单个表进行配置,展示出柱状图,折线图,饼图,气泡图,词汇云,数字,环状层次图,有向图,蛇形图,地图,平行坐标,热力图,箱线图,树状图,热力图,水平图等图,官网上是不可以操作多个表的,不过我们可以操作视图,也就是说在数据库建好视图,也可以在 superset 中给表新增一列进行展示。
2、配置好了我们想要的图表之后我们可以把它添加到仪盘表进行展示,还可以去配置缓存,来加速仪盘表的查询,不必要没次都去查询数据库。
3、我们可以查看进行查询表的sql ,也可以把查询导出为json , csv 文件。
它有自己的 sql 编辑器,我们可以在里面来编写sql 。
一、系统基本使用在使用本系统前,应该先进行账户的建立操作。
1.1 登陆输入开通的账号、密码点击登录即可。
1.2 新建账号在登陆时可以使用admin 进行用户的创建。
先登陆 admin 用户,点击界面栏目"安全 " → "用户列表"→,点击按钮在填写完信息后点击保存(注:红色* 的选项未必填项)即可使用新建账号登陆。
在创建账号时,根据使用账号功能需求选择不同的角色属性,每个账号的用户名不能相同。
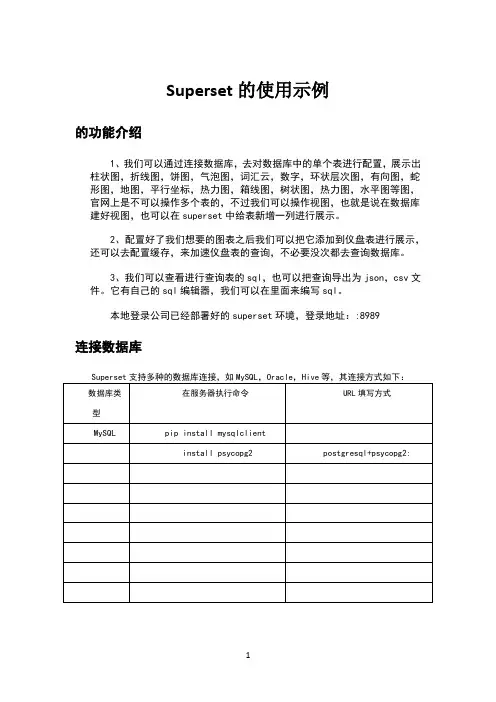
二、创建数据源2.1.1 superset 连接 MySQL登录到部署 superset 主机1. 进入 superset 的 Web界面,点击 sources 下拉选项的D atabases ,如下图:2. 进入数据库界面,点击“ +”按钮进入数据库连接界面,填写正确字段后保存,操作如下:3.查看已经连接好的数据库2.1.2 添加数据表Sources -> Tables点击加号( +)新增数据表Database 选择之前创建好的数据源, Table Name 必须是数据源中对应真实的表名,表中必须包含一个 Date 或者 Timestamp 类型的字段2.1.3 数据表查看、编辑Sources -> Tables可看到所有已连接的数据表可对表结构、数据类型、是否可进行group 、 filter 、 count 、 sum、 min 、 max 操作等进行编辑2.2 数据探索分析与可视化展示Table 定义好维度字段和指标之后,即可针对该表进行数据探索分析与可视化展示,在Table 页面,点击一个表名,即可进入。

大数据技术之Superset版本:V1.0第1章Superset入门1.1 Superset概述Apache Superset是一个开源的、现代的、轻量级BI分析工具,能够对接多种数据源、拥有丰富的图标展示形式、支持自定义仪表盘,且拥有友好的用户界面,十分易用。
1.2 Superset应用场景由于Superset能够对接常用的大数据分析工具,如Hive、Kylin、Druid等,且支持自定义仪表盘,故可作为数仓的可视化工具。
SupersetHiveKylin Impala MySQLSuperset第2章Superset安装及使用Superset官网地址::/2.1 安装Python环境Superset是由Python语言编写的Web应用,要求Python3.6的环境。
12.1.1 安装Minicondaconda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同Python版本的软件包及其依赖,并能够在不同的Python环境之间切换,Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等,Miniconda包括Conda、Python。
此处,我们不需要如此多的工具包,故选择MiniConda。
1)下载Miniconda(Python3版本)下载地址:s:repo.anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh2)安装Miniconda(1)执行以下命令进行安装,并按照提示操作,直到安装完成。
[atguiguhadoop102 lib]$ bash Miniconda3-latest-Linux-x86_64.sh(2)在安装过程中,出现以下提示时,可以指定安装路径(3)出现以下字样,即为安装完成3)配置环境变量修改/etc/profile.d/env.sh文件,内容如下4)取消激活base环境Miniconda安装完成后,每次打开终端都会激活其默认的base环境,我们可通过以下命令,禁止激活默认base环境。

Conda是一个开源软件包管理系统和环境管理系统,用于安装多个版本的软件包和它们依赖的软件包,并在它们之间轻松切换。
而Superset是由Airbnb公司推出的一个用于数据分析和可视化的开源BI工具。
接下来我们将介绍如何通过Conda来安装Superset,并使用简书文章共享你的Superset使用心得。
一、Conda是什么?1. Conda是一个强大的开源软件包管理系统和环境管理系统,它可以同时管理多个软件版本和依赖关系。
2. Conda可以用于安装、更新、卸载软件包,并且可以创建不同的环境,使得不同的软件包可以相互独立地运行。
