嵌入式汇编
- 格式:doc
- 大小:27.00 KB
- 文档页数:3




嵌入式汇编延时指令
在嵌入式汇编中,延时通常用于控制程序的执行速度或等待某些事件发生。
以下是一些常见的延时指令:NOP (No Operation):这是一个空操作,它不会对任何数据进行操作。
它在一些情况下可以用于产生微小的延时。
assembly复制代码
NOP
DELAY:这是一个自定义的延时指令,具体的延时时间取决于你的硬件和编译器。
它通常会执行一系列的NOP或其他无操作指令来产生延时。
assembly复制代码
DELAY
HLT (Halt):这会导致处理器暂停执行,直到收到一个中断。
它可以用于产生更长的延时,但会消耗CPU时间。
assembly复制代码
HLT
WAIT:这个指令会使程序暂停执行,直到某个条件满足。
它通常与中断或某个特定的状态寄存器一起使用。
assembly复制代码
WAIT
循环:通过循环执行某些指令可以产生延时。
例如,你可以循环执行NOP或其他无操作指令来产生延时。
assembly复制代码
LOOP: NOP
...
...
JMP LOOP
请注意,这些只是常见的延时指令,具体的实现可能会根据你使用的硬件和编译器有所不同。
在实际应用中,你可能需要根据你的特定需求和硬件平台来调整这些指令。

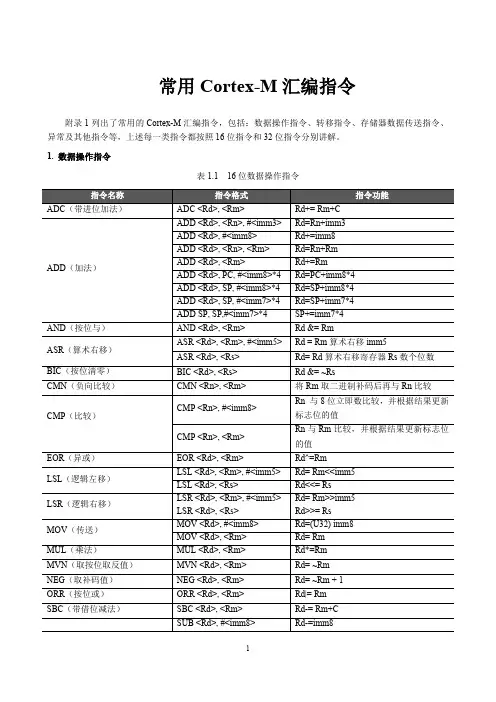
常用Cortex-M汇编指令附录1列出了常用的Cortex-M汇编指令,包括:数据操作指令、转移指令、存储器数据传送指令、异常及其他指令等,上述每一类指令都按照16位指令和32位指令分别讲解。
1. 数据操作指令表1.1 16位数据操作指令SUB <Rd>, <Rn>, <Rm> Rd= Rn-RmSUB(减法)SUB SP, #<imm7> * 4 SP-= imm7*4TST(测试)TST <Rn>, <Rm> 执行Rn & Rm,并根据结果更新标志位REV <Rd>, <Rn> Rd=Rn字内的字节顺序反转REV(反转)REVH/REV16(反转)REV16 <Rd>, <Rn> Rd=Rn两个半字内的字节顺序反转SXTB(字节提取扩展符号位)SXTB <Rd>, <Rm> 从寄存器Rm中提取字节[7:0],传送到寄存器Rd中,并用符号位扩展到32位SXTH(半字提取扩展符号位)SXTH <Rd>, <Rm> 从寄存器Rm中提取半字[15:0],传送到寄存器Rd中,并用符号位扩展到32位UXTB(字节提取扩展零位)UXTB <Rd>, <Rm> 从寄存器Rm中提取字节[7:0],传送到寄存器Rd中,并用零位扩展到32位UXTH(半字提取扩展零位)UXTH <Rd>, <Rm> 从寄存器Rm中提取半字[15:0],传送到寄存器Rd中,并用零位扩展到32位表1.2 32位数据操作指令操作,Rm 的值不变LSL (逻辑左移) LSL{S}.W <Rd>, <Rn>, <Rm> Rd= Rn<<Rm LSR (逻辑右移) LSR{S}.W <Rd>, <Rn>, <Rm> Rd= Rn>>Rm MLA (乘加) MLA.W <Rd>, <Rn>, <Rm>, <Racc> Rd= Racc+Rn*Rm MLS (乘减) MLS.W <Rd>, <Rn>, <Rm>, <Racc> Rd= Racc-Rn*RmMOVW.W <Rd>, #<imm16> 将16位立即数传送到Rd 的低半字中,并把高半字清零MOVW (加载) MOVT (加载) MOVT.W <Rd>, #<imm16> 将16位立即数传送到Rd 的高半字中,Rd 的低半字不受影响 MUL (乘法) MUL.W <Rd>, <Rn>, <Rm> Rd= Rn*Rm ORR{S}.W <Rd>, <Rn>, #<imm12 Rd= Rn | imm12ORR{S}.W <Rd>, <Rn>, <Rm>{, <shift>} 