因子分析在STATA中实现和案例
- 格式:doc
- 大小:163.50 KB
- 文档页数:14

stata 因子变量
在使用Stata进行回归分析时,需要将一些分类变量(例如性别、教育程度、年龄组等)转换成因子变量,以便于进行分析。
对于一个分类变量,Stata会将其全部作为一个变量来处理,这
可能会导致一些误差和偏差。
因此,需要将分类变量转换成若干个二
元因子变量。
假设有一个分类变量“受教育程度(仅限于初中毕业、高中毕业、本科毕业)”,这个变量可以用3个二元因子变量来代表,分别是
“初中毕业”、“高中毕业”和“本科毕业”。
在Stata中,可以使
用以下命令将分类变量转换成因子变量:
tabulate education_level //查看分类变量的类别
gen hsgrad = (education_level=="高中毕业")
gen collegegrad = (education_level=="本科毕业")
在上述命令中,先使用tabulate命令查看分类变量的类别,然
后使用gen命令来新建两个变量hsgrad和collegegrad,分别用来表
示是否是高中毕业和本科毕业。
如果是高中毕业,则hsgrad取值为1,否则为0;如果是本科毕业,则collegegrad取值为1,否则为0。
这样,我们就可以在回归模型中使用这些因子变量来代表分类变量,以便进行更准确的分析。

因子分析在STATA中实现和案例因子分析是一种统计方法,用来研究一组变量之间的相关性,以及这些变量是否可以被归纳为更少的无关变量,即因子。
在STATA软件中,我们可以使用factor命令进行因子分析。
在本文中,我们将介绍STATA中因子分析的实现步骤,并给出一个案例来说明。
实现步骤:1. 数据准备:将需要进行因子分析的变量导入STATA软件,并确保变量为连续型变量。
如果变量中存在缺失值,可以使用命令“dropmiss”删除缺失值。
2. 因子分析模型的选择:在因子分析中,我们需要选择合适的因子数和因子分析模型。
常见的因子数选择方法有Kaiser准则、斯科马洛维准则和Cattell准则等。
常见的因子分析模型有主成分分析和最大似然估计法。
在STATA中,我们可以使用命令“factor”来估计主成分分析模型或最大似然估计法模型。
3. 进行因子分析:在STATA中,我们可以使用命令“factor”进行因子分析。
命令的一般语法如下:factor 变量列表,选项常用的选项有:-pca:使用主成分分析模型-ml:使用最大似然估计法模型-factors(n):指定因子的个数为n-rotation(r):选择因子旋转方法,常见的有方差最大旋转法(varimax)和极大似然估计法(method=ml)等4.结果解读:进行因子分析后,STATA会生成一份结果报告,其中包括每个因子的因子载荷、特征值、解释方差比等指标。
因子载荷可以用来解释原始变量与因子之间的关系,特征值可以用来衡量因子的重要性,解释方差比可以用来衡量因子分析模型的拟合度。
案例:假设我们现在有一组数据,包括10个变量:x1、x2、x3、x4、x5、x6、x7、x8、x9和x10。
我们希望对这组变量进行因子分析,以便找出潜在的结构。
步骤如下:1.数据准备:将数据导入到STATA软件中,并确保变量为连续型变量。
2. 因子分析模型的选择:我们首先通过计算相关性矩阵来选择合适的因子数。

因子分析︱使用Stata做主成分分析文章来自计量经济学圈主成分分析在许多领域的研究与应用中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律。
多变量大样本无疑会为研究和应用提供了丰富的信息,但也在一定程度上增加了数据采集的工作量,更重要的是在多数情况下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性,同时对分析带来不便。
如果分别对每个指标进行分析,分析往往是孤立的,而不是综合的。
盲目减少指标会损失很多信息,容易产生错误的结论。
因此需要找到一个合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。
由于各变量间存在一定的相关关系,因此有可能用较少的综合指标分别综合存在于各变量中的各类信息。
主成分分析与因子分析就属于这类降维的方法。
主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。
主成分分析,是考察多个变量间相关性一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构,即从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,且彼此间互不相关.通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。