3. Conda不仅可以用于Python软件包的管理,还可以用于R、Ruby、Lua等多种编程语言的软件包管理。
二、安装Conda1. 需要下载并安装Miniconda,Miniconda是一个轻量级的Conda发行版,它包含了Conda、Python和一些常用的工具包。
2. 在全球信息站(xxx)上下载对应的Miniconda安装包,根据系统类型选择32位或64位安装包进行下载。
3. 安装Miniconda时,需要注意添加到系统环境变量,方便在命令行中使用Conda命令。
三、创建Superset环境1. 打开命令行工具,输入以下命令创建一个新的Conda环境并安装Superset:```shellconda create -n superset python=3conda activate supersetpip install apache-superset```2. 这个命令会创建一个名为superset的新环境,并在此环境中安装Superset所需的Python版本和依赖包。
四、启动Superset1. 在命令行中输入以下命令启动Superset服务:```shellsuperset run -p 8088 --with-threads --reload --debugger```2. 启动成功后,可以在浏览器中输入xxx访问Superset的Web界面。

Superset 中文使用手册一、简介Superset 是一个开源的数据可视化工具,为用户提供了强大的数据可视化能力。
它能帮助用户轻松地探索、分析和呈现大量数据,并具有高度的定制性和灵活性。
本手册将指导您如何安装、配置和使用Superset,帮助您充分利用其强大的功能。
二、安装与配置1.环境准备: 根据您的操作系统,确保已安装必要的依赖项,如Python、pip、virtualenv 等。
2.安装Superset: 使用pip 安装Superset:pip install superset。
3.配置Superset: 根据您的需求,编辑Superset 的配置文件,设置数据源和其他相关参数。
三、界面介绍1.导航栏: 包含了所有功能和操作的菜单项,如“数据源”、“可视化”、“仪表盘”等。
2.侧边栏: 用于展示当前选择的数据源信息和过滤条件。
3.内容区域: 这是主要的可视化区域,展示了图表和仪表盘。
四、数据源配置1.添加数据源: 在Superset 中添加数据源,需要提供数据库连接信息。
2.数据表选择: 在添加完数据源后,您可以从数据源中选择数据表以进行进一步的操作。
五、图表类型与配置1.常见图表类型: 包括柱状图、线图、饼图、散点图等。
2.配置图表参数: 可根据需要调整图表的详细参数,如颜色、轴标签等。
六、仪表盘设计1.创建仪表盘: 通过选择不同的组件和图表,创建一个新的仪表盘。
2.配置仪表盘: 可对仪表盘进行自定义布局和样式设置。
七、数据查询与过滤1.SQL 查询: 使用SQL 查询语言进行数据筛选和查询。
2.过滤条件: 通过设置过滤条件,仅展示感兴趣的数据部分。
八、权限与安全设置1.用户管理: 创建、删除和修改用户,为不同用户分配不同的角色和权限。
2.权限管理: 可以控制不同角色对数据源、图表和仪表盘的访问权限。
九、高级功能与优化1.性能优化: 优化数据查询和图表渲染性能,提高系统运行效率。
2.扩展性: 通过集成插件和扩展,增加Superset 的功能和定制性。
Superset文档数据库连接(步骤1-11)1、将Maxcompute中的数据,下载到本地数据库mysql中;2、使用superset超级用户(刚刚设定的账号密码)进入superset(此账号为超级用户);3、选择sources下的databases4、新建链接数据源5、进入页面后,在database中填写名,在SQLAlchemy URI中填写连接,mysql://数据库账号:数据库密码@数据库所在IP:端口号/数据库?charset=utf8charset=utf8 防止中文乱码勾选EXPOSE IN SQL LAB 和ALLOW RUN SYNC6、选择sources中的tables7、添加数据表8、选择数据库,在table name中填写数据库中数据表的名字9、添加成功后,原来table页面会出现所连接数据库中名称一样的数据表,点击数据表前的第二个图标进行编辑(第一个图标是查看,第三个图标是删除)10、进入后,选择list columns,对数据表中的列进行操作勾选,一般前两列都会填满,与时间相关的column要勾选第三列;完成勾选后,点击detail,然后滑到页面下端,点击save按钮进行保存;11、点击数据表名称,对该数据表进行探索;具体使用方式(步骤12-15)12、在visualization type 选择要表现的图表形式(当前是table view)13、以第一个柱状图为例(每个图例里面的选择项有所差异)TIME:对时间进行筛选,time column 时间列,time grain 颗粒度大小,time range 时间范围QUERY:查询:mertrics 显示图表内容,series 图标横坐标,filers 数据筛选,breakdowns对数据进行进一步分组显示(这里暂不举例)页面右上角:json:显示json格式数据;csv:下载当前页面数据保存csv格式;三条杠:显示相关的sql语句,结果14、如果对查询的结果满意,想要保存结果,点击save按钮,在弹窗中填写保存名称,这里填写testing,点击save15、点击charts,会出现刚刚保存的testing 图表,点击图表后,重新进入chart的查看编辑页面,chart的名称已经发生变化。
