计量经济学实验报告 (5)
- 格式:pdf
- 大小:158.52 KB
- 文档页数:4

计量经济学回归模型实验报告(大全)第一篇:计量经济学回归模型实验报告(大全)回归模型分析报告背景意义:教育是立国之本,强国之基。
随着改革开放的进行、经济的快速发展和人们生活水平的逐步提高,“教育”越来越受到人们的重视。
一方面,人均国内生产总值的增加与教育经费收入的增加有着某种联系,而人口的增长也必定会对教育经费收入产生影响。
本报告将从这两个方面进行分析。
我国1991 年~2013 年的教育经费收入、人均国内生产总值指数、年末城镇人口数的统计资料如下表所示。
试建立教育经费收入Y 关于人均国内生产总值指数 X 1 和年末城镇人口数 X 2的回归模型,并进行回归分析。
年份教育经费收入Y(亿元)人均国内生产总值指数X 1(1978 年=100)年末城镇人口数X 2(万人)1991 731.50282 256.67 31203 1992 867.04905 289.72 32175 1993 1059.93744 326.32 33173 1994 1488.78126 364.91 34169 1995 1877.95011 400.6 35174 1996 2262.33935 435.76 37304 1997 2531.73257 471.13 39449 1998 2949.05918 503.25 41608 1999 3349.04164 536.94 437482000 3849.08058 577.64 45906 2001 4637.66262 621.09 48064 2002 5480.02776 672.99 50212 2003 6208.2653 735.84 52376 2004 7242.59892 805.2 54283 2005 8418.83905 891.31 56212 2006 9815.30865 998.79 58288 2007 12148.0663 1134.67 60633 2008 14500.73742 1237.48 62403 2009 16502.7065 1345.07 64512 2010 19561.84707 1480.87 66978 201123869.29356 1613.61 69079 2012 28655.30519 1730.18 71182 2013 30364.71815 1853.97 73111 资料来源:中经网统计数据库。

目录(一) 研究背景 (2)(二) 理论来源 (2)(三) 模型设定 (2)(四) 数据处理 (2)1. 数据来源 (2)2. 解释变量的设置 (3)(五) 先验预期 (3)1.经验预期 (3)2.散点图分析 (3)(六) 参数估计 (4)(七) 显著性检验 (5)(八) 正态性检验 (5)(九) MWD检验 (5)(十) 相关系数 (7)(十一) 虚拟变量 (7)(十二) 异方差检验、修正 (8)1. 图形检验 (8)2.格莱泽检验 (9)3.帕克检验 (10)4.异方差的修正加权最小二乘法 (10)5.异方差修正后的检验 (11)(十三) 自相关检验 (11)1. 图形法 (11)2.德宾-沃森d检验 (12)(十四) 最终结果 (12)(一) 研究背景中国是一个大国,幅员辽阔,历史上自然地形成了一个极端不平衡发展的格局。
而1978年开始的改革,政府采取了由东向西梯度推进的非均衡发展战略,使已经存在的地区间的差距进一步扩大,不利于整个社会的稳定和发展。
地区发展不平衡问题包括社会发展不平衡,尤其是教育发展的不平衡。
因此关注中国教育发展的地区不平衡性非常迫切。
不仅是因为教育的重要性,还因为当前我国需要进一步推进教育改革的进程,使其朝着更健康的方向发展。
(二) 理论来源刘红梅.中国各地区教育发展水平差异的实证分析[J]数理统计与管理.2013.7(三) 模型设定⏹ Yi=B1+B2X2i+B3X3i+B4X4i+B5X2i+B6X4i+uiY——地区教育水平,用平均受教育年限表示,(年)X2——学生平均预算内教育经费,(万元/人)X3——人均GDP,(万元/人)X4——平均生师比 22⏹ ⏹ ⏹ ⏹(四) 数据处理1. 数据来源:国家统计局官网,选取2014年的数据:1) 各省GDP2) 各地区总人口3) 各地区每十万人拥有的各种受教育程度人口比较数据4) 地区在校总学生数5) 各地区教育财政投入6) 地区每十万总专任教师数2. 解释变量的设置:⏹ X2=地区预算内教育经费/地区在校总学生数=学生平均预算内教育经费(万元/人)X3=地区总GDP/地区总人口=人均GDP(万元/人)X4=地区每十万人口各级学校平均在校生数的和/地区每十万人口总专任教师数=平均生师比⏹ ⏹其中:P为各地区每十万人拥有的各种受教育程度人口比较数T为教育年限1,6,9,12,16(五) 先验预期1. 经验预期:平均受教育年限分别跟学生平均预算内教育经费、人均GDP呈正相关关系,跟平均生师比呈负相关关系。