最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Var(F1)越大,表示F1包含的信息越多。
因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分。
如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求Cov(F1, F2)=0,则称F2为第二主成分,依此类推可以构造出第三、第四,……,第P个主成分。
2. 问题描述下表1是某些学生的语文、数学、物理、化学成绩统计:首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系。

Stata Fama French三因子代码一、介绍Stata是一种统计分析软件,非常适合进行数据分析和数据管理。
而Fama-French三因子模型是用来解释股票回报的经典模型,在资产定价和投资组合管理中具有重要意义。
结合Stata和Fama-French三因子模型,可以对股票市场进行深入的分析和研究。
本文将详细介绍如何在Stata中使用Fama-French三因子模型进行分析,并给出相应的代码和操作步骤。
二、获取数据在使用Stata进行Fama-French三因子模型分析之前,首先需要获取所需的数据。
一般来说,可以从金融数据库或者股票交易所获取股票收益率和市值数据,以及市场大盘收益率和无风险利率数据。
在本文的案例中,我们将使用一家股票交易所提供的样本数据来进行模型分析。
三、安装Stata模块Stata并没有直接内置Fama-French三因子模型的计算功能,但是可以通过安装相应的模块来实现。
在Stata中,可以通过输入以下命令来安装ff运行Stata模块:```statassc install ff```这样就可以安装ff模块并准备好进行Fama-French三因子模型分析。
四、导入数据在安装好ff模块后,接下来可以导入所需的数据进行分析。
以导入月度股票收益率、市值和市场大盘收益率数据为例,可以按照以下步骤进行操作:```statause yourfile, clear```五、运行Fama-French三因子模型在导入数据后,就可以利用ff模块来运行Fama-French三因子模型了。
以运行单因子模型为例,可以按照以下步骤进行操作:```stataff reg stock_return, famafrench(market smb hml)```其中,stock_return为股票收益率变量名称,market为市场大盘收益率变量名称,smb为规模因子变量名称,hml为价值因子变量名称。
运行以上命令后,就可以得到Fama-French三因子模型的回归结果了。

stata迭代主因子法【实用版】目录1.引言2.Stata 迭代主因子法的概述3.Stata 迭代主因子法的操作步骤4.Stata 迭代主因子法的应用实例5.总结正文1.引言在数据分析中,主因子分析是一种常用的降维方法,它能够将原始变量转化为少数几个线性无关的主因子,从而实现变量的简化。
而 Stata 作为一款功能强大的统计分析软件,提供了迭代主因子法这一有效的主因子分析方法。
本文将对 Stata 迭代主因子法进行详细介绍,包括其概述、操作步骤和应用实例。
2.Stata 迭代主因子法的概述Stata 迭代主因子法是一种基于迭代计算的主因子分析方法,其主要目的是通过迭代计算来逼近原始变量的协方差矩阵,从而得到更准确的主因子。
这种方法在处理高维数据和大规模数据时具有较好的效果,能够提高主因子分析的准确性和可靠性。
3.Stata 迭代主因子法的操作步骤在 Stata 中,可以使用“factor”命令进行迭代主因子分析。
以下是具体的操作步骤:(1) 首先,输入原始数据。
假设我们有一个包含 10 个变量的数据集,可以使用以下命令:```* 示例数据* insheet using "data.csv", clear```(2) 进行迭代主因子分析。
在 Stata 中,可以使用“factor”命令进行迭代主因子分析,具体操作如下:```factor```(3) 查看迭代主因子分析的结果。
Stata 会输出迭代主因子分析的结果,包括每个主因子的方差贡献率、累积方差贡献率和特征值等。
4.Stata 迭代主因子法的应用实例假设我们有一个包含 10 个变量的数据集,希望通过主因子分析来提取其中的关键信息。
具体操作如下:(1) 首先,输入原始数据。
