华中师范大学17年9月课程考试《SPSS统计软件》作业考核试题
- 格式:doc
- 大小:31.50 KB
- 文档页数:7


华师17年9⽉课程考试《计算机图形学》作业考核试题华师17年9⽉课程考试《计算机图形学》作业考核试题⼀、单选题(共 20 道试题,共 40 分。
)1. 双线性法向插值法(PhongShading)有何优点?()A. 法向计算精确B. ⾼光域准确C. 对光源和视点没有限制D. 速度较快2. 下⾯关于深度缓存消隐算法(Z-Buffer)的论断哪⼀条不正确?A. 深度缓存算法并不需要开辟⼀个与图像⼤⼩相等的深度缓存数组B. 深度缓存算法不能⽤于处理对透明物体的消隐C. 深度缓存算法能并⾏实现D. 深度缓存算法中没有对多边形进⾏排序3. 触摸屏是____设备。
A. 输⼊B. 输出C. 输⼊输出D. 既不是输⼊也不是输出4. 图形软件系统提供给⽤户三种基本的输⼊⽅式,不包含的选项是____。
A. 请求⽅式B. 采样⽅式C. 事件⽅式D. 随机⽅式5. ⽤转⾓法判别点在区域的内外。
将疑点M与边界上⼀点P连接,当P沿边界移动⼀周时,M点处于区域外的是____。
A. MP与给定的某条直线夹⾓变化值为0B. MP与给定的某条直线夹⾓变化值为2πC. MP与给定的某条直线夹⾓变化值为πD. MP与给定的某条直线夹⾓变化值为3π6. 下列有关平⾯⼏何投影的叙述,错误的是____。
A. 透视投影⼜可分为⼀点透视、⼆点透视、三点透视B. 斜投影⼜可分为斜等测、斜⼆测C. 正轴测⼜可分为正⼀测、正⼆测、正三测D. 正视图⼜可分为主视图、侧视图、俯视图。
B. 1.6MBC. 2.7MBD. 3.9 MB8. 三维空间中的透视投影,主灭点最多可以有⼏个____。
A. 1B. 2C. 3D. 49. 下列有关多边形连贯性原理的叙述,错误的是____。
A. 由区域的连贯性知,扫描线与多边形边界的交点数为偶数B. 边的连贯性是区域连贯性在⼀条扫描线上的反映C. 扫描线的连贯性是多边形区域连贯性在⼀条扫描线上的反映D. 已知⼀条扫描线与多边形边的交点序列,可根据边的连贯性,增加⼀个递增量算出相邻扫描线与多边形边的交点序列10. 计算机内存编址的基本单位是____。
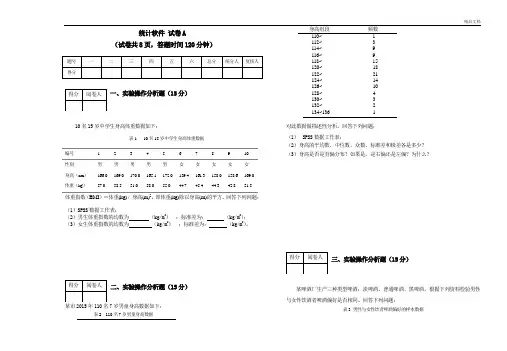
精品文档统计软件 试卷A(试卷共8页,答题时间120分钟)一、实验操作分析题(15分)10名15岁中学生身高体重数据如下:表1 10名15岁中学生身高体重数据编号 1 2 3 4 5 6 7 8 9 10 性别 男 男 男 男 男 女 女 女 女 女 身高(cm ) 166.0 169.0 170.0 165.1 172.0 159.4 161.3 158.0 158.6 169.0 体重(kg )57.058.551.058.055.044.745.444.342.851.5体重指数(BMI )=体重(kg) / 身高(m)2,即体重(kg)除以身高(m)的平方。
回答下列问题: (1)SPSS 数据工作表;(2)男生体重指数的均数为 (kg/m 2) ;标准差为: (kg/m 2);(3)女生体重指数的均数为 (kg/m 2) ;标准差为: (kg/m 2)。
二、实验操作分析题(15分)某市2015年110名7岁男童身高数据如下:身高组段 频数 110~ 1 112~ 3 114~ 9 116~ 9 118~ 15 120~ 18 122~ 21 124~ 14 126~ 10 128~ 4 130~ 3 132~ 2 134~136 1对此数据做描述性分析。
回答下列问题:(1) SPSS 数据工作表;(2)身高的平均数、中位数、众数、标准差和极差各是多少? (3)身高是否是有偏分布?如果是,是右偏还是左偏?为什么? 三、实验操作分析题(15分)某啤酒厂生产三种类型啤酒:淡啤酒、普通啤酒、黑啤酒。
根据下列资料检验男性与女性饮酒者啤酒偏好是否相同。
回答下列问题:表3 男性与女性饮者啤酒偏好的样本数据(1)SPSS数据工作表;(2)选用SPSS过程;(3)SPSS的结果与解释(包括检验方法、统计量、P值和统计推断)。
四、实验操作分析题(15分)对10例肺癌病人和12例矽肺(硅沉着病)0期工人用X线片测量肺门横径右侧距RD值(cm),结果见表。

《数据分析与SPSS软件应用》试卷及答案一、填空题(每空2分,共20分)1. 统计分析所使用的数据按照其测量精度,可以分为四种类型,分别是定性数据、定序数据、和。
2. SPSS中可以进行变量转换的命令有。
3. 多选项二分法是将设置为一个SPSS变量,而多选项分类法是将设置为SPSS变量。
4. 进行两独立样本群均值比较前,首先要验证的是。
5. 协方差分析中,对协变量的要求是数值型,多个协变量间互相独立和。
6. 多配对样本的柯克兰Q检验适用的数据类型为。
7. 衡量定距变量间的线性关系常用相关系数。
8.常用来刻画回归直线对数据拟合程度的检验统计量指标为。
二、选择题(每小题2分,共20分)1. 在SPSS中,以下哪种不属于SPSS的基本运行方式?()A 完全窗口菜单方式B 批处理命令方式C 程序运行方式D 混合运行方式2. 设置变量属性时,不属于SPSS提供的变量类型的是()A 数值型B 科学计数型C 分数型D 字符型3. 数据的描述统计分析结果显示偏度值为-1.3,则下列对数据分布状态说法正确的是()A 左偏B 正偏C 与正态分布一致D 可能存在极大值4. 若原假设与备择假设为:,则:()A 应使用右侧单尾检验B 应使用左侧单尾检验C 应使用双尾检验D 无法检验5. 下列哪个不是单因素方差分析的基本假定?()A 各总体的均值相等B 各总体相互独立C 样本来自于正态总体D 各总体的方差相等6. 两个配对样本的Wilcoxon符号秩检验所对应的参数检验方法是?()A 两个独立总体均值差的检验B 两个配对总体均值差的检验C 一个总体均值的检验D 单因素方差分析7. 皮尔逊简单相关系数为1,说明()A 两变量之间不存在线性相关关系B 两变量之间是负相关关系C 两变量之间存在完全的线性相关关系D 两变量之间具有高度相关性8.下列说法正确的是()A回归分析是以变量之间存在函数关系为前提的B回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法C 回归分析中自变量个数只能为一个D 回归分析是反应确定性问题的统计分析方法9.以下关于聚类分析的叙述中错误的是()A 聚类分析的目的在于将事物按其特性分成几个聚类,使同一类内的事物具有高度相似性B 不同聚类的事物则具有高度的异质性C 对于衡量相似性,只能使用距离的工具D 建立聚类的方法,有层次聚类法和快速聚类法10. 关于因子分析,错误的说法是()A 适用于多变量、大样本B 原变量间不必要存在高度的相关性C定类和定序变量不适合做因子分析D 因子得分可以作为新变量存储在数据表格中三、判断题(每小题2分,共20分)1. SPSS中可将”.”用于变量命名,且”.”可以位于变量名末尾。