目录(一) 研究背景 (2)(二) 理论来源 (2)(三) 模型设定 (2)(四) 数据处理 (2)1. 数据来源 (2)2. 解释变量的设置 (3)(五) 先验预期 (3)1.经验预期 (3)2.散点图分析 (3)(六) 参数估计 (4)(七) 显著性检验 (5)(八) 正态性检验 (5)(九) MWD检验 (5)(十) 相关系数 (7)(十一)虚拟变量 (7)(十二)异方差检验、修正 (8)1. 图形检验 (8)2.格莱泽检验 (9)3.帕克检验 (10)4.异方差的修正加权最小二乘法 (10)5.异方差修正后的检验 (11)(十三)自相关检验 (11)1. 图形法 (11)2.德宾-沃森d检验 (12)(十四)最终结果 (12)(一)研究背景中国是一个大国,幅员辽阔,历史上自然地形成了一个极端不平衡发展的格局。
而1978年开始的改革,政府采取了由东向西梯度推进的非均衡发展战略,使已经存在的地区间的差距进一步扩大,不利于整个社会的稳定和发展。
地区发展不平衡问题包括社会发展不平衡,尤其是教育发展的不平衡。
因此关注中国教育发展的地区不平衡性非常迫切。
不仅是因为教育的重要性,还因为当前我国需要进一步推进教育改革的进程,使其朝着更健康的方向发展。
(二)理论来源刘红梅.中国各地区教育发展水平差异的实证分析[J]数理统计与管理.2013.7(三)模型设定⏹Y i=B1+B2X2i+B3X3i+B4X4i+B5X2i 2+B6X4i2+ui⏹Y——地区教育水平,用平均受教育年限表示,(年)⏹X2——学生平均预算内教育经费,(万元/人)⏹X3——人均GDP,(万元/人)⏹X4——平均生师比(四)数据处理1.数据来源:国家统计局官网,选取2014年的数据:1)各省GDP2)各地区总人口3)各地区每十万人拥有的各种受教育程度人口比较数据4)地区在校总学生数5)各地区教育财政投入6)地区每十万总专任教师数2.解释变量的设置:⏹X2=地区预算内教育经费/地区在校总学生数=学生平均预算内教育经费(万元/人)⏹X3=地区总GDP/地区总人口=人均GDP(万元/人)⏹X4=地区每十万人口各级学校平均在校生数的和/地区每十万人口总专任教师数=平均生师比其中:P为各地区每十万人拥有的各种受教育程度人口比较数T为教育年限1,6,9,12,16(五)先验预期1.经验预期:平均受教育年限分别跟学生平均预算内教育经费、人均GDP呈正相关关系,跟平均生师比呈负相关关系。

上海海关学院
实验报告
实验课程名称 __ 计量经济学_ _
指导教师姓名 __ 高军______
学生姓名__王圣___
学生专业班级__税收1401 __
填写日期__2017.6.10
四、模型设定
为分析建筑业企业利润总额(Y)和建筑业总产值(X)的关系,作如下散点图:
Y i=2.368138+0.034980X i (9.049371) (0.001754)
检验
F=;查表可得
绝原假设,此即表明模型存在异方差。
表.用权数w2的结果
(3) w3=1/x^0.5
经估计检验发现用权数w2的效果最好。
可以看出,运用加权最小二乘法消除了异方检验均显著,F检验也显著,即估计结果为
表示国内生产总值。
三、检验自相关
该回归方程可决系数较高,回归系数显著。
dL=1.316,dU=1.469, DW<dL,
,说明在
4.利用EViews软件作如图残差图
LM=TR²=27×0.517409=13.970043,其中p 值为0.0009,表明存在自相关。
自相关问题的处理
由最终模型可知,中国进口需求总额每增加1亿元,平均说来国内生产总值
20。

计量经济学实验基于EViews的中国能源消费影响因素分析学院:班级:学号:姓名:基于EViews的中国能源消费影响因素分析一、背景资料能用消费是引是指生产和生活所消耗的能源。
能源消费按人平均的占有量是衡量一个国家经济发展和人民生活水平的重要标志。
