数据分析算法与模型一附答案
- 格式:doc
- 大小:122.35 KB
- 文档页数:6


商务数据分析模拟习题与参考答案一、单选题(共40题,每题1分,共40分)1、在EXCe1中,文本数据默认的对齐方式是A、右对齐B、居中对齐C、左对齐D、两端对齐正确答案:C2、大数据时代,数据使用的关键是()。
A、数据再利用B、数据存储C、数据分析D、数据收集正确答案:A3、V1OOKUP函数在()与匹配中的应用非常广泛。
A、模块B、窗体C、查找D、宏正确答案:C4、在EXCe1中,下列()是输入正确的公式格式。
A、B2*D3+1B、C7+C1C、SUM(D1:D2)D、=8*2正确答案:D5、一般情况下,在网店绩效考核中,销售业绩占比最大,工作能力次之,O 占比较少。
A、工作态度责任心C、积极主动性D、学习力正确答案:A6、函数COUNTIF(range,criteria)的功能是()。
A、根据指定条件对若干单元格求和B、求其参数的算数平均值C、计算参数中包含数字的单元格的个数D、计算某个区域中满足给定条件的单元格个数正确答案:D7、下列有关EXCe1工作表单元格的说法中,错误的是()。
A、若干单元格构成工作表B、每个单元格都有固定的地址C、同列不同单元格的宽度可以不同D、同列不同单元格可以选择不同的数字分类正确答案:C8、《网络安全法》第四十条规定:网络运营者应当对()严格保密,并建立健全用户信息保护制度。
A、其收集的用户信息B、付费的会员信息C、自己的个人信息D、企业的员工信息正确答案:A9、残损商品会影响企业和门店的销售额和利润,残损率不仅是一个分析指标,还是一个()。
A、服务指标B、促销指标C^追踪指标D、多维指标正确答案:C10、王圆同学想用电子表格中的图表来展示一年中的天气气温变化情况,最恰当的图标类型应是()。
A、饼图B、柱形图C、折线图D、面积图11、统计分组的依据是()。
A^标志B、指C^标志值D、变量值正确答案:A12、监控大宗交易,是因为大宗交易中藏着很多隐蔽的交易,而这些交易对()都有伤害。

数据分析笔试题目及答案解析数据分析笔试题目及答案解析——第1题——1. 从含有N个元素的总体中抽取n个元素作为样本,使得总体中的每一个元素都有相同的机会(概率)被抽中,这样的抽样方式称为?A. 简单随机抽样B. 分层抽样C. 系统抽样D. 整群抽样答案:A——第2题——2. 一组数据,均值中位数众数,则这组数据A. 左偏B. 右偏C. 钟形D. 对称答案:B「题目解析」分布形状由众数决定,均值大于众数的化,说明峰值在左边,尾巴在右边,所以右偏。
偏态是看尾巴在哪边。
——第3题——3. 对一个特定情形的估计来说,置信水平越低,所对应的置信区间?A. 越小B. 越大C. 不变D. 无法判断答案:A「题目解析」根据公式,Z减小,置信区间减小。
——第4题——4.关于logistic回归算法,以下说法不正确的是?A. logistic回归是当前业界比较常用的算法,用于估计某种事物的可能性B. logistic回归的目标变量可以是离散变量也可以是连续变量C. logistic回归的结果并非数学定义中的概率值D. logistic回归的自变量可以是离散变量也可以是连续变量答案:B「题目解析」逻辑回归是二分类的分类模型,故目标变量是离散变量,B错;logisitc回归的结果为“可能性”,并非数学定义中的概率值,不可以直接当做概率值来用,C对。
——第5题——5.下列关于正态分布,不正确的是?A. 正态分布具有集中性和对称性B. 期望是正态分布的位置参数,描述正态分布的集中趋势位置C. 正态分布是期望为0,标准差为1的分布D. 正态分布的期望、中位数、众数相同答案:C「题目解析」N(0,1)是标准正态分布。
——第6题——6. 以下关于关系的叙述中,正确的是?A. 表中某一列的数据类型可以同时是字符串,也可以是数字B. 关系是一个由行与列组成的、能够表达数据及数据之间联系的二维表C. 表中某一列的值可以取空值null,所谓空值是指安全可靠或零D. 表中必须有一列作为主关键字,用来惟一标识一行E. 以上答案都不对答案:B「题目解析」B. 关系是一张二维表,表的每一行对应一个元组,每一列对应一个域,由于域可以相同,所以必须对每列起一个名字,来加以区分,这个名字称为属性。

教师数据应用能力题目及答案1. 数据分析基础题目:请简要说明什么是数据分析?答案:数据分析是指通过收集、整理、分析和解释数据,以发现数据中的模式、趋势和关联性,并以此为基础进行决策和预测的过程。
数据分析可以帮助我们理解数据的含义,揭示数据背后的规律,并为业务决策提供支持。
题目:数据分析的步骤有哪些?答案:数据分析通常包括以下步骤:1. 收集数据:从各种来源收集相关的数据。
2. 整理数据:清洗和处理数据,使其符合分析的需求。
3. 分析数据:使用适当的统计方法和工具对数据进行分析,探索数据中的模式和趋势。
4. 解释数据:根据分析结果解释数据的含义,推断数据背后的原因和关联性。
5. 做出决策:基于数据分析的结果,制定相应的决策和行动计划。