spss考试试题及答案一、选择题(每题2分,共20分)1. SPSS中,用于描述数据集中的观测值的中心趋势的统计量是:A. 方差B. 均值C. 标准差D. 众数答案:B2. 在SPSS中,以下哪个选项不是数据转换的方法?A. 计算变量B. 重新编码C. 描述统计D. 计算描述答案:C3. 在SPSS中,进行相关性分析的命令是:A. CORRELATEB. REGRESSIONC. T-TESTD. ANOVA答案:A4. SPSS中,用于创建新的变量或修改现有变量的命令是:A. COMPUTEB. DESCRIPTIVESC. AGGREGATED. RECODE答案:A5. 在SPSS中,用于比较两个独立样本均值差异的统计检验是:A. 卡方检验B. T检验C. 方差分析D. 相关性检验答案:B6. SPSS中,用于检查数据中是否存在缺失值的命令是:A. DESCRIPTIVESB. FREQUENCIESC. MISSING VALUESD. DETECT答案:A7. 在SPSS中,用于创建数据集的副本的命令是:A. SPLIT FILEB. SAVE ASC. TRANSPOSED. DATASET ACTIVATE答案:B8. SPSS中,用于生成数据集的频率分布表的命令是:A. DESCRIPTIVESB. FREQUENCIESC. CROSSTABSD. DESCRIPTIVES EXPLORE答案:B9. 在SPSS中,用于执行多重回归分析的命令是:A. REGRESSIONB. MANOVAC. FACTORD. CLUSTER答案:A10. SPSS中,用于绘制箱线图的命令是:A. CHARTSB. PLOTC. GRAPHD. EXAMINE答案:A二、简答题(每题5分,共20分)1. 请简述SPSS中数据清洗的步骤。
答案:数据清洗通常包括以下步骤:检查缺失值、异常值、错误数据,进行数据转换,以及数据标准化等。

华师18年9月课程考试《SPSS统计软件》作业考核试题答案华师18年9月课程考试《SPSS统计软件》作业考核试题1、C2、B3、C4、C5、C一、单选题共20题,40分1、定义性别变量时,假设用数值1表示男,用数值2表示女,需要使用到的工具是()A个案B变量名C变量名标签D变量值标签正确答案是:C2、下面偏度系数的值表明数据分布形态是正态分布的是()A1.429B0C-3.412D1正确答案是:B3、有效百分比是各频数占()的百分比。
A总次数B总样本量C有效样本量D缺失样本量正确答案是:C4、频数分析中常用的统计图不包括()A直方图B柱形图D条形图正确答案是:C5、变量的起名规则一般:变量名的字符个数不多于()A6B7C8D9正确答案是:C6、变量之间的关系可以分为两大类,它们是()。
A函数关系与相关关系B线性相关关系和非线性相关关系C正相关关系和负相关关系D简单相关关系和复杂相关关系正确答案是:A7、复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。
ANOTBANDCORD都不是正确答案是:A8、数据编辑窗口中的一行称为一个()A变量B个案C属性D元组正确答案是:B9、在横向合并数据文件时,两个数据文件都必须事先按关键变量值()A升序排序C不排序D可升可降正确答案是:A10、()是访问和分析Spss变量的唯一标识。
A个案B变量名C变量名标签D变量值标签正确答案是:B11、回归分析的第一步是()A确定解释和被解释变量B确定回归模型C建立回归方程D进行检验正确答案是:A12、工资、年龄、成绩等变量一般定义成()数据类型。
A字符型B数值型C日期型D圆点型正确答案是:B。

1.请使用SPSS计算21名从事某作业工人的血红蛋白量(g%)的均数、标准差、标准误、最大值、最小值、全距、几何均数。
数据如下:14.8 15.4 13.7 14.1 14.4 15.3 14.2 14.8 14.9 12.8 15.6 15.9 14.7 14.4 13.7 15.4 16.4 12.5 17.0 14.4 14.42.试用SPSS对下述数据进行正态性检验。
50例链球菌咽峡炎患者的潜伏期频数分布表潜伏期(小时)12~24~36~48~60~72~84~96~108~120病例数 1 7 11 11 7 5 4 2 2⑴把上述数据库文件转换成SPSS的数据文件;⑵生成两个新变量:理论课成绩:其值为主观和客观考试成绩之和,格式为整数;总评成绩:其值为理论成绩70%+实验课成绩30%,格式为小数点后保留一位;4.将钩端螺旋体病人的血清分别用标准株和水生株作凝溶试验,测得稀释倍数如下,问两组的平均效价有无差别?标准株(11人):100 200 400 400 400 400 800 1600 1600 1600 3200水生株( 9人):100 100 100 200 200 200 200 400 4005.52例麻疹患者恢复期血清麻疹病毒特异性1gG荧光抗体滴度的频数分布如下,求平均抗体滴度。
抗体滴度1:40 1:80 1:160 1:320 1:640 1:1280例数 3 2 17 19 0 16.A、B两因素伴随3H-TdR掺入对K562细胞抑制情况的试验结果如下表,相对抑制值越大,表明抑制能力越强。
试进行分析。
A:氧浓度重复试验编号B(药物)B1 B2 B3 B4A1(含氧3%) 1 0.31 0.46 0.29 0.492 0.18 0.39 0.18 0.513 0.12 0.40 0.12 0.624 0.13 0.34 0.13 0.53A2(含氧20%) 1 0.29 0.65 0.87 0.742 0.27 0.84 0.39 0.783 0.29 0.45 0.57 1.454 0.28 0.63 0.64 1.417.某医师研究A、B和C三种药物治疗肝炎的效果,将32只大白鼠感染肝炎后,按性别相同、体重接近的条件配成8个配伍组,然后将各配伍组中4只大白鼠随机分配到各组:对照组不给药物,其余三组分别给予A、B和C药物治疗。

笔试题型一、填空题(1×20=20分)二、判断题(2×10=20分)三、选择题(2×5=10分)四、上机计算填空题练习1.SPSS意为“统计产品与服务解决方案”它的英文全称是.2.SPSS分别由三个主要窗口,它们分别是:、输出窗口、语句窗口Syntax。
3.SPSS系统运行方式有三种,分别是完全窗口菜单运行管理方式、程序运行管理方式、混合运行管理方式4.常见对话框类型有文件操作对话框、统计分析对话框、其他选择项对话框。
5.对话框的构成:按钮、单选项、复选项、箭头按钮矩形、文本选择框6.SPSS 变量有三种基本类型: 、字符型、日期型。
7.Data 菜单中,命令Define dates的意思是:自动生成时间变量;那么Insert variable的意义是:8.9.10.11.变量的是对变量取值含义的解释说明,以明确数据的含义。
12.利用ANOVA 进行大中小城市16 岁男性青年平均身高的比较,结果给出sig.=0.043,说明:按照0.05 显著性水平,则H0假设。