Superset的使用示例的功能介绍1、我们可以通过连接数据库,去对数据库中的单个表进行配置,展示出柱状图,折线图,饼图,气泡图,词汇云,数字,环状层次图,有向图,蛇形图,地图,平行坐标,热力图,箱线图,树状图,热力图,水平图等图,官网上是不可以操作多个表的,不过我们可以操作视图,也就是说在数据库建好视图,也可以在superset中给表新增一列进行展示。
2、配置好了我们想要的图表之后我们可以把它添加到仪盘表进行展示,还可以去配置缓存,来加速仪盘表的查询,不必要没次都去查询数据库。
3、我们可以查看进行查询表的sql,也可以把查询导出为json,csv文件。
它有自己的sql编辑器,我们可以在里面来编写sql。
本地登录公司已经部署好的superset环境,登录地址::8989连接数据库python install重启superset:superset runserver –p 8989superset 连接Kylin数据库操作数据库经过上边的步骤就连接上了数据库,下边就可以进行数据的可视化操作了。
首先点击SQL测试下拉菜单下的SQL编辑器按钮。
如下图所示:SQL语句的执行结果如下:点击Visualize按钮进入数据可视化编辑窗口:图形使用案例Distribution – Bar Chart(分布-条形图)案例需求:统计每个state的总人数,总女生人数,总男生人数。
SELECT state AS state,sum(num) AS sum__num,sum(sum_girls) AS sum__sum_girls,sum(sum_boys) AS sum__sum_boysFROM(select *from birth_names) AS expr_qryWHERE ds >= '1917-07-05 18:21:31'AND ds <= '2017-07-05 18:21:31'GROUP BY stateORDER BY sum__num DESC LIMIT 50000进入可视化界面,可按需求显示图形:在图形的右上方有对图形的保存等一些操作:图表的保存:查看保存的图表:1.2Table View –表视图需求1:根据name,gender分组,统计总人数。

Superset的安装配置及基础使用手册之前研究过一些可视化工具/开源框架,包括powerBI、T ableau 和Superset等。
Superset是Airbnb开源BI数据分析与可视化平台(曾用名Caravel、Panoramix),该工具主要特点是可自助分析、自定义仪表盘、分析结果可视化(导出)、用户/角色权限控制,还集成了一个SQL编辑器,可以进行SQL编辑查询等,原来是用于支持Druid的可视化分析,后面发展为支持很多种关系数据库及大数据计算框架,如:mysql, oracle, Postgres, Presto, sqlite, Redshift, Impala, SparkSQL, Greenplum, MSSQL。
总结记录一下Superset安装配置和基础使用。
1. 安装(CentOS & Win)1.1 CentOS (参考https:///qq273681448/article/details/75050513)1.yum makecache2.sudo easy_install -i /simple/ pip3.sudo easy_install pip4.sudo yum install gcc libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel1.#安装Superset2.pip install superset3.4.#创建管理员用户名和密码5.fabmanager create-admin --app superset6.7.#初始化Superset8.superset db upgrade9.10.#装载初始化样例数据11.superset load_examples12.13.#创建默认角色和权限14.superset init15.16.#启动Superset17.superset runserver数据库依赖1.2 Windows(参考https:///p/36223295)1.2.1 安装虚拟环境virtualenv(需要安装Python,并配置环境变量)pip install virtualenv1.2.2 使用virtualenv。
