稀疏编码 Optimization with sparse inducingnorms
- 格式:pdf
- 大小:315.67 KB
- 文档页数:22

大规模稀疏数据处理方法近年来,随着互联网技术的快速发展和应用,大规模稀疏数据的处理变得越来越重要。
在机器学习、数据挖掘和人工智能等领域中,稀疏数据处理是一项关键技术,因为这些领域中的大部分数据都呈现出高维度和稀疏性的特点。
本文将介绍一些常用的大规模稀疏数据处理方法,包括特征选择、稀疏编码和稀疏矩阵运算等。
一、特征选择特征选择是大规模稀疏数据处理的第一步。
由于稀疏数据集中只有少数几个特征对结果有重要影响,因此通过选择相关性较高的特征,可以降低计算复杂度,并且提高模型的准确性。
常用的特征选择方法包括过滤法、包装法和嵌入法。
过滤法是根据特征和目标变量之间的相关性进行筛选,常用的指标包括皮尔逊相关系数和卡方检验等。
包装法是将特征选择过程看作是一个搜索问题,通过评估不同特征子集来选择最佳的特征组合。
嵌入法是在模型训练的过程中通过正则化方法进行特征选择,常用的方法有L1范数正则化和决策树剪枝等。
二、稀疏编码稀疏编码是一种常用的数据降维技术,通过将高维度的稀疏数据映射到低维度的稠密空间中,从而减少数据的冗余性。
稀疏编码的目标是找到一组基向量,使得原始数据在这组基向量上的表示尽可能稀疏。
常用的稀疏编码算法包括奇异值分解(SVD)、主成分分析(PCA)和字典学习等。
奇异值分解是一种线性代数的技术,可以将一个矩阵分解为三个矩阵的乘积,分别表示原始数据的特征向量、特征值和特征矩阵。
主成分分析是一种统计学的技术,用于找到数据中最重要的成分。
字典学习是一种无监督学习的方法,通过学习一个字典,将原始数据表示为该字典的线性组合。
三、稀疏矩阵运算在大规模稀疏数据处理中,由于数据的稀疏性,传统的矩阵运算方法效率低下。
因此,针对稀疏矩阵的特点,提出了一些高效的矩阵运算方法,包括CSR格式、CSC格式和压缩感知等。
CSR格式(Compressed Sparse Row)是一种常用的稀疏矩阵存储格式,它将矩阵的非零元素按行存储,并且记录每行非零元素在矩阵中的位置和值。

稀疏自编码器(Sparse Auto-Encoder,SAE)是一种深度学习算法,它可以通过学习数据的有用特征来对数据进行降维和重建。
在数据融合方面,稀疏自编码器可以有效地提取数据中的隐含特征,并与其他辅助信息进行融合,从而提高推荐的准确性和精度。
一个典型的稀疏自编码器包括一个编码器和一个解码器。
编码器负责从输入数据中学习隐含特征,解码器则负责根据学习到的隐含特征重建输入数据。
在训练过程中,稀疏自编码器通过优化损失函数(如均方误差)来学习数据的有用特征。
在数据融合算法中,稀疏自编码器可以与其他算法(如关联规则挖掘、聚类等)相结合。
以关联规则挖掘为例,可以利用稀疏自编码器学习数据中的关联规则,并将学习到的规则与其他辅助信息(如用户评分、评论等)进行融合,从而提高推荐的准确性。
此外,稀疏自编码器还可以与其他聚类算法(如K-means、DBSCAN等)相结合,通过学习数据的隐含特征来提高聚类的性能。
具体而言,首先使用稀疏自编码器学习数据的有用特征,然后将这些特征作为输入进行聚类分析。
实验结果表明,与传统的聚类算法相比,稀疏自编码器与其他聚类算法的结合可以获得更好的聚类效果。



稀疏编码与自然语言处理的跨界创新探索自然语言处理(Natural Language Processing,NLP)是人工智能领域中的一个重要分支,旨在让机器能够理解、处理和生成自然语言。
而稀疏编码(Sparse Coding)则是一种信号处理技术,用于在高维数据中找到最少的重要特征表示。
这两个看似不相关的领域,却在跨界创新中产生了令人惊喜的结果。
在传统的自然语言处理中,常常需要对文本进行向量化表示,以便于机器进行处理。
一种常见的方法是使用词袋模型(Bag of Words),将每个词语表示为一个独立的特征。
然而,这种表示方法存在一个严重的问题,即高维稀疏性。
在大规模文本数据中,绝大部分特征都是零值,这导致了计算和存储的浪费。
为了解决这个问题,研究者们开始探索将稀疏编码技术应用于自然语言处理中。
稀疏编码通过学习一个稀疏的特征表示,能够更好地捕捉到数据的本质特征。
在自然语言处理中,这种技术可以用于降低维度,提取关键特征,从而提高模型的性能。
例如,在文本分类任务中,传统的方法往往使用词频作为特征表示。
然而,这种方法无法捕捉到词语之间的语义关系。
而利用稀疏编码技术,可以将每个词语表示为一个稀疏向量,其中非零元素表示该词语在文本中的重要性。
这样一来,模型就能更好地理解文本中的语义信息,从而提高分类的准确性。
除了文本分类,稀疏编码还可以应用于文本生成、机器翻译等任务中。
在文本生成任务中,稀疏编码可以用于生成高质量的文本摘要。
