Excel回归分析结果的详细阐释
- 格式:doc
- 大小:339.00 KB
- 文档页数:7

Excel做线性回归分析基本原理及实例一、原理1、回归分析原理由一个或一组非随机变量来估计或预测某一个随机变量的观测值时,所建立的数学模型及所进行的统计分析,称为回归分析。
按变量个数的多少,回归分析有一元回归分析与多元回归分析之分,多元回归分析的原理与一元回归分析的原理类似。
按变量之间关系的形式,回归分析可以分为线性回归分析和非线性回归分析。
2、回归分析的主要内容回归分析的内容包括如何确定因变量与自变量之间的回归模型;如何根据样本观测数据,估计并检验回归模型及未知参数;在众多的自变量中,判断哪些变量对因变量的影响是显著的,哪些变量的影响是不显著的;根据自变量的已知值或给定值来估计和预测因变量的值。
3、利用图表进行分析例23-1:某种合成纤维的强度与其拉伸倍数之间存在一定关系,图23-1所示(“线性回归分析”工作表)是实测12个纤维样品的强度y与相应的拉伸倍数x的数据记录。
试求出它们之间的关系。
A B r c11编号"拉伸倍数强度2-1T.9 1.4 3匚22 1.3 4.3 2.1 1.8 5r42,5 2.5 65 2.7 2.87匚62.7 2.58r? 3.5398 3.5 2.710匚94411104 3.512r11 4.5 4.213_12 4.6最5(1)打开“线性回归分析”工作表。
(2)利用“图表向导”绘制XY散点图”。
(3)在XY散点图”中绘制趋势回归直线,如图23-2所示二、Excel中的回归分析工作表函数(1)截距函数语法:INTERCEPT(known_y's,known_x's)其中:Known_y's为因变的观察值或数据集合,Known_x's为自变的观察值或数据集合。
(2)斜率函数语法:SLOPE(known_y's,known_x's)其中:Known_y's为数字型因变量数据点数组或单元格区域;Known_x's 为自变量数据点集合。

EXCEL回归分析结果分析回归分析是一种统计分析方法,用于探究自变量与因变量之间的关系。
在Excel中进行回归分析可以帮助我们了解自变量与因变量之间的关系,并可以使用回归方程来预测因变量的值。
下面将对Excel回归分析结果进行详细分析。
通常,Excel回归分析的结果会被分为多个部分,包括回归系数、显著性和模型拟合度等。
首先,我们来分析回归系数。
回归系数是用来衡量自变量对因变量的影响程度的。
在Excel回归分析的结果中,回归系数通常以Coefficient这一列的形式呈现。
每个回归系数对应一个自变量,并且包括系数的估计值、标准误差、t值和p值。
系数的估计值可以告诉我们自变量的变化对因变量的变化方向和幅度有什么样的影响。
例如,如果自变量的系数为正数,意味着自变量的增加会导致因变量的增加;而如果自变量的系数为负数,意味着自变量的增加会导致因变量的减少。
标准误差是用来衡量回归系数的精确度的。
标准误差越小,表示回归系数的估计值越准确。
如果标准误差较大,就说明估计值不太可靠,需要更多的样本数据来提高估计的准确性。
t值是用来检验回归系数是否显著的。
在Excel的回归分析结果中,通常会给出t值和相应的临界值,可以根据t值是否大于临界值来判断回归系数是否显著。
如果t值大于临界值(通常为1.96),则表示回归系数是显著的,说明自变量对因变量有显著影响;如果t值小于临界值,则表示回归系数是不显著的,自变量对因变量的影响效果不明显。
p值是用来衡量回归系数的显著性的。
p值是一个介于0和1之间的数值,通常以概率的形式表示。
在Excel的回归分析结果中,p值小于0.05通常被认为是显著的,说明自变量对因变量有显著影响;而p值大于等于0.05通常被认为是不显著的,自变量对因变量的影响效果不明显。
除了回归系数的分析,显著性的分析也是回归分析结果中很重要的一部分。
显著性可以帮助我们判断回归模型是否能够很好地预测因变量的变化。
在Excel的回归分析结果中,显著性通常以F值和p值的形式呈现。

excel回归结果解读摘要:1.回归分析简介2.Excel回归分析步骤3.回归结果解读4.回归系数含义及解释5.模型检验与优化6.总结与建议正文:随着数据分析和统计方法的普及,回归分析已成为各领域研究者的重要工具。
回归分析旨在研究两个或多个变量之间的关系,其中,Excel是一款广泛应用于数据分析的软件。
本文将详细介绍如何进行Excel回归分析,以及如何解读回归结果。
一、回归分析简介回归分析是一种统计方法,用于研究自变量与因变量之间的依赖关系。
通常,回归分析的结果以线性方程形式表示,即y = a + bx,其中y为因变量,x为自变量,a和b分别为截距和斜率。
二、Excel回归分析步骤1.准备数据:首先,需要将数据整理为适当的格式。
通常,自变量和因变量应分别位于不同列中。
2.插入图表:在Excel中,选择图表类型为“散点图”,并将数据插入图表。
3.添加趋势线:右键单击图表,选择“添加趋势线”,在弹出的对话框中选择“线性”趋势线类型。
4.计算回归系数:在Excel中,可以使用“数据分析”工具箱中的“回归”功能。
将数据输入“因变量区域”和“自变量区域”,并选择“标签”选项,以计算回归系数。
5.得出线性方程:根据计算出的回归系数,得出线性方程,如y = a + bx。
三、回归结果解读1.回归系数:回归系数b表示自变量x每变动一个单位时,因变量y的平均变动量。
正负号表示自变量与因变量之间的正负相关关系。
2.截距:截距a表示当自变量x为0时,因变量y的预测值。
它可以用于评估模型的初始状态。
3.确定系数R:R表示模型对数据的拟合程度,值越接近1,拟合程度越好。
4.显著性检验:通过t检验和p值判断回归系数是否显著。
若p值小于0.05,说明回归系数显著。
四、模型检验与优化1.残差分析:检查模型是否存在异方差、序列相关等问题,若存在,可采用其他模型进行优化。
2.多重共线性检验:若自变量存在多重共线性,可采用逐步回归、主成分分析等方法进行优化。
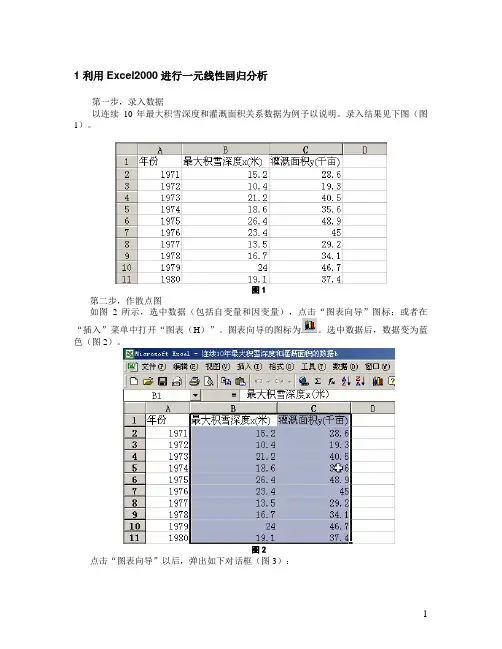
1 利用Excel2000进行一元线性回归分析第一步,录入数据以连续10年最大积雪深度和灌溉面积关系数据为例予以说明。