先移位Rm ,然后Rd= Rn | 新Rm ORN{S}.W <Rd>, <Rn>, #<immed12) Rd= Rn | ~imm12ORR (按位或) ORN (按位或) ORN{S}.W <Rd>, <Rn>, <Rm>{, <shift>} 先移位Rm ,然后Rd= Rn | ~新Rm RBIT (位反转) RBIT.W <Rd>, <Rm> Rd=Rm 按位反转后的值 REV.W <Rd>, <Rm> Rd=Rm 字内的字节顺序反转 REV16.W <Rd>, <Rn> Rd=Rn 每个半字内的字节顺序反转 REV (反转)REVH/REV (16反转) REVSH (反转) REVSH.W <Rd>, <Rn> Rd=Rn 低半字内的字节反转后再符号扩展ROR (循环右移) ROR{S}.W <Rd>, <Rn>, <Rm> Rd= Rn 循环右移Rm 位 RRX (带进位循环右移一位)RRX.W Rd, RnRd = (Rn>>1)+(C<<31)SBFX (带符号位段提取)SBFX.W <Rd>, <Rn>, #<lsb>, #<width> 抽取Rn 中以lsb 位为最低有效位,共width 宽度的位段,并带符号扩展到Rd 中 SDIV (带符号除法) SDIV<c><Rd>,<Rn>,<Rm>Rd= Rn/RmSMLAL (带符号64位乘加)SMLAL.W <RdLo>, <RdHi>, <Rn>, <Rm> RdHi:RdLo+= Rn*Rm SMULL 带符号64位乘法SMULL.W <RdLo>, <RdHi>, <Rn>, <Rm> RdHi:RdLo= Rn*RmSSAT (带符号数饱和运算) SSAT<C><Rd>, #<imm>, <Rn>{, <shift>} 先移位Rn ,再把Rn 的低imm 位执行带符号饱和操作,并把结果带符号扩展后写到RdSBC{S}.W <Rd>, <Rn>, #<imm12>Rd= Rn- imm12-C SUB{S}.W <Rd>, <Rn>, #<imm12> Rd= Rn-imm12SUB{S}.W <Rd>, <Rn>, <Rm>{, <shift>} 先移位Rm ,Rd= Rn-新Rm SBC (减法) SUB (减法) SUBW (减法) SUBW.W <Rd>, <Rn>, #<imm12> Rd= Rn-imm12SXTB (带符号扩展) SXTH (带符号扩展)SXTB.W <Rd>, <Rm>{,ROR #<imm>}先循环移位Rm ,然后取出Rm 的低8位,带符号扩展到32位,并存储到RdSXTH.W <Rd>, <Rm>{,ROR #<imm>}先循环移位Rm ,然后取出Rm 的低16位,带符号扩展到32位,并存储到RdTEQ.W <Rn>, #<imm12>Rn 与imm12按位异或,并根据结果更新标志位TEQ (按位异或)TEQ.W <Rn>, <Rm>{, <shift>} 先移位Rm ,然后 Rn 与Rm 按位异或,并根据结果更新标志位 TST.W <Rn>, #<imm12)>Rn 与imm12按位与,并根据结果更新标志位TST (按位与)TST.W <Rn>, <Rm>{, <shift>}先移位Rm ,然后 Rn 与Rm 按位与,并根据结果更新标志位UBFX (抽取) UBFX.W <Rd>, <Rn>, #<lsb>, #<width> 抽取Rn 中以lsb 位为最低有效位,共width 宽度的位段,并无符号扩展到Rd 中UDIV (无符号除法) UDIV<c><Rd>,<Rn>,<Rm>Rd= Rn/RmUMLAL (无符号64位乘加)UMLAL.W <RdLo>, <RdHi>, <Rn>, <Rm> RdHi:RdLo+= Rn*Rm UMULL (无符号64位乘法)UMULL.W <RdLo>, <RdHi>, <Rn>, <Rm> RdHi:RdLo= Rn*RmUSAT <c><Rd>, #<imm>, <Rn>{, <shift>} 先移位Rn ,再把Rn 的低imm 位执行带符号饱和操作,将结果无符号扩展后写到Rd 中UXTB.W <Rd>, <Rm>{, <rotation>}先循环移位Rm ,然后取出Rm 的低8位,无符号扩展到32位,并存储到RdUSAT (无符号扩展) UXTB (无符号扩展) UXTH (无符号扩展)UXTH.W <Rd>, <Rm>{, <rotation>}先循环移位Rm ,然后取出Rm 的低16位,无符号扩展到32位,并存储到Rd2. 转移指令表1.3 16位转移指令CBZ <Rn>, <label> 比较结果为零时跳转CBZ (比较转移)CBNZ(比较转移)CBNZ <Rn>, <label> 比较结果不为零时分支IT<cond> 以下面一条指令为条件IT<x><cond> 以下面两条指令为条件IT(条件转移)IT<x><y><cond> 以下面三条指令为条件IT<x><y><z><cond> 以下面四条指令为条件表1.4 32位转移指令3. 存储器数据传送指令表1.5 16位存储器数据传送指令STRB <Rd>, [<Rn>, #< offset5>] *( (U8*) (Rn+offset5) ) = (U8)Rd STRB(将寄存器中的低字节存储到存储器中)STRB <Rd>, [<Rn>, <Rm>] *( (U8*) (Rn+Rm) ) = (U8)Rd LDMIA(多字加载)LDMIA <Rn>!, <register> 多个连续的存储器字加载STMIA(多字存储)STMIA <Rn>!, <registers> 将多个寄存器字保存到连续的存储单元中,首地址由Rn给出,每保存完一个Rn+4PUSH <registers> 若干寄存器压栈PUSH(压栈)PUSH <registers, LR> 若干寄存器和LR压栈POP <registers> 若干寄存器出栈POP(出栈)PUSH <registers, PC> 若干寄存器和PC出栈表1.6 32位存储器数据传送指令中LDRSH.W <Rxf>, [PC, #+/–< offset12>] 加载PC+/–offset12地址处的半字,并带符号扩展到Rxf 中LDRSB.W <Rxf>, [<Rn>, #< offset12>]加载Rn+ offset12地址处的字节,并带符号扩展到Rxf 中LDRSB.W <Rxf>. [<Rn>], #+/-< offset8>加载Rn 地址处的字节,并带符号扩展到Rxf 中,然后Rn+/-= offset8LDRSB.W <Rxf>, [<Rn>, #<+/–< offset8>]!先Rn+/-= offset8,再加载新Rn 地址处的字节,并带符号扩展到Rxf 中LDRSB.W <Rxf>, [<Rn>, <Rm>{, LSL#<shift>}]先把Rm 按要求左移0、1、2、3位,再加载Rn+新Rm 地址处的字节,并带符号扩展到Rxf 中 LDRSB (加载字节并扩展符号位)LDRSB.W <Rxf>, [PC, #+/–< offset12>]加载PC+/- offset12地址处的字节,并带符号扩展到Rxf 中LDRD.W <Rxf>, <Rxf2>, [<Rn>, #+/–<offset8>*4]{!}读取Rn 地址加上8位偏移量乘以4处的双字到Rxf(低32位), Rxf2(高32位),前索引。

汇编语言的类型汇编语言是一种低级语言,它是由机器指令和汇编指令组成的。
汇编语言是一种直接操作计算机硬件的语言,它可以直接控制计算机的各种硬件资源,如CPU、内存、I/O等。
汇编语言的类型主要有以下几种:1. x86汇编语言x86汇编语言是一种基于Intel x86架构的汇编语言,它是目前最为流行的汇编语言之一。
