人均国内生产总值和人均消费水平相关回归分析课堂练习题
- 格式:docx
- 大小:17.45 KB
- 文档页数:2

第七章思考与练习参考答案1.答:函数关系是两变量之间的确定性关系,即当一个变量取一定数值时,另一个变量有确定值与之相对应;而相关关系表示的是两变量之间的一种不确定性关系,具体表示为当一个变量取一定数值时,与之相对应的另一变量的数值虽然不确定,但它仍按某种规律在一定的范围内变化。
2.答:相关和回归都是研究现象及变量之间相互关系的方法。
相关分析研究变量之间相关的方向和相关的程度,但不能确定变量间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况;回归分析则可以找到研究变量之间相互关系的具体形式,并可变量之间的数量联系进行测定,确定一个回归方程,并根据这个回归方程从已知量推测未知量。
3.答:单相关系数是度量两个变量之间线性相关程度的指标,其计算公式为:总体相关系数,样本相关系数。
复相关系数是多元线性回归分析中度量因变量与其它多个自变量之间的线性相关程度的指标,它是方程的判定系数2R 的正的平方根。
偏相关系数是多元线性回归分析中度量在其它变量不变的情况下两个变量之间真实相关程度的指标,它反映了在消除其他变量影响的条件下两个变量之间的线性相关程度。
4.答:回归模型假定总体上因变量Y 与自变量X 之间存在着近似的线性函数关系,可表示为t t t u X Y ++=10ββ,这就是总体回归函数,其中u t 是随机误差项,可以反映未考虑的其他各种因素对Y 的影响。
根据样本数据拟合的方程,就是样本回归函数,以一元线性回归模型的样本回归函数为例可表示为:tt X Y 10ˆˆˆββ+=。
总体回归函数事实上是未知的,需要利用样本的信息对其进行估计,样本回归函数是对总体回归函数的近似反映。
两者的区别主要包括:第一,总体回归直线是未知的,它只有一条;而样本回归直线则是根据样本数据拟合的,每抽取一组样本,便可以拟合一条样本回归直线。
第二,总体回归函数中的0β和1β是未知的参数,表现为常数;而样本回归直线中的0ˆβ和1ˆβ是随机变量,其具体数值随所抽取的样本观测值不同而变动。


1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
α=)。
(5)检验回归方程线性关系的显著性(0.05(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:系数a模型非标准化系数标准系数t Sig.相关性B标准误差试用版零阶偏部分1(常量).003人均GDP.309.008.998.000.998.998.998 a. 因变量: 人均消费水平有很强的线性关系。
(3)回归方程:734.6930.309y x=+系数a模型非标准化系数标准系数t Sig.相关性回归系数的含义:人均GDP没增加1元,人均消费增加元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t显著性B标准误Beta1(常量)人均GDP(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1.998a.996.996a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
模型摘要模型R R 方调整的 R 方估计的标准差1.998(a)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(5)F检验:Anova b模型平方和df均方F Sig.1回归.6801.680.000a 残差5总计.7146a. 预测变量: (常量), 人均GDP。
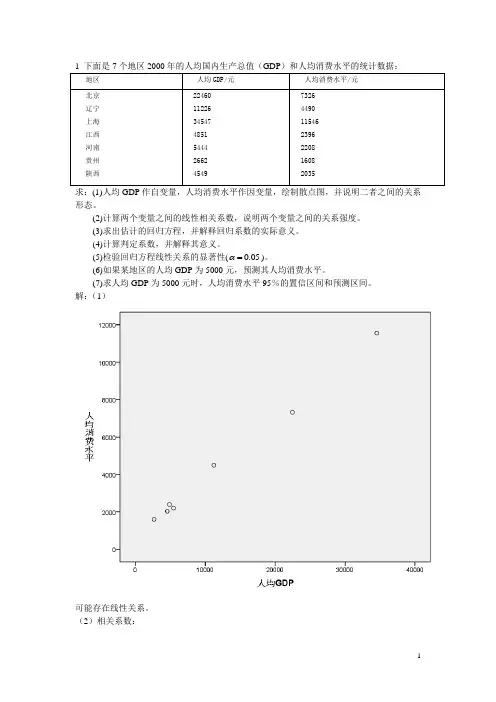
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。



