origin模型拟合教程-肖慧珍
- 格式:doc
- 大小:1.34 MB
- 文档页数:15

Origins型曲线拟合是一种将实际观测到的数据拟合到以原点为起点的曲线上的方法。
这种类型的曲线拟合通常用于分析科学领域中的实验数据,如物理、化学和生物学等。
要进行Origins型曲线拟合,可以使用各种数学函数来拟合数据。
一种常见的方法是通过多项式拟合,可以使用线性回归、多项式回归或非线性最小二乘法等方法。
具体步骤如下:
1. 收集实际观测到的数据,并将其绘制在图表上。
2. 选择一个适合描述数据的数学函数,例如多项式函数或指数函数等。
3. 使用选定的数学函数对数据进行拟合,以找到最佳拟合曲线。
这可以通过最小二乘法、非线性最小二乘法或线性回归等方法实现。
4. 评估拟合结果,检查拟合曲线是否能够很好地描述实际观测数据。
这可以通过计算误差、R平方值或残差图等方法实现。
5. 如果拟合结果不满意,可以调整数学函数或使用其他方法重新进行拟合,直到获得满意的结果。
需要注意的是,Origins型曲线拟合是一种技术性的数据处理方法,需要具备一定的统计学和数学基础。
在进行曲线拟合时,应该遵
循科学的方法和原则,确保结果的可靠性和准确性。

origin数据拟合成曲线摘要:I.简介- 引入origin 软件- 介绍数据拟合成曲线的重要性II.origin 数据拟合成曲线的步骤- 准备数据- 选择合适的拟合模型- 输入数据并设置参数- 分析拟合结果III.数据拟合成曲线的应用- 在科学研究中的应用- 在工程实践中的应用- 在经济学和管理学中的应用IV.结论- 总结数据拟合成曲线的重要性- 强调origin 软件在数据拟合中的优势正文:I.简介在科学研究、工程实践以及经济学和管理学等领域,数据分析是必不可少的。
origin 是一款功能强大的数据处理软件,可以方便地进行数据拟合成曲线。
在开始之前,让我们先了解一下origin 软件以及数据拟合成曲线的重要性。
II.origin 数据拟合成曲线的步骤1.准备数据:首先,需要收集和整理相关的数据,这些数据可以来自于实验、观测或者调查等。
确保数据的准确性和完整性对于后续的分析至关重要。
2.选择合适的拟合模型:根据数据的特征和需求,选择合适的拟合模型。
origin 提供了多种拟合模型供用户选择,如线性拟合、多项式拟合、指数拟合等。
选择合适的拟合模型可以更好地反映数据的内在规律。
3.输入数据并设置参数:在origin 软件中,输入收集到的数据,并根据需要设置拟合参数。
例如,可以设置拟合的精度、迭代次数等。
4.分析拟合结果:origin 软件会自动根据设定的参数进行数据拟合,并生成拟合曲线。
通过分析拟合结果,可以了解数据的趋势、周期性等信息,为进一步的数据分析和实际应用提供依据。
III.数据拟合成曲线的应用数据拟合成曲线在各个领域有着广泛的应用。
在科学研究中,可以揭示数据之间的内在联系,为理论研究和实验设计提供依据;在工程实践中,可以优化设计方案、提高生产效率;在经济学和管理学中,可以预测市场趋势、指导企业决策等。
IV.结论总之,数据拟合成曲线是数据分析的重要环节,origin 软件为用户提供了方便快捷的数据拟合功能。


origin数据拟合步骤-回复数据拟合是统计学中的一项重要任务,它涉及将收集到的数据与数学模型进行比较和匹配,以得出模型中的参数估计。
这个过程通常包括以下步骤:1. 数据收集和预处理首先,我们需要收集与所需模型相关的数据。
这可能涉及到实地调查、实验室测试或从已有数据库中提取数据。