录入结果见下图(图1)。
图1第二步,作散点图如图2所示,选中数据(包括自变量和因变量),点击“图表向导”图标;或者在“插入”菜单中打开“图表(H)”。
图表向导的图标为。
选中数据后,数据变为蓝色(图2)。
图2点击“图表向导”以后,弹出如下对话框(图3):图3在左边一栏中选中“XY散点图”,点击“完成”按钮,立即出现散点图的原始形式(图4):图4第三步,回归观察散点图,判断点列分布是否具有线性趋势。
只有当数据具有线性分布特征时,才能采用线性回归分析方法。
从图中可以看出,本例数据具有线性分布趋势,可以进行线性回归。
回归的步骤如下:⑴首先,打开“工具”下拉菜单,可见数据分析选项(见图5):图5用鼠标双击“数据分析”选项,弹出“数据分析”对话框(图6):图6⑵然后,选择“回归”,确定,弹出如下选项表(图7):图7进行如下选择:X、Y值的输入区域(B1:B11,C1:C11),标志,置信度(95%),新工作表组,残差,线性拟合图(图8-1)。
或者:X、Y值的输入区域(B2:B11,C2:C11),置信度(95%),新工作表组,残差,线性拟合图(图8-2)。
注意:选中数据“标志”和不选“标志”,X、Y值的输入区域是不一样的:前者包括数据标志:最大积雪深度x(米)灌溉面积y(千亩)后者不包括。
这一点务请注意(图8)。
图8-1 包括数据“标志”图8-2 不包括数据“标志”⑶再后,确定,取得回归结果(图9)。
图9 线性回归结果⑷最后,读取回归结果如下:截距:356.2=a ;斜率:813.1=b ;相关系数:989.0=R ;测定系数:979.02=R ;F 值:945.371=F ;t 值:286.19=t ;标准离差(标准误差):419.1=s ;回归平方和:854.748SSr =;剩余平方和:107.16SSe =;y 的误差平方和即总平方和:961.764SSt =。

excel回归结果解读(原创实用版)目录1.引言:回归分析简介2.目的:Excel 回归结果的解读方法3.方法:如何在 Excel 中进行回归分析3.1 准备数据3.2 选择合适的函数3.3 输出结果4.结果解读:回归系数、R值、p 值等5.结论:回归分析在实际问题中的应用正文一、引言:回归分析简介回归分析是一种统计方法,用于研究两个或多个变量之间的关系。
在实际问题中,回归分析可以帮助我们了解各个变量对目标变量的影响程度,从而为决策提供依据。
Excel 作为一款功能强大的数据处理工具,可以方便地进行回归分析。
本文将介绍如何在 Excel 中进行回归分析并解读结果。
二、目的:Excel 回归结果的解读方法在 Excel 中进行回归分析后,我们得到一系列结果,如何正确解读这些结果是关键。
本文旨在介绍如何解读 Excel 回归结果,以便更好地分析和解决实际问题。
三、方法:如何在 Excel 中进行回归分析3.1 准备数据在进行回归分析之前,需要先准备好分析所需的数据。
数据应包括自变量和因变量,以及其他可能的影响因素。
例如,在分析房价与房屋面积、地段等因素的关系时,房价为因变量,房屋面积和地段为自变量。
3.2 选择合适的函数在 Excel 中,有多种回归函数可供选择,如线性回归、多项式回归、指数回归等。
根据实际问题和数据特点,选择合适的回归函数进行分析。
例如,在分析房价与房屋面积、地段等因素的关系时,可以选择线性回归函数。
3.3 输出结果在 Excel 中输入相关数据和函数后,按下回车键,即可得到回归分析的结果。
结果包括回归系数、R值、p 值等。
四、结果解读:回归系数、R值、p 值等回归分析的结果包括多个指标,下面对这些指标进行解读:1.回归系数:回归系数表示自变量每变动一个单位时,因变量相应变动的数量。
正数表示正相关,负数表示负相关,接近 0 表示相关性较弱。
2.R值:R值表示回归方程对观测数据的拟合程度。
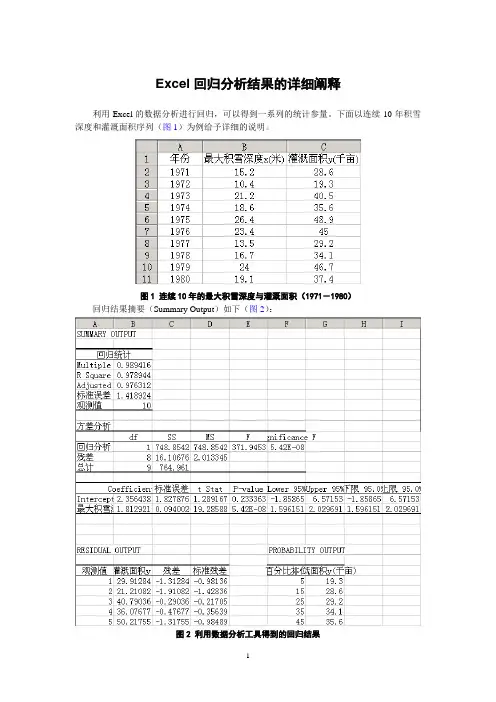
Excel回归分析结果的详细阐释利用Excel的数据分析进行回归,可以得到一系列的统计参量。
下面以连续10年积雪深度和灌溉面积序列(图1)为例给予详细的说明。
图1 连续10年的最大积雪深度与灌溉面积(1971-1980)回归结果摘要(Summary Output)如下(图2):图2 利用数据分析工具得到的回归结果第一部分:回归统计表这一部分给出了相关系数、测定系数、校正测定系数、标准误差和样本数目如下(表1):表1 回归统计表逐行说明如下:Multiple 对应的数据是相关系数(correlation coefficient),即R=0.989416。
R Square 对应的数值为测定系数(determination coefficient),或称拟合优度(goodness of fit),它是相关系数的平方,即有R 2=0.9894162=0.978944。
Adjusted 对应的是校正测定系数(adjusted determination coefficient),计算公式为1)1)(1(12−−−−−=m n R n R a 式中n 为样本数,m 为变量数,R 2为测定系数。
对于本例,n =10,m =1,R 2=0.978944,代入上式得976312.01110)978944.01)(110(1=−−−−−=a R标准误差(standard error )对应的即所谓标准误差,计算公式为SSe 11−−=m n s这里SSe 为剩余平方和,可以从下面的方差分析表中读出,即有SSe=16.10676,代入上式可得418924.110676.16*11101=−−=s最后一行的观测值对应的是样本数目,即有n =10。
第二部分,方差分析表方差分析部分包括自由度、误差平方和、均方差、F 值、P 值等(表2)。
表2 方差分析表(ANOVA )逐列、分行说明如下:第一列df 对应的是自由度(degree of freedom ),第一行是回归自由度dfr ,等于变量数目,即dfr=m ;第二行为残差自由度dfe ,等于样本数目减去变量数目再减1,即有dfe=n -m -1;第三行为总自由度dft ,等于样本数目减1,即有dft=n -1。

EXCEL回归分析结果分析Excel回归分析结果的详细阐释利用Excel的数据分析进行回归,可以得到一系列的统计参量。