基于回归分析的居民人均消费水平与人均GDP的研究居民消费在社会经济的持续发展中有着重要作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长。
本文是对1978年至2009年的居民消费水平数据进行分析并预测。
标签:回归分析检验居民消费水平一、简介改革开放以来,随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也在不断增长。
研究中国全体居民的消费水平与经济发展的数量关系,对于探寻居民消费增长的规律性,预测居民消费的发展趋势有重要意义。
在本研究中,通过在《国家统计数据库》选取了1978年~2009年的年度人均GDP和年度全国居民平均消费水平,并对人均GDP对居民消费水平的影响以及2010年居民消费水平进行预测。
二、一元线性回归分析可以看出.居民消费水平(Y)和人均GDP(X)大体呈现为线性关系,为分析中国居民消费水平随人均GDP变动的数量规律性,建立线性Y=a+bx。
回归模型。
参数估计及检验应用Eviews进行操作得下表:根据分析结果,可以得出回归方程为:y=a+bx=0.360x+327.3329,常数项和GDP系数的参数估计分别对应系数为327.3329和0.3598。
此外,残差平方和是2611591,对数似然值是-226.3618,分别是最小二乘估计和最大似然估计目标函数的值。
1978年到2009年这期间的居民人均消费和人均GDP之间的相关系数为0.987,说明我国人均GDP与居民人均消费之间存在着高度的相关关系,我国人均GDP每增长一元,我国居民的人均消费就增加0.36元。
这符合我国的国情,也符合宏观经济理论框架。
在结果中,参数估计量的标准差分别是70.49,0.00749。
对应常数项C和变量X系数两个参数估计的T的统计量分别是32.81,114.52,反映两个参数都是显著的。
2.检验T检验:是对回归系数的线性统计关系的检验,得出t值4.643139查表得tα/2 (30)=2.042。
第二章练习题及参考解答练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或,()()X Y X X Y Y r --=计算结果:M2GDPM2 10.996426148646GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
相关系数为:说明美国软饮料公司的广告费用X 与销售数量Y 的正相关程度相当高。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。
回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。
练习题2.3参考解答:1、 建立深圳地方预算内财政收入对GDP 的回归模型,建立EViews 文件,利用地方预算内财政收入(Y )和GDP 的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ 利用EViews 估计其参数结果为即 ˆ20.46110.0850t tY GDP =+ (9.8674) (0.0033)t=(2.0736) (26.1038) R 2=0.9771 F=681.4064经检验说明,深圳市的GDP 对地方财政收入确有显著影响。
20.9771R =,说明GDP 解释了地方财政收入变动的近98%,模型拟合程度较好。
模型说明当GDP 每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。

第三章练习题及参考解答3.1为研究中国各地区入境旅游状况,建立了各省市旅游外汇收入(Y ,百万美元)、旅行社职工人数(X1,人)、国际旅游人数(X2,万人次)的模型,用某年31个省市的截面数据估计结果如下:ii i X X Y 215452.11179.00263.151ˆ++-= t=(-3.066806) (6.652983) (3.378064)R 2=0.934331 92964.02=R F=191.1894 n=311)从经济意义上考察估计模型的合理性。