```* 示例数据* insheet using "data.csv", clear```(2) 进行迭代主因子分析。
```factor```(3) 查看迭代主因子分析的结果。

stata 共同因子方法
共同因子方法是一种统计技术,用于识别和解释多个变量之间的共同因子或潜在结构。
这种方法在许多领域都有应用,包括心理学、社会学、经济学等。
在Stata中,可以使用以下步骤进行共同因子分析:
确定要分析的变量。
这些变量应该是可以测量的,并且它们之间应该存在一定的相关性,以便可以识别出共同因子。
对变量进行因子分析。
在Stata中,可以使用factor命令进行因子分析。
该命令将计算每个变量的因子载荷,并确定共同因子的数量。
解释因子结构。
因子载荷是变量与共同因子之间的相关系数。
通过观察因子载荷的大小和符号,可以解释每个共同因子所代表的概念或结构。
解释因子得分。
因子得分可以帮助您了解每个观测值的共同因子结构。
可以使用Stata中的score命令来计算因子得分。
解释结果。
解释因子得分和因子载荷可以帮助您理解共同因子的含义和作用。
此外,您还可以使用这些结果进行进一步的统计分析或预测模型的开发。
总之,共同因子方法是分析多个变量之间关系的有力工具,可以帮助您揭示潜在的结构和模式。
在Stata中,使用factor命令可以轻松地进行共同因子分析,并解释结果。

因子分析︱使用Stata做主成分分析因子分析是一种常用的多变量数据分析方法,可以用于降维、变量筛选和构建综合指标等方面。
在实际应用中,Stata是一款功能强大的统计软件,可以方便地进行因子分析。
本文将介绍如何使用Stata进行主成分分析。
首先,我们需要准备好需要进行因子分析的数据。
假设我们有一份包含10个变量的数据集,每个变量都代表了某种特征或指标。
我们希望通过因子分析来找出这些变量的共同因素,并将其转化为更少的几个主成分。
在Stata中,我们可以使用“factor”命令来进行主成分分析。
首先,我们需要加载数据集。
假设我们的数据集名为“data”,我们可以使用以下命令加载数据:```use data```接下来,我们可以使用“factor”命令进行主成分分析。
以下是一个示例命令:```factor var1-var10, pcf```在上述命令中,“var1-var10”表示我们要进行因子分析的变量范围,而“pcf”表示使用主成分法进行因子分析。
执行该命令后,Stata会输出一份关于因子分析结果的报告。
报告中的一项重要指标是共同度(communality),它表示每个变量与所有因子的相关程度。
共同度越高,说明变量与因子之间的关联越强。
我们可以根据共同度来判断每个变量对应的主成分是否合适。
此外,报告还会给出每个主成分的解释方差比例(proportion of variance explained)。
解释方差比例表示每个主成分能够解释原始数据中的多少方差。
通常,我们希望选择解释方差比例较高的主成分,以便更好地代表原始数据。
在进行因子分析后,我们还可以使用“rotate”命令对主成分进行旋转,以便更好地解释数据。
Stata提供了多种旋转方法,如方差最大旋转(varimax rotation)和直角旋转(orthogonal rotation)等。
我们可以根据需要选择合适的旋转方法。
除了使用命令行进行因子分析,Stata还提供了可视化工具来帮助我们更好地理解和解释数据。

stata迭代主因子法
stata迭代主因子法(Iterative Principal Factor Method in Stata)是一种数据降维技术,用于发现和提取数据集中的主要因子。
该方法基于主成分分析(PCA)和因子分析的原理,通过迭代的方式逐渐确定数据中的主要因子,并计算每个因子对原始数据的贡献程度。
本文将一步一步回答有关stata迭代主因子法的相关问题。
第一部分:概述和背景
- 什么是迭代主因子法(Iterative Principal Factor Method)?
- 迭代主因子法在数据降维中的作用是什么?
第二部分:迭代主因子法的基本原理
- 迭代主因子法是如何通过迭代的方式确定数据中的主要因子的?
- 主成分分析(PCA)和因子分析的原理是什么?它们是如何与迭代主因子法相关联的?
第三部分:实施迭代主因子法
- 在Stata中如何使用迭代主因子法进行数据降维?
- 通过一个简单的示例数据集介绍如何使用迭代主因子法。
- 如何根据迭代主因子法的结果进行数据的解释和分析?
第四部分:迭代主因子法的应用领域和限制
- 迭代主因子法在哪些领域中得到广泛应用?
- 迭代主因子法存在哪些限制?如何根据限制进行结果的解释和分析?
第五部分:比较和结论
- 迭代主因子法与其他主成分分析方法的比较与评估。
- 在不同情景下,迭代主因子法的优势与劣势是什么?