Superset的功能介绍1、我们可以通过连接数据库,去对数据库中的单个表进行配置,展示出柱状图,折线图,饼图,气泡图,词汇云,数字,环状层次图,有向图,蛇形图,地图,平行坐标,热力图,箱线图,树状图,热力图,水平图等图,官网上是不可以操作多个表的,不过我们可以操作视图,也就是说在数据库建好视图,也可以在superset中给表新增一列进行展示。
2、配置好了我们想要的图表之后我们可以把它添加到仪盘表进行展示,还可以去配置缓存,来加速仪盘表的查询,不必要没次都去查询数据库。
3、我们可以查看进行查询表的sql,也可以把查询导出为json,csv文件。
它有自己的sql编辑器,我们可以在里面来编写sql。
一、系统基本使用在使用本系统前,应该先进行账户的建立操作。
1.1登陆输入开通的账号、密码点击登录即可。
1.2新建账号在登陆时可以使用admin进行用户的创建。
先登陆admin用户,点击界面栏目"安全"→"用户列表"→,点击按钮在填写完信息后点击保存(注:红色*的选项未必填项)即可使用新建账号登陆。
在创建账号时,根据使用账号功能需求选择不同的角色属性,每个账号的用户名不能相同。
二、创建数据源2.1.1 superset连接MySQL登录到部署superset主机1.进入superset的Web界面,点击sources下拉选项的Databases,如下图:2.进入数据库界面,点击“+”按钮进入数据库连接界面,填写正确字段后保存,操作如下:3.查看已经连接好的数据库2.1.2 添加数据表Sources -> Tables点击加号(+)新增数据表Database选择之前创建好的数据源,Table Name必须是数据源中对应真实的表名,表中必须包含一个Date或者Timestamp类型的字段2.1.3 数据表查看、编辑Sources -> Tables可看到所有已连接的数据表可对表结构、数据类型、是否可进行group、filter、count、sum、min、max操作等进行编辑2.2 数据探索分析与可视化展示Table定义好维度字段和指标之后,即可针对该表进行数据探索分析与可视化展示,在List Table页面,点击一个表名,即可进入。
ApacheSuperset1.2.0教程(⼀)——安装(Windows版)Apache Superset 是⼀款由 Airbnb 开源的“现代化的企业级 BI(商业智能) Web 应⽤程序”,其通过创建和分享 dashboard,为数据分析提供了轻量级的数据查询和可视化⽅案。
近⽇推出了全新的 1.2.0版本,本教程也就从头开始讲解Apache Superset的使⽤。
不想去官⽹下载的同学,本⽂⽤到的安装⽂件,关注⼤数据流动,后台回复 superset20210712 进⾏下载。
Apache Superset安装(Windows版)window安装superset⾮常的简单,由于最新的版本已经加⼊pip库,所以我们可以使⽤pip库轻松的安装superset。
⼀、安装Python环境我们使⽤anaconda快速的安装python环境。
Anaconda指的是⼀个开源的Python发⾏版本,包含了⼤量的科学包。
也提供了很多好⽤的⼯具,安装起来⾮常的友好。
最近安装包下载地址通过以下地址可以下载各种版本的安装包。
我们只需要下载windows版本即可。
下载完成后安装此exe⽂件。
安装过程中记得勾选添加环境变量这样Python环境就搞定了,进⼊cmd命令⾏,输⼊指令进⾏验证python -VPython 3.8.3⼆、Apache Superset安装⾸先更新pip库pip install --upgrade pip等待更新完成后,可以查看⼀下库⾥的apache-superset版本pip install apache-superset==可以看到,最新的版本为 1.2.0pip install --upgrade apache-superset需要⼀段时间将依赖包都安装好。
⼀定要确保所有都安装好,有问题及时修复。
#初始化数据库superset db upgrade成功!#初始化⽤户superset fab create-admin依次设置⽤户名密码#加载例⼦superset load_examples#初始化权限superset init使⽤如下指令启动supersetsuperset run -p 8088 --with-threads --reload --debugger使⽤设置好的⽤户名密码登录即可全新的页⾯。

superset 计算字段Superset是一个用于数据探索和可视化的开源平台,它提供了强大的计算字段功能,可以帮助用户根据已有的数据字段创建新的计算字段。
在本文中,我将介绍Superset的计算字段功能及其应用,并以一些具体示例来展示其用法和效果。
我们来了解一下什么是计算字段。
计算字段是根据已有的字段进行计算而生成的新字段,它可以通过各种数学运算、聚合函数、条件语句等方式来定义。
计算字段的作用在于根据现有数据的特点和需求,生成新的数据指标或特征,从而更好地理解和分析数据。
在Superset中,创建计算字段非常简单。
首先,我们需要进入数据探索界面,在数据集中选择要进行计算的字段。
然后,点击“计算字段”按钮,进入计算字段编辑界面。
