偏倚分析流程
- 格式:doc
- 大小:144.50 KB
- 文档页数:4

临床研究中常见偏倚及其控制临床研究中常见偏倚及其控制1.引言在临床研究中,偏倚(bias)是一个非常重要的概念。
它指的是在研究过程中可能导致研究结果与真实情况不一致的因素。
控制偏倚是确保研究结果的可靠性和有效性的关键步骤。
本文将介绍临床研究中常见的偏倚类型及其控制方法。
2.偏倚类型2.1 选择偏倚(Selection bias)选择偏倚是指参与研究的样本群体与目标总体不完全一致,从而导致研究结果的错误。
控制选择偏倚的方法包括:- 随机抽样:通过随机选择样本,减少选择偏倚的可能性。
- 匹配:在研究设计阶段根据特定标准选取对照组样本,使其与受试组样本在某些特征上匹配,减少选择偏倚的影响。
- 敏感性分析:通过分析不同样本选择策略下的研究结果,评估选择偏倚的影响程度。
2.2 测量偏倚(Measurement bias)测量偏倚是指在对研究对象进行测量时,存在的误差或倾向性,导致测量结果与实际情况存在偏差。
控制测量偏倚的方法包括: - 标准化测量工具:使用标准化的测量工具或问卷,确保测量结果的准确性和可比性。
- 培训和校准:对参与测量的研究人员进行培训和校准,提高测量的一致性和准确性。
- 双盲设计:在实验研究中,采用双盲设计,使研究人员和受试者在不知道实际处理情况的情况下进行评估,减少主观判断的干扰。
2.3 回忆偏倚(Recall bias)回忆偏倚是指在调查研究中,受试者对过去事件的回忆存在偏差,导致研究结果的失真。
控制回忆偏倚的方法包括: - 限定回溯时期:对受试者进行限定回溯时期,减少过远过近的回忆,提高回忆的准确性。
- 不透露假设:在调查过程中,不透露研究者的假设和研究目的,减少受试者对回忆的主观干扰。
- 避免听证:避免向受试者介绍其他受试者的回忆情况,以免互相影响。
3.控制偏倚的方法3.1 随机化随机化是控制偏倚的重要手段,它可以通过评估和平衡干扰因素的分布,减少干扰因素对研究结果的影响。
在临床研究中,常用的随机化方法有简单随机化、分层随机化、区组随机化等。
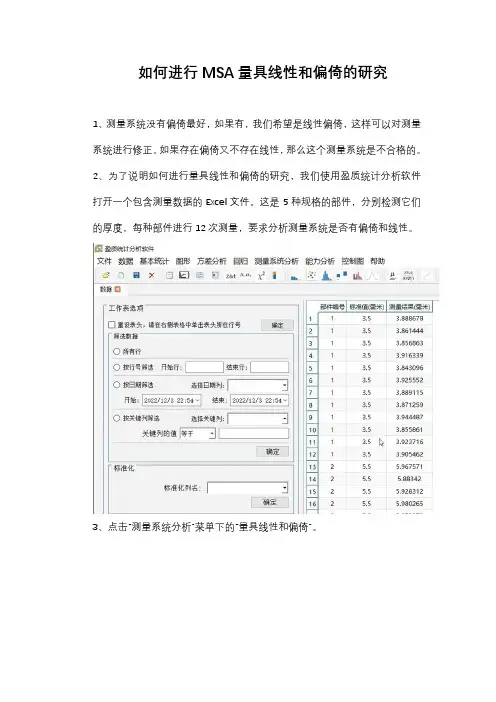
如何进行MSA量具线性和偏倚的研究
1、测量系统没有偏倚最好,如果有,我们希望是线性偏倚,这样可以对测量系统进行修正。
如果存在偏倚又不存在线性,那么这个测量系统是不合格的。
2、为了说明如何进行量具线性和偏倚的研究,我们使用盈质统计分析软件打开一个包含测量数据的Excel文件。
这是5种规格的部件,分别检测它们的厚度,每种部件进行12次测量,要求分析测量系统是否有偏倚和线性。
3、点击“测量系统分析”菜单下的“量具线性和偏倚”。
4、部件号选择“部件编号”这一列,参考值选择“标准值(毫米)”这一列,测量结果选择“测量结果(毫米)”这一列,过程变异或6倍历史标准差有则填,没有则不填。
5、点击确定,可得到量具线性和偏倚的分析结果及图形。