2. 教师数据应用能力题目:为什么教师需要具备数据应用能力?答案:教师需要具备数据应用能力的原因如下:1. 个性化教学:通过分析学生的数据,教师可以了解每个学生的研究情况和需求,从而为其提供个性化的教学服务。
2. 教学改进:数据分析可以揭示教学过程中的问题和瓶颈,帮助教师针对性地改进教学方法和策略。
3. 教学评估:通过数据分析,教师可以评估学生的研究成绩和教学效果,为学校和家长提供客观的评估依据。
4. 教育决策:数据应用能力使教师能够基于数据做出科学的教育决策,提高教学质量和效益。
题目:教师如何提升数据应用能力?答案:教师可以通过以下方式提升数据应用能力:1. 研究数据分析知识:教师可以参加相关的培训课程或自学数据分析的基本知识和技能。
2. 使用数据分析工具:教师可以研究和使用一些常用的数据分析工具,如Excel、Python等,以便能够熟练地进行数据处理和分析。
3. 实践数据分析:教师可以利用学校的教学数据进行实践,例如分析学生的考试成绩、出勤情况等,从而提升自己的数据分析能力。
4. 与同行交流:教师可以与具有数据应用能力的同行进行交流和分享,互相研究和借鉴经验。
以上是教师数据应用能力题目及答案的内容。

数据分析面试题及答案数据分析面试题及答案1.问题描述在大规模数据处理中,常遇到的一类问题是,在海量数据中找出出现频率最高的前K个数,或者从海量数据中找出最大的前K个数,这类问题通常称为“top K”问题,如:在搜索引擎中,统计搜索最热门的10个查询词;在歌曲库中统计下载率最高的前10首歌等等。
2.当前解决方案针对top k类问题,通常比较好的方案是【分治+trie树/hash+小顶堆】,即先将数据集按照hash方法分解成多个小数据集,然后使用trie树或者hash统计每个小数据集中的query词频,之后用小顶堆求出每个数据集中出频率最高的前K个数,最后在所有top K中求出最终的top K。
实际上,最优的解决方案应该是最符合实际设计需求的方案,在实际应用中,可能有足够大的内存,那么直接将数据扔到内存中一次性处理即可,也可能机器有多个核,这样可以采用多线程处理整个数据集。
本文针对不同的应用场景,介绍了适合相应应用场景的解决方案。
3.解决方案3.1 单机+单核+足够大内存设每个查询词平均占8Byte,则10亿个查询词所需的内存大约是10^9*8=8G内存。
如果你有这么大的内存,直接在内存中对查询词进行排序,顺序遍历找出10个出现频率最大的10个即可。
这种方法简单快速,更加实用。
当然,也可以先用HashMap求出每个词出现的频率,然后求出出现频率最大的10个词。
3.2 单机+多核+足够大内存这时可以直接在内存中实用hash方法将数据划分成n个partition,每个partition交给一个线程处理,线程的处理逻辑是同3.1节类似,最后一个线程将结果归并。
该方法存在一个瓶颈会明显影响效率,即数据倾斜,每个线程的处理速度可能不同,快的线程需要等待慢的线程,最终的处理速度取决于慢的线程。
解决方法是,将数据划分成c*n个partition(c>1),每个线程处理完当前partition后主动取下一个partition继续处理,直到所有数据处理完毕,最后由一个线程进行归并。


数据分析及应用复习题(附参考答案)一、单选题(共30题,每题1分,共30分)1、python语言中字符串的格式化保留了同C语言类似的%格式化方法,其中%d, %s分别表示(?)。
A、A IB、B nC、C PD、D y正确答案:D2、下列字符串表示 plot 线条颜色、点的形状和类型为红色五角星点短虚线的是( )。
A、A bs-B、B go-.C、C r+-.D、D r*:正确答案:D3、以下代码执行的输出结果为:()import numpy as np arr = np.array([1, 2, 3, 4, 5, 6, 7]) print(arr[-3:-1])A、A x=random.randint(1,5, size=(5,3))B、B x=random.choice([1,2,3,4,5],size=(3,5))C、C x=random.randint(1,5, size=(3,5))D、D x=random.choice([1,2,3,4,5],size=(5,3))正确答案:B4、以下代码执行的结果为:() arr = np.array([ banana , cherry , apple , Python ]) print(np.sort(arr))A、A [ Python apple banana cherry ]B、B [ apple banana cherry Python ]C、C [ cherry banana apple Python ]D、D [ Python cherry banana apple ]正确答案:A5、对于DataFrame对象,以下说法错的是:()A、A DataFrame对象是一个表格型的数据结构B、B DataFrame对象的列是有序的C、C DataFrame对象列与列之间的数据类型可以互不相同D、D DataFrame对象每一行都是一个Series对象(P223 DataFrame对象每一列都是一个Series对象)正确答案:D6、已知中国人的血型分布约为A型:30%,B型:20%,O型:40%,AB型:10%,则任选一批中国人作为用户调研对象,希望他们中至少有一个是B 型血的可能性不低于90%,那么最少需要选多少人?A、A 7B、B 9C、C 11D、D 13正确答案:C7、数据库DB、数据库系统DBS、数据库管理系统DBMS之间的关系是______。