通过学习一个稀疏的特征表示,模型可以更好地理解文本的重要信息,从而生成更加准确、简洁的摘要。
在机器翻译任务中,稀疏编码可以用于提取句子的关键特征,从而提高翻译的质量和准确性。
除了在自然语言处理中的应用,稀疏编码还可以与其他领域进行跨界创新。
例如,在图像处理中,稀疏编码可以用于图像压缩和图像恢复。
通过学习一个稀疏的特征表示,模型可以更好地捕捉到图像的本质特征,从而实现更高效的图像压缩和更准确的图像恢复。

Deep Learning论文笔记之(二)Sparse Filtering稀疏滤波Deep Learning论文笔记之(二)Sparse Filtering稀疏滤波zouxy09@/zouxy09 自己平时看了一些论文,但老感觉看完过后就会慢慢的淡忘,某一天重新拾起来的时候又好像没有看过一样。
所以想习惯地把一些感觉有用的论文中的知识点总结整理一下,一方面在整理过程中,自己的理解也会更深,另一方面也方便未来自己的勘察。
更好的还可以放到博客上面与大家交流。
因为基础有限,所以对论文的一些理解可能不太正确,还望大家不吝指正交流,谢谢。
本文的论文来自:Sparse filtering , J. Ngiam, P. Koh, Z. Chen, S. Bhaskar, A.Y. Ng.NIPS2011。
在其论文的支撑材料中有相应的Matlab代码,代码很简介。
不过我还没读。
下面是自己对其中的一些知识点的理解:《Sparse Filtering》本文还是聚焦在非监督学习Unsupervised feature learning算法。
因为一般的非监督算法需要调整很多额外的参数hyperparameter。
本文提出一个简单的算法:sparse filtering。
它只有一个hyperparameter(需要学习的特征数目)需要调整。
但它很有效。
与其他的特征学习方法不同,sparse filtering并没有明确的构建输入数据的分布的模型。
它只优化一个简单的代价函数(L2范数稀疏约束的特征),优化过程可以通过几行简单的Matlab代码就可以实现。
而且,sparse filtering可以轻松有效的处理高维的输入,并能拓展为多层堆叠。
sparse filtering方法的核心思想就是避免对数据分布的显式建模,而是优化特征分布的稀疏性从而得到好的特征表达。
一、非监督特征学习一般来说,大部分的特征学习方法都是试图去建模给定训练数据的真实分布。

稀疏自编码器的作用稀疏自编码器(sparse autoencoder)是一种神经网络模型,它可以用以学习数据的特征表示。
在深度学习领域中被广泛应用。
稀疏自编码器之所以“稀疏”,是因为它能够产生稀疏编码。
此外,稀疏自编码器还有一些其他的特征和用途,下面就来介绍一下。
作为一种监督学习方法,自编码器是一类用于学习输入数据的基础特征表示的算法。
稀疏自编码器则是自编码器的一种变体,它还可以实现对输入数据的降维。
与普通自编码器不同的是,稀疏自编码器在学习基础特征表示的同时,还可以产生稀疏的编码。
首先来说一下稀疏自编码器的降维作用。
在数据挖掘领域,降维是一项重要的任务,可以帮助我们发现数据中的规律性和特征,快速准确地判断数据所属的分类。
稀疏自编码器可以通过学习有效的基础特征表示来实现降维。
它采用了一种“压缩”原始数据的方式,将数据压缩到较小的维度空间中,同时能够尽可能地保留原始数据的信息。
这样一来,我们可以更加方便地观察和分析数据,同时也可以避免过拟合的情况出现。
其次,稀疏自编码器能够产生稀疏编码。
稀疏编码指的是将大量的输入数据通过相对较小的编码进行表示。
相较于一般的编码方法,稀疏编码可以帮助我们更好地理解数据,并更好地挖掘其中所包含的特征和规律,逐渐学习到数据的内在结构。
稀疏自编码器通过引入稀疏性的约束,来实现产生稀疏编码。
具体而言,它引入了一个稀疏性约束条件,在训练过程中对编码进行限制,使得网络产生的编码更加稀疏。
而这种稀疏的编码可以对于输入的数据进行更加准确的分类,具有更好的泛化性能。
另外,稀疏自编码器还具有去噪的作用。
许多真实世界中的数据都含有一些噪声,这些噪声可能会干扰我们对数据的理解和分类。
利用去噪自编码器的方法,可以在训练过程中通过对源数据进行噪声干扰,来训练出适应性更强的网络,从而更好地去除噪声。
稀疏自编码器同样也能够实现去噪,因为它在训练过程中将得到噪声分布下的样本,因此同样可以学习到充分抗噪的特征表达。