6、从右侧的图形可以清楚看到,测量系统存在正偏倚。
7、再来看左侧的分析结果,量具偏倚,整体偏倚为0.408208,P值为0,表明这是显著的偏倚。
那么来看一下这种偏倚是否有线性,主要看量具线性中的斜率,其P值大于0.05,表明它是不显著的,所以不存在线性。
综上所述,该测量系统存在偏倚却不存在线性,需要更换或调整再评估。
7、如果已知过程变异或6倍历史标准差为0.36,可以更清晰地在图上看到存在偏倚,不存在线性。
8、分析结果的量具偏倚中求得平均偏倚为113.4%,线性百分率只有0.039。
9、如需查看完整视频或了解更多信息,请百度搜索“盈质统计分析软件”查看。

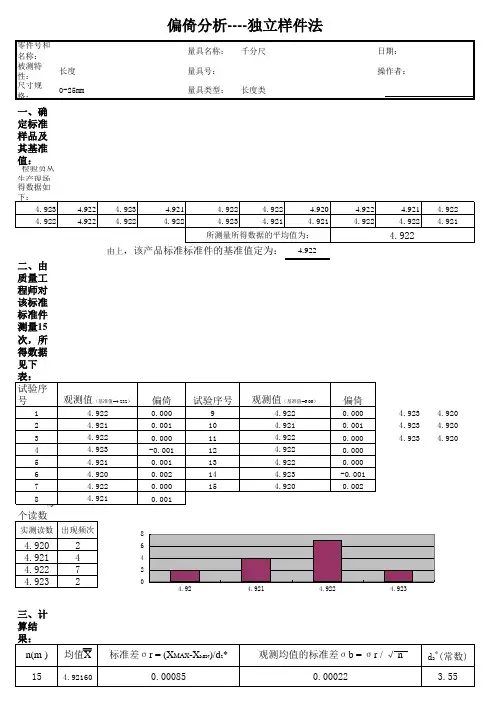
5.7.偏倚分析
5.7.1.独立样本法:
(1)获取一个样本并确定其相对于标准的基准值。
如果没有这样的样品,则选取一个样品,但其测量值应处于预期测量范围的中间区域。
可能需要建立相应于预期测量范围的低、中、高数值的三个样品,并对每个样品用更精密的量具测量10次计算其平均值,此值即为“基准值”。
(2)由一位测量员以常规的方式对每个样品测量10次,并计算10次的平均值,此值即为“观测平均值”。
(3)相对于基准值将数据画出直方图,评审直方图。
a.计算均值:
b.计算可重复性标准偏差:
c.计算偏倚:偏倚=观察平均值-基准值
d.偏倚的t统计量:
t=偏倚/σ
b
e.偏倚接受准则:
如果0 落在围绕偏倚值1-a(95%)置信区间以内,偏倚在a 水平是可接受的。

偏倚分析,你真的知道怎么做吗(打开以下地址查看)https:///s?__biz=MjM5NTk4NjUxMw==&tempkey=MTA4MV9NMDBWN Gd0bWltTUlkdnFOcEFwcUljNU0yMG53NDdtRHY4MTQzSFVaU210eGcxdHA0MmZrRl9 SYVBFeXRKaTB3N2JnZ1ZsOFNqY0RLMEpOdS0yR0dxWmctX0ktQ0pFV05GRXkyZUd MMURuR0JBNDFtRnBOVHI5SkNKWHRMWXJGaDVmOXA4b1gzSThubDBWcTNnU0R hdDFIZlJSaVJfNUFKUXJSQlBBfn4%3D&chksm=3efed867098951713636d70d117aa39b 1523bc95a7eaebbac373f8ca06fa0279a2f60f4ec331#rd测量系统分析当中有个叫偏倚分析的方法,其主要目的是分析测量系统的偏差是否可以接受,从而不会导致因为测量过程的偏差较大而对产品或过程造成错误的决定。
目前绝大多数企业在进行测量系统的偏差分析的时候,都是采用0值与95%的上下区间进行比较的方式来进行判断,认为只要0值落在95%的上下置信区间内,则偏倚就可以接受。
但是,仅凭这一个条件进行判断的方法是不可靠的。