算法与程序设计模拟试题一、单项选择题1.穷举法的适用范围是()。
A.一切问题B.解的个数极多的问题C.解的个数有限且可一一列举D.不适合设计算法2.通过多重循环一一列举出解决问题的所有可能解,并在逐一列举的过程中,检验每个可能的解是否是问题的真正解的算法是(),而从实际问题中归纳出数学解析式,就此设计出合适的算法是()。
A.解析法穷举法B.递归法解析法C.穷举法解析法D.穷举法,递归法3.判断某自然数m是不是素数(只能被1或本身整除的大于1的自然数称为素数)的算法基本思想是:把m作为被除数,将2到m-1中的自然数作为除数,逐一进行相除,如果都除不尽,m就是素数,否则m 就不是素数。
这种判定素数的算法属于()。
A.枚举算法B.解析算法C.递归算法D.排序算法4.图书管理系统对图书管理是按图书的序号从小到大进行管理的,若要查找一本已知序号的书,则能快速的查找的算法是()。
A.枚举算法B.解析算法C.对分查找D.冒泡排序5.VB程序如下:Dim aa = Array(1,2,3,4,5,6,7,8)i = 0For k = 100 To 90 Step -2s = a(i)^2If a(i) > 3 Then Exit Fori = i + 1Next kPrint k;a(i);s上述程序的输出结果是()。
A.88 6 36B.88 1 2C.90 2 4D.94 4 166.在所有排序算法中,关键字比较次数与纪录的初始排列次序无关的是()。
A.希尔排序B.起泡排序C.插入排序D.选择排序7.在使用计算机处理数据的过程中,往往需要对数据进行排序,所谓排序就是()。
A.把杂乱无章的数据变为从小到大排列的数据B.把杂乱无章的数据变为从大到小排列的数据C.把杂乱无章的数据变为有序的数据D.以上说法都错误8.某食品连锁店5位顾客贵宾消费卡的积分依次为900、512、613、700、810,若采用选择排序算法对其进行从小到大排序,如下表,第二趟的排序结果是()A.512 613 700 900 810 B.512 810 613 900 700C.512 900 613 700 810D.512 613 900 700 8109.在《算法与程序设计》教材中,主要介绍了下列“算法”()。

数据分析及应用习题库(附答案)一、单选题(共40题,每题1分,共40分)1、Python语言属于()。
A、A机器语言B、B汇编语言C、C高级语言D、D科学计算语言正确答案:C2、以下代码执行的输出结果为:()importnumpyasnparr=np.array([1,3,5,7])print(arr[2]+arr[3])A、A8B、B12C、C5D、D13正确答案:B3、对于j=10,foriinrange(j)循环内执行语句j-=1,那么该循环将执行(?)次。
A、A10B、B7C、C6D、D程序报错正确答案:A4、Thecorrectsyntaxtoaddthe1abe1s〃〃x〃〃,"V"、and""∕'"toaPandasSeries:()importpandasaspdA、Apd.DataFrame([12,z,,z13zr,,z14zz],index=["x","y","z"])"B、Bpd.1ist([12/z,'13z,,,z1Γ],index=[〃x〃,〃y〃,〃z〃])〃C、Cpd.Series([12,z∕,13,,,,z14,z],index=[〃x〃,〃y〃,〃z〃])〃D、Ddf=Pd.Series([12”,〃13〃,〃14〃],diet=[〃x〃,〃y〃,〃z〃])〃正确答案:C5、将一颗骰子投掷两次,依次记录点数,两数之差绝对值为1的概率()A、A0.1B0.2C、C0.3D、D0.4正确答案:A6、网络报文记录及分析装置告警信息可以按照多种方式进行分类,其中不包含下列哪种方式()A、Λ网络B、BIEDC、C时间段D、D模型正确答案:D7、假设有命令(P)importnumpyasnpbArraynp.array([[1,2,3],[4,5,6]])则,bΛrray.ndim的结果是A、A逻辑覆盖法B、B等价类划分C、C边界值分析D、D功能图法正确答案:A8、随机变量X、Y的协方差,记为COV(X,Y)=(?)oA、AE((X-E(X))(Y-E(Y)))B、BE(XY-E(X)E(Y))C、CE(((D(X)D(Y))71∕2))D、DE正确答案:A9^用importmatp1ot1ib.pyp1otaspt引入pyp1ot模块后,下面可以对执行的代码是()A^Apit.p1ot([1,2,3])BsBpt.p1ot([1,2,3])C>Cpit.p1ot[1,2,3]D>Dpt.p1ot[1,2,3]正确答案:B10>用importmatp1ot1ib.pyp1otaspt引入pyp1ot模块后,下面可以对执行的代码是()A、A按位取反B、B按位异或C、C按位与D、D左移一个字节正确答案:A11A importpandasaspds=pd.Series([1,2,3],index=[2,3,1])s[2]上述代码输出结果是多少?A、A数据库设计B、B软件测试C、C软件设计D、D可行性研究正确答案:D12、fractions模块中FraCtiOn类用于构造(?)类型数据。