下面以连续10年积雪深度和灌溉面积序列(图1)为例给予详细的说明。
图1 连续10年的最大积雪深度与灌溉面积(1971,1980)回归结果摘要(Summary Output)如下(图2):图2 利用数据分析工具得到的回归结果第一部分:回归统计表这一部分给出了相关系数、测定系数、校正测定系数、标准误差和样本数目如下(表1): 表1 回归统计表逐行说明如下:Multiple对应的数据是相关系数(correlation coefficient),即R=0.989416。
R Square对应的数值为测定系数(determination coefficient),或称拟合优度(goodness of fit),它是相关系数的平方,即有R2=0.9894162=0.978944。
Adjusted对应的是校正测定系数(adjusted determination coefficient),计算公式为式中n为样本数,m为变量数,R2为测定系数。
对于本例,n=10,m=1,R2=0.978944,代入上式得标准误差(standard error)对应的即所谓标准误差,计算公式为这里SSe为剩余平方和,可以从下面的方差分析表中读出,即有SSe=16.10676,代入上式可得最后一行的观测值对应的是样本数目,即有n=10。
第二部分,方差分析表方差分析部分包括自由度、误差平方和、均方差、F值、P值等(表2)。
表2 方差分析表(ANOVA)逐列、分行说明如下:第一列df对应的是自由度(degree of freedom),第一行是回归自由度dfr,等于变量数目,即dfr=m;第二行为残差自由度dfe,等于样本数目减去变量数目再减1,即有dfe=n-m-1;第三行为总自由度dft,等于样本数目减1,即有dft=n-1。

实验报告用EXCEL进行相关与回归分析
一、实验介绍
本实验通过用Excel进行相关和回归分析,以探讨两个变量之间的关系。
二、实验步骤
(1)首先,在Excel中收集数据,并将这些数据编入表格,表格中
的每一列分别表示变量,每一行表示一组观测数据;
(2)进行相关分析,首先,需要在Excel中计算出两个变量之间的
相关系数,然后判断相关系数的绝对值,确定变量之间的相关关系;
(3)接着,进行回归分析,在回归分析中,可以使用线性回归、非
线性回归等方法,用Excel中的函数计算出回归方程,以及回归系数r2,表示变量之间的回归关系;
(4)最后,根据实验结果,利用Excel拟合数据,画出变量之间的
拟合曲线,作出实验结果的图解;
三、实验结果
本次实验使用的数据集是一组实验观测数据,观测数据为抽样数据,
表示其中一种物品同时装入不同重量时的质量损失情况,两个变量分别为
物品的重量和质量损失。
在相关分析中,使用Excel函数计算出来的两个变量之间的相关系数为:0.837、根据结果可以判断,两个变量之间有较强的相关性。
而在回归分析中,使用Excel函数计算出来的线性回归方程为:
y=0.36x-1.27,回归系数r2为:0.701、由此可以看出,两个变量之间有较强的回归关系。

回归分析:利用Excel探索数据关系一、介绍回归分析的概念和基本原理回归分析是一种统计学技术,可以用来确定两种或多种变量之间的关系。
它可以帮助我们理解变量之间的联系,并预测特定变量值的变化。
回归分析的基本原理是,它可以用来拟合一个或多个变量的数据,以确定它们之间的关系。
例如,假设我们想要研究学生的成绩与学习时间之间的关系。
我们可以收集一组数据,其中包含学生的学习时间和他们的成绩,并使用回归分析来确定两者之间的关系。
另一个例子是,假设我们想要研究消费者的收入与购买行为之间的关系。
我们可以收集一组数据,其中包含消费者的收入和购买行为,并使用回归分析来确定两者之间的关系。
回归分析可以帮助我们了解变量之间的关系,并预测特定变量值的变化。
它可以帮助我们更好地理解数据,并做出更好的决策。
回归分析也可以帮助我们更好地预测未来的变化,并为未来做出更好的准备。
二、介绍excel回归分析的基本步骤Excel回归分析是一种有效的数据分析方法,用于探索和解释两个或多个变量之间的关系。
它可以帮助我们更深入地了解变量之间的联系,从而更好地分析问题并做出更好的决策。
Excel回归分析的基本步骤如下:第一步:准备数据。
首先,我们需要准备好要使用的数据,包括自变量和因变量的值,并将它们放入Excel表格中,以便进行进一步的分析。
比如,我们要分析学生的学习成绩和睡眠时间之间的关系,那么我们需要准备学生的睡眠时间和学习成绩的数据,并将它们放入Excel表格中。
第二步:选择回归分析工具。
接下来,我们需要从Excel中选择回归分析工具,这将帮助我们计算出自变量和因变量之间的关系。
比如,我们可以从Excel中选择“数据分析”工具,然后从中选择“线性回归”工具,以计算学生的学习成绩和睡眠时间之间的关系。
第三步:计算回归系数。
接下来,我们需要计算回归系数,以确定自变量和因变量之间的关系。
比如,我们可以计算出学生的学习成绩和睡眠时间之间的回归系数,以确定这两者之间的关系是正相关还是负相关。

回归分析excel实验报告回归分析是一种广泛应用于统计学和经济学中的分析方法,用于研究两个或多个变量之间的关系。
在Excel中,可以使用内置的回归分析工具来进行回归分析,并得出相关的统计指标和模型拟合结果。
本实验报告将使用Excel进行回归分析,并对结果进行解读和讨论。
首先,我们需要收集所需的数据,并将其整理成一个合适的数据表格。
在这个实验中,我们将以销售量为因变量,广告投入为自变量,来研究广告投入对销售量的影响。
接下来,打开Excel并将数据导入到工作表中。
选择“数据”选项卡中的“数据分析”按钮,并选择“回归”选项。
在弹出窗口中,将因变量和自变量的范围输入到相应的框中,并选中“置信水平”和“残差等级检验”选项。
点击“确定”按钮后,Excel将进行回归分析,并生成一个新的工作表,其中包含了回归分析的结果。
分析结果包括回归方程、离散度分析、方差分析、残差分析等内容。
回归方程是回归分析的核心结果之一,它表示了因变量与自变量之间的关系。
回归方程的形式为:Y = a + bX,其中Y表示因变量,X表示自变量,a表示截距,b表示斜率。