sparsecodingsr流程英文版Sparse Coding SR (Super-Resolution) ProcessIn the realm of computer vision and image processing, sparse coding has emerged as a powerful tool for enhancing image quality. Among its many applications, sparse coding has been particularly effective in super-resolution (SR) techniques, where it aims to reconstruct high-resolution images from their low-resolution counterparts. This article outlines the basic steps involved in the sparse coding SR process.1. Understanding Sparse CodingSparse coding is a form of dimensionality reduction where a signal is represented as a linear combination of a small number of elements from a larger dictionary of elements. In the context of images, this dictionary typically consists of image patches or features. The sparsity constraint ensures that only a few of thesepatches contribute significantly to the reconstruction of the original image.2. Preparing the Low-Resolution ImageBefore applying sparse coding for SR, the low-resolution image must be preprocessed. This involves scaling the image to the desired size and potentially applying other image enhancement techniques such as denoising or contrast enhancement.3. Constructing the DictionaryThe next step is to construct a dictionary of high-resolution image patches. These patches are typically extracted from a large collection of high-resolution images or can be learned through an optimization process. The goal is to have a diverse set of patches that can effectively represent a wide range of textures and features.4. Sparse CodingWith the dictionary in place, the low-resolution image is divided into overlapping patches. Each patch is thenrepresented as a sparse combination of patches from the dictionary. This sparse representation is obtained by solving an optimization problem that minimizes the reconstruction error while enforcing sparsity.5. Reconstruction of High-Resolution PatchesUsing the sparse codes obtained in the previous step, high-resolution patches are reconstructed. This is done by mapping the sparse codes back to the dictionary and retrieving the corresponding high-resolution patches.6. Merging the High-Resolution PatchesThe reconstructed high-resolution patches are then merged to form a complete high-resolution