在这里,我们可以使用Superset提供的函数和表达式来定义计算字段。
举个例子,假设我们有一个销售数据集,其中包含了产品的销售额和销售数量。
我们可以通过计算字段来生成产品的平均售价。
在计算字段编辑界面,我们可以输入如下表达式来定义平均售价字段:销售额/销售数量。
然后,我们可以为这个计算字段命名,并选择数据类型和格式。
最后,点击保存按钮,Superset会自动为我们生成这个计算字段,并在数据探索界面中展示出来。
除了基本的数学运算,Superset还提供了丰富的聚合函数,如求和、平均值、最大值、最小值等。
这些聚合函数可以应用于特定的字段或计算字段,帮助我们更好地理解数据的总体情况和趋势。
Superset还支持使用条件语句来定义计算字段。
条件语句可以帮助我们根据不同的条件对数据进行分类和分组,从而生成更具有实际意义的计算字段。
例如,我们可以使用条件语句来判断产品销售额是否超过某个阈值,然后将结果作为新的字段进行展示和分析。
除了以上介绍的功能,Superset还支持使用SQL表达式来定义计算字段。
这为有SQL编程经验的用户提供了更大的灵活性和扩展性,可以根据具体的需求来编写复杂的计算字段逻辑。

superset 时间格式-回复Superset是一个强大的数据可视化和探索工具,可以帮助用户快速而直观地理解和分析数据。
在Superset中,时间数据是一种常见的数据类型,它通常用于创建时间序列分析和可视化的仪表盘。
本文将重点介绍Superset中时间格式的使用,以及如何在Superset中处理和呈现时间数据。
首先,让我们了解Superset中的时间格式。
Superset支持多种时间格式,包括日期时间格式(如YYYY-MM-DD HH:MM:SS)和日期格式(如YYYY-MM-DD)。
这些格式允许用户以不同的精度和方式处理时间数据。
在Superset中,时间数据可以用于多种方式。
首先,它可以用作仪表盘的过滤器,允许用户根据特定的时间范围进行数据过滤。
例如,如果用户只想看最近一周的数据,他们可以选择从过去七天的日期开始,然后设置过滤器以显示这个时间范围内的数据。
另外,时间数据还可以用于创建时间序列图表。
在Superset中,用户可以使用时间字段作为X轴,将数据点按时间顺序显示。
这对于展示趋势、时间相关性和周期性数据非常有用。
用户可以选择不同的时间粒度,如按小时、按天、按周或按月进行分组。
这可以根据用户的需求和数据的特性来决定,一般情况下,较大的时间粒度适合较长期间的数据,而较小的时间粒度则适合较短期间的数据。
为了在Superset中正确处理和呈现时间数据,需要进行一些设置和转换。
首先,确保数据源中的时间字段正确定义为时间数据类型。
这样Superset 才能正确解析和处理时间数据。
其次,确保数据源中的时间字段的格式与Superset中的时间格式匹配。
如果格式不匹配,Superset可能无法正确显示时间数据。
在这种情况下,可以使用一些SQL函数或转换工具来处理时间字段,以确保时间格式的一致性。
另外,Superset还提供了一些内置的函数和功能,用于处理时间数据。
用户可以使用这些函数来进行时间计算、转换和聚合。
标题:如何在Superset中合并表格单元格在Superset中,表格是一种常见的数据展示方式,然而,有时候我们需要对表格的单元格进行合并操作以便更好地展示数据。
本文将介绍如何在Superset中进行表格单元格的合并操作。
一、添加数据表格在Superset中,首先需要添加一个数据表格。
在“新建仪表盘”页面,点击“添加图表”按钮,在弹出的图表类型中选择“数据表格”。
二、选择数据源在弹出的数据表格设置界面中,首先需要选择数据源。
点击“数据源”下拉菜单,选择相应的数据源。
三、选择要展示的字段在“数据源”设置完成之后,需要选择要在数据表格中展示的字段。
点击“字段”下拉菜单,选择需要展示的字段名称。
四、添加关联信息如果需要在数据表格中添加关联信息,可以点击“关联信息”下拉菜单,选择相应的关联信息。
五、设置其他属性在数据表格设置的可以根据需要设置数据表格的其他属性,如是否显示标题、是否显示行号等。
六、保存并查看数据表格在完成数据表格的设置之后,点击页面右上角的“保存”按钮保存设置。
随后,点击“查看”按钮可以查看数据表格的展示效果。
七、合并单元格在数据表格中,如果需要对单元格进行合并操作,可以通过以下几种方式实现:1. 使用SQL语句进行合并在Superset中,可以通过编写SQL语句来实现表格单元格的合并操作。
在数据表格设置界面中,点击“自定义SQL”选项,在弹出的文本框中编写SQL语句进行单元格的合并操作。
2. 使用HTML标签进行合并在Superset中,还可以通过在数据表格中使用HTML标签来实现单元格的合并操作。
在数据表格中,可以通过在需要合并的单元格中使用colspan和rowspan属性来实现单元格的合并操作。
3. 使用JavaScript进行合并还可以通过在Superset中使用JavaScript来实现表格单元格的合并操作。
在数据表格设置界面中,可以通过自定义JavaScript脚本来实现单元格的合并操作。
