统计学之虚拟变量
- 格式:pptx
- 大小:1.39 MB
- 文档页数:45

虚拟变量的名词解释在数据分析和统计学中,虚拟变量是一种常用的变量类型。
虚拟变量,也被称为哑变量或指示变量,通常用来表示分类变量的不同水平或类别。
虚拟变量在数据分析中起到了至关重要的作用。
通过将分类变量转化为虚拟变量,我们能够使用数值变量来表示不同的类别,并在统计模型中使用。
这样做的好处是可以将分类变量的影响纳入模型中,而不是简单地将其作为单一的类别。
虚拟变量通常采用二元编码方式来表示分类变量的不同类别。
举个例子,假设我们有一个分类变量是颜色,可能有红、蓝、绿三个类别。
我们可以使用两个虚拟变量来表示这三个类别,比如我们可以设定一个虚拟变量为红色,取值为1表示观测值为红色,取值为0表示观测值不是红色;另外一个虚拟变量设定为蓝色,同样取值为1或0。
这样,对于每个观测值,我们可以用两个二元变量表示其颜色。
虚拟变量在回归分析中特别有用。
通过将分类变量转化为虚拟变量后,我们可以将其纳入回归模型中进行分析。
以线性回归为例,如果我们的自变量包含一个虚拟变量,我们可以在回归模型中将其作为一个系数进行解释。
假设这个虚拟变量是性别,取值为1表示男性,取值为0表示女性。
在回归模型中,该虚拟变量的系数,即回归系数,可以解释男性和女性在因变量上的平均差异。
另一个常见的用途是在分类器和机器学习算法中。
虚拟变量可以作为输入特征,帮助机器学习算法区分不同的类别。
比如,在邮件垃圾分类器中,我们可以使用虚拟变量表示是否包含某个关键词,而分类器可以根据虚拟变量的取值来判断邮件是否是垃圾邮件。
此外,虚拟变量还可以消除分类变量之间的顺序关系。
有时候,分类变量之间存在不同的大小或顺序。
例如,季节变量可以表示春季、夏季、秋季和冬季。
如果我们简单地将这个分类变量用1、2、3、4来编码,模型可能会误认为这是一种连续变量,并对它们的大小加以解释。
为了消除这种顺序关系,我们可以将这个分类变量转化为三个虚拟变量,每个季节一个虚拟变量,使得其取值只能为0或1,而不再具有顺序性。



虚拟变量实验报告引言虚拟变量(dummy variable)是在统计学中常用的一种技术,用于表示分类变量。
通过将分类变量转换为二进制数值变量,虚拟变量可以在回归分析、方差分析以及其他统计模型中发挥重要作用。
本实验报告旨在介绍虚拟变量的概念、用法以及在实际应用中的一些注意事项。
虚拟变量的定义虚拟变量是一种二元变量,用于表示某个特征是否存在。
通常情况下,虚拟变量的取值为0或1。
虚拟变量可以用于将分类变量转换为数值变量,使其适用于各种统计模型。
虚拟变量的应用虚拟变量主要用于以下两个方面的统计模型:1. 回归分析在回归分析中,虚拟变量被用于表示一个分类变量的不同水平。
例如,在研究某产品的销售量时,可以引入虚拟变量表示该产品是否进行了促销活动。
这样,回归模型就可以分析促销活动对销售量的影响。
2. 方差分析方差分析是一种用于比较不同组之间差异的统计方法。
虚拟变量可以用于表示不同组的存在与否。
例如,在研究不同药物对某种疾病治疗效果时,可以引入虚拟变量表示不同药物的使用与否,进而进行方差分析。
如何创建虚拟变量创建虚拟变量的方法通常有两种:1. 单变量编码单变量编码是最常见的创建虚拟变量的方法。
对于具有k个水平的分类变量,单变量编码将该变量转换为k-1个虚拟变量。
其中,k-1个虚拟变量分别表示k个水平的存在与否。
例如,在研究不同颜色对产品销售量的影响时,可以使用单变量编码将颜色变量转换为两个虚拟变量,分别表示是否为蓝色和是否为红色。
2. 二进制编码二进制编码是一种使用更少虚拟变量的方法。
对于具有k个水平的分类变量,二进制编码将该变量转换为log2(k)个虚拟变量。
其中,每个虚拟变量都表示一个水平的存在与否。