13.Xy 是SPSS 的有效变量名,a+b SPSS 的有效变量名。
14.15.在描述性统计分析中,、众数、中位数等属于集中趋势指标。
、方差、最大值、标准误等描述统计量属于离散趋势指标。
16.(label)用于定义变量名标签,对变量名的含义进一步解释说明。
17.在数据分类汇总功能中,Split File 分割文件的功能是把当前工作逻辑上分割成两个或两个以上的组,随后的分析将对每个分组进行。
文件并没有真正变成两个文件。
18.在数据分类汇总功能中,Merge file是把两个文件按照要求横向或纵向合并,操作完成后两个文件合并成了一个文件19.合并文件(Merge file)中,选择Add cases是20.合并文件(Merge file)中,选择Add variables是21.22.、中位数、最大值、标准差等都属于描述性统计量。


华师17年9月课程考试《明清小说史》作业考核试题一、单选题(共 10 道试题,共 30 分。
)1. 下列故事情节,不属于《红楼梦》的是()。
A. 晴雯撕扇B. 黛玉葬花C. 刘姥姥进大观园D. 高老庄招亲正确答案:D2. 基本上实现了从类型化人物向性格化人物转变的小说是()。
A. 《三国演义》B. 《金瓶梅》C. 《儒林外史》D. 《红楼梦》正确答案:B3. 《聊斋志异》的文体类型是()。
A. 文言长篇小说B. 文言短篇小说C. 白话长篇小说D. 白话短篇小说正确答案:B4. 长篇小说《红楼梦》是()。
A. 历史演义B. 英雄传奇C. 神魔小说D. 世情小说正确答案:D5. 产生于清初的()是中国讽刺小说的代表作。
A. 《三国演义》B. 《金瓶梅》C. 《儒林外史》D. 《红楼梦》正确答案:C6. 金圣叹评点过的明代著名长篇小说是()。
A. 《三国演义》B. 《水浒传》C. 《西游记》D. 《红楼梦》正确答案:B7. 蒲松龄的代表作《聊斋志异》继承六朝志怪与()的传统,又有所创造发展。
A. 唐诗B. 宋词C. 元曲D. 唐传奇正确答案:D8. 英雄传奇讲述江湖中寻走的英雄、侠客等,代表作是()。
A. 《三国演义》B. 《水浒传》C. 《西游记》D. 《红楼梦》正确答案:B9. 《红楼梦》前()回为曹雪芹著,后四十回现在一般认为是高鹗所续。
A. 五十B. 六十C. 七十D. 八十正确答案:D10. ()完整地叙写了一次农民起义的全过程。
A. 《三国演义》B. 《水浒传》C. 《西游记》D. 《红楼梦》正确答案:B华师17年9月课程考试《明清小说史》作业考核试题二、多选题(共 10 道试题,共 40 分。
)1. 拟话本小说的代表作品有()。
A. 冯梦龙的“三言”B. 凌濛初的“二拍C. 陆人龙的“一型”D. 蒲松龄的《聊斋志异》正确答案:ABC2. 明代小说从语言媒体角度可分为()。
A. 文言小说B. 白话小说C. 写实小说D. 浪漫小说正确答案:AB3. 《水浒传》中梁山英雄好汉人人都有绰号,这些绰号非常形象,具有脸谱化的功能。
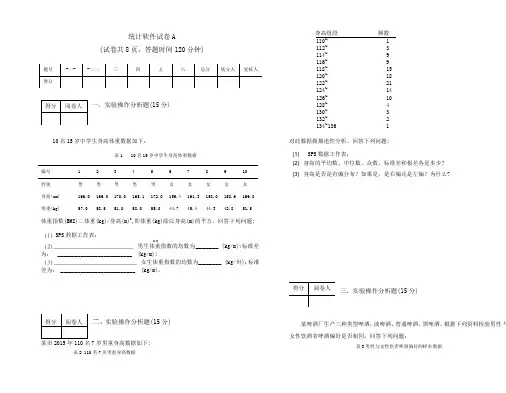
统计软件试卷A(试卷共8页,答题时间120分钟)题号-一--二二三四五六总分统分人复核人得分得分 阅卷人一、实验操作分析题(15分)110~ 1 112~ 3 114~ 9 116~ 9 118~ 15 120~ 18 122~ 21 124~ 14 126~ 10 128~ 4 130~ 3 132~ 2 134~136 1身高组段 频数10名15岁中学生身高体重数据如下: 对此数据做描述性分析。
回答下列问题: 编号 1 2 3 4 5 6 7 8910性别 男 男 男 男 男 女 女 女 女 女 身高(cm) 166.0 169.0 170.0 165.1 172.0 159.4 161.3 158.0 158.6 169.0 体重(kg)57.0 58.5 51.0 58.0 55.0 44.7 45.4 44.3 42.8 51.5 表1 10名15岁中学生身高体重数据(1)SPS 数据工作表;(2) 身高的平均数、中位数、众数、标准差和极差各是多少? (3) 身高是否是有偏分布?如果是,是右偏还是左偏?为什么?体重指数(BMI)二体重(kg)/身高(m)2,即体重(kg)除以身高(m)的平方。
回答下列问题: (1) SPS 敎据工作表; 2 2 (2) _________________________ 男生体重指数的均数为 ________ (kg/m);标准差为: __________________________ (kg/m); (3) __________________________ 女生体重指数的均数为 ________ (kg/卅);标准差为: __________________________ (kg/m)。
得分阅卷人三、实验操作分析题(15分)得分阅卷人实验操作分析题(15分)某市2015年 110名7岁男童身高数据如下:某啤酒厂生产三种类型啤酒:淡啤酒、普通啤酒、黑啤酒。
1、习题5-4用某药治疗6位高血压病人,对每一位病人治疗前、后的舒张压进行了测量,结果如下表所示:治疗前后的舒张压测量表(2)治疗前后病人的血压是否有显著变化?将数据录入SPSS软件中,进行两配对样本T检验,分析结果如下表所示:表一统计量表二配对样本相关系数表从表一中可以看出,治疗前后高血压病人的舒张压的平均值分别为124.67、118.67,说明治疗后舒张压的平均值降低了;治疗前后这6位病人的标准分别为13.246、18.217,治疗后标准差增大了。
从表三中可以看出,治疗前后这6位病人的舒张压的差值序列的平均值为6,计算出的T统计量为1.061,其相伴概率值为0.337,比显著性水平要大,因此,不能拒绝T检验的原假设,也就是说治疗前后病人的舒张压没有显著的变化。
从两个样本平均值可以看出,治疗后的舒张压比治疗前的并没有降低很多,于是我们认为药物没有起到治疗作用。
某学校要对两位老师的教学质量进行评价,这两位老师分别教甲班和乙班,这两班数学课成绩如下表所示,这两个班的成绩是否存在差异?甲、乙两班数学考试成绩将数据录入SPSS 软件中,进行两独立样本T 检验,得到分析结果如下表所示:表一 统计量从表一中可以看出两个班数学成绩的平均值分别为83.60和75.45,对应的标准差分别为6.7、9.179,很明显甲班的数学平均成绩高于乙班。
从表二中可以得知,F 统计量的值为1.11,对应的相伴概率值为0.299,大于显著性水平0.05,不能拒绝方差相等的假设,可以认为两个老师所带的班级学生的数学成绩的方差没有显著性差异;然后观察在方差相等的条件下T 检验的结果,T 统计量的相伴概率值为0.003,小于显著性水平0.05,因此拒绝T 检验的原假设,即甲乙两班学生的数学成绩存在显著差异,从两个班数学成绩的平均值可以看出,甲班的成绩高于乙班。