superset 科学计数法
Superset 是一个数据分析软件,支持大数据集的可视化和分析。
在Superset 中,科学计数法是一个常见的数值格式,用于表示非常大或非常小的数字。
科学计数法的格式为:a×10^n,其中 a 是范围在 1
至 10 之间的数字,n 是一个整数。
Superset 支持使用科学计数法来显示数字。
要在 Superset 中使用科
学计数法,需要在可视化图表的设置中选择“科学计数法”。
在选择“科学计数法”后,Superset 将会用科学计数法来显示所有大于或等于 10000 的数字,并会自动根据数字的大小调整指数的大小。
另外,在 Superset 中也可以使用 Jinja 语言来编写自定义文本和标签。
这允许用户在可视化图表中使用科学计数法来显示数据标签和/或自定义文本。
例如,要在可视化图表中使用科学计数法来显示数据标签,
可以使用以下代码:
```
{% for item in column %}
{{ item|scientific }}
{% endfor %}
```
此代码将会将数据列中的每个数字转换为科学计数法,并在可视化图表中显示出来。
总之,科学计数法对于处理大数据集非常重要,能够方便地将非常大或非常小的数字进行表示和比较。
在 Superset 中,科学计数法非常容易使用,是一个非常方便的数据可视化和分析工具。
superset 字段权限-回复Superset 字段权限: 保护您的数据访问控制引言在现代数据驱动的世界中,保护数据的安全性和保密性是至关重要的。
数据分析平台Superset 为用户提供了强大的数据可视化和探索功能,但同时也需要对敏感数据进行适当的权限控制,以确保只有合适的人员可以访问和处理数据。
本文将深入探讨Superset 的字段权限功能,讲解如何为您的数据设置精细的访问控制规则。
第一部分:理解Superset 字段权限在Superset 中,字段权限允许管理员和数据所有者限制用户对特定字段的访问权限。
这是一种细粒度的访问控制,可以确保只有需要的用户可以查看和操作敏感数据。
字段权限可以应用于数据表、视图和数据列,并根据用户角色和组织进行细分。
第二部分:配置字段权限步骤1. 定义字段级别权限规则在Superset 中,管理员可以定义字段级别的权限规则,以确保只有有权访问的用户可以查看和使用特定字段。
通过以下步骤可以实现:a. 登录到Superset 平台并转到"安全" 菜单。
b. 在"字段级别权限" 下,单击"新增条目"。
c. 选择要配置权限的数据源和表格。
d. 选择要应用权限的列,并选择允许或禁止访问该列的用户角色。
2. 设置用户角色和组织为了使字段权限生效,您需要为用户分配适当的角色和组织。
这些角色和组织将与字段权限规则关联,决定用户可以查看和操作哪些字段。
以下是设置角色和组织的步骤:a. 转到"安全" 菜单下的"用户" 选项卡。
b. 选择要编辑的用户或直接创建一个新用户。
c. 为用户分配适当的角色和组织。
这些角色和组织将与字段权限规则相关联。
3. 测试和验证权限设置一旦配置了字段权限规则并分配了角色和组织,就可以进行测试和验证权限设置是否按预期工作。
以下是验证字段权限的步骤:a. 使用一个测试账号登录到Superset 平台。
superset 物理表传参Superset是一个开源的数据探索和可视化工具,它提供了一个可视化的界面来查询和可视化数据。
在Superset中,物理表是指在数据库中存储的实际数据表。
可以通过传参来在Superset中使用和操作物理表。
使用物理表在Superset中进行数据查询和可视化,需要首先在Superset中连接到数据库,并将物理表导入到Superset中。
导入物理表的方法有很多种,可以使用Superset提供的UI界面,也可以使用Superset提供的命令行工具或者API来导入物理表。
一旦导入了物理表,就可以在Superset中使用它们进行数据查询和可视化。
在Superset中,可以通过传参来操作物理表。
传参的方式有很多种,可以通过URL传参、通过Pivot Table插件传参、或者通过SQL Lab中的查询传参等方式。
下面将分别介绍这几种传参的方式:1. URL传参:可以通过在URL中添加查询参数的方式来传参。
例如,可以通过在URL中添加一个查询参数来指定一个特定的物理表,然后使用该物理表进行数据查询和可视化。
URL传参的方式非常简单,只需要在URL后面添加查询参数即可。
2. Pivot Table插件传参:Superset提供了一个Pivot Table插件,可以以交互式的方式传递参数。
通过使用该插件,可以选择物理表中的特定字段进行分组和聚合,生成交叉表格或透视图。
使用Pivot Table插件传参可以实现更复杂的数据查询和可视化需求。
3. SQL Lab查询传参:在Superset的SQL Lab中,可以使用传参的方式来编写和执行SQL查询。
通过在SQL语句中使用参数占位符的方式,可以将参数值传递给查询。
这种方式可以实现更加灵活和动态的数据查询和可视化需求。