看看下面的例子:从这个例子中可以看出,测量数据中只要改一个和原数据相差很大的值,按照0落在上下95% 区间的判断规则其结论还是可以接受的。
那么怎么样才能确定测量系统的偏倚性可以接受呢?一般要满足三个条件:条件1:重复性变差(即设备变差)%EV≤10%;条件2:数据直方图没有任何异常值;条件3:0值落在上下95%置信区间。
为什么会造成很多企业或MSA爱好者偏偏喜欢采用一个条件来进行偏倚性的判断呢?这其实很多时候都是受到了一些咨询师和培训师的误导,以外找一张Excel表格就可以万事大吉,还是要仔细研究一下呀。

临床研究中的偏倚及控制讲解临床研究是评估新药治疗效果或疾病预防策略有效性等的重要手段,但由于研究设计和实施过程中的一些因素的存在,可能会引入偏倚(bias),导致研究结果的误差。
为了减小偏倚对研究结果的影响,研究人员需要在研究设计和分析中进行偏倚的控制。
本文将就临床研究中的常见偏倚及其控制方法进行讲解。
1. 选择偏倚(Selection Bias)选择偏倚是由于研究对象的选择不是随机的,而是与研究目标相关的因素导致的偏倚。
为了控制选择偏倚,应采取以下措施:-采用随机分组方法:通过随机分组,可以使得研究对象的分组与其自身特征无关,从而减小选择偏倚的风险。
-需要制定明确的入组和排除标准:研究对象的选择应该严格遵守预定的入组和排除标准,避免人为的选择操作。
-多中心研究:多中心研究可以增加样本的代表性,从而减小选择偏倚的可能。
2. 配置偏倚(Allocation Bias)配置偏倚是指由于随机分组的不完全或不严格导致的偏倚。
为了控制配置偏倚,应采取以下措施:-采用适当的随机化方法:应采用随机数字生成、随机封号等方法以实现随机分组,从而减小分组差异的可能性。
-实施隐藏分组:应确保在研究对象入组前,研究人员无法预测下一个分组的具体分组方法,以保证分组的随机性。
-进行双盲或者三盲研究:盲法是控制配置偏倚的有效手段之一,可以减少研究人员对研究对象的知情和预期。
3. 报告偏倚(Reporting Bias)报告偏倚是由于一些研究结果未被完整地报告或被错误地报告而引入的偏倚。
为了控制报告偏倚,应采取以下措施:-注册研究计划:在开始临床研究之前,应该注册研究计划,并明确预先确定的主要研究结局指标,以减小结果报告的选择性。
-完整报告结果:无论结果是积极的还是消极的,都需要完整地报告,以确保研究结果的透明和客观性。
-准确描述研究方法:应该准确地描述研究的设计和方法,包括分析方法和样本大小等,避免结果解读的误导。
4. 记忆偏倚(Recall Bias)记忆偏倚是由于研究对象回忆自身的信息时,受到主观记忆和偏好的影响而引入的偏倚。

临床研究中的偏倚及控制讲解在医学领域,临床研究对于推动医学进步、改善医疗质量至关重要。
然而,在临床研究的过程中,偏倚的存在可能会导致研究结果的不准确和不可靠,从而影响临床决策和患者的治疗效果。
因此,了解和控制临床研究中的偏倚是至关重要的。