例如,在研究不同国家对某项政策的支持时,可以使用二进制编码将国家变量转换为几个虚拟变量,每个虚拟变量表示一个国家的存在与否。
虚拟变量的注意事项在使用虚拟变量时需要注意以下几点:1.避免虚拟变量陷阱:虚拟变量陷阱是指多个虚拟变量之间存在完全共线性的情况,这会导致回归模型的多重共线性。

dummy variable的系数解释
在统计学中,虚拟变量(dummy variable)也称为指示变量或分类变量,通常用于表示分类数据。
虚拟变量的系数解释依赖于其使用的回归模型和解释变量的设定。
对于二元虚拟变量,其系数解释通常表示当自变量增加一个单位时,因变量相对于参考类别的变化量。
例如,如果一个二元虚拟变量用于表示某个人是否为男性(男性为1,女性为0),则该变量的系数可以解释为相对于女性,男性在因变量上的平均变化量。
对于多元虚拟变量,情况会变得更加复杂。
每个虚拟变量的系数都表示该变量相对于参考类别的变化量。
为了解释多元虚拟变量的系数,可以使用冗余分析(redundancy analysis)或主成分分析(principal component analysis)等方法来了解各个自变量对因变量的贡献程度。
需要注意的是,虚拟变量的系数解释并不是固定不变的,它可能受到模型设定、数据特征和样本大小等因素的影响。
因此,在解释虚拟变量的系数时,需要仔细考虑其背景和上下文,并谨慎评估其意义和可靠性。

虚拟变量熵权法-回复虚拟变量与熵权法在统计学中具有重要的应用,本文将一步一步回答关于这两个主题的问题,并对其原理和应用进行探讨。
一、虚拟变量(Dummy Variable)虚拟变量在统计学中是一种用于表示分类变量的技术。
分类变量是一种具有离散取值的变量,例如性别(男/女)或者国家(中国/美国/英国等)。
然而,一般的统计分析方法不能直接处理这种离散取值的情况,因此需要使用虚拟变量来对其进行编码。
1.1 什么是虚拟变量?虚拟变量也被称为二值变量,其取值为0或1。
虚拟变量用于表示原始分类变量的不同取值,例如当变量为性别时,可以使用一个虚拟变量表示"男",另一个虚拟变量表示"女"。
虚拟变量的取值通常为1(表示某个特定类型)或者0(表示其他类型)。
1.2 虚拟变量与独热编码的关系是什么?独热编码是一种常见的虚拟变量编码方式,它将分类变量的每个取值都表示为0或1的形式。
具体而言,对于一个变量有n个取值,独热编码将其转换为n个虚拟变量,其中每一个虚拟变量只有一个取值为1,其他都为0。
1.3 虚拟变量的应用场景有哪些?虚拟变量的应用场景非常广泛。
例如,在回归分析中,虚拟变量可以用来表示一个或多个分类变量,以便研究它们与其他连续变量之间的关系。
在实验设计中,虚拟变量可以用来研究因素的影响,例如对于一个商品的销售量,虚拟变量可以表示不同的市场营销策略。
二、熵权法(Entropy Weight Method)熵权法是一种基于信息熵理论的数据处理方法。
它通过计算各指标的信息熵,进而确定其权重,用于比较和评价不同指标的重要性。
2.1 什么是熵权法?熵权法是一种模糊综合评价方法,它通过计算各指标的信息熵,然后按熵值的大小确定各指标的权重。
熵值越大,表示该指标的信息量越丰富,对决策结果的影响越大,权重也就越高。
2.2 熵权法的原理是什么?熵权法的核心原理是基于信息熵的概念。
信息熵是度量一个随机事件或变量的不确定性的度量,熵值越大表示不确定性越高。



设计虚拟变量方法
虚拟变量方法(Dummy Variable Method)是一种在统计分析中常用的方法,用于将类别变量转换为可供回归模型使用的二进制虚拟变量。
它将每个类别变量的取值拆分成多个二进制变量,每个变量代表一个类别,其取值为1或0。
以下是设计虚拟变量方法的步骤:
1. 确定需要转换为虚拟变量的类别变量。
在回归分析中,通常将影响因素为类别的变量转换为虚拟变量。