回归方程的系数可以用来解释自变量对因变量的影响程度。
在本实验中,回归方程可以表示为:销售量= 截距+ 广告投入* 斜率。
离散度分析用于评估回归方程的拟合程度。
它可以通过计算解释变差和未解释变差之间的比例来进行评估。
解释变差是因变量的一部分变差,可以由自变量来解释,而未解释变差则是因变量的另一部分变差,无法由自变量来解释。
离散度分析结果以R方值表示,它的取值范围在0到1之间,值越接近1表示回归方程拟合程度越好。
方差分析用于检验回归模型的显著性。
在Excel的回归分析结果中,方差分析表中的F值可以用来检验回归模型的显著性。
当F值显著小于0.05时,可以认为回归模型是显著的,即自变量对因变量的影响是有意义的。
残差分析用于评估回归模型的拟合优度。
在Excel的回归分析结果中,我们可以查看残差图和残差的正态性检验。

Excel回归阐发结果的详细阐释之五兆芳芳创作利用Excel的数据阐发进行回归,可以得到一系列的统计参量.下面以连续10年积雪深度和浇灌面积序列(图1)为例赐与详细的说明.图1 连续10年的最大积雪深度与浇灌面积(1971-1980)回归结果摘要(Summary Output)如下(图2):图2 利用数据阐发东西得到的回归结果第一部分:回归统计表这一部分给出了相关系数、测定系数、校正测定系数、尺度误差和样本数目如下(表1):表1 回归统计表逐行说明如下:Multiple对应的数据是相关系数(correlation coefficient),即R=0.989416.R Square对应的数值为测定系数(determination coefficient),或称拟合优度(goodness of fit),它是相关系数的平方,即有R22=0.978944.Adjusted对应的是校正测定系数(adjusted determination coefficient),计较公式为式中n为样本数,m为变量数,R2为测定系数.对于本例,n=10,m=1,R2=0.978944,代入上式得尺度误差(standard error)对应的即所谓尺度误差,计较公式为这里SSe为剩余平方和,可以从下面的方差阐发表中读出,即有SSe=16.10676,代入上式可得最后一行的不雅测值对应的是样本数目,即有n=10.第二部分,方差阐发表方差阐发部分包含自由度、误差平方和、均方差、F值、P值等(表2).表2 方差阐发表(ANOVA)逐列、分行说明如下:第一列df对应的是自由度(degree of freedom),第一行是回归自由度dfr,等于变量数目,即dfr=m;第二行动残差自由度dfe,等于样本数目减去变量数目再减1,即有dfe=n-m-1;第三行动总自由度dft,等于样本数目减1,即有dft=n-1.对于本例,m=1,n=10,因此,dfr=1,dfe=n-m-1=8,dft=n-1=9.第二列SS对应的是误差平方和,或称变差.第一行动回归平方和或称回归变差SSr,即有它表征的是因变量的预测值对其平均值的总偏差.第二行动剩余平方和(也称残差平方和)或称剩余变差SSe,即有它表征的是因变量对其预测值的总偏差,这个数值越大,意味着拟合的效果越差.上述的y的尺度误差即由SSe给出.第三行动总平方和或称总变差SSt,即有它暗示的是因变量对其平均值的总偏差.容易验证748.8542+16.10676=764.961,即有而测定系数就是回归平方和在总平方和中所占的比重,即有显然这个数值越大,拟合的效果也就越好.第四列MS对应的是均方差,它是误差平方和除以相应的自由度得到的商.第一行动回归均方差MSr,即有第二行动剩余均方差MSe,即有显然这个数值越小,拟合的效果也就越好.第四列对应的是F值,用于线性关系的判定.对于一元线性回归,F值的计较公式为式中R 2=0.978944,dfe=10-1-1=8,因此第五列Significance F 对应的是在显著性水平下的F α临界值,其实等于P 值,即弃真几率.所谓“弃真几率”即模型为假的几率,显然1-P 便是模型为真的几率.可见,P 值越小越好.对于本例,P =0.0000000542<0.0001,故置信度达到99.99%以上.第三部分,回归参数表回归参数表包含回归模型的截距、斜率及其有关的查验参数(表3).表3 回归参数表第一列Coefficients 对应的模型的回归系数,包含截距ab =1.812921065,由此可以成立回归模型或第二列为回归系数的尺度误差(用a s ˆ或b s ˆ暗示),误差值越小,标明参数的精确度越高.这个参数较少使用,只是在一些特此外场合出现.例如L. Benguigui 等人在When and where is a city fractal ?一文中将斜率对应的尺度误差值作为分形演化的尺度,建议采取0.04作为分维判定的统计指标(拜见EPB2000).不常使用尺度误差的原因在于:其统计信息已经包含在后述的t 查验中.第三列t Stat 对应的是统计量t 值,用于对模型参数的查验,需要查表才干决定.t 值是回归系数与其尺度误差的比值,即有a a s at ˆ=,b b s bt ˆ=按照表3中的数据容易算出:289167.1827876.1356438.2==a t ,28588.19094002.0812921.1==b t对于一元线性回归,t 值可用相关系数或测定系数计较,公式如下将R=0.989416、n=10、m=1代入上式得到对于一元线性回归,F值与t值都与相关系数R等价,因此,相关系数查验就已包含了这部分信息.但是,对于多元线性回归,t查验就不成缺省了.第四列P value对应的是参数的P值(双侧).当P<0.05时,可以认为模型在α=0.05的水平上显著,或置信度达到95%;当P<0.01时,可以认为模型在α=0.01的水平上显著,或置信度达到99%;当P<0.001时,可以认为模型在α=0.001的水平上显著,或置信度达到99.9%.对于本例,P=0.0000000542<0.0001,故可认为在α=0.0001的水平上显著,或置信度达到99.99%.P值查验与t值查验是等价的,但P值不必查表,显然要便利得多.最后几列给出的回归系数以95%为置信区间的上限和下限.