然后,我们需要对数据进行预处理,包括删除异常值、填补缺失值和进行数据归一化等操作,以减小数据的误差和噪音。
2. 选择合适的模型在选择模型时,我们需要考虑数据的特点和实际问题。
如果数据呈现线性关系,我们可以选择线性回归模型;如果数据呈现指数关系,我们可以选择指数拟合模型等等。
此外,我们还可以根据数据分布的特点,选择合适的概率分布模型进行拟合。
3. 模型参数估计模型参数估计是数据拟合的核心步骤,它通过最大似然估计、最小二乘法或贝叶斯估计等方法,对模型中的未知参数进行估计。
最大似然估计是一种常用的参数估计方法,它通过使得数据出现的概率最大来确定参数的值。
最小二乘法则是一种通过最小化实际观测值与模型估计值之间的差距来估计参数的方法。
4. 模型拟合和评估在估计出模型的参数后,我们将模型应用到数据集中,并计算模型的拟合优度。
常见的拟合优度指标包括均方差(Mean Square Error, MSE)、决定系数(Coefficient of Determination, R²)等。
这些指标可以帮助我们评估模型的拟合程度和预测能力。
5. 模型验证和调整为了进一步验证模型的有效性,我们可以利用交叉验证等技术,将数据集划分为训练集和测试集。
然后,我们可以将模型应用到训练集中,评估其预测能力,并根据结果进行调整和改进。
此外,我们还可以通过引入正则化项或进行模型选择来提高模型的泛化能力。
6. 解释和应用模型最后,我们可以利用拟合好的模型进行数据解释和应用。
通过对模型参数的解释,我们可以了解不同因素对结果的影响程度。
此外,我们还可以利用模型进行预测、决策和优化等操作,帮助我们解决实际问题。
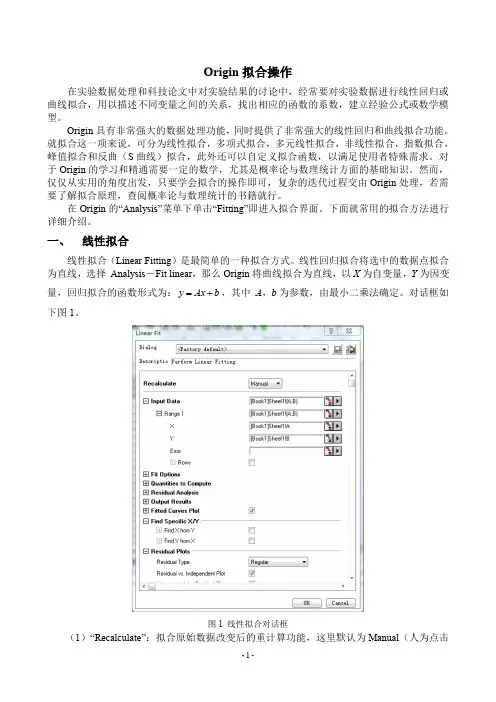

origin拟合曲线方程近年来,随着科技的迅猛发展,数据分析技术已成为了许多人眼中的“热门技能”,其中“曲线拟合”技术更是数据分析的重点。
而今天我们主要来探讨数据中,如何围绕“origin拟合曲线方程”。
一、安装Origin软件要进行曲线拟合,还需要一个数据处理软件,这里我们以常用的Origin软件为例进行介绍。
下载安装好Origin软件后,就可以愉快的开始了!二、导入数据在开始拟合曲线之前,首先需要准备好数据。
将需要拟合的数据整理成表格形式,可以将数据保存到txt、xls等格式中,然后在Origin软件中选择"File" --"Open" --选择数据文件,即可将数据导入Origin软件中。
三、创建工作表在导入数据后,需要打开Origin的工作表,在统计菜单中单击“工作表”-“新建工作表”创建一张新的工作表,将用来存储处理后的数据。
四、绘制散点图在创建好工作表后,就可以开始绘制散点图了。
将需要拟合的数据在工作表中选中,然后在顶部的菜单栏中选择“Graphs” –“Scatter” –“Simple Scatter”,即可绘制出当前数据的散点图。
五、拟合曲线方程在绘制散点图之后,可以通过相应的拟合方式来得到曲线拟合的结果。
在Origin中,包括线性拟合、非线性拟合、多项式拟合、指数拟合等多种方式。
通过选择相应的拟合方式,然后对进行拟合参数进行调整,最后点击“OK”按钮,即可得到拟合的曲线方程。
六、曲线拟合结果在拟合曲线完成之后,便可得到相应的曲线拟合方程,该方程可以用于后续的数据预测和预处理等。
综上所述,在使用Origin拟合曲线方程时,需要注意的是:首先,需要保证选取的数据是合理性的,能够准确地显示出数据的变化趋势,其次,拟合曲线的方式需要根据具体的数据情况进行选择,避免选择错误或不合适的拟合方式导致预测误差较大。