- 结论和未来研究展望。
以上是对于stata迭代主因子法的一个大致的解析,根据需要可以进一步展开和详细讨论每一个部分。
根据不同的情况和背景,文章长度可能在3000-6000字之间。
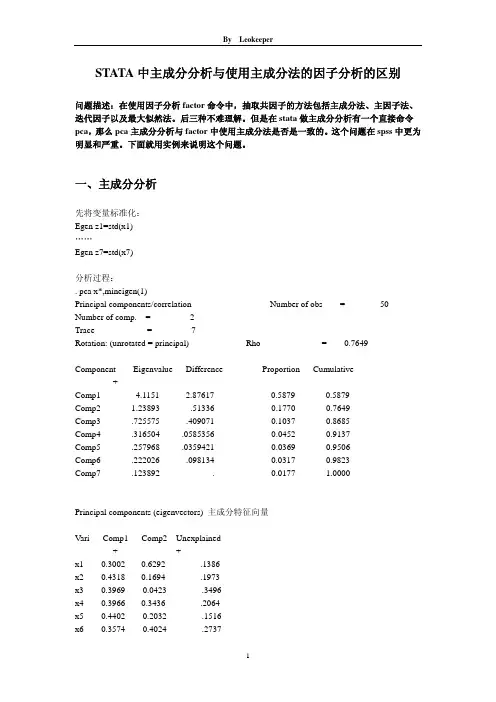
STATA中主成分分析与使用主成分法的因子分析的区别问题描述:在使用因子分析factor命令中,抽取共因子的方法包括主成分法、主因子法、迭代因子以及最大似然法。
后三种不难理解。
但是在stata做主成分分析有一个直接命令pca,那么pca主成分分析与factor中使用主成分法是否是一致的。
这个问题在spss中更为明显和严重。
下面就用实例来说明这个问题。
一、主成分分析先将变量标准化:Egen z1=std(x1)……Egen z7=std(x7)分析过程:. pca x*,mineigen(1)Principal components/correlation Number of obs = 50 Number of comp. = 2Trace = 7Rotation: (unrotated = principal) Rho = 0.7649--------------------------------------------------------------------------Component Eigenvalue Difference Proportion Cumulative-------------+------------------------------------------------------------Comp1 4.1151 2.87617 0.5879 0.5879Comp2 1.23893 .51336 0.1770 0.7649Comp3 .725575 .409071 0.1037 0.8685Comp4 .316504 .0585356 0.0452 0.9137Comp5 .257968 .0359421 0.0369 0.9506Comp6 .222026 .098134 0.0317 0.9823Comp7 .123892 . 0.0177 1.0000--------------------------------------------------------------------------Principal components (eigenvectors) 主成分特征向量------------------------------------------------Vari Comp1 Comp2 Unexplained-------------+--------------------+-------------x1 0.3002 -0.6292 .1386x2 0.4318 -0.1694 .1973x3 0.3969 0.0423 .3496x4 0.3966 -0.3436 .2064x5 0.4402 0.2032 .1516x6 0.3574 0.4024 .2737x7 0.2952 0.5023 .3288------------------------------------------------. loadingplot. estat loading,cnorm(eigen)Principal component loadings (unrotated) 主成分负荷component normalization: sum of squares(column) = eigenvalue----------------------------------Comp1 Comp2-------------+--------------------x1 .6091 -.7003x2 .8758 -.1886x3 .8051 .04705x4 .8046 -.3825x5 .8929 .2262x6 .725 .4479x7 .5988 .5591----------------------------------注:主成分向量=负荷/特征值的开方. estat kmo KMO检验Kaiser-Meyer-Olkin measure of sampling adequacy-----------------------Variable kmo-------------+---------x1 0.6759x2 0.8398x3 0.8517x4 0.8675x5 0.7961x6 0.6731x7 0.7318-------------+---------Overall 0.7836-----------------------. estat smcSquared multiple correlations of variables with all other variables-----------------------Variable smc-------------+---------x1 0.6093x2 0.7300x3 0.5951x4 0.6453x5 0.7948x6 0.7275x7 0.4858-----------------------. estat antiAnti-image correlation coefficients --- partialing out all other variables------------------------------------------------------------------------------------Va x1 x2 x3 x4 x5 x6 x7-------------+----------------------------------------------------------------------x1 1.0000x2 -0.3698 1.0000x3 -0.2740 -0.0700 1.0000x4 -0.2669 -0.3694 -0.0779 1.0000x5 -0.1825 -0.0386 -0.1297 -0.2412 1.0000x6 0.4149 -0.3903 -0.0029 0.1277 -0.6471 1.0000x7 0.2781 -0.0107 -0.4681 0.0538 -0.2887 0.0757 1.0000------------------------------------------------------------------------------------注:KMO、SMC和ANTI结合判断是否适合做主成分分析。