2. 为每个类别变量的取值创建一个虚拟变量。
对于一个类别变量,如果它有k 个不同的取值,那么就需要创建k-1个虚拟变量。
例如,如果一个类别变量的取值为A、B、C,那么需要创建两个虚拟变量D1和D2。
其中,D1表示取值为B,D2表示取值为C。
取值为A的情况可以通过所有虚拟变量都为0来表示。
3. 分配虚拟变量的取值。
对于每个样本,根据类别变量的取值,为对应的虚拟变量赋值1,其余虚拟变量赋值0。
4. 回归分析。
将转换后的虚拟变量和其他变量一起用于回归模型中进行分析。
需要注意以下几点:
- 虚拟变量方法的基础是虚拟变量陷阱(Dummy Variable Trap)。
为了避免共
线性问题,应该始终忽略转换后的一个虚拟变量。
- 在创建虚拟变量时,可以使用软件工具自动完成。
许多统计软件如Python的pandas库、R的caret包和SPSS等都提供了创建虚拟变量的函数或方法。
- 虚拟变量方法一般适用于线性回归模型,对于其他模型,如逻辑回归等,也可以使用相应的方法将类别变量进行转换。
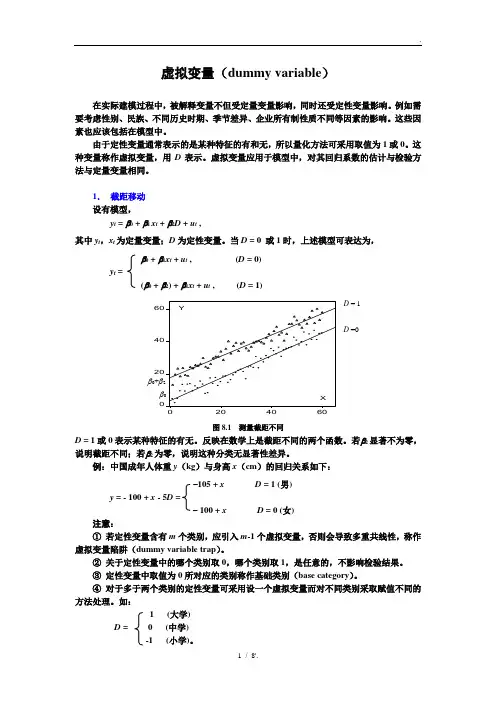
第二节 虚拟变量一、虚拟变量及其作用经济变量的影响因素中间有时还包括一些定性因素,例如,消费习惯、地区差异将直接影响居民的消费支出;季节因素对产品的生产和销售都会产生影响。
舍弃定性因素,一方面不能真实地描述经济变量之间的相关关系,增大模型的设定误差,同时也不能计量这些定性因素的影响。
10D ⎧=⎨⎩ ,1为城镇居民,0为农村居民1D ⎧=⎨⎩ ,1为销售旺季,0为销售淡季10D ⎧=⎨⎩, 1政策紧缩,0为政策宽松10D ⎧=⎨⎩,1为本科以上学历,0以本科以下学历在计量经济模型中引入虚拟变量有以下作用: (1) 可以描述和测量定性因素的影响(2) 能够正确反映经济变量之间的相互关系,提高模型的精度。
(3) 便于处理异常数据;当样本资料中存在异常数据时,一般有三种处理方式,一是在样本容量较大的时候直接剔除异常数据;二是用平均数方式修匀异常数据;三是设置虚拟变量:虚拟变量的设置有规律吗?练习:中日关系的冷热也是一个定性因素,如果让你设置,你怎么设置呢? 表 一个局部数据列表012wage female edu u βββ=+++问:如果1表示女性,0表示男性,那么1β的经济含义是什么呢^-^通过图形来说明。
二、虚拟变量的设定(一) 虚拟变量的引入方式:加法方式,乘法方式,一般方式。
1.加法方式居民家庭的教育费用支出除了受收入水平的影响之外,还与子女的年龄结构密切相关。
如果家庭中有适龄子女,教育支出就多一些。
1D ⎧=⎨⎩ ,1为有适龄子女,0为无适龄子女。
将家庭教育费用支出函数取成: 012i i i i Y X D βββε=+++ 这样,就形成了两个函数:没有适龄子女家庭的教育费用支出:01i i i Y X ββε=++有适龄子女家庭的教育费用支出:012i i i Y X βββε=+++=021()i i X βββε+++画出样本回归方程的图像可知,以加法方式引入虚拟变量时,反映的是定性因素对截矩的影响,即平均水平的差异情况。
第⼗章虚拟变量第⼗章虚拟变量⼀个例⼦:⼯资⽅程个⼈薪资收⼊(earnings )受到多种因素的影响,⼈们特别感兴趣的两个主要因素是受教育程度 (years of education) 和⼯作经验(years of experience )。
为区别这两个因素对⼯资报酬的影响,就需要⼀个多元回归模型。
经济学家在设定⼯资模型时,⼀般认为因变量使⽤⼯资的对数⽐⼯资本⾝更贴近⾼斯—马尔科夫假定。
其模型的⼀个形式为01122ln i i i E y y u βββ=+++其中,E 、1i y 和2i y 分别表⽰⼯资、受教育程度和⼯作经验。