甲班 90 93 82 88 85 80 87 85 74 90 88 83 82 85 73 86 77 94 68 82 乙班 76 75 73 75 98 62 90 75 83 66 65 78 80 68 87 74 64 68 72 80某职业病研究所对29名矿工中肺矽病患者、可疑患者和非患者进行了用力肺活量测定,如表6-4所示,问3组矿工的用力肺活量有无差别?用力肺活量测定数据(单位:L)肺矽病患者 1.8 1.4 1.3 1.5 1.9 1.6 1.6 1.7 2 2.1可疑患者 2.1 2.3 2.6 2.1 2.5 2.1 2.4 2.4 2.1非患者 2.8 2.9 3.2 3 3.4 3.5 3.4 2.9 3.2 3.3将数据录入SPSS软件中,进行单因素方差分析,得到分析结果如下表所示:表一方差齐性检验由上表可以看出,p值大于显著性水平0.05,因此无法拒绝方差齐性的原假设,即各个组总体方差是相等的,根据方差检验的前提条件要求,这组数据是适合进行单因素方差分析的。
华中师范大学网络教育学院《SPSS统计软件》练习题库及答案(本科)一、选择题(选择类)(A)1、在数据中插入变量的操作要用到的菜单是:A Insert Variable;B Insert Case;C Go to Case;D Weight Cases(C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:A Sort Cases;B Select Cases;C Compute;D Categorize Variables(C)3、Transpose菜单的功能是:A 对数据进行分类汇总;B 对数据进行加权处理;C 对数据进行行列转置;D 按某变量分割数据(A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明:A. 按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别;B. 三种城市身高没有差别的可能性是0.043;C. 三种城市身高有差别的可能性是0.043;D. 说明城市不是身高的一个影响因素(B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异;B 服用某种药物前后病情的改变情况;C 服用药物和没有服用药物的病人身体状况的差异;D性别和年龄对雇员薪水的影响二、填空题(填空类)6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。
8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。
三、名词解释(问答类)9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。
spss应用教程考试题及答案一、选择题(每题2分,共20分)1. 在SPSS中,数据文件的扩展名是什么?A. .txtB. .xlsC. .savD. .csv答案:C2. SPSS中,用于描述数据集中变量分布情况的统计图是?A. 散点图B. 箱线图C. 条形图D. 饼图答案:B3. 在SPSS中进行相关分析时,通常使用哪个菜单?A. 分析B. 转换C. 描述统计D. 数据管理答案:A4. 如何在SPSS中创建一个新变量?A. 通过数据菜单下的“计算变量”B. 通过转换菜单下的“计算变量”C. 通过分析菜单下的“计算变量”D. 通过文件菜单下的“计算变量”5. 在SPSS中,进行回归分析应该选择哪个菜单?A. 分析B. 转换C. 数据管理D. 描述统计答案:A6. SPSS中,用于比较两组数据均值差异的统计检验是?A. t检验B. 方差分析C. 卡方检验D. 相关分析答案:A7. 在SPSS中,如何对数据进行排序?A. 通过数据菜单下的“排序案例”B. 通过转换菜单下的“排序案例”C. 通过分析菜单下的“排序案例”D. 通过文件菜单下的“排序案例”答案:A8. SPSS中,用于创建数据子集的选项位于哪个菜单下?A. 数据B. 转换C. 分析D. 文件答案:A9. 在SPSS中,执行因子分析应该选择哪个菜单?B. 转换C. 数据管理D. 描述统计答案:A10. SPSS中,如何查看数据的频率分布表?A. 通过分析菜单下的“描述统计”中的“频率”B. 通过转换菜单下的“描述统计”中的“频率”C. 通过数据菜单下的“描述统计”中的“频率”D. 通过文件菜单下的“描述统计”中的“频率”答案:A二、填空题(每空1分,共20分)1. 在SPSS中,数据的录入可以通过________菜单下的“输入数据”来完成。
答案:数据2. SPSS中,数据的导出可以通过________菜单下的“导出数据”来实现。
答案:文件3. 当需要对数据进行分组分析时,可以使用SPSS中的________功能。
一、单项选择题: (本大题小题,1 分/每小题,共分)1.SPSS 的数据文件后缀名是 : A(A).sav (B).dbf (C).exe (D).com2.对数据的各种统计处理, SPSS 是在下面哪一个选项中进行: A(A)数据编辑窗口; (B)数据显示窗口; (C)数据输出窗口; (D)任意一个窗口均可;3.在 SPSS 中,下面哪一个不是 SPSS 的运行方式 A(A)输入运行方式; (B)完全窗口菜单方式; (C)程序运行方式; (D)混合运行方式;4.下面哪一个选项不属于 SPSS 的数据分析步骤: D(A)定义数据文件结构; (B)录入、修改和编辑待分析数据;(C)进行统计分析; (D)数据扩展;5.在 SPSS 中,下面哪一个选项不属于对变量 (列)的描述: B(A)变量名称; (B)变量名称大小; (C)变量宽度; (D)变量对齐方式6.在 SPSS 的定义中,下面哪一个变量名的定义是错误的: C(A)ABC_C; (B)ABC; (C)A_&_A; (C)A_BFG_;7.在 SPSS 的定义中,下面哪一个变量名的定义是错误的: C(A)AND; (B)A_BC; (C)B_&_A; (C)A_BFG;8.在 SPSS 数据文件中,下面那一项不属于数据的结构: D(A)变量类型; (B)变量值说明; (C)数据缺失值情况; (D)数据值;9.在 SPSS 数据文件中,下面那一项属于数据的内容: D(A)变量类型; (B)变量值说明; (C)数据缺失值情况; (D)数据值;10. 通常来说,发放了 900 份问卷,可直接得到的有效问卷有 800 份,则 SPSS 所建立的相关数据文件中的行数为 D(A)900; (B)600; (C)820 (D)800;11.下面那一项不属于 SPSS 的基本变量类型: D(A)数值型; (B)字符串型; (C)日期型; (D)整数型;12. 当在 SPSS 数据文件中输入变量为“职工姓名”,则应选择的变量类型是: B(A)数值型; (B)字符串型; (C)日期型; (D)整数型;13. 当在 SPSS 数据文件中输入变量为“职工工资数”,则应选择的变量类型是: A(A)数值型; (B)字符串型; (C)日期型; (D)整数型;13. 