x86汇编语言可以直接操作CPU的寄存器、内存和I/O端口等硬件资源,它可以实现高效的程序设计和优化。
x86汇编语言的语法比较复杂,需要掌握大量的指令和寄存器,但是它可以实现非常高效的程序设计和优化。
2. ARM汇编语言ARM汇编语言是一种基于ARM架构的汇编语言,它是嵌入式系统和移动设备上最为流行的汇编语言之一。
ARM汇编语言可以直接操作CPU的寄存器、内存和I/O端口等硬件资源,它可以实现高效的程序设计和优化。
ARM汇编语言的语法比较简单,但是需要掌握大量的指令和寄存器。
3. MIPS汇编语言MIPS汇编语言是一种基于MIPS架构的汇编语言,它是嵌入式系统和网络设备上常用的汇编语言之一。
MIPS汇编语言可以直接操作CPU的寄存器、内存和I/O端口等硬件资源,它可以实现高效的程序设计和优化。
MIPS汇编语言的语法比较简单,但是需要掌握大量的指令和寄存器。
4. AVR汇编语言AVR汇编语言是一种基于AVR架构的汇编语言,它是嵌入式系统和单片机上常用的汇编语言之一。
AVR汇编语言可以直接操作CPU 的寄存器、内存和I/O端口等硬件资源,它可以实现高效的程序设计和优化。
AVR汇编语言的语法比较简单,但是需要掌握大量的指令和寄存器。
5. PowerPC汇编语言PowerPC汇编语言是一种基于PowerPC架构的汇编语言,它是IBM和苹果电脑上常用的汇编语言之一。
PowerPC汇编语言可以直接操作CPU的寄存器、内存和I/O端口等硬件资源,它可以实现高效的程序设计和优化。
PowerPC汇编语言的语法比较复杂,需要掌握大量的指令和寄存器,但是它可以实现非常高效的程序设计和优化。

c嵌入arm汇编指令嵌入 ARM 汇编指令到 C 代码中在进行嵌入式系统开发中,经常需要使用汇编指令来对特定的硬件进行操作。
而在 C 语言中,直接使用汇编指令是不被允许的,因此需要借助特定的语法和约定来嵌入 ARM 汇编指令到 C 代码中。
本文将介绍如何在 C 代码中嵌入 ARM 汇编指令,并提供一些常用的示例。
一、嵌入 ARM 汇编指令的语法在 C 代码中嵌入 ARM 汇编指令,可以使用 `asm` 关键字和特定的语法结构。
基本的语法格式如下所示:```casm("汇编指令");```其中,"汇编指令"表示要嵌入的 ARM 汇编指令,可以是单条指令或者多条指令的序列。
需要注意的是,汇编指令通常是以字符串的形式给出,因此需要使用双引号将其括起来。
二、嵌入 ARM 汇编指令的使用示例1. 嵌入汇编指令修改寄存器的值```cint main() {int a = 10;int b = 20;asm("ldr r0, %[value]" : : [value] "m" (b)); // 将 b 的值加载到寄存器 r0asm("str %[value], %[address]" : : [value] "r" (a), [address] "m" (&a)); // 将 a 的值存储到地址 &a 处return 0;}```在上述示例中,通过 `ldr` 指令将变量 b 的值加载到寄存器 r0 中,然后通过 `str` 指令将变量 a 的值存储到地址 &a 处。
2. 嵌入汇编指令实现延时功能```cvoid delay(int count) {asm("mov r1, %[value]" : : [value] "r" (count)); // 将参数 count 的值移动到寄存器 r1asm("loop: subs r1, r1, #1"); // 寄存器 r1 的值减 1asm("bne loop"); // 如果寄存器 r1 的值不等于零,则跳转到标签loop 处继续执行return;}```上述示例中定义了一个延时函数 delay,通过循环减少寄存器 r1 的值来实现延时功能。

C51汇编语言16进制书写规则1. 概述C51汇编语言是一种常用于嵌入式系统开发的低级语言,它通过对CPU 的指令进行底层控制,可以实现对硬件设备的高效操作。