能源是支持经济增长的重要物质基础和生产要素。
能源消费量的不断增长,是现代化建设的重要条件。
我国能源工业的迅速发展和改革开放政策的实施,促使能源产品特别是石油作为一种国际性的特殊商品进入世界能源市场。
随着国民经济的发展和人口的增长,我国能源的供需矛盾日益紧张。
同时,煤炭、石油等常规能源的大量使用和核能的发展,又会造成环境的污染和生态平衡的破坏。
可以看出,它不仅是一个重大的技术、经济问题,而且以成为一个严重的政治问题。
在20世纪的最后二十年里,中国国内生产总值(GDP)翻了两番,但是能源消费仅翻了一番,平均的能源消费弹性仅为左右。
然而自2002年进入新一轮的高速增长周期后,中国能源强度却不断上升,经济发展开始频频受到能源瓶颈问题的困扰。
鉴于此,研究能源问题不仅具有必要性和紧迫性,更具有很大的现实意义。
由于我国目前面临的所谓“能源危机”,主要是由于需求过大引起的,而我国作为世界上最大的发展中国家,人口众多,所需能源不可能完全依赖进口,所以,研究能源的需求显得更加重要。
二、影响因素设定根据西方经济学消费需求理论可知,影响消费需求的因素有:商品的价格、消费者收入水平、相关商品的价格、商品供给、消费者偏好以及消费者对商品价格的预期等。
对于相关商品价格的替代效应,我们认为其只存在能源品种内部之间,而消费者偏好及消费者对商品价格的预期数据差别较大,不容易进行搜集整理在此暂不涉及。
另外,发展经济学认为,来自知识、人力资本的积累水平所体现的技术进步不仅可以带动劳动产出的增长,而且会通过外部效应可以提高劳动力、自然资源、物质资本与生产要素的生产效率,消除其中收益递减的内在联系,带来递增的规模收益。

实验一 EViews软件的基本操作【实验目的】了解EViews软件的基本操作对象,掌握软件的基本操作。
【实验内容】一、EViews软件的安装;二、数据的输入、编辑与序列生成;三、图形分析与描述统计分析;四、数据文件的存贮、调用与转换。
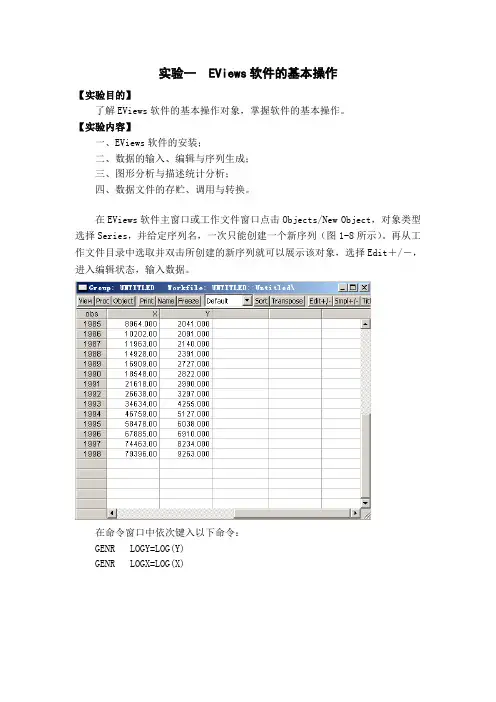
在EViews软件主窗口或工作文件窗口点击Objects/New Object,对象类型选择Series,并给定序列名,一次只能创建一个新序列(图1-8所示)。
再从工作文件目录中选取并双击所创建的新序列就可以展示该对象,选择Edit+/-,进入编辑状态,输入数据。
在命令窗口中依次键入以下命令:GENR LOGY=LOG(Y)GENR LOGX=LOG(X)利用SCAT命令绘制X、Y的相关图加,两者大体呈线性变化趋势。
利用PLOT命令绘制趋势图从图中可以看出,我国1985-1998年间税收收入与GDP都大体呈指数增长趋势。
在序列和数组窗口观察变量的描述统计量数组描述统计量窗口单独变量序列描述统计量窗口存贮工作文件存贮若干个变量将工作文件分别存贮成文本文件和Excel文件在工作文件窗口中选择要保存的一个或多个变量,点击Eviews主窗口菜单栏中的File/Export/Write Text-Lotus-Excel,在弹出的对话框中指定存贮路径和存贮的文件格式(图1-25),若存贮成文本文件则选择Text-ASCII,若存贮成Excel文件则选择Excel.xls,再点击保存按钮,弹出ASCII Text Export(Excel Export)窗口(图1-26),点击OK按钮即可在对象窗口中点击Name按钮,将对象存贮于工作文件。
实验二一元回归模型【实验目的】掌握一元线性、非线性回归模型的建模方法【实验内容】建立我国税收预测模型估计线性回归模型一元线性Y=0.0946x+987.5417残值残值残值半对数函数模型LS log(Y) C xY=7.5086+2.07x*10^-5残值二次函数模型Y=5.58x*10^-7+0.046x+1645.7 残值模型比较四个模型的经济意义都比较合理T检验。

中国国债规模的实证研究一、经济理论背景对于国债规模的研究,可以分为规范研究和实证研究,规范研究方法提供了很好的思想,但未能得出准确的数量结论。
相对规范研究,实证研究方法则侧重于利用国债规模的历史资料,利用各种经济模型,给出国债规模的具体数量。
有关国债规模的实证研究分析,我国理论界也作了不少的研究:杨大楷等人采用相关分析法、灰色关联度分析法:周军民等人使用回归计量模型;朱世武和应惟伟应用传统的统计方法和向量自回归法;高勇强、贺远琼应用相关分析法对中国国债发行规模进行了实证研究。