可以看出,在α=0.05的显著水平上,截距的变更上限和下限为-1.85865和6.57153,即有斜率的变更极限则为1.59615和2.02969,即有第四部分,残差输出结果这一部分为选择输出内容,如果在“回归”阐发选项框中没有选中有关内容,则输出结果不会给出这部分结果.残差输出中包含不雅测值序号(第一列,用i暗示),因变量的预测值(第二列,用i yˆ暗示),残差(residuals,第三列,用e i暗示)以及尺度残差(表4).表4 残差输出结果预测值是用回归模型计较的结果,式中x i即原始数据的中的自变量.从图1可见,x1=15.2,代入上式,得其余依此类推.残差e i的计较公式为从图1可见,y1=28.6,代入上式,得到其余依此类推.尺度残差即残差的数据尺度化结果,借助均值命令average和尺度差命令stdev容易验证,残差的算术平均值为0,尺度差为1.337774.利用求平均值命令standardize(残差的单元格规模,均值,尺度差)立即算出表4中的结果.当然,也可以利用数据尺度化公式逐一计较.将残差平方再求和,便得到残差平方和即剩余平方和,即有利用Excel的求平方和命令sumsq容易验证上述结果.以最大积雪深度x i为自变量,以残差e i为因变量,作散点图,可得残差图(图3).残差点列的散布越是没有趋势(没有法则,即越是随机),回归的结果就越是可靠.用最大积雪深度x i为自变量,用浇灌面积y i及其预测值i yˆ为因变量,作散点图,可得线性拟合图(图4).图3 残差图图4 线性拟合图第五部分,几率输出结果在选项输出中,还有一个几率输出(Probability Output)表(表5).第一列是按等差数列设计的百分比排位,第二列则是原始数据因变量的自下而上排序(即从小到大)——选中图1中的第三列(C列)数据,用鼠标点击自下而上排序按钮,立即得到表5中的第二列数值.当然,也可以沿着主菜单的“数据(D)→排序(S)”路径,打开数据排序选项框,进行数据排序.用表5中的数据作散点图,可以得到Excel所谓的正态几率图(图5).表5 几率输出表图5 正态几率图【几点说明】第一,多元线性回归与一元线性回归结果相似,只是变量数目m≠1,F值和t值等统计量与R值也不再等价,因而不克不及直接从相关系数计较出来.第二,利用SPSS给出的结果与Excel也大同小异.当然,SPSS可以给出更多的统计量,如DW值.在暗示办法上,SPSS也有一些不合,例如P Value(P值)用Sig.(显著性)表征,因为两者等价.只要能够读懂Excel的回归摘要,就可以读懂SPSS回归输出结果的大部分外容.。
excel回归结果的详细解释在Excel中进行回归分析是一种常见的统计方法,它帮助我们了解变量之间的关系,并且可以使用回归结果做出预测。
下面详细解释一下Excel回归结果的含义。
1. 回归方程:回归方程是回归分析的核心结果之一。
在Excel中,回归方程是以y = a + bx的形式呈现的,其中y表示因变量,x表示自变量,a表示截距,b表示斜率。
回归方程告诉我们自变量对因变量的影响程度和方向。
2. 截距项(a):截距项表示当自变量等于0时,因变量的取值。
它表示因变量的基准值或在其他自变量影响下的常量部分。
较大的截距项意味着即使自变量为0,因变量也有较高的取值。
3. 斜率项(b):斜率项表示自变量每增加一个单位对因变量的平均变化量。
较大的斜率项表明自变量对因变量有更强的影响。
4. R²(确定系数):确定系数是用来衡量回归模型的拟合程度的指标。
它的取值范围在0到1之间,越接近1表示模型对数据的拟合程度越好。
Excel回归结果中的R²告诉我们自变量对因变量的变异有多少能够被模型解释。
5. F统计量:F统计量也是回归结果中的一个重要指标。
它判断回归方程的整体显著性,即自变量的组合对因变量的解释程度是否显著。
F统计量越大,说明回归模型的整体效果越好。
6. p值:p值是判断回归系数是否显著的指标,用于检验自变量对因变量的影响是否具有统计学意义。
当p值小于某个显著性水平(通常设置为0.05或0.01)时,表示回归系数显著。
通过解释Excel的回归结果,我们可以得到自变量对因变量的影响程度和方向,并且可以评估模型的拟合程度和显著性。
这些信息对于数据分析和预测都是至关重要的。
希望这些解释对你理解Excel回归结果有所帮助。
适用标准文档内容1.利用 Excel 进行一元线性回归剖析2.利用 Excel 进行多元线性回归剖析1.利用 Excel 进行一元线性回归剖析第一步,录入数据以连续10年最大积雪深度和浇灌面积关系数据为例予以说明。
录入结果见下列图(图1)。
图 1第二步,作散点图如图 2 所示,选中数据(包含自变量和因变量),点击“图表导游”图标;或许在“插入”菜单中翻开“图表(H )”。
图表导游的图标为。
选中数据后,数据变为蓝色(图 2 )。
图 2点击“图表导游”此后,弹出以下对话框(图3):图 3在左侧一栏中选中“XY 散点图”,点击“达成”按钮,立刻出现散点图的原始形式(图 4):浇灌面积 y( 千亩)60504030浇灌面积 y( 千亩)20100102030图 4第三步,回归察看散点图,判断点列散布能否拥有线性趋向。
只有当数据拥有线性散布特点时,才能采纳线性回归剖析方法。
从图中能够看出,本例数据拥有线性散布趋向,能够进行线性回归。
回归的步骤以下:1. 第一,翻开“工具”下拉菜单,可见数据剖析选项(见图5):图 5用鼠标双击“数据剖析”选项,弹出“数据剖析”对话框(图6):图 62. 而后,选择“回归”,确立,弹出以下选项表(图7):图 7进行以下选择: X、 Y 值的输入地区( B1:B11 , C1:C11 ),标记,置信度( 95% ),新工作表组,残差,线性拟合图(图 8-1 )。
或许: X、 Y 值的输入地区( B2:B11 ,C2:C11 ),置信度( 95% ),新工作表组,残差,线性拟合图(图 8-2 )。
注意:选中数据“标记”和不选“标记”,X、 Y 值的输入地区是不同样的:前者包含数据标记:最大积雪深度 x(米 ) 浇灌面积 y(千亩 )后者不包含。
这一点务请注意(图 8)。
图 8-1包含数据“标记”图 8-2 不包含数据“标记”3. 再后,确立,获得回归纳果(图9)。