一、什么是临床研究中的偏倚偏倚,简单来说,就是在研究过程中,由于各种因素的影响,导致研究结果偏离了真实情况。
在临床研究中,偏倚可能来自研究设计、研究对象的选择、数据的收集和分析等多个环节。
常见的偏倚类型包括选择偏倚、信息偏倚和混杂偏倚。
选择偏倚发生在研究对象的选择过程中。
例如,如果研究某种疾病的治疗效果,但只选择了病情较轻的患者,那么得出的治疗效果可能会过于乐观,无法反映真实情况。
信息偏倚则与数据的收集有关。
比如,患者回忆病史时不准确,或者医生在诊断和评估时存在主观偏差,都可能导致信息偏倚。
混杂偏倚是指除了研究因素之外,还有其他因素同时影响了研究结果。
比如,在研究吸烟与肺癌的关系时,如果没有考虑到空气污染这个混杂因素,可能会得出错误的结论。
二、偏倚产生的原因1、研究设计不合理研究方案不完善,如样本量不足、对照组选择不当、随访时间过短等,都可能导致偏倚的产生。
2、研究对象的选择偏差如果纳入和排除标准不明确,或者在招募研究对象时存在倾向性,就可能导致研究对象不能代表总体人群,从而产生偏倚。
3、测量误差在收集数据时,使用的测量工具不准确、测量方法不一致或者观察者的主观判断差异,都可能引入测量误差,进而导致偏倚。
4、随访丢失在长期的随访研究中,部分研究对象失去联系或拒绝继续参与,导致数据不完整,也可能产生偏倚。
5、数据分析方法不当错误的统计分析方法或不合理的数据分析策略,可能会放大或掩盖偏倚的影响。
三、偏倚对临床研究的影响偏倚会严重影响临床研究的质量和可靠性。
如果研究结果存在偏倚,可能会导致错误的临床决策,浪费医疗资源,甚至对患者的健康造成危害。
例如,一项关于某种新药物疗效的研究,如果因为选择偏倚只纳入了对药物反应良好的患者,可能会高估药物的疗效,从而使医生在临床实践中过度使用该药物,而实际上它对大多数患者可能并没有那么有效。
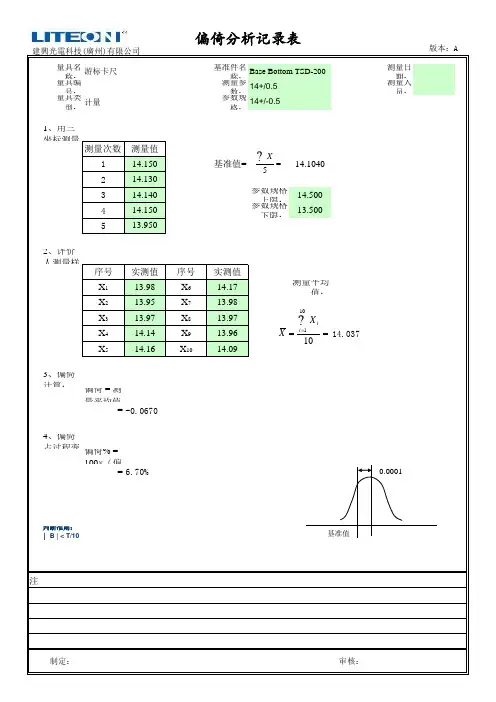
量具名称:基准件名称:测量日期:量具编号:测量参数:测量人员:
量具类型:参数规格:1、用三坐标测量仪确定样件基准值(测量5次,取平均值):
测量次数
测量值114.150基准值=
14.1040
214.130314.140参数规格上限:14.500414.150参数规格下限:13.500
5
13.950
2、评价人测量样件10次,取平均值:
序号实测值序号实测值X 113.98X 614.17测量平均值:
X 213.95X 713.98X 313.97X 813.97X 414.14X 913.9614.037
X 5
14.16
X 10
14.09
3、偏倚计算:
偏倚 = 测量平均值-基准值
= -0.0670
4、偏倚占过程变差(公差)的百分比计算:
偏倚% = 100×(偏倚/过程变差(公差))
= 6.70%
判断准则: | B | < T/10
备注:偏倚占过程变差6.7%,量测系统可以接受.