⽤OLS 估计该模型得 01122ln i i E y y βββ∧∧∧∧=++ 1β∧代表⼯作经验相同的情况下,受教育程度(1i y )对⼯资对数(ln E ∧)的边际影响。
或者理解为受教育年限增加1年,⼯资的百分⽐变化1111(ln )(ln )1d E d E dE dE dE E dy dE dy E dy dy =?==1β∧= 11i y β∧是⼯资对受教育程度的弹性;2β∧代表受教育程度不变的情况下,⼯作经验(2i y )对⼯资对数(ln E ∧)的边际影响。
通过对⼯资的分析发现,受教育程度和⼯作经验的影响因⼈⽽异。
⼀般认为性别歧视在⼀定程度上是存在的。
性别歧视是否存在?若存在,如何研究男性与⼥性的报酬差异?为此,可以引⼊⼀个特殊的变量对观测对象进⾏分组。
这个特殊的变量就是虚拟变量。
⼀. 虚拟变量的概念虚拟变量(dummy variable )⼜称为双值变量,取值0或1,⽤以反映观测对象是否具有某种性质或属性,习惯上⽤D 表⽰。
在计量经济模型中引⼊虚拟变量,可以扩展模型的应⽤范围,使模型能更准确反映真实情况。
⼆. 虚拟变量作为⾃变量(⼀)⾃变量中只有虚拟变量性别(i D )与收⼊(i y )的关系,可⽤模型i i i y D u αβ=++,i D 是虚拟变量,01i D ?=??m a n w o m a n ()i i E y D ααβαβ=+=+ 01i i D D ==若经过检验,β是显著的,即0β≠,说明性别对收⼊有明显影响。
虚拟变量熵权法-回复什么是虚拟变量和熵权法,并介绍它们的应用。
在统计学和机器学习领域,虚拟变量(Dummy variable)和熵权法(Entropy weighting)是两个常用的概念和方法。
虚拟变量是一种在回归分析和实证研究中常用的数值表示方法,而熵权法是一种多指标综合评价方法。
下面将一步一步回答关于虚拟变量和熵权法的问题。
一、什么是虚拟变量?虚拟变量又称为哑变量或指示变量,在数学和统计学中,是用来表示分类变量的一种数值表示方法。
通常情况下,分类变量是离散的,比如性别、国籍等。
虚拟变量可以将这些分类变量编码为数值,用0和1表示。
虚拟变量的编码规则是,为每个分类变量设定一个虚拟变量,如果观测数据属于某一类别,则该虚拟变量取值为1,否则为0。
这种编码方式可以有效地将分类变量引入回归模型中。
虚拟变量的使用可以帮助解决回归分析中的一些问题,比如处理分类变量、多组比较和交互效应等。
在实际应用中,虚拟变量的使用非常广泛,比如用来研究不同性别对收入的影响、不同地区对销售额的影响等。
二、什么是熵权法?熵权法是一种多指标综合评价方法,用来确定多个指标的权重以及指标之间的重要性关系。
该方法基于信息熵原理,通过计算指标的信息熵来确定其权重。
熵是度量信息的不确定性的指标,表示了信息的平均信息量。
在熵权法中,先计算每个指标的熵值,然后根据熵值大小来确定其权重。
熵值越大,代表了指标的不确定性越高,权重越小;反之,熵值越小,代表了指标的不确定性越小,权重越大。
熵权法的优点是能够考虑到指标之间的相互影响和重要性关系,从而更准确地反映多指标下的综合评价结果。
该方法在决策分析、风险评估和投资评价等领域得到了广泛的应用。
三、虚拟变量和熵权法的应用虚拟变量和熵权法在不同领域有着各自的应用。
虚拟变量在回归分析中的应用很广泛。
通过将分类变量转化为虚拟变量,可以将其引入回归模型中,从而探究不同类别对因变量的影响。
比如,研究性别对工资的影响时,可以将性别编码为虚拟变量,然后用回归模型来解释工资与性别之间的关系。
一、课程名称:虚拟变量二、教学目标:1. 理解虚拟变量的概念和作用;2. 掌握虚拟变量的设置方法和步骤;3. 能够运用虚拟变量进行回归分析;4. 培养学生分析问题和解决问题的能力。
三、教学重点与难点:1. 教学重点:虚拟变量的概念、设置方法和步骤;2. 教学难点:虚拟变量的应用和回归分析。