图 9 线性回归纳果4.最后,读取回归纳果以下:截距: a 2.356 ;斜率: b 1.813;有关系数: R 0.989;测定系数:R2 0.979 ;F 值:F 371.945 ; t 值: t 19.286 ;标准离差(标准偏差):s 1.419;回归平方和:SSr 748.854 ;节余平方和:SSe 16.107 ;y的偏差平方和即总平方和: SSt764.961。
Excel回归分析结果得详细阐释利用Excel得数据分析进行回归,可以得到一系列得统计参量。
下面以连续10年积雪深度与灌溉面积序列(图1)为例给予详细得说明。
图1 连续10年得最大积雪深度与灌溉面积(1971-1980)回归结果摘要(Summary Output)如下(图2):图2 利用数据分析工具得到得回归结果第一部分:回归统计表这一部分给出了相关系数、测定系数、校正测定系数、标准误差与样本数目如下(表1):表1 回归统计表逐行说明如下:Multiple 对应得数据就是相关系数(correlation coefficient),即R=0、989416。
R Square 对应得数值为测定系数(determination coefficient),或称拟合优度(goodness of fit),它就是相关系数得平方,即有R 2=0、9894162=0、978944。
Adjusted 对应得就是校正测定系数(adjusted determination coefficient),计算公式为1)1)(1(12-----=m n R n R a式中n 为样本数,m 为变量数,R 2为测定系数。
对于本例,n =10,m =1,R 2=0、978944,代入上式得976312.01110)978944.01)(110(1=-----=a R标准误差(standard error)对应得即所谓标准误差,计算公式为SSe 11--=m n s这里SSe 为剩余平方与,可以从下面得方差分析表中读出,即有SSe=16、10676,代入上式可得418924.110676.16*11101=--=s最后一行得观测值对应得就是样本数目,即有n =10。
第二部分,方差分析表方差分析部分包括自由度、误差平方与、均方差、F 值、P 值等(表2)。
表2 方差分析表(ANOVA)逐列、分行说明如下:第一列df 对应得就是自由度(degree of freedom),第一行就是回归自由度dfr,等于变量数目,即dfr=m ;第二行为残差自由度dfe,等于样本数目减去变量数目再减1,即有dfe=n -m -1;第三行为总自由度dft,等于样本数目减1,即有dft=n -1。
excel回归结果解读摘要:一、回归分析概述二、Excel 回归功能介绍三、Excel 回归结果的解读方法四、实际案例分析五、总结正文:一、回归分析概述回归分析是一种统计分析方法,用于研究两个或多个变量之间的关系。
在数据分析中,回归分析被广泛应用于预测、优化和解释变量之间的关系。
二、Excel 回归功能介绍Excel 作为一款功能强大的数据处理工具,也提供了回归分析功能。
用户可以在Excel 中使用“数据”菜单下的“数据分析”工具,选择“回归”选项来进行回归分析。
三、Excel 回归结果的解读方法在Excel 中进行回归分析后,会得到一个包含多个结果单元格的工作表。
要解读这些结果,我们需要关注以下几个关键指标:1.R值:R值表示自变量对因变量的解释程度,其值范围为0-1。
R值越接近1,表示自变量对因变量的解释能力越强。
2.斜率:斜率表示自变量每变动一个单位时,因变量相应变动的数量。
正斜率表示两者正相关,负斜率表示两者负相关。
3.截距:截距表示当自变量为0 时,因变量的取值。
在回归分析中,截距通常用于表示因变量的基线值。
4.标准误差:标准误差表示回归线的不确定性。
标准误差越小,表示回归线越接近真实值。
5.t 值和p 值:t 值表示回归系数除以其标准误差,p 值表示t 值的概率。
通常,如果p 值小于显著性水平(如0.05),则认为回归系数显著。
四、实际案例分析假设我们想要研究一家公司的销售额与广告投入、员工数量和产品价格之间的关系。
在收集了相关数据后,我们可以使用Excel 进行回归分析。
在Excel 中,我们首先将数据输入到一个工作表中,然后选择“数据”菜单下的“数据分析”工具,点击“回归”,并选择“线性回归”。
在弹出的对话框中,我们分别设置因变量(销售额)和自变量(广告投入、员工数量和产品价格),并选择合适的统计方法。
分析完成后,我们可以在工作表中看到回归结果。
通过观察R值、斜率、截距、标准误差、t 值和p 值等指标,我们可以了解广告投入、员工数量和产品价格对销售额的影响程度及方向。
Excel回归分析结果详解利用Excel的数据分析进行回归,可以得到一系列的统计参量。
下面以连续10年积雪深度和灌溉面积序列(图1)为例给予详细的说明。
图1 连续10年的最大积雪深度与灌溉面积(1971-1980)回归结果摘要(Summary Output)如下(图2):图2 利用数据分析工具得到的回归结果第一部分 回归统计表这一部分给出了相关系数、测定系数、校正测定系数、标准误差和样本数目如下(表1):表1 回归统计表逐行说明如下:Multiple 对应的数据是相关系数(correlation coefficient),即R=0.989416。
R Square 对应的数值为测定系数(determination coefficient),或称拟合优度(goodness of fit),它是相关系数的平方,即有R 2=0.9894162=0.978944。
Adjusted 对应的是校正测定系数(adjusted determination coefficient),计算公式为1)1)(1(12-----=m n R n R a式中n 为样本数,m 为变量数,R 2为测定系数。
对于本例,n =10,m =1,R 2=0.978944,代入上式得976312.01110)978944.01)(110(1=-----=a R标准误差(standard error )对应的即所谓标准误差,计算公式为1--=m n SSe s 这里SSe 为剩余平方和,可以从下面的方差分析表中读出,即有SSe=16.10676,代入上式可得418924.11110106761.16=--=s 最后一行的观测值对应的是样本数目,即有n =10。