制定:审核:
2. 本表單格式生效日期:11/1/05
游标卡尺计量
Base Bottom TSD-200 14+/0.514+/-0.5
0.0001
基准值
=
å5
X ==
å=10
10
1
i i
X
X 建興光電科技(廣州)有限公司。

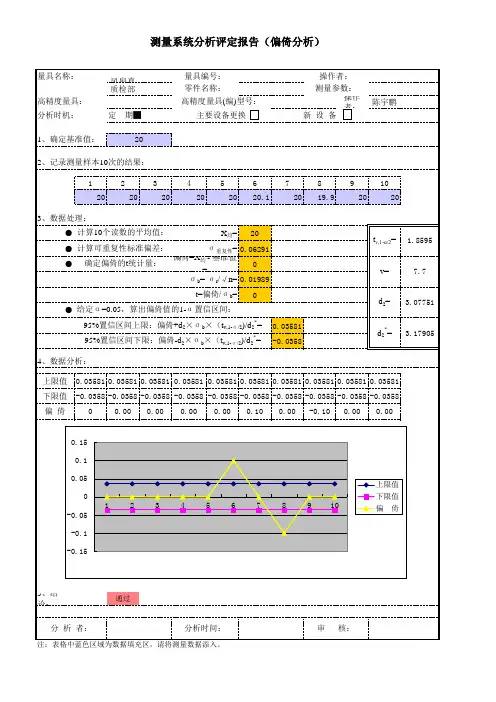
偏倚计算一名制造工程师需要对一个新的测量系统进行偏倚的分析,他的研究程序是:1.选取一个样件,得出一个可追溯到相关标准的基准值。
这个基准值是“6.0”。
2.请一个评价人,以工作状态通常的方法测量这个样件15次。
3.相对于基准值,将数据画出直方图。
评审直方图,确定是否存在特殊原因或出现异常;如果没有,继续分析。
4.计算该评价人n个读数的均值。
公式如下:该评价人15次测量的平均值是:6.00675.计算可重复性标准偏差σr,既σ重复性。
其中d2*可以从《与均值极差分布相关的值》的表中查到,查出的d2*值是:注:g=1(子组容量为1),m=n=15(子组大小)。
计算结果:0.225146.确定偏倚的t统计量:t= 偏倚/σb偏倚 = 测量值的平均值—基准值该评价人15次测量的偏倚值是:0.0067σb利用下面的公式计算。
计算结果是:0.11537.根据子组的容量和子组的大小,通过173页的《与均值极差分布相关的值》表格,查找出自由度(v或df);查出的结果是df=10.88.再查表找出显著的t值。
该值是通过查《t分布分位数表》来找出的,依据自由度v(df)10.8,选α(置信度)= 0.05,α/2就是0.025,1-α/2=0.9750,则从表p=0.9750与自由度V值10.8的交叉处选值。
该表中的自由度只有10和11,没有10.8我们所要求的数,故应予以分摊。
其中10为2.22814,11为2.20099,分摊到10.8的自由度为2.20642。
8.下面开始计算;0.0067-[0.05813(2.20642)]= -0.121560.0067+[0.05813(2.20642)]=0.134969.结果评价计算结果表明,“0”落在这两个上下限计算值之间。
结论是该测量系统的偏倚是可以接受的。

一文解析临床研究中的偏倚及控制方法在临床科研过程中,我们都致力于一点,就是让分析所得的关联性(association)尽量接近病因性(causation)。
除了应用统计学方法以外,非常重要的就是从根本上分析造成偏倚(bias)的原因并控制误差和偏倚。
正如LinkLab前文所提及的,我们需要重点分析和排除的误差包括:随机误差和系统误差(bias),以及发现和解释效应修正(effect modification)。
其中随机误差是随机分布且不可预测的,因此除了增加样本量或重复测量取均值外别无他法。
但对于系统误差和效应修正却可以得到控制或解释,帮助理解所得结论。
系统误差包括:混淆偏倚(confounding)、选择偏倚(selection bias)和信息偏倚(information bias)。
其中,信息偏倚(information bias)是指在研究的实施阶段中从研究对象获取研究所需的信息时产生的系统误差,其原因是由于诊断疾病、测量暴露或结局的方法有问题,导致被比较各组间收集的信息有差异而引入的误差。
本文将不对其进行描述。
阅读此文前强烈建议您阅读LinkLab 2015年11月6日《流行病学也好玩(四):一种方法教会你理清科研思路》,之后就能轻松理解清楚误差和偏倚,以及有效的解决方法。