在编写C51汇编程序时,经常会用到16进制数值,因此了解16进制数值的书写规则对于正确编写程序至关重要。
本文将对C51汇编语言16进制书写规则进行详细介绍。
2. 16进制数值的表示方式16进制数值由0-9和A-F共16个字符组成,分别对应10-15的十进制数值。
在C51汇编语言中,16进制数值可以使用0x或者#前缀进行表示,例如0x1A或者#1F表示16进制数值1A和1F。
3. 16进制数值的书写规则在C51汇编语言中,16进制数值的书写规则如下:3.1 小写字母表示在书写16进制数值时,C51汇编语言允许使用小写字母a-f来表示十六进制的A-F,也就是说,整个16进制数值可以使用小写字母来表示,例如:0x1a3b。
3.2 数值前缀在表示16进制数值时,一般会在数值前面加上0x或者#前缀,这样可以明确表示这是一个16进制数值而不是10进制数值。
3.3 数值范围在C51汇编语言中,16进制数值的范围通常是0x00到0xFF,表示的是一个字节范围内的数值。
4. 16进制数值的应用在C51汇编语言程序中,16进制数值经常用于表示寄存器的位置区域、控制寄存器的位操作、设置定时器的初值等。
使用16进制数值可以有效地减少程序的长度,提高程序的执行效率。
5. 总结了解C51汇编语言16进制数值的书写规则对于编写高质量、高效率的程序至关重要。
通过掌握16进制数值的表示方式和书写规则,开发人员可以更加灵活地利用C51汇编语言来实现对嵌入式系统的底层控制,从而更好地满足项目的需求。
在C51汇编语言程序中,16进制数值的合理使用可以提高程序的可读性和可维护性,减少程序的长度,提高程序的执行效率。
对C51汇编语言16进制数值的书写规则进行了解和掌握对于程序开发人员至关重要。

这两天参加了一个编写操作系统的项目,因为要做很多底层的东西,而且这个操作系统是嵌入式的,所以开始学习ARM汇编,发现ARM汇编和一般PC平台上的汇编有很多不同,但主要还是关键字和伪码上的,其编程思想还是相同的。
现将一些学习感悟部分列出来,希望能给有问题的人一点帮助。
1、ARM汇编的格式:在ARM汇编里,有些字符是用来标记行号的,这些字符要求顶格写;有些伪码是需要成对出现的,例如ENTRY和END,就需要对齐出现,也就是说他们要么都顶格,要么都空相等的空,否则编译器将报错。
常量定义需要顶格书写,不然,编译器同样会报错。
2、字符串变量的值是一系列的字符,并且使用双引号作为分界符,如果要在字符串中使用双引号,则必须连续使用两个双引号。
3、在使用LDR时,当格式是LDR r0,=0x022248,则第二个参数表示地址,即0x022248,同样的,当src变量代表一个数组时,需要将r0寄存器指向src 则需要这样赋值:LDR r0,=src 当格式是LDR r0,[r2],则第二个参数表示寄存器,我的理解是[]符号表示取内容,r2本身表示一个寄存器地址,取内容候将其存取r0这个寄存器中。
4、在语句:CMP r0,#numBHS stop书上意思是:如果r0寄存器中的值比num大的话,程序就跳转到stop标记的行。
但是,实际测试的时候,我发现如果r0和num相等也能跳转到stop 标记的行,也就是说只要r0小于num才不会跳转。
下面就两个具体的例子谈谈ARM汇编(这是我昨天好不容易看懂的,呵呵)。