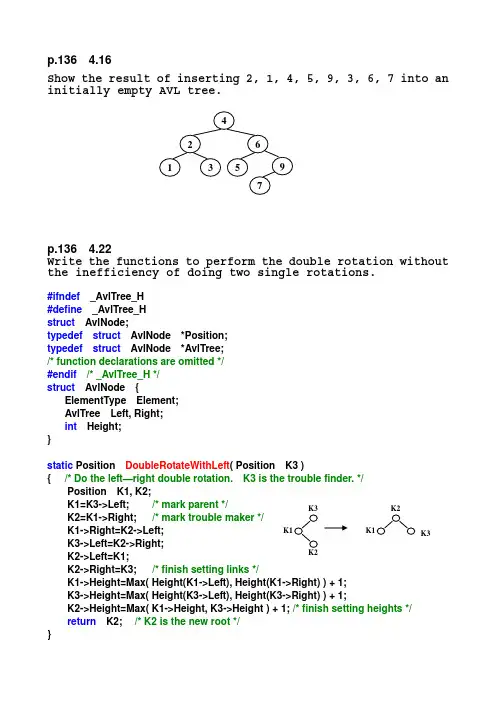
p.136 4.16Show the result of inserting 2, 1, 4, 5, 9, 3, 6, 7 into an initially empty AVL tree.p.136 4.22Write the functions to perform the double rotation without the inefficiency of doing two single rotations.#ifndef _AvlTree_H #define _AvlTree_H struct AvlNode;typedef struct AvlNode *Position; typedef struct AvlNode *AvlTree; /* function declarations are omitted */ #endif /* _AvlTree_H */ struct AvlNode { ElementType Element; AvlTree Left, Right; int Height; }static Position DoubleRotateWithLeft ( Position K3 ){ /* Do the left—right double rotation. K3 is the trouble finder. */ Position K1, K2;K1=K3->Left; /* mark parent */ K2=K1->Right; /* mark trouble maker */K1->Right=K2->Left;K3->Left=K2->Right;K2->Left=K1;K2->Right=K3; /* finish setting links */ K1->Height=Max( Height(K1->Left), Height(K1->Right) ) + 1; K3->Height=Max( Height(K3->Left), Height(K3->Right) ) + 1; K2->Height=Max( K1->Height, K3->Height ) + 1; /* finish setting heights */ return K2; /* K2 is the new root */ }K3static Position DoubleRotateWithRight( Position K1 ){ /* Do the right--left double rotation. K1 is the trouble finder. */Position K2, K3; /* Similar to the above function */K3=K1->Right;K2=K3->Left;K1->Right=K2->Left;K3->Left=K2->Right;K2->Left=K1;K2->Right=K3;K1->Height=Max( Height(K1->Left), Height(K1->Right) ) + 1;K3->Height=Max( Height(K3->Left), Height(K3->Right) ) + 1;K2->Height=Max( K1->Height, K3->Height ) + 1;return K2;}p.136 4.23Show the result of accessing the keys 3, 9, 1, 5 in order in the splay tree in Figure 4.61.Figure 4.61Result for 3:Result for 9:Result for 1:Result for 5:。
《计算方法》习题答案第一章 数值计算中的误差1.什么是计算方法?(狭义解释)答:计算方法就是将所求的的数学问题简化为一系列的算术运算和逻辑运算,以便在计算机上编程上机,求出问题的数值解,并对算法的收敛性、稳定性和误差进行分析、计算。
2.一个实际问题利用计算机解决所采取的五个步骤是什么?答:一个实际问题当利用计算机来解决时,应采取以下五个步骤: 实际问题→建立数学模型→构造数值算法→编程上机→获得近似结果 4.利用秦九韶算法计算多项式4)(53-+-=x x x x P 在3-=x 处的值,并编程获得解。
解:400)(2345-+⋅+-⋅+=x x x x x x P ,从而 1 0 -1 0 1 -4 -3 -3 9 -24 72 -2191-38-2473-223所以,多项式4)(53-+-=x x x x P 在3-=x 处的值223)3(-=-P 。