混淆偏倚(confounding)E:暴露变量(exposure);Y:结果变量(outcome);C:混淆因素在研究暴露与疾病的联系时,C作为混淆因素(confounder)必须满足:1)与exposure相关联;2)与outcome相关联且不是因为exposure;3)不在E和Y的因果链上。
但并不是满足这三个条件就是混淆因素。
由于混杂变量的存在,造成了观察到的联系强度偏离了实际情况,则称为混杂偏倚。
小测试:假设A=exposure,Y=outcome,哪些图的L不是混淆因素呢?答案就是最后一个图。
混淆因素严重干扰我们对于risk的估计,所以必须想办法控制这些variable。
研究中的偏倚检验与调整随着科学研究的不断深入和发展,对研究过程中存在的偏倚进行检验和调整变得越来越重要。
研究中的偏倚是指在研究设计、样本选择、数据收集、数据分析等过程中可能存在的误差或偏离真实情况的情况。
这些偏倚的存在可能会导致结论的不准确性甚至是错误,因此需要进行专门的检验和调整。
一、研究设计中的偏倚检验与调整研究设计中的偏倚是指在研究过程中可能存在的设计错误或方法不当导致的偏差。
为了减少或避免这些偏差,需要进行合理的研究设计和方法选择。
其中,关键是要确保研究的可控性和可重复性,以确保研究结果的可靠性和有效性。
如果在研究设计中出现了不可控的因素或者方法不当导致了结果的不确定性,那么就需要对研究设计进行调整,重新设计或重新选择方法。
二、样本选择中的偏倚检验与调整研究中的样本选择是非常关键的一步。
合理的样本选择可以确保研究结果的代表性和严谨性,而不合理的样本选择则可能导致结果偏离真实情况。
其中,最常见的偏倚是选择偏差,即样本被选择时,存在一些因素可能导致特定个体在样本中被选中的概率比其他个体更高。
为了检验和调整这种偏倚,可以通过随机抽样或特定抽样进行纠正,确保样本的随机性和代表性。
三、数据收集中的偏倚检验与调整在数据收集过程中,存在着多种不同的偏倚可能。
例如,调查问卷的设计可能存在偏颇,而访谈调查中可能会存在因数据筛选或者采集过程中人员选择不当导致的偏差。
这些偏差会影响到结果的准确性和可靠性,因此需要进行相应的校正和调整。
四、数据分析中的偏倚检验与调整在数据分析过程中,常见的偏差有四种类型:选择偏差、测量偏差、操作偏差和分析偏差。
选择偏差是指在样本选择过程中,存在某些因素会导致特定类型的个体被选入样本的概率比其他个体更高;测量偏差是指在数据收集过程中,存在因素会导致数据收集结果出现偏差;操作偏差是指在数据收集和分析过程中,使用的方法或者方式存在误差或者不当;而分析偏差是指在数据分析过程中,处理数据时出现了错误或者偏差。
MSA偏倚分析报告引言在当今社会,人们越来越依赖机器学习和自动化技术来做出决策。
然而,这些技术是否存在偏倚成为一个备受关注的话题。
本文将通过一系列步骤来分析MSA (Machine Sentiment Analysis)算法中是否存在偏倚。
步骤一:数据收集为了进行MSA偏倚分析,我们首先需要收集大量的数据。
这些数据应该包含不同类别、不同来源的文本内容。
我们选择了一份新闻文章的数据集作为实例。
这个数据集包含了来自多个新闻机构的文章,涵盖了不同主题和不同观点。
步骤二:数据预处理在进行MSA偏倚分析之前,我们需要对数据进行预处理。
这包括文本清洗、分词和去除停用词等步骤。
通过这些步骤,我们可以减少噪音和冗余,并提取出关键信息。
步骤三:模型训练接下来,我们将使用机器学习算法来训练一个MSA模型。
在这个过程中,我们会将数据集分成训练集和测试集。
训练集用于训练模型,测试集用于评估模型的性能。
常见的机器学习算法包括朴素贝叶斯、支持向量机和深度学习算法等。