2)在5%显著性水平上,分别检验参数21,ββ的显著性。
3)在5%显著性水平上,检验模型的整体显著性。
练习题3.1参考解答:(1)由模型估计结果可看出:从经济意义上说明,旅行社职工人数和国际旅游人数均与旅游外汇收入正相关。
平均说来,旅行社职工人数增加1人,旅游外汇收入将增加0.1179百万美元;国际旅游人数增加1万人次,旅游外汇收入增加1.5452百万美元。
这与经济理论及经验符合,是合理的。
(2)取05.0=α,查表得048.2)331(025.0=-t 因为3个参数t 统计量的绝对值均大于048.2)331(025.0=-t ,说明经t 检验3个参数均显著不为0,即旅行社职工人数和国际旅游人数分别对旅游外汇收入都有显著影响。
(3)取05.0=α,查表得34.3)28,2(05.0=F ,由于34.3)28,2(1894.19905.0=>=F F ,说明旅行社职工人数和国际旅游人数联合起来对旅游外汇收入有显著影响,线性回归方程显著成立。
3.2 表3.6给出了有两个解释变量2X 和.3X 的回归模型方差分析的部分结果:表3.6 方差分析表RSS 的自由度各为多少?2)此模型的可决系数和调整的可决系数为多少?3)利用此结果能对模型的检验得出什么结论?能否确定两个解释变量2X 和.3X 各自对Y 都有显著影响?练习题3.2参考解答:(1) 因为总变差的自由度为14=n-1,所以样本容量:n=14+1=15因为 TSS=RSS+ESS 残差平方和RSS=TSS-ESS=66042-65965=77回归平方和的自由度为:k-1=3-1=2残差平方和RSS 的自由度为:n-k=15-3=12(2)可决系数为:2659650.99883466042ES R TSS S === 修正的可决系数:222115177110.998615366042i ie n R n ky--=-=-=ᄡ--¥¥(3)这说明两个解释变量2X 和.3X 联合起来对被解释变量有很显著的影响,但是还不能确定两个解释变量2X 和.3X 各自对Y 都有显著影响。
![2[1].回归方程复习题](https://uimg.taocdn.com/1976344f011ca300a6c3906e.webp)
第二、三章 回归方程复习题一、 单项选择题1、将内生变量的前期值作解释变量,这样的变量称为( D )。
A .虚拟变量 B. 控制变量C .政策变量 D. 滞后变量2、把反映某一总体特征的同一指标的数据,按一定的时间顺序和时间间隔排列起来,这样的数据称为( B )。
A .横截面数据 B. 时间序列数据C .修匀数据 D. 原始数据3、在简单线性回归模型中,认为具有一定概率分布的随机数量是( A )。
A .内生变量 B. 外生变量C .虚拟变量 D. 前定变量4、回归分析中定义的( B ) 。
A .解释变量和被解释变量都是随机变量B .解释变量为非随机变量,被解释变量为随机变量C .解释变量和被解释变量都为非随机变量D .解释变量为随机变量,被解释变量为非随机变量5、双对数模型μββ++=X Y ln ln ln 10中,参数β1的含义是( C )。
A .Y 关于X 的增长率 B. Y 关于X 的发展速度C .Y 关于X 的弹性 D. Y 关于X 的边际变化6、半对数模型i i i X Y μββ++=ln 10中,参数β1的含义是( D )。
A .Y 关于X 的弹性 B. X 的绝对量变动,引起Y 的绝对量变动C .Y 关于X 的边际变动 D. X 的相对变动,引起Y 的期望值绝对量变动7、在一元线性回归模型中,样本回归方程可表示为:( C )。
A .t t t X Y μββ++=10 B. t t t t X Y E Y μ+=)|(C .t t X Y 10ˆˆˆββ+= D. t t t X X Y E 10)|(ββ+= (其中t=1,2,…,n )8、设OLS 法得到的样本回归直线为i i i e X Y ++=10ˆˆββ,以下说法不正确的是( D )。