stata的dfactor用法dfactor是Stata软件中一个强大的命令,用于进行因子分析。
因子分析是一种统计方法,旨在将大量变量归纳为少数几个相关因子,以便简化数据集和提取隐藏的结构。
使用dfactor命令,我们可以对数据集中的变量进行因子分析,并获得有关因子的许多结果和统计信息。
要使用dfactor命令进行因子分析,首先需要确保已经安装了Stata软件并正确加载了要分析的数据集。
然后,可以按照以下步骤使用dfactor命令:1. 打开Stata软件并加载数据集。
2. 输入以下命令以查看数据集中的变量列表和描述性统计信息:summarize3. 使用dfactor命令进行因子分析。
以下是一个例子:dfactor var1 var2 var3, pcf(3)这个命令将对变量var1、var2和var3进行因子分析,提取出3个主成分因子。
4. 运行dfactor命令后,Stata将输出许多结果和统计信息,包括因子载荷(factor loadings)、公共因子方差(communalities)和特殊因子方差(unique variances)等。
这些结果将帮助我们理解数据集中的潜在因子结构和变量之间的关系。
5. 可以使用命令“help dfactor”来获取更多关于dfactor命令的详细信息和选项。
通过使用dfactor命令,我们可以探索数据集中的隐藏结构,并理解变量之间的关系。
因子分析是一个强大的统计方法,适用于各种领域和研究问题。
利用Stata软件中的dfactor命令,我们可以轻松地进行因子分析,并获得有关因子的重要信息和统计结果。

stata迭代主因子法摘要:I.引言- 介绍Stata 软件- 介绍主因子分析方法II.Stata 迭代主因子法的应用- 迭代主因子法的原理- 在Stata 中的操作步骤- 应用实例III.Stata 迭代主因子法的优势与局限- 优势:高效、易用、结果准确- 局限:对数据质量和样本量的要求IV.总结- 概括Stata 迭代主因子法的特点和应用范围- 提出未来研究方向和展望正文:I.引言Stata 是一款广泛应用于统计分析、数据处理和绘图的软件,其功能强大且操作简便。
主因子分析是一种常用的多元统计分析方法,可以用来找出多个变量之间的内在联系,以及确定对变量影响最大的主要因素。
Stata 软件提供了迭代主因子法(Iterative Principal Factors,IPF)的功能,可以方便地进行主因子分析。
II.Stata 迭代主因子法的应用迭代主因子法是一种求解主因子的高效方法,其基本原理是通过反复计算变量之间的相关系数,并选取最大相关系数对应的因子,直至所有变量均与已有因子无关。
在Stata 中,可以使用命令“pca”或者“factor”来实现迭代主因子分析。
例如,我们有一个包含5 个变量的数据集,想要进行主因子分析。
在Stata 中输入以下命令:```use example_data, clearpca var1 var2 var3 var4 var5, components(3)```其中,“example_data”为数据文件名,`var1`、`var2`、`var3`、`var4`、`var5`为需要进行主因子分析的变量名,`components(3)`表示我们想要提取3 个主因子。
执行完上述命令后,Stata 将自动完成迭代主因子分析,并输出结果。
我们可以在结果中看到提取的主因子及其方差贡献率和累积方差贡献率,以及每个变量对应的因子载荷。
III.Stata 迭代主因子法的优势与局限Stata 迭代主因子法具有以下优势:1.高效:相较于传统的求解主因子方法,迭代主因子法计算速度更快,能更快地得到结果。
[stata代码模板]主成分分析及因子分析1. 主成分分析黄色字体为自己填写部分,红色字体为可缺省部分。
————————————模板————————————factor 变量名,pc factor(#) covariance means mineigen(#)————————————模板————————————pc代表是主成分分析,如果没有pc,则为因子分析。
factor(#)指定保留因子的个数,可缺省。
covariance指定主成分是从协方差阵计算,而不是从相关阵,也就是说,不加covariance意味着变量被标准化了,可缺省。
means给出各变量的均数、标准差、最小值、最大值,可缺省。
mineigen(#)指定保留的最小特征根。
2. 因子分析主成分分析是将原指标的综合,因子分析是将原指标分解。
(1)因子载荷估计黄色字体为自己填写部分,红色字体为可缺省部分。
————————————模板————————————factor 变量名, factor(#) covariance means 因子提取的方法————————————模板————————————factor(#)、covariance、means与前面意义一样。
因子提取的方法有:Pf 主因子法(缺省时默认)pcf 主成分因子法ipf 迭代因子法ml 极大似然法mineigen(#)指定保留的最小特征根,用主成分提取因子时,缺失值为1,其他情况缺失值为0。
(2)因子旋转当因子估计的模型中的公共因子含义不清或没有合理解释时,可对因子载荷阵进行旋转,使因子载荷的结构简化,以便于对公共因子进行解释。
其原理很像调节显微镜的焦点,以便看清楚观察物的细微之处。