当在 SPSS 数据文件中输入变量为“公司成立日期”,则应选择的变量类型是: C(A)数值型; (B)字符串型; (C)日期型; (D)整数型;14.在 SPSS 的数据结构中,下面那一项不是“缺失数据”的定义: D(A)数据缺失; (B)数据不合理; (C)数据明显错误; (D)数据不是科学计数法;15.统计学依据变量的计量尺度将变量分为三类,以下哪一类不属于这三类: D(A)数值型变量; (B)定序型变量; (C)定类型变量; (D)科学计数类型;16.在统计学中,变量“身高”属于计量尺度中的: A(A)数值型变量; (B)定序型变量; (C)定类型变量; (D)科学计数类型;17.在统计学中,将变量“年龄”分为“老年”、“中年”、“青年”三个取值,分别用 1 、2 、3 表示,则变量“年龄”属于计量尺度中的: B(A)数值型变量; (B)定序型变量; (C)定类型变量; (D)科学计数类型;18.在统计学中,将变量“性别”分为“男”、“女”、两个取值,分别用 1、2 表示,则变量“性别”属于计量尺度中的: C(A)数值型变量; (B)定序型变量; (C)定类型变量; (D)科学计数类型;19.下面哪一个选项不能被 SPSS 系统正常打开: D(A)SPSS 文件格式; (B)excel 文件格式; (C)文本文件格式; (D)可执行文件格式;20. 下面哪一个选项不能被 SPSS 系统正常打开: D(A).sav; (B).xls; (C).dat; (D).exe;21.在 SPSS 数据编辑窗口中,需要定义变量的数据结构,以下哪一项不属于变量的数据结构:D(A)变量名; (B)变量类型; (C)变量名标签; (D)变量值;22. 在 SPSS 数据结构中,下面哪一项不属于数据类型: D(A)数值型; (B)字符型; (C)日期型; (D)数值标签型;23.下面哪一个选项不是 SPSS 中定义的基本描述统计量: D(A)均值; (B)方差; (C)标准差; (D)回归函数;24.下面哪一个选项不是 SPSS 中定义的基本描述统计量: D(A)样本标准差; (B)全距; (C)偏度系数; (D)因子;25.下面那一项刻画了随机变量分布形态的对称性: D(A)均值; (B)方差; (C)标准差; (D)偏度系数;26.下面那一项刻画了随机变量分布形态陡缓程度: D(A)均值; (B)方差; (C)标准差; (D)峰度系数;27.对于 SPSS 来说,下面那一项不包括在变量的频数分布内容中: D(A)频数; (B)百分比; (C)有效百分比; (D)均值;27.对于 SPSS 来说,下面那一项不包括在变量的频数分布内容中: C(A)频数; (B)百分比; (C)标准差; (D)累积百分比;28.在 SPSS 中,下面那一项不是频数分析中常用的统计图形: D(A)柱状图或者条状图; (B)饼图; (C)直方图; (D)分类图;29.在 SPSS 中,当需要对变量进行频数分析时,需要选择下面那一项菜单: C(A)视图; (B)文件; (C)分析; (D)图形;30.在进行数据的统计分析之前,一般需要完成数据的预处理,以下哪一项不属于数据的预处理内容: B(A)缺失值和异常数据的处理; (B)峰度和偏度处理; (C)数据的转换处理; (D)数据抽样;31.在 SPSS 中,当我需要对原有某个变量的数据进行取对数运算时,应选取下面那一项进行处理: A(A)变量计算; (B)数据排序; (C)数据选取; (D)计数;32.在 SPSS 中,下面那一项不属于数据分组的目的: D(A)有利于连续数据的频数分析; (B)可实现连续数据的离散化;(C)更能概括和体现出数据的分布特征; (D)有利于进行因子分析;33.对于 SPSS 中的组距分组,下面那一项是正确的说法: A(A)分组数与数据本身特点和数据个数有关; (B)分组的目的是为了减少数据数目;(C)通常来说,组数少点更易于进行分析; (D)组数多点有利于观察数据分布的特征和规律;34.对于 SPSS 来说,能够快捷找到变量数据的最大值和最小值的数据预处理方法是: A(A)排序; (B)分类汇总; (C)变量计算; (D)分组;35.对于 SPSS 来说,能够快捷找到变量数据的异常值的数据预处理方法是: A(A)排序; (B)分类汇总; (C)变量计算; (D)分组;36.在学生的一张数据表中,有平时分数、实验分数和卷面分数,如使用 SPSS 计算最终得分,则需要使用 SPSS 预处理中的: C(A)排序; (B)分类汇总; (C)变量计算; (D)分组;37.在 SPSS 中,以下哪个选项可以完成如下功能:由收集的整体数据中抽取出年龄大于 30 的数据: A(A)数据选取; (B)分组; (C)排序; (D)计算;38.下面哪一个选项不是对数据的基本统计分析: C(A)编制单个变量的频数分布表; (B)计算单个变量的描述统计量;(C)编制多变量的交叉频数分布表; (D)实现变量的排序与合并;39.在 SPSS 中,当变量是数值型时,则频数分析所用图形为: A(A)直方图; (B)饼图; (C)柱状图; (D)条形图;40.在 SPSS 中,当需要选取出满足某一个条件的所有个案,则使用下面的那一项: A(A)个案选择; (B)个案排序; (C)变量计算; (D)个案计数;41.在 SPSS 中,均值的计算适合下面那一项: A(A)定距型; (B)定类型; (C)定序型; (D)全都适合;42.现有一批数据为(0,1,2,-2,3,-3,4) ,则这批数据的极差为: A(A)7; (B)6; (C)3(D)4;43.以下图是某随机变量的概率密度,请问其峰度是:(A)大于零; (B)小于零; (C)等于零; (D)全错;44. 以下图是某随机变量的概率密度,请问其峰度是:(A)大于零; (B)小于零; (C)等于零; (D)全错;45. 以下图是某随机变量的概率密度,请问其峰度是: C(A)大于零; (B)小于零; (C)等于零; (D)全错;46.单因素方差分析的第一步是明确观测变量和控制变量,例如,当分析不同施肥量是否对农产品产量带来显著影响、地域差别是否对妇女生育率有关系和学历对工资的作用关系时,控制变量分别是: A(A)施肥量、地域和学历; (B)施肥量、生育率和学历;(C)施肥量、地域和工资; (D) 农产品产量、地域和学历;47. 单因素方差分析的第一步是明确观测变量和控制变量,例如,当分析不同施肥量是否对农产品产量带来显著影响、地域差别是否对妇女生育率有关系和学历对工资的作用关系时,观测变量分别是: A(A)农产品产量、妇女生育率和工资; (B)施肥量、生育率和学历;(C)施肥量、地域和妇女生育率; (D)妇女生育率、地域和学历;48. 当需要分析多个随机变量之间的相互影响和关系时,在 SPSS 中应使用下面哪一个选项:D(A)方差; (B)均值; (C)峰度; (D)交叉分组下的频数分析;49.下面那一种情况下,可以使用交叉列联表中来进行卡方分布检验: A(A)列联表单元格的全部期望频数都大于 6; (B)列联表中有 1 个单元格内的期望频数为 1;(C)列联表中有 30%单元格的期望频数小于 5; (D)列联表中有 2 个单元格内期望频数为 1;50. 