A .0=∑i e B. ),(Y X 在回归直线上C .Y Y =ˆ D. 0),(≠i i e X COV9、同一时间,不同单位相同指标组成的观测数据称为( B )。

⼤数据CPDA考试模拟样题—数据分析算法与模型考试模拟样题—数据分析算法与模型⼀.计算题 (共4题,100.0分)1.下⾯是7个地区2000年的⼈均国内⽣产总值(GDP)和⼈均消费⽔平的统计数据:⼀元线性回归.xlsx⼀元线性回归预测.xlsx要求:(1)绘制散点图,并计算相关系数,说明⼆者之间的关系;(2)⼈均GDP作⾃变量,⼈均消费⽔平作因变量,利⽤最⼩⼆乘法求出估计的回归⽅程,并解释回归系数的实际意义;(3)计算判定系数,并解释其意义;(4)检验回归⽅程线性关系的显著性(a=0.05);(5)如果某地区的⼈均GDP为5000元,预测其⼈均消费⽔平;(6)求⼈均GDP为5000元时,⼈均消费⽔平95%的置信区间和预测区间。
(所有结果均保留三位⼩数)正确答案:(1)以⼈均GDP为x,⼈均消费⽔平为y绘制散点图,如下:⽤相关系数矩阵分析可求得相关系数为0.9981。
从图和相关系数都可以看出⼈均消费⽔平和⼈均国内⽣产总值(GDP)有⽐较强的正相关关系。
(2)以⼈均GDP作⾃变量,⼈均消费⽔平作因变量,做线性回归分析,得到回归⽅程如下:y = 0.3087x + 734.6928回归系数0.3087表⽰⼈均GDP每增加⼀个单位,⼈均消费⽔平⼤致增加0.3087个单位,⼈均GDP对⼈均消费⽔平的影响是正向的,⼈均GDP越⾼⼈均消费⽔平也越⾼。
(3)判定系数R⽅为0.9963,说明模型拟合效果很好。
(4)T检验和F检验的P值都⼩于0.05,线性关系显著。
(5)做预测分析可得,如果某地区的⼈均GDP为5000元,则其⼈均消费⽔平为2278.1066元。
(6)⼈均GDP为5000元时,由预测分析的结果可知,⼈均消费⽔平95%的置信区间为[1990.7491,2565.4640],预测区间为[1580.4632,2975.7500]。
2.根据以下给出的数据进⾏分析,本次给出鸢尾花数据,其中包含萼⽚长、萼⽚宽、花瓣长、花瓣宽、以及花的类型数据,请根据以下问题进⾏回答。
相关分析与回归分析练习试卷1(题后含答案及解析) 题型有:1. 单选题 2. 多选题单项选择题以下每小题各有四项备选答案,其中只有一项是正确的。
1.根据散点图8-1,可以判断两个变量之间存在( )。
A.正线性相关关系B.负线性相关关系C.非线性关系D.函数关系正确答案:A 涉及知识点:相关分析与回归分析2.假设某品牌的笔记本市场需求只与消费者的收入水平和该笔记本的市场价格水平有关。
则在假定消费者的收入水平不变的条件下,该笔记本的市场需求与其市场价格水平的相关关系就是一种( )。
A.单相关B.复相关C.偏相关D.函数关系正确答案:C解析:在某一现象与多种现象相关的场合,假定其他变量不变,专门考察其中两个变量的相关关系称为偏相关。
在假定消费者的收入水平不变的条件下,该笔记本的市场需求与其市场价格水平的关系就是一种偏相关。
知识模块:相关分析与回归分析3.相关图又称( )。
A.散布表B.折线图C.散点图D.曲线图正确答案:C解析:相关图又称散点图,是指把相关表中的原始对应数值在乎面直角坐标系中用坐标点描绘出来的图形。
知识模块:相关分析与回归分析4.下列相关系数取值中错误的是( )。
A.-0.86B.0.78C.1.25D.0正确答案:C解析:相关系数r的取值介于-1与1之间。
知识模块:相关分析与回归分析5.如果相关系数r=0,则表明两个变量之间( )。
A.相关程度很低B.不存在任何关系C.不存在线性相关关系D.存在非线性相关关系正确答案:C解析:相关系数r是根据样本数据计算的度量两个变量之间线性关系强度的统计量。
如果相关系数r=0,说明两个变量之间不存在线性相关关系。
知识模块:相关分析与回归分析6.当所有观测值都落在回归直线上,则两个变量之间的相关系数为( )。
A.1B.-1C.+1或-1D.大于-1,小于+1正确答案:C解析:当所有观测值都落在回归直线上时,说明两个变量完全线性相关,所以相关系数为+1或-1。