————————————模板————————————rotate,因子旋转的方法————————————模板————————————因子旋转的方法可以缺省,常有以下三种:正交方差极大旋转(varimax),默认为此斜交旋转(promax(#),括号内数为参加旋转的因子数),一般取2或3个因子参加旋转,stata中promax(3)为缺省值。
第13章因子分析因子分析始于1904年Chars Spearman对学生成绩的分析,在经济领域有着极为广泛的用途。
在多个变量的变化过程中,除了一些特定因素之外,还受到一些共同因素的影响。
因此,每个变量可以拆分成两部分,一是共同因素,二是特殊因素。
这些共同因素称为公因子,特殊因素称为特殊因子。
因子分析即是提出多个变量的公共影响因子的一种多元统计方法,它是主成分分析的推广。
因子分析主要解决两类问题:一是寻求基本结构,简化观察系统。
给定一组变量或观察数据,是否存在一个子集,特别是一个加权子集,来解释整个问题,即将为数众多的变量减少为几个新的因子,以再现它们之间的内在联系。
二是用于分类,将变量或样本进行分类,根据因子得分值,在因子轴所构成的空间中进行分类处理。
p个变量X的因子模型表达式为:f称为公因子,Λ称为因子载荷。
X的相关系数矩阵分解为:对于未旋转的因子,1Φ。
ψ称为特殊度,即每个变量中不属于共性的部=分。
13.1 因子估计Stata可以通过变量进行因子分析,也可以通过矩阵进行。
命令为factor 或factormat。
webuse bg2,cleardescribefactor bg2cost1-bg2cost6factor bg2cost1-bg2cost6, factors(2)* pf 主因子方法,用复相关系数的平方作为因子载荷的估计量(默认选项)factor bg2cost1-bg2cost6, factors(2) pcf* pcf 主成分因子,假定共同度=1factor bg2cost1-bg2cost6, factors(2) ipf* ipf 迭代主因子,重复估计共同度factor bg2cost1-bg2cost6, factors(2) ml* ml 极大似然因子,假定变量(至少3个)服从多元正态分布,对偏相关矩阵的行列式进行最优化求解,等价于Rao的典型因子方法13.2 预测Stata可以通过predict预测变量得分、拟合值和残差等。
因子分析在STATA中实现和案例因子分析是一种利用统计方法对多个变量进行综合分析的方法,通过对变量之间的相关性进行分析,将多个相关变量归纳为较少的无关因子,从而简化数据分析和数据解读的过程。
STATA是一款常用的统计分析软件,对因子分析提供了较为全面的支持和功能。
本文将介绍如何在STATA中实现因子分析,并通过一个实例来解释因子分析的应用。
首先,我们需要明确本次因子分析的研究目的。
假设我们的研究目的是分析一些国家的经济发展水平,使用了10个指标作为判断经济发展水平的变量,这些指标包括国内生产总值(GDP)、人均收入、就业率、失业率、消费水平、投资水平、贸易额、通货膨胀率、教育水平和医疗水平。
现在我们希望将这些指标归纳为几个综合的指标,即因子。
那么,我们首先需要进行因子分析的准备工作。
我们可以使用STATA中的`factor`命令来实现因子分析。
首先,我们需要先加载数据集。
假设我们的数据集名为"EconData",则可以使用如下命令加载数据:```use EconData```接下来,我们可以使用`factor`命令进行因子分析。
在进行因子分析之前,我们需要先进行一些参数设置。
常用的参数设置包括因子数目和因子旋转方式。
我们可以使用如下命令来设置参数:```factor varlist, factors(num_factors) rotation(method)```其中,`varlist`是要进行因子分析的变量列表,`num_factors`是要分析的因子数目,`method`是因子旋转的方法。
在本例中,我们假设选择提取3个因子,并使用最大方差法进行因子旋转。
则我们可以使用如下命令进行因子分析:``````执行以上命令后,STATA会对所选变量进行因子分析,并给出因子载荷矩阵、特殊因子方差、因子复合得分等结果。
接下来,我们来解释一下上述结果。
因子载荷矩阵显示了每个变量和每个因子之间的关系,也称为因子负荷。
在Stata中,因子变量(Factor Variable)是一种特殊的变量类型,用于在回归模型中方便地加入虚拟变量、交乘项、平方项或高次项。
这些因子变量可以从现有变量中生成,并用于合成新的指标或变量。
要合成指标,你可以使用Stata中的因子变量功能。
以下是一些常见的步骤:生成虚拟变量:如果你的数据中包含分类变量 categorical variable),你可以使用i.前缀将其转换为虚拟变量。
例如,如果你有一个名为industry的分类变量,你可以使用i.industry来生成与该分类变量相关的虚拟变量。
创建交乘项:你可以使用##或#运算符来创建交乘项。
例如,如果你有两个变量x1和x2,你可以使用c.x1##c.x2来创建它们之间的交乘项。
这将在模型中同时包括x1、x2以及它们的交乘项。
生成多项式项:如果你需要在模型中加入某个变量的高次项( 如平方项、立方项等),你可以使用c.前缀并指定所需的次数。
例如,c.x1##c.x1将生成x1的平方项。
合成新指标:一旦你生成了所需的虚拟变量、交乘项或多项式项,你可以将它们组合起来创建新的指标。
你可以使用Stata中的表达式或创建新的变量来存储这些组合。
需要注意的是,具体的操作步骤可能会因你的数据和研究需求而有所不同。
因此,在实际操作中,你可能需要根据自己的情况进行适当的调整。
另外,如果你需要进行因子分析 Factor Analysis),这是一种不同的统计方法,用于将多个相关变量综合为少数几个潜在因子。
在Stata中,你可以使用factor命令来进行因子分析,并根据提取的公因子合成新的指标。
但请注意,因子分析与因子变量在概念上是有所区别的,不要混淆它们。
希望这些信息能帮助你合成所需的指标!如果你有其他问题,请随时提问。
1。