5.叙述误差的种类及来源。
答:误差的种类及来源有如下四个方面:(1)模型误差:数学模型是对实际问题进行抽象,忽略一些次要因素简化得到的,它是原始问题的近似,即使数学模型能求出准确解,也与实际问题的真解不同,我们把数学模型与实际问题之间存在的误差称为模型误差。
(2)观测误差:在建模和具体运算过程中所用的一些原始数据往往都是通过观测、实验得来的,由于仪器的精密性,实验手段的局限性,周围环境的变化以及人们的工作态度和能力等因素,而使数据必然带有误差,这种误差称为观测误差。
(3)截断误差:理论上的精确值往往要求用无限次的运算才能得到,而实际运算时只能用有限次运算的结果来近似,这样引起的误差称为截断误差(或方法误差)。
(4)舍入误差:在数值计算过程中还会用到一些无穷小数,而计算机受机器字长的限制,它所能表示的数据只能是一定的有限数位,需要把数据按四舍五入成一定位数的近似的有理数来代替。
这样引起的误差称为舍入误差。
6.掌握绝对误差(限)和相对误差(限)的定义公式。
数值分析韩旭里答案【篇一:数值分析上机题目】>1631110xxxx 材料科学与工程学院一.第2章插值法l2.7 给定数据表2-15.用newton插值公式计算3次插值多项式n3(x).表2-15x f(x)1 1.251.52.500 1.002 5.50a. matlab代码如下,two.m,%第二章,p45,练习题2第七题 clear(); x=[1,1.5,0,2];y(:,1)=[1.25,2.50,1.00,5.50];%已知点集合x和y syms t w; w(1)=1; %计算基函数序列w和差商表y,以及函数序列的权数diag(y),计算的牛顿三次多项式表述为t的函数 for j=2:length(x) fori=j:length(x)y(i,j)=(y(i,j-1)-y(i-1,j-1))/(x(i)-x(i-j+1)); i=i+1; endw(j)=prod(t-x(1:j-1)); j=j+1; enddisp(三次牛顿插值多项式为); disp(collect(w*diag(y)));plot(x,y(:,1),*); hold on;fplot(collect(w*diag(y)),[-0.5,2.5]);legend({已知点集,三次牛顿插值多项式函数},location,northwest,fontsize,14); xlabel(x,fontsize,16);ylabel(y,fontsize,16); hold off;b. 计算结果如下:二.第3章函数逼近与数据拟合a. matlab代码,three.m,%第三章函数逼近与数据拟合,p68练习题,第2题 clear(); syms x;%所使用的非线性基函数序列,用符号表示 y=abs(x);%被逼近函数f=[1,x^2,x^4];%求解法方程的系数矩阵a*gn=b,其中a和b均为行向量gn=ones(length(f),length(f)); for i=1:length(f) for j=1:length(f) gn(i,j)=int(f(i)*f(j),-1,1);j=j+1; endb(i)=int(f(i)*y,-1,1); i=i+1; enda=b/gn;%最佳平方逼近的系数行向量 disp(逼近函数表达式);disp(vpa(f*a));disp(最佳函数逼近得平方误差); disp(vpa(int(y^2,-1,1)-a*b));fplot(y,[-1,1]); hold on; fplot(a*f,[-1,1]);legend({被逼近函数,逼近函数},location,north,orientation,horizontal,fontsize,16,fontweight,b old);xlabel(x,fontsize,20,fontweight,bold);ylabel(y,fontsize,20,fontweight,bold); hold off;b. 运行结果如下:三.第4章数值积分与数值微分例4.9用romberg求积法计算定积分 01sin?(??)??a. matlab代码,four.m%romberg求积公式,外推原理 clear(); clear(); format long; a=0; b=1;t(1,1)=(b-a)/2*(f(a)+f(b));t(2,1)=1/2*t(1,1)+(b-a)/2*f((a+b)/2); t(1,2)=(4*t(2,1)-t(1,1))/(4-1);col=2;while abs(t(1,col)-t(1,col-1))0.5*10^-6%t(1,col)对应的计算的是多少步的值,col→coln关系col=col+1;%此时求得是第n+1次均分后的结果,使用的是第n次的结果,注意在矩阵 %计算的第n斜列是第n-1次均分的结果 for j=1:colif j==1h=(b-a)/2^(col-2);%使用n+1之前的第n次结果【篇二:数值分析a教学】>一、课程基本信息二、课程目的和任务“数值分析”是理工科院校计算数学、力学、物理、计算机软件等专业的学生必须掌握的一门重要的基础课程。