四、教学过程:(一)导入1. 通过生活中的实例引入虚拟变量的概念,激发学生的学习兴趣;2. 引导学生思考虚拟变量在统计学和计量经济学中的重要作用。
(二)教学内容1. 虚拟变量的概念及作用- 解释虚拟变量的定义,使学生了解虚拟变量的含义;- 分析虚拟变量在统计学和计量经济学中的具体应用,如回归分析、时间序列分析等。
2. 虚拟变量的设置方法- 介绍虚拟变量的类型,如二元虚拟变量、多元虚拟变量等;- 讲解虚拟变量的设置步骤,包括确定变量类型、构建虚拟变量矩阵等;- 通过实例演示虚拟变量的设置过程。
3. 虚拟变量的应用- 介绍虚拟变量在回归分析中的应用,如处理定性变量、分离异常因素等;- 讲解虚拟变量系数的估计和检验方法;- 通过实例展示虚拟变量在回归分析中的具体应用。
(三)课堂练习1. 让学生独立完成虚拟变量的设置和回归分析,巩固所学知识;2. 教师巡视指导,解答学生提出的问题。
(四)课堂总结1. 总结本节课所学内容,强调虚拟变量的概念、设置方法和应用;2. 鼓励学生在实际生活中运用虚拟变量解决实际问题。
五、教学评价:1. 课堂表现:观察学生在课堂上的学习态度、参与程度等;2. 作业完成情况:检查学生独立完成虚拟变量设置和回归分析的能力;3. 期末考试:考察学生对虚拟变量的掌握程度。
六、教学反思:1. 教师根据教学效果,反思教学过程中的优点和不足;2. 教师针对学生的反馈,调整教学内容和方法,提高教学质量。
本教案设计旨在帮助学生掌握虚拟变量的概念、设置方法和应用,培养学生的实际操作能力,提高学生的综合素质。
通过本课程的学习,使学生能够将虚拟变量应用于实际问题,为后续统计学和计量经济学课程的学习打下坚实基础。
虚拟变量熵权法虚拟变量是用来表示分类变量的一种方法。
在统计学和机器学习中,分类变量是指具有有限个可能取值的变量,例如性别(男/女)、教育水平(小学/初中/高中/大学)等。
虚拟变量的引入使得分类变量可以被用于回归分析和其他统计模型中。
在创建虚拟变量时,我们将原始的分类变量进行拆分,转化为多个二元变量,其中一个分类变量的每个可能取值对应一个二元变量。
例如,对于性别变量,我们可以创建一个名为“性别_男”的虚拟变量(取值为1表示为男性,取值为0表示为女性),以及一个名为“性别_女”的虚拟变量(取值为1表示为女性,取值为0表示为男性)。
这样,原始的性别变量就被拆分成了两个虚拟变量。
虚拟变量的引入有以下几个优点:1.保留了分类变量的信息:原始的分类变量可能包含有用的信息,通过引入虚拟变量,我们可以在建模中保留这些信息。
2.支持回归分析:在回归分析中,我们需要将所有的变量转化为数值变量,以便进行计算。
虚拟变量的引入使得分类变量可以被纳入回归分析中。
3.可以解决分类变量的非线性关系:虚拟变量的引入使得分类变量可以表达非线性关系,例如可以通过引入交互项来探索不同分类变量之间的相互作用。
虚拟变量的引入也有一些注意事项:1.避免虚拟变量陷阱:虚拟变量陷阱指的是在回归模型中引入多个虚拟变量时,不能同时包含所有的虚拟变量。
为了避免多重共线性(即变量之间高度相关),通常会在模型中删除一个虚拟变量。
例如,在性别变量中,只需要包含一个虚拟变量(例如“性别_男”),即可表达性别信息。
2.阈值的选择:在将连续变量进行虚拟变量转化时,通常需要选择一个阈值来确定变量的类别。
这个选择可能对最终模型的结果产生影响,需要根据具体问题和数据进行选择。
熵权法(Entropy Weight Method)是一种多指标权重确定方法,用于在无主观信息的情况下,确定指标的权重。
熵权法是基于信息熵的原理,通过计算指标之间的相对信息熵,来确定其权重。
熵权法的步骤如下:1.数据标准化:将原始的指标数据进行标准化处理,使得不同指标的量纲一致,方便后续计算。