但是,目前理论界对中国国债规模影响因素的研究如下问题:这些研究都没有说明为什么这些因素对中国国债的规模产生影响;分析的结果不统一,作者们所选择的指针与国债规模的相关度的分析结果不一致;这些实证研究都仅针对中国内部国债发行规模的影响因素进行探讨。
本文应用计量经济法,建立回归直线模型,根据年度资料建立我国国债规模研究模型,对我国国债规模与经济变量之间的影响关系进行实证分析。
二、指标选取和数据搜集(一)国债规模主要影响因素的选择和指标选取1. GDP对国债规模的影响。
一国国债规模明显地由该国的经济发展水平所决定。
一般来说。
经济规模越大,发展水平越高,则国债规模及其潜力就越大。
2.财政收支状况对国债规模的影响。
众所周知,国债的一个重要目的就是弥补财政赤字。
当财政收入越多、财政支出越少时,用国债来弥补财政赤字的压力就越小。
由于在实证分析中,赤字对国债规模的影响不显著,本文选取了财政收入与财政支出两个变量来综合考虑其对国债规模的影响。
3. 预算内投资规模对国债规模影响。
国债的另一主要目的是筹资建设资金,近几年我国国债资金主要用于重大项目、重点项目的建设。
一国预算内投资规模越大,其对资金的需求越大。
当财政收入不足于财政支出时,政府的投资缺口一般要通过发行国债来弥补。
4.还本付息支出对国债规模的影响。
一方面,国债规模越大,还本付息支出越多,当其支出额达到无法以当年财政收入来偿还时,不得不以发新债来还旧债。

实验一一元线性回归模型一、实验目的:了解EViews软件的基本操作对象,掌握软件的基本操作二、实验内容:1、搜集2001-2011年,人均消费和人均gdp数据,构建消费模型,并估计,检验,按照教材例题数据处理过程处理。
表一 2001-2011年人均消费和人均gdp数据年份人均消费人均GDP2001 3611 75432002 3791 81842003 4089 91012004 4552 105612005 5439 140402006 6111 160842007 7081 189342008 8183 226982009 9098 255752010 9968 299922011 12272 351812、下表是中国1978-2000年的财政收入Y和国内生产总值(GDP)的统计资料要求,(1)作出散点图。
建立财政收入随国内生产总值变化的一元线性回归方程,并解释斜率的经济意义;(2)对所建立的回归方程进行检验;(3)若2001年中国国内生产总值为105709亿元,求财政收入的预测值及预测区间。
表二中国1978-2000年的财政收入Y和国内生产总值(GDP)年份Y GDP 年份Y GDP 1978 1132.26 3624.1 1990 2937.1 18547.91979 1146.38 4038.2 1991 3149.48 21617.81980 1159.93 4517.8 1992 3483.37 26638.11981 1175.79 4862.4 1993 4348.95 34634.41982 1212.33 5294.7 1994 5218.1 46759.41983 1366.95 5934.5 1995 6242.2 58478.11984 1642.86 7171 1996 7407.99 67884.61985 2004.82 8964.4 1997 8651.14 74462.61986 2122.01 10202.2 1998 9875.95 78345.21987 2199.35 11962.5 1999 11444.08 82067.51988 2357.24 14928.3 2000 13395.23 89403.61989 2664.9 16909.2三、实验步骤及结果1.1建立工作文件,输入数据在Eviews软件的命令窗口中键入数据输入命令:DATA XF GDP此时将显示一个数组窗口(如所示),即可以输入每个变量的数值图1-1 2001-2011年人均消费和人均gdp数据1.2图形分析借助图形分析可以直观地观察经济变量的变动规律和相关关系,合理地确定模型的数学形式。