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
相关分析1 相关关系内涵1.1 相关关系的概念无论是在自然界还是社会经济领域,一种现象与另一种现象之间往往存在着依存关系,当我们用变量来反映这些现象的特征时,便表现为变量之间的依存关系。
如某种商品的销售额(y )与销售量(x )之间的关系、商品销售额(y )与广告费支出(x )之间的关系以及粮食亩产量(y )与施肥量(1x )、降雨量(2x ) 、温度(3x )之间的关系等。
统计学的主要研究对象是随机变量,在多个变量的时候,至少有一个变量是随机变量,因此我们对变量之间关系的分析是随机变量之间的关系或随机变量与确定变量之间的关系。
变量之间的依存关系可以分为两种:一是函数关系,指变量之间保持的严格的依存关系。
其主要特征是它的确定性,即对一个变量的每一个值,另一个变量都具有惟一确定的值与之相对应。
变量之间的函数关系通常可以用函数式确切地表示出来。
如圆的面积(S)与半径之间的关系可表示为S = 2R ,当圆的半径R 的值取定后,其圆的面积也随之确定。
二是相关关系,如果我们所研究的事物或现象之间,存在着一定的数量关系,即当一个或几个相互联系的变量取一定数值时,与之相对应的另一变量的值虽然不能一一确定,但按某种规律在一定的范围内变化。
我们把变量之间的这种不稳定、不精确的变化关系称为相关关系。
例如人的身高与体重这两个变量,一般而言是相互依存的,但它们并不表现为确定的函数的关系。
因为制约这两个变量的还有其他因素,如遗传因素、营养状况和运动水平等,以至于同一身高的人可以有不同的体重,同一体重的人又表现出不同身高。
变量间的这种不严格的依存关系就构成了相关与回归分析的对象。
在复杂的社会系统中,各种事物或现象之间的联系大多体现为相关关系,而不是函数关系,这主要是由于影响一个变量的因素很多,而其中一些因素还没有被人们所完全认识和掌握,或是处于已经认识但对其产生的影响还不能完全控制和测量。
另外,有些因素尽管可以控制和测量,但在操作过程中或多或少都会有误差,所有这些偶然因素的综合作用导致了变量之间的不确定性。
基于R对国内各省、市、区GDP与主要经济指标的回归分析学号:107551300678 姓名:杨治峰班级:地矿学院(“三矿”专业)摘要:基于对2012年国内生产总值的数据分析,找出我国GDP 与多个指标,尤其是对投资、消费、出口等基本指标的依赖关系,运用相关分析和回归分析方法,建立回归模型,找出我国GDP的增长受社会固定资产依赖性较强,尤其是东部的山东省,也受制于出口收入,而我国消费水平依然不高的问题并为之提出改进措施和经济发展的预测,对国家各地区经济的科学发展建言献策关键词:R语言、相关分析、回归分析、中国GDP1 引言在当前复杂多变的国际经济形势下,我国国民生产总值(GDP)依然保持较快发展,国民生产总值是一个综合指标,依赖于多个指标的良性组合。
世界各国都十分重视GDP结构问题的研究。
本文基于对2012年国内生产总值的数据分析,找出我国GDP 与多个指标,尤其是对投资、消费、出口等基本指标的依赖关系,建立回归模型,尝试着探索出我国GDP 存在的结构性问题和不足之处,并为之提出改进措施和经济发展的预测,对国家各地区经济的科学发展建言献策!2.数据与分析方法2.1.数据描述性统计2.1.1.数据源的格式化处理R软件在读入excel数据源的时候,必须先对数据源进行格式化处理和调整才可以达到R软件的读取标准。
如表头的单行单列、文字间空格符号的消除等,调整完后,依据个人习惯将数据存入txt文本格式,命名为“ryuan.txt”。
2.1.2.数据的读取> A=read.table("ryuan.txt",header=T)> A#解析变量成y,x1,x2,x3,x4,x5,x6,x7,;X=A[,c(1,4,2,9,6,8,3)]Xy=A[,c(1)]#地区生产总值(亿元)yy2=A[,c(4)]#人均地区生产总值(元)y2x1=A[,c(2)]#社会固定资产投资(亿元)x1x2=A[,c(9)]#出口总额(亿美元)x2x3=A[,c(6)]#城镇人均消费支出(元)x3x4=A[,c(8)]#农民人均消费支出(元)x4x5=x3+x4#各地区人均消费总额(元)x5x6=A[,c(3)]#各地区居民消费价格指数x6B=data.frame("地区生产总值(亿元)"=y,"社会固定资产投资(亿元)"=x1,"出口总额(亿美元)"=x2,"各地区人均总额(元)"=x5)2.1.3.对读入的数据进行描述性统计。