通过传参的方式,在Superset中可以对物理表进行灵活和定制化的查询和可视化操作。
可以根据不同的需求,在Superset中使用不同的传参方式来操作物理表。
superset 应用示例摘要:1.Superset 应用简介2.Superset 的主要功能3.Superset 的应用示例4.Superset 的优势与不足5.Superset 的未来发展前景正文:1.Superset 应用简介Superset 是一款集数据处理、可视化、协作功能于一体的数据分析工具,旨在帮助数据分析师和团队更高效地完成数据分析工作。
Superset 提供了丰富的功能,包括数据导入、数据清洗、数据可视化、数据协作等,使得用户可以轻松地完成数据分析任务。
2.Superset 的主要功能(1)数据导入:Superset 支持多种数据源的导入,包括CSV、Excel、SQL、API 等。
用户可以根据需要选择相应的数据源进行导入。
(2)数据清洗:Superset 提供了丰富的数据清洗功能,包括数据预览、数据筛选、数据转换等,帮助用户快速地处理脏数据。
(3)数据可视化:Superset 提供了多种可视化工具,包括柱状图、折线图、饼图等,用户可以根据需要选择相应的可视化工具进行数据展示。
(4)数据协作:Superset 支持多人协作,团队成员可以在同一份数据上进行操作,提高工作效率。
3.Superset 的应用示例假设一个市场营销团队需要分析最近一年的销售数据,以便制定下一季度的市场策略。
他们可以使用Superset 完成以下任务:(1)将销售数据从CSV 文件中导入到Superset 中。
(2)对销售数据进行清洗,包括去除空值、异常值等。
(3)对销售数据进行可视化,例如绘制年度销售额柱状图、各季度销售额折线图等。
(4)分析可视化结果,发现销售数据的规律和趋势,为制定市场策略提供依据。
(5)团队成员可以共同参与数据分析过程,提高工作效率。
4.Superset 的优势与不足优势:(1)功能齐全,支持数据处理、可视化、协作等多种功能。
(2)易用性强,用户界面友好,容易上手。
(3)支持多种数据源,适应性强。
superset 物理表传参(实用版)目录1.引言2.什么是 Superset3.Superset 与物理表的关系4.物理表的传参过程5.总结正文1.引言在现代科学研究中,数据分析和处理变得越来越重要。
为了更好地对数据进行操作和管理,科学家们需要使用一些专业的工具。
Superset 就是这样一个工具,它可以帮助用户轻松地对数据进行处理和管理。
本文将介绍 Superset 与物理表的关系,以及物理表的传参过程。
2.什么是 SupersetSuperset 是一款开源的数据管理工具,可以帮助用户轻松地对数据进行操作和管理。
它支持多种数据源,包括关系型数据库、CSV 文件、Excel 文件等。
通过 Superset,用户可以方便地对数据进行清洗、转换、合并等操作,从而为数据分析提供便利。
3.Superset 与物理表的关系在 Superset 中,物理表是指存储数据的底层表结构。
它可以是关系型数据库中的一张表,也可以是 CSV 文件中的一行数据。
物理表是Superset 进行数据操作和管理的基本单位。
用户可以通过 Superset 对物理表进行各种操作,如查询、更新、删除等。
4.物理表的传参过程物理表的传参过程是指在 Superset 中将物理表的参数传递给另一个物理表的过程。
这个过程可以通过 Superset 的 API 进行操作。
具体来说,用户需要先创建一个物理表,然后通过 API 接口将这个物理表的参数传递给另一个物理表。
这样,另一个物理表就可以使用第一个物理表的参数进行数据操作和管理。
5.总结Superset 是一款强大的数据管理工具,它可以帮助用户轻松地对数据进行操作和管理。
在 Superset 中,物理表是进行数据操作和管理的基本单位。
Superset的功能介绍
1、我们可以通过连接数据库,去对数据库中的单个表进行配置,展示出柱状
图,折线图,饼图,气泡图,词汇云,数字,环状层次图,有向图,蛇形图,地图,平行坐标,热力图,箱线图,树状图,热力图,水平图等图,官网上是不可以操作多个表的,不过我们可以操作视图,也就是说在数据库建好视图,也可以在superset中给表新增一列进行展示。
2、配置好了我们想要的图表之后我们可以把它添加到仪盘表进行展示,还可
以去配置缓存,来加速仪盘表的查询,不必要没次都去查询数据库。
3、我们可以查看进行查询表的sql,也可以把查询导出为json,csv文件。
它有自己的sql编辑器,我们可以在里面来编写sql。
一、系统基本使用
在使用本系统前,应该先进行账户的建立操作。
1.1登陆
输入开通的账号、密码点击登录即可。
1.2新建账号
在登陆时可以使用admin进行用户的创建。
先登陆admin用户,点击界面栏目"安全"→"用户列表"→,点击按钮
在填写完信息后点击保存(注:红色*的选项未必填项)即可使用新建账号登陆。
在创建账号时,根据使用账号功能需求选择不同的角色属性,每个账号的用户名不能相同。
二、创建数据源
2.1.1 superset连接MySQL