因子分析︱使用Stata做主成分分析主成分分析(Principal Component Analysis,PCA)是一种常用的多变量数据降维方法,通过将原始变量转化为一组线性无关的主成分,实现数据的简化和解释。
本文将介绍如何使用Stata软件进行主成分分析。
首先,我们需要准备一组多变量数据,以便进行主成分分析。
假设我们有一个包含5个变量的数据集,变量分别为A、B、C、D和E。
我们将使用这些变量来进行主成分分析。
第一步,打开Stata软件并导入数据集。
可以使用命令`use`或`import`来导入数据集。
假设我们的数据集文件名为"dataset.dta",则可以使用以下命令导入数据集:```use "dataset.dta"```第二步,进行主成分分析。
在Stata中,可以使用命令`pca`来进行主成分分析。
该命令的基本语法如下:```pca varlist [if] [in] [, options]```其中,`varlist`是要进行主成分分析的变量列表,`if`和`in`是可选的条件语句,`options`是可选的参数。
假设我们要对变量A、B、C、D和E进行主成分分析,可以使用以下命令:```pca A B C D E```第三步,查看主成分分析结果。
主成分分析后,Stata会生成一些与主成分相关的结果。
可以使用命令`pca list`来查看主成分分析的结果。
该命令会显示每个主成分的方差解释比例、特征值、载荷和贡献度等信息。
除了`pca list`命令外,还可以使用其他命令来进一步分析和解释主成分分析的结果。
例如,使用`pca components`命令可以查看每个主成分的系数,使用`pca scores`命令可以计算每个样本在主成分上的得分。
第四步,解释主成分分析结果。
主成分分析的一个重要任务是解释主成分的含义和贡献。
可以使用命令`pca loadings`来查看每个变量在每个主成分上的载荷。
第13章因子分析因子分析始于1904年Chars Spearman对学生成绩的分析,在经济领域有着极为广泛的用途。
在多个变量的变化过程中,除了一些特定因素之外,还受到一些共同因素的影响。
因此,每个变量可以拆分成两部分,一是共同因素,二是特殊因素。
这些共同因素称为公因子,特殊因素称为特殊因子。
因子分析即是提出多个变量的公共影响因子的一种多元统计方法,它是主成分分析的推广。
因子分析主要解决两类问题:一是寻求基本结构,简化观察系统。
给定一组变量或观察数据,是否存在一个子集,特别是一个加权子集,来解释整个问题,即将为数众多的变量减少为几个新的因子,以再现它们之间的内在联系。
二是用于分类,将变量或样本进行分类,根据因子得分值,在因子轴所构成的空间中进行分类处理。
p个变量X的因子模型表达式为:=Λ'efX+f称为公因子,Λ称为因子载荷。
X的相关系数矩阵分解为:∑'ψ=+ΛΦΛ对于未旋转的因子,1Φ。
ψ称为特殊度,即每个变量中不属于共性的部=分。
因子估计Stata可以通过变量进行因子分析,也可以通过矩阵进行。
命令为factor或factormat。
webuse bg2,cleardescribefactor bg2cost1-bg2cost6factor bg2cost1-bg2cost6, factors(2)* pf 主因子方法,用复相关系数的平方作为因子载荷的估计量(默认选项)factor bg2cost1-bg2cost6, factors(2) pcf* pcf 主成分因子,假定共同度=1factor bg2cost1-bg2cost6, factors(2) ipf* ipf 迭代主因子,重复估计共同度factor bg2cost1-bg2cost6, factors(2) ml* ml 极大似然因子,假定变量(至少3个)服从多元正态分布,对偏相关矩阵的行列式进行最优化求解,等价于Rao的典型因子方法预测Stata可以通过predict预测变量得分、拟合值和残差等。
webuse bg2,clearfactor bg2cost1-bg2cost6predict f1 f2* factor1 factor2因子分得分predict stdp residuals* 预测标准差和残差EstatEatat给出了几个非常有用的工具,包括KMO、SMC等指标。
webuse bg2,clearfactor bg2cost1-bg2cost6estat antiestat kmoestat residualsestat smcestat summarize因子旋转与作图因子分析的旋转方法以及碎石图、得分图、因子载荷图与主成分分析的方法相同,请参见”主成分分析”一章。
webuse bg2,clearfactor bg2cost1-bg2cost6screeplot /*碎石图*/scoreplot /*得分图*/loadingplot /*因子载荷图*/rotate /*旋转*/例:利用2009年的数据对中国社会发展状况进行综合考察,原始数据如下表:省份人均GDP(元)新增固定资产(亿元)城镇居民人均年可支配收入(元)农村居民家庭人均纯收入(元)高等学校数(所)卫生机构数(个)area x1x2x3x4x5x6北京63029856497天津55473552784河北2323910515632山西20398699431内蒙古32214397162辽宁3125910414627吉林23514559659黑龙江21727787928上海73124662822江苏3962214613357浙江422149815290安徽144851047837福建30123814478江西14781828229山东3308312514973河南1959364149411683湖北1986011810305湖南1752111514455广东3758912515819广西1496614196810427海南17175162220重庆180********四川153789020738贵州8824903455848云南125871551599249西藏1386161326陕西182********甘肃121103910534青海1738991582宁夏178********新疆198********程序:clear*定义变量的标签label