步骤四:模型评估在这一步中,我们将评估训练好的模型的性能。
我们可以使用各种评估指标,如准确率、召回率和F1得分等。
通过这些指标,我们可以了解模型在不同类别上的表现,并判断其是否存在偏倚。
步骤五:偏倚分析在模型评估的基础上,我们可以进一步分析MSA算法是否存在偏倚。
我们可以通过以下几种方法来进行分析: 1. 样本分布分析:检查训练集和测试集中不同类别的样本分布情况。
如果某个类别的样本数量远远超过其他类别,那么模型可能会对该类别偏向。
2. 错误分类分析:分析模型在测试集上的错误分类情况。
如果模型在某个类别上表现较差,可能存在偏倚问题。
3. 特征重要性分析:借助特征重要性分析工具,我们可以了解模型对不同特征的依赖程度。
如果某些特征对模型的预测结果起到更大的影响,那么可能存在偏倚。
步骤六:偏倚修正如果在偏倚分析中发现了MSA算法的偏倚问题,我们需要采取一些措施进行修正。
一文解析临床研究中的偏倚及控制方法临床研究的目标是评估医疗措施的效果和安全性,以指导临床实践或政策制定。
然而,由于人类实验的复杂性和伦理限制,临床研究中存在着多种偏倚(即误差)的可能性,这可能导致研究结论的失真。
因此,为了减少偏倚并提高研究的可靠性,在设计和进行临床研究时需要采取相应的控制方法。
一、随机分组设计:偏倚:选择性偏倚,指研究者可能倾向于将更严重的患者分配到他们认为较好的治疗方法组,或将健康状况较好的患者分配到他们认为较差的治疗方法组。
控制方法:随机分组设计能够将受试者随机分配到不同的治疗组中,以减少选择性偏倚的可能性。
通过随机分组可以保证研究组和对照组之间的可比性,控制其他潜在的干扰因素。
二、盲法:偏倚:知识偏倚,即治疗组和对照组中患者或研究者对受试者的知识或期望有所差异,从而影响了研究结果的评估。
控制方法:单盲法和双盲法是常用的方法。
单盲法指受试者不知道自己所接受的是哪种治疗方法;双盲法指受试者和研究者均不知道其所接受的治疗方法。
盲法能够降低知识偏倚对研究结果的影响,使研究结果更加客观和可靠。
三、对照组选择和匹配:偏倚:记忆偏倚,指回顾性对照研究中,受试者和对照组之间基线特征存在差异,从而影响了研究结果的比较。
控制方法:对照组的选择要与实验组相匹配,以控制其他可能的潜在干扰因素。
匹配可根据年龄、性别、病情严重程度等因素进行。
此外,区组随机设计和块随机设计是一种经常使用的对照组配对方法,可以进一步控制潜在的干扰因素。
四、分层随机:偏倚:混杂因素偏倚,即伴随其他疾病或因素而导致的干扰因素。
控制方法:分层随机法可以将混杂因素作为分层变量,使其在不同的实验组中均匀分布,从而减少混杂因素对研究结果的影响。
五、交叉设计:偏倚:演化偏倚,即研究对象在不同时期因为疾病的发展、治疗的效果等因素而导致结果的改变。
控制方法:交叉设计可以在相同受试者中比较不同治疗方法的效果,消除演化偏倚的影响。
研究对象在不同时期接受不同治疗方法,从而使得个体间的差异及干扰因素得到消除或降低。
临床研究中的偏倚及控制讲解临床研究中的偏倚及控制讲解引言:临床研究是评估医学干预措施安全性和有效性的重要方法。
然而,在进行临床研究时,由于各种原因,可能会产生偏倚,影响研究结果的准确性和可靠性。
因此,了解和控制研究中的偏倚是临床研究的关键之一。
本文将详细介绍临床研究中常见的偏倚类型和控制方法。
一、选择偏倚选择偏倚是由于研究对象选择不当引起的偏倚。
常见的选择偏倚包括:1、非随机选择:研究对象的选择不是随机进行的,可能导致对研究对象特点的错误估计。
2、丢失追踪偏倚:研究对象在随访过程中丢失或失去追踪,导致结果缺失或不全。