数据挖掘与分析考试题库(含答案)选择题1. 数据挖掘的主要功能是什么?A. 挖掘数据潜在的信息B. 对数据进行记录和处理C. 提高数据存储的效率D. 对数据进行分类和排序Answer: A2. 下列哪种算法不属于聚类算法?A. K-MeansB. BP神经网络C. DBSCAND. 层次聚类Answer: B3. 数据挖掘中使用最多的算法是什么?A. 决策树B. 关联规则C. 神经网络D. 贝叶斯Answer: A4. 数据挖掘的预处理不包括下列哪项?A. 数据压缩B. 数据清洗C. 数据变换D. 数据标准化Answer: A5. 下列哪项不是数据挖掘的步骤?A. 数据预处理B. 特征选择C. 模型评价D. 问题求解Answer: D填空题1. 数据挖掘的类型有分类、聚类和__________。
(回归)2. 决策树分类的根节点对应的是__________。
(最优属性)3. 聚类算法的优化目标是__________。
(最小化)4. 在SPSS Modeler中可以通过“数据变换”节点进行数据__________。
(离散化)5. 数据挖掘可以发现数据中的__________规律。
(潜在)论述题1. 请简要介绍数据挖掘的主要任务及其流程。
答:数据挖掘的主要任务是挖掘数据中潜在的信息,包括分类、聚类、关联规则等。
其流程通常包括数据预处理、特征选择、模型构建和模型评价等步骤。
其中,数据预处理是数据挖掘的重要步骤,包括数据清洗、数据变换、数据标准化等,主要是为了提高数据的质量和可用性。
特征选择是指选择最具有代表性的特征,以便于数据的分析和建模,主要是为了降低模型的复杂度和提高模型的精度。
模型构建是依据所选的算法来构建数据模型,包括决策树、神经网络、关联规则等。
模型评价则是通过对构建的模型进行测试和评价,以便于知道模型的优劣和改进方向。
2. 请论述聚类分析的常用算法及其优缺点。
答:聚类分析的常用算法包括K-Means、层次聚类和DBSCAN等。
第1章绪论1 •简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。
答案:数据:是客观事物的符号表示,指所有能输入到计算机中并被计算机程序处理的符号的总称。
如数学计算中用到的整数和实数,文本编辑所用到的字符串,多媒体程序处理的图形、图像、声音、动画等通过特殊编码定义后的数据。
数据元素:是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。
在有些情况下,数据元素也称为元素、结点、记录等。
数据元素用于完整地描述一个对象,如一个学生记录,树中棋盘的一个格局(状态)、图中的一个顶点等。
数据项:是组成数据元素的、有独立含义的、不可分割的最小单位。
例如,学生基本信息表中的学号、姓名、性别等都是数据项。
数据对象:是性质相同的数据元素的集合,是数据的一个子集。
例如:整数数据对象是集合N={0,士1,士2,…},字母字符数据对象是集合C={ ‘ A', ‘ B…,‘ Z,‘ a'b ',…,‘ z ' },学生基本信息表也可是一个数据对象。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
换句话说,数据结构是带“结构”的数据元素的集合,“结构”就是指数据元素之间存在的关系。
逻辑结构:从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。
因此,数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
存储结构:数据对象在计算机中的存储表示,也称为物理结构。
抽象数据类型:由用户定义的,表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称。
具体包括三部分:数据对象、数据对象上关系的集合和对数据对象的基本操作的集合。
2 •试举一个数据结构的例子,叙述其逻辑结构和存储结构两方面的含义和相互关系。
答案:例如有一张学生基本信息表,包括学生的学号、姓名、性别、籍贯、专业等。
每个学生基本信息记录对应一个数据元素,学生记录按顺序号排列,形成了学生基本信息记录的线性序列。
数据分析方法与技术近年来,随着大数据时代的到来,数据分析成为了各个行业和领域的热门话题和工作内容。
数据分析不仅可以帮助企业和组织更好地理解和把握市场和用户需求,还可以帮助领导决策者更好地了解社会情况和公众需求。
本文旨在介绍数据分析的方法和技术,并探讨其在现实应用中的价值和意义。
一、数据分析方法数据分析的方法包括统计分析、机器学习、数据挖掘等。
其中,统计分析是基于数据分布的进行分析,而机器学习则是利用算法模型来进行数据分析,数据挖掘则是根据已有数据发现新的模式和关联。
1. 统计分析统计分析是一种基于数据分布的分析方法,它通过搜集数据并将其分析,帮助处理未知问题和探索数据。
统计分析是把分析问题和理解数据结合起来的一个方法。