最后,要认真检查拟合参数是否恰当,以保证拟合结果的准确性和可靠性。


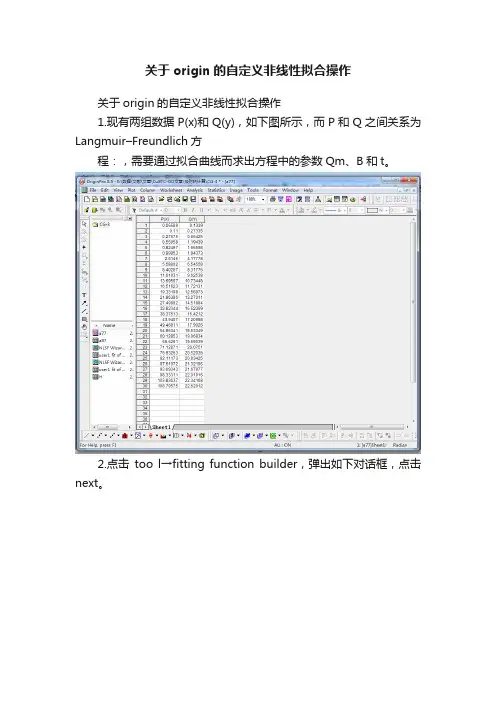
关于origin的自定义非线性拟合操作
关于origin的自定义非线性拟合操作
1.现有两组数据P(x)和Q(y),如下图所示,而P和Q之间关系为Langmuir–Freundlich方
程:,需要通过拟合曲线而求出方程中的参数Qm、B和t。
2.点击too l→fitting function builder,弹出如下对话框,点击next。
3.输入方程名称Langmuir–Freundlich,并选择origin C,如图所示,点击next。
4.输入自变量P、因变量Q和参数(Qm, B, t),如图所示,点击next。
5.将方程表达式转化为:Q=Qm*B*P^(1/t)/(1+(B*P^(1/t)))输入后,点击途中红圈所示编译
按钮。
后返回上图。
7.一直点击next,直到finish。
选中P(x)和Q(y)两列数值后点击annlysis→fitting→nonliner
curve fit→open dialog,出现下图对话框,通过category和function两个下拉菜单选择
我们刚才编辑好的方程:Langmuir–Freundlich。
由于参数的初始值系统默认均为1,这并不符合方程的收敛要求,所以需要点击红圈所示的粗拟合以便得到符合要求的参数初
始值,然后点击fit即可得到通过最小二乘法拟合出的自定义非线性曲线的各项参数值。
8.拟合后的参数值以及曲线数据等均会在同一个worbook的新sheet中展示,如下图所示。

oringin分段拟合的方法嗨,宝子们!今天咱们来唠唠Origin里分段拟合这事儿呀。
Origin可是个超厉害的数据分析和绘图软件呢。
那分段拟合是啥情况呢?比如说,咱们有一组数据,它不是那种规规矩矩能用一个函数就拟合得很好的。
可能前面一部分数据符合一种规律,后面一部分又符合另外一种规律。
这时候分段拟合就闪亮登场啦。
在Origin里,咱先把数据导进去。
这就像把食材准备好才能下锅做菜一样重要哦。
然后呢,咱得先观察数据的走势。
你就像个小侦探一样,看看哪里像是转折点。
这转折点就是咱们分段的关键啦。
找到转折点后,咱就可以开始操作拟合啦。
在Origin的菜单里找拟合的选项,就像在百宝箱里找宝贝一样。
对于每一段的数据,我们可以选择不同的拟合函数。
比如说,前面一段可能用线性拟合就很棒,那后面一段说不定指数拟合更合适呢。
这就像是给不同的小宠物找合适的小窝,每个都得舒舒服服的才行。
在进行拟合的时候,要多看看拟合的结果哦。
如果那个拟合曲线和数据点就像好朋友一样紧紧挨在一起,那说明拟合得很不错。
要是有些地方离得老远,就像两个闹别扭的小伙伴,那咱就得调整调整拟合的函数或者参数啦。
而且呀,Origin还能给咱把拟合的结果显示得清清楚楚呢。
像拟合的方程啊,相关系数这些。
咱们就可以根据这些来判断拟合的好坏啦。
要是相关系数接近1,那就像考试得了高分一样,超棒的。
还有哦,要是对拟合的曲线不满意,咱可别灰心。
就像画画的时候改了又改一样,在Origin里可以不断尝试不同的拟合方式。
说不定多试几次,就找到最完美的那个拟合啦。
分段拟合虽然有点小麻烦,但就像解开一个有趣的小谜题,当你成功的时候,那种成就感是超爽的呢。
宝子们,快去试试吧!。

origin如何拟合函数的一部分概述及解释说明1. 引言1.1 概述在科学研究和实践应用中,我们常常需要拟合函数来模拟和预测现象或数据。