经济与政法学院计量经济学试验汇报班级: 国贸1312姓名: 纪方方学号:西藏 3574.0 1475.3 5102.9 12231.9 19604.0 2956.7 陕西 5724.2 3151.2 3351.4 16679.7 16441.0 7667.8 甘肃 4849.6 2203.4 2904.4 14020.7 13329.7 6819.3 青海 6060.2 2347.5 3848.9 13539.5 14015.6 8115.4 宁夏 6489.7 2878.4 4052.6 15321.1 15363.9 8402.8 新疆 6119.11311.85984.615206.215585.36802.6依据试验要求建立计量经济模型为以下线性模型:()()i i i i i i i i i X D X X D X D Y μδβδβδβ++++++=222111100二、 估量参数假定所建模型及扰动项i u 满足古典假定, 能够用OLS 法估量其参数。
利用计算机软件SPSS 作计量经济分析十分方便。
利用SPSS 作简单线性回归分析步骤以下: 1、 建立工作文件2、 输入数据3、估量参数输入/移去变量模型输入变量移去变量方法1 DX2, 其她收入,DX1, 工资收入,居民a. 输入a. 已输入全部请求变量。
Anova b模型平方和df 均方 F Sig.1 回归 2.196E9 5 4.393E8 497.557 .000a残差 4.944E7 56 882878.011总计 2.246E9 61a. 估计变量: (常量), DX2, 其她收入, DX1, 工资收入, 居民。
b. 因变量: 生活消费系数a模型非标准化系数标准系数t Sig.B 标准误差试用版1 (常量) 2599.142 680.415 3.820 .000工资收入.487 .047 .633 10.272 .000其她收入.602 .086 .320 7.019 .000居民-1573.891 933.735 -.131 -1.686 .097DX1 .190 .079 .095 2.398 .020DX2 -.006 .155 -.003 -.038 .970 a. 因变量: 生活消费表2在本例中, 参数估量结果为:2211006.0602.0190.0487.0891.1573142.2599DX X DX X D Y i -+++-=(680.415) (933.735) (0.047) (0.079) (0.086) (0.155) t 3.820 -1.686 10.272 2.398 7.019 -0.038 R 2=0.978 976.02=RF=497.555 df=56RSS u =56*882878.01=49441168.56二、 受约束回归一输入/移去变量模型 输入变量 移去变量 方法 1DX2, 其她收入, 工资收入a. 输入a. 已输入全部请求变量。

实验报告课程名称:计量经济学实验项目:我国国内资金利用研究学生姓名:曾健超学号:200973250131班级:0901班专业:国际经济与贸易指导教师:刘潭秋2011 年 06 月计量经济学实验报告实验时间:2011年6月24日实验地点:一教10楼实验目的:使用Eviews软件,将多元线性回归模型的理论和方法应用于我国的资金来源的研究分析。
实验原理:改革开放以来,我们国家经济持续显著的增长,经济发展一片大好。
经济的持续快速增长需要资本的不断注入,所以我对我们国家的近15年的资金利用做了一个研究。
随着资金的源源不断的涌入,我们国家的资金构成大致分成五个部分,国家预算内资金,国内贷款,利用外资,自筹资金和其他资金。
这五个部分基本上构成了我国资金来源的全部,我选取了改革开放30年来中的15个年份,具有一定的代表性。
资金是经济发展的血液,对我国的资金来源的构成做一个研究十分必要。
在这个实验中,选取国家预算内资金为被解释变量Y,解释变量为国内贷款X1利用外资X2,自筹资金X3,其他资金X4,对我国的资金利用的各部分之间的关系做一个细致的研究。
一、计量经济学模型:根据变量之间的关系,我们假定回归模型为:Y=β0+β1X1+β2X2+β3X3+β4X4+U其中Y表示我国的国家内预算资金,X1、X2、X3、X4分别代表国内贷款,利用外资,自筹资金,其他资金, 0表示在不变的情况下,资金利用的固定部分,β1β2、β3、β4、分别代表我国资金利用的各部分的权数,U 代表随机误差项。
由式子可知,我国资金利用的后面四个部分每增长1个百分点,国家预算内资金会如何变化。
二、验证方法选择:多元线性计量经济学模型的初步估计与分析、异方差检验、序列相关检验、多重共线性检验三、实验步骤:1、基本假设:设国家预算内资金为被解释变量Y,解释变量为国内贷款X1,国外资金X2,自筹资金X3,其他资金X4,U是随机干扰项,代表所有的影响因素。