第二部分 方差分析表方差分析部分包括自由度、误差平方和、均方差、F 值、P 值等(表2)。
表2 方差分析表(ANOV A )逐列、分行说明如下:第一列df 对应的是自由度(degree of freedom ),第一行是回归自由度dfr ,等于变量数目,即dfr=m ;第二行为残差自由度dfe ,等于样本数目减去变量数目再减1,即有dfe=n -m -1;第三行为总自由度dft ,等于样本数目减1,即有dft=n -1。
excel做回归分析的原理和实例Excel做线性回归分析基本原理及实例一、原理1、回归分析原理由一个或一组非随机变量来估计或预测某一个随机变量的观测值时,所建立的数学模型及所进行的统计分析,称为回归分析。
按变量个数的多少,回归分析有一元回归分析与多元回归分析之分,多元回归分析的原理与一元回归分析的原理类似。
按变量之间关系的形式,回归分析可以分为线性回归分析和非线性回归分析。
2 、回归分析的主要内容回归分析的内容包括如何确定因变量与自变量之间的回归模型;如何根据样本观测数据,估计并检验回归模型及未知参数;在众多的自变量中,判断哪些变量对因变量的影响是显著的,哪些变量的影响是不显著的;根据自变量的已知值或给定值来估计和预测因变量的值。
3、利用图表进行分析例23-1:某种合成纤维的强度与其拉伸倍数之间存在一定关系,图23-1所示(“线性回归分析”工作表)是实测12个纤维样品的强度y与相应的拉伸倍数x的数据记录。
试求出它们之间的关系。
(1)打开“线性回归分析”工作表。
(2)利用“图表向导”绘制“XY散点图”。
(3)在“XY散点图”中绘制趋势回归直线,如图23-2所示。
二、 Excel中的回归分析工作表函数(1)截距函数语法:INTERCEPT(known_y's,known_x's)其中:Known_y's为因变的观察值或数据集合,Known_x's为自变的观察值或数据集合。
(2)斜率函数语法:SLOPE(known_y's,known_x's)其中:Known_y's为数字型因变量数据点数组或单元格区域;Known_x's为自变量数据点集合。
(3)测定系数函数语法:RSQ(known_y's,known_x's)其中:Known_y's为数组或数据点区域,Known_x's为数组或数据点区域。
(4)估计标准误差函数语法:STEYX(known_y's,known_x's)其中:Known_y's为因变量数据点数组或区域,Known_x's为自变量数据点数组或区域。
Excel回归分析结果的详细阐释利用Excel的数据分析进行回归,可以得到一系列的统计参量。
下面以连续10年积雪深度和灌溉面积序列(图1)为例给予详细的说明。
图1 连续10年的最大积雪深度与灌溉面积(1971-1980)回归结果摘要(Summary Output)如下(图2):图2 利用数据分析工具得到的回归结果第一部分:回归统计表这一部分给出了相关系数、测定系数、校正测定系数、标准误差和样本数目如下(表1):表1 回归统计表逐行说明如下:Multiple 对应的数据是相关系数(correlation coefficient),即R=0.989416。
R Square 对应的数值为测定系数(determination coefficient),或称拟合优度(goodness of fit),它是相关系数的平方,即有R 2=0.9894162=0.978944。
Adjusted 对应的是校正测定系数(adjusted determination coefficient),计算公式为1)1)(1(12-----=m n R n R a式中n 为样本数,m 为变量数,R 2为测定系数。
对于本例,n =10,m =1,R 2=0.978944,代入上式得976312.01110)978944.01)(110(1=-----=a R标准误差(standard error )对应的即所谓标准误差,计算公式为SSe 11--=m n s这里SSe 为剩余平方和,可以从下面的方差分析表中读出,即有SSe=16.10676,代入上式可得418924.110676.16*11101=--=s最后一行的观测值对应的是样本数目,即有n =10。
第二部分,方差分析表方差分析部分包括自由度、误差平方和、均方差、F 值、P 值等(表2)。
表2 方差分析表(ANOVA )逐列、分行说明如下:第一列df 对应的是自由度(degree of freedom ),第一行是回归自由度dfr ,等于变量数目,即dfr=m ;第二行为残差自由度dfe ,等于样本数目减去变量数目再减1,即有dfe=n -m -1;第三行为总自由度dft ,等于样本数目减1,即有dft=n -1。
对于本例,m =1,n =10,因此,dfr=1,dfe=n -m -1=8,dft=n -1=9。
第二列SS 对应的是误差平方和,或称变差。
第一行为回归平方和或称回归变差SSr ,即有8542.748)ˆ(SSr 12=-=∑=ni i iy y它表征的是因变量的预测值对其平均值的总偏差。
第二行为剩余平方和(也称残差平方和)或称剩余变差SSe ,即有10676.16)ˆ(SSe 12=-=∑=ni i iyy它表征的是因变量对其预测值的总偏差,这个数值越大,意味着拟合的效果越差。
上述的y 的标准误差即由SSe 给出。
第三行为总平方和或称总变差SSt ,即有它表示的是因变量对其平均值的总偏差。
容易验证748.8542+16.10676=764.961,即有SSt SSe SSr =+而测定系数就是回归平方和在总平方和中所占的比重,即有978944.0961.7648542.748SStSSr 2===R显然这个数值越大,拟合的效果也就越好。
第四列MS 对应的是均方差,它是误差平方和除以相应的自由度得到的商。
第一行为回归均方差MSr ,即有8542.74818542.748dfr SSr MSr ===第二行为剩余均方差MSe ,即有013345.2810676.16dfeSSe MSe ===显然这个数值越小,拟合的效果也就越好。
第四列对应的是F 值,用于线性关系的判定。