函数拟合可以帮助我们找到真实数据背后的规律和趋势,从而更好地理解和解释数据。
Origin是一款功能强大的数据分析和图形绘制软件,它提供了丰富的工具和方法来进行函数拟合。
1.2 文章结构本文将详细介绍如何使用Origin软件进行函数的拟合,并重点关注如何拟合函数的一部分。
首先,在“引言”部分,我们将概述文章的目的、结构以及origin 软件的基本介绍。
接下来,在“origin如何拟合函数的一部分”部分,我们将深入探讨函数拟合方法的概念,并简要介绍Origin软件的特点。
随后,在“origin 拟合函数的步骤及工具介绍”部分,我们将逐步介绍Origin软件中关于数据导入、函数选择和参数设置以及结果分析方面所采取的步骤和工具。
最后,在“应用示例与实践经验分享”部分,我们将通过生物化学实验数据、物理实验数据以及工程应用案例来展示Origin软件在不同领域中的实际应用情况,并分享一些经验和技巧。
1.3 目的本文的目的是帮助读者更加全面地了解Origin软件在函数拟合方面的功能和应用。
通过阅读本文,读者将了解到函数拟合方法的基本原理、Origin软件的使用步骤以及如何针对不同数据类型和实际应用场景来优化拟合结果。
同时,本文还将通过具体案例分析和实践经验分享,为读者提供一些建议和指导,使他们能够在自己的研究或工作中更好地应用Origin软件进行函数拟合。
(注:文章内容仅供参考)2. origin如何拟合函数的一部分:2.1 函数拟合方法概述:在科研和实验过程中,经常需要将实验数据进行拟合,以找到最佳的函数形式来描述这些数据。
函数拟合是对实验数据进行曲线拟合,即通过在样本点之间插值来推测未测得的数值,进而得到一个连续的理论曲线。
origin是一种常用的数据可视化和分析软件,它提供了多种函数拟合方法以及丰富的工具来帮助用户完成这个过程。
origin数据拟合成曲线摘要:1.概述origin 数据拟合成曲线2.拟合成曲线的目的和意义3.拟合成曲线的方法和步骤4.拟合成曲线的应用案例5.总结正文:1.概述origin 数据拟合成曲线Origin 数据拟合成曲线是一种在Origin 软件中,通过已有数据点拟合出平滑曲线的方法。
这种曲线能够更加直观地展示数据点的变化趋势,以及数据点之间的关系。
在科学研究和数据分析领域,这种曲线经常被用于揭示数据背后的规律。
2.拟合成曲线的目的和意义拟合成曲线的主要目的是通过计算数据点之间的相互关系,找到一个能够描述这些关系并平滑连接各个数据点的曲线。
这样可以使得数据更加易于理解和分析,同时也可以提高数据的可视化效果。
此外,通过拟合成曲线,我们还可以发现数据中可能存在的规律或者趋势,这对于后续的数据分析和预测具有重要的意义。
3.拟合成曲线的方法和步骤在Origin 软件中,拟合成曲线主要有以下几种方法:线性拟合、多项式拟合、指数拟合、对数拟合等。
每种方法都有其适用的场景,需要根据具体的数据特征和研究目的进行选择。
以下是拟合成曲线的基本步骤:(1)打开Origin 软件,导入需要拟合的数据。
(2)选择数据点,创建一个新的数据表。
(3)在数据表中选择需要拟合的列,点击“分析”菜单,选择“曲线拟合”。
(4)在弹出的对话框中,选择拟合方法,设置拟合参数,然后点击“确定”。
(5)Origin 软件会自动计算并绘制出拟合曲线。
4.拟合成曲线的应用案例拟合成曲线在各个领域都有广泛的应用,例如在生物学领域,可以通过对实验数据进行拟合,发现生物体内某种物质的变化规律;在经济学领域,可以通过对历史数据进行拟合,预测未来的经济发展趋势等。