当需要分析某一个变量的分布情况时,采用下面那一个选项较为合适: A(A)频数分析; (B)方差分析; (C)列联表分析; (D)假设检验;51.在统计分析中,描述变量的数据离散程度的基本统计量是: A(A)标准差; (B)偏度; (C)峰度; (D)中位数;52.在统计分析中,描述变量数据分布的中心位置的基本统计量是: D(A)标准差; (B)偏度; (C)峰度; (D)均值;53.在统计分析中,描述变量数据分布的对称程度的基本统计量是: B(A)标准差; (B)偏度; (C)峰度; (D)均值;54.在统计分析中,描述变量的数据分布的陡峭程度的基本统计量是: C(A)标准差; (B)偏度; (C)峰度; (D)均值;55.下面那一种说法是正确的: A(A)偏度大于零,则数据分布的长尾巴在右边;(B)偏度大于零,则数据分布的长尾巴在左边;(C)偏度大于零,则数据分布没有尾巴;(D) 偏度等于零,则数据分布的长尾巴在左边;56.下图中右下角的问号应选择: C(A)均值; (B)方差; (C)参数检验; (D)峰度57.在得到一批未知其总体分布的数据后,可使用以下哪种方法验证其是否与某个已知理论 分布相吻合: C(A)计算均值; (B)计算方差; (C)参数检验; (D)非参数检验;58. 需要检验一批未知的连续数值型随机单样本是否是正态分布,则需要下面的那一项: D(A)t 检验; (B)方差检验; (C)标准差检验; (D)K-S 检验;59.已知某一分布是正态分布的随机变量 x 的均值为 ,方差为 Q 2 ,则将其转换成标准正态 分布(即均值为 0,标准差为 1)的公式是: A(A) (x ); (B) (x ); (C) (x ); (D) (x Q ); Q Q 2 n60.下面那一项不是两独立样本 t 检验的前提条件: D(A)样本来自的总体应服从或近似服从正态分布;(B)两样本相互独立;(C)从一个总体抽取一个样本对从另一总体抽取样本没有任何影响;(D)两个样本的方差必须相等;61.设待检验两个总体的均值分别为 1 、 2 ,则相关的两独立样本 t 检验的假设 H 0 是: A(A) H 0 :1 2 = 0; (B) H 0 : 1 2 0;(C) H 0 : 1 2 0; (D) H 0 : 1 2 < 0; 62.在交叉列联表检验中,行数为 6, 列数为 7,则当变量间独立时所对应卡方分布的自由度 是: A(A)30; (B)42; (C)13; (D)1;63.在交叉列联表检验中,当变量间独立时所对应检验统计量的分布是: A(A)开方分布; (B)F 分布; (C)t 分布; (D)s 分布;64.已知两批独立随机样本都服从正态分布,要检验这两批随机样本的方差是否相同,则需 要采用: A(A)F 检验; (B)t 检验; (C)S 检验; (D)Q 检验;65. . 已知两批独立随机样本都服从正态分布,要检验这两批随机样本的均值是否相同,则需 要采用: B(A)单样本 t 检验; (B)两独立样本 t 检验; (C)S 检验; (D)Q 检验;66. 已知一批独立随机样本服从正态分布, 要检验这批随机样本的均值是否与某总体分布的 均值相同,则需要采用: A(A)单样本 t 检验; (B)两独立样本 t 检验; (C)S 检验; (D)Q 检验;67.下面那一项不属于假设检验的基本步骤: B(A)提出原假设和备择检验; (B)画出随机样本的直方图;(C)选择检验统计量; (D)计算检验统计量的概率, 并将其与显著性水平的大小做出统计决策;68.当样本的分布未知,需要利用样本的数据推断出总体分布形态的方法是: A(A)非参数检验; (B)参数检验; (C)方差检验; (D)因子分解;69. 在总体分布未知的情况下,利用样本数据对所假定总体的分布进行显著性检验的方法 是: B统计方法推断统计参数检验非参数检验 描述统计 参数估计(A)参数检验; (B)非参数检验; (C)方差检验; (D)回归检验;70.现有两段独立样本数据,欲判断它们之间的分布是否存在显著性差异,则可采用: B(A)参数检验; (B)非参数检验; (C)方差检验; (D)回归检验;71.单样本的总体分布卡方检验属于: C(A)参数检验,用于比较均值; (B)非参数检验,用于比较方差;(C)非参数检验,用于了解样本的分布是否与某一已知的理论分布吻合;(D)方差检验;72. 单样本 K-S 检验属于: C(A)参数检验,用于比较均值; (B)非参数检验,用于比较方差;(C)非参数检验,用于了解连续数值型样本的分布是否与某一已知的理论分布吻合;(D)方差检验;73. 两配对样本 t 检验的目的是: A(A)推导出来自于两个总体的配对样本的均值是否存在显著性差异;(B)推导出来自于两个总体的独立样本的均值是否存在显著性差异;(C)推导出来自于两个总体的配对样本的分布是否存在显著性差异;(D)推导出来自于两个总体的独立样本的均值是否存在显著性差异;74.以下是使用 SPSS 所做的非参数检验的结果图,根据所给图选择正确的一项: A:(A)接受假设 H0; (B)拒绝假设 H0; (C)不好说; (D)以上都不正确;75.样本值序列为 1011011010011000101010000111,则整段样本值序列的游程数是: A(A)17; (B)20; (C)10; (D)16 ;75.样本值序列为男男女女女男女女男男男男,则整段样本值序列的游程数是: A(A)5; (B)7; (C)10; (D)3 ;76.样本值序列为男男男男男男男女女女女女,则整段样本值序列的游程数是: A(A)2; (B)7; (C)10; (D)3;77. 样本值序列为男男男男男男男女女女女女,则整段样本值序列的游程数是: A(A)2; (B)7; (C)10; (D)3;78. 样本值序列为男女男女男女男女男女男男,则整段样本值序列的游程数是: C(A)10; (B)7; (C)11; (D)9;79. 样本值序列为00110111000100100010,则整段样本值序列的游程数是: C(A)10; (B)7; (C)11; (D)9;80. 样本性质下面的那一项可适用于两独立样本的曼 -惠特尼 U 检验: A(A)样本秩; (B)样本数值; (C)均值; (D)方差;81. 样本性质下面的那一项可适用于两独立样本的 K-S 检验: A(A)样本秩; (B)样本数值; (C)均值; (D)方差;82 .下图是某两独立样本的游程检验示意图,请问图中数据的游程数是: A(A)6; (B)8; (C)5; (D)7;83.K-S 检验可用于: B(A)均值检验; (B)非参数检验; (C)参数检验; (D)方差检验;84.下面那一选项是独立样本: A(A)分别对两批不同年级的大学生调查他们的学习兴趣;(B)对同一批人,观察他们服用减肥茶前后的体重;(C)对同一批运动员,观察一种新的训练方法对他们运动成绩的影响;(D)分析同一批商品使用不同的销售手段下的销售量;85.