第一个是使用跳转表解决分支转移问题的例程,源代码如下(保存的时候请将文件后缀名改为s):AREA JumpTest,CODE,READONLYCODE32num EQU 4ENTRYstartMOV r0, #4MOV r1, #3MOV r2, #2MOV r3, #0CMP r0, #numBHS stopADR r4, JumpTableCMP r0, #2MOVEQ r3, #0LDREQ pc, [r4,r3,LSL #2]CMP r0, #3MOVEQ r3, #1LDREQ pc, [r4,r3,LSL #2]CMP r0, #4MOVEQ r3, #2LDREQ pc, [r4,r3,LSL #2]CMP r0, #1MOVEQ r3, #3LDREQ pc, [r4,r3,LSL #2]DEFAULTMOVEQ r0, #0SWITCHENDstopMOV r0, #0x18LDR r1, =0x20026SWI 0x123456JumpTableDCD CASE1DCD CASE2DCD CASE3DCD CASE4DCD DEFAULTCASE1ADD r0, r1, r2B SWITCHENDCASE2SUB r0, r1, r2B SWITCHENDCASE3ORR r0, r1, r2B SWITCHENDCASE4AND r0, r1, r2B SWITCHENDEND程序其实很简单,可见我有多愚笨!还是简要介绍一下这段代码吧。

在阅读Linux源代码时,你可能碰到一些汇编语言片段,有些汇编语言出现在以.S为扩展名的汇编文件中,在这种文件中,整个程序全部由汇编语言组成,有些汇编命令出自以.c 为扩展名的C文件中,在这种文件中,既有C语言,也有汇编语言,我们把出自现在C代码中的汇编语言叫做“嵌入式”汇编,不管这些汇编代码出现在哪里,它一定程度上都成为了阅读源代码的拦路虎。
尽管C语言已经成为编写操作系统的主要语言,但是,在操作系统与硬件打交道的过程中,在需要频繁调用的函数中以及某些特殊的场合中,C语言显得力不从心,这时繁琐但又高效的汇编语言必须粉墨登场。
因此,在了解一些硬件的基础上,必须对相关的汇编语言知识也有所了解。
读者可能有过在DOS操作系统下编写汇编程序的经历,也具备一定的汇编知识,但是在Linux的源代码中,你可能看到了与Intel的汇编语言格式不一样的形式,这就是AT&T 的386汇编语言。
一,AT&T与Intel汇编语言的比较我们知道,Linux是Unix家族的一员,尽管Linux的历史不长,但与其相关的很多事情都发源于Unix,就Linux所使用的386汇编语言而言,它也是起源于Unix,Unix最初死为PDP-2开发的开发的,曾先后被移植到V AX及68000系列的处理器上,这些处理器上的汇编语言都采用的事A T&T指令格式,当Unix被移植到I386时,自然也就采用AT&T的汇编语言格式,而不是Intel的格式,静这两种汇编语言在语法上有一定的差异,但所基于的硬件知识是相同的。
因此,如果你非常熟悉Intel的语法格式,那么你也可以很容易地把它“移植”到AT&T来,下面我们通过对照Intel与AT&T的语法格式,以便于你把过去的知识能很快的移植过来.1.前缀在Intel的语法中,寄存器和立即数都没有前缀,但是在AT&T中,寄存器前缀以“%”,而立即数前以“$”。
混合编程的基本方式,在C51中嵌入汇编程序在单片机应用系统设计中,过去主要采用汇编语言开发程序。
汇编语言编写的程序对单片机硬件操作很方便,编写的程序代码短,效率高,但系统设计的周期长,可读性和可移植性都很差。
C语言程序开发是近年来单片机系统开发应用所采用的主要开发方式之一,C 语言功能丰富、表达能力强、使用灵活方便、开发周期短、可读性强、可移植性好。
但是,采用C 语言编程还是存在着如对硬件没有汇编方便、效率没有汇编高、编写延时程序精确度不高等缺点,因而现在单片机系统开发中经常用到C 语言与汇编语言混合编程技术。
混合编程技术可以把C 语言和汇编语言的优点结合起来,编写出性能优良的程序。
单片机混合编程技术通常是,程序的框架或主体部分用C 语言编写,对那些使用频率高、要求执行效率高、延时精确的部分用汇编语言编写,这样既保证了整个程序的可读性,又保证了单片机应用系统的性能。
1、混合编程的基本方式C 语言与汇编语言混合编程通常有两种基本方法:在C 语言中嵌入汇编程序和在C 语言中调用汇编程序。