var area 省份label var x1 "人均GDP(元)"label var x2 "新增固定资产(亿元)"label var x3 "城镇居民人均年可支配收入(元)"label var x4 "农村居民家庭人均纯收入(元)"label var x5 "高等学校数(所)"label var x6 "卫生机构数(个)"describefactor x1-x6screeplot /* 碎石图(特征值等于1处的水平线标示保留主成分的分界点)*/*检验estat kmo /*KMO检验,越高越好*/estat smc /*SMC检验,值越高越好*/rotate /*旋转*/loadingplot , yline(0) xline(0)/*载荷图*/*预测predict score fit residual q /*预测变量得分、拟合值和残差以及残差的平方和*/ predict f1 f2label var f1 收入因子label var f2 "投资、社会因子"list area f1 f2summarize f1 f2correlate f1 f2scoreplot,xtitle("收入因子") ytitle("投资、社会因子")--------------------------------------------------------------------------LR test: independent vs. saturated: chi2(15) = Prob>chi2 =Factor loadings (pattern matrix) and unique variances-----------------------------------------------------------Variable | Factor1 Factor2 Factor3 | Uniqueness-------------+------------------------------+--------------x1_s | |x2_s | |x3_s | |x4_s | |x5_s | |x6_s | |-----------------------------------------------------------从上面的分析可以看出,只有两个成分大于1大于的特征值,同时两个成分解释了全部六个变量组合的方差还多。
不重要的第2 到6个主成分在随后的分析中可以放心地省略去。
运行factor命令后,我们可以接着运行screeplot命令画出碎石图。
碎石图中特征值等于1处的水平线标示了保留主成分的常用分界点,同时再次强调了本例中的成分3到成分6并不重要。
E i g e n v a l u e s碎石图检验的方法还是跟上一章的主成分分析一样,由于我们都是选用实际的数据来进行分析,所以在一般情况下,检验都是通得过的,可以忽略,觉得有需要的再进行检验。
旋转会进一步简化因子结构。
在提取因子之后,键入rotate 命令进行旋转。
Factor analysis/correlation Number of obs = 31 Method: principal factors Retained factors = 3 Rotation: orthogonal varimax (Kaiser off) Number of params = 15--------------------------------------------------------------------------Factor | Variance Difference Proportion Cumulative -------------+------------------------------------------------------------ Factor1 | Factor2 | Factor3 | . --------------------------------------------------------------------------LR test: independent vs. saturated: chi2(15) = Prob>chi2 =Rotated factor loadings (pattern matrix) and unique variances-----------------------------------------------------------Variable | Factor1 Factor2 Factor3 | Uniqueness-------------+------------------------------+--------------x1 | |x2 | |x3 | |x4 | |x5 | |x6 | |-----------------------------------------------------------Factor rotation matrix-----------------------------------------| Factor1 Factor2 Factor3-------------+---------------------------Factor1 |Factor2 |Factor3 |-----------------------------------------结合实际情况,我们通过上面的分析整理出前两个主因子的正交因子表。
表:正交因子表根据上表将六个指标按高载荷分成两类,并结合专业知识对各因子命名,如下表:表:高载荷分类接着进行一个后续因子分析的制图命令loadingplote有助于将其可视化。
从图中我们就可以直观的看出在主因子1中x1、x3、x4明显取得较大值,而对于主因子2则是x2、x5、x6取得较大的值。