登录到部署superset主机
1.进入superset的Web界面,点击sources下拉选项的Databases,如下图:
2.进入数据库界面,点击“+”按钮进入数据库连接界面,填写正确字段后保存,操作如
下:
3.查看已经连接好的数据库
2.1.2 添加数据表
Sources -> T ables
点击加号(+)新增数据表
Database选择之前创建好的数据源,Table Name必须是数据源中对应真实的表名,表中必须包含一个Date或者Timestamp类型的字段
2.1.3 数据表查看、编辑
Sources -> T ables可看到所有已连接的数据表
可对表结构、数据类型、是否可进行group、filter、count、sum、min、max操作等进行编辑
2.2 数据探索分析与可视化展示
Table定义好维度字段和指标之后,即可针对该表进行数据探索分析与可视化展示,在List Table页面,点击一个表名,即可进入。
在分析页面中,可以针对某一个表事先定义的时间字段、维度及指标字段进行数据探索分析,并可以选择相应的图表进行可视化展示。
2.2.1 可视化图表类型选择
选择可视化图表类型。
Superset自带的图表类型如上,包括柱状图、饼图、时间序列线图、
堆积图、图表、热词图等。
2.2.2 数据时间范围选择
选择:
时间所在数据列。
时间粒度,时间跨度
2.2.3 维度展示选择、图表可视化选择Group by:x轴统计维度
Metrics:y轴展示的数据指标(包括指标的sum、avg等)Sort By:排序依据
可视化选择
配色
图例
是否堆积/分布
……
2.2.4 坐标轴编辑
选择X、Y轴数据格式
编辑X、Y轴标签
编辑Y轴边界
2.2.5 自定义查询/过滤
自定义SQL语句
where、having语句、内置in/not in过滤器
2.2.6 查询可视化保存
将查询结果保存为slice
将slice增加到已有的dashboard/新增dashboard中
2.2.7 Dashboard编辑
编辑每个Slice对应的模块,可以自由拖拽位置和大小,并保存整个Dashboard的布局。
2.2.8 多表关联查询
在数据表编辑界面,可通过Database Expression,运用SQL语句实现多表关联查询。
3.Superset操作数据库
经过上边的步骤就连接上了数据库,下边就可以进行数据的可视化操作了。
首先点击SQL测试下拉菜单下的SQL编辑器按钮。
如下图所示:
SQL语句的执行结果如下:
点击Visualize按钮进入数据可视化编辑窗口:
4.superset部分图形使用案例
4.1 Distribution –Bar Chart(分布-条形图)案例需求:统计每个state的总人数,总女生人数,总男生人数。
进入可视化界面,可按需求显示图形:
在图形的右上方有对图形的保存等一些操作:
图表的保存:
查看保存的图表:
3.2Table View –表视图
需求1:根据name,gender分组,统计总人数。
SQL:
3.3Pivot Table –数据透视表
数据透视表(Pivot Table)是一种交互式的表,可以进行某些计算,如求和与计数等。
所进行的计算与数据跟数据透视表中的排列有关。
案例需求:按照name,gender分组,对每个state人数进行统计。
SQL:
3.4Time Series –Line Chart –时序线图案例需求:查看每个state人数总数随时间的变化。
SQL:
3.5Time Series –Stacked –时序面积图
面积图强调数量随时间而变化的程度,也可用于引起人们对总值趋势的注意。
例如,表示随时间而变化的产生的数据可以绘制在面积图中以强调总数据量。
案例需求:根据每个state每年的总人数的时序图-叠图。
SQL:
3.6Time Series –Bar Chart –时序柱形图案例需求:比较不同的年份每个state的人数差异的时序柱形图。
SQL:
3.7Distribution –NVD3 - Pie Chart –饼图案例:比较每个state的人数占总人数的比例。
SQL:
3.8Bubble Chart –气泡图SQL语句:
3.9MarKup –标记图
4.10 Word Clould –文字云
案例需求:显示所有的name,且看到使用这个名字的人数比重。
SQL语句:
3.10Sunburst –旭日图
案例需求:第一层gender,第二层name,统计人数。
SQL:
3.11Parallel Coordinates –平行坐标图
平行坐标图为一种数据可视化的方式。
以多个垂直平行的坐标轴表示多个维度,以维度上的刻度表示在该属性上对应值,以颜色区分类别。
每个样本在各个维度上对应一个值,相连而得的一个折线表示该样本。
SQL:
3.12Box plot –盒图
盒图(boxplot):摆弄数据离散度的一种图形。
它对于显示数据的离散的分布情况效果不错。
在软件工程中,Nassi和Shneiderman 提出了一种符合结构化程序设计原则的图形描述工具,叫做盒图,也被称为N-S图。
SQL:
* *。