现有一批数据: 2.3, 1.2, 3.8, 6, 9,则 6 的秩是: C(A)3; (B)2; (C)4, (D)686. 观察某新开发的饲料对猪的影响:首先不用这个饲料,测量猪在一个月的体重;再在下一个月内使用新饲料喂养同一批猪,测量体重;实验者想知道前后两个月猪的体重的分布是否有差别,则可用以下哪一项进行检验: B(A)非参数检验; (B)参数检验; (C)方差检验; (D)均值检验;87. 观察某新的营销手段对商品销售量的影响:首先不用这个营销手段,测量 10 种商品在一个月的销售量;再在下一个月内使用该新营销手段处理同样这 10 种商品,测量销售量;实验者想知道这新的营销手段是否对商品的销售量有显著性区别,则可用以下哪一项进行检验(销售量的分布未知 ): A(A) 非参数检验中的两配对样本检验;(B) 非参数检验中的两独立样本检验;(C) 参数检验中的两配对样本检验;(D) 参数检验中的两独立样本检验;88.观察性别是否对书籍种类的购买意愿有差别:随机选择 20 个男同学,随机选择 30 个女同学,分别调查他们对书籍的购买意愿,调查者想知道性别对数据种类的购买是否有影响,则可使用(男和女同学购买数据的分布是正态分布 ): D(A) 非参数检验中的两配对样本检验;(B) 非参数检验中的两独立样本检验;(C) 参数检验中的两配对样本检验;(D) 参数检验中的两独立样本检验;89.在假设检验中,秩的概念主要用在下面那一项中: B(A)参数检验; (B)非参数检验; (C)方差检验; (D)均值检验;90.现有一种饲料,使用不同的数量来喂养动物,测量出不同喂养量情况下动物的体重,现欲知道动物的体重是否与不同喂养量有关,则采用下面那一项: D(A)参数检验; (B)K-S 检验; (C)卡方检验; (D)方差检验;91.使用某种肥料对 10 块玉米田的产量进行实验,分别在每块田内使用 0 公斤、 1 公斤、 2 公斤、 3 公斤、 4 公斤、 5 公斤该肥料,再测量出每种肥料使用量和每块田的产量,当使用方差分析时,下面哪一个说法是正确的: A(A)肥料量是控制变量,每块田的产量是观测变量;(B) 每块田的产量是控制变量,肥料量是观测变量;(C)所有田的产量之和是控制变量,肥料量是观测变量;(D)所有田的肥料量之和是控制变量,产量是观测变量;92.在制定某商品广告宣传策略时,广告效果可能会受到广告形式、地区规模、选择的栏目、播放的时间段、播放的频率等因素的影响。
华师18年9月课程考试《SPSS统计软件》作业考核试题1、C2、B3、C4、C5、C一、单选题共20题,40分1、定义性别变量时,假设用数值1表示男,用数值2表示女,需要使用到的工具是()A个案B变量名C变量名标签D变量值标签正确答案是:C2、下面偏度系数的值表明数据分布形态是正态分布的是()A1.429B0C-3.412D1正确答案是:B3、有效百分比是各频数占()的百分比。
A总次数B总样本量C有效样本量D缺失样本量正确答案是:C4、频数分析中常用的统计图不包括()A直方图B柱形图C树形图D条形图正确答案是:C5、变量的起名规则一般:变量名的字符个数不多于()A6B7C8D9正确答案是:C6、变量之间的关系可以分为两大类,它们是()。
A函数关系与相关关系B线性相关关系和非线性相关关系C正相关关系和负相关关系D简单相关关系和复杂相关关系正确答案是:A7、复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。
ANOTBANDCORD都不是正确答案是:A8、数据编辑窗口中的一行称为一个()A变量B个案C属性D元组正确答案是:B9、在横向合并数据文件时,两个数据文件都必须事先按关键变量值()A升序排序B降序排序C不排序D可升可降正确答案是:A10、()是访问和分析Spss变量的唯一标识。
A个案B变量名C变量名标签D变量值标签正确答案是:B11、回归分析的第一步是()A确定解释和被解释变量B确定回归模型C建立回归方程D进行检验正确答案是:A12、工资、年龄、成绩等变量一般定义成()数据类型。
A字符型B数值型C日期型D圆点型正确答案是:B。
《SPSS统计软件》课程作业要求:数据计算题要求注明选用的统计分析模块和输出结果;并解释结果的意义。
完成后将作业电子稿发送至1. 某单位对100名女生测定血清总蛋白含量,数据如下:74.3 78.8 68.8 78.0 70.4 80.5 80.5 69.7 71.2 73.579.5 75.6 75.0 78.8 72.0 72.0 72.0 74.3 71.2 72.075.0 73.5 78.8 74.3 75.8 65.0 74.3 71.2 69.7 68.073.5 75.0 72.0 64.3 75.8 80.3 69.7 74.3 73.5 73.575.8 75.8 68.8 76.5 70.4 71.2 81.2 75.0 70.4 68.070.4 72.0 76.5 74.3 76.5 77.6 67.3 72.0 75.0 74.373.5 79.5 73.5 74.7 65.0 76.5 81.6 75.4 72.7 72.767.2 76.5 72.7 70.4 77.2 68.8 67.3 67.3 67.3 72.775.8 73.5 75.0 73.5 73.5 73.5 72.7 81.6 70.3 74.373.5 79.5 70.4 76.5 72.7 77.2 84.3 75.0 76.5 70.4计算样本均值、中位数、方差、标准差、最大值、最小值、极差、偏度和峰度,并给出均值的置信水平为95%的置信区间。
解:样本均值为:73.6680;中位数为:73.5000;方差为:15.515;标准差为:3.93892;最大值为:84.30;最小值为:64.30;极差为:20.00;偏度为:0.054;峰度为:0.037;均值的置信水平为95%的置信区间为:【72.8864,74.4496】。
2. 绘出习题1所给数据的直方图、盒形图和QQ图,并判断该数据是否服从正态分布。
华师17年9月课程考试《SPSS统计软件》作业考核试题
一、单选题(共 20 道试题,共 40 分。
)
1. 数据选取的方法中,()是按符合条件的数据进行选取。
A. 按指定条件选取
B. 随即选取
C. 选取某一区域内样本
D. 过滤变量选取
正确答案:A
2. 下列()散点图只可以表示一对变量间统计关系。
A. 简单散点图
B. 重叠散点图
C. 矩阵散点图
D. 三维散点图
正确答案:A
3. SPSS中进行数据的排序应选择()主窗口菜单。
A. 视图
B. 编辑
C. 数据
D. 分析
正确答案:C
4. spss输出结果保存时的文件扩展名是()
A. .sav
B. .spv
C. .dat
D. .sas
正确答案:B
5. 对大学毕业班的同学的学习成绩惊醒综合评价,可以依次计算每个同学的若干门专业课中有几门课程是优,几门是良,并以门次为权重进行分析。