3、剔除偏倚:研究者在分析数据时,剔除了某些不符合要求或不完整的数据,导致结果偏向某一方向。
控制选择偏倚的方法包括:1、随机分组:通过随机分组,尽可能减少选择偏倚的可能性。
2、利用对照组:设立对照组,与干预组进行比较,尽可能减少干预因素对结果的干扰。
3、进行完整性分析:对丢失追踪的研究对象进行完整性分析,尽可能充分利用已有的数据。
二、观察偏倚观察偏倚是由于研究者观察方法不当引起的偏倚。
常见的观察偏倚包括:1、信息偏倚:研究者因为主观经验或期望影响了数据的收集和分析。
2、回忆偏倚:研究对象在回顾过去事件时,由于记忆衰退或个人主观因素,记忆出现偏差。
控制观察偏倚的方法包括:1、盲法:对研究者、研究对象和数据分析者进行盲法设计,减少主观因素的干扰。
2、使用标准操作程序:在数据收集时使用标准操作程序,减少信息偏倚和回忆偏倚的可能性。
3、多中心研究:在多个研究中心进行研究,减少个体观察偏倚的影响。
三、报告偏倚报告偏倚是由于研究结果的报道不全面或不准确引起的偏倚。
常见的报告偏倚包括:1、发表偏倚:研究者倾向于发表阳性结果而忽视或压制阴性结果。
2、结果选择性偏倚:只报告某些结果或指标,而忽略其他不利于研究者假设的结果。
控制报告偏倚的方法包括:1、完整报告结果:尽可能完整地报告所有研究结果,包括阳性和阴性结果。
目录:页码:
文件修订履历表 (2)
1目的 (3)
2适用范围 (3)
3定义 (3)
4负责部门..................................................................................................... 错误!未定义书签。
5分析方法 (3)
6附件 (4)
文件修订履历表
1目的
明确测量系统的偏倚研究方法。
2适用范围
适用于可获得更高级测量特性值的测量系统的偏倚研究,更高级的测
量特性值也称基准值。
A.新计量具器验收试验
B.比较鉴定
C.怀疑时的仲裁
3定义
偏倚是测量结果的观察平均值与基准值的差值。
基准值,也称为可接受的基准值或标准值,是充当测量值的一个一致认可的基准,一个基准值可以通过采用更高级的测量设备或(和)有精测资格的人进行10次测量取其平均值来确定。
4负责部门:实验室
5偏倚的分析方法:
5.1在计量室或全尺寸检验设备上对一个零件进行精密测量10次(Bi),取其平均
值作为确定的基准值(B),记录于(G-C45-001)
5.2操作者用被评价量具对5.1中的同一个零件的同一处测量特性值测量10次(Xi),
测量值记录于(G-C45-001)。
5.3由检定人员完成下列计算:
5.3.1观察平均值(X)=∑Xi / 10
5.3.2偏倚(Y)=观测平均值(X)—基准值(B)
5.3.3偏倚率(P)=偏倚(Y)/ 公差(T)*100%
5.4检定人员根据测量系统偏倚的大小,可进一步分析判定测量系统的偏倚是否可接
受。
P≤10% 接受
10% < P≤20% 可能是可接受的
P>20% 不可接受
5.5对于可能是可接受的偏倚的这部分测量系统设计人员/部门要根据其应用的重要
性、量具成本、维修费用等作分析后,作出结论。
偏倚分析应由设备部、质量部、
实验室参加并会签认可,记录见偏倚分析报告(G-C45-002)。
6 附件
A测量系统的偏倚研究记录 G-C45-001
B 偏倚分析报告 G-C45-002
附件A
G-C45-002偏倚分析报告.xlsx G-C45-001测量系统
偏倚分析记录表.xlsx
拟制:杨志红审核:李佳批准:韩伟。