1.1 在C51 中嵌入汇编程序在C51 中嵌入汇编程序主要用于实现延时或中断处理,以便生成精练的代码,减少运行时间。
嵌入式汇编通常用在当汇编函数不大,且内部没有复杂的跳转的时候。
在单片机C 语言程序中嵌入汇编程序是通过C51 中的预处理指令# pragmaasm/endasm 语句实现,格式如下:#pragmaASM;汇编程序代码#pragmaENDASM通过# pragma asm 和# pragma endasm 告诉C51 编译器它们之间的语句行不用编译成汇编程序代码。
1.2 在C51 中调用汇编程序。
本节是第一次在内核源程序中接触到C语言中的嵌入式汇编代码。
由于我们在通常的C语言程序的编制过程中一般是不会使用嵌入式汇编程序的,因此这里有必要对其基本格式进行简单的描述,详细的说明可参见GNU gcc手册中[5]第4章的内容(Extensions to the C Language Family),或见参考文献[20](Using Inline Assembly with gcc)。
具有输入和输出参数的嵌入汇编的基本格式为:
asm(“汇编语句”
: 输出寄存器
: 输入寄存器
: 会被修改的寄存器);
其中,“汇编语句”是你写汇编指令的地方;“输出寄存器”表示当这段嵌入汇编执行完之后,哪些寄存器用于存放输出数据。
此地,这些寄存器会分别对应一C 语言表达式或一个内存地址;“输入寄存器”表示在开始执行汇编代码时,这里指定的一些寄存器中应存放的输入值,它们也分别对应着一C变量或常数值。
下面我们用例子来说明嵌入汇编语句的使用方法。
我们在下面列出了前面代码中第22行开始的一段代码作为例子来详细解说,为了能看清楚我们将这段代码进行了重新编排和编号。
01 #define get_seg_byte(seg,addr) \
02 ({ \
03 register char __res; \
04 __asm__("push %%fs; \
05 mov %%ax,%%fs; \
06 movb %%fs:%2,%%al; \
07 pop %%fs" \
08 :"=a" (__res) \
09 :"" (seg),"m" (*(addr))); \
10 __res;})
这段10行代码定义了一个嵌入汇编语言宏函数。
因为是宏语句,需要在一行上定义,因此这里使用反斜杠'\'将这些语句连成一行。
这条宏定义将被替换到宏名称在程序中被引用的地方。
第1行定义了宏的名称,也即是宏函数名称get_seg_byte(seg,addr)。
第3行定义了一个寄存器变量__res。
第4行上的__asm__表示嵌入汇编语句的开始。
从第4行到第7行的4条AT&T格式的汇编语句。
第8行即是输出寄存器,这句的含义是在这段代码运行结束后将eax所代表的寄存器的值放入__res变量中,作为本函数的输出值,"=a"中的"a"称为加载代码,"="表示这是输出寄存器。
第9行表示在这段代码开始运行时将seg放到eax寄存器中,""表示使用与上面同个位置的输出相同的寄存器。
而(* (addr))表示一个内存偏移地址值。
为了在上面汇编语句中使用该地址值,嵌入汇编程序规定把输出和输入寄存器统一按顺序编号,顺序是从输出寄存器序列从左到右从上到下以"%0"开始,分别记为%0、%1、…%9。
因此,输出寄存器的编号是%0(这里只有一个输出寄存器),输入寄存器前一部分("" (seg))的编号是%1,而后部分的编号是%2。
上面第6行上的%2即代表(*(addr))这个内存偏移量。
现在我们来研究4— 7行上的代码的作用。
第一句将fs段寄存器的内容入栈;第二句将eax中的段值赋给fs段寄存器;第三句是把fs:(*(addr))所指定的字节放入al寄存器中。
当执行完汇编语句后,输出寄存器eax的值将被放入__res,作为该宏函数的返回值。
很简单,不是吗?