计量经济学实验报告学院:班级姓名:学号:一、经济学理论概述1、需求是指消费者(家庭)在某一特定时期内,在每一价格水平时愿意而且能够购买的某种商品量。
需求是购买欲望与购买能力的统一。
2、需求定理是说明商品本身价格与其需求量之间关系的理论。
其基本内容是:在其他条件不变的情况下,一种商品的需求量与其本身价格之间成反方向变动,即需求量随着商品本身价格的上升而减少,随商品本身价格的下降而增加。
3、需求量的变动是指其他条件不变的情况下,商品本身价格变动所引起的需求量的变动。
需求量的变动表现为同一条需求曲线上的移动。
二、经济学理论的验证方法在此次试验中,我运用了Eviews和Excel软件对相关数据进行处理和分析。
1、拟合优度检验——可决系数R2统计量回归平方和反应了总离差平方和中可由样本回归线解释的部分,它越大,参差平方和越小,表明样本回归线与样本观测值的拟合程度越高。
2、方程总体线性的显着性检验——F检验(1)方程总体线性的显着性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显着成立作出判断。
(2)给定显着性水平α,查表得到临界值F α(k ,n-k-1),根据样本求出F 统计量的数值后,可通过F >F α(k ,n-k-1) (或F ≤F α(k ,n-k-1))来拒绝(或接受)原假设H0,以判定原方程总体上的线性关系是否显着成立。
3、变量的显着性检验——t 检验 4、异方差性的检验——怀特检验怀特检验不需要排序,对任何形式的异方差都适用。
5、序列相关性的检验——图示法和回归检验法 6、多重共线性的检验——逐步回归法以Y 为被解释变量,逐个引入解释变量,构成回归模型,进行模型估计。
三、验证步骤 1、确定变量 (1)被解释变量“货币流通量”在模型中用“Y ”表示。
(2)解释变量①“货币贷款额”在模型中用“1X ”表示; ②“居民消费价格指数”在模型中用“2X ”表示;③把由于各种原因未考虑到和无法度量的因素归入随机误差项,在模型中用“μ”。
一、实验目的:掌握多重共线性检验的方法和处理的方法二、实验原理:解释变量相关系数法、判定系数检验法、逐步回归法三、实验步骤:1. 创建一个新的工作文件打开Eviews软件,点击File中的new选择Workfile,创立一个新的工作文件,此时将出现Workfile Range,在其中选择时间变量数据Annual,输入实验数据的时间,在Start date 中输入1983年,在End date中输入2000年。
点击ok即可创立一个新的工作文件。
点击save 输入文件名即可保存。
如图:2. 创建一个数据输入窗口在quike文件菜单下找到Empty Group即可创建一个数据输入窗口。
将Excel文档菜单下的中国粮食生产函数模型的数据进行复制,粘贴到Empty Group的空白表格中,将每一列的列标题输入,即六个变量y,x1,x2,x3,x4,x5。
点击Name,把名称存为1点击ok把实验数据表保存。
如图:3. 用普通最小二乘法估计模型参数在quike文件菜单下的Estimate Equation中输入y c x1 x2 x3 x4 x5。
在普通最小二乘法估计模型以及样本确认的情况下,点击ok,即可出现普通最小二乘法的回归结果。
点击name 保存为EQ1。
如图所示:从图中发现:x1的参数估计值为6.212562。
t的估计值为8.385373。
x2的参数估计值为0.421380。
t的估计值为3.319919。
x3的参数估计值为-0.166260反方向变化,故为负值。
x4代表农业机械总动力。
x4的参数估计值为-0.097770,x4的值与所学经济学理论不相符。
x5代表投入农业劳动力。
x5的参数估计值为-0.028425。
一般情况下投入的农业劳动力是正向变化,现在为负值,x5的值与所学经济学理论不相符。
因此说明有可能存在多重共线性。
4.多重共线性检验(1)综合统计检验法根据综合统计检验法,得知判定系数R-squared为0.982798.调整以后的判定系数值问为0.975630,可以看出其拟合优度比较高。
经济与政法学院 计量经济学实验报告班级:国贸 1312 班姓名:纪方方学号:2013104208经济与政法学院实验课程 实验名称计量经济学 异方差性检验与修订实验目的和内容1.利用 SPSS 计算 OLS 估计量 2.对模型估计结果进行检验。