对于一元线性回归,F 值的计算公式为22221dfe )1(11RR R m n R F -=---=式中R 2=0.978944,dfe=10-1-1=8,因此9453.371978944.01978944.0*8=-=F第五列Significance F 对应的是在显著性水平下的F α临界值,其实等于P 值,即弃真概率。
所谓“弃真概率”即模型为假的概率,显然1-P 便是模型为真的概率。
可见,P 值越小越好。
对于本例,P =0.0000000542<0.0001,故置信度达到99.99%以上。
第三部分,回归参数表961.764)(SSr 12=-=∑=ni i iy y回归参数表包括回归模型的截距、斜率及其有关的检验参数(表3)。
表3 回归参数表第一列Coefficients 对应的模型的回归系数,包括截距a =2.356437929和斜率b =1.812921065,由此可以建立回归模型i i x y8129.13564.2ˆ+= 或i i i x y ε++=8129.13564.2第二列为回归系数的标准误差(用a s ˆ或b s ˆ表示),误差值越小,表明参数的精确度越高。
这个参数较少使用,只是在一些特别的场合出现。
例如L. Benguigui 等人在When and where is a city fractal ?一文中将斜率对应的标准误差值作为分形演化的标准,建议采用0.04作为分维判定的统计指标(参见EPB2000)。
不常使用标准误差的原因在于:其统计信息已经包含在后述的t 检验中。
第三列t Stat 对应的是统计量t 值,用于对模型参数的检验,需要查表才能决定。
t 值是回归系数与其标准误差的比值,即有a a sa t ˆ=,b b sb t ˆ=根据表3中的数据容易算出:289167.1827876.1356438.2==a t ,28588.19094002.0812921.1==b t对于一元线性回归,t 值可用相关系数或测定系数计算,公式如下112---=m n RR t将R=0.989416、n =10、m =1代入上式得到28588.191110989416.01989416.02=---=t对于一元线性回归,F 值与t 值都与相关系数R 等价,因此,相关系数检验就已包含了这部分信息。
但是,对于多元线性回归,t 检验就不可缺省了。
第四列P value 对应的是参数的P 值(双侧)。
当P<0.05时,可以认为模型在α=0.05的水平上显著,或者置信度达到95%;当P <0.01时,可以认为模型在α=0.01的水平上显著,或者置信度达到99%;当P <0.001时,可以认为模型在α=0.001的水平上显著,或者置信度达到99.9%。
对于本例,P=0.0000000542<0.0001,故可认为在α=0.0001的水平上显著,或者置信度达到99.99%。
P 值检验与t 值检验是等价的,但P 值不用查表,显然要方便得多。
最后几列给出的回归系数以95%为置信区间的上限和下限。
可以看出,在α=0.05的显著水平上,截距的变化上限和下限为-1.85865和6.57153,即有57153.685865.1≤≤-a斜率的变化极限则为1.59615和2.02969,即有02969.259615.1≤≤b第四部分,残差输出结果这一部分为选择输出内容,如果在“回归”分析选项框中没有选中有关内容,则输出结果不会给出这部分结果。
残差输出中包括观测值序号(第一列,用i 表示),因变量的预测值(第二列,用i yˆ表示),残差(residuals ,第三列,用e i 表示)以及标准残差(表4)。
表4 残差输出结果预测值是用回归模型i i x y8129.13564.2ˆ+= 计算的结果,式中x i 即原始数据的中的自变量。
从图1可见,x 1=15.2,代入上式,得118129.13564.2ˆx y+=91284.292.15*8129.13564.2=+= 其余依此类推。
残差e i 的计算公式为i i i yy e ˆ-= 从图1可见,y 1=28.6,代入上式,得到31284.191284.296.28ˆ111-=-=-=yy e 其余依此类推。
标准残差即残差的数据标准化结果,借助均值命令average 和标准差命令stdev 容易验证,残差的算术平均值为0,标准差为1.337774。
利用求平均值命令standardize(残差的单元格范围,均值,标准差)立即算出表4中的结果。
当然,也可以利用数据标准化公式)var(*i i i z z z z -=ii zz σ-=逐一计算。
将残差平方再求和,便得到残差平方和即剩余平方和,即有10676.16)ˆ(1212=-==∑∑==ni i ini iyyeSSe 利用Excel 的求平方和命令sumsq 容易验证上述结果。
以最大积雪深度x i 为自变量,以残差e i 为因变量,作散点图,可得残差图(图3)。
残差点列的分布越是没有趋势(没有规则,即越是随机),回归的结果就越是可靠。
用最大积雪深度x i 为自变量,用灌溉面积y i 及其预测值i yˆ为因变量,作散点图,可得线性拟合图(图4)。
图3 残差图图4 线性拟合图第五部分,概率输出结果在选项输出中,还有一个概率输出(Probability Output)表(表5)。
第一列是按等差数列设计的百分比排位,第二列则是原始数据因变量的自下而上排序(即从小到大)——选中图1中的第三列(C 列)数据,用鼠标点击自下而上排序按钮,立即得到表5中的第二列数值。
当然,也可以沿着主菜单的“数据(D)→排序(S)”路径,打开数据排序选项框,进行数据排序。
用表5中的数据作散点图,可以得到Excel所谓的正态概率图(图5)。
表5 概率输出表图5 正态概率图【几点说明】第一,多元线性回归与一元线性回归结果相似,只是变量数目m≠1,F值和t值等统计量与R值也不再等价,因而不能直接从相关系数计算出来。
第二,利用SPSS给出的结果与Excel也大同小异。
当然,SPSS可以给出更多的统计量,如DW值。
在表示方法上,SPSS也有一些不同,例如P Value(P值)用 Sig.(显著性)表征,因为二者等价。
只要能够读懂Excel的回归摘要,就可以读懂SPSS回归输出结果的大部分内容。