通过上面分析,我们知道,宏名称中的seg代表一指定的内存段值,而addr表示一内
存偏移地址量。
到现在为止,我们应该很清楚这段程序的功能了吧!该宏函数的功能是从指定段和偏移值的内存地址处取一个字节。
在看下一个例子。
01 asm("cld\n\t"
02 "rep\n\t"
03 "stol"
04 : /* 没有输出寄存器*/
05 : "c"(count-1), "a"(fill_value), "D"(dest)
06 : "%ecx", "%edi");
1-3行这三句是通常的汇编语句,用以清方向位,重复保存值。
第4行说明这段嵌入汇编程序没有用到输出寄存器。
第5行的含义是:将count-1的值加载到ecx寄存器中(加载代码是"c"),fill_value加载到eax中,dest放到edi中。
为什么要让gcc编译程序去做这样的寄存器值的加载,而不让我们自己做呢?因为gcc在它进行寄存器分配时可以进行某些优化工作。
例如fill_value值可能已经在eax中。
如果是在一个循环语句中的话,gcc就可能在整个循环操作中保留eax,这样就可以在每次循环中少用一个movl语句。
最后一行的作用是告诉gcc这些寄存器中的值已经改变了。
很古怪吧?不过在gcc知道你拿这些寄存器做些什么后,这确实能够对gcc的优化操作有所帮助。
下面列表中,是一些你可能会用到的寄存器加载代码及其具体的含义。
表4.1 常用寄存器加载代码说明
代码说明代码说明
-----------------------------------------------
a 使用寄存器eax m 使用内存地址
b 使用寄存器ebx o 使用内存地址并可以加偏移值
c 使用寄存器ecx I 使用常数0-31
d 使用寄存器edx J 使用常数0-63
S 使用esi K 使用常数0-255
D 使用edi L 使用常数0-65535
q 使用动态分配字节可寻址寄存器
(eax、ebx、ecx或edx) M 使用常数0-3
r 使用任意动态分配的寄存器N 使用1字节常数(0-255)
g 使用通用有效的地址即可
(eax、ebx、ecx、edx或内存变量) O 使用常数0-31
A 使用eax与edx联合(64位)
下面的例子不是让你自己指定哪个变量使用哪个寄存器,而是让gcc为你选择。
01asm("leal (%1, %1, 4), %0"
02: "=r"(y)
03: "0"(x));
第一句汇编语句leal (r1, r2,4), r3语句表示r1+r2*4  r3。
这个例子可以非常快地将x乘5。
其中"%0","%1"是指gcc自动分配的寄存器。
这里"%1"代表输入值x要放入的寄存器,"%0"表示输出值寄存器。
输出寄存器代码前一定要加等于号。
如果输入寄存器的代码是0或为空时,则说明使用与相应输出一样的寄存器。
所以,如果gcc 将r指定为eax的话,那么上面汇编语句的含义即为:
"leal (eax,eax,4), eax"
注意:在执行代码时,如果不希望汇编语句被gcc优化而挪动地方,就需要在asm符
号后面添加volatile关键词:
as m volatile (……);
或者更详细的说明为:
__asm__ __volatile__ (……);
下面在具一个较长的例子,如果能看得懂,那就说明嵌入汇编代码对你来说基本没问题了。
这段代码是从include/string.h文件中摘取的,是strncmp()字符串比较函数的一种实现。
需要注意的是,其中每行中的"\n\t"是用于gcc预处理程序输出列表好看而设置的,含义与C语言中相同。
//// 字符串1与字符串2的前count个字符进行比较。
// 参数:cs - 字符串1,ct - 字符串2,count - 比较的字符数。
// %0 - eax(__res)返回值,%1 - edi(cs)串1指针,%2 - esi(ct)串2指针,%3 - ecx(count)。
// 返回:如果串1 > 串2,则返回1;串1 = 串2,则返回0;串1。