5.总结Origin 数据拟合成曲线是一种强大的数据分析和可视化工具,能够帮助我们更好地理解数据、发现数据中的规律,以及预测未来的发展趋势。
origin拟合曲线确定点坐标
如果给定一个包含一系列点的原始数据,你可以使用拟合曲线的方法来估计曲线上给定点的坐标。
以下是一个基本的步骤来拟合曲线以确定点的坐标:
1. 收集原始数据:从已知的数据源中收集一系列点的坐标,并将其作为输入数据。
2. 选择合适的拟合曲线模型:根据数据的特点和拟合的要求,选择合适的曲线模型。
常用的曲线模型包括线性、多项式、指数、对数等。
3. 使用拟合算法进行参数估计:根据选择的曲线模型,使用拟合算法来估计模型中的参数。
常用的拟合算法有最小二乘法、最大似然估计等。
4. 进行拟合:使用上一步得到的参数值,将拟合曲线绘制到原始数据上。
5. 通过曲线获得目标点的估计坐标:根据拟合曲线,确定目标点在曲线上的位置,并得到其估计的坐标。
需要注意的是,拟合曲线只是对原始数据进行估计和拟合,得到的坐标仅仅是基于模型和数据的结果,可能不完全准确。
在使用拟合曲线确定点坐标时,要根据具体应用场景和数据的特点进行合理的评估和调整。
origin模型拟合教程-肖慧珍一、langmiur模型拟合1输入数据,绘制散点图2选择langmiur模型开始进行拟合Analysis>Fitting>Nonlinear Curve Fit>Open Dialog(这一步可直接用快捷键ctrl+Y)3选择langmiur模型,注意核对公式是否一致,一致可直接采用,不一致需另外自行编辑公式,这里示范公式一致的模型拟合操作方式,编辑公式请参考下面的Freundlich模型拟合方法步骤根据langmiur公式,需要将参数c设置为04点击Fit,出现:(目前没发现Yes或No有什么不同……)拟合结果如下:因为示范数据是我随便选的,数据并不好,所以无法拟合5将模型与散点图组合把这里的数据全部复制,去sheet1里面粘贴,记得重新set X将所有的模型拟合数据输入后,回到图像,用自己擅长的方法,在原有散点图上添加数据Langmiur模型拟合教程结束附加:下面提供两种添加数据的方法,即把模型图与散点图结合1创建图层法:将df都放进右边,然后点击OK最后将右Y轴的scale调节与左Y轴一致,完成2直接添加数据法:现在表格处选中所需要添加的数据,记得设置X(列表单击右键)回到图形的页面选择Gragh>Add Plot to Layer>Line完成二、Freundlich模型拟合(自定义公式拟合教程)1从上述第2步开始,选择自定义公式2创建公式就会出现以下页面:然后关掉点OK,保存3用自定义公式进行拟合先选择刚刚保存好的函数然后编辑参数拟合结果:4然后就会出现这个:后续步骤与上述第4步和第5步一致效果完成图如下:Freundlich模型拟合教程结束。
一、langmiur模型拟合1输入数据,绘制散点图2选择langmiur模型开始进行拟合Analysis>Fitting>Nonlinear Curve Fit>Open Dialog(这一步可直接用快捷键ctrl+Y)3选择langmiur模型,注意核对公式是否一致,一致可直接采用,不一致需另外自行编辑公式,这里示范公式一致的模型拟合操作方式,编辑公式请参考下面的Freundlich模型拟合方法步骤根据langmiur公式,需要将参数c设置为04点击Fit,出现:(目前没发现Yes或No有什么不同……)拟合结果如下:因为示范数据是我随便选的,数据并不好,所以无法拟合5将模型与散点图组合把这里的数据全部复制,去sheet1里面粘贴,记得重新set