统计分析的重要性在于它可以帮助进行数据预测和数据控制。
它可以用于发现数据中的错误、其他规则或其他问题,以及帮助我们理解数据中发现的一些模式或规律。
2. 机器学习机器学习是一种通过训练算法来预测结果的技术。
这种方法可以利用大量的数据,训练算法以识别出数据中的模式和关联。
机器学习广泛应用在推荐系统、分类、预测和识别等领域。
机器学习可以用于数据预测和处理。
例如在金融市场中使用机器学习能够预测风险和走势等信息。
在医疗领域中,机器学习可以用于识别和预测疾病的传播趋势和分析数据。
机器学习还广泛应用于机器视觉、自然语言处理等技术领域。
3. 数据挖掘数据挖掘是一种从大量数据中发现新的模式和关联的方法,其目标是发掘数据中关联性更强的内容以进行更好的决策。
数据挖掘可以被用于发现与生产率相关联的模式,态势倾向的异常行为、预测销售趋势等,以及人们可能没有想到的其他发现。
数据挖掘在很多场景中已发挥了重要作用,尤其是在金融、企业管理和医疗等领域。
通过抽取关键数据和组织并挖掘未来可能发生的信息和趋势,数据挖掘可以发现未知的模式和规律,帮助推动整个企业或机构变得更加高效。
二、数据分析技术数据分析的技术包括数据清洗、数据可视化、模型构建等。
精品文档
数据分析算法与模型模拟题(一)
一、计算题(共4题,100分)
1、影响中国人口自然增长率的因素有很多,据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。
(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。
为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。
暂不考虑文化程度及人口分布的影响。
从《中国统计年鉴》收集到以下数据(见表1):
表1 中国人口增长率及相关数据
人口自然增长率国民总收入居民消费价格指数增长人均GDP 年份(元)率((亿元) CPI(%。
))%
1366 15037 1988 15.73 18.8
1519 1989 18 17001 15.04
1644 18718 1990 14.39 3.1
1893 21826 3.4 1991 12.98
2311 26937 11.6 6.4 1992
2998 35260 14.7 11.45 1993
4044 48108 1994 24.1 11.21
5046 17.1 10.55 59811 1995
5846 70142 1996 10.42 8.3
6420 10.06 1997 2.8 78061
-0.8 1998 9.14
83024
6796
8.18
7159 1999
88479 -1.4
7858
2000
0.4
7.58
98000
精品文档.
精品文档
0.7 6.95
108068
8622 2001
9398 119096 2002 6.45 -0.8
10542 2003 135174 6.01 1.2
12336 5.87 2004 3.9 159587
14040 1.8 5.89 2005 184089
16024 1.5
5.38
2006
213132
设定的线性回归模型为:
算法1多元线性回归.xlsx
(1)求出模型中的各个参数,试从多个角度评价此线性回归模型,并检验模型的经济意义;
(2)检验模型中是否存在多重共线性问题(逐步回归),若有,试消除多重共线性。
解:
(1)首先进行数据预处理,数据经检查,无缺失值,接着将数据导入dataHoop 平台中,进行异常值检验等分析,数据基本正常,但是数据存在多重共线性,多重共线性将在第二问中详述。
然后对数据进行多元线性回归拟合,以人口自然增长率(Y)作为因变量,国民总收入(X1)、居民消费价格指数增长率(X2)和人均GDP(X3)作为自变量,得到拟合结果为:
Y = 14.7236 + 0.0003X1 + 0.0644X2 - 0.0052X3
调整R方为0.8831,F检验的p值为0,(常数项)t检验的p值为0,国民总收入t检验的p值为0.0427,居民消费价格指数增长率t检验的p值为0.1359,人均GDPt检验的p值为0.0243。
该模型解释为在其他变量不变的情况下,国民收入每增长1亿元,则人口增长率随之增长0.0003%;在其他变量不变的情况下,居民消费价格指数增长率每增长1%,则人口增长率随之增长0.0644%;在其他变量不变的情况下,人均GDP每增长1元,则人口增长率随之降低0.0052%。
居民精品文档.
精品文档
消费价格指数增长率CPI与人口增长率呈正增长与现实情况不符,说明模型反映出的统计学意义与实际情况不完全相符,可能是因为自变量之间存在共线性。
(2)发现国民收入与人均GDP相关系数高达0.9996,两个变量间极高度相关,因此得到回归方程存在多重共线性。
变量间的多重共性对基于最小二乘法的回归模型模拟结果有非常严重的影响,导致回归结果不准确。
采用“逐步回归法”对模型进行优化消除变量间的多重共线性。
分别对单个变量进行分析:
国民总收入(X1):
:X2居民消费价格指数增长率()
精品文档.