其中计算门次的过程就是一个()过程。
A. 计数
B. 分组
C. 聚类
D. 计算变量
正确答案:A
6. SPSS中生成新变量应选择()主窗口菜单。
A. 转换
B. 编辑
C. 数据
D. 分析
正确答案:A
7. 频数分析中常用的统计图包括()
A. 直方图
B. 柱形图
C. 饼图
D. 树形图
正确答案:C
8. 个体间的()通常通过某种距离来测度。
A. 差异程度
B. 相似程度
C. 相异程度
D. 相同程度
正确答案:A
9. 数据编辑窗口的主要功能有()
A. 定义SPSS数据的结构
B. 录入编辑和管理待分析的数据
C. 结果输出
D. A和B
正确答案:D
10. 回归分析的第一步是()
A. 确定解释和被解释变量
B. 确定回归模型
C. 建立回归方程
D. 进行检验
正确答案:A
11. SPSS中进行参数检验应选择()主窗口菜单。
A. 视图
B. 编辑
C. 文件
D. 分析
正确答案:D
12. 统计学依据数据的计量尺度将数据划分为三大类,它不包括()
A. 定值型数据
B. 定距型数据
C. 定序型数据
D. 定类型数据
正确答案:A
13. 有效百分比是各频数占()的百分比。
A. 总次数
B. 总样本量
C. 有效样本量
D. 缺失样本量
正确答案:C
14. 相关关系是指()。
A. 变量间的非独立关系
B. 变量间的因果关系
C. 变量间的函数关系
D. 变量间不确定性的依存关系
正确答案:D
15. 职工号码、姓名等变量一般定义成()数据类型。
A. 字符型
B. 数值型
C. 日期型
D. 圆点型
正确答案:A
16. ()的功能是显示管理SPSS统计分析结果、报表及图形。
A. 数据编辑窗口
B. 结果输出窗口
C. 数据视图
D. 变量视图
正确答案:B
17. 变量的起名规则一般:变量名的字符个数不多于()
A. 6
B. 7
C. 8
D. 9
正确答案:C
18. SPSS中聚类分析应选择()主窗口菜单。
A. 视图
B. 编辑
C. 数据
D. 分析
正确答案:D
19. SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。
A. 哈佛大学
B. 斯坦福大学
C. 波士顿大学
D. 剑桥大学
正确答案:B
20. 在横向合并数据文件时,两个数据文件都必须事先按关键变量值()
A. 升序排序
B. 降序排序
C. 不排序
D. 可升可降
正确答案:A
华师17年9月课程考试《SPSS统计软件》作业考核试题
二、多选题(共 15 道试题,共 30 分。
)
1. 下列()属于多选项问题。
A. 购买保险原因调查
B. 高考志愿调查
C. 储蓄原因调查
D. 各省市现代化指数分析
正确答案:ABC
2. ()可以刻画集中趋势。
A. 均值
B. 全距
C. 众数
D. 中位数
正确答案:ACD
3. SPSS中实现基本统计分析,往往采用两种方式()
A. 数值计算
B. 图形绘制
C. 计算均值
D. 频数分析
正确答案:AB
4. 进行频数分析时,利用的工具包括()
A. 散点图
B. 相关系数
C. 频数分布表
D. 条形图
正确答案:CD
5. ()可以刻画分布形态。
A. 标准差
B. 偏度系数
C. 峰度系数
D. 均值标准误差
正确答案:BC
6. 利用SPSS进行频数分析时,频数分布表中内容的输出顺序可以有()
A. 按变量值升序
B. 按变量值降序
C. 按频数升序
D. 按频数降序
正确答案:ABCD
7. ()是SPSS为用户提供的基本运行方式。
A. 完全窗口菜单方式
B. 程序运行方式
C. 混合运行方式
D. 以上都是
正确答案:ABCD
8. 方差分析的基本假设前提包括()
A. 各总体服从正态分布
B. 各总体相互独立
C. 各总体的方差应相同
D. 各总体的方差不同
正确答案:AC
9. 下列Z值()可以被认为是异常值。
A. 0
B. -3
C. 6
D. 10
正确答案:BCD
10. 交叉列联表中的内容包括()
A. 行变量
B. 列变量
C. 层变量
D. 组变量
正确答案:ABC
11. 数据分析一般经过()主要阶段。
A. 收集数据
B. 加工和整理数据
C. 分析数据
D. 检验数据
正确答案:ABC
12. 下列()可以通过频数分析获得。
A. 分位数
B. 最大值
C. 最小值
D. 方差
正确答案:ABCD
13. 下列关于数据排序正确的是()
A. 可以了解缺失值
B. 快速找到最大最小值
C. 计算全距
D. 快速发现异常值
正确答案:ABCD
14. 两配对样本t检验的前提()
A. 样本来自的总体服从或近似服从正态分布
B. 两样本观察值的先后顺序一一对应
C. 两样本的数量可以不相等
D. 两样本的数量相等
正确答案:ABD
15. 两独立样本t检验的前提()
A. 样本来自的总体服从或近似服从正态分布
B. 两样本相互独立
C. 两样本的数量可以不相等
D. 两样本的数量相等
正确答案:ABC
华师17年9月课程考试《SPSS统计软件》作业考核试题
三、判断题(共 15 道试题,共 30 分。
)
1. 在进行两独立样本t检验之前,正确组织数据是一个非常关键的任务。
()
A. 错误
B. 正确
正确答案:B
2. 对数据可以进行多重拆分,类似于数据的多重排序。
()
A. 错误
B. 正确
正确答案:B
3. 单样本t检验的前提是样本来自的总体应服从或近似服从正态分布。
()
A. 错误
B. 正确
正确答案:B
4. 样本方差也是表示变量取值离散程度的统计量()
A. 错误
B. 正确
正确答案:B
5. 两个数据文件必须至少有一个名称相同的变量,该变量是两个数据文件横向拼接的依据,称为关键变量。
()
A. 错误
B. 正确
正确答案:B
6. 一元线性回归模型为:y=β0+β1 x1+.......βpxp+e()
A. 错误
B. 正确
正确答案:A
7. SPSS的分析结果显示区可以分为目录区和内容区两个部分。
()
A. 错误
B. 正确
正确答案:B
8. 两配对样本t检验是通过转化成单样本t检验来实现的。
()
A. 错误
B. 正确
正确答案:B
9. 数据排序是整行数据排序,而不是只对某列变量排序。
()
A. 错误
B. 正确
正确答案:B
10. 配对样本的一个特征是:两组样本的样本量相同。
()
A. 错误
B. 正确
正确答案:B
11. 样本标准差是表示变量取值距均值的平均离散程度的统计量()
A. 错误
B. 正确
正确答案:B
12. sav文件格式可以使用Word,Excel等软件打开。
()
A. 错误
B. 正确
正确答案:A
13. 变量值标签是对变量取值含义的解释说明信息,对于定类型和定距型数据尤为重要()
A. 错误
B. 正确
正确答案:A
14. SPSS数据的输入和结果的输出是在同一窗口进行的。
()
A. 错误
B. 正确
正确答案:A
15. 变量的起名规则中,首字符应以中文开头,后面可以跟 . ()
A. 错误
B. 正确
正确答案:B。