X将所有的模型拟合数据输入后,回到图像,用自己擅长的方法,在原有散点图上添加数据Langmiur模型拟合教程结束附加:下面提供两种添加数据的方法,即把模型图与散点图结合1创建图层法:将df都放进右边,然后点击OK最后将右Y轴的scale调节与左Y轴一致,完成2直接添加数据法:现在表格处选中所需要添加的数据,记得设置X(列表单击右键)回到图形的页面选择Gragh>Add Plot to Layer>Line完成二、Freundlich模型拟合(自定义公式拟合教程)1从上述第2步开始,选择自定义公式2创建公式就会出现以下页面:然后关掉点OK,保存3用自定义公式进行拟合先选择刚刚保存好的函数然后编辑参数拟合结果:4然后就会出现这个:后续步骤与上述第4步和第5步一致效果完成图如下:Freundlich模型拟合教程结束。
origin e指数拟合模型公式
在Origin中,e指数拟合模型公式为y=aexp(bx),其中a和b为拟合参数。
该公式适用于拟合以e(自然对数的底)为底的指数函数。
在Origin中,可以使用Curve Fitting工具进行e指数拟合。
具体步骤如下:
1. 打开Origin软件,导入数据。
2. 在菜单栏上选择“Analysis”->“Fitting”->“Nonlinear Curve Fit”->“ExpDec1”。
3. 在弹出的对话框中,设置初始参数,点击“OK”。
4. 在Curve Fitting工具栏中,选择拟合类型为“ExpDec1”,并设置拟合参数。
5. 点击“Fit”按钮,即可进行e指数拟合,并将结果输出到Origin中。
请注意,e指数拟合模型的公式为y=aexp(bx),其中a和b为拟合参数。
在实际应用中,需要根据具体数据和问题进行选择和调整。
origin模型拟合教程-肖慧珍
一、langmiur模型拟合
1输入数据,绘制散点图
2选择langmiur模型开始进行拟合
Analysis>Fitting>Nonlinear Curve Fit>Open Dialog(这一步可直接用快捷键ctrl+Y)
3选择langmiur模型,注意核对公式是否一致,一致可直接采用,不一致需另外自行编辑公式,这里示范公式一致的模型拟合操作方式,编辑公式请参考下面的Freundlich模型拟合方法步骤
根据langmiur公式,需要将参数c设置为0
4点击Fit,出现:
(目前没发现Yes或No有什么不同……)拟合结果如下:
因为示范数据是我随便选的,数据并不好,所以无法拟合5将模型与散点图组合
把这里的数据全部复制,去sheet1里面粘贴,记得重新set X
将所有的模型拟合数据输入后,回到图像,用自己擅长的方法,在原有散点图上添加数据
Langmiur模型拟合教程结束
附加:下面提供两种添加数据的方法,即把模型图与散点图结合1创建图层法:
将df都放进右边,然后点击OK
最后将右Y轴的scale调节与左Y轴一致,完成
2直接添加数据法:
现在表格处选中所需要添加的数据,记得设置X(列表单击右键)
回到图形的页面选择Gragh>Add Plot to Layer>Line
完成
二、Freundlich模型拟合(自定义公式拟合教程)1从上述第2步开始,选择自定义公式
2创建公式
就会出现以下页面:
然后关掉点OK,保存
3用自定义公式进行拟合先选择刚刚保存好的函数
然后编辑参数
拟合结果:
4然后就会出现这个:
后续步骤与上述第4步和第5步一致效果完成图如下:
Freundlich模型拟合教程结束。