精品文档
人均GDP(X3):
X3为基础变量;方更高,且均通过检验,所以采用通过对比,X3的调整R :(X1)和国民总收入人均GDP(X3)
X2):()GDP(人均X3和居民消费价格指数增长率
精品文档.
精品文档方更大,且均通过了检验。
X3的组合的调整R显然X1和:X2)(X1)和居民消费价格指数增长率(人均GDP(X3)、国民总收入
的假设检验并没有通过,R方有了一定的增加,但是X2当加入X2后,虽然调整和X3两个变量的方程。
方程为:所以采用X1X3
– 0.0058Y = 15.7418 + 0.0004X1
(分10抽取290人对这部电影的评分部电影进行调查研究,2、对近期上映的10 值0~10分),结果如下表所示。
部电影的评分进行因子分析,并解析各个因子的含)根据表中数据对这101(义;)2可否利用电影的评分数据对这290
名观影者进行聚类分析?给出你的理由。
(
算法2因子分析.xlsx
精品文档.
精品文档首先计算所有变量的相关系数矩阵,从结果可以看出,大部分的相关系(1)解:0.3,所以,此数据适合做因子分析。
数均大于左右,所以该数据个进行分析,结果得到第四个因子比例仅占比3%按因子为4 3个。
隐含因子设定为
载荷矩阵如下:
第一因子为动作片,第二因子为爱情片,第三因子为动画片。
所以,容易看出,)同观众可能会偏好不同类型的电影,体现在对不同类型电影的评分不同。
2(因此可以利用电影评分数据对观众进行聚类分析。
、某超市为了优化商品摆放结构,对近期顾客购买的商品类型进行了统计,如3
附表所示。
,minconfidence=50%);)写出所有有效强关联规则
((1minsupport=10% 2)结合实际情况分析顾客喜欢的商品搭配,并对该超市提出合理的建议。
(
算法3关联分析.xlsx
(1)支持度大于1的均为有效强关联规则。
精品文档.
精品文档的关联分析中可被,在DATEHOOP数据无缺失值,几个变量(商品)的值为T/F对变量果蔬、鲜肉、奶制品、蔬菜制品、肉识别,故直接将数据导入datehoop制品、冷冻食品、啤酒、红酒、软饮料、鱼类、糖果进行关联分析。
设置最小的有效强10.1、最小置信度为0.5,得到的强关联规则中提升度大于
支持度为啤蔬菜制品.}->{冷冻食品关联规则如下所示:{冷冻食品}->{蔬菜制品.蔬菜制.蔬菜制品.啤酒冷冻食品酒}->{}->{冷冻食品}->{啤酒蔬菜制啤酒鲜肉}->{冷冻食品啤酒品}->{,.鲜肉}->{红酒红酒.}->{蔬菜制品,冷冻食
品}->{啤酒}
品}->{蔬菜制品,啤酒冷冻食品
)可见,蔬菜制品、冷冻食品、啤酒之前存在较高的关联性,故建议由(1(2)故建议红酒与鲜肉之前存在较高的关联性,将三类商品陈列区域互相临近;另,将两类商品陈列区域互相临近。
、”表示有视力缺陷)”表示视力正常,“1“0某市为调查驾驶员视力情况4、(”表示没有),这三个因素对0”表示有,“年龄、是否有驾驶教育经历(“1”表示未发生过)的影响,随机0是否曾引起交通事故(“1”表示发生过,“ 45名驾
驶员,得到数据如下:抽样调查了)建立模型分析驾驶员视力情况、年龄、是否有驾驶教育经历对是否曾引起1(交通事故的影响,写出详细的思路过程。
)若要应用此模型预测某批驾驶员中可能会引起过交通事故的人都有哪些,(2 则还需要进行的研究步骤有哪些?请说明。
精品文档.
精品文档算法4逻辑回归.xlsx)数据类型是数值型的不需要数值化,而且
不存在缺失值。
逻辑回归要考虑(1因此我们进行异常值分析和相关性分异常值的影响,以及变量是否存在共线性,析。
异常值分析发现异常值较多,猜测可能是分类的影响,因此不做处理。
由相关矩阵可看出变量之间虽然也有相关,但不是很强,因此可以进行逻辑回归。
为自变量进行逻辑回归分析,分driveaccident以为因变量,视力状况、age、析结果如下:
ln(P(Yi)/(1-P(Yi))=-0.0819+-0.7412 得到逻辑回归方程
x1+0.032x2-1.4972x3、准确率召回率等都较大,模型拟合效果较好,训练误、AUC可以看到Accuracy差不大。
若想用此模型优化成为可以用来预测哪些人可能会引起过交通事故,则一2()个样本),在大样本量的基本上继续使方面需进一步丰富样本量(本题只有45直到泛化误差小到可接受的范围测试数据集训练模型的拟合度,用训练数据集、内,再进一步应用到预测中来。
精品文档.
精品文档
精品文档.。