(举例如上)实验步骤1. 构建 X 年全国 31 个省份的税收函数模型, 被解释变量为人均消费支出 y, 解释变量为 从事农业经营的纯收入,其它来源纯收入等。
2. 将数据导入 SPSS 中 3. 求解参数估计值。
4. 根据模型估计结果检验估计效果和拟合图形。
实验成果(系统化研究结果的说明和研究过程介绍,纸张不够可以加页)一、研究目的和意义 中国农村居民人均消费支出主要由人均纯收入来决定。
农村人均纯收入纯收入除从 事农业经营收入外,还包括从事其他产业的经营性收入以及工资性收入、财政收入和转 移支付收入等。
在改革开放的早期,农村居民从事农业经营的收入占到了其纯收入的一 个不小的部分,但其他来源收入可能会在不同的地区差异较大。
为了考察从事农业经营 的收入和其他收入对中国农村居民消费支出增长的影响,可使用如下双对数模型:ln Y 0 1 ln X1 2 ln X 2 其中,Y 表示农村家庭人均消费支出,X1 表示从事农业经营的纯收入,X2 表示其他来源 的纯收入。
2经济与政法学院地区人均消费支出 Y从事农业经营的纯 收入 X1其他来源纯收入 X2北京 天津 河北 山西 内蒙古 辽宁 吉林 黑龙江 上海 江苏 浙江 安徽 福建 江西 山东 河南 湖北 湖南 广东 广西 海南 重庆 四川 贵州 云南 西藏 陕西3552.1 2050.9 1429.8 1221.60 1554.60 1786.30 1661.70 1604.50 4753.20 2374.70 3479.20 1412.40 2503.10 1720.00 1905.00 1375.60 1649.20 1990.30 2703.36 1550.62 1357.43 1475.16 1497.52 1098.39 1336.25 1123.71 1331.03579.10 1314.60 928.80 609.80 1492.80 1254.30 1634.60 1684.10 652.50 1177.60 985.80 1013.10 1053.00 1027.80 1293.00 1083.80 1352.00 908.20 1242.90 1068.80 1386.70 883.20 919.30 764.00 889.40 589.60 614.804446.40 2633.10 1674.80 1346.20 480.50 1303.60 547.60 596.20 5218.40 2607.20 3596.60 1006.90 2327.70 1203.80 1511.60 1014.10 1000.10 1391.30 2526.90 875.60 839.80 1088.00 1067.70 647.80 644.30 814.40 876.003经济与政法学院甘肃 青海 宁夏 新疆1127.37 1330.45 1388.79 1350.23621.60 803.80 859.60 1300.10887.00 753.50 963.40 410.30二、估计参数 假定所建模型及随机扰动项 u i 满足古典假定,可以用 OLS 法估计其参数。
一、实验背景计量经济学是经济学的一个重要分支,它运用数学统计方法对经济现象进行分析和研究。
本实验旨在通过实际操作,使学生掌握计量经济学的基本理论和方法,提高学生的实际操作能力。
二、实验目的1. 掌握计量经济学的基本理论和方法;2. 熟悉计量经济学软件的操作;3. 能够运用计量经济学方法分析实际问题;4. 培养学生的团队合作意识和沟通能力。
三、实验内容1. 实验数据来源本实验数据来源于我国某地区的统计数据,包括地区生产总值(GDP)、居民消费水平(C)、投资水平(I)和进出口总额(M)等变量。
2. 实验步骤(1)数据预处理首先,将原始数据导入计量经济学软件,对数据进行清洗和整理。
包括去除缺失值、异常值等。
(2)建立模型根据实验目的,选择合适的计量经济学模型。
本实验采用多元线性回归模型,研究地区生产总值与居民消费水平、投资水平和进出口总额之间的关系。
(3)模型估计利用计量经济学软件对模型进行参数估计,得到模型参数的估计值。
(4)模型检验对估计得到的模型进行检验,包括残差分析、F检验、t检验等。
(5)模型预测根据估计得到的模型,对地区生产总值进行预测。
3. 实验结果与分析(1)模型估计结果通过计量经济学软件,得到多元线性回归模型的估计结果如下:Y = 10000 + 0.5X1 + 0.3X2 + 0.2X3其中,Y为地区生产总值,X1为居民消费水平,X2为投资水平,X3为进出口总额。