相关与回归分析思考与练习一、判断题1.产品的单位成本随着产量增加而下降,这种现象属于函数关系。
答:错。
应是相关关系。
单位成本与产量间不存在确定的数值对应关系。
2.相关系数为0表明两个变量之间不存在任何关系。
答:.错。
相关系数为零,只表明两个变量之间不存在线性关系,并不意味着两者间不存在其他类型的关系。
3.单纯依靠相关与回归分析,无法判断事物之间存在的因果关系。
答:对,因果关系的判断还有赖于实质性科学的理论分析。
4.圆的直径越大,其周长也越大,两者之间的关系属于正相关关系。
答:错。
两者是精确的函数关系。
5.总体回归函数中的回归系数是常数,样本回归函数中的回归系数的估计量是随机变量。
答:对。
6.当抽取的样本不同时,对同一总体回归模型估计的结果也有所不同。
答:对。
因为,估计量属于随机变量,抽取的样本不同,具体的观察值也不同,尽管使用的公式相同,估计的结果仍然不一样。
二、选择题1.变量之间的关系按相关程度分可分为:b 、c 、da.正相关;b. 不相关;c. 完全相关;d.不完全相关; 2.复相关系数的取值区间为:aa. 10≤≤R ;b.11≤≤-R ;c.1≤≤∞-R ;d.∞≤≤-R 1 3.修正自由度的决定系数a 、b 、da.22R R ≤; b.有时小于0 ; c. 102≤≤R ;d.比2R 更适合作为衡量回归方程拟合程度的指标 4.回归预测误差的大小与下列因素有关:a 、b 、c 、da 样本容量;b 自变量预测值与自变量样本平均数的离差c 自变量预测误差;d 随机误差项的方差三、问答题1.请举一实例说明什么是单相关和偏相关?以及它们之间的差别。
答:例如夏季冷饮店冰激凌与汽水的消费量,简单地就两者之间的相关关系进行考察,就是一种单相关,考察的结果很可能存在正相关关系,即冰激凌消费越多,汽水消费也越多。
然而,如果我们仔细观察,可以发现一般来说,消费者会在两者中选择一种消费,也就是两者之间事实上应该是负相关。
第七章 相关与回归分析一、单项选题题1、当自变量X 减少时,因变量Y 随之增加,则X 和Y 之间存在着( ) A 、线性相关关系 B 、非线性相关关系 C 、正相关关系 D 、负相关关系2、下列属于函数关系的有( )A 、身高与体重之间B 、广告费用支出与商品销售额之间C 、圆面积与半径之间D 、施肥量与粮食产量之间 3、下列相关程度最高的是( )A 、r=0.89B 、r=-0.93C 、r=0.928D 、r=0.8 4、两变量x 与y 的相关系数为0.8,则其回归直线的判定系数为( ) A 、0.80 B 、0.90 C 、0.64 D 、0.50 5、在线性回归模型中,随机误差项被假定服从( )A 、二项分布B 、t 分布C 、指数分布D 、正态分布6、物价上涨,销售量下降,则物价与销售量之间的相关属于( ) A 、无相关 B 、负相关 C 、正相关 D 、无法判断7、相关分析中所涉及的两个变量( )A 、必须确定哪个是自变量、哪个是因变量B 、都不能为随机变量C 、都可以是随机变量D 、不是对等关系 8、单位产品成本y (元)对产量x (千件)的回归方程为:t t x y 2.0100-=∧,其中“—0.2”的含义是( )A 、产量每增加1件,单位成本下降0.2元B 、产量每增加1件,单位成本下降20%C 、产量每增加1000件,单位成本下降20%D 、产量每增加1000件,单位成本平均下降0.2元E 、产量每增加1000件,单位成本平均下降20% 二、多项选择题1、下列说法正确的有( )A 、相关分析和回归分析是研究现象之间相关关系的两种基本方法B 、相关分析不能指出变量间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况 