image. This merging process requires careful handling to avoid artifacts and ensure smooth transitions between patches.7. Post-Processing and EnhancementFinally, the reconstructed high-resolution image may undergo further post-processing steps such as sharpening,color correction, or noise reduction to further enhance its quality.ConclusionThe sparse coding SR process is an effective way to improve image quality by leveraging the sparse representation of signals. By carefully constructing a dictionary, sparse coding, and reconstructing high-resolution patches, this method enables the reconstruction of high-quality images from their low-resolution counterparts.中文版稀疏编码SR(超分辨率)流程在计算机视觉和图像处理领域,稀疏编码作为一种强大的工具,对提升图像质量有着显著效果。
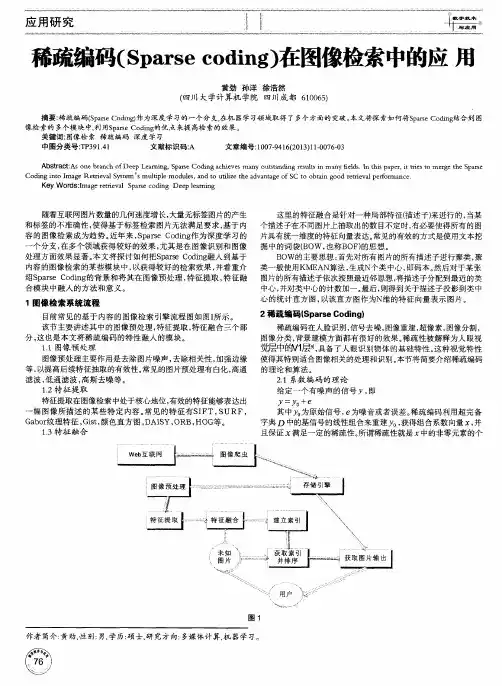


稀疏编码算法及其应用研究共3篇稀疏编码算法及其应用研究1稀疏编码算法及其应用研究随着人工智能和机器学习的发展,稀疏编码算法作为一种常用的特征提取技术,应用广泛。
本文主要介绍稀疏编码算法的原理、优点以及在实际应用中的研究。
一、稀疏编码算法稀疏编码算法是一种基于线性变换的特征提取方法,其目标是从原始数据中提取出一组有用的特征,以便于后续的分类和预测。
与其他特征提取方法相比,稀疏编码算法具有以下优点:1.高效性:稀疏编码算法可以在大规模数据上高效处理,并且不需要人为干预。
2.自适应性:稀疏编码算法可以针对不同的数据集进行自适应调整,提取出更加有意义的特征。
3.高抗噪性:稀疏编码算法经过特殊的处理,可以有效地处理输入数据中的噪声。
4.可解释性:稀疏编码算法可以将输入数据映射到某个稠密空间中,使得特征的物理含义更加明显。
稀疏编码算法的主要目标是学习一个线性变换矩阵W和一个偏置向量b,以将输入x表示为一个尽可能少的非零元素的线性组合,即:$x=W^Th+b$其中,h是一个隐藏层的向量,表示特征的稀疏表示。
为了达到这个目标,稀疏编码算法通常采用以下两个步骤:1.编码阶段:给定输入x,找到一个稀疏表示h,使得x可以用W和h的线性组合表示。
2.解码阶段:给定一个稀疏向量h,重构输入向量x。
通过不断迭代优化,可以得到最优的稀疏表示h。
这种算法的特点是在学习高维数据结构时,能够通过减少特征数量实现数据降维。
其样本复杂度成线性复杂度,因此在大数据处理上非常高效。
二、应用研究稀疏编码算法在计算机视觉、自然语言处理和语音识别等领域中应用广泛。
1.计算机视觉稀疏编码在计算机视觉领域中广泛应用,主要用于图像识别、目标检测、人脸识别等场景中的特征提取。
通过使用更加有效的特征表示方法,能够提高分类和检测的准确性。
2.自然语言处理稀疏编码在自然语言处理领域中的应用涵盖了从语言模型到文本分类等多个任务。
在这些任务中,稀疏编码被用来提取文本的语义特征,以便于后续的建模和分类。
稀疏计算与稠密计算概述说明以及解释1. 引言1.1 概述稀疏计算和稠密计算是当前计算领域内广泛讨论的两个重要概念。
它们在不同领域中都具有重要的应用价值,并以不同的方式处理数据和计算任务。
稀疏计算基于稀疏数据集,即数据中只有少数非零元素,而稠密计算则处理密集型数据集,其中几乎所有元素均非零。
1.2 文章结构本文将分为六个部分进行阐述与讨论。
首先,在引言部分,我们将对稀疏计算和稠密计算进行概览,并解释它们在现实生活中的重要性。
接下来,第二部分将详细介绍稀疏计算和稠密计算的定义、特点以及它们之间的区别和联系。
第三部分将着重探讨稀疏计算技术及其在机器学习和图像处理领域的应用案例。
随后,第四部分将介绍常见的稠密计算模型和方法,并讨论在科学运筹优化和物理模拟等领域中的应用案例。
第五部分将比较两者之间的优缺点,并探讨二者的结合和互补性,同时预测稀疏计算和稠密计算在人工智能领域的未来发展趋势。
最后,在结论部分总结全文的内容,并展望稀疏计算和稠密计算的重要性及应用价值。
1.3 目的本文旨在介绍稀疏计算和稠密计算这两个关键概念,解释它们在不同领域中的应用,以及它们之间的关系。
通过对不同技术和方法的讨论,我们将评估它们各自的优缺点,并探究二者如何相互补充与结合。
此外,我们还将探索稀疏计算和稠密计算在人工智能领域的未来发展方向,并强调它们对于推动科学研究和技术进步的重要性。
通过阅读本文,读者将更好地了解稀疏计算和稠密计算,并认识到它们对现代计算领域所带来的深远影响。
2. 稀疏计算与稠密计算概述2.1 稀疏计算的定义和特点稀疏计算是一种在处理大规模数据时采用只关注数据中非零元素的方法。
在稀疏数据中,只有少量的元素是非零的,而其他元素都是零。
这些零值元素可以通过跳过它们来节省计算资源和存储空间。
稀疏计算的优势在于减少了不必要的计算开销,并且能够更快地处理大规模数据集。
2.2 稠密计算的定义和特点相比之下,稠密计算是对所有数据点进行操作和处理的一种方法。
基于稀疏编码的特征提取技术研究随着人工智能技术的快速发展,特征提取技术已经成为机器学习领域的重要研究方向。
特征提取的目的是从海量的数据中提取有用的信息,然后用这些信息来进行分类、回归、聚类等任务。
基于稀疏编码的特征提取技术是目前最为流行和成功的一种方法,下面我们就来详细地介绍一下。
一、稀疏编码的概念与原理稀疏编码(sparse coding)就是在给定数据的情况下,通过寻找一组稀疏表示系数,将每个数据样本表示成这组系数的线性组合,从而实现对特征的提取。
这个过程可以看作是一种数据降维的方法,可以将大量的数据信息表示成一小部分稀疏向量,进而方便后续的处理。
稀疏编码的原理可以用下面的式子来表示:$\min_{\alpha} \parallel x - D\alpha \parallel_2^2 + \lambda\parallel \alpha \parallel_1$其中,$x$是输入的原始数据,$D$是稀疏字典,$\alpha$是稀疏表示系数,$\lambda$是控制稀疏性的超参数。
这个式子的意义是:输出的稀疏表示系数应该使得输入数据和稀疏字典的线性组合能够最好地逼近原始数据,并且系数是要尽可能地稀疏。
二、稀疏编码的应用稀疏编码技术在很多领域都有着非常广泛的应用,比如图像识别、语音处理、自然语言处理等。
以下是几个常见的应用领域:1.图像识别在图像识别领域,稀疏编码主要用于特征提取。
通过将图像的像素点表示成向量形式,然后使用稀疏编码技术将向量表示成稀疏向量,这样就可以保留图像中的重要特征,并且能够大大降低数据的维度。
然后就可以使用聚类、分类等算法对稀疏向量进行处理,以实现图像识别的目的。
2.语音处理在语音处理领域,稀疏编码主要用于音频信号的降噪和特征提取。
通过将音频信号表示成向量形式,然后使用稀疏编码技术对向量进行降噪处理,以消除噪声对语音信号的影响。
同时还可以通过稀疏编码提取音频信号的特征,以便后续的处理和分析。
如何解决稀疏编码中的多任务学习问题稀疏编码是一种机器学习中常用的技术,用于处理高维数据中的冗余信息。
然而,在实际应用中,我们往往面临多任务学习的问题,即同时处理多个相关但不完全相同的任务。
本文将探讨如何解决稀疏编码中的多任务学习问题。
首先,我们需要明确多任务学习的概念。
多任务学习是指在一个模型中同时学习多个相关任务,通过共享特征来提高模型的泛化能力。
在稀疏编码中,多任务学习可以通过引入任务相关的先验信息来实现。
一种常见的方法是使用联合稀疏编码(Joint Sparse Coding,JSC)。
JSC假设不同任务之间的特征表示具有一定的相似性,因此可以共享稀疏编码的过程。
具体而言,JSC通过最小化所有任务的重构误差和稀疏性约束来学习共享的稀疏表示。
这样,不仅可以提取出任务共享的特征,还可以保留每个任务的个性化特征。
另一种方法是使用分组稀疏编码(Group Sparse Coding,GSC)。
GSC将所有任务分成若干组,每组任务共享一组稀疏编码。
这样,每个组内的任务可以共享相似的特征表示,而不同组之间的任务则可以有不同的特征表示。
GSC通过最小化重构误差和稀疏性约束来学习每个组的稀疏表示,从而实现多任务学习。
除了JSC和GSC,还有一些其他的方法可以解决稀疏编码中的多任务学习问题。
例如,可以使用低秩稀疏编码(Low-Rank Sparse Coding,LRSC)。
LRSC假设任务之间的特征表示可以通过低秩矩阵来近似,从而实现特征的共享和压缩。
LRSC通过最小化重构误差和稀疏性约束来学习低秩矩阵的表示,从而实现多任务学习。
此外,还可以使用深度学习方法来解决稀疏编码中的多任务学习问题。
深度学习通过叠加多个隐藏层来学习更加复杂的特征表示。
在多任务学习中,可以使用多个输出层来处理不同的任务,通过共享隐藏层的表示来实现特征的共享。
深度学习方法在图像、语音和自然语言处理等领域取得了显著的成果,可以作为解决稀疏编码中多任务学习问题的有力工具。