(2)模型检验结果通过残差分析、F检验和t检验,发现模型估计结果具有较好的拟合效果,可以接受。
(3)模型预测结果根据估计得到的模型,对地区生产总值进行预测。
预测结果如下:当居民消费水平为5000元、投资水平为3000元、进出口总额为2000元时,地区生产总值约为11000元。
四、实验总结1. 通过本次实验,使学生掌握了计量经济学的基本理论和方法,提高了学生的实际操作能力;2. 学生学会了运用计量经济学软件进行数据预处理、模型估计、模型检验和模型预测;3. 培养了学生的团队合作意识和沟通能力。
实验异方差性一、实验目的掌握异方差和自相关模型的检验方法与处理方法.二、实验要求1.应用教材第141页案例做异方差模型的图形法检验、Goldfeld-Quanadt 检验与White检验,使用WLS法对异方差进行修正;2.应用教材第171页案例做自相关模型的图形法检验和DW检验,使用科克伦—奥克特迭代法对自相关进行修正。
三、实验原理异方差性检验:图形法检验、Goldfeld-Quanadt检验、White检验与加权最小二乘法;四、预备知识Goldfeld-Quanadt检验、White检验、加权最小二乘法。
五、实验步骤【案例1】异方差性在现实经济活动中,最小二乘法的基本假定并非都能满足,本案例将讨论随机误差违背基本假定的一个方面——异方差性。
本案例将介绍:异方差模型的图形法检验、Goldfeld-Quanadt检验与White检验;异方差模型的WLS法修正。
1、表中列出了1995年北京市规模最大的20家百货零售商店的商品销售收入X和销售利润Y的统计资料。
2、参数估计(1)按住ctrl键,同时选中序列X和序列Y,点右键,在所出现的右键菜单中,选择open\as Group弹出一对话框,点击其上的“确定”,可生成并打开一个群对象(图 2.3.1)。
在群对象窗口工具栏中点击view\Graph\Scatter\Simple Scatter, 可得X与Y的简单散点图,可以看出X与Y是带有截距的近似线性关系。
(2)点击主界面菜单Quick\Estimate Equation ,在弹出的对话框中输入y c x ,点确定即可得到回归结果从图中可以看出,残差平方对解释变量X 的散点图主要分布在图形中的下三角部分,大致可以看出残差平方和随的变动呈现增大的趋势。
因此,2^i e 2^i e i X模型有可能存在异方差。
3、检验模型的异方差本例用的是1995年北京市规模最大的20家百货零售商店的商品销售收入和销售利润,由于地区之间存在的不同人口数,因此,对每一家百货零售商店的销售会存在不同的需求,这种差异使得模型很容易产生异方差,从而影响模型的估计和运用。
教材第六章6.11的问题分析,具体数据在实验五文件夹中给出了未经季节调整的零售服装和饰品季度数据(1992年第一季度~2008年第二季度): 考虑下面的模型:其中,备择实验步骤:1.建立Eviews 工作文件并录入数据(原始数据见文件夹中文件名:实验五-虚拟变量回归模型-备择实验数据6.11)。
{{{,1,04,1,03,1,024433221===++++=tt t tt t t tD D D u D B D B D B B Sales其他 第四季度第二季度数据其他第三季度数据其他2.估计上述回归。
取第一季度为基准类。
则:se=(60.92140) (61.86597) (61.86597) t= (0.963) (0.931) (21.629) p=(0.3393)(0.3554)(0.0000)R 2=0.912955{{{,1,04,1,03,1,02===+=tt t ttD D D u Sales DDDSalestttt432109.133860907.576667.584118.930+++=∧3.解释各个系数的含义。
含义:第一季度的销售量为930.4118;第二季度比第一季度多58.6667;第三季度比第一季度多57.60907;第四季度比第一季度多1338.109;但是只有第四季度t的统计量通过了检验,即第四季度与第一季度是显著不同的;其他各季度与第一季度没有显著差别。
各季度的销售额为:第一季度:930.4118;第二季度:989.0785第三季度:988.0209;第四季度: 2268.5214.如何利用估计的回归结果消除季节模式用实际的Y减去方程中估计的Y,即方程的残差;然后加上基础类的均值B:1。