C、回归分析可以不必确定变量中哪个是自变量,哪个是因变量 D、相关分析必须事先研究确定具有相关关系的变量中哪个为自变量,哪个为因变量 E、相关分析中所涉及的变量可以都是随机变量,而回归分析中因变量是随机的,自变量是非随机的2、判定现象之间有无相关关系的方法有()A、计算回归系数B、编制相关表C、绘制相关图D、计算相关系数E、计算中位数3、相关关系按相关的形式可分为()A、正相关B、负相关C、线性相关D、非线性相关E、复相关4、在直线回归方程∧yt=∧β1+∧β2Xt中,回归系数∧β2的数值()A、表明两变量之间的平衡关系B、其正、负号表明两变量之间的相关方向C、表明两变量之间的密切程度D、表明两变量之间的变动比例E、在数学上称为斜率5、下列那些项目属于现象完全相关()A、r=0B、r= —1C、r= +1D、y的数量变化完全由X的数量变化所确定E、r=0.986、在回归分析中,要求所涉及的两个变量x和y()A、必须确定哪个是自变量、哪个是因变量B、不是对等关系C、是对等关系D、一般来说因变量是随机的,自变量是非随机变量E、y对x的回归方程与x对y的回归方程是一回事7、下列有相关关系的是()A、居民家庭的收入与支出B、广告费用与商品销售额C、产量与单位产品成本D、学生学习的时间与学习成绩E、学生的身高与学习成绩8、可决系数2r=86.49%时,意味着()A 、自变量与因变量之间的相关关系密切B 、因变量的总变差中,有80%可通过回归直线来解释 C 、因变量的总变差中,有20%可由回归直线来解释 D 、相关系数绝对值一定是0.93 E 、相关系数绝对值一定是0.8649 三、填空题1、相关系数r 的取值范围为 。
第十一章相关回归分析课堂练习题:
对15个地区2006年的人均国内生产总值(GDP)和人均消费水平的统计数据进行相关回归分析,以人均GDP作自变量,人均消费水平作因变量,利用EXCEL的具体计算结果如下:
方差分析
试根据以上数据处理结果,分析:
(1)根据散点图,说明两个变量之间存在什么相关关系,写出他们的相关系数。
(2)写出判定系数,并解释其意义。
(3)写出估计的回归方程,并解释回归系数的实际意义。
(4)在 =0.05显著性水平下,检验回归方程线性关系的显著性。
(5)写出标准误差S y,并解释其意义。
(6)如果人均GDP为5000元,预测其人均消费水平;如果给定95%的概率保证,估计人均消费水平的预测区间。
解:(1) 根据散点图,说明两个变量之间存在什么相关关系,写出他们的相关系数。
答:两个变量之间存在正线性相关关系。
相关系数r=0.9981,因为r ﹥0.8,根据经验可认
为两个变量之间存在高度线性相关。
(2) 写出判定系数,并解释其意义。
答:判定系数R 2=0.9963。
说明在人均消费水平的变动中,有99.63%可以由人均GDP 和人
均消费水平之间的线性关系来解释。
(或者答:在人均消费水平的变动中,有99.63%可以由人均GDP 来决定。
)
(3) 写出估计的回归方程,并解释回归系数的实际意义。
答:估计的回归方程是0.74x 457.28ˆ+==y。
回归系数2.457ˆ0=β是截距,没具体的经济意义。
回归系数74.ˆ
1o =β是斜率,表示人均GDP 每增加1单位,人均消费水平平均增加0.74单位。
(4) 在α=0.05显著性水平下,检验回归方程线性关系的显著性。
答:0:10=βH
因为Significance F=3.61282E-17﹤=0.05,所以拒绝H0,表明人年均消费水平和人
均GDP 之间的线性关系是显著的。
(5)标准误差S e =167.29元,说明根据人均GDP 来估计人均消费水平时,平均的估计误差为167.29元。
(6) 如果人均GDP 为5000元,预测其人均消费水平;如果给定95%的概率保证,估计人均消费水平的预测区间。
答:(元)28.4157500074.028.457ˆ=⨯+=y
)63.4518,93.3795(35.36128.415729.16716.228.4157ˆ)215